GPU八卡A100使用INT4-W4A16量化大模型实验
A100 * 8 量化Meta-llama8B模型实验
简介
本实验旨在探索在 NVIDIA A100 × 8 GPU 环境下,对 Meta-LLaMA-8B 大语言模型进行权重量化的可行性、效率与性能影响。通过采用 llmcompressor 工具集成 GPTQ 算法,实现对所有线性层的权重量化(W4A16 方案)。最终通过 lm-eval 工具在 GSM8K 任务上对压缩模型进行评估。
实验步骤(含遇到的问题,解决方案)
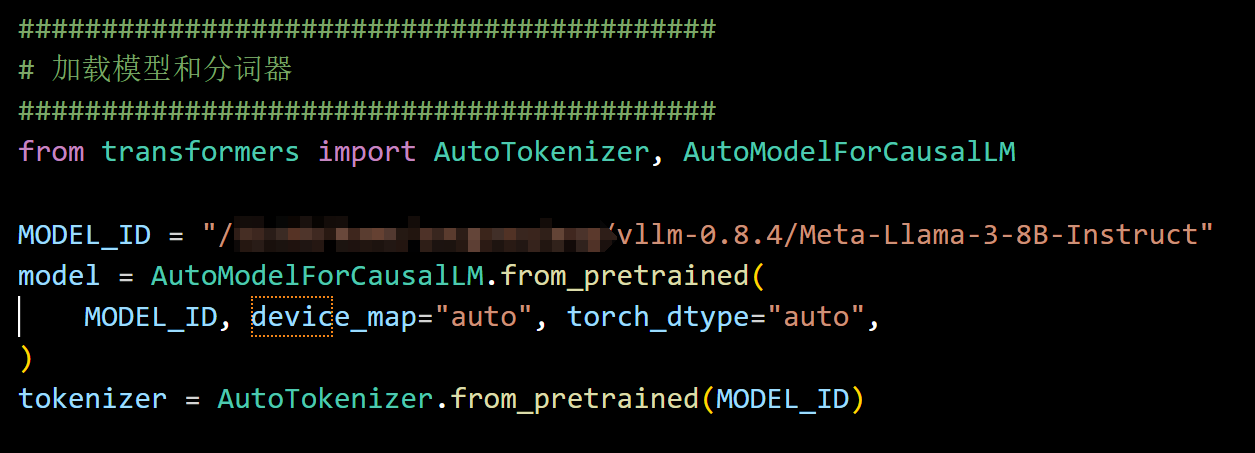
一:使用 transformers 加载模型和分词器:
- 使用 device_map=“auto” 自动分配多卡显存。
