[论文阅读]RQ-RAG: Learning to Refine Queries for Retrieval Augmented Generation
RQ-RAG: Learning to Refine Queries for Retrieval Augmented Generation
[2404.00610] RQ-RAG: Learning to Refine Queries for Retrieval Augmented Generation
现有的 RAG 实现主要集中在用于上下文检索的初始输入,忽略了模棱两可或复杂查询的细微差别,这些查询需要进一步澄清或分解以获得准确的响应。 为此,本文提出学习改进查询以用于检索增强生成 (RQ-RAG),旨在通过为模型配备显式重写、分解和消歧的能力来增强模型。
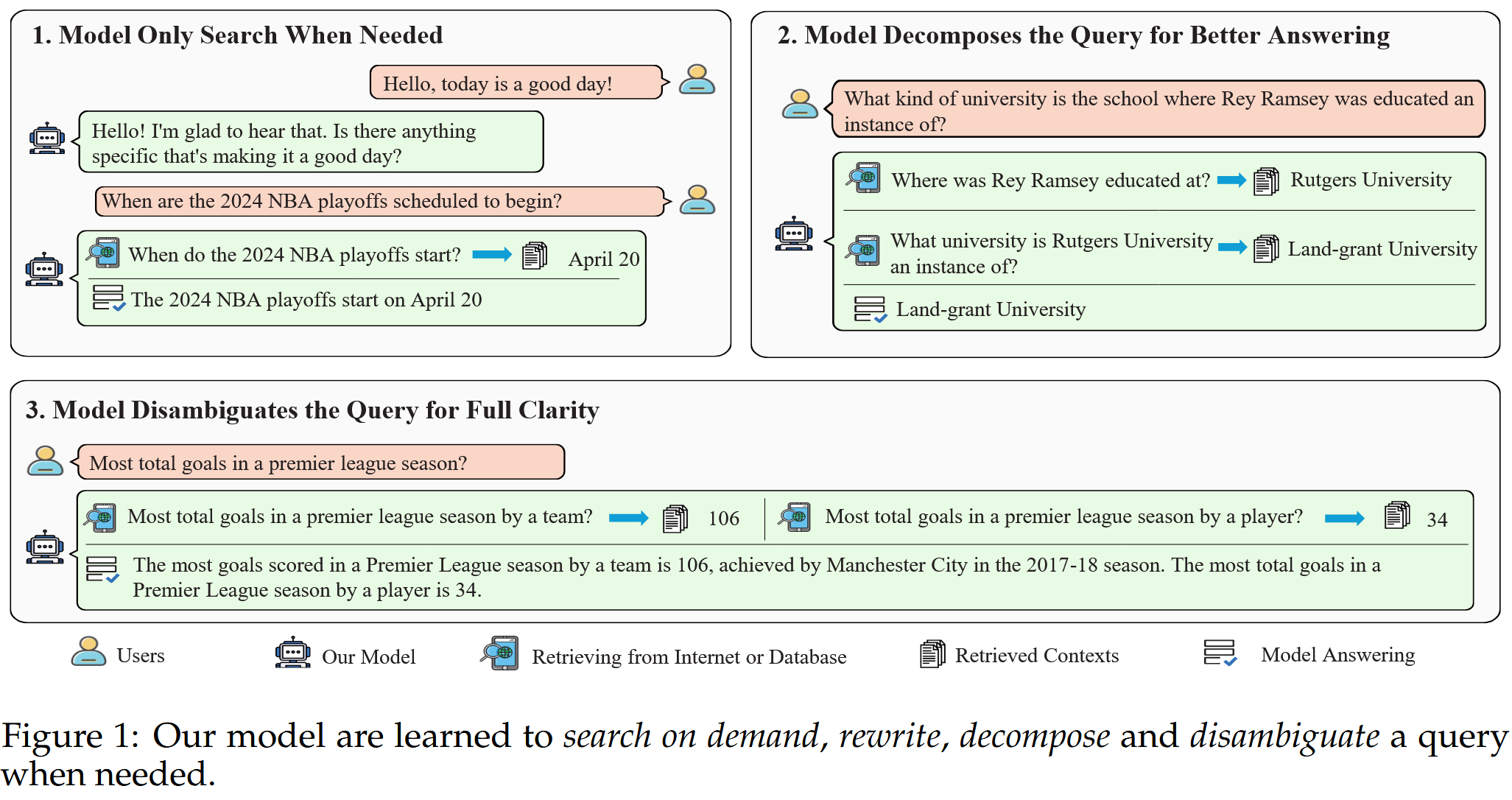
无脑整合RAG导致的问题:不相关的上下文降低生成质量,甚至阻碍LLM回答它们原本能够回答问题的能力;对于简单的查询类似日常问候等,应该直接回复,此时整合上下文十分不必要。因此,模型应该学会按需搜索(图1左上角场景)。
对于复杂查询,只用原始查询及逆行搜索通常无法检索到足够的信息,对于LLM来说,首先把这些查询分解为更加简单,可回答的子查询,然后搜索与这些子问题相关的信息,这个路径会更加具有可解释性并且回答结果更加准确。通过整合对这些子查询的响应,LLM 可以构建对原始复杂查询的全面答案。(图1右上角)
对于具有多个可能答案的模糊查询,使用原始查询进行信息检索是不够的。 为了提供完整和细致的响应,LLM 必须学会澄清查询,理想情况下是通过识别用户的意图,然后制定更具针对性的搜索查询。 收集到相关信息后,LLM 就可以提供详细且全面的回复(图1下)
具体措施:端到端方式训练大模型,使其能够通过改写、分解和澄清歧义来动态地精炼搜索查询。
RQ-RAG
训练数据集的构建
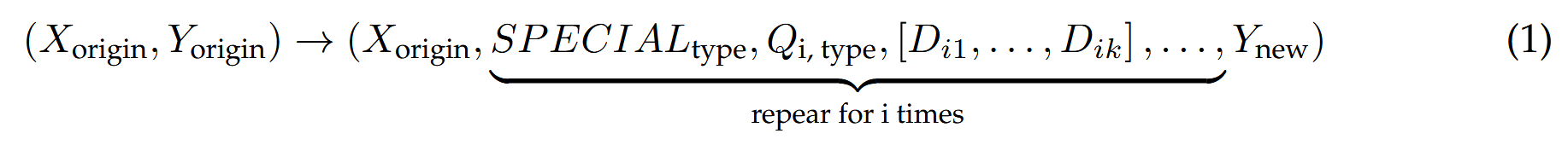
给定原始数据集中的一个输入-输出对 (Xorigin,Yorigin),主要目标是构建包含特殊token的动作序列。 这些特殊符元指定了细化的类型 SPECIAL_type,并后跟细化的查询,以特定特殊符元为条件,表示为 Q_{i, type},其中“type”指的是细化操作(重写、分解或消歧),而“i”指的是迭代的轮次。 随后检索前 k 个文档,表示为 [Di1,Di2,…,Dik]。 在最后的迭代步骤中,根据上面表示为 Y_new 的上下文生成一个新的答案。
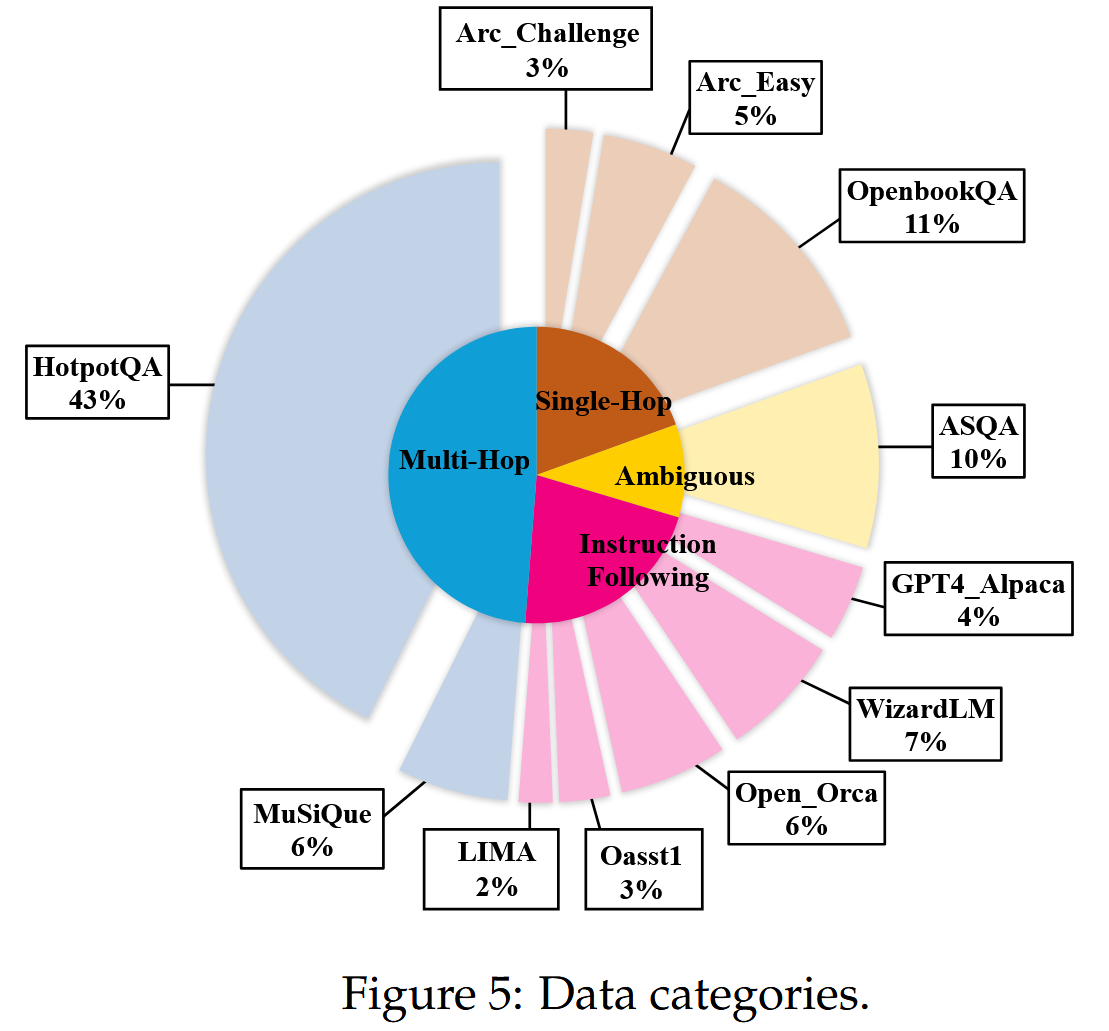
