Redis一站式指南二:主从模式高效解决分布式系统“单点问题”
一.分布式系统的 “单点问题”
核心矛盾:要是服务器程序只靠 一个物理服务器(节点) 撑着,会有大麻烦:
- 可用性差:这台机器一挂,服务直接断,用户就用不了了(比如网站直接打不开 )。
- 性能有限:一个服务器能扛的并发请求少,访问量大时就 “扛不住”,卡到崩溃 。
解决思路:用 分布式系统 把任务拆给多台服务器,避免 “单点依赖”,让服务更稳、性能更强~
1.1Redis 集群的作用
分布式系统里,常把 多个服务器部署 Redis,组成 Redis 集群:
- 好处很直接:让 Redis 能存更多数据、扛更高并发,给其他服务(比如网站、APP 后台 )提供更稳、更快的数据存储 。
- 说白了:以前一个 Redis 服务器 “单打独斗” 容易崩,现在一群 Redis 服务器 “组队”,抗造又高效
二.主从模式
为了让 Redis 集群更灵活,有几种经典玩法:
主从模式:
- 核心逻辑:选一台当 “主服务器(Master)”,其他当 “从服务器(Slave)”。主负责写数据,从负责同步主的数据、处理读请求 。
- 好处:读请求分散到从服务器,减轻主的压力;主挂了,理论上能手动切从当主(但需要人工干预 )。
主从 + 哨兵模式:
- 核心逻辑:在 “主从模式” 基础上,加几个 “哨兵(Sentinel)”。哨兵专门盯着主服务器,一旦主挂了,哨兵能自动选新的主,不用人工插手 。
- 好处:解决主从模式 “主挂了没人管” 的问题,自动切换更智能、更稳 。
集群模式(Cluster):
- 核心逻辑:把多台 Redis 服务器分成 “分片”,数据分散存在不同分片里。比如按 key 的哈希值,把数据分到不同服务器,并发处理能力更强 。
- 好处:支持超大规模数据存储,还能自动分片、自动容错(某台服务器挂了,其他分片继续干活 ),是最常用的 “分布式 Redis” 方案 。
2.1 基本概念
在若干个 redis 节点中,有的是 “主” 节点,有的是 “从” 节点
假设有三个物理服务器(称为三个节点),分别部署一个 redis-server 进程
此时可以把其中一个节点作为 “主节点”,另外两个作为 “从节点”
从节点规则:
- 从节点得听主节点的~~(从节点数据要跟随主节点变化,保持一致)
- 本来主节点保存一堆数据,引入从节点后,主节点的数据会复制到从节点中.
- 后续主节点修改数据,都会同步到从节点上(从节点是主节点的副本)
从节点的限制:
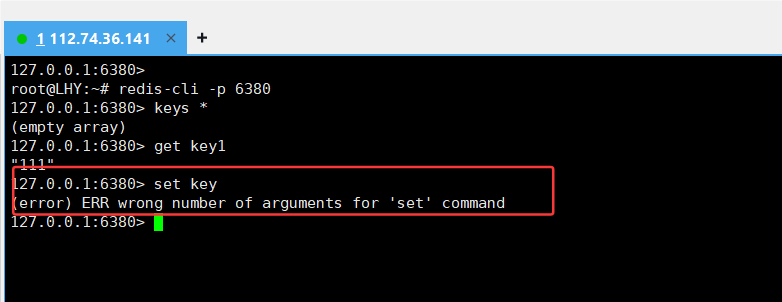
- Redis 主从模式中,从节点数据不允许修改!只能读取数据!
主从模式的目标:
主要针对 “读操作”,提高并发量 & 可用性~~
写操作依赖主节点(主节点不能多个 ),但实际业务中读操作更频繁,所以主从模式能缓解压力
2.2 可用性与风险
单个节点的问题:
之前单个 redis 服务器挂了,整个 redis 就挂了~~
主从结构的优势:
这些 redis 机器不太可能 “同时挂”,但整个机房可能被 “一锅端”(异地多活可解决 )
节点挂掉的影响:
- 挂掉从节点:没啥影响,客户端继续从主 / 其他从节点读数据.
- 挂掉主节点:从节点只能读,无法写数据(可用性提高,但未到理想程度 )
多个主节点的麻烦:
一山不容二虎~~两个主节点同步数据会很复杂,所以主从模式一般只有一个主节点
2.3 配置步骤
前提:需要启动多个 redis 服务器~~
正常每个 redis 服务器应在单独主机(分布式 ),但如果只有一个云服务器时,可在一个主机运行多个 redis-server 进程(通过不同端口区分 )
主从复制:在一个服务器使用,三个进程,设置一个主节点,两个从节点(端口号6380,6381)
1.创建一个文件夹:
root@LHY:~# mkdir redis-conf2.拷贝两份(slave1.conf,slave2.conf)redis配置文件:
root@LHY:~# cp /etc/redis/redis.conf ./slave1.conf
root@LHY:~# cp /etc/redis/redis.conf ./slave2.conf
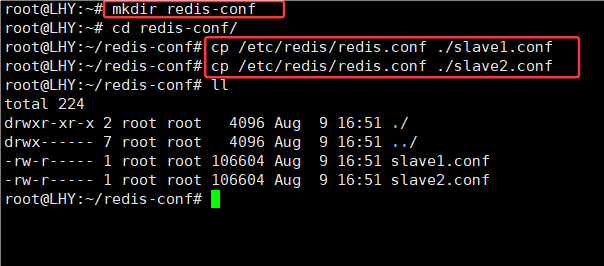
4.进入redis-conf文件夹,打开slave1.conf配置文件:
root@LHY:~# cd redis-conf/
root@LHY:~/redis-conf# vim slave1.conf5.修改端口:
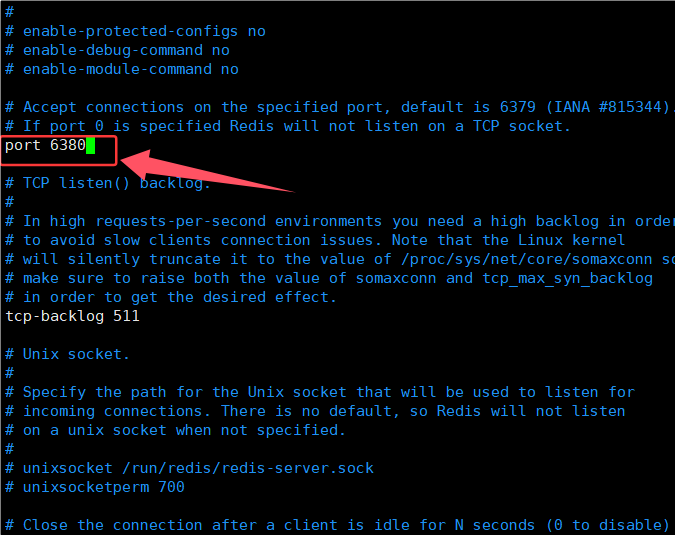
6.修改进程可以在后台方式运行
