2025年山东省省赛数模竞赛C题完整论文+代码分享
基于多目标优化的中国碳排放与GDP增长双重优化研究:区域差异分析与回归模型应用
摘要
随着全球气候变化问题日益严重,如何在保证经济增长的同时有效减少碳排放已成为各国面临的重要挑战。本文通过收集中国近年来能源消费、产业结构、技术创新、经济发展及环境污染等相关数据,基于KMO检验、KPCA降维等方法,研究并优化了碳排放与GDP增长之间的关系模型,提出了一个以“碳排放最小化”和“GDP增长率最大化”为目标的优化模型,并对不同地区的碳排放及经济发展进行分析。
在数据处理部分,本文首先收集了中国各区域的能源消费结构、产业结构调整、技术创新、经济发展与环境污染的相关指标,并对数据进行了标准化处理。通过KMO检验分析数据的适宜性,并使用KPCA方法对非线性指标进行降维,以获得适合后续研究的降维数据。降维后的数据作为污染综合评价指标,分别与经济增长、产业结构、能源消费和技术创新进行回归分析。通过一次、二次、三次回归及SVR–RBF回归模型进行拟合,选择了最优模型作为关系模型。
在问题一的研究中,基于数据预处理后的降维数据,本文构建了经济增长与污染之间的关系模型,并通过不同回归模型进行拟合,选定了最高精度的回归模型进行分析。
针对问题二,本研究探讨了碳排放最小化与GDP增长最大化的双目标优化模型。首先分析了碳排放与GDP增长率的关系,发现二者并没有显著的关联。随后,通过特征选择,构建了基于相关性较高的五个指标的回归模型,并结合历史数据设置了合适的取值区间。约束条件设定了未来五年内年均GDP增长率不低于5%。采用Pareto优化算法进行求解,并对折点解和灵敏度进行分析,最终得出具有实际应用价值的优化方案。
问题三则针对不同地区的碳排放与经济发展问题,本文分别基于全国及七大地区的统计数据计算了各地区的能源消费结构和碳排放情况,并将其应用于问题二的优化模型中,探讨了不同地区在同一优化模型下的表现与差异。
最后,本研究通过对中国碳排放与经济增长之间的多维度分析,提出了符合实际的优化方案,并对不同地区的差异性进行了详细研究。本文的创新点在于结合了多种回归模型与多目标优化算法,提出了适用于中国各地区的碳排放与GDP增长双重优化策略,为政府政策制定和企业可持续发展提供了决策支持。
关键词:碳排放最小化,GDP增长最大化,回归模型,Pareto优化,KPCA
一、模型假设
为了方便模型的建立与模型的可行性,我们这里首先对模型提出一些假设,使得模型更加完备,预测的结果更加合理。
1、未来五年GDP年均增长率不低于5%: 依据中国政府规划和发展目标,假设未来五年内中国的年均GDP增长率将在5%以上。
2、假设所收集的数据具有代表性和稳定性,即这些历史数据能够较为准确地反映未来几年的经济发展趋势、能源消费结构、产业结构和技术创新的变化情况。
3、能源消费结构变化与碳排放变化是同步的:假设在经济发展过程中,能源消费结构的变化(如煤炭、石油、天然气、电力等比例的调整)会对碳排放产生直接影响。即,能源消费结构的优化和转型是控制碳排放的重要因素。
二、模型的建立与求解
5.1 数据预处理
5.1.1 数据收集
基于后续问题的需要,我们需要以国家为主题收集中国近年来的能源消费结构、产业结构调整、技术创新、经济发展与环境污染相关指标。由于各种指标复杂而多样,单一指标均不能表示整体描述,我们基于这种现状,对每个一级指标都基于国家统计局(https://data.stats.gov.cn/index.htm)进行数据收集。
具体结果如下所示
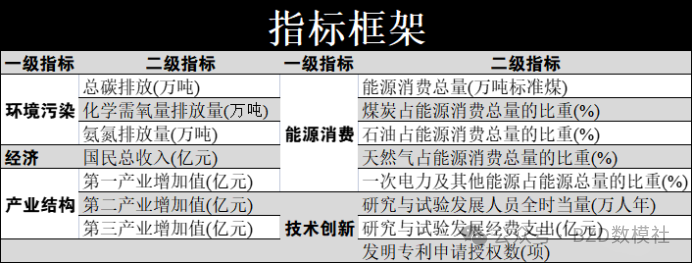
环境污染指标:
总碳排放(万吨):反映碳排放的整体水平。
化学需氧量排放量(万吨):衡量水污染程度,主要由工业废水、农业排放等引起。
氨氮排放量(万吨):是氮污染的重要指标,常见于农业和工业领域。
能源消费指标:
能源消费总量(万吨标准煤):衡量国家或地区的能源消耗水平。
各种能源的占比:煤炭、石油、天然气、一次电力及其他能源占比等,帮助我们了解能源结构。
经济发展指标:
国民总收入(亿元):衡量国家经济总量。
产业结构指标:
第一产业、第二产业、第三产业的增加值(亿元):反映各个产业对经济的贡献,间接体现其对环境污染的影响。
