一文速览可证数学定理的DeepSeek-Prover系列模型:从Prover V1、Prover V1.5到DeepSeek-Prover V2
前言
我个人目前和各个合伙人共管4个办公室:
- 长沙大模型与具身团队侧重大模型赋能机械臂和人形的定制开发,例如具身大脑、VLA泛化等,及指导各高校对一系列世界级前沿论文、模型的复现
- 北京教育团队侧重C端教育 比如论文/项目/申博等各种1V1,和B端企业服务、高校服务
虽然我司「七月在线」聚焦具身智能开发了,但教育业务依然保留着
比如我们现在课程视频 都有对应的字幕 摘要,以及可以随时截图视频某一帧 提问VLM
很快,我们还会实现类似腾讯会议的转写功能
方便大家 「基于视频的所有字幕内容」做快速回顾,和单个字级别的精准定位——点击右侧的文字 让左边的视频跳转到对应位置
- 武汉具身团队侧重开发线缆插拔、零部件智能装配、上下料等,偏机械臂上的模仿学习及RL
- 上海(原南京团队亦即将迁至上海)具身团队侧重人形大小脑的协调开发,包含上肢操作、下肢运动规划控制,在统一协调中完成在工厂的落地
个人在长沙居多,但经常去上述几个地方,如之前在博客里提到过的,因为个人在长沙,所以我很早就想把在长沙做大模型和具身智能的给聚起来
- 于是在几个月前,我便把长沙三大985(国防科大、中南、湖大),以及中兴、七月做大模型和具身的人聚起来了,每季度都会不定期开展线下交流 平时则线上
- 当然,因为本博客影响力的与日俱增,我和我司也基本和各大人形厂商、各大TOP985高校的具身实验室皆有一定的交流、合作
昨天下午,我请中南的两个具身方向的博士生以及中兴的一大模型业务负责人在渔人码头喝茶,期间聊到了DeepSeek-Prover V2
- 一方面,即将问世的R2 相信会有Prover V2的功劳,提前做个解读和了解 有用
- 二方面,DS这一系列模型对具身模型的发展、推动,都有着不小的价值与意义
故虽然之前 没咋注意这个模型,但昨晚回来后 我快速扫了一眼论文,发觉确实值得解读,于此,本文便来了
数学定理本身的证明是严谨而优美的,我在解读时 也会一如既往的注重直观、通俗,且尽可能让本文每一段的描述都看着赏心悦目
第一部分 DeepSeek-Prover
1.1 引言与相关工作
1.1.1 引言与提出背景
在现代数学中,证明日益复杂,这给同行评审带来了重大挑战。这种复杂性导致错误的证明被接受,关键性缺陷往往要经过相当长时间才被发现
- 为了解决这些问题,已经开发了诸如 Lean
De Moura 等, 2015,即The Lean Theorem Prover
Moura 和 Ullrich, 2021],即The Lean 4 Theorem Prover and Programming Language,Lean 4 是 Lean 定理证明器的重新实现,是一种可扩展的定理证明器和高效的编程语言。其编译器可生成 C 代码,用户能在 Lean 中实现高效的证明自动化,编译为 C 代码后作为插件加载
Isabelle [Paulson, 1994]和 Coq [The Coq Development Team] 等形式化数学语言。这些语言使得计算机可验证的证明成为可能 [Avigad, 2023]
