iOS 审核 4.3a【二进制加固】
我们应该知道,面对iOS 上架 遇到4.3a的问题或者制作马甲包.最基础的操作就是混淆代码
尤其是我们专业做上架的,需要对各种语言的编译模式,产物,以及ipa构成都需要非常了解, 每种语言开发的App的编译产物不同,针对不同的编译产物做不同的处理方式
有一些经验的开发者, 应该知道 目前的混淆方式大概可以分为是三种
1: 源代码混淆
顾名思义, 就是通过处理源代码,让代码达到翻新的效果, 比如修改一些静态特征,代码结构
难度: 低
优点: 效率高,限制低
缺点:
1: 难以维护最难级别, 源代码改动之后,难以辨别, 对维护多个项目造成非常大的工作量
2: 需要针对各种语言分别开发,比如当前开发iOS的app 的语言有iOS , swift, c++, 需要针对各种不同的语言开发不同的混淆工具, 这个工作量太大, 能够开发iOS的app 的语言高达十几种, 制作十几种语言的混淆工具 根本不现实
2: 编译器混淆
这种混淆方式不需要处理源代码, 直接通过xcode在编译时混淆,也就是在xcode将源代码编译成.o的时机接入混淆,替换符号
难度: 中
优点: 不需要改动源代码, 不涉及到维护难度,不区分语言, 可混淆各种语言的代码
缺点:
1: 处理范围小, 只能对一些符号进行替换, 比如你想改变一些代码结构, 这个基本无法实现.
2: 能力有限,比如一些静态库在xcode编译前就已经被编译好, 所有静态库无法替换符号 ,也就是说他只能处理编译列表的文件

3: 替换符号可能会造成闪退,因为有些访问是通过kvc来完成的,如果符号被替换了, kvc还是使用原来的字符串去访问就会造成闪退或者功能异常
3: 直接修改二进制-加固
你是否听到了熟悉的词语-"加固", 我们这行把直接修改二进制的方法喜欢叫成" 加固", 直接修改二进制,达到混淆的效果,也就是说我们直接最终编译的ipa中的可执行文件
举个例子, 比如我们正在考试.
1: 修改源代码的方式相当于,你勤勤恳恳的学习,然后提交试卷后,等待老师审查
2: 编译器的方式相当于, 你在考试的提交试卷的时候替换了别人的考卷,等到老师审查
3: iOS加固的方式相当于, 直接修改考试分数
我们简单的了解加固的概念后,进入正题:
难度指数:满级
优点:非常多,不需要关注源代码,不需要打开xcode, 你只需要给我一个ipa, 我返回给你一个ipa
我们先简单了解什么是二级制:
我们通过拆解ipa, 你往往会看到一个黑色的小盒子, 这就是一个可执行文件 ,我们简称二进制,当然这个文件不能直接打开或者双击执行

这个可执行文件的大小, 往往取决于你的代码量, 代码量越大, 这个文件越大,这个里面是什么东西呢?
机器码
没错这个二进制里面全是机器码,我们使用xxd命令查看最原始的内容

没错这个就是二进制的最原始的内容,但是这种机器码我们根本无法阅读,
汇编代码
这些原始的机器码(十六进制字节)正是由汇编代码(Assembly Code)转换(“汇编”)而来的。这个转换过程由汇编器(Assembler) 完成。
我们使用otool -tV 命令进行反汇编查看内容

是不是发现了一些带语义的符号了? 但是仍然难以阅读, 我们来翻编译更高级的语言
高级语言
反编译的目标是将机器码/汇编代码转换回更抽象、可读性更高的伪代码, 还需要一个解析的过程,不同语言所在二进制的位置不同, 解析方式也不同,这里不过多介绍, 我们直接来看解析后的结果
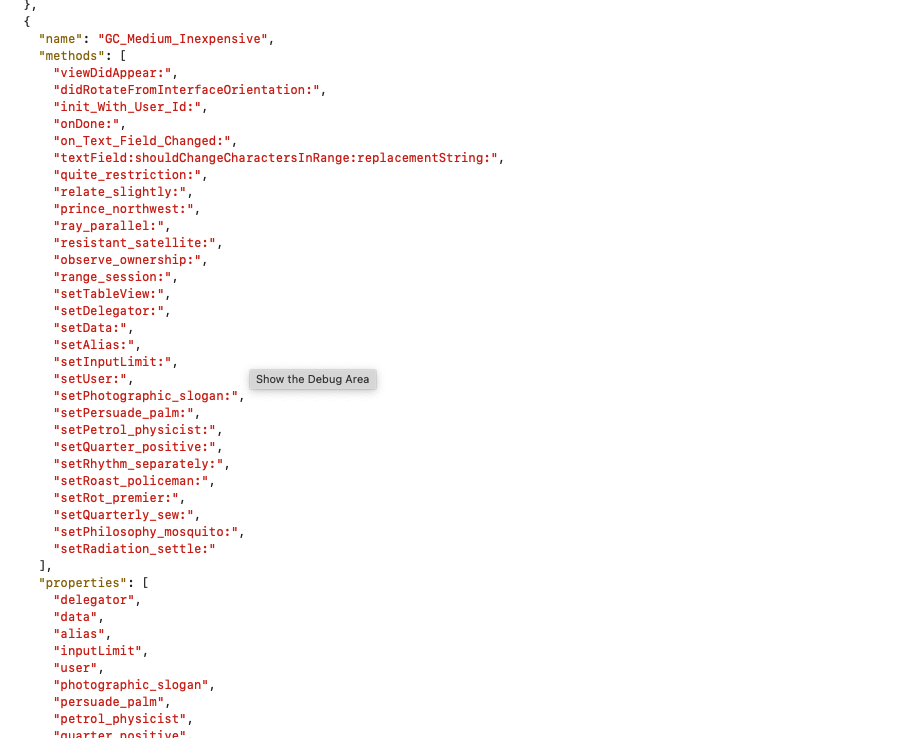
这个是不是就是你最熟悉的oc代码了?
它们的层级关系是:
高级语言 (C/C++/Swift) -> 编译器 -> 汇编代码 (Assembly) -> 汇编器 -> 机器码 (Machine Code)
我们继续关注二进制里面的结构,看看它内部是怎么划分的, 我们使用size-m 查看二进制的概览情况

我们发现内容非常多, 非常乱, 不过像我看多了就习惯了, 大致就是分为几个段, 段里面又被分成了各种小的节
三大段
1: __LINKEDIT (符号表主要存放位置)
2: __TEXT (代码主要存放位置)
3: __DATA (静态变量主要存放位置)
我们发现text段中的text节 占据了主要的体积 , 没错, 这就是你的源代码主要存放的位置, 我们加固重点就是处理这个text节
