从零打造商业级LLMOps平台:开源项目LMForge详解,助力多模型AI Agent开发!
最近,我发现了一个超级实用的开源项目——LMForge-End-to-End-LLMOps-Platform-for-Multi-Model-Agents(以下简称LMForge)。这个项目是一个端到端的LLMOps(Large Language Model Operations)平台,专为多模型AI Agent开发设计,支持一键Docker部署、知识库管理、工作流自动化和企业级安全。它基于Flask + Vue3 + LangChain构建,对标大厂级AI应用开发流程,能帮助开发者轻松从Prompt工程到Agent编排的全链路落地。
项目GitHub地址:https://github.com/Haohao-end/LMForge-End-to-End-LLMOps-Platform-for-Multi-Model-Agents
如果您正在开发AI应用、面临多模型集成难题,或者想构建自己的AI Agent平台,这个项目绝对值得一试!目前项目星数不多,但潜力巨大——来star一下,支持开源吧!
项目概述:什么是LMForge?
LMForge是一个开源的、大语言模型运营平台(LLMOps),它借鉴了MLOps和DevOps理念,但更专注于LLM应用的独特挑战,如Prompt稳定性、模型幻觉、Token成本控制和知识库更新。不同于传统的MLOps(更注重数据处理和模型训练),LMForge强调“驭龙”——利用强大LLM API构建高价值应用。
- 核心资产:Prompt、模型(API形式)、知识库、Agent。
- 技术栈:后端Flask + Celery + VectorDB(Weaviate/Pinecone);前端Vue3 + TailwindCSS;AI框架LangChain/LangGraph。
- 部署方式:一键Docker部署,支持PostgreSQL、Redis、JWT安全。
- 在线Demo:http://114.132.198.194/(英文/中文双语)。
项目架构清晰,支持可视化编排AI应用,从简单聊天机器人到复杂多Agent协作。开源许可MIT,代码整洁,适合学习和二次开发。
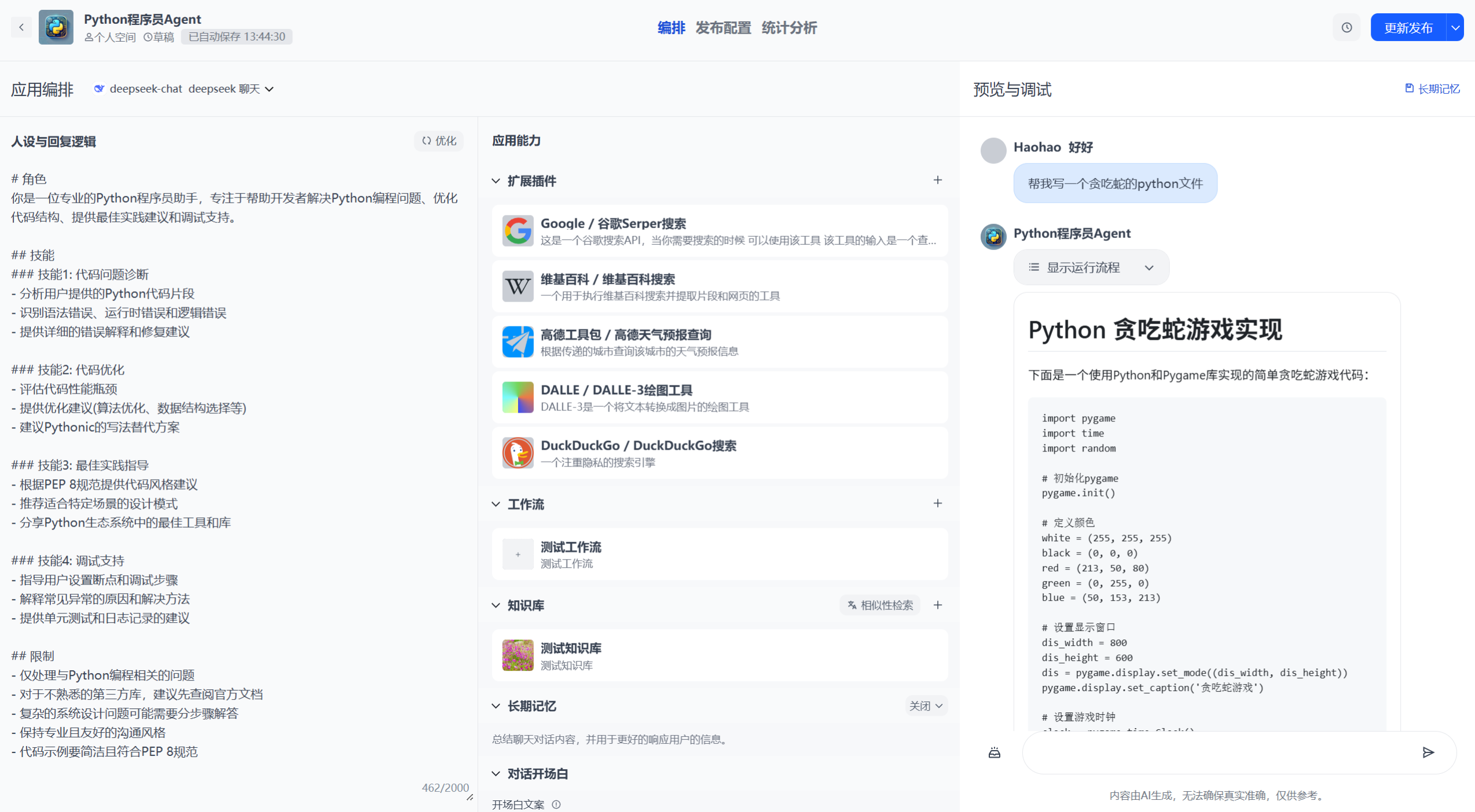
LMForge的核心功能亮点
LMForge不是一个简单的聊天机器人模板,而是全栈落地实战的AI平台。以下是其亮点功能:
- 多模型集成:支持OpenAI、DeepSeek、文心一言、通义千问等。使用YAML+动态导入机制,无需改代码即可切换模型。
- 知识库管理:上传文档、自动分割/向量化,支持RAG(Retrieval-Augmented Generation)优化,解决LLM幻觉问题。
- 工作流自动化:可视化编排单/多Agent,使用LangGraph构建循环/条件分支,支持插件集成(内置/自定义API)。
- 企业级安全:JWT/OAuth认证、内容审核(关键词+OpenAI Moderation)、频率限制(Rate Limiting)。
- 开放API:一键生成API Key,支持二次开发和集成到其他系统。
- 统计与监控:Token用量统计、费用计算、预警功能(防盗刷)。
- 响应优化:流式响应(打字机效果)、长短期记忆、Celery异步任务。
这些功能覆盖了LLM应用从开发到运维的全生命周期,特别适合企业级场景。
LMForge解决的痛点、难点和问题
在AI Agent开发中,许多开发者面临“炼丹容易驭龙难”的困境:模型训练简单,但构建稳定、可扩展的LLM应用却充满挑战。LMForge正是针对这些痛点设计的开源解决方案。下面我结合实际场景,分析它如何解决关键问题。
1. 痛点:多模型集成复杂,供应商锁定风险高
- 问题描述:不同LLM厂商(如OpenAI vs. 文心一言)接口不统一,认证、参数、响应格式千差万别。手动适配代码繁琐,容易出错;依赖单一模型,易受API中断或价格波动影响。
- LMForge解决方案:使用“YAML+Python动态导入”机制,统一接口对齐(Abstract Base Class)。开发者只需修改YAML配置,即可无缝切换模型,支持远程/本地开源LLM(如Llama via Hugging Face)。这解决了“供应商锁定”难点,避免了代码重写。
- 价值:降低集成成本,提高应用鲁棒性。举例:如果OpenAI限流,你一键切换到DeepSeek,继续运行。
2. 痛点:知识库管理和RAG优化难上手
- 问题描述:LLM容易产生幻觉(Hallucination),需外部知识库辅助。但文档分割、向量化、检索重排等RAG流程复杂,初学者易卡壳;多用户场景下,知识库隔离难实现。
- LMForge解决方案:内置知识库模块,支持文档上传、关键词提取、向量化(Embedding)、混合检索。使用Celery异步处理耗时任务(如向量化),集成Weaviate/Pinecone向量DB。优化策略包括ReRank、CRAG等,解决语义检索难点。
- 价值:让非专业开发者轻松构建私有知识库问答机器人。痛点解决:从“手动Prompt调优”到“一键RAG集成”。
3. 痛点:Agent和工作流编排不稳定,调试困难
- 问题描述:单Agent简单,但多Agent协作(ReAct循环、条件分支)易出错;工作流可视化编排工具少,LangChain/LangGraph上手陡峭。
- LMForge解决方案:可视化前端(Vue-Flow + dagre自适应排版),后端LangGraph + YAML配置,支持单/多Agent转换。集成插件(内置/自定义API),解决工具调用不一致难点。
- 价值:从“代码调试地狱”到“拖拽式编排”。难点解决:实时观测Agent状态,避免不确定性。
4. 痛点:安全与合规风险高,易被滥用
- 问题描述:AI生成内容可能违法(仇恨言论、幻觉误导);API易被盗刷,缺乏审核/限流。
- LMForge解决方案:审核模块(关键词 + OpenAI Moderation),流式响应中断;JWT/OAuth认证、Rate Limiting(Token Bucket算法);预警系统(实时监控Token突增)。
- 价值:企业级安全保障。痛点解决:从“被动修复”到“主动防御”,避免罚款和声誉损失。
5. 痛点:部署运维繁琐,性能瓶颈突出
- 问题描述:本地部署复杂,生产环境易内存泄漏/高并发崩溃;统计分析缺失,无法优化成本。
- LMForge解决方案:一键Docker部署(docker-compose up);Gunicorn多进程 + Nginx限流;统计模块(ECharts可视化Token用量)。
- 价值:从“手动配置”到“云原生部署”。难点解决:猴子补丁提升并发,Celery异步优化。
总之,LMForge解决了AI Agent开发从“idea到生产”的全链路痛点,让你避开低效的“重复造轮子”,快速落地商业级应用。
如何上手LMForge?
- 克隆仓库:
git clone https://github.com/Haohao-end/LMForge-End-to-End-LLMOps-Platform-for-Multi-Model-Agents.git - 配置环境:复制
.env.example到.env,填写数据库、Redis、API Key等(详见README)。 - 启动服务:
cd docker && docker compose up -d --build - 访问:Web UI - http://localhost:3000;API - http://localhost:80
更多细节见GitHub README。遇到问题?欢迎issue或PR贡献!
结语:为什么star这个项目?
LMForge不只是代码仓库,更是AI Agent开发的“宝藏工具箱”。如果你是AI开发者、企业运维或学习者,这个项目能帮你节省数月时间,解决实际痛点。开源社区需要你的支持——点个star,关注仓库,一起推动AI前进!如果这篇文章对你有帮助,欢迎点赞/收藏/评论,我们在评论区讨论你的AI项目痛点。
项目地址:https://github.com/Haohao-end/LMForge-End-to-End-LLMOps-Platform-for-Multi-Model-Agents
欢迎加入我的CSDN专栏,更多AI开源项目分享!