然而,撰写形式化证明需要大量的努力、专业知识,即使对于经验丰富的数学家来说也极具挑战性。因此,自动定理证明的重要性正在不断上升 [Shulman, 2024] - 为了减少书写形式化数学证明所需的工作量,已有多种方法
Polu and Sutskever, 2020,
Jiang et al., 2021,
Han et al., 2021,
Polu et al., 2022,
Lample et al., 2022,
Jiang et al.,2022a,
Yang et al., 2024
被提出,这些方法主要关注于探索提出定理潜在解的搜索算法
然而,这些方法常常难以应对复杂定理所需的庞大搜索空间,因此对于更复杂的证明往往效果不佳 [Loos et al., 2017] - 近期,大型语言模型(LLM)的进展引入了一种新颖的策略,即利用预训练模型来引导搜索过程
尽管这些新方法
Jiang 等,2022b
Zhao 等,2023
Xin 等,2023
代表了显著的进步,但由于缺乏平行语料库,它们在实际应用中仍然存在不足
与 Python 或 Java 等传统编程语言不同,形式化证明语言仅被相对较少的数学家使用,导致数据集有限。最近在自动形式化[Wu 等,2022]方面的进展使得可以合成更多对齐的数据,用于训练基于 LLM 的自动定理证明器
然而,生成的数据集仍然太小,无法充分释放 LLM 的能力
为了解决这一问题,作者提出了一种从非正式数学问题生成大量 Lean 4 证明数据的方法,即为DeepSeek-Prover
- 其对应的paper为:DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data

- DeepSeek-Prover 构建于 DeepSeekMath-Base 7B 模型之上 [Shao 等, 2024],该模型是一种仅解码器的 Transformer [Vaswani 等, 2017],在包含 1200 亿个与数学相关的token的语料库上进行了预训练
详见此文《一文通透GRPO——通俗理解群体相对策略优化GRPO及其代码实现:去掉价值估计,不用像PPO中复杂的GAE计算》的第二部分 DeepSeekMath及其提出的GRPO - 且使用全局批量大小为 512 和恒定学习率 1×10−4 对该模型进行了微调,并结合了 6,000 步的合成数据预热
方法将高中和本科级别的数学竞赛题目转化为形式化表述。随后,利用大型语言模型(LLM)自动生成证明,并在 Lean 4 环境中验证这些证明的正确性。该方法的主要挑战在于确保合成数据的规模和质量
在质量保证上,通过多步流程提升生成证明的质量
- 首先,利用质量评分模型过滤掉简单陈述,并通过假设拒绝策略排除无效陈述。作者提出的新型迭代框架通过让一个在有限数据上微调的训练不足的LLM,从非正式数学问题中初步生成合成陈述,进而提升证明质量。这些陈述用于生成相应的证明,随后通过Lean 4 验证器验证其正确性
- 正确的定理-证明对随后用于进一步训练初始模型。经过多轮迭代,基于大规模合成数据训练的模型相比最初训练不足的LLM,其能力显著提升,从而产生更高质量的定理-证明对
在规模保障上
- 证明时往往会碰到大规模搜索空间这一挑战,其中导致延迟的一个重要原因是生成了无法被证明的陈述,这些陈述会一直被处理,直到达到时间限制
- 为缓解这一问题,作者提出并行证明否定陈述。一旦原始陈述或其否定中的任意一个被证明,整个证明过程即终止
作者在 Lean 4 定理证明任务中评估了方法的有效性,使用了来自 miniF2F [Zheng 等,2021] 的 488 个问题和来自 FIMO 基准测试 [Liu 等, 2023] 的 148 个问题,采用了DeepSeekMath 7B [Shao 等, 2024] 作为基础
- 结果显示,在Lean 4 miniF2F-test 基准上以 64 个样本实现了 46.3% 的整体证明生成准确率,超过了 GPT-4 [Achiam 等, 2023] 的 23.0% 和树搜索强化学习方法的 41.0%
- 此外,在Lean 4形式化国际数学奥林匹克FIMO基准中,用 100 个样本解决了 148 个问题中的 4 个,而 GPT-4 未能解决任何问题,并且我们的方法在 4096 个样本下解决了 5 个问题
最终,作者提出了一种迭代方法,用于从非正式数学问题中合成800万条形式化陈述,每条陈述都附有形式化证明
1.1.2 相关工作
- 基于神经模型的ATP
随着深度学习的发展,已经提出了多种将神经模型与ATP结合的方法 [Loos 等, 2017]
一系列ATP方法采用了由神经模型引导的树搜索算法
Polu 和Sutskever, 2020
Han 等, 2021
Polu 等, 2022
Jiang 等, 2022a
Yang 等, 2024
这些方法主要利用强化学习技术来提升模型的准确性
Kaliszyk 等, 2018
Crouse 等,2021
Wu 等, 2021;
Lample 等, 2022
但由于搜索空间极其庞大,搜索过程会消耗大量时间和计算资源
另一系列的ATP方法利用了大型语言模型的强大能力。这些方法通常涉及经过开源证明数据微调的语言模型,并通过状态-动作转换程序与验证器交互
Polu andSutskever, 2020
Jiang et al., 2021
Han et al., 2021
Polu et al., 2022
Lample etal., 2022
Jiang et al., 2022a
Yang et al., 2024
该过程会迭代地生成证明步骤,并通过形式化验证器验证其正确性。随后根据形式化验证器返回的证明状态生成下一个证明步骤。尽管这些方法取得了较高的性能,但计算开销较大
为提升效率,近期研究利用语言模型直接生成完整的形式化证明
First et al., 2023
Jiang et al.,2022b
Zhao et al., 2023
Xin et al., 2023
从而在生成证明时绕过了迭代交互 - 自动形式化用于形式化数学
由于可用于训练的形式化语料库有限,当前大语言模型(LLMs)的性能也受到限制
因此,一些方法提出了自动形式化
Wu 等, 2022
Jiang 等, 2022b
即将自然语言描述转换为可由证明助理验证的形式化陈述
已有多项研究通过对现有定理进行基于规则的转换,生成了形式化证明的合成数据集
Wu 等, 2020
Wang 和 Deng, 2020
