领域知识如何注入LLM-检索增强生成
领域知识类似于图书馆的藏书和期刊资料。
写论文时你不可能通读图书馆所有资料,而是根据主题查找最相关的资料。
同样,根据用户提问,Agent不可能通读领域内所有知识,而是从预先构建的领域知识库检索相关信息,再由LLM组织并生成最终回答。
1 什么是检索增强
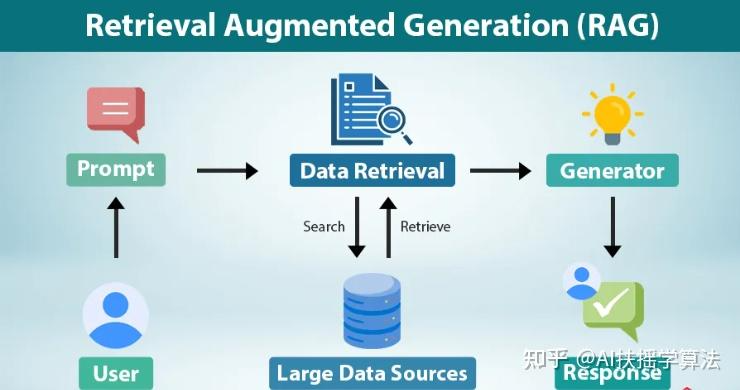
以上过程就是检索增强生成的过程,也称为RAG(Retrieval-Augmented Generation),是领域知识注入LLM常用的一种方式。Agent实时从领域知识库检索问题相关信息,将这些信息拼接到输入提示中,LLM生成准确和有用的回答或文本。以下是检索增强生成的三要素:
1)检索(Retrieval)
从外部知识库中精准抓取与问题高度相关的信息片段,为生成提供知识依据。
2)增强(Augmented)
将检索到的信息拼接到输入提示中,为生成模型注入外部知识。
3)生成(Generation)
结合检索到的信息和原始问题,LLM输出连贯、自然且准确的回答或文本。
2 领域知识库构建
1)知识库构建
领域知识库构建,一般需要以下三步
(1)数据处理
对领域文档进行预处理,按块大小和重叠量切分。
如果是PDF文件,需要先解析为结构清晰的文本后,再进行分块。
网友认可的PDF开源解析工具-CSDN博客
(2)向量化
使用文本嵌入模型将文本块转换为向量,存储在向量数据库中。
目前流行的向量模型有bge-m3、qwen-embedding等,向量库有milvus等。
开源向量LLM - BGE (BAAI General Embedding) _LLM向量嵌入技术-CSDN博客
轻量级milvus安装和应用示例-CSDN博客
(3)召回
推理时通过相似度搜索召回相关文档,作为上下文信息或 few-shot 示例提供给基座模型。
为提高准确率,可能需要先从知识库初筛出大量文档,然后结合问题对初筛结果进行精排,即reranker。
reranker过程参考如下。
开源向量模型-精排bge reranker示例-CSDN博客
2)dify示例
基于dify构建RAG知识库示例如下,需要考虑分块、分块重叠问题。
另外,还需要选择合适向量模型、设置搜索召回方案等。
