Python实验4 列表与字典应用
目的 :熟练操作组合数据类型。
试验任务:
1. 基础:生日悖论分析。
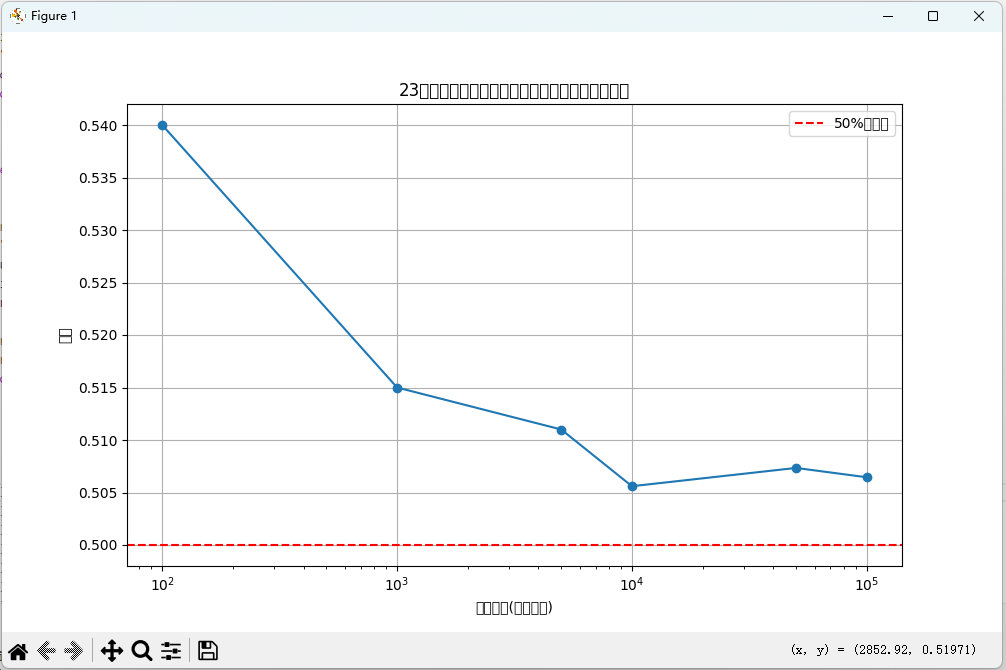
如果一个房间有23 人或以上,那么至少有两个人的生日相同的概率大于50%。编写程序,输出在不同随机样本数量下,23 个人中至少两个人生日相同的概率。
import random
import matplotlib.pyplot as pltdef birthday_paradox_simulation(num_people, num_simulations):"""模拟生日悖论"""count = 0for _ in range(num_simulations):birthdays = [random.randint(1, 365) for _ in range(num_people)]if len(birthdays) != len(set(birthdays)):count += 1return count / num_simulationsdef analyze_birthday_paradox():"""分析生日悖论"""num_people = 23simulation_sizes = [100, 1000, 5000, 10000, 50000, 100000]probabilities = []print("生日悖论分析 (23人):")print("模拟次数\t概率")for size in simulation_sizes:prob = birthday_paradox_simulation(num_people, size)probabilities.append(prob)print(f"{size}\t\t{prob:.4f}")# 绘制结果plt.figure(figsize=(10, 6))plt.plot(simulation_sizes, probabilities, marker='o')plt.axhline(y=0.5, color='r', linestyle='--', label='50%概率线')plt.xscale('log')plt.xlabel('模拟次数(对数尺度)')plt.ylabel('概率')plt.title('23人中至少两人生日相同的概率随模拟次数的变化')plt.legend()plt.grid(True)plt.show()# 运行生日悖论分析
analyze_birthday_paradox()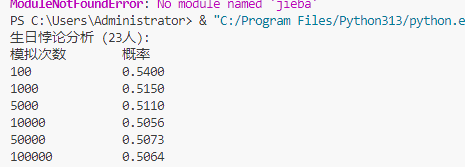
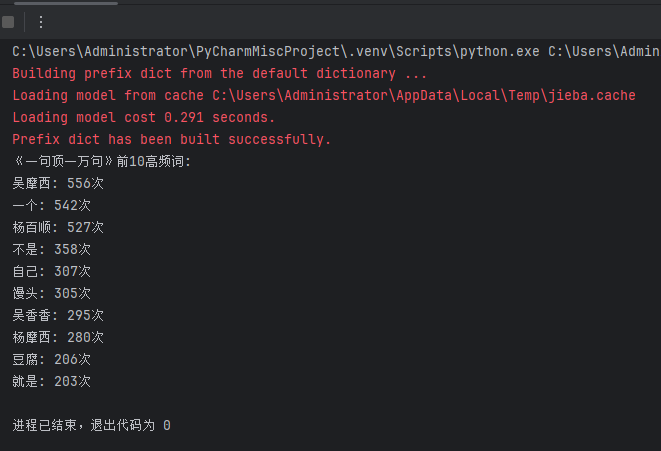
2. 进阶:统计《一句顶一万句》文本中前10 高频词,生成词云。
# coding:utf-8
import jieba
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as pltdef process_text_and_generate_wordcloud():"""处理文本并生成词云"""# 请将文本文件放在同一目录下,文件名为"yiju.txt"try:with open("yiju.txt", "r", encoding="utf-8") as f:text = f.read()except FileNotFoundError:print("未找到文本文件'yiju.txt',请将文件放在同一目录下")return# 使用jieba分词words = jieba.lcut(text)# 去除停用词和单字with open("stopwords.txt", "r", encoding="utf-8") as f:stopwords = set([line.strip() for line in f])filtered_words = [word for word in words if len(word) > 1 and word not in stopwords]# 统计词频word_counts = Counter(filtered_words)top10_words = word_counts.most_common(10)print("《一句顶一万句》前10高频词:")for word, count in top10_words:print(f"{word}: {count}次")# 生成词云wc = WordCloud(font_path="C:/Windows/Fonts/simhei.ttf", # 使用黑体,请确保字体文件存在background_color="white",max_words=200,width=800,height=600)wc.generate_from_frequencies(word_counts)plt.figure(figsize=(10, 8))plt.imshow(wc, interpolation="bilinear")plt.axis("off")plt.show()# 运行文本分析
process_text_and_generate_wordcloud()
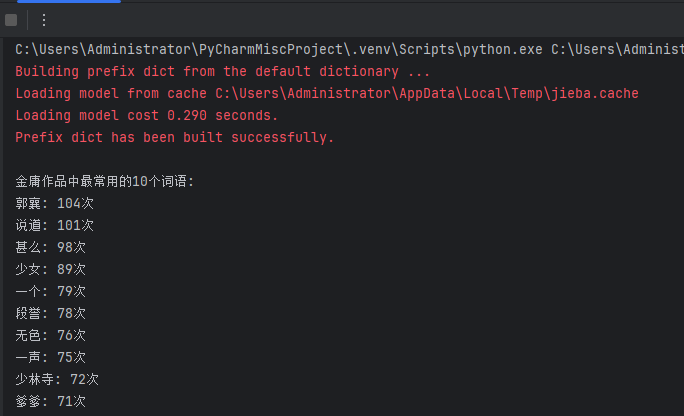
3. 拓展:金庸、古龙等武侠小说写作风格分析。
输出不少于3 个金庸(古龙)作品的最常用10 个词语,找到其中的相关性,总结其风格。
import jieba
from collections import Counter
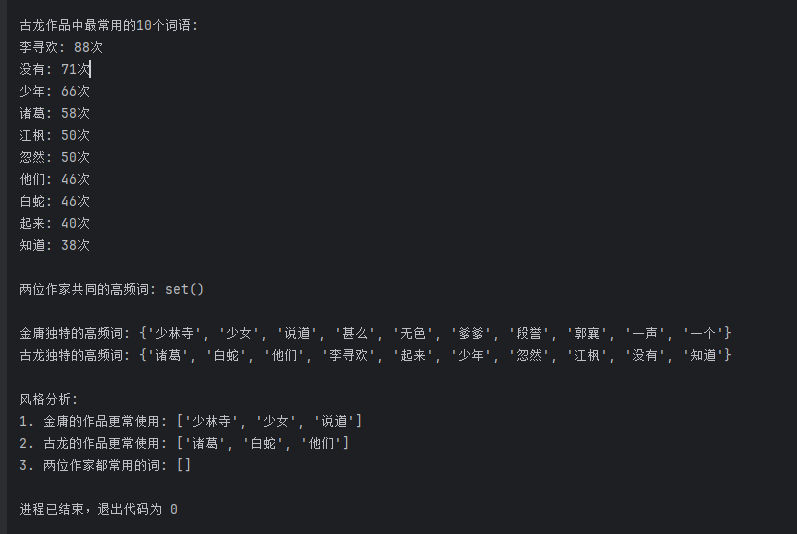
import matplotlib.pyplot as pltdef analyze_author_style(author_name, book_files):"""分析作者风格"""all_words = []for book_file in book_files:try:with open(book_file, "r", encoding="utf-8") as f:text = f.read()words = jieba.lcut(text)all_words.extend(words)except FileNotFoundError:print(f"未找到文件: {book_file}")continue# 去除停用词和单字with open("stopwords.txt", "r", encoding="utf-8") as f:stopwords = set([line.strip() for line in f])filtered_words = [word for word in all_words if len(word) > 1 and word not in stopwords]# 统计词频word_counts = Counter(filtered_words)top10_words = word_counts.most_common(10)print(f"\n{author_name}作品中最常用的10个词语:")for word, count in top10_words:print(f"{word}: {count}次")return dict(top10_words)def compare_authors_styles():"""比较金庸和古龙的写作风格"""# 假设有这些文本文件,实际使用时请替换为真实文件路径jin_yong_books = ["shediao.txt", "tlbb.txt", "tianlong.txt"]gu_long_books = ["xiaoli.txt", "chulai.txt", "liuxing.txt"]# 分析金庸风格jin_yong_words = analyze_author_style("金庸", jin_yong_books)# 分析古龙风格gu_long_words = analyze_author_style("古龙", gu_long_books)# 找出共同高频词common_words = set(jin_yong_words.keys()) & set(gu_long_words.keys())print("\n两位作家共同的高频词:", common_words)# 找出各自独特的高频词jin_yong_unique = set(jin_yong_words.keys()) - set(gu_long_words.keys())gu_long_unique = set(gu_long_words.keys()) - set(jin_yong_words.keys())print("\n金庸独特的高频词:", jin_yong_unique)print("古龙独特的高频词:", gu_long_unique)# 简单风格分析print("\n风格分析:")print("1. 金庸的作品更常使用:", [word for word in jin_yong_unique if word in jin_yong_words][:3])print("2. 古龙的作品更常使用:", [word for word in gu_long_unique if word in gu_long_words][:3])print("3. 两位作家都常用的词:", list(common_words)[:3])# 运行风格分析
compare_authors_styles()