Xiong 等, 2023
虽然这些方法有效,但受限于对预定义规则的依赖,缺乏更广泛应用的灵活性
近期的方法采用大语言模型将自然语言问题翻译为形式化陈述 [Huang 等, 2024]。然而,这些数据集仍然规模较小,且仅限于小型数学基准,导致对语言模型训练结果的提升有限
1.2 Prover的方法论
方法包括如图1所示的四个关键流程
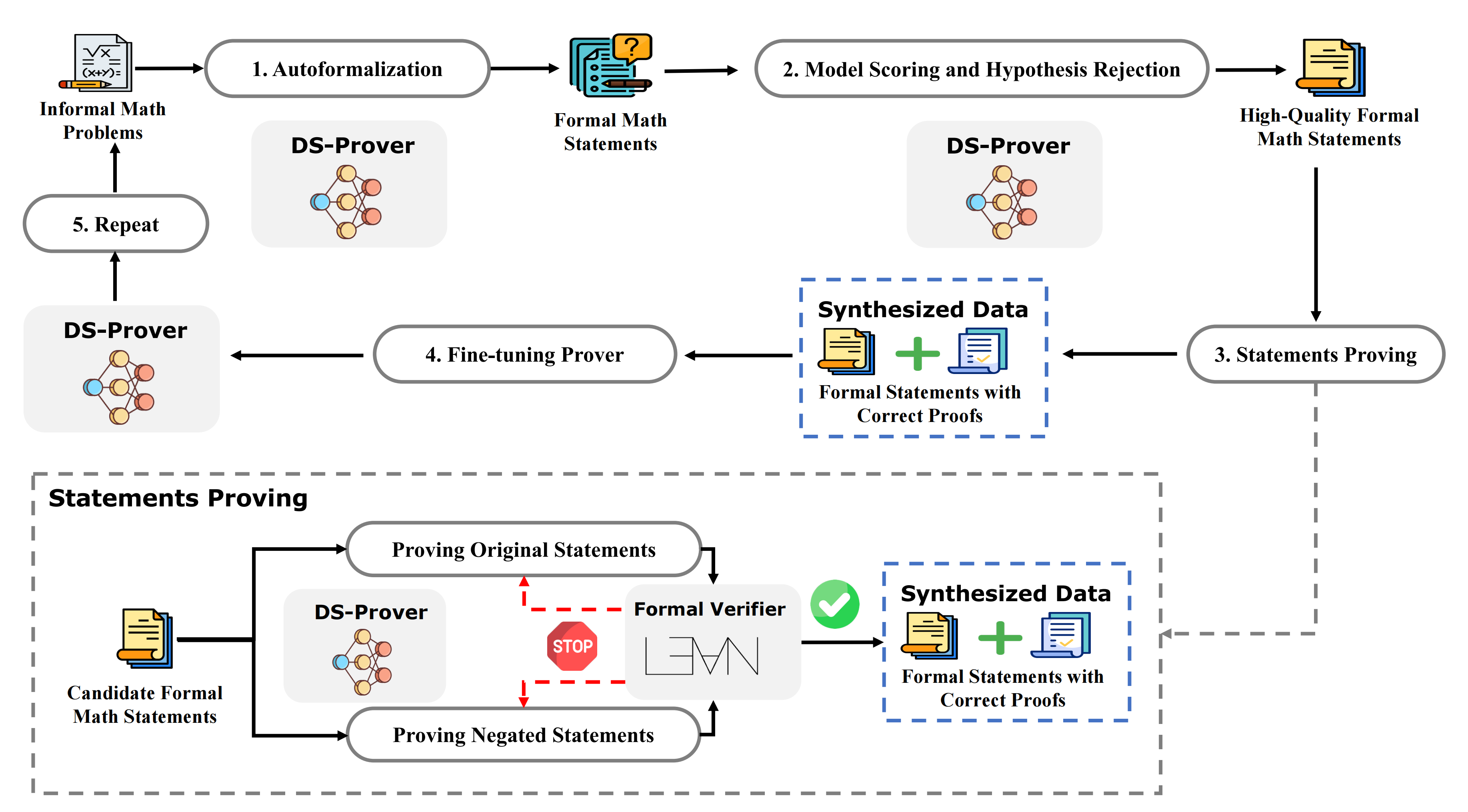
- 初始阶段侧重于从大量非正式数学问题中生成需要进一步证明的正式数学陈述
- 接下来,通过模型评分和假设拒绝方法对自动形式化的陈述进行筛选,以选出高质量的陈述
- 这些陈述随后由名为DeepSeek-Prover的模型进行证明,其正确性由名为Lean 4的形式化验证器进行验证,从而获得经过验证的正式陈述和证明
这些数据作为合成数据用于对DeepSeek-Prover进行微调 - 在增强DeepSeek-Prover后,重复上述整个流程
该循环持续进行,直到DeepSeek-Prover的提升变得微乎其微
值得注意的是,为了提升证明效率,同时对原始陈述及其否定进行证明。这种方法的优点在于,当原始陈述无效时,可以通过证明其否定迅速将其剔除
1.2.1 让自动形式化(Autoformalization)更好的第一步:微调
形式化证明数据的生成在根本上依赖于大量形式化陈述的可用性。然而,在实际操作中,收集大量手工制作的形式化陈述具有一定的挑战性,幸运的是,互联网上有着大量用自然语言表述的数学相关问题
- 作者观察到,具有明确条件和明确定义目标的问题通常比需要复杂定义和构造的高级数学主题更容易形式化
因此,本文主要考察高中和本科阶段的竞赛题,特别侧重于代数和数论,兼顾组合、几何和统计。尽管这些问题表面上看似简单,但往往涉及复杂的解题技巧,因此非常适合作为构建用于提升大语言模型(LLMs)定理证明能力的证明数据 - 为了编制数据集,采用了网页爬取和精细的数据清洗技术,从包含高中和本科练习、考试和竞赛题目的在线资源中提取题目,最终获得了一个包含869,659道高质量自然语言数学题的数据集
具体而言,作者使用 DeepSeekMath-Base 7B 模型 [Shao 等, 2024] 初始化了 DeepSeek-Prover。最初,该模型在将非正式数学问题转换为形式化表述时表现不佳
为了解决这一问题,利用 MMA 数据集 [Jiang 等, 2023] 对 DeepSeek-Prover 模型进行了微调
- 标准Lean 4
自然语言
该数据集包含了 Lean 4 的 mathlib 中的形式化表述,这些表述通过 GPT-4 被反向翻译成自然语言问题描述
- 自然语言
随后,指导模型采用结构化方法,将这些自然语言问题翻译为 Lean 4 的形式化表述
相当于GPT4先翻译标准Lean 4为自然语言,随后让Prover模型基于自然语言预测对应的Lean 4
1.2.2 让自动形式化更好的第二步:质量筛选
自动形式化陈述的质量被发现存在两个主要问题,因此表现不佳
- 首先,许多形式化陈述过于简单。为了解决这一问题,作者制定了评分标准,并从 miniF2F-valid 中提供了示例,作为少量样例来指导DeepSeek-Prover
