PETR/PETRv2
PE: position embedding
一、PETR算法动机回归
1.1 DETR
输入组成:包含2D位置编码和Object Query
核心流程:通过Object Query直接索引2D特征图,结合位置编码迭代更新Query
特点:整体流程简洁,每个Query代表一个潜在目标
1.2 DETR3D
特征采样机制:通过Query生成3D参考点,反投影到2D图像采样特征
存在问题:
- 投影偏差:参考点位置出错会导致特征采样失效
- 特征局限性:仅使用单点特征导致全局信息学习不足
- 流程复杂度:需要反复投影和特征重采样,影响落地效率
二、PETR网络结构
三种结构的对比
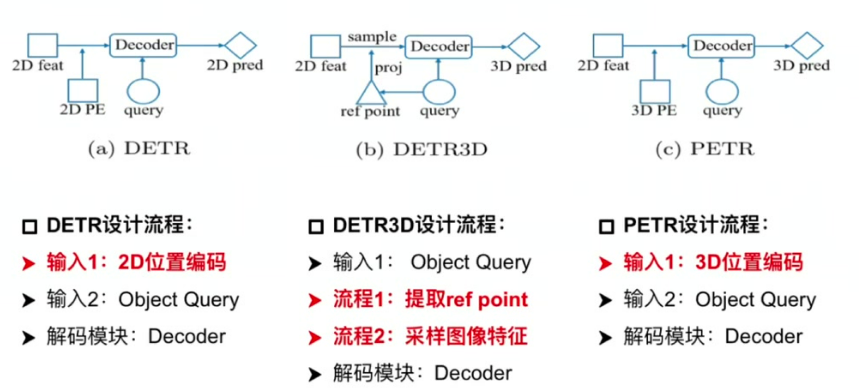
核心改进:引入3D位置编码生成3D感知特征
关键技术:
- 特征融合:将2D图像特征与3D位置编码结合形成
- 流程简化:省略反投影步骤,直接建立3D语义环境
- 优势:避免特征采样偏差,增强全局特征学习能力
PETR网络结构
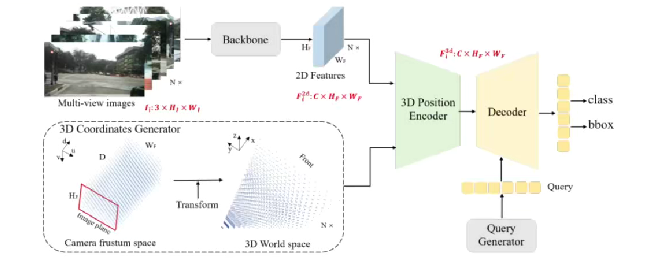
1. Image-view Encoder设计流程
输入输出:处理6视角图像(如nuScenes数据集),输出多尺度特征
Backbone选择:支持ResNet/Swin Transformer等架构
特征处理:
- 初始特征:维度为(原始图像) 3HW
- 输出特征:通过FPN得到的多尺度融合特征 C * Hf * Wf
2. 3D Coordinates Generator设计流程
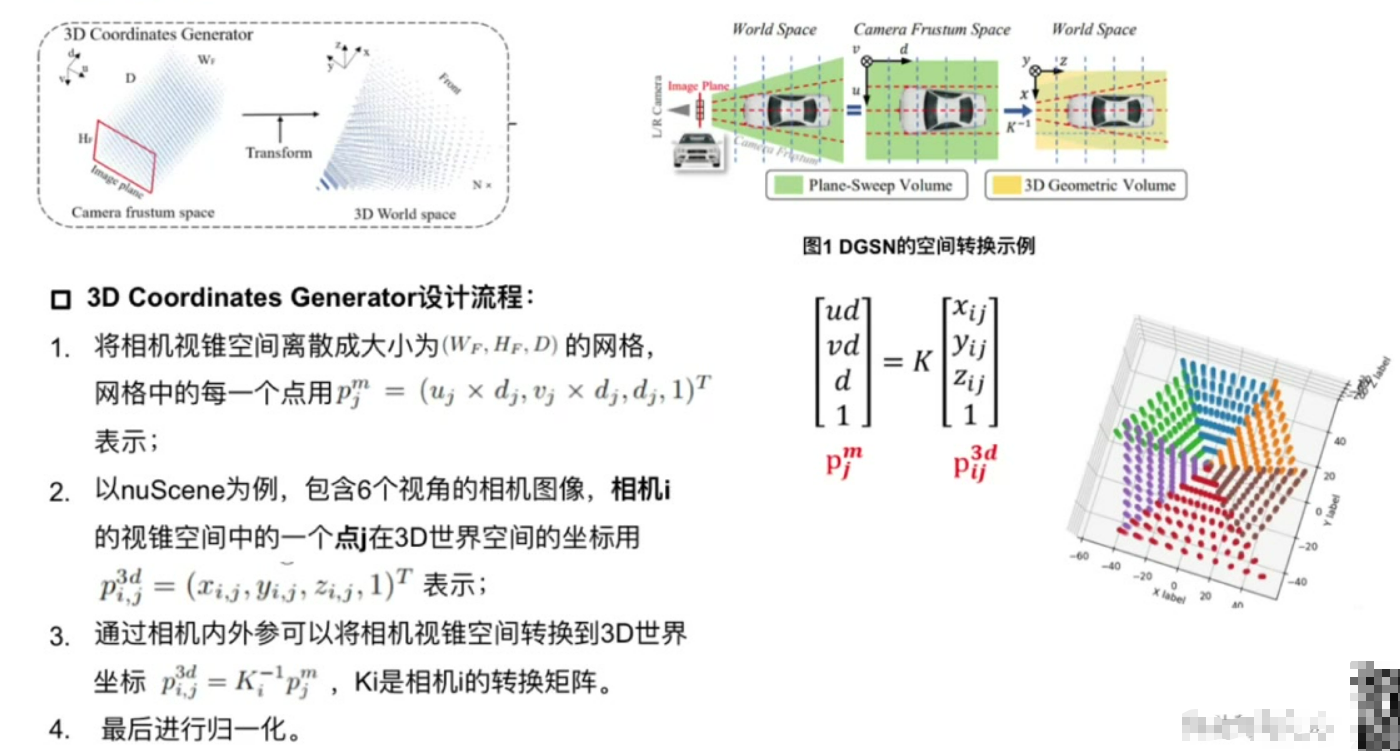
空间离散化:将相机视锥空间划分为三维网格
坐标转换:
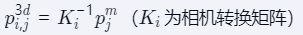
实现步骤:
- 像素坐标与深度值构成网格点
- 通过相机内外参转换到世界坐标系
- 对6视角结果进行归一化处理
输出特性:不同视角转换结果存在重叠区域,共同构成完整3D空间
3. 3D Position Encoder设计流程
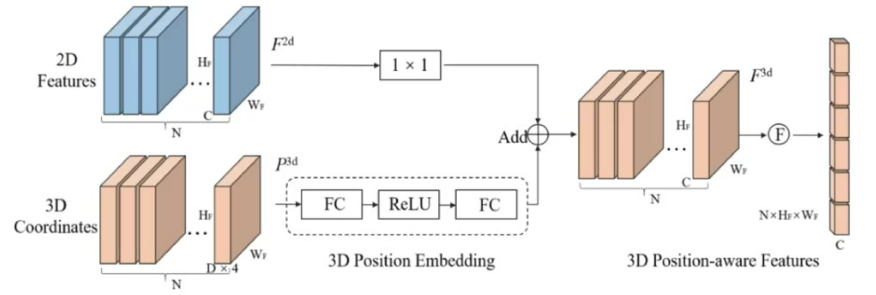
双支路处理:
- 图像特征支路:使用1×1卷积进行通道降维
- 坐标支路:通过3D PE模块对齐维度
特征融合:
- 操作方式:将处理后的2D特征与3D坐标特征相加
- 输出特性:生成具有位置感知的3D特征
后续处理:展平后与Object Query共同输入Decoder进行预测
三、PETR损失函数
损失组成: 包含分类损失和回归框损失等标准3D检测损失
结构特点: 与DETR3D等模型采用相同的损失函数设计
训练稳定性: 通过CBGS(Class Balanced Grouping and Sampling)策略进行训练优化
四、PETR性能对比
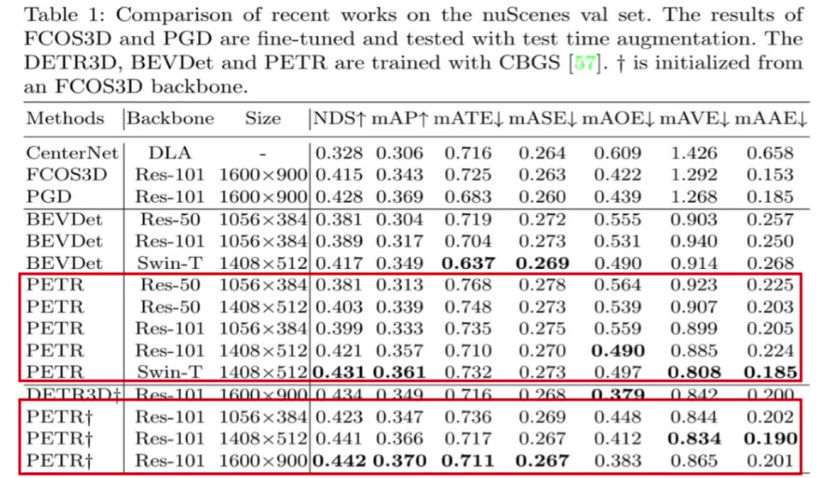
分辨率影响: 高分辨率图像(如1600×900)性能明显优于低分辨率(1056×384)
Backbone影响: ResNet101性能优于ResNet50,Swin Transformer表现最佳
收敛特性: 相比DETR3D收敛速度较慢,需要更长训练时间
位置编码优势: 3D位置编码(3D PE)相比传统2D PE带来显著性能提升