技术创新指标:
研究与试验发展人员(万人年):代表技术研发的投入。
研究与试验发展经费支出(亿元):反映技术创新的资金投入。
发明专利申请授权数:衡量创新成果,通常与低碳技术创新相关。
5.1.2 数据预处理
对于收集的数据,由于2024年部分数据无法统计,为了后续的建模数据输入,我们使用插值方式进行填充。
| 指标 | 环境污染 | 经济 | ||
| 总碳排放(万吨 | 化学需氧量排放量(万吨) | 氨氮排放量(万吨) | 国民总收入(亿元) | |
| 2016年 | 1267446.524 | 658.1 | 56.77 | 757492 |
| 2017年 | 1300852.072 | 608.88 | 50.87 | 846292.7 |
| 2018年 | 1342516.497 | 584.22 | 49.44 | 931972.5 |
| 2019年 | 1391921.812 | 567.14 | 46.25 | 1003108.4 |
| 2020年 | 1461529.792 | 2564.76 | 99.27 | 1026751.9 |
| 2021年 | 1502006.743 | 2530.98 | 87.68 | 1165816.8 |
| 2022年 | 1542483.693 | 2595.84 | 82.03 | 1223706.8 |
| 2023年 | 1582960.644 | 2954.37 | 119.34 | 1284773.9 |
| 2024年 | 1623437.595 | 1339814.6 | ||
在本次研究中,我们针对某地区2016年至2024年的COD(化学需氧量)排放量和氨氯排放量数据进行了插值分析,目的是通过已知的数据点来估算缺失年份的数据值,从而为末来的排放量预测提供参考。数据输入包含了多个年份的数据,部分年份的排放量数据缺失,因此需要使用插值方法来填补这些空缺。
首先,我们收集了包含缺失值的排放量数据,其中包含了2016年到2024年间的COD排放量和氨氯排放量。缺失的数据项主要集中在2024年,因此我们需要通过插值技术估算这些缺失值。为了完成插值,我们选择了三种常见的插值方法:线性插值、多项式插值和样条插值。
线性插值是一种常用的估算方法,它假设在相邻的已知数据点之间,数据变化是线性的。具体地说,对于两个相邻年份的已知排放量数据,线性插值通过建立一条直线连接这两个点,并假设该直线可以近似描述两者之间的数据变化。其数学公式为:

多项式插值,特别是三次分段插值(Piecewise Cubic Hermite Interpolating Polynomial,简称PCHIP),是一种较为精确的插值方法。PCHIP方法通过构建分段三次多项式来逼近数据点之间的变化,它不仅保证了插值点在已知数据点处的一致性,还能更好地反映数据的非线性特征,避免了过度振荡。对于每个区间,PCHIP方法根据相邻数据点的导数信息构造多项式,从而确保插值的平滑性和精确度。
最后,样条插值是一种通过分段多项式实现数据平滑拟合的方法。它通过使用低阶多项式(通常为三次多项式)在每两个已知数据点之间拟合,并保证在数据点处的连续性和光滑性。样条插值的优点在于能够提供非常平滑的曲线,并避免了多项式插值中可能出现的不必要的震荡。数学上,样条插值通过建立一个包含多个区间的分段函数来表示,确保在每个区间的连接处有连续的导数和二阶导数。
通过以上三种插值方法,我们可以得到COD排放量和氨氮排放量的完整数据序列,其中包括插值填
多项式插值,特别是三次分段插值(Piecewise Cubic Hermite Interpolating Polynomial,简称PCHIP),是一种较为精确的插值方法。PCHIP方法通过构建分段三次多项式来逼近数据点之间的变化,它不仅保证了插值点在已知数据点处的一致性,还能更好地反映数据的非线性特征,避免了过度振荡。对于每个区间,PCHIP方法根据相邻数据点的导数信息构造多项式,从而确保插值的平滑性和精确度。
