如何看懂GPU架构?万云智算一分钟带你了解GPU参数指标
GPU架构参数如CUDA核心数、显存带宽、Tensor TFLOPS、互联方式等,并非 “冰冷的数字”,而是直接关系设备能否满足需求、如何发挥最大价值、是否避免资源浪费等问题的核心要素。
本篇文章将全面分析GPU核心参数体系:算力、显存大小、显存带宽、热门架构特性等关键指标,旨在帮您理解不同应用场景下,如何选择最合适的GPU算力解决方案。
01
算力
GPU执行浮点运算的能力,通常以TFLOPS(每秒浮点操作次数)为单位衡量。
浮点运算能力是针对“高精度小数计算”的专项能力,也是处理“复杂科学 / 工程任务”的核心,它能加速模型训练、数据分析以及复杂模拟的处理速度。
那我们常提到的半精度(FP16)、单精度(FP32)、双精度(FP64)分别是什么?
它们是电脑存储和计算「小数」的三种“精度档位”,就像手机拍照的 “720P、1080P、4K”,档位越高,细节越精细,精度越高,但“处理速度”(计算效率)越慢,效率越低,成本越贵。
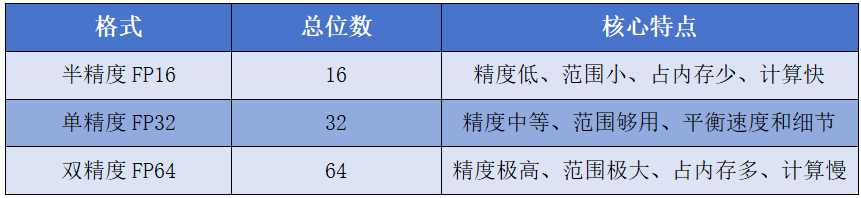
以前的大模型训练以FP32为主,现在更多是FP32和FP16的混合精度;推理的话,更多是FP16及其以下。
02
显存
是GPU用于存储数据和纹理的专用内存,与系统内存(RAM)不同,显存具有更高的带宽和更快的访问速度。显存的大小和性能直接影响GPU处理大规模数据的能力。
03
显存带宽
作为GPU与显存之间数据传输的桥梁;显存带宽=显存位宽x显存频率
如何理解显存与显存带宽的关系呢?
显存容量决定了“车厢”的载货量,显存越大装载的货物越多,而显存带宽决定了“装卸货”的速度,带宽越高装卸货的效率越高。
04
显存类型
显卡上用于存储和处理图形数据的专用内存技术,不同显存类型在带宽、功耗和性能上有显著差异。
主流显存类型有3种:GDDR、HBM和LPDDR。
GDDR系列主要用于游戏,HBM系列主要用于高端AI计算,如数据中心,LPDDR系列主要用于移动/边缘设备。
05
功耗
指单位时间内的能量消耗,反应消耗能量的速率单位是瓦特(W)。
06
卡间互联
卡间互联的作用是“高速专用通道”(比如 NVIDIA的NVLink、行业通用的PCIe 5.0),传输速度能达到每秒几百 GB(比如 NVLink 能到 400GB/s),和计算速度匹配,让所有卡 “算得快、传得也快”,不浪费算力。
NVLink是由NVIDIA研发的专用高速互联技术,专为解决“多 GPU 协同计算”的瓶颈 —— 当单张 GPU 算力不足时,多张 GPU 需快速交换数据,PCIe 的带宽和延迟成为瓶颈。
例如:训练千亿参数大模型时,8 张 GPU 需实时同步梯度数据,NVLink 让它们直接 “面对面沟通”。
07
流处理器(CUDA核心)
CUDA全称:CUDA 核心(Compute Unified Device Architecture Core)
它是NVIDIA GPU的基础计算单元。每个CUDA核心只处理简单的数学运算(如浮点加减乘除),但通过集成数千个这样的核心,GPU能同时处理海量数据,速度远超CPU。CUDA核心越多,并行处理能力越强。
08
张量核心(Tensor Core)
它是NVIDIA GPU中的一种专用计算单元,专门用于加速矩阵和张量运算,尤其在深度学习和高性能计算(HPC)中表现突出。
张量核心与CUDA相比,在于它能做矩阵运算,而CUDA一次只能算一个数字。所以张量核心效率更高。
09
Tensor性能
Tensor性能(Tensor TFLOPS)是衡量GPU或AI加速器在张量计算任务中的浮点运算能力的核心指标。专指通过上面的Tensor Core加速的浮点运算。数字越大,计算越快。
需要补充说明的是一般企业在做决策时不会太关注Tensor core的数量,而更看重Tensor性能。
10
英伟达GPU架构
英伟达数据中心级GPU名称中,首字母是架构的缩写。例如,B代表Blackwell、H代表Hopper,A代表Ampere、L代表Lovelace、都是用世界著名的科学家名字来命名。
数字往往代表GPU产品的等级或者性能表现。每一代的产品英伟达都会设计低中高不同价格、性能和功耗的GPU。数字部分越大,通常代表GPU越强大、价格越昂贵(A800和H800这类阉割版产品除外)。
比如:H100、A100、V100这类产品型号代表的同一代产品中的旗舰产品,价格最昂贵、性能最强大。也拥有最高的核心数和最大的显存,专为大型模型推理以及训练而设计。
Ampere架构
Ampere架构是继Volta和Turing架构之后的新一代技术,以540亿个晶体管打造,是有史以来最大的 7 纳米 (nm) 芯片,于2020年首次发布。
该架构具有更多的CUDA核心,并引入了第三代Tensor Core,针对AI和深度学习计算进一步优化,支持更高效的混合精度运算,显著提升了AI训练和推理的性能。
Ampere GPU使用了更快的内存技术(如GDDR6X)和更大的内存容量,并支持更高数据传输速度的PCI Express 4.0标准,从而能够更好地处理大规模数据集和复杂的应用程序。
典型卡型号:NVIDIA A100、A800

Hopper架构
Hopper 架构发布于 2022 年,拥有超过 800 亿个晶体管,并采用新型流式处理器。Hopper支持第四代Tensor Core,能够支持混合的 FP8 和 FP16 精度,与上一代相比,Hopper 将 TF32、FP64、FP16 和 INT8 精度的每秒浮点运算(FLOPS)提高了 3 倍,在矩阵运算中提供更高的吞吐量和效率。
Hopper Tensor Core 与 Transformer 引擎和第四代NVLink(GPU之间高达900GB/s的双向带宽)相结合,可使 HPC 和 AI 工作负载的加速实现数量级提升。
典型卡型号:NVIDIA H100、H200、H800、H20

Blackwell架构
Blackwell架构发布于 2024 年,具有2080亿个晶体管,采用了双倍光刻极限尺寸的裸片,通过10 TB/s的片间互联技术连接成一块统一的 GPU。
NVIDIA 还推出了第五代 NVLink,提供前所未有的并行性和 1.8TB/s 的芯片间通信带宽,性能远超Hopper架构。Blackwell GPU具备192GB的HBM3E,支持高达7400亿个参数的模型,提供了高达8TB/s的带宽。
此外,它还引入了第二代 Transformer 引擎,支持 FP4 精度和动态精度切换,有助于自动将模型转换为适当的格式以达到最佳性能。
典型卡型号:NVIDIA B100、B200、B300

GPU 计算能力已成为推动全球技术革命的核心引擎,其作用贯穿人工智能、科学研究、工业制造等关键领域,深刻改变着人类解决复杂问题的能力边界。
在这场算力革命中,谁尽早掌握GPU的核心技术,谁就能在人工智能、元宇宙、数智化转型中占据制高点。