SAP HANA Scale-out 01:表分布
基础信息
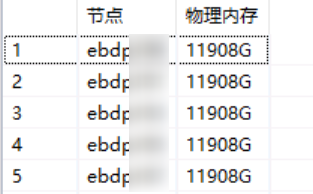
节点内存
--查询节点信息
SELECT HOST AS "节点",TO_VARCHAR(VALUE/1024/1024/1024,'0') || 'G' AS "物理内存"
FROM M_HOST_INFORMATION
WHERE KEY = 'mem_phys'示例
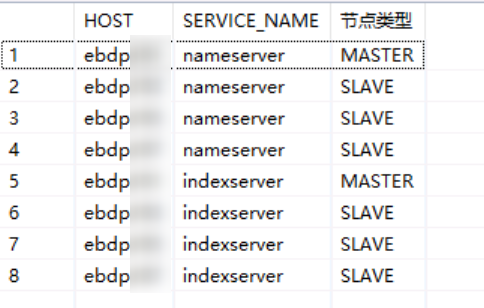
节点类型
--查询节点类型
SELECT
HOST
,SERVICE_NAME
,COORDINATOR_TYPE AS "节点类型"
FROM M_SERVICES
WHERE ACTIVE_STATUS = 'YES'
AND SERVICE_NAME IN ('nameserver','indexserver')示例
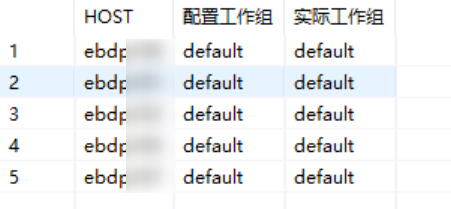
系统拓扑
--查询系统工作组
SELECTHOST,WORKER_CONFIG_GROUPS AS "配置工作组",WORKER_ACTUAL_GROUPS AS "实际工作组"
FROM M_LANDSCAPE_HOST_CONFIGURATION
WHERE HOST_ACTIVE = 'YES' AND HOST_STATUS = 'OK'
示例
卷
--查询卷
SELECT * FROM M_VOLUMES
--查询卷大小
SELECT * FROM M_VOLUME_SIZES表分组
表分组结构
Column | Description |
SCHEMA_NAME | The schema name. |
TABLE_NAME | 表名 |
GROUP_NAME | 组名 |
GROUP_TYPE | 组类型,BW内预定的类型有: sap.bw.cube, sap.bw.dso, sap.bw.psa and so on. |
SUBTYPE | The subtype. This is required for some group types, for example in SAP BW:
|
IS_GROUP_LEAD | Determines the leading table within a group. If none is set, the largest, partitioned, non-replicated column store table is used as leading table. |