数据主要包含单跳问答任务,包括 Arc-Easy/Arc-Challenge (Clark 等人,2018)、OpenbookQA (Mihaylov 等人,2018),多跳问答任务,包括 HotpotQA (Yang 等人,2018)、Musique (Trivedi 等人,2022),模糊任务,包括 ASQA (Stelmakh 等人,2022),为了使模型具备通用能力,还添加了指令遵循任务,包括 LIMA (Zhou 等人,2024)、WizardLM (Xu 等人,2023b)、Open-Orca (Mukherjee 等人,2023)、OpenAssistant (Köpf 等人,2024)、GPT4-Alpaca (Taori 等人,2023)。 总\收集了 42810 个实例。
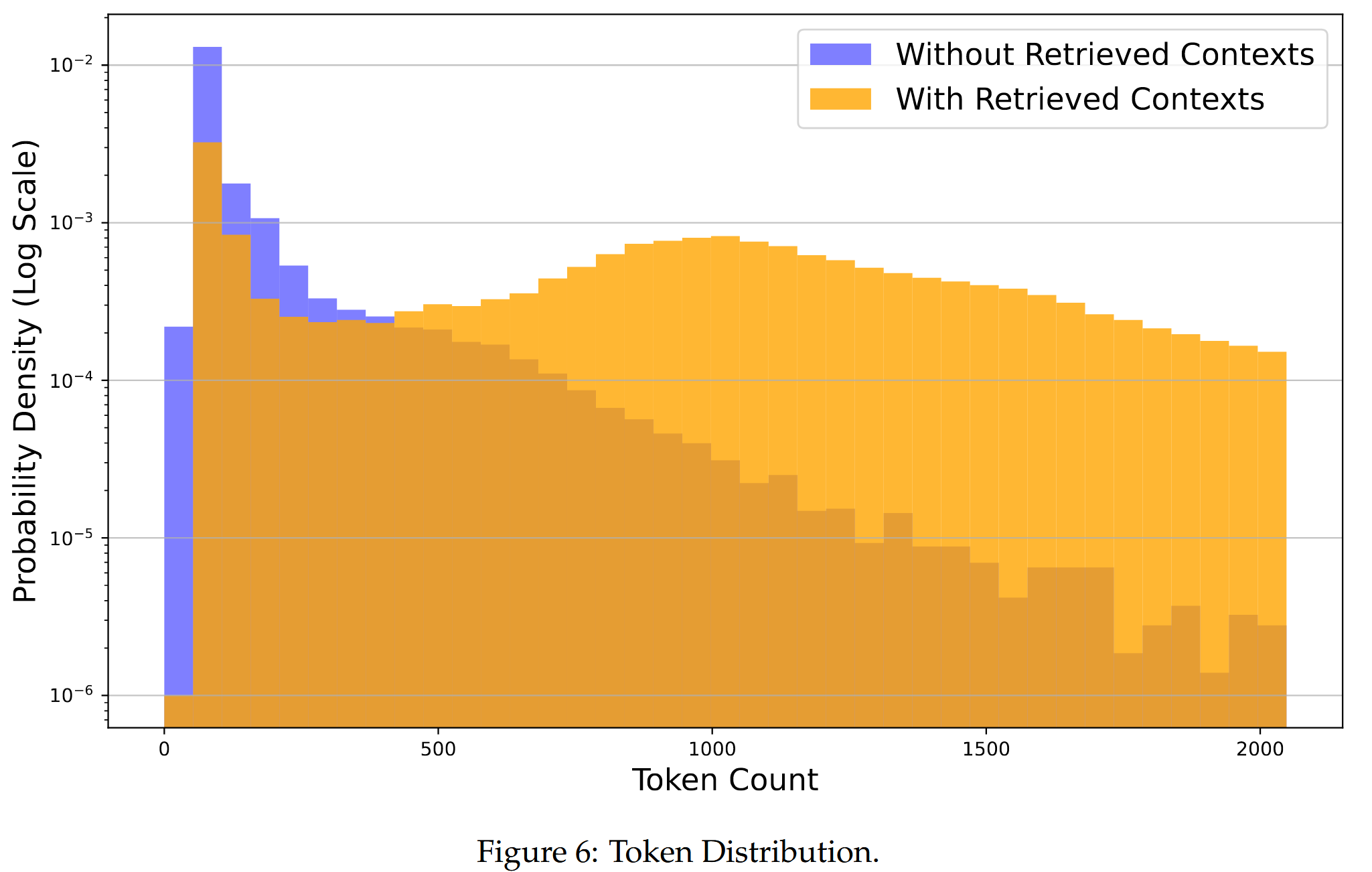
搜索增强显著改变了概率密度下的符元分布。 增强的 dataset 显示出符元数量的显著增长,其中大多数实例的符元数量介于 150 到 2000 之间。 相反,原始数据集的长度明显更短,大多数条目在 200 个符元以下。
把上面提到的多种任务合并后,建立一个任务池,按照公式1中的流程进行转换。按理来说需要人工参与来完善查询,但是过于耗时、耗费资源,因此用CHATGPT来自动执行标注。
使用 gpt-3.5-turbo-0125 用于数据标注,将温度参数设置为 0 以增强复现性。出现拒绝回答以及无法遵循指定输出格式的都被抛弃掉。



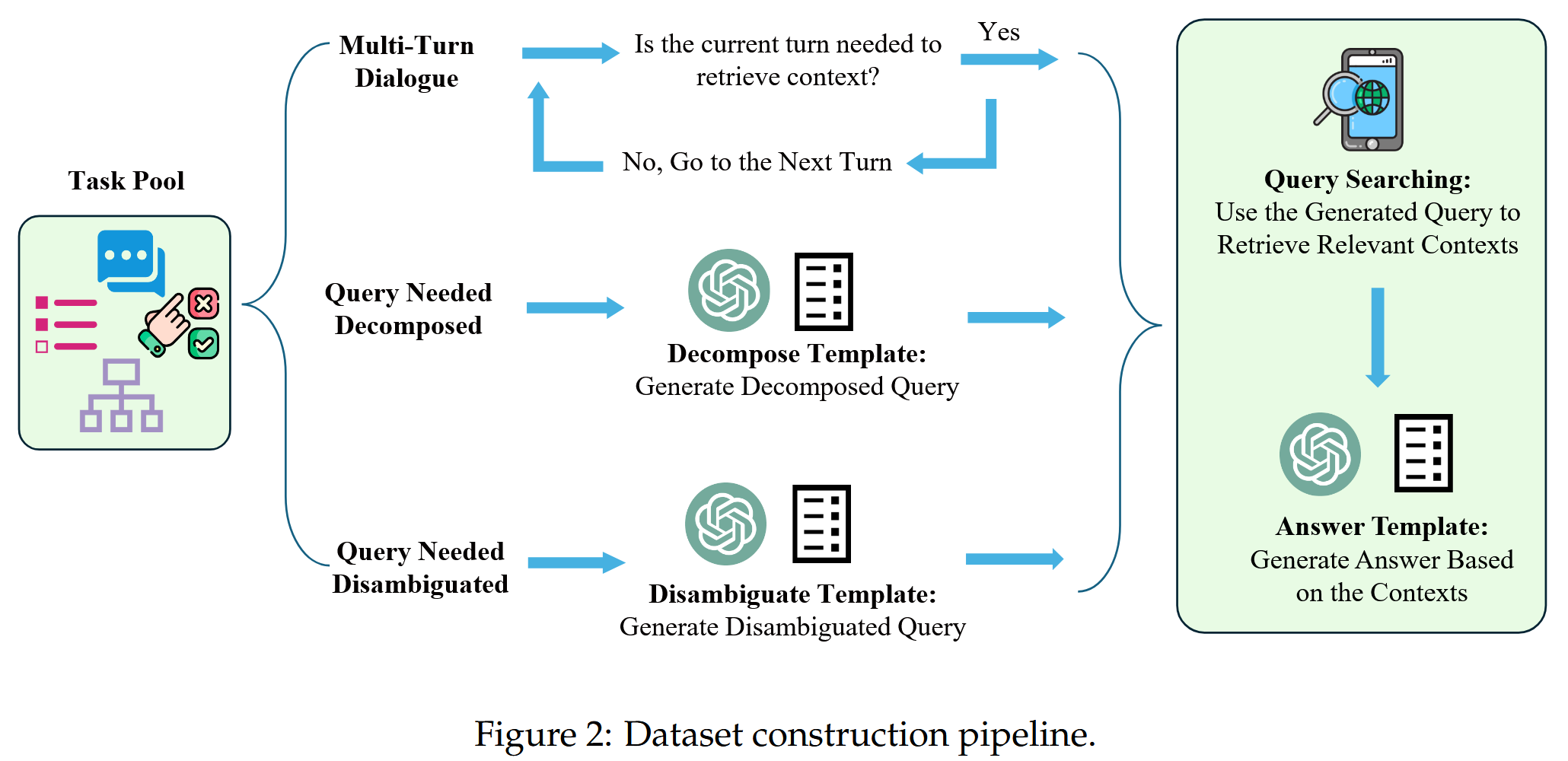
如图2,自动化标注包含以下三个阶段:
- 从将收集池中的任务分类到前面提到的三类中开始。 此步骤很简单,因为每个数据集都对应于特定的数据类型。
- 对于每种数据集类型,最初使用 ChatGPT 和预定义的提示模板来生成一个完善的查询。 然后使用此查询从外部数据源中搜索信息。 在大多数情况下,主要使用 DuckDuckGo,并将检索过程视为黑盒。
- 之后提示 ChatGPT 根据完善的查询及其相应的上下文生成新的响应。 通过重复此过程,总共积累了大约 40,000 个实例。
生成器训练
自回归方式训练 LLM
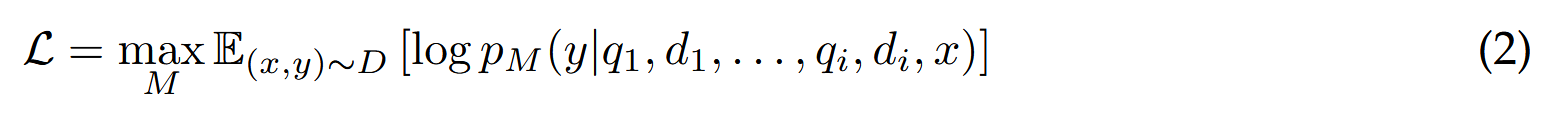
最大化给定输入 x 和经过细化的查询 qi 以及检索到的文档 di 的情况下生成响应 y 的概率的对数的期望。
采样策略
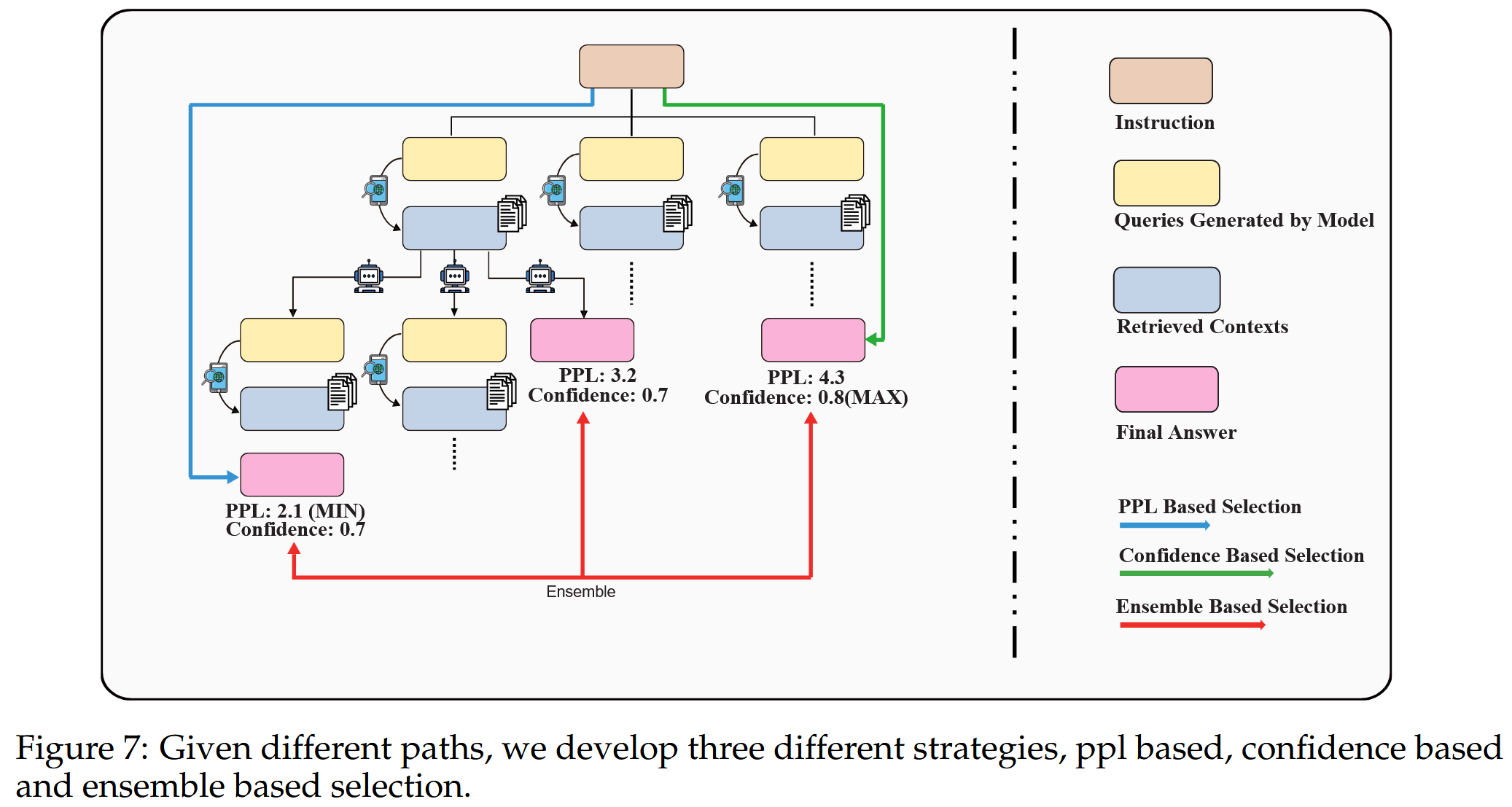
在每个时间步模型可以选择重写、分解或消解给定的查询,也可以选择直接生成响应。作者针对不同的查询细化方法设计了树解码策略。 但是使用不同的查询进行搜索会得到不同的检索上下文,从而导致不同的最终答案。 也就是说,如何在这些轨迹中采样最合适的路径是系统中的一个关键部分。 因此提出了三种不同类型的采样策略,如下所示:
使用 p_M 来表示具有参数 M 的语言模型,并且使用 [R1,R2,…,Rn] 来表示 n 条轨迹,其中每条轨迹包含一个序列列表,该序列列表表示为 [X,Y]。 这里,X 是输入提示,Y 是 Z1,…,Zi 的 i 个中间步骤(每个 Zi 是查询和检索上下文的组合)和最终答案 Yfinal 的串联。
基于困惑度:选择总生成输出PPL最低的轨迹
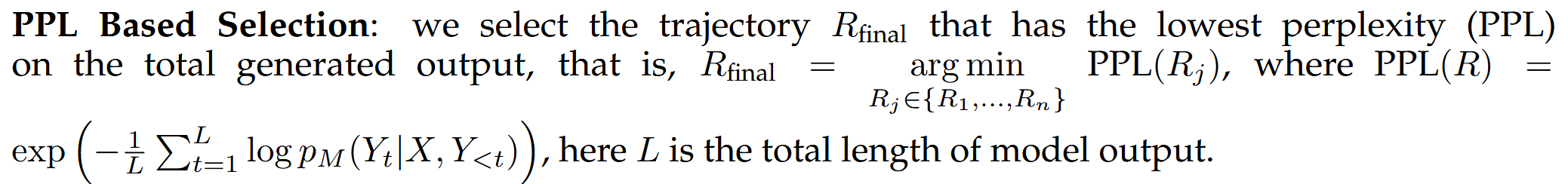
基于置信度:选择对最终答案Yfinal具有最高置信度的轨迹Rfinal(将其与基于PPL的选择区分开来,后者评估生成的总输出)

基于集成的选择:选择累积置信度得分最高的最终结果来集成最终结果
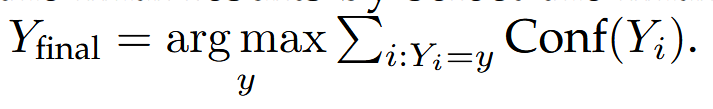
上限:定义了系统的上限,这意味着如果任何一个轨迹导致正确答案,那么就认为它是正确的
实验
评估任务
使用数据集:
对于单跳QA:Arc-Challenge包含 1172 个四选一 QA 实例使用准确率来衡量模型性能;PopQA专注于 1399 个实例的长尾子集,并采用匹配得分指标来评估模型输出是否包含基本事实;OpenbookQA包含 500 个四选一 QA 实例,使用准确率来衡量模型性能。
对于多跳QA:使用F1分数
检索器设置:
数据整理过程中主要使用 DuckDuckGo 来收集大多数场景的相关上下文,并选择前 3 个文档。 每个结果都包含标题、预览摘要和网页的 URL。 为了简化流程只使用标题和预览文本,而不会进一步抓取 URL。 对于多跳 QA 任务,利用 BM25 从特定数据集提供的候选文档中提取上下文,并丢弃上下文与支持文档不一致的实例。
在单跳 QA 任务的推理过程中标准方法是从 DuckDuckGo 检索三个上下文。 对于多跳 QA 场景利用 text-embedding-3-large 模型 (OpenAI) 来识别每一步中来自候选文档的三个最相关的上下文。
基线
无检索基线,它们在不使用从外部数据库检索到的上下文的的情况下回答问题
有检索基线,它们首先从外部来源检索相关上下文,然后根据这些上下文进行回答。
比较包括 Llama2-7B 和 Llama2-7B-Chat的零样本配置以及这些模型在特定任务数据集(例如,ARC_C 和 OBQA 用于单跳 QA 任务,需要注意的是,POPQA 缺乏训练集,因此无法在此数据集上进行训练,而 HOTPOTQA、2WIKI 和 MUSIQUE 用于多跳 QA 任务)和 作者精心制作的数据集(没有中间步骤)上进行了微调,作为更稳健的基线。
评估了 SAIL-7B(Luo et al.,, 2023) 和之前建立的最新技术 Self-RAG-7B(Asai et al.,, 2024) 在三个单跳 QA 数据集上的表现。 对于多跳 QA 任务,扩展到 思维链(Wei et al.,, 2022) 和 笔记链 (Yu et al.,, 2023),利用 ChatGPT 和 GPT-4 作为底层语言模型。
实验结果
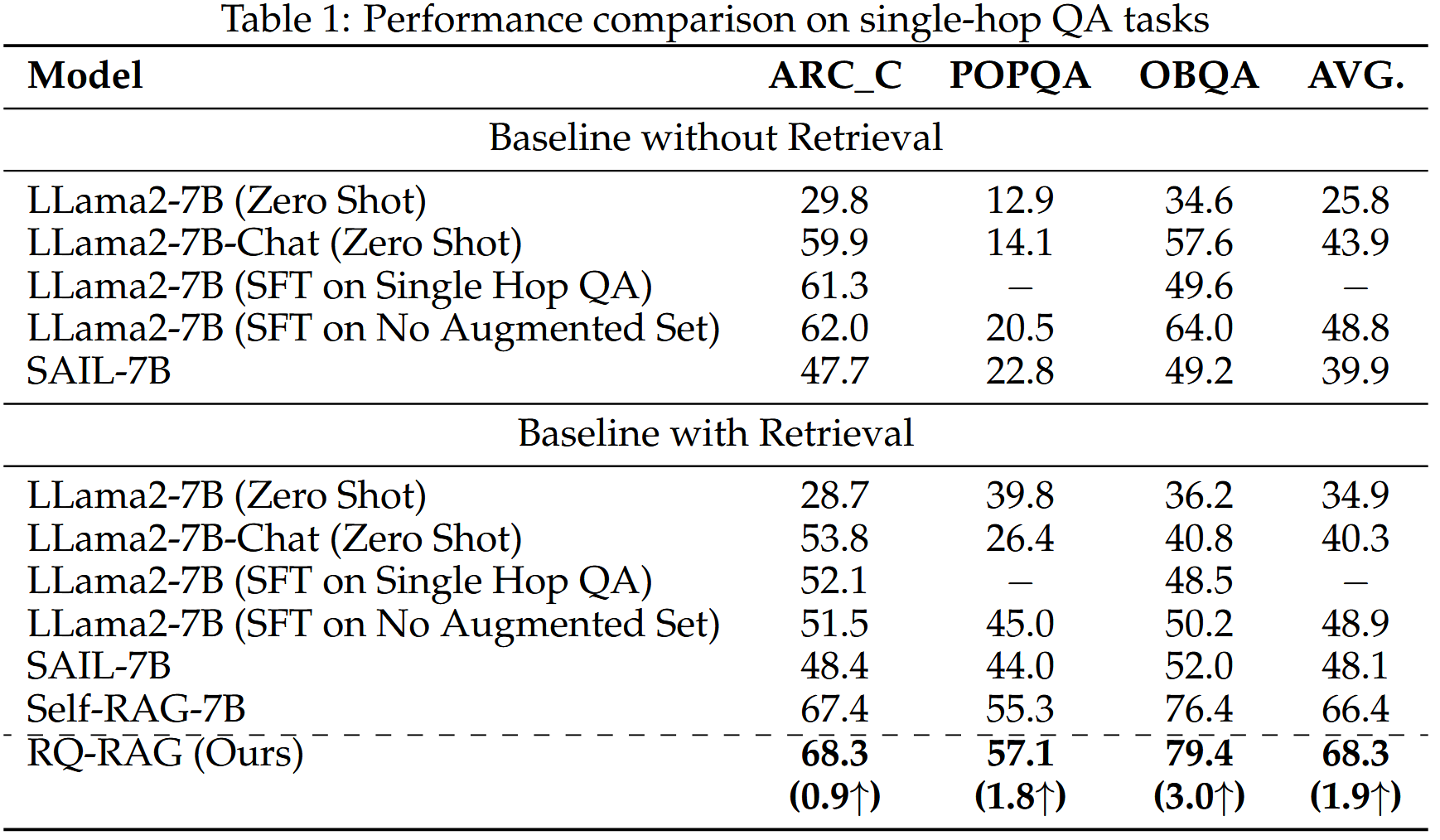
RQ-RAG 在单跳 QA 任务中优于 Self-RAG 和 SAIL
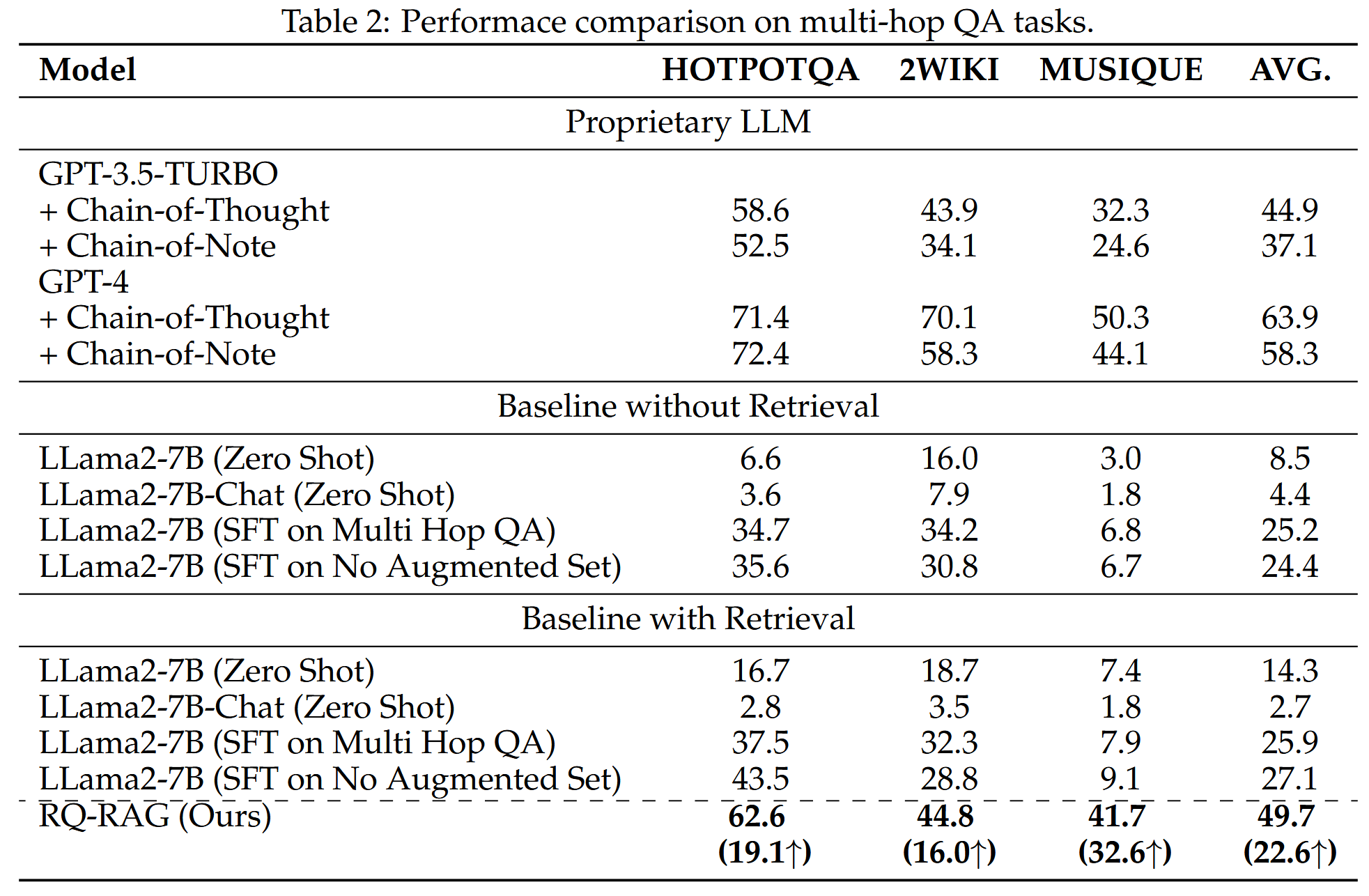
RQ-RAG 在多跳问答数据集上表现出优越的性能
即使RQ-RAG的最终结果不如GPT4,但是考虑到它是对LLama2-7B进行的微调,效果只比增强后的gpt4稍逊一筹,足以体现其强势性。
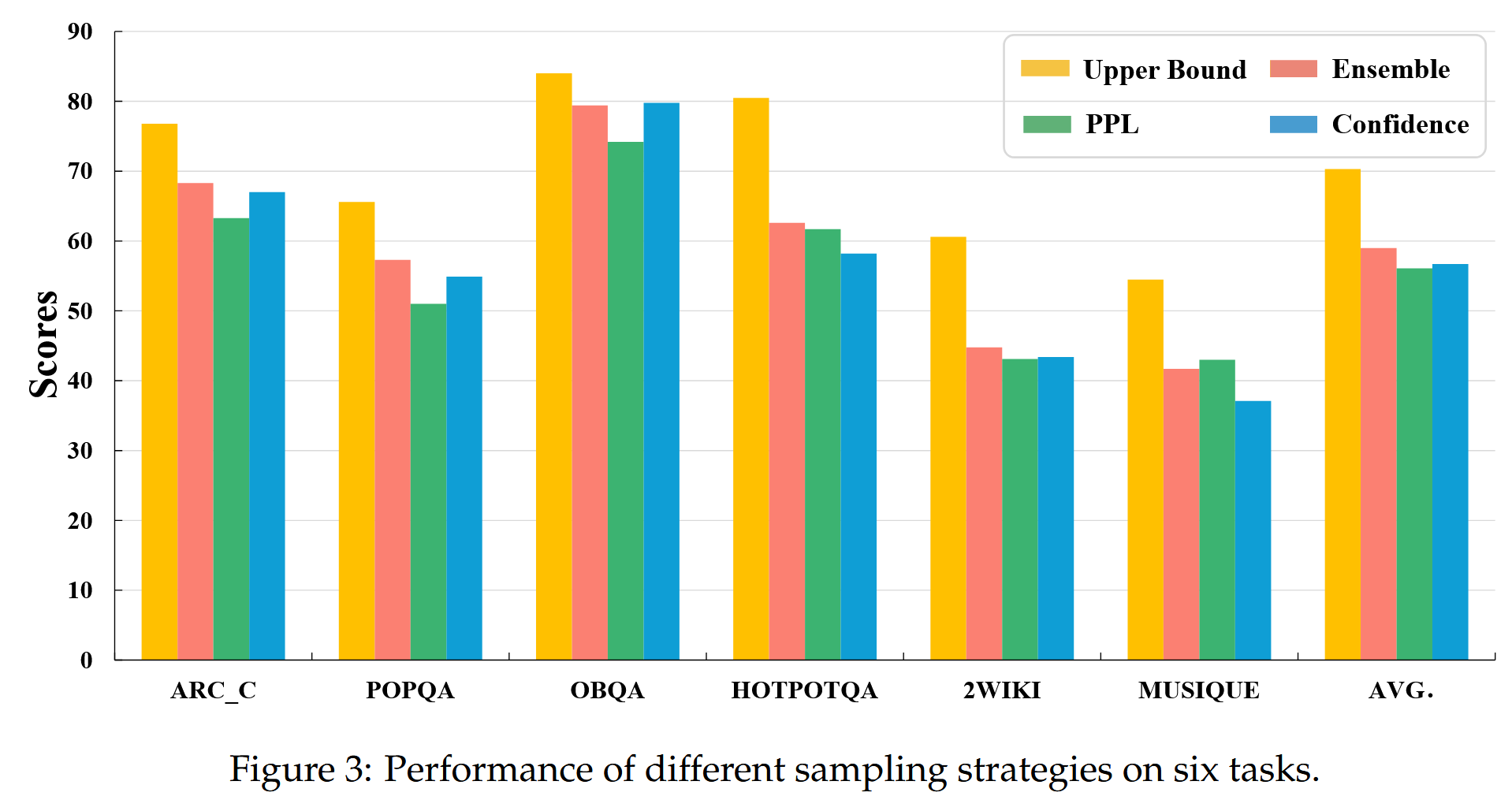
RQ-RAG展示了系统的高上限
对于单跳问答任务,基于置信度的策略通常表现出色,而对于多跳问答任务,基于集成的策略表现出优越的性能。基于 ppl 的策略表现出中等性能。
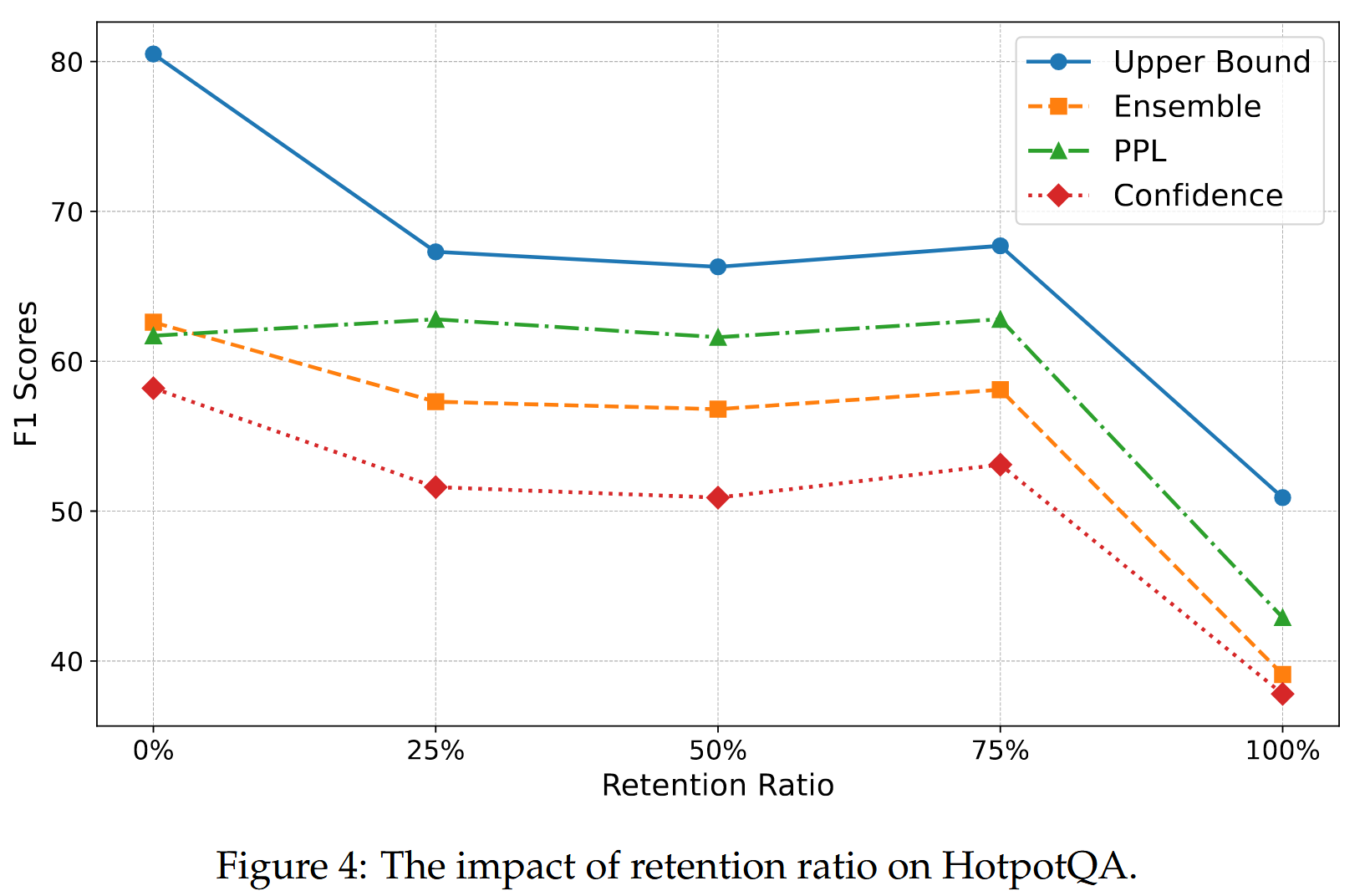
基于上下文重新生成答案很重要
方法的一个关键创新是使用 ChatGPT 基于提供的上下文重新生成答案,而不是依赖数据集中的原始答案。探讨了改变从数据集中保留的原始答案比例的影响。 为了确保公平的比较,我们在实验中保持一致的训练超参数。 