告别音色漂移!微软超长语音合成模型VibeVoice正式开源
告别音色漂移!微软超长语音合成模型VibeVoice正式开源
今日凌晨,AI语音合成领域迎来了一枚由微软研究院投下的“重磅炸弹”——VibeVoice-1.5B模型正式开源!
这不仅是一次简单的代码共享,更标志着长时、多speaker、高保真语音合成的技术壁垒被彻底击穿。它一举解决了困扰业界多年的三大难题:时长限制、音色漂移与多人交互,将AI语音生成的“天花板”提升到了一个前所未有的高度。
想象一下,让AI一键生成90分钟的有声书、一场多人参与的专题播客,甚至是一部广播剧的完整音频,期间多位主播谈笑风生、音色稳定、对话流畅,且无需任何后期剪辑——这,就是VibeVoice-1.5B为我们描绘的未来图景。
它的开源,无疑是为全球开发者和创作者送上了一份“大礼包”。无论是想打造下一代AI配音平台、开发沉浸式游戏叙事,还是构建多语言虚拟助手,VibeVoice都提供了此前难以想象的强大基础能力。
技术的边界已被刷新,AI语音合成的“GPT时刻”,或许真的来了。
架构介绍
VibeVoice 的核心架构以 Qwen2.5-1.5B 语言模型为基座,通过多阶段建模与模块化设计实现了高质量、长序列的语音生成。系统主要由以下部分组成:
1. 语言模型骨干(LLM Backbone)
采用 Qwen2.5-1.5B 作为核心语言模型,负责理解和建模文本语义与对话结构,输出高层语义表征以指导声学生成过程。模型在训练中通过课程学习逐步将上下文长度扩展至 65,536 token,为生成长篇语音提供充足的序列建模能力。
2. 双分词器模块(Dual Tokenizers)
-
声学分词器(Acoustic Tokenizer): 基于 σ-VAE 变体构建,采用镜像对称的编码器-解码器架构,共包含 7 层改进型 Transformer 模块。该模块实现对 24kHz 原始音频的 3200 倍压缩,在保障重建质量的同时有效缓解传统 VAE 中的方差坍缩问题。编码器和解码器参数量各约为 340M。
-
语义分词器(Semantic Tokenizer): 其编码器部分与声学分词器保持结构一致(不含 VAE 变分模块),通过自动语音识别(ASR)代理任务进行训练,专注于从语音中提取与文本语义高度相关的抽象表征。
3. 扩散解码头(Diffusion Head)
