SpringBoot整合Elasticsearch
SpringBoot整合Elasticsearch
依赖、配置
引入依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>yml配置:
server:port: 10002
spring:application:name: elasticsearch-demoelasticsearch:
#本地测试建议把elasticsearch服务配置的ssl关闭,直接通过http访问而不是httpsuris: http://127.0.0.1:9200socket-timeout: 10s
#如果elasticsearch开启了安全校验,配置了密码username: elasticpassword: 123456Elasticsearch在SpringBoot中的使用
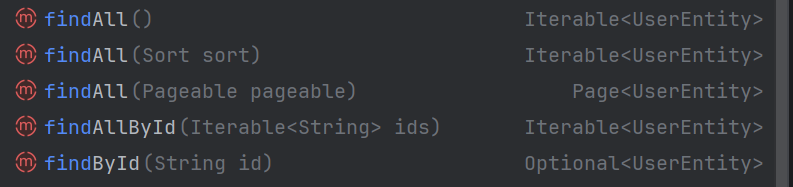
一、ElasticsearchRepository接口
ElasticsearchRepository接口同Spring Boot整合MongoDB的MongoRepository接口类似,里面定义了一些常用的增、查、删方法,同时也可以自定义方法遵循命名规则自动生成DSL语句
DSL:就是Elasticsearch特有的查询语言,遵循一些特有的格式,就类似于Mysql的Sql语句
预定义的一些常用方法:
![]()
![]()
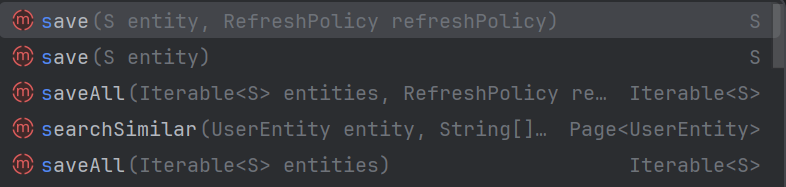
searchAimilar是用来进行相似文档搜索的方法
- entity: 要基于其查找相似文档的实体对象
- fields: 要在其中搜索相似内容的字段数组
- pageable: 分页信息(页码、页面大小等)
自定义方法自动生成DSL语句:
命名规则要点:
- 顺序很重要:参数按在方法名中出现的顺序匹配条件
- 属性名称:要和实体类里面定义的属性名一致
- 条件可组合:多个条件可以用 And/Or 连接
- 大小写敏感:关键词首字母大写,属性名遵循驼峰命名
- 返回类型灵活:根据业务需求选择合适的返回类型
- 嵌套属性:使用点号访问嵌套对象属性,如 findByAddressCity
这套命名规范可以满足大部分查询需求,对于复杂查询可以结合 @Query 注解使用自定义查询语句。
方法名结构:[前缀]By[属性名][条件][连接词][属性名][条件]
- 常用前缀

- 常用条件关键词
比较操作
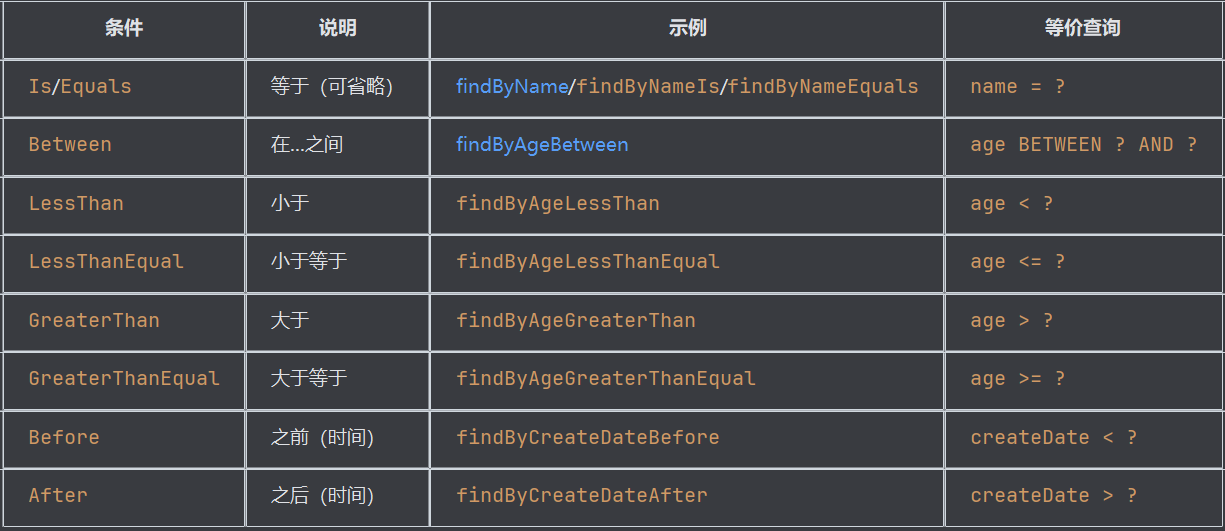
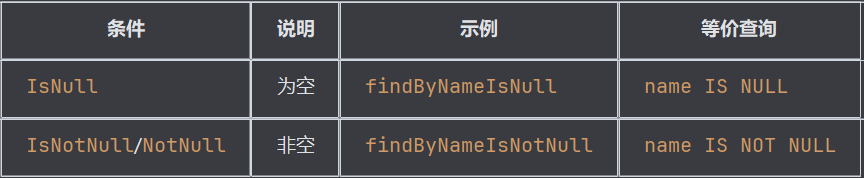
空值检查
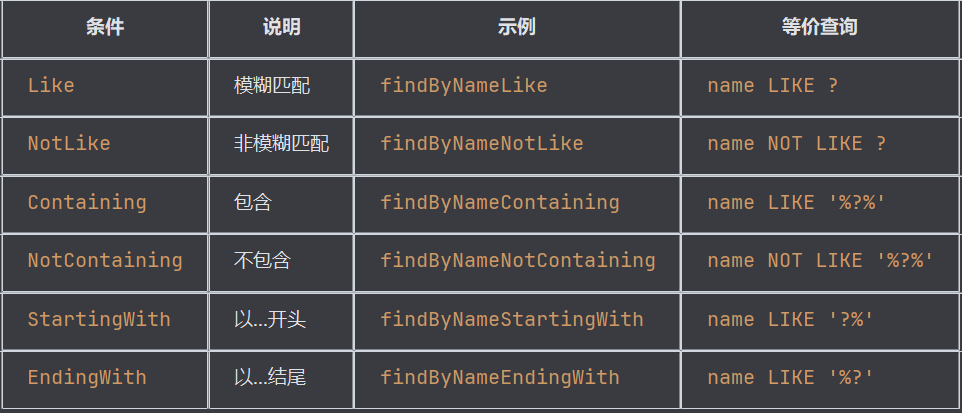
字符串操作
集合操作

布尔操作
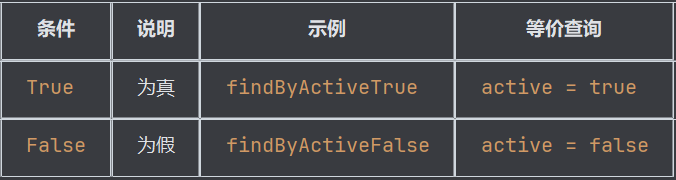
其他操作

- 常用连接词

- 排序和限制关键词
限制结果数量
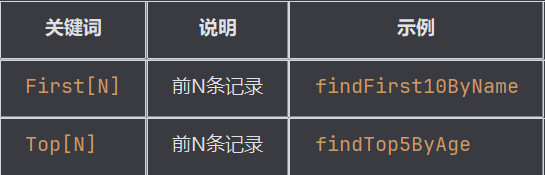
排序

示例:
public interface UserRepository extends ElasticsearchRepository<UserEntity, String> {// 基本查询List<UserEntity> findByName(String name);List<UserEntity> findByAge(Integer age);// 范围查询List<UserEntity> findByAgeBetween(Integer start, Integer end);List<UserEntity> findByAgeLessThan(Integer age);List<UserEntity> findByCreateDateBefore(Date date);// 字符串查询List<UserEntity> findByNameContaining(String name);List<UserEntity> findByNameStartingWith(String prefix);List<UserEntity> findByNameContainingIgnoreCase(String name);// 多条件查询List<UserEntity> findByNameAndAge(String name, Integer age);List<UserEntity> findByNameOrEmail(String name, String email);// 集合查询List<UserEntity> findByAgeIn(List<Integer> ages);List<UserEntity> findByAgeNotIn(List<Integer> ages);// 空值检查List<UserEntity> findByNameIsNull();List<UserEntity> findByNameIsNotNull();// 布尔查询List<UserEntity> findByActiveTrue();List<UserEntity> findByActiveFalse();// 否定查询List<UserEntity> findByNameNot(String name);List<UserEntity> findByNameNotLike(String name);// 排序和限制List<UserEntity> findFirst10ByName(String name);List<UserEntity> findTop5ByAgeOrderByCreateDateDesc(Integer age);List<UserEntity> findByNameOrderByAgeAsc(String name);// 统计方法long countByName(String name);long countByAgeGreaterThan(Integer age);boolean existsByName(String name);// 删除方法long deleteByName(String name);void removeByName(String name);List<UserEntity> deleteByAgeLessThan(Integer age);
}
注意:ElasticsearchRepository里面定义的方法返回类型对象不能用Map<String,Object>,必须使用对应的文档实体:
错误写法:
@Service
public interface UserRepository extends ElasticsearchRepository<UserEntity, String> {List<Map<String, Object>> findByName(String name);
}
@Query
@Query 注解在 Spring Data Elasticsearch 中的主要作用是允许开发者自定义 Elasticsearch 查询语句,绕过方法名派生查询的限制,提供更灵活和强大的查询能力。
例如:
@Service
public interface UserRepository extends ElasticsearchRepository<UserEntity, String> {@Query("{\"match\":{\"name\":\"?0\"}}")List<UserEntity> findByQuery(String name);}
?0, ?1, ?2... 就类似于占位符表示第1个、第2个、第3个参数
当然我们也可以用@Param注解来实现参数匹配
@Query("{\"match\":{\"name\":\":name\"}}")
List<UserEntity> findByQuery(@Param("name") String name);二、ElasticsearchTemplate核心类
添加/更新文档
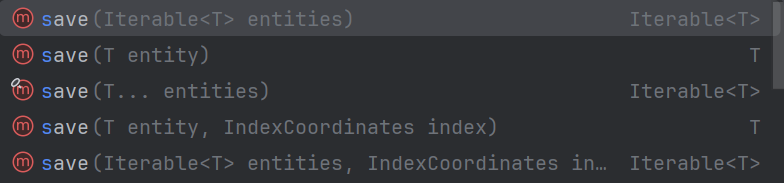
save():保存或更新文档,如果文档 ID 不存在则创建,如果存在则更新(全量替换)
特点:
- 全量更新:会替换整个文档内容
- 幂等操作:多次执行相同操作结果一致
- 自动创建索引:如果索引不存在会自动创建
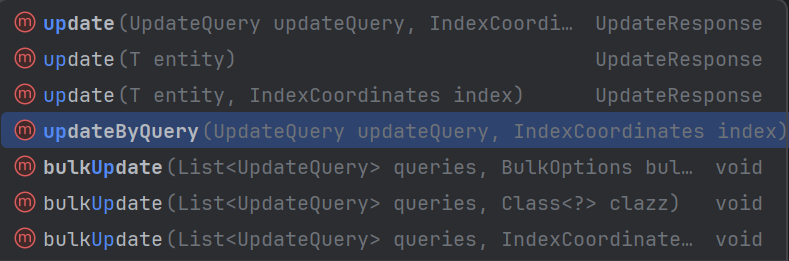
update():部分更新文档:只更新指定的字段,其他字段保持不变,局部更新,只修改指定字段
blukUpdate():批量更新操作,单个操作失败不影响其他操作
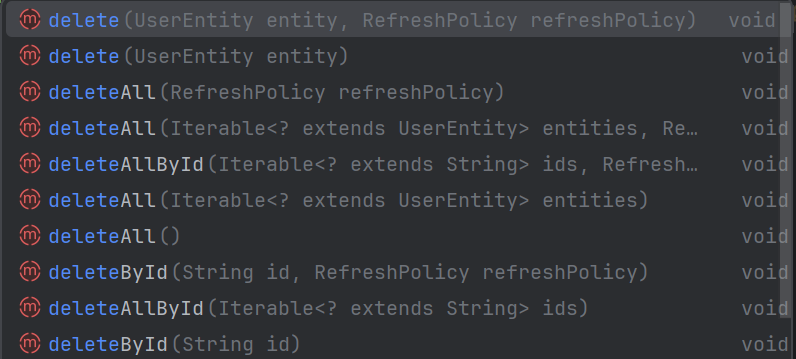
删除文档
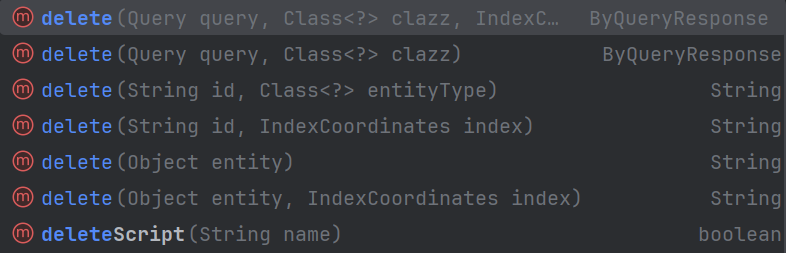
动态分页查询文档
定义一个user文档实体
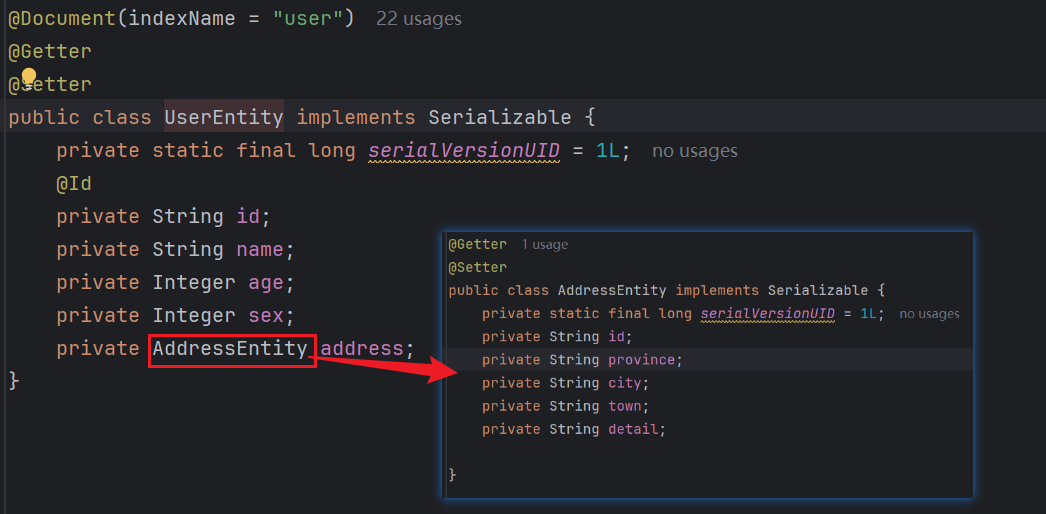
查询实体:
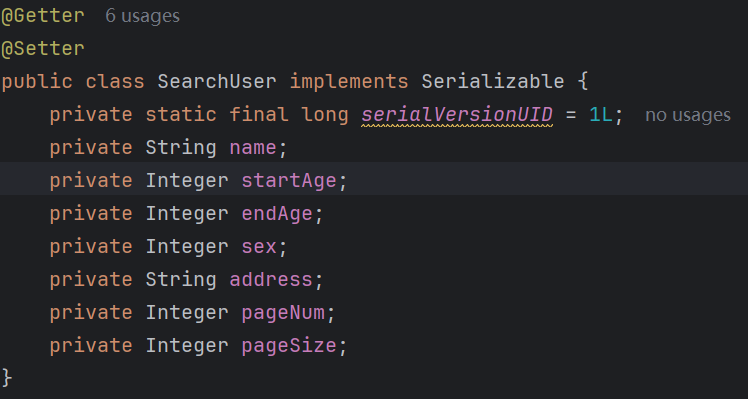
动态查询示例:这里的示例包括注释掉的可以含概大部分的查询需求
public PageResponse<UserEntity> pageQuery(SearchUser user) {Query.Builder builder = new Query.Builder();//模糊查询if (user.getName() != null){//左右模糊builder.wildcard(QueryBuilders.wildcard().field("name").wildcard("*" + user.getName() + "*").build());//前缀匹配查询//builder.prefix(QueryBuilders.prefix().field("name").value(user.getName()).build());//正则表达式//builder.regexp(QueryBuilders.regexp().field("name").value(".*" + user.getName() + ".*").build());}//词项级查询,可以说是等值查询,匹配字段的值必须完全匹配输入的文本if (user.getSex() != null){builder.term(QueryBuilders.term().field("sex").value(user.getSex()).build());}//RangeQuery.Builder ageRange = new RangeQuery.Builder().field("age");//范围查询 使用gte lte 或者 from toif (user.getStartAge() != null){builder.range(QueryBuilders.range().field("age").gte(JsonData.of(user.getStartAge())).build());//或者//builder.range(QueryBuilders.range().field("age").from(String.valueOf(user.getStartAge())).build());}if (user.getEndAge() != null){builder.range(QueryBuilders.range().field("age").lte(JsonData.of(user.getEndAge())).build());//或者//builder.range(QueryBuilders.range().field("age").to(String.valueOf(user.getEndAge())).build());}// 全文查询 默认会将输入文本进行分词处理,然后进行匹配,不同的分词器分词也不同if(user.getAddress() != null){//多字段匹配查询,模糊匹配, 在用户文档的地址相关字段中搜索用户输入的地址关键词,只要任何一个字段包含该关键词,该用户文档就会被匹配到builder.multiMatch(QueryBuilders.multiMatch().fields(List.of("address.province","address.city","address.town","address.detail")).query(user.getAddress()).type(TextQueryType.CrossFields) //类型:BestFields(默认),BestMatch,MostFields,CrossFields,Phrase,BoolPrefix.build());//match最基本的全文查询 operator表示匹配逻辑,默认是OR,表示匹配任意一个字段,可以设置为AND表示必须匹配所有字段//builder.match(QueryBuilders.match().field("address.detail").query(user.getAddress()).operator(Operator.And).build());//match_phrase 精确匹配//builder.matchPhrase(QueryBuilders.matchPhrase().field("address.detail").query(user.getAddress()).build());//match_phrase_prefix 匹配前缀//builder.matchPhrasePrefix(QueryBuilders.matchPhrasePrefix().field("address.detail").query(user.getAddress()).build());}Pageable pageable = Pageable.ofSize(user.getPageSize()).withPage(user.getPageNum() - 1);Query query = builder.build();NativeQueryBuilder queryBuilder = NativeQuery.builder();if (query._kind() != null){queryBuilder.withQuery( query);}NativeQuery nativeQuery = queryBuilder.withPageable(pageable).withMinScore(1.0f) // 设置最小得分阈值.build();SearchHits<UserEntity> search = elasticsearchTemplate.search(nativeQuery, UserEntity.class);PageResponse<UserEntity> pageResponse = new PageResponse<>();pageResponse.setTotal(search.getTotalHits());search.getSearchHits().forEach(searchHit -> {System.out.println(searchHit.getId() + ": "+searchHit.getScore());});pageResponse.setItems(search.getSearchHits().stream().map(SearchHit::getContent).toList());pageResponse.setPageNum(user.getPageNum());pageResponse.setPageSize(user.getPageSize());return pageResponse;}重点讲一下多字段匹配查询multi_match
多字段匹配查询, 在文档的字段列表中搜索用户输入的关键词,只要字段列表里的任何一个字段包含该关键词,该文档就会被匹配到,但是注意用户输入会被分词后再进行匹配,比如用户输入’贵州‘,可能会被分词成’贵‘和’州‘,所以地址里面只要包含’贵‘和’州‘的都会被匹配到,当然每个文档的得分情况不一样,默认是按得分的降序返回结果,相似度越高,得分越高。不同的type,计算得分点方式也不一样,根据不同业务类型选择合适的type.
TextQueryType 枚举值
best_fields(默认值)
特点:
- 在每个字段上单独执行 match 查询
- 适用于希望在多个字段中找到最佳匹配的场景
- 返回得分最高的字段的得分
使用场景:
- 商品搜索(名称、描述字段)
- 用户搜索(姓名、昵称字段)
most_fields
特点:
- 在所有字段上执行 match 查询
- 适用于需要在多个字段中都匹配到内容的场景
- 将所有字段的得分相加
使用场景:
- 复制字段策略(将内容复制到多个字段以提高召回率)
- 需要多个字段都匹配的场景
cross_fields
特点:
- 将所有字段视为一个大的字段
- 适用于跨字段搜索场景
- 先对所有字段进行分析,然后在所有字段中搜索每个词
使用场景:
- 人名搜索(姓、名分别存储在不同字段)
- 地址搜索(省、市、区分别存储)
phrase
特点:
- 在每个字段上执行 match_phrase 查询
- 相当于在每个字段上执行短语查询
- 要求词语按顺序完整匹配
使用场景:
- 需要精确短语匹配的场景
- 标题或名称的精确匹配
phrase_prefix
特点:
- 在每个字段上执行 match_phrase_prefix 查询
- 适用于自动补全场景
- 最后一个词可以是前缀匹配
使用场景:
- 搜索建议和自动补全
- 前缀匹配搜索
bool_prefix
特点:
- 在每个字段上执行 match_bool_prefix 查询
- 提供更好的性能和相关性
- 将查询文本分析为布尔查询,最后一个词作为前缀
使用场景:
- 高性能的前缀搜索
- 复杂的布尔查询场景
结果示例:
请求体:
{"pageNum":1,"pageSize":10,"address":"于都"
}响应结果:
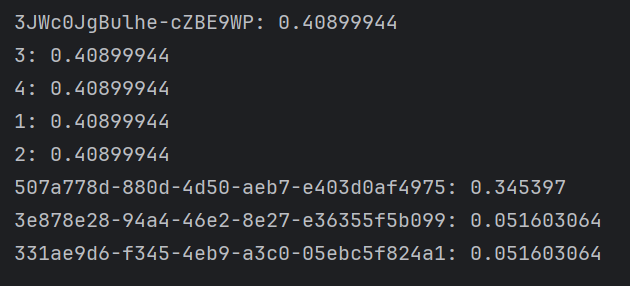
{"pageNum": 1,"pageSize": 10,"total": 8,"items": [{"id": "3JWc0JgBulhe-cZBE9WP","name": "yzz","age": 30,"sex": 1,"address": {"id": null,"province": null,"city": "赣州","town": "于都","detail": null}},{"id": "3","name": "yzz","age": 30,"sex": 1,"address": {"id": null,"province": null,"city": "赣州","town": "于都","detail": null}},{"id": "4","name": "yzz","age": 30,"sex": 1,"address": {"id": null,"province": null,"city": "赣州","town": "于都","detail": null}},{"id": "1","name": "ddd","age": 19,"sex": 1,"address": {"id": null,"province": null,"city": "赣州","town": "于都","detail": null}},{"id": "2","name": "ddd","age": 19,"sex": 1,"address": {"id": null,"province": null,"city": "赣州","town": "于都","detail": null}},{"id": "507a778d-880d-4d50-aeb7-e403d0af4975","name": "小米","age": 19,"sex": 1,"address": {"id": "1","province": "江西省","city": "赣州市","town": "于都县","detail": "银坑镇洋黅村"}},{"id": "3e878e28-94a4-46e2-8e27-e36355f5b099","name": "小白","age": 19,"sex": 1,"address": {"id": "1","province": "江西省","city": "赣州市","town": "宁都县","detail": "歌奥"}},{"id": "331ae9d6-f345-4eb9-a3c0-05ebc5f824a1","name": "小才","age": 20,"sex": 1,"address": {"id": "1","province": "贵州省","city": "详细市","town": "宁都县","detail": "歌奥"}}]
}
对应的得分情况: