LongRefiner:解决长文档检索增强生成的新思路
大语言模型与RAG的应用越来越广泛,但在处理长文档时仍面临不少挑战。今天我们来聊聊一个解决这类问题的新方法——LongRefiner。
背景问题:长文档处理的两大难题
使用检索增强型生成(RAG)系统处理长文档时,主要有两个痛点:
- 信息杂乱:长文档中往往包含大量与用户问题无关的内容,就像大海捞针,模型很难准确找到真正有用的信息。
- 计算成本高:处理完整长文档会大大增加输入长度,导致计算资源消耗增加,系统响应变慢,尤其在实际应用中更为明显。
LongRefiner:三步走策略
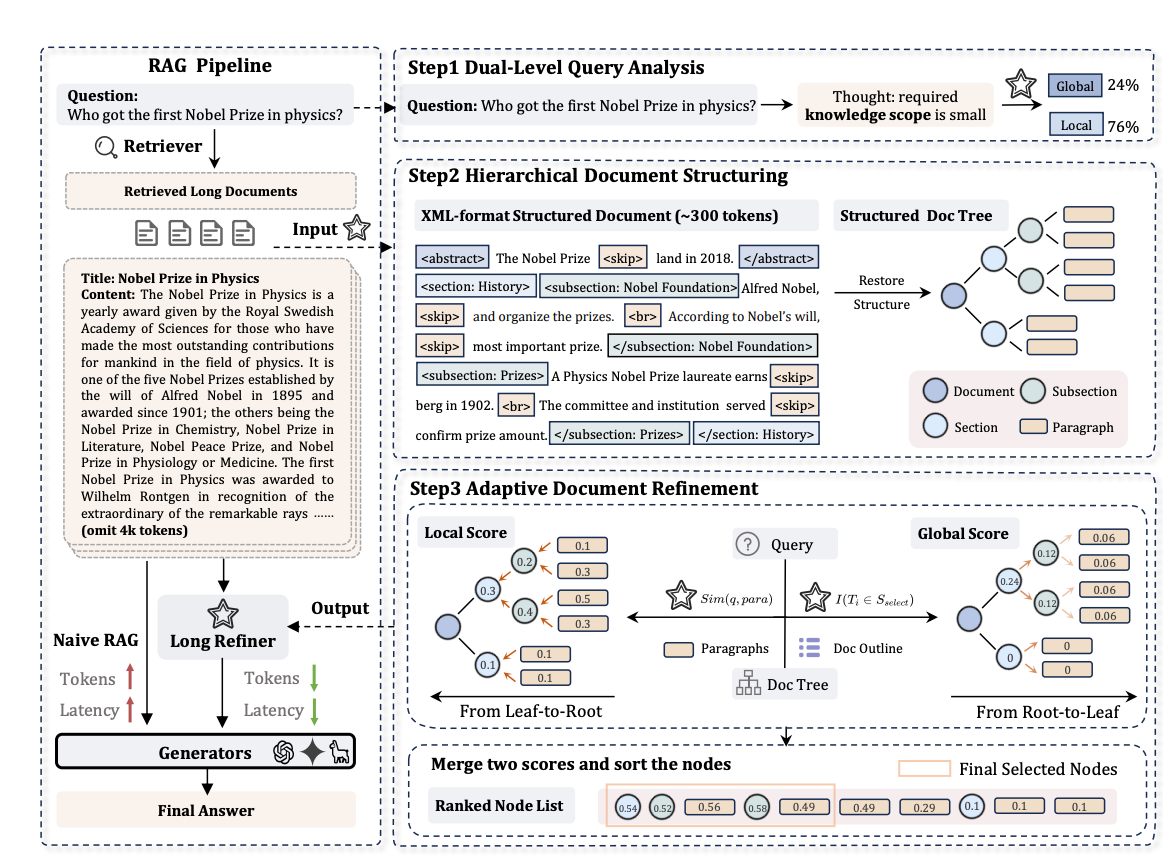
如图所示,针对这些问题,研究者提出了LongRefiner,一个即插即用的文档精炼系统。它通过三个关键步骤来提高长文档处理效率:
1. 双层查询分析
不同的问题需要不同深度的信息,LongRefiner把查询分为两种类型:
- 局部查询:只需要文档中某个部分或片段的信息就能回答
- 全局查询:需要对整个文档进行全面理解才能回答
系统会先判断用户的问题属于哪种类型,然后再决定需要提取多少信息。
2. 文档结构化处理
把杂乱无章的长文档变成有条理的结构化文档,主要包括:
- 设计基于XML的文档结构表示方式,用特殊标签(如
<section>、<subsection>)标记出文档的层次结构 - 利用维基百科网页数据建立文档结构树,方便后续处理
3. 自适应文档精炼
根据不同问题类型,系统会从两个角度评估文档各部分的重要性:
- 局部视角:从文档的最小单元(如段落)开始,计算与查询的相关性
- 全局视角:从文档的整体结构出发,确保能够全面理解文档
最后,系统会结合这两种视角的评分,筛选出最相关的内容来回答问题。
实验成果:事实胜于雄辩
研究者在多种问答数据集上进行了测试,结果相当出色:
- 在保持低延迟的情况下,LongRefiner在所有测试数据集上都取得了最佳性能
- 与现有方法相比,性能提升了9%以上
- 与直接使用完整文档的方法相比,LongRefiner将标记使用量减少了10倍,延迟降低了4倍,同时在多数数据集上性能反而更好
关键发现
实验分析还揭示了几个有意思的发现:
- 系统中的三个组件(双层查询分析、文档结构化、自适应精炼)缺一不可,移除任何一个都会导致性能明显下降
- 随着模型参数的增加,性能提升会逐渐变小
- LongRefiner在处理较长文档时表现尤为出色
- 该方法在不同的基础生成器上都能表现稳定
总结
LongRefiner为长文档的RAG系统提供了一种高效的解决方案。通过理解查询类型、结构化文档以及自适应精炼机制,它成功地在保持高性能的同时大幅降低了计算成本。这一研究为未来大语言模型处理长文档问题提供了新的思路。
对于需要处理大量长文档的应用场景,如智能客服、文档检索系统、知识库问答等,LongRefiner无疑是一个值得关注的技术。