最后,样条插值是一种通过分段多项式实现数据平滑拟合的方法。它通过使用低阶多项式(通常为三次多项式)在每两个已知数据点之间拟合,并保证在数据点处的连续性和光滑性。样条插值的优点在于能够提供非常平滑的曲线,并避免了多项式插值中可能出现的不必要的震荡。数学上,样条插值通过建立一个包含多个区间的分段函数来表示,确保在每个区间的连接处有连续的导数和二阶导数。
通过以上三种插值方法,我们可以得到COD排放量和氨氮排放量的完整数据序列,其中包括插值填
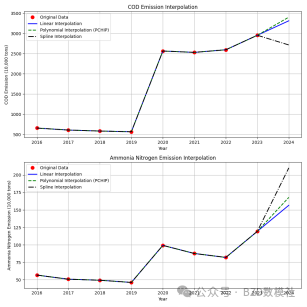
该图展示了两个排放量数据的插值结果,分别为COD排放量和氨氮排放量。图中,红色圆点表示原始数据,其中部分年份的数据缺失。线性插值、三次多项式插值和样条插值的结果通过不同的线型表示。上图为COD排放量的插值结果,线性插值呈现出较为平滑的连接,而多项式插值和样条插值则显示了更为平稳的曲线,尤其在2020年后数据变化较大的区域。下图则为氨氮排放量的插值结果,趋势类似,三种插值方法都能够较好地填补缺失的排放数据。插值后的曲线反映了各方法对数据趋势的不同拟合程度,其中样条插值和多项式插值展现了更精确的平滑度,而线性插值则较为简洁。
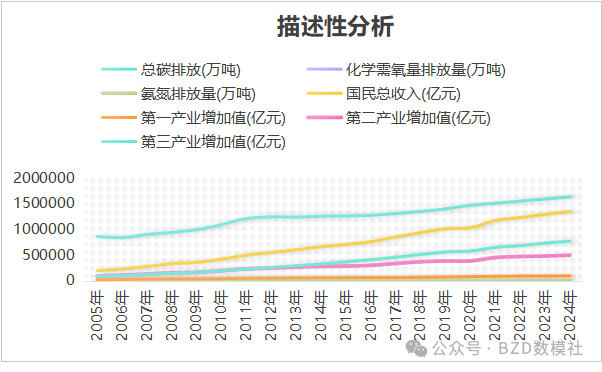
5.1.3 描述性分析
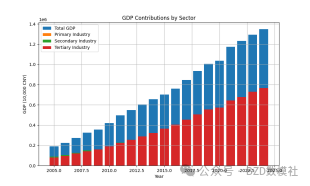
5.2 关系模型
5.2.1 经济与污染关系模型
本研究使用了相关分析和主成分分析中的KMO检验来评估数据中各变量之间的相关性,并计算其对于因子分析的适用性。首先,输入的数据矩阵包含了四个变量:总碳排放、化学需氧量(COD)排放量、氨氮排放量以及废水排放总量。这些数据经过整理后,进行了相关分析,得到了一个相关矩阵,用以描述这些变量之间的线性关系。
随后,通过对相关矩阵的逆矩阵进行计算,得到了反相关矩阵,并进而通过该矩阵计算部分相关系数矩阵。部分相关系数衡量了在控制其他变量影响后,两个变量之间的直接关系。为此,我们利用反相关矩阵的元素,计算了每对变量的部分相关系数,其公式为:

整体 KMO = 0.4359
各变量 KMO =
0.4587
0.6412
0.2897
0.4465
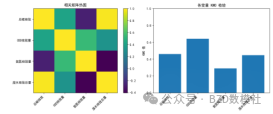
该图包含两个部分,左侧为相关矩阵的热图,右侧为各变量的KMO值条形图。在相关矩阵热图中,矩阵中的每个方格表示两个变量之间的相关系数,颜色从紫色到黄色表示相关系数的强弱,紫色代表负相关,黄色则代表正相关,颜色深浅显示了各变量之间的相关程度。根据热图,可以直观地看出不同变量之间的线性关系,显示出碳排放、化学需氧量、氨氮排放量和废水排放总量之间的关联情况。右侧的KMO值条形图展示了每个变量的KMO值,条形的高度代表各个变量在因子分析中的适用性。KMO值越高,表示该变量与其他变量之间的相关性越强,数据越适合进行因子分析。从图中可以看出,各变量的KMO值大致相近,表明这些变量在进行进一步的统计分析时具有较好的适用性。
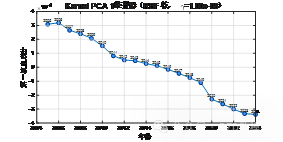
| 非线性降方式对比 |
在本研究中,我们使用了核主成分分析(Kernel Principal Component Analysis,简称Kernel PCA)方法来对数据进行非线性降维分析。与传统的线性主成分分析(PCA)不同,核主成分分析通过使用核函数将数据映射到高维空间,在高维空间中进行线性降维,从而能够处理非线性的数据结构。本研究的核心目标是通过调整核函数的参数,找到最佳的参数值,从而提取数据的主要特征,并进行有效的降维。
首先,输入的数据是一个包含20个样本、4个变量的矩阵,每行代表一个年份的数据,包含四个不同的排放量变量:总碳排放量、化学需氧量(COD)排放量、氨氮排放量以及废水排放量。这些数据在进行分析之前,先进行了标准化处理。标准化的目的是消除不同变量尺度上的差异,使得每个变量的均值为零,方差为一。标准化处理后,数据的每一列均被转换为标准正态分布,这样可以保证后续分析不会被某些具有较大数值范围的变量主导。
接下来,研究通过对不同的核函数参数值进行测试,使用高斯径向基函数(RBF,Radial Basis Function)作为核函数来计算核矩阵。高斯RBF核的计算公式如下: