Langchain文本摘要
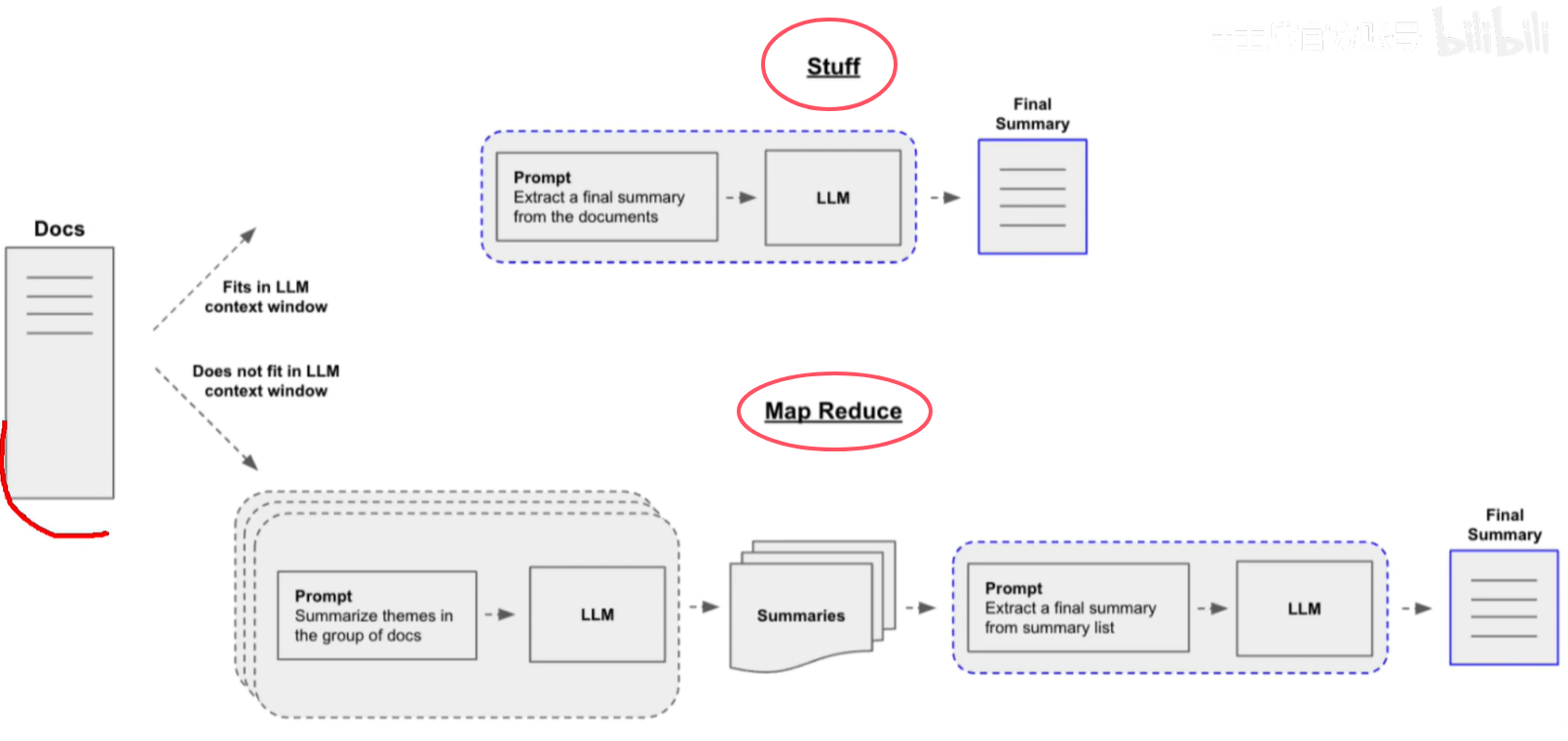
对一组文档,总结内容。当文档Token较少,通过Stuff即可总结。Document较大时,超过LLM的Token上限,则需要用MapReduce进行分布式总结。
## 这里用的chroma向量数据库
pip install tiktoken chromadb
总结/组合文档3种方式
- 填充(Stuff),它简单地将文档链接成一个提示;
- 映射-归约(Map-reduce),将文档分成批次,总结1这些批次,然后总结all总结1
- 细化(Refine),通过是顺序迭代文档来更新滚动摘要
初始化
import osfrom langchain.chains.combine_documents.stuff import StuffDocumentsChain from langchain.chains.llm import LLMChain from langchain.chains.summarize import load_summarize_chain from langchain_community.document_loaders import WebBaseLoader from langchain_core.prompts import PromptTemplate from langchain_core.runnables import RunnablePassthrough from langchain_openai import ChatOpenAIos.environ['http_proxy'] = '127.0.0.1:7890' os.environ['https_proxy'] = '127.0.0.1:7890'os.environ["LANGCHAIN_TRACING_V2"] = "true" os.environ["LANGCHAIN_PROJECT"] = "LangchainDemo" os.environ["LANGCHAIN_API_KEY"] = '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' # os.environ["TAVILY_API_KEY"] = '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'# 创建模型 model = ChatOpenAI(model='gpt-3.5-turbo', temperature=0)
加载文档
WebBaseLoader( url ):用以加载网络文章
docs是全文Document
# 加载我们的文档。我们将使用 WebBaseLoader 来加载博客文章: loader = WebBaseLoader('https://lilianweng.github.io/posts/2023-06-23-agent/') docs = loader.load() # 得到整篇文章
Stuff
写法1:chain = load_summarize_chain(model, chain_type='stuff') #chain_type默认stuff
写法2:Prompt+Chain。当你有额外输出需求,即需要使用写法2,
1.