我们通过保留 0%(我们的主要方法)、25%、50%、75% 和 100% 的原始答案来策划我们的搜索增强数据集,然后评估了对三个多跳 QA 数据集性能的影响。 图4 说明了我们在 HotpotQA 上的发现,完全重新生成的答案设置(0% 保留)显示了最佳性能。 此外,随着保留的原始答案比例的增加,有效性明显下降,这表明我们基于检索到的上下文重新生成答案的策略是有益的。
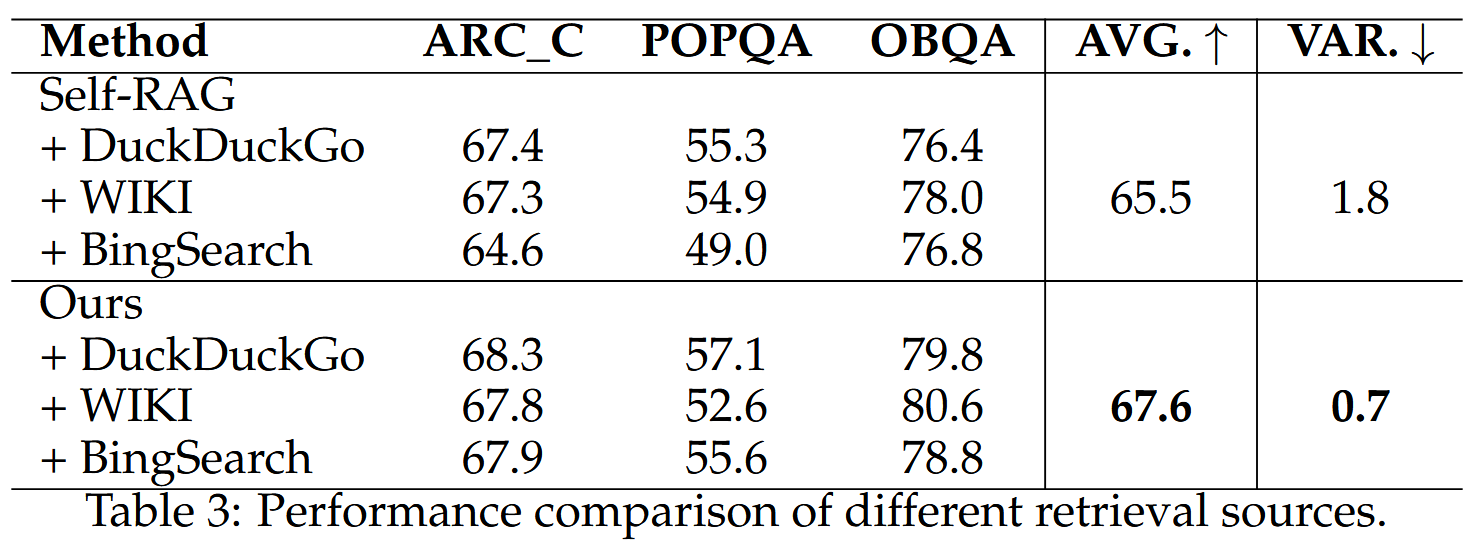
系统对不同的数据资源具有弹性
在推理期间分别使用 DuckDuckGo、维基百科和必应搜索作为数据源,结果就是表3所示,文章提出的RQ-RAG更加稳定。
【这篇文章还是很有意义很有意思的,数据集开源于zorowin123/rq_rag · Datasets at Hugging Face,通过数据集可以看到作者新构造了一些token,比如[S_Decomposed_Query],[/R_Evidences],[A_Response],[S_Disambiguated_Query],[S_Response]通过这些token来标榜作者划分的三种不同场景的问题形式,使用训练来让llama2学习到这三种不同的场景。不过system prompt似乎设定的并不一致,少了一些case study,无法得知具体在RAG中的应用。】