配置表分组
--建表时指定
CREATE COLUMN TABLE ZFIGL00 (A INT)
GROUP NAME ZFIGL
GROUP TYPE GP_T1
GROUP SUBTYPE ST_01
;
-后期修改
ALTER TABLE ZFIGL00 SET GROUP NAME "GP_T2";示例
Table Name | Group Type (GROUP_TYPE) | Subtype (SUBTYPE) | Group Name (GROUP_NAME) |
/BIC/AZFIGL00 | sap.bw.dso | ACTIVE | ZFIGL |
/BIC/AZFIGL40 | sap.bw.dso | QUEUE | ZFIGL |
/BIC/B0000197000 | sap.bw.dso | CHANGE_LOG | ZFIGL |
查询表分组
--查询数据表的分组信息
SELECTSCHEMA_NAME --,TABLE_NAME --表名,GROUP_TYPE --组类型,SUBTYPE --子组,GROUP_NAME --组名,IS_GROUP_LEAD --是否组内主表
FROM SYS.TABLE_GROUPS
WHERE TABLE_NAME LIKE '%%'位置分布
位置信息
位置可以使用系统预定义位置、用户自定义工作组、用户自定义位置。
系统预定义位置
Location | Description |
default | 'default' is the name of a worker group and it used as the default location for hosts if no other locations are defined. This value can be seen in the WORKER_CONFIG_GROUPS field in system view M_LANDSCAPE_HOST_CONFIGURATION. |
master | This is the master location node. The value 'MASTER' is set as coordinator_type for the indexserver in system view M_SERVICES. |
slave | Other pre-defined locations are slaves, that is, any coordinator_type value for the indexserver in system view M_SERVICES which is not MASTER. |
all | The 'all' location includes both masters and slaves. |
用户自定义工作组
--配置工作组
call SYS.UPDATE_LANDSCAPE_CONFIGURATION( 'SET WORKERGROUPS','<hostname>','<name1> <name2> <name3>' )
--查询工作组
call SYS.UPDATE_LANDSCAPE_CONFIGURATION( 'GET WORKERGROUPS','<hostname>')
--工作组
SELECT HOST --主机,WORKER_CONFIG_GROUPS --配置的工作组,WORKER_ACTUAL_GROUPS --实际工作组
FROM M_LANDSCAPE_HOST_CONFIGURATION用户自定义位置
--自定义位置MyLocation
ALTER SYSTEM ALTER TABLE PLACEMENT LOCATION MyLocation SET (INCLUDE => '2,3',
EXCLUDE => 'SLAVE');
--调整自定义位置MyLocation
ALTER SYSTEM ALTER TABLE PLACEMENT LOCATION MyLocation SET (INCLUDE => '2,3',
EXCLUDE => '');
--删除自定义位置
ALTER SYSTEM ALTER TABLE PLACEMENT LOCATION MyLocation UNSET;位置分布规则
--位置分布表
SELECTLOCATION_NAME --位置名称,INCLUDE --包含的位置,EXCLUDE --排除的位置
FROM SYS.TABLE_PLACEMENT_LOCATIONS默认表数据如下:
LOCATION_NAME | INCLUDE | EXCLUDE |
ALL | WORKER_DT | |
SLAVE | WORKER_DT | |
MY_GROUP | WORKER_DT, MASTER | |
OLTP_PROCESSOR | 2,3 | |
myLocation | 5 |
Note that the worker group worker_dt is a special worker group required for handling warm data in the extension node (see section on Extension Node and following example).
位置与卷对照关系
New locations and volume assignments are only effective after the next reconfiguration of the indexserver,当前有效的对照关系在表M_TABLE_PLACEMENT_LOCATIONS
--查看当前有效的位置与卷的对照关系
SELECTLOCATION_NAME --组名,SYSTEM_DEFINED_VOLUME_IDS --,INCLUDE --,EXCLUDE --EFFECTIVE_VOLUME_IDS --有效的卷ID
FROM M_TABLE_PLACEMENT_LOCATIONS示例数据
| LOCATION_NAME | SYSTEM_DEFINED_VOLUME_IDS | INCLUDE | EXCLUDE | EFFECTIVE_VOLUME_IDS |
| all | 3,4,5,6 | 3,4,5,6 | ||
| coordinator | 3 | 3 | ||
| default | 3,4,5,6 | 3,4,5,6 | ||
| worker | all | coordinator | 4,5,6 |
表分布规则
配置【表分布规则】
可以按表分组内的字段值配置表分布
--配置表分布规则
ALTER SYSTEM ALTER TABLE PLACEMENT (
SCHEMA_NAME => 'MY_APPLICATION') SET (LOCATION=>'all_without_worker_dt');ALTER SYSTEM ALTER TABLE PLACEMENT (
SCHEMA_NAME => 'MY_APPLICATION',GROUP_TYPE=>'WARM_DATA') SET (LOCATION=>'worker_dt');建表时使用分布规则
--建表时,根据配置的分布规则进行分布
CREATE TABLE "MY_APPLICATION"."TABLE_A" (INT A);
CREATE TABLE "MY_APPLICATION"."TABLE_B" (INT A);
CREATE TABLE "MY_APPLICATION"."TABLE_C" (INT A) GROUP TYPE "WARM_DATA";分布规则如何应用
按以下内容从上到下,1是最高优先级
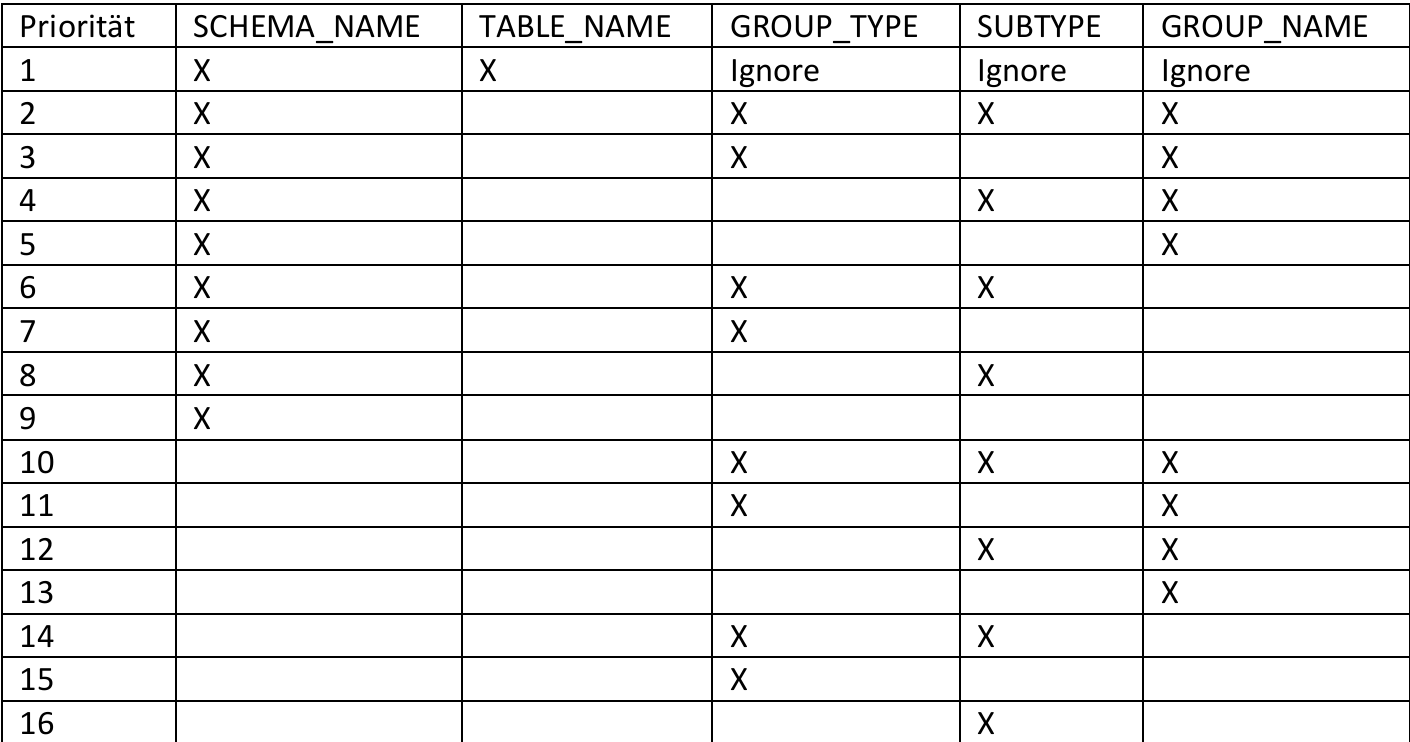
查询表的分布规则
SYS.TABLE_PLACEMENT
# | Column | Description |
1 | SCHEMA_NAME | The schema name (as for table groups). |
2 | TABLE_NAME | The table name. |
3 | GROUP_NAME | The group name. |
4 | GROUP_TYPE | The group type. |
5 | SUBTYPE | The subtype. |
6 | MIN_ROWS_FOR_PARTITIONING | Partitioning rule: the number of records that must exist in the table before the number of first-level partitions is increased above 1. |
7 | INITIAL_PARTITIONS | Partitioning rule: determines the number of initial partitions to create, for example, HASH 1, HASH 3, 经测试只有在表内实际数据大于MIN_ROWS_FOR_PARTITIONING后会生成此数目的分区,而不是刚建表就生成此数目的分区 |
8 | REPARTITIONING_THRESHOLD | Partitioning rule: if the row count exceeds this value then further split iterations are considered. |
9 | DYNAMIC_RANGE_THRESHOLD | Applies to tables that use the dynamic range partitioning feature. Overwrites the system default value defined in indexserver.ini [partitioning] dynamic_range_default_threshold (10,000,000) for that specific combination of schema / table / group characteristics. |
10 | SAME_PARTITION_COUNT | Specifies that all partitions of the tables in a group will contain the same number of partitions. Globally maintained in global.ini [table_placement] same_num_partitions but in case of several applications with deviating settings, it can be maintained on a more granular level. |
11 | LOCATION | Location rule: master, slave, all (see following topic on Locations). |
12 | PERSISTENT MEMORY | Whether or not the data is loaded in persistent memory. |
13 | PAGE LOADABLE | Whether or not the data is page loadable. |
14 | NUMA_NODE_INDEXES | The allowed NUMA nodes. |
15 | REPLICA COUNT | The required number of replicas. |
16 | REPLICA TYPE | The replication type. The default type is ASYNCHRONOUS. |
示例

查询分布规则匹配的位置
根据分布规则匹配到的分布位置
SELECT
*
FROM M_EFFECTIVE_TABLE_PLACEMENT表重分布
使用以下工具进行表重分布
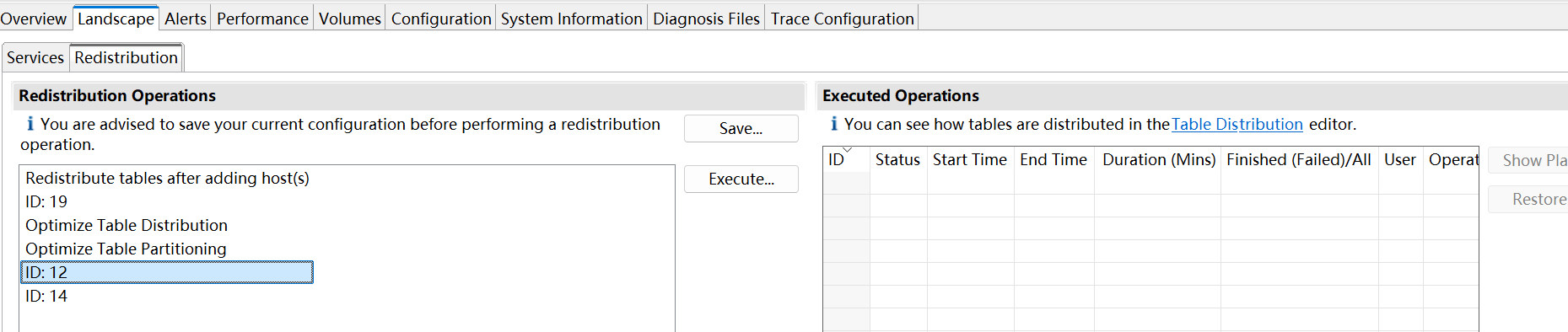
- SAP HANA Cockpit
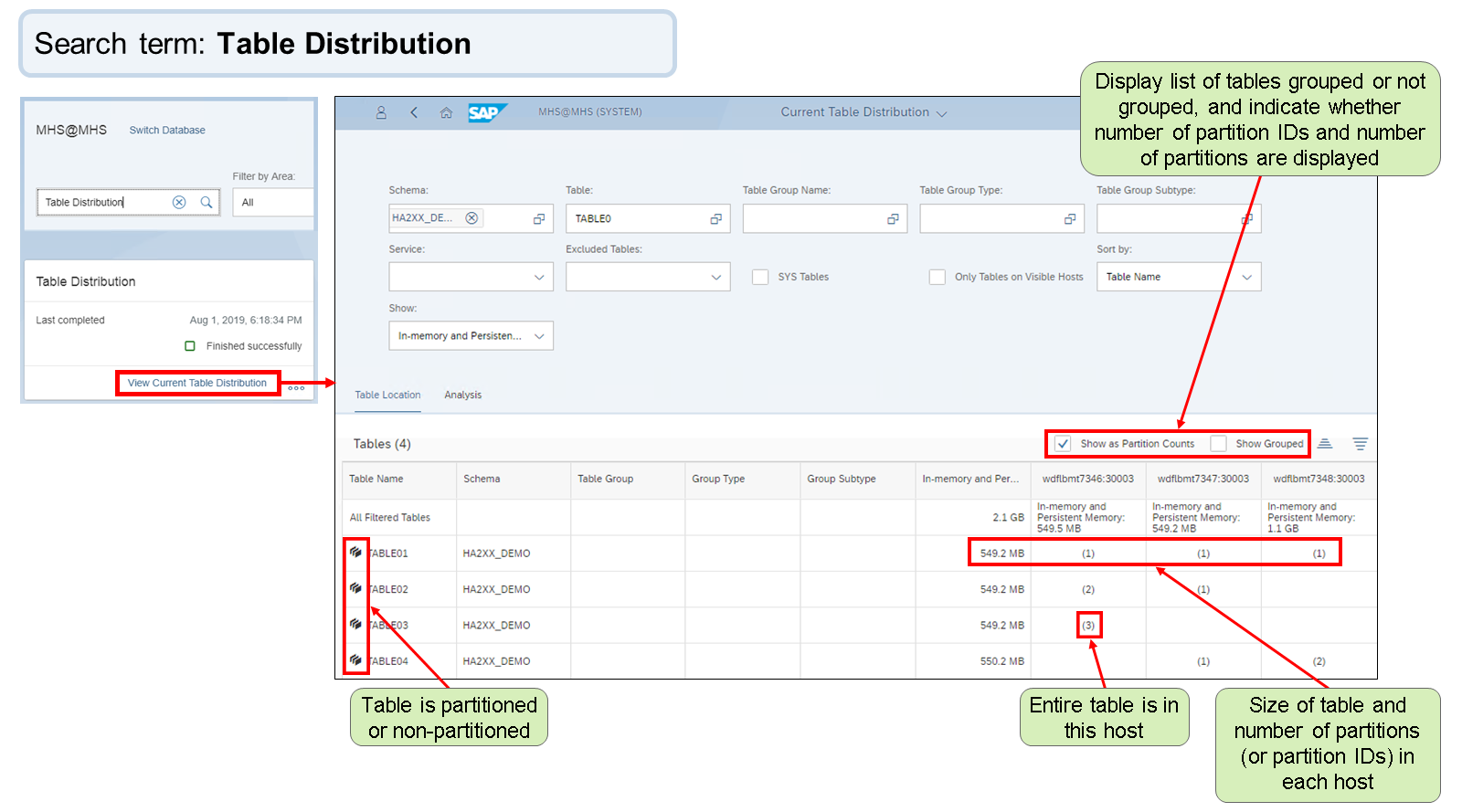
- SQL Console
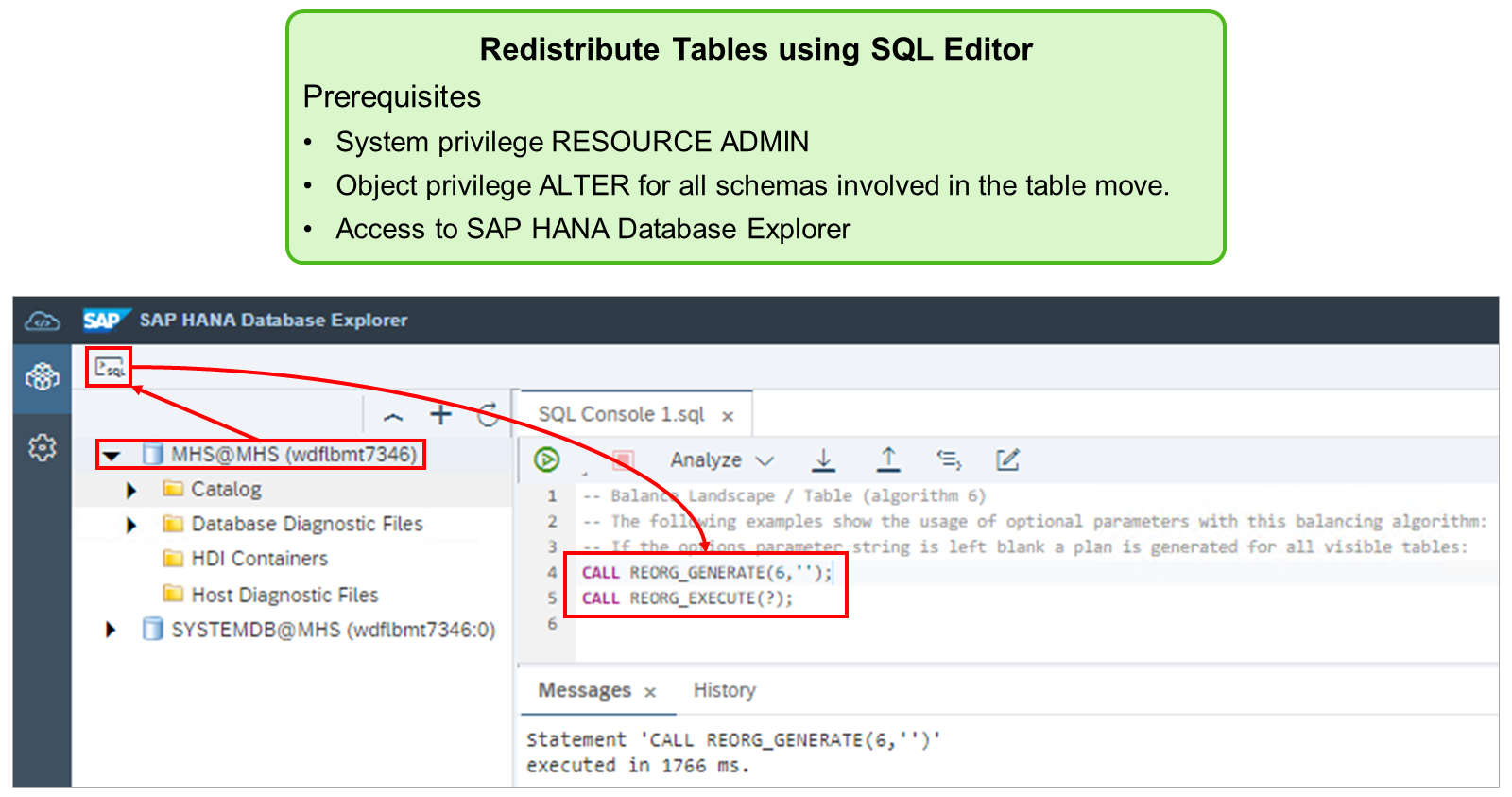
- SAP HANA Studio (deprecated)
表的实际分布
--表的逻辑分布:M_TABLE_LOCATIONS
SELECT * FROM M_TABLE_LOCATIONS
--表的物理分布:M_TABLE_PERSISTENCE_LOCATIONS
SELECT * FROM M_TABLE_PERSISTENCE_LOCATIONS