五、PETR V2
5.1 网络结构
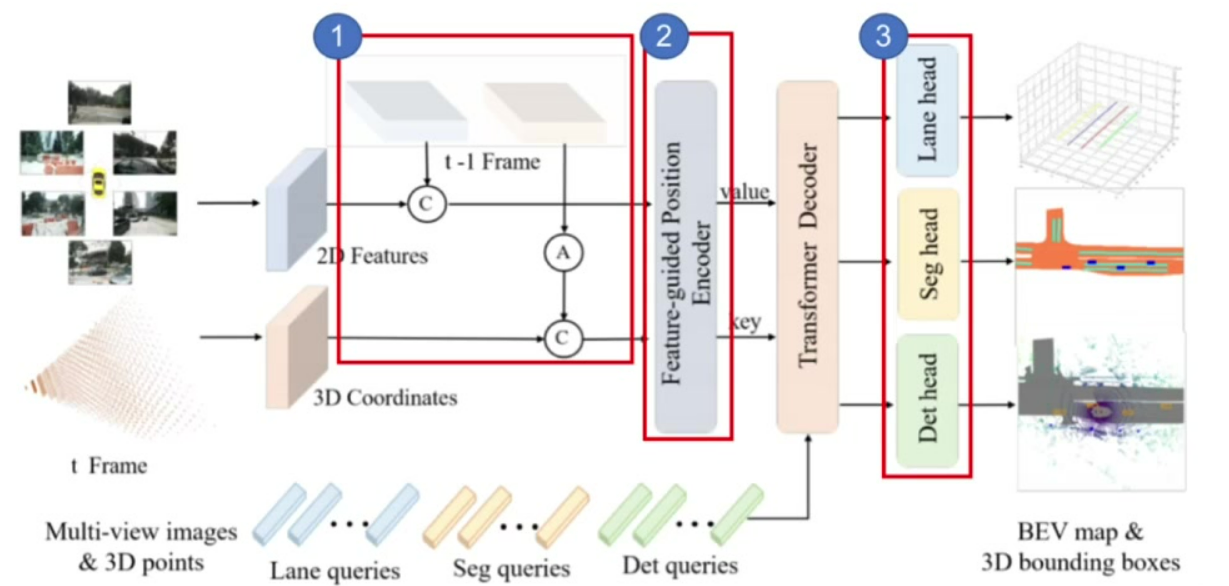
核心改进: 引入时序建模和多任务学习两大创新点
时序建模: 通过姿态变换对齐历史帧3D坐标,实现隐式时序特征融合,如图中模块1
多任务扩展: 新增分割头和车道线检测任务,形成统一感知框架,如图中模块3
5.2 多任务学习
任务类型: 同时支持3D检测、BEV分割和车道线检测
查询设计: 针对不同任务设计专用Query(Det/Seg/Lane queries)
性能优势: 多任务联合训练带来各任务性能的协同提升
5.3 网络结构与输入输出
输入保持: 延续多视角RGB图像输入
输出扩展: 除3D检测框外,新增分割mask和车道线输出
特征提取: 支持ResNet/Swin Transformer等多种backbone
5.4 特征提取与融合
2D特征提取: 通过共享backbone提取多视角图像特征
3D坐标生成: 将视锥空间坐标转换为世界坐标系
特征融合: 通过改进的position encoder融合2D特征和3D坐标
5.5 时序信息处理
关键创新: 通过实现历史帧3D坐标对齐
性能验证: 时序建模显著提升运动物体检测精度
5.6 检测任务扩展
检测头改进: 在原有检测头基础上增加分割分支
查询机制: 不同任务使用独立可学习的query向量
联合优化: 通过多任务损失函数实现端到端训练
5.7 实验性能与结论
综合性能: 在nuScenes等基准测试中达到SOTA水平
计算效率: 保持实时性(FPS>10)的同时提升精度
框架优势: 验证了统一感知框架的可行性