- torch_dtype=“auto” 让模型根据硬件选择 FP16 。
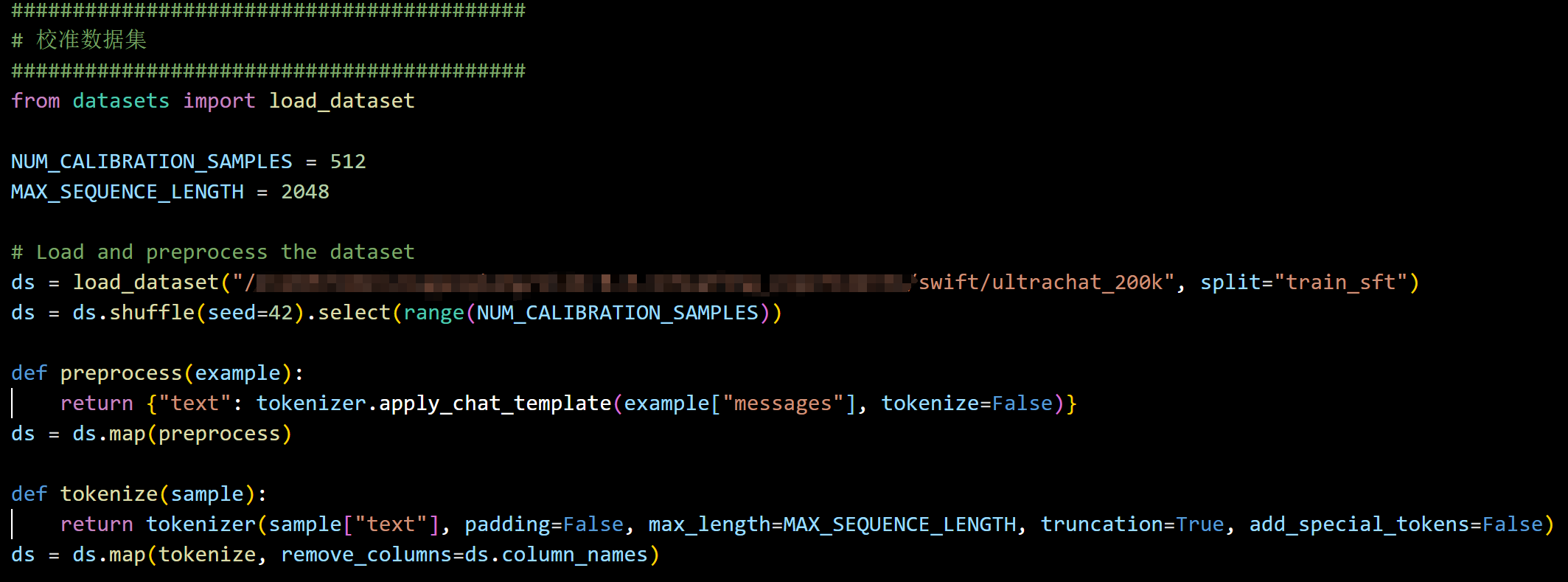
二:构建校准数据集:
- 在 Modelscope 下载 UltraChat 200k 数据集(最好使用与你的部署数据紧密匹配的校准数据)
在使用datasets加载数据集时遇到了一个问题:

这个问题出现的原因是数据集的 dataset_info.json 文件中的 features 字段格式不正确——它试图构造 Value 类型,但缺少 dtype 字段。
解决方法:
删除数据集目录下的 dataset_infos.json 文件,让 datasets 自动推断特征。
