大模型Rag - 两大检索技术
一、稀疏检索:关键词匹配的经典代表
稀疏检索是一种基于关键词统计的传统检索方法。其基本思想是:通过词频和文档频率来衡量一个文档与查询的相关性。
核心原理
文档和查询都被表示为稀疏向量(如词袋模型),只有在词出现的位置才有非零值。
最常见的两种稀疏检索算法:
- TF-IDF(Term Frequency-Inverse Document Frequency)
由两个部分组成: - TF(词频):某个词在文档中出现的频率
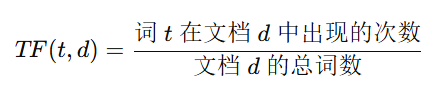
- IDF(逆文档频率):某个词在所有文档中出现的稀有程度
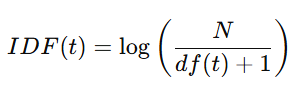
df(t) 是包含词 𝑡 的文档数量
最终得分:TF-IDF(t,d)=TF(t,d)×IDF(t)
稀疏检索的局限性:
1. 不考虑词序和上下文语义
示例:
- “男朋友送的礼物”
- “送男朋友的礼物”
在语义上完全不同,但关键词相同,稀疏检索会认为它们高度相似。
2. 对同义词不敏感
- 例如“车”和“汽车”虽然含义一致,稀疏模型不会将它们归为同一语义。
二、稠密检索:理解语义的现代方法
稠密检索依赖于深度学习模型将文本转化为向量(embedding),这些向量可以捕捉语义信息、词序和上下文。
核心原理:
使用预训练模型(如 BERT、GTE、BGE)将文档和查询转化为稠密的向量表示(维度通常为768、1024等)
使用 向量相似度(如余弦相似度、点积)进行匹配和排序
优势:
- 捕捉语义信息:能区分不同语义的句子
- 支持同义词识别、上下文推理
- 更适合处理自然语言表达丰富的用户提问
潜在问题:
- 训练成本高:需要训练或微调 embedding 模型
- 信息压缩:将高维文本语义压缩进一个定长向量,可能导致信息丢失
- 可解释性差:不像关键词检索那样能清楚看到匹配逻辑
三、两者对比
| 项目 | 稀疏检索(TF-IDF / BM25) | 稠密检索(Embedding) |
|---|---|---|
| 原理 | 基于关键词统计 | 基于语义向量相似度 |
| 表达方式 | 稀疏词袋向量 | 稠密浮点向量 |
| 优势 | 简单、高效、易解释 | 理解语义、词序、上下文 |
| 缺点 | 无法处理语义变化 | 信息压缩、训练成本高 |
| 同义词识别 | 差 | 好 |
| 查询变化适应 | 差 | 好 |