C++初阶-string类2
目录
1.迭代器
1.1普通迭代器的使用
1.2string::begin
1.3string::end
1.4const迭代器的使用
1.5泛型迭代器和const反向迭代器
1.6string::rbegin
1.6string::rend
1.7string::cbegin、string::cend、string::crbegin、string::crend
与begin/end、rbegin/rend的区别
2.Capacity
2.1string::size
2.2string::length
2.3string::max_size
2.3.1max_size()的返回值含义
2.3.2典型返回值
2.3.3重要特性
2.3.4使用示例
2.3.5实际应用场景
2.3.6注意事项
2.4string::clear
2.5string::empty
2.7string::shrink_to_fit
2.8string::capacity
2.9string::reserve
2.10string::resize
示例代码
重要注意事项
3. 总结

1.迭代器
迭代器在string中用的不多,所以在这里我只是简单讲解一下。这是迭代器的全部成员函数,但是在这之前我们需要先了解一部分迭代器的基本用法,迭代器之后会详细讲解。

1.1普通迭代器的使用
迭代器是定义在类域里面的,所以我们需要指定类域(string类里面的)。在类域里面定义有两种情况需要指定类域:内部类和在类域里面typedef(之后会讲)。相当于这个iterator这个类封装在这个类里面了,iterator是类型,叫做迭代器。
#include<iostream>
using namespace std;
#include<string>
int main()
{string s2("hello world");//返回第一个位置的迭代器string::iterator it = s2.begin();//it的打印cout << *it << endl;return 0;
}我们这个阶段可以把迭代器视为一个指针,但是又与指针有区别的东西(解引用的时候可以访问到它)。
1.2string::begin
这个函数有俩个重载:
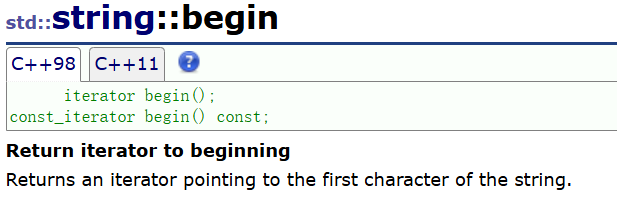
返回的是第一个位置的迭代器,所以上面程序的结果为:

1.3string::end
在这个成员函数定义中也是有两个重载函数,我们暂时只要知道普通对象的使用就可以了:
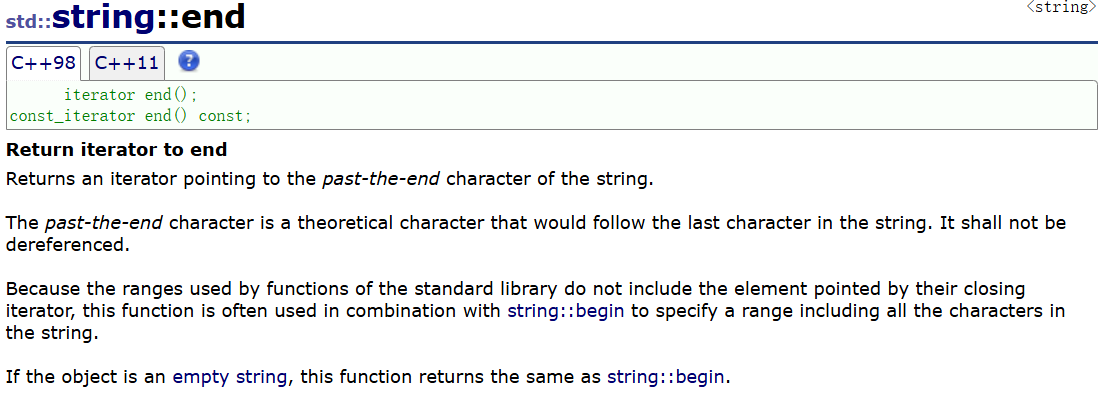
这个end函数的功能我们发现还是比较长的,我们用翻译软件来翻译一下:
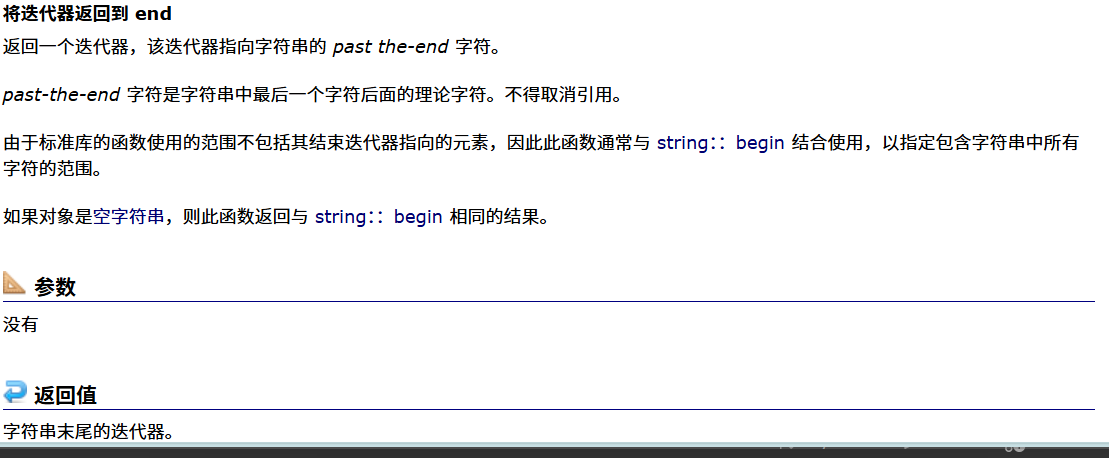