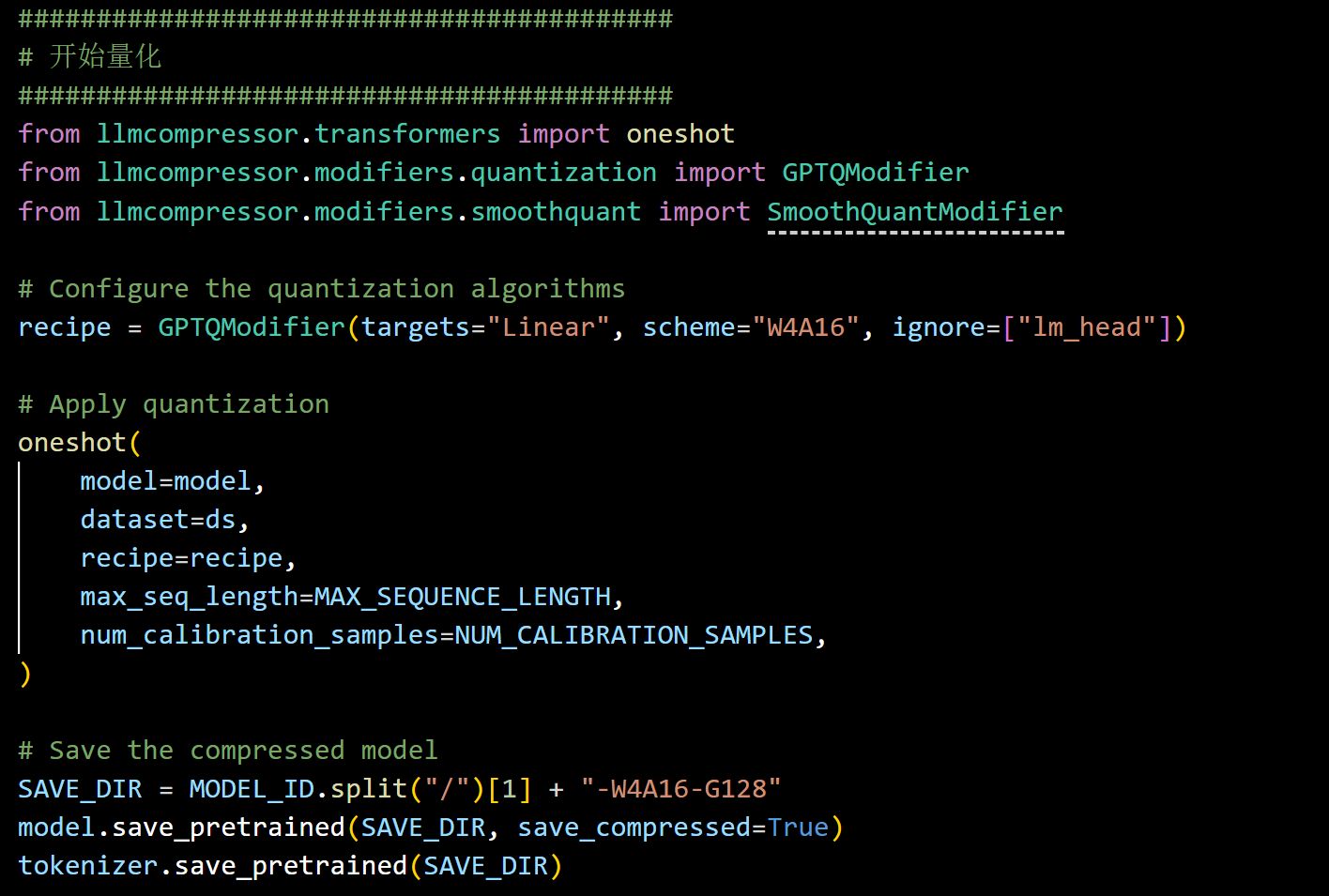
三:运行量化
- 通过 llmcompressor 中的 GPTQModifier,将模型线性层权重压缩为 INT4(W4A16 格式)
- 使用 one-shot 方法进行静态量化
- 排除 lm_head,避免因极端权重量化精度损失
实验结果
- 量化过程
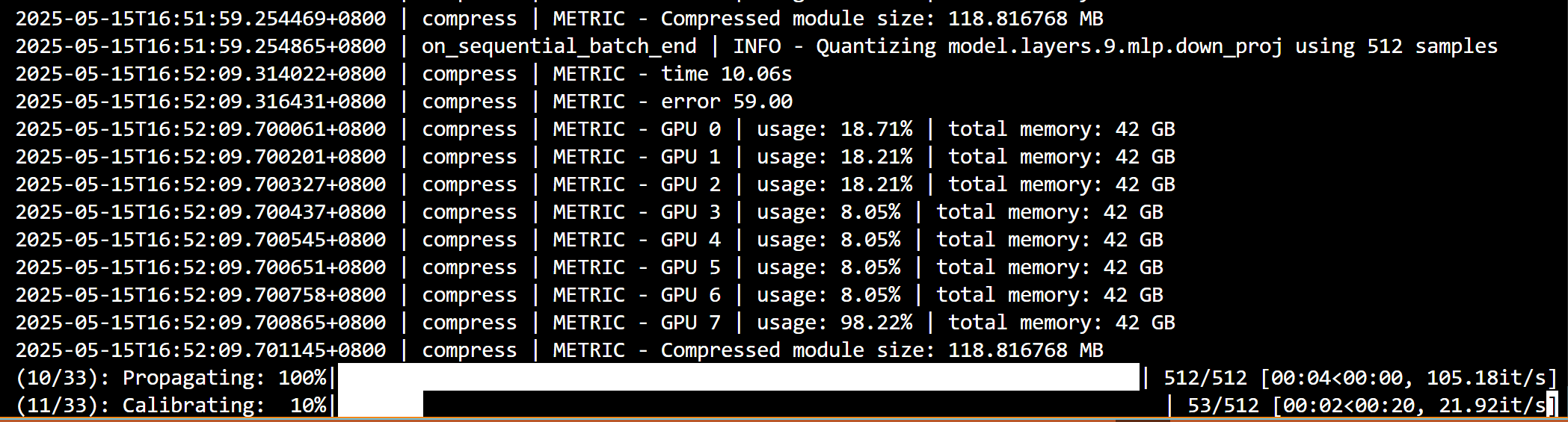
- 在量化到第31个迭代时,出现了OOM错误:

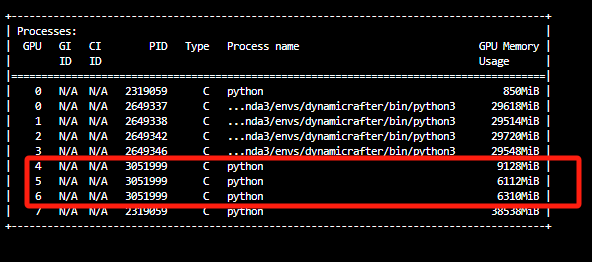
- 使用nvidia-smi观察了一下,发现好几张卡有其他进程在使用:

量化的是8B的模型,其实不需要太多卡,那么如何修改代码,来指定运行量化的代码呢?