作为一个轻量级生成模块(4 层网络,约 123M 参数),该头部以语言模型输出的隐藏状态为条件,基于去噪扩散概率模型(DDPM)递归生成声学特征。在推理阶段,引入分类器自由引导(CFG)和 DPM-Solver 等加速采样策略,在保证生成质量的同时提升合成效率。
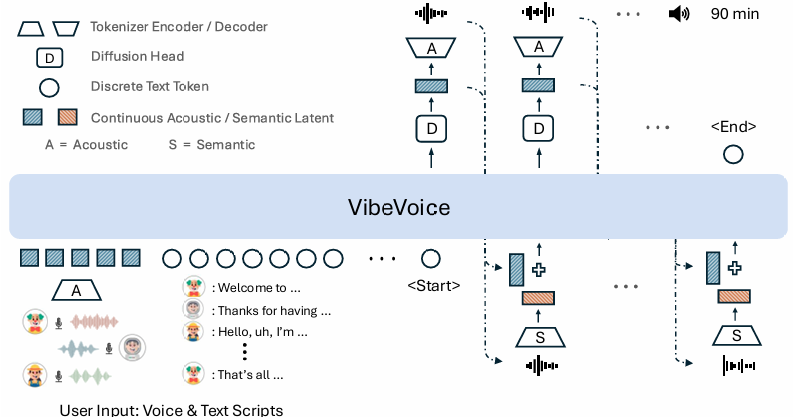
4. 训练与推理策略
系统采用分阶段训练方式:声学与语义分词器首先进行独立预训练,其后参数被固定,仅对语言模型和扩散头进行联合优化。在生成长语音时,模型充分运用双分词器提取的混合特征,实现声学与语义维度的高效对齐与上下文建模。
评测结果
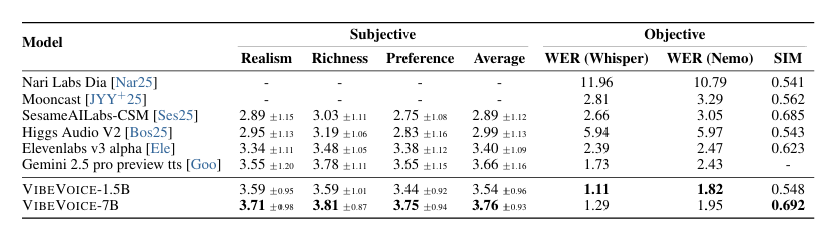
VIBEVOICE能够合成超过5000秒的音频,同时在主观评估中,在用户偏好、真实感和丰富性方面持续超越各类强大的开源与闭源系统。
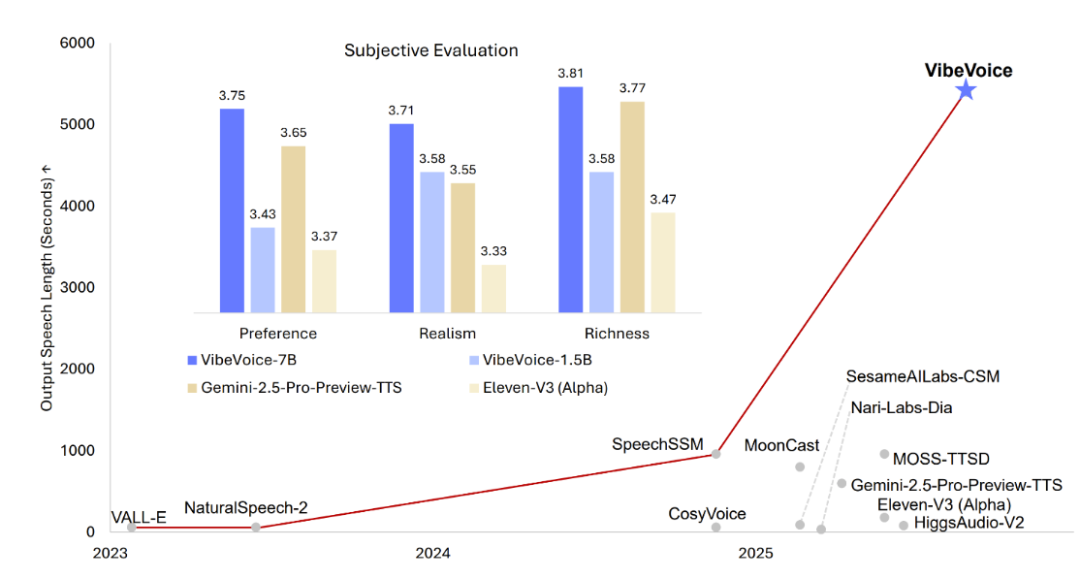
实验结果表明:所提出的VIBEVOICE模型在长对话语音生成任务中,于客观指标和主观评测上均优于其他顶级模型。与VIBEVOICE-1.5B模型相比,VIBEVOICE-7B模型在所有客观指标和说话人相似度上均取得显著提升,同时保持了相当的词错误率水平。
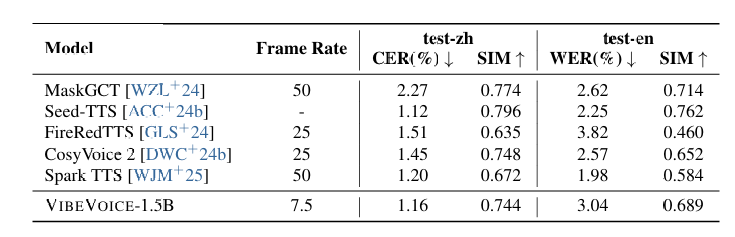
下表展示了VIBEVOICE在SEED测试集上的结果。尽管该模型主要针对长语音进行训练,但在短语音基准测试中仍展现出强大的泛化能力。此外,通过采用更低的帧率,VIBEVOICE显著降低了合成每秒钟语音所需的解码步数。
社区地址
OpenCSG社区:https://opencsg.com/models/microsoft/VibeVoice-1.5B
hf社区:https://huggingface.co/microsoft/VibeVoice-1.5B
关于 OpenCSG
OpenCSG 是全球领先的开源大模型社区平台,致力于打造开放、协同、可持续的 AI 开发者生态。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的一站式托管、协作与共享服务,具备业界领先的模型资产管理能力,支持多角色协同和高效复用。