LLMChain
- 作用:将
PromptTemplate与大语言模型 (llm) 绑定,形成可重复使用的输入-输出处理单元。- 关键特性:
- 输入变量自动匹配:从
prompt中提取变量名(如text),要求输入数据包含对应字段。- 输出结构化:返回包含
text(输入)和output_text(模型生成结果)的字典2.
StuffDocumentsChain
- 作用:处理多文档输入,将所有文档内容拼接为单个字符串,传递给
LLMChain。- 关键步骤:
- 文档合并:提取所有文档的
page_content,用换行符连接。- 变量注入:将合并后的文本赋值给
document_variable_name(即text)。- 调用LLMChain:执行
LLMChain并返回结果。# Stuff的第一种写法 # chain = load_summarize_chain(model, chain_type='stuff')# Stuff的第二种写法 # 定义提示 prompt_template = """针对下面的内容,写一个简洁的总结摘要:"{text}"简洁的总结摘要:""" prompt = PromptTemplate.from_template(prompt_template)llm_chain = LLMChain(llm=model, prompt=prompt)stuff_chain = StuffDocumentsChain(llm_chain=llm_chain, document_variable_name='text')result = stuff_chain.invoke(docs) print(result['output_text'])
注意:chain = {'text': RunnablePassthrough()} | prompt | model,此处不可行。StuffDocumentsChain的一个关键功能是将多个文档合并成一个文本,
RunnablePassthrough可能不会自动处理多个文档的合并。

MapReduce
### 从初始化开始。
原因:LLM的Token有上限,需要分布式处理。
Map(总—分)——Combine(分——分分)——Reduce(分分——LLM);
1、Map
# 第二种: Map-Reduce # 第一步: 切割阶段 # 每一个小docs为1000个token text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=1000, chunk_overlap=0) split_docs = text_splitter.split_documents(docs)# 第二步: map阶段 map_template = """以下是一组文档(documents)"{docs}"根据这个文档列表,请给出总结摘要:"""map_prompt = PromptTemplate.from_template(map_template) map_llm_chain = LLMChain(llm=model, prompt=map_prompt)2、Reduce
# 第三步: reduce阶段: (combine和 最终的reduce) reduce_template = """以下是一组总结摘要:{docs}将这些内容提炼成一个最终的、统一的总结摘要:""" reduce_prompt = PromptTemplate.from_template(reduce_template) reduce_llm_chain = LLMChain(llm=model, prompt=reduce_prompt)''' reduce的思路: 如果map之后文档的累积token数超过了 4000个, 那么我们递归地将文档以<= 4000 个token的批次 传递给我们的 StuffDocumentsChain 来创建批量摘要。 一旦这些批量摘要的累积大小小于 4000 个token, 我们将它们全部传递给 StuffDocumentsChain 最后一次 ,以创建最终摘要。 '''3、Combine
当所有的 批量摘要 累积<4000 Token,停止Combine。
collapse_documents_chain:可选参数,如果超出了token_max时使用的中间chain
# 定义一个combine的chain combine_chain = StuffDocumentsChain(llm_chain=reduce_llm_chain, document_variable_name='docs')reduce_chain = ReduceDocumentsChain(# 这是最终调用的链。combine_documents_chain=combine_chain,# 中间的汇总的脸collapse_documents_chain=combine_chain,# 将文档分组的最大令牌数。token_max=4000 )4、合并所有链
MapReduceDocumentsChain:链接Map、Reduce
return_intermediate_steps:F——不返回中间(分)的总结,T——返回。
# 第四步:合并所有链 map_reduce_chain = MapReduceDocumentsChain(llm_chain=map_llm_chain,reduce_documents_chain=reduce_chain,document_variable_name='docs',return_intermediate_steps=False )# 第五步: 调用最终的链 result = map_reduce_chain.invoke(split_docs) print(result['output_text'])