解决方法:设置环境变量,只暴露闲置的卡:
os.environ["CUDA_VISIBLE_DEVICES"] = "4,5,6"
然后重新量化:
可以看到,这样就只在这三张卡上运行量化了。
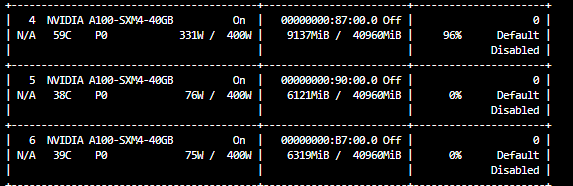
发现卡4使用率较高,而另外两张卡使用率很低,什么原因呢?
百度一下原因大致是:使用device_map=“auto” 在量化时选择了更多计算密集的层放到这张卡上(卡4)。
如何解决:可以通过手动配置 device_map 或使用 数据并行 等方式来更好地平衡负载,使得 GPU 4、5、6 的使用率更加均匀。
运行了大概二十多分钟就量化完成了,具体时间没有记录(后悔)。
我们使用du -sh简单看一下量化前和量化后的模型文件总大小:
15G Meta-Llama-3-8B-Instruct/
5.4G disk0-W4A16-G128/
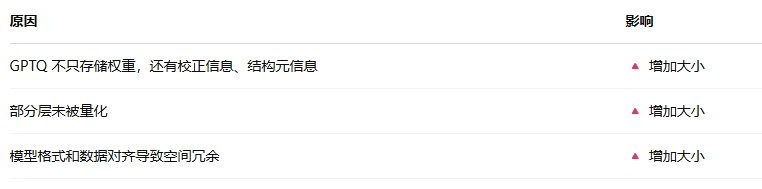
这里5.4G 是合理的 GPTQ 4bit 模型大小,虽然不是完美的四分之一,但相比原始模型已经大大减小(接近 1/3)
为什么不是四分之一,截取一下gpt的回答,有错误欢迎指正:
部署推理及模型评估
- 通过 lm-eval 工具(lm_eval 是一个用于评估语言模型性能的 Python 库,使用pip install安装即可),对量化模型在 GSM8K 数据集(gsm8k是数学推理任务,可以用你的目标任务替换)上的 zero-shot/few-shot 表现进行评估;
- 评估中使用 vllm 作为推理框架,使用 huggingface 也可以;
lm_eval --model vllm \--model_args pretrained="./Meta-Llama-3-8B-Instruct-W4A16-G128",add_bos_token=true \--tasks gsm8k \--num_fewshot 5 \--limit 250
执行评估报错,这里也是因为显存的问题:
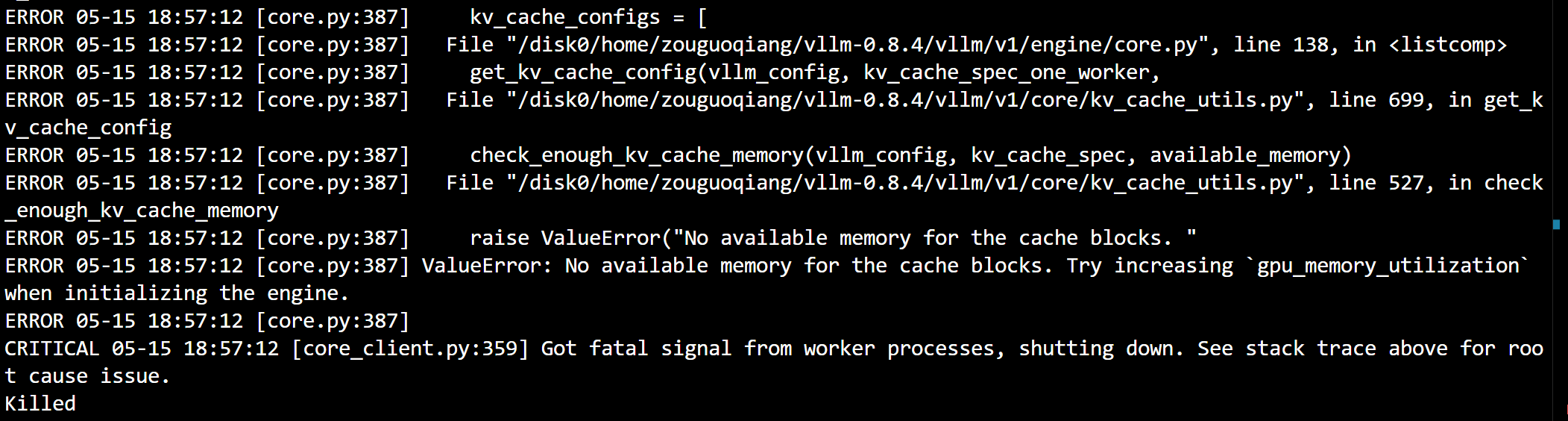
设置环境变量,用空闲的卡进行评估:
export CUDA_VISIBLE_DEVICES=4