返回值这个东西是我们需要注意的,因为返回的并不是最后一个字符的迭代器,而是最后一个字符的后面一个位置,所以我们不能让它在遍历时到达it.end()位置!
我们可以把begin-end这一部分视为数学里面的左闭右开的方式,也就是说,如果最后一个字符的下标是4,那么end就指向的是下标为5的位置。其使用方式如下:
#include<iostream>
using namespace std;
#include<string>
int main()
{string s2("hello world");//返回第一个位置的迭代器string::iterator it = s2.begin();while (it != s2.end()){cout << *it << " ";++it;}cout << endl;return 0;
}运行结果如下:

我们可以发现:这种方式也可以遍历string对象,虽然我们之前用下标+[]的形式更方便,但是它只适用于用数组实现的数据结构,而迭代器却能适用于各种数据结构!
如:用迭代器向链表中插入5个数据
#include<iostream>
using namespace std;
#include<string>
#include<list>
//用迭代器向链表中插入5个数据
int main()
{list<int> lt1 = { 1,2,3,4,5 };list<int>::iterator it1 = lt1.begin();while (it1 != lt1.end()){cout << *it1 << " ";++it1;}cout << endl;return 0;
}则运行结果如下:
可见,迭代器在数据结构和其他的东西用法还是比较广泛的!
其次我们不能在迭代器中的结束条件改为:it1<s2.end();因为它是链表,不是线性的,不是连续存放在堆(动态开辟)上面的,所以不能这样写!
1.4const迭代器的使用
#include<iostream>
using namespace std;
#include<string>
int main()
{string s5("hello CSDN");string::const_iterator it3 = s5.begin();//const迭代器const string s4("hello world");//会报错string::iterator it1 = s4.begin();//正确的使用方式string::const_iterator it2 = s4.begin();return 0;
}这个const迭代器可以用普通的string对象来定义,也可以用const的string对象来定义,因为前者是权限缩小,是可以的;而后者是权限放大时不行的,所以会:
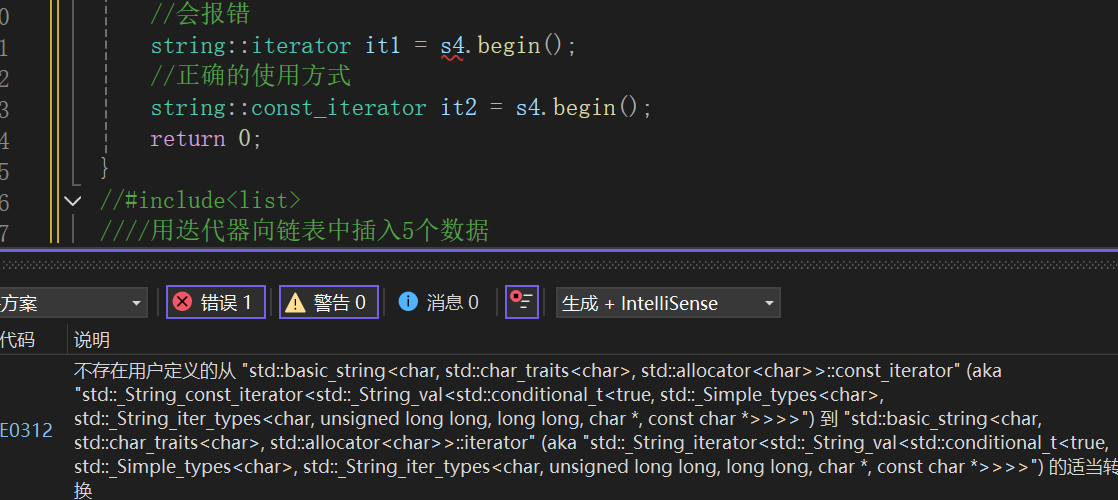
且不是在string::iterator it1前加const,因为这代表it1不可修改,而不是代表it1指向的对象不可修改。
当然,我们可以用之前学过的知识:auto关键字,直接用auto it5=s4.begin();也可以,只是你一定要知道这个it5的类型是不能修改的迭代器!
1.5泛型迭代器和const反向迭代器
当然,迭代器还有反向迭代器和const反向迭代器。如果想倒着遍历就可以用它。其他的和普通迭代器与const迭代器差别不大:
#include<iostream>
using namespace std;
#include<string>
int main()
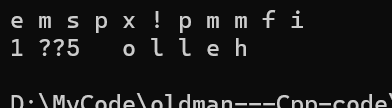
{string s2("hello world");const string s3("hello 5·1");//可读可写string::reverse_iterator rit = s2.rbegin();while (rit != s2.rend()){(*rit)++;cout << *rit << " ";++rit;}cout << endl;//只可读string::const_reverse_iterator rit1 = s3.rbegin();while (rit1 != s3.rend()){//报错//(*rit1)++;cout << *rit1 << " ";++rit1;}cout << endl;return 0;
}运行结果如下:
1.6string::rbegin
这个成员函数只能适用于反向迭代器,所以其重载成员函数:

翻译成中文为:
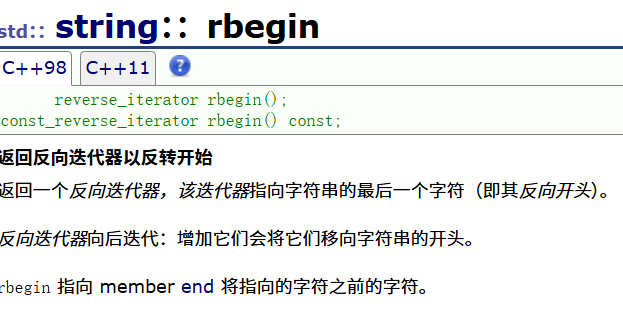
所以这个成员函数若用rbegin则返回的是最后一个字符,而且++是往前遍历,并不是往后遍历,所以会出现之前的情况。
1.6string::rend
这个和end功能刚好相反,且是以反向迭代器作为返回值。

其翻译如下:

rend指向的是第一个元素前面一个位置,其注意点差不多。
反向迭代器一定不是指针,因为指针++不可能做到往后走,故必须有运算符重载的函数,且是有一个类封装的指针。
1.7string::cbegin、string::cend、string::crbegin、string::crend
这些在string中用得真得不是很多,所以我在这里只截图这些函数的声明和这些成员函数的用法(翻译)。
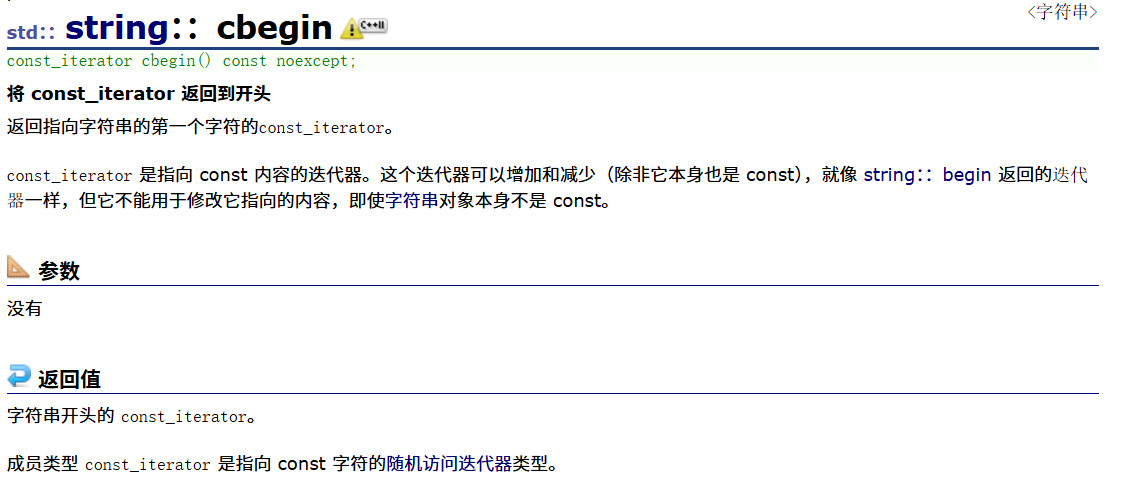
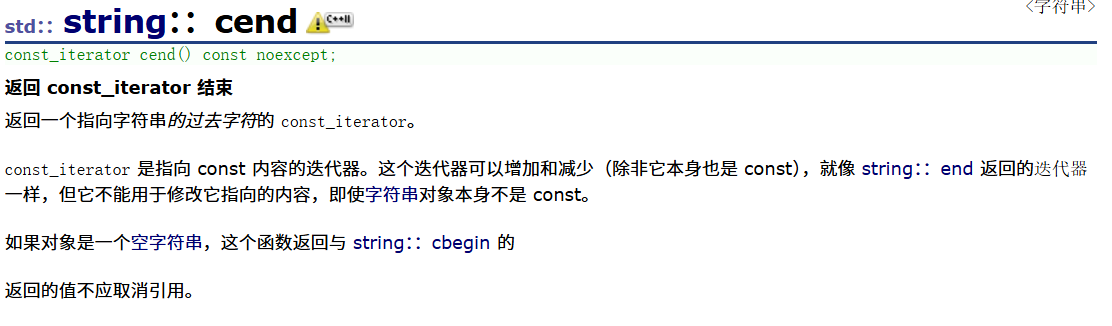
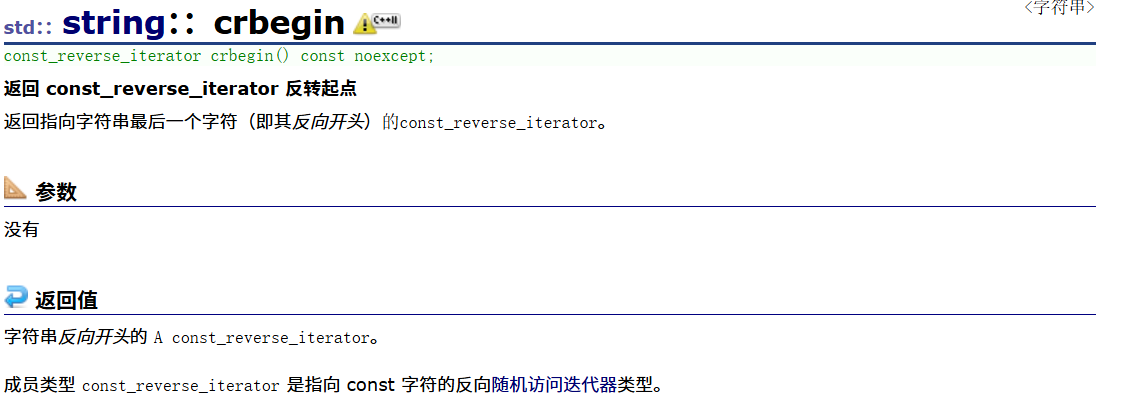

以下是deepseek的搜索结果:
C++ string类的cbegin、cend、crbegin、crend用法
这些是C++ string类提供的迭代器相关成员函数,用于以不同方式遍历字符串。它们都是C++11引入的const迭代器版本,确保不会通过迭代器修改字符串内容。
1. cbegin() 和 cend()
- cbegin(): 返回指向字符串第一个字符的const迭代器
- cend(): 返回指向字符串末尾(最后一个字符后面)的const迭代器
#include <iostream>
#include <string>int main()
{std::string str = "World";// 反向遍历for (auto it = str.crbegin(); it != str.crend(); ++it) {std::cout << *it << " "; // 可以读取但不能修改// *it = 'a'; // 错误!不能修改}// 输出: d l r o W
}2. crbegin() 和 crend()
- crbegin(): 返回指向字符串最后一个字符的const反向迭代器
- crend(): 返回指向字符串开头(第一个字符前面)的const反向迭代器
#include <iostream>
#include <string>int main() {std::string str = "World";// 反向遍历for (auto it = str.crbegin(); it != str.crend(); ++it) {std::cout << *it << " "; // 可以读取但不能修改// *it = 'a'; // 错误!不能修改}// 输出: d l r o W
}与begin/end、rbegin/rend的区别
-
cbegin/cend是begin/end的const版本 -
crbegin/crend是rbegin/rend的const版本 -
非const版本允许修改字符串内容,而const版本不允许
-
std::string str = "Example";auto it1 = str.begin(); // 可读写迭代器 *it1 = 'e'; // 允许修改auto it2 = str.cbegin(); // 只读迭代器 // *it2 = 'E'; // 编译错误
使用场景
1. 当需要遍历字符串但不修改内容时
2. 在const成员函数中访问字符串内容
3. 需要明确表达不修改字符串意图的代码中
这些const迭代器提供了更好的代码安全性和表达性,特别是在团队开发或大型项目中。
这些用得不多,所以我们只要了解一下即可。
2.Capacity
这个单词的意思是:容量。而在这个分类中包含了以下函数:

2.1string::size
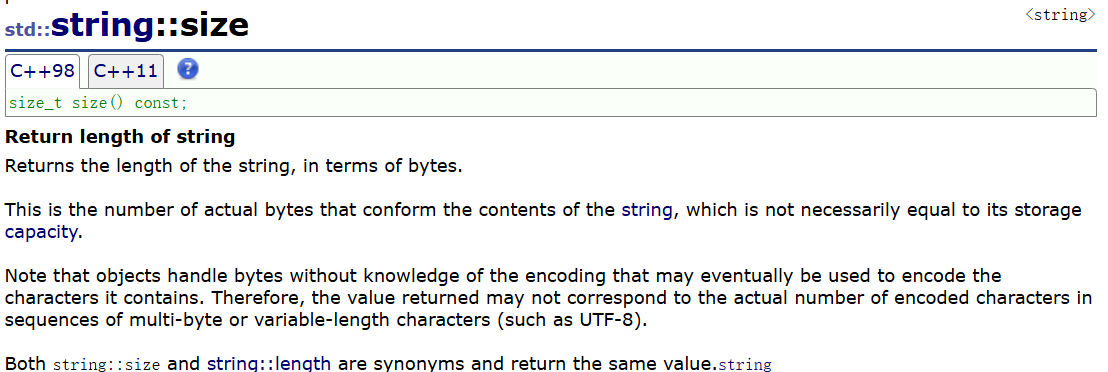
这个函数的作用是:
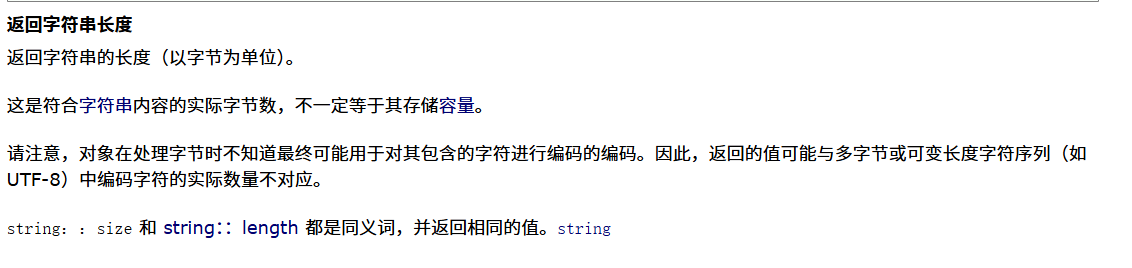
如果我们存储的是char类型的变量,可以视为能返回所存储的数据个数,但实际上不包含\0,而我们一般又把\0要加进去,所以我们一般返回的是不包含\0的数据个数。所以之后可能需要加1来保证所存储的数据个数准确。
2.2string::length
我们可以看到虽然length和size返回的是一样的,除了函数名不相同,其余的都是相同的,难道是我们可以用size和length都来计算这个string对象的长度?
本质上,size和length都是返回的字符个数(字符串)。我们要了解其区别,就要看Deepseek给的答案了(适当用AI是没有问题的):
C++ string类中size()和length()的区别
在C++的`std::string`类中,`size()`和`length()`这两个成员函数**功能完全相同**,它们都返回字符串中字符的个数(不包括结尾的空字符'\0')。
相同点
1. 两者都返回字符串的字符数量
2. 两者时间复杂度都是O(1)(常数时间)
3. 两者都不计算结尾的空字符'\0'
4. 两者都可以用于空字符串(返回0)
std::string str = "Hello";
std::cout << str.size(); // 输出5
std::cout << str.length(); // 输出5为什么有两个功能相同的函数?
1. 历史原因:
- `length()`来自于早期的字符串概念,更符合自然语言描述
- `size()`是为了与STL容器(如vector、list等)保持一致性,因为所有STL容器都有size()方法
2. 设计理念:
- `length()`强调"字符串长度"的概念
- `size()`强调"容器大小"的概念
使用建议
1. 在字符串上下文中,使用`length()`可能更直观
2. 在泛型编程或模板代码中,使用`size()`可以保持与其他容器的一致性
3. 两者性能完全相同,选择哪个纯粹是风格问题
// 字符串专用代码
if (str.length() > 10) { /*...*/ }// 泛型代码
template <typename T>
void printSize(const T& container)
{std::cout << container.size(); // 对string和vector等都适用
}总结
`size()`和`length()`在功能上没有区别,选择使用哪个主要取决于:
- 代码上下文(是否强调字符串特性)
- 个人或团队的编码风格
- 需要与其他STL容器保持一致的场景
其实一般我们要使用的是size()因为有些数据结构上是没有length函数的,所以我们使用size也是方便我们之后使用的,因为如果链式结构我们用length的话就确实不怎么好,因为length的意思是长度,链式结构存储地址是不一样的,所以我们用这个确实也不准确。所以我的建议是用size()而不是length()。
2.3string::max_size
这就相当于数据结构中特别的capacity概念,就是动态开辟的空间个数,限定了我们的最大能存储的数据个数,但是同样,它返回值是少了'\0'后的容量,可以视为返回的是容量-1,假设size==capacity,即开辟的所有空间都存储数据的情况下,则返回的是最大的下标。
#include<iostream>
using namespace std;
#include<string>
int main()
{string s2("I love you China");//size()的使用cout << s2.size() << endl;//length()的使用cout << s2.length() << endl;//max_size()的使用cout << s2.max_size() << endl;return 0;
}运行结果为:
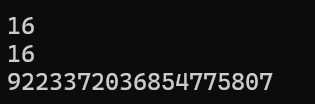
max_size()是C++ std::string类的一个成员函数,它返回该string对象在当前系统环境下理论上能够容纳的最大字符数量。
2.3.1max_size()的返回值含义
-
理论最大值:返回string在当前系统实现下能够表示的最大可能大小
-
实现定义:具体值取决于C++标准库的实现和系统环境
-
不是可用内存:不代表实际可用内存,只是理论限制
2.3.2典型返回值
-
在64位系统上,通常返回一个非常大的数,如:
-
GNU libstdc++: 通常是
2^64 / sizeof(char) - 1(约1.8×10¹⁹) -
Microsoft Visual C++: 通常是
2^64 - 1(约1.8×10¹⁹)
-
2.3.3重要特性
-
不是分配保证:即使max_size()返回很大的值,实际能分配的字符串受限于可用内存
-
与capacity()区别:
-
capacity():当前已分配的内存能容纳的字符数 -
max_size():理论上的最大可能值
-
-
平台依赖性:不同平台、不同编译器实现可能返回不同值
2.3.4使用示例
#include <iostream>
#include <string>int main() {std::string str;std::cout << "Max size: " << str.max_size() << std::endl;// 通常输出类似(64位系统):// Max size: 9223372036854775807 或 18446744073709551615
}2.3.5实际应用场景
-
边界检查:在需要处理极大字符串时进行理论限制检查
-
异常处理:在分配大内存前检查是否超过理论限制
-
调试信息:了解当前平台的字符串理论限制
2.3.6注意事项
-
尝试分配接近max_size()大小的字符串通常会抛出
std::bad_alloc异常 -
实际可用大小远小于max_size(),受限于物理内存和系统限制
-
这个值主要用于理论上的完整性检查,而非实际内存分配指导
在大多数实际应用中,你不需要关心max_size(),除非你在处理极端情况下的字符串大小问题。
以上是max_size()比较详细的介绍,我们只要了解一下就可以了。
2.4string::clear

这个函数只是清除字符串中的所有数据,而不释放空间。并且还会让size=0(成员变量),capacity一般不清理。
2.5string::empty
2.7string::shrink_to_fit
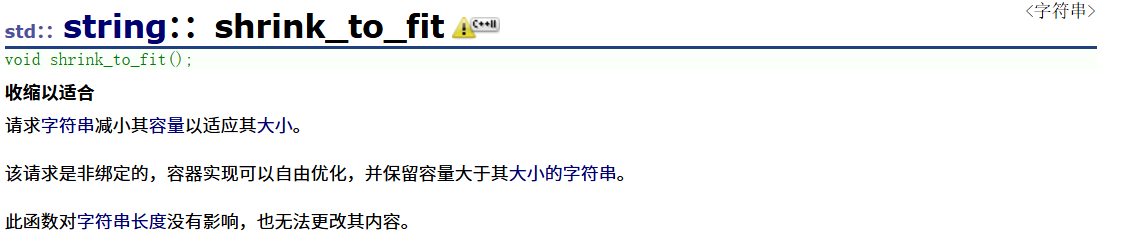
缩容,对capacity进行缩小,缩小容量至size。我们一般用这个函数来实现以空间换时间的情况,因为我们多释放一部分空间,使capacity也缩小,不用遍历那么多次了。
但是这个缩容不是在原地址上进行释放空间,它会先在其他地方申请size个空间,再把内容拷贝过去,最后再释放原空间,这是异地缩容,它的效率比较低,异地扩容代价很大,所以尽量别使用这个函数,除非你想用空间来换时间,因为空间是很大的。
2.8string::capacity
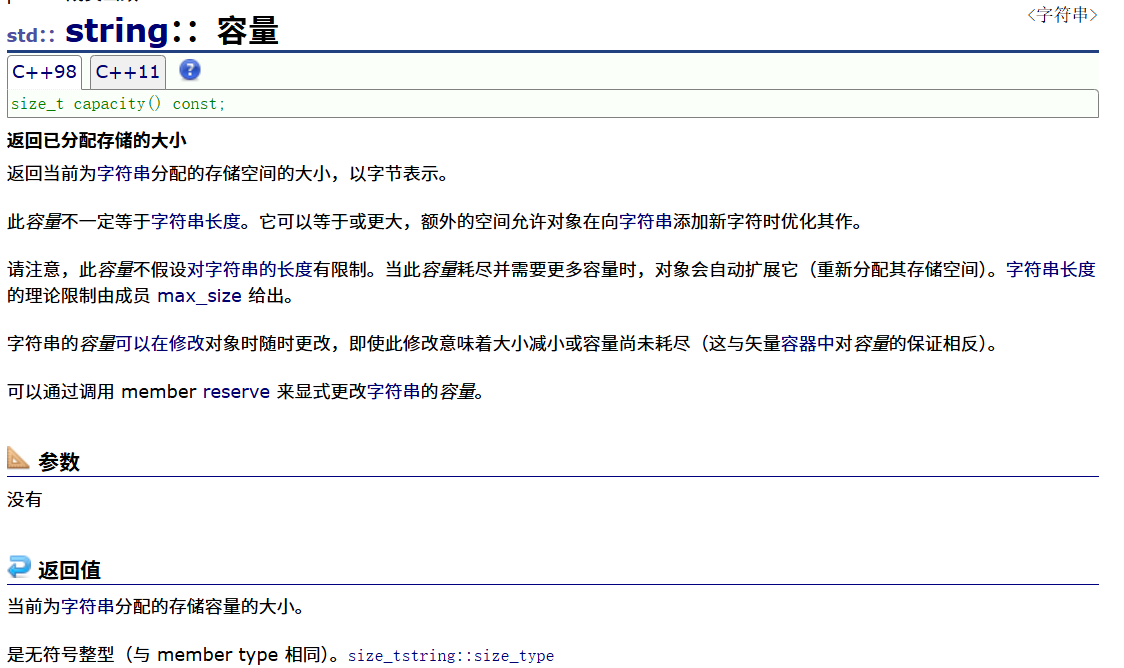
这个函数是返回不包括\0后的空间大小,所以会返回的比实际大小小1,一般用来计算能存储数据个数大小。
2.9string::reserve
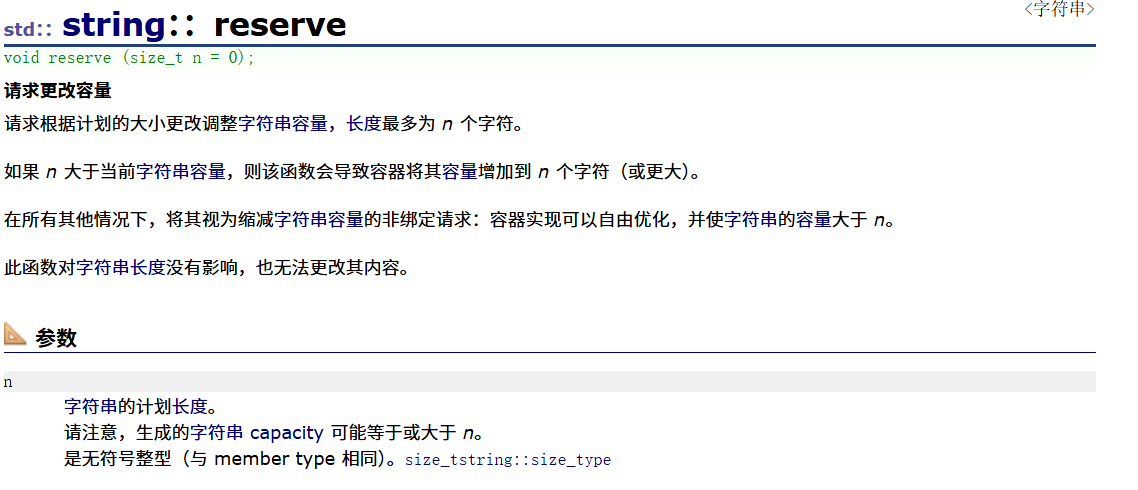
reserve翻译过来有保留的意思,注意:reverse是反转、逆置的意思。这两个单词不要区分不清楚了!reserve就是把它的capacity改变到n个字符去,而且是按计划来的。
#include<iostream>
using namespace std;
#include<string>
int main()
{string s("Hello world");string a("Hello world");string b("Hello world");string c("Hello world");cout << s.capacity() << endl;a.reserve(10);cout << "改变为10后的结果为 " << a.capacity() << endl;b.reserve(15);cout << "改变为15后的结果为 " << b.capacity() << endl;c.reserve(20);cout << "改变为20后的结果为 " << c.capacity() << endl;return 0;
}运行结果为:

我们发现如果在给的数值小于size个的时候,就不会缩容,而必定会扩容,我们若这样写:
#include<iostream>
using namespace std;
#include<string>
int main()
{string s("Hello world");string a("Hello world");cout << s.capacity() << endl;cout << s.size() << endl;a.reserve(12);cout << "改变为12后的结果为 " << a.capacity() << endl;return 0;
}则运行结果为:

所以这和我们的shrink_to_fit函数是有区别的,一般我们都用这个函数来扩容。
reserve的作用:减少扩容,如我们知道开始就知道要插入1000个字符,那么我们直接:s.reserve(1000),这样我们就不用频繁扩容了,这样减少扩容,提高了效率,若不够会继续扩容的。
2.10string::resize

这个函数用得不是很多,所以现在我不会讲很多,主要是用deepseek的结果来讲解:
-
当n < 当前size:
-
截断字符串,保留前n个字符
-
capacity保持不变
-
不释放内存
-
-
当n > 当前size:
-
扩展字符串长度
-
可能需要重新分配内存(如果n > capacity)
-
单参数版本用空字符('\0')填充新增部分
-
双参数版本用指定字符c填充新增部分
-
-
当n == 当前size:
-
不做任何改变
-
示例代码
#include <iostream>
#include <string>int main() {std::string str = "Hello";// 截断字符串str.resize(3);std::cout << str << std::endl; // 输出: Hel// 扩展字符串(默认填充'\0')str.resize(6);std::cout << "After resize(6): [" << str << "]" << std::endl;// 扩展字符串并用特定字符填充str.resize(10, 'X');std::cout << "After resize(10, 'X'): " << str << std::endl;// 输出: HelXXX XXXX (注意之前有隐含的'\0')
}重要注意事项
-
内存分配:
-
如果新size超过当前capacity,会触发内存重新分配
-
内存分配可能导致迭代器、指针和引用失效
-
-
性能考虑:
-
频繁resize可能导致多次内存分配
-
可以先reserve()预留足够空间再resize()
-
实际应用场景
-
预先分配并填充缓冲区:
std::string buffer; buffer.resize(1024, '\0'); // 分配1KB空间并清零 -
动态调整字符串大小:
std::string data = getData(); data.resize(data.find_first_of('\0')); // 截断到第一个null字符 -
格式化输出准备:
std::string line(50, '-'); line.resize(30); // 缩短线长度
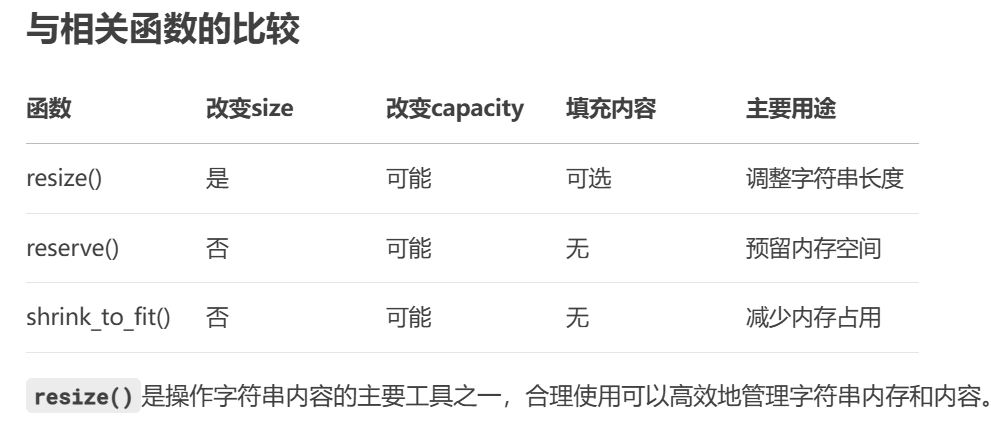
这个函数需要我们了解的真的不多,所以我就不怎么讲解了。
3. 总结
这节课主要是讲了迭代器和capacity的知识,下节将讲解:

以及一些扩容的额外的知识,所以一定要不能缺这些内容啊,因为下节的博客需要讲解的是string的增删查改的一部分内容,喜欢的可以一键三连哦!提前祝各位五一劳动节快乐啊!