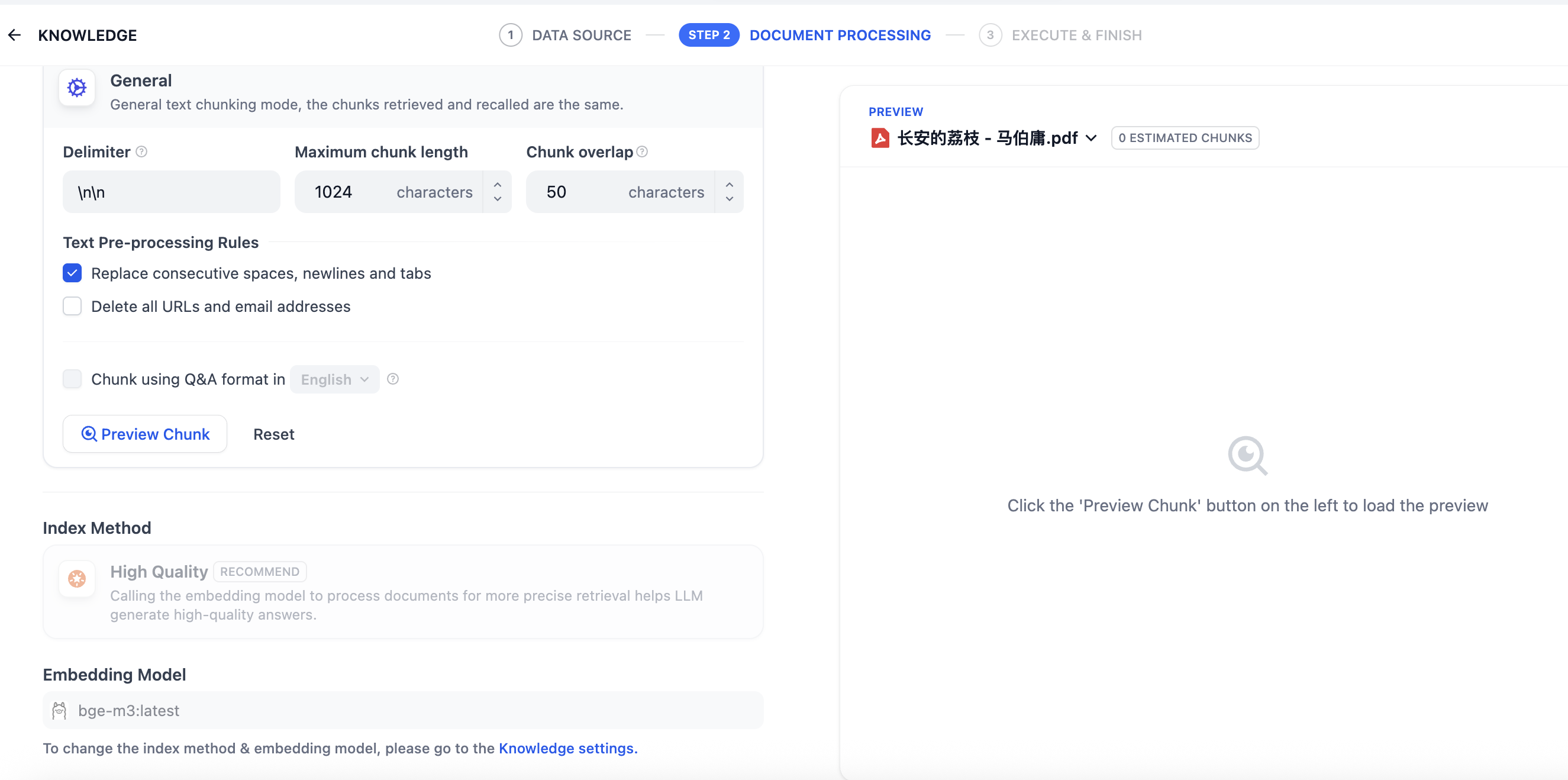
基于dify、ollama、bge搭建RAG知识库方案参考
基于dify+ollama+bge组合搭建本地知识库-CSDN博客
3 检索增强综合评估
检索增强实现领域知识注入LLM,具有保持通用能力,例如,模型参数不变,仍保留通用语言能力。可以快速更新,比如,知识库可动态更新,无需重新训练模型。另外,开发效率较高,避免大规模训练,节省计算资源。
检索增强也有一些劣势,比如依赖知识库质量,检索到的文档质量直接影响回答质量。另外检索过程可能增加推理延迟,并且需要消耗更多的 token,间接要求LLM支持32k甚至更高的上下文长度。而且要求基座模型强大,比如满血版的Deepseek,否则有可能不能有效理解和组合检索出来的领域知识。
reference
---
一文搞懂大模型知识增强:知识注入(Prompt + Finetune + RAG)
https://zhuanlan.zhihu.com/p/1915735984034788656
构建特定领域的大语言模型
https://syhya.github.io/zh/posts/2025-01-05-domain-llm-training/
有哪些可以把领域知识注入到大语言模型中的方法?
https://www.zhihu.com/question/630353844/answers/updated
RAG向量化文档分块方式探索
https://blog.csdn.net/liliang199/article/details/149798215
基于dify+ollama+bge组合搭建本地知识库
https://blog.csdn.net/liliang199/article/details/150859268
开源向量模型-精排bge reranker示例
https://blog.csdn.net/liliang199/article/details/150342360
网友认可的PDF开源解析工具
https://blog.csdn.net/liliang199/article/details/150986528
轻量级milvus安装和应用示例
https://blog.csdn.net/liliang199/article/details/150526054