模型在使用链式思维方法评估这些陈述的内容和质量时表现出色。对这些评分的人工复核证实,模型的评估结果与人类的直觉和预期高度一致
具体而言,模型被指示(详见附录A.1中的详细提示)将每条正式陈述的质量分为:“优秀”、“良好”、“中上”、“一般”或“较差”。被评为“一般”或“较差”的陈述随后被剔除 - 第二个问题涉及到形式陈述,虽然这些陈述是可证明的,但它们基于不一致的假设,导致空洞的结论,从而使这些结论在数学上毫无意义
例如,请考虑以下由模型生成的陈述:
在这里,关于所有复数的假设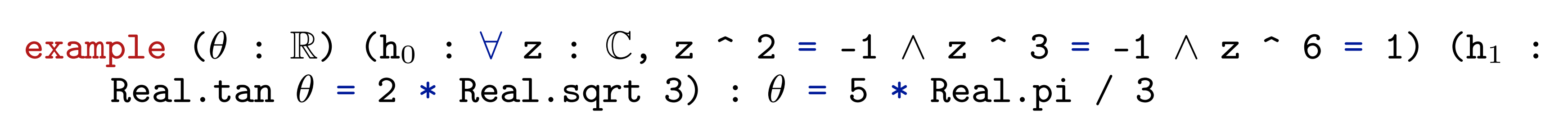
显然是错误的,因此由此得出的任何结论都是没有意义的
为排除此类情况,作者实施了一种假设拒绝方法
具体做法是使用DeepSeek-Prover 模型尝试以”False” 为结论来证明该形式化陈述。如果证明成功,则表明假设无效,从而将该陈述排除在外
下面展示了一个例子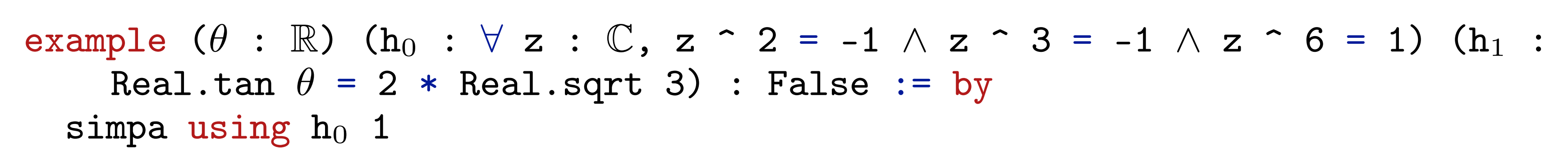
通过采用模型评分与假设拒绝的双重策略,筛选出一组精炼的712,073条高质量形式化陈述
1.2.3 陈述证明时,双向验证:既证正向 也证方向,避免有的正向命题本身就是错的
在创建了大量高质量的形式化陈述语料库后,作者利用该模型对这些陈述进行证明搜索
- 传统上,语言模型在证明定理时主要采用蛮力方式——不断尝试,直到找到有效证明或计算资源耗尽。这种方法对于我们的目标来说效率低下
- 通常,语言模型应用于由人工精心挑选的形式化陈述,这些陈述通常是经过仔细设计的,且大多为真实且可证明的
然而,在自动形式化陈述的证明任务中,模型生成的许多陈述可能是错误的 - 实际上,期望模型在任何可靠的证明系统中验证一个错误命题是不合理的
在大规模自动形式化过程中,这一问题更加突出,作者观察到,即使经过质量筛选,模型生成的形式化陈述中仍有至少20%是错误的,如果采用蛮力方法处理,将导致大量计算资源的浪费
为了最大限度地减少在不可证伪命题上的资源浪费并提高证明搜索过程的效率,作者利用了命题与其否定之间的逻辑对称性来加速证明合成
- 即为每个合成命题实现了双重并发证明搜索:
一个针对命题
另一个针对其否定
一旦其中任意一方找到有效证明,搜索即刻终止,从而有力地证明了另一方不可证。每个证明搜索流程最多尝试个证明,除非更早出现有效证明
所有经验证的证明,无论是证明原始定理还是其否定,都会被汇总用于进一步训练 DeepSeek-Prover
因此,这种双重方法实际上是一种数据增强形式,即使模型未能正确形式化原命题,也能通过引入命题及其否定来丰富数据集
1.2.4 迭代增强
由于整个流程高度依赖 DeepSeek-Prover,每轮迭代后提升模型性能至关重要
- 为此,持续使用新生成的数据对模型进行微调。更新后的模型随后被用于后续的自动形式化迭代
该迭代过程的关键见解在于,模型在每次精炼和应用循环后会逐步增强其能力和效果 - 此迭代过程会持续进行,直到不再观察到进一步的提升。因此,模型生成的定理-证明对在每次迭代后都会变得越来越高质量
该方法确保 DeepSeek-Prover持续提升其性能,最终通过不断优化生成更优质的定理-证明对
// 待更