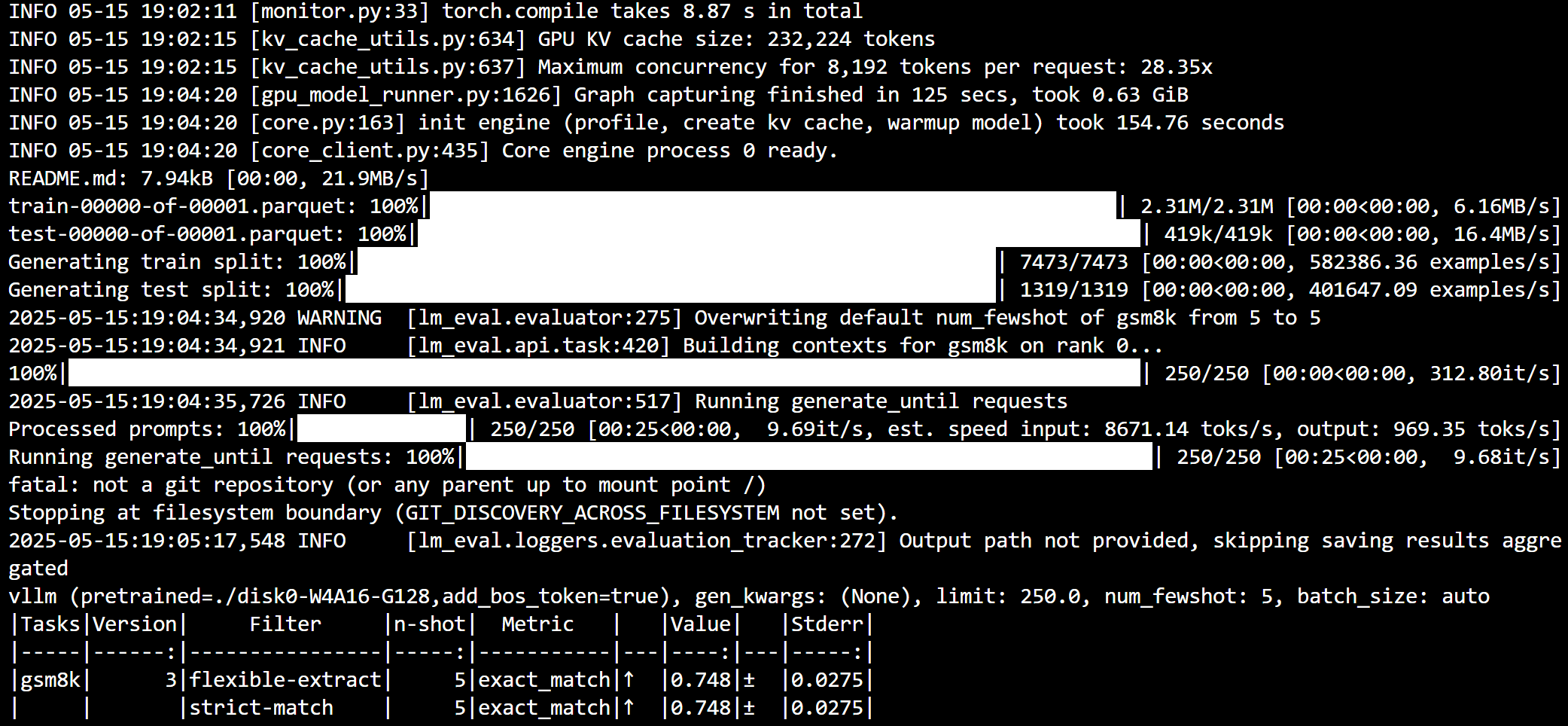
可以看到这里四号卡在进行评估了,评估结果:
然后使用相同的方法评估一下量化前我们的llama 8B模型的准确率:
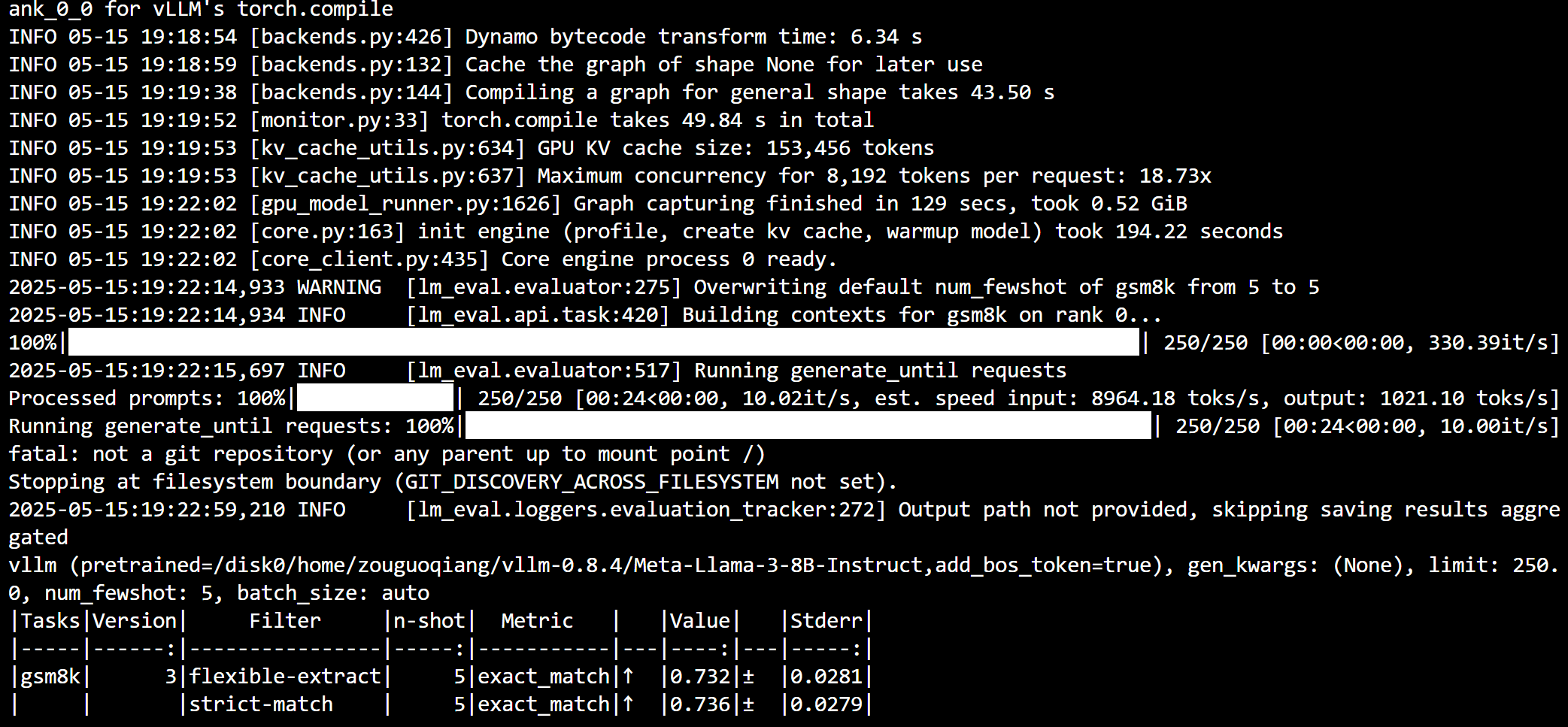
可见量化模型在 gsm8k 上 5-shot 的 exact match 达到 74.8%准确率,而量化前的模型准确率只有73.2%,这是什么原因呢(手动狗头)
这听起来违反直觉,但其实在实际应用中,这种现象并不罕见,原因可能包括:
- GPTQ 的误差感知机制实际提升了模型“对任务有用”部分的表示能力;
- 校准数据集(ultrachat_200k)与目标任务分布更贴近,反而帮助模型对某些推理任务表现得更好;
- 测试集样本较少(你用的是 --limit 250),有统计波动;
- 推理时的实现细节(如 BOS token 添加、tokenizer 或输入截断策略)可能略有差异;
- 原始模型输出过于“冗长或不精确”,而量化后的模型输出更简洁,有利于 strict match。
对于实际的原因,可能要进一步实验和验证,这里就不继续了,要下班了。