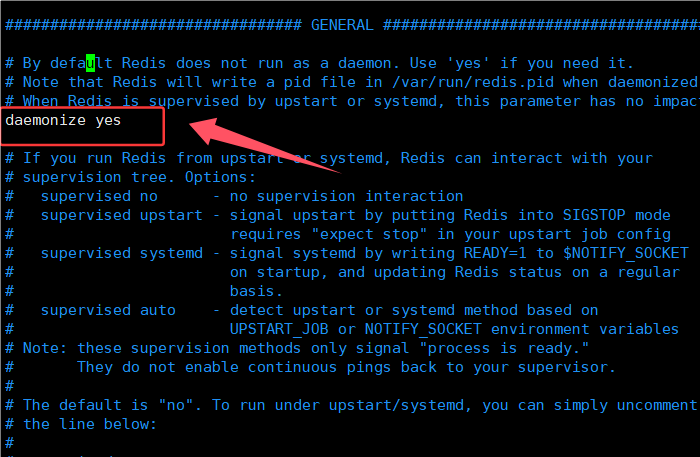
其实还要默认修改主机ip地址和保护模式关闭(但是已在主配置修改)
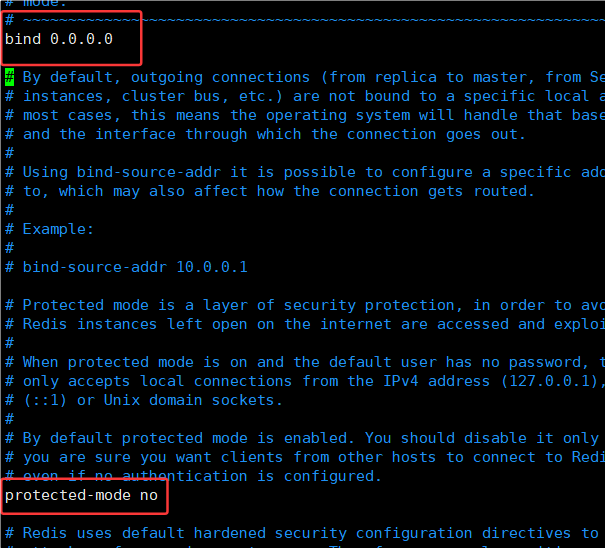
slave2.conf文件步骤一样
9.启动6380进程,6381
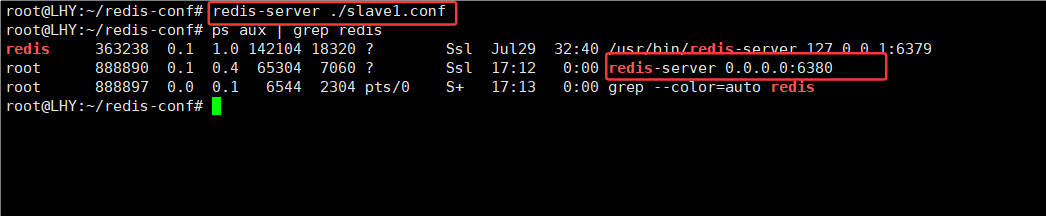

但是三个节点是相互独立的,没有主从结构的联系,还要进一步配置
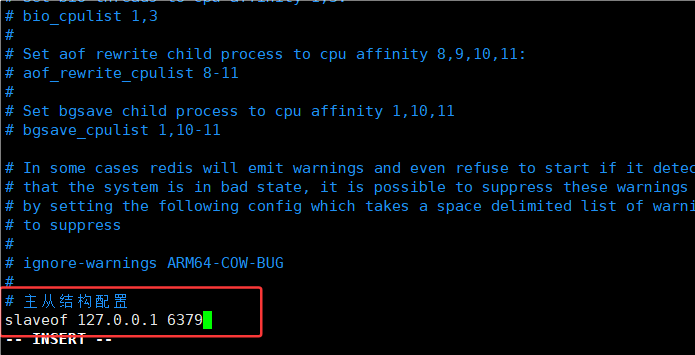
11.进入slave1.con,slave2.conff配置(命令模式,按G可直接到达文件末尾噢)
# 主从结构配置
slaveof 127.0.0.1 6379
12.redis配置文件要重新启动才生效

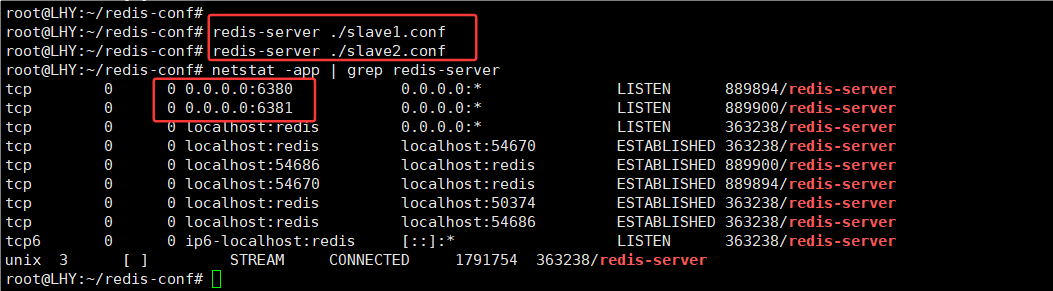
现在这台机器上有 三个 Redis 实例 同时在跑:
| 端口 | PID | 配置文件来源 |
|---|---|---|
| 6379 | 363238 | 默认主节点 |
| 6380 | 889894 | slave1.conf |
| 6381 | 889900 | slave2.conf |
6380 和 6381 已经和 6379 建立了连接(ESTABLISHED),是主从复制链路。
13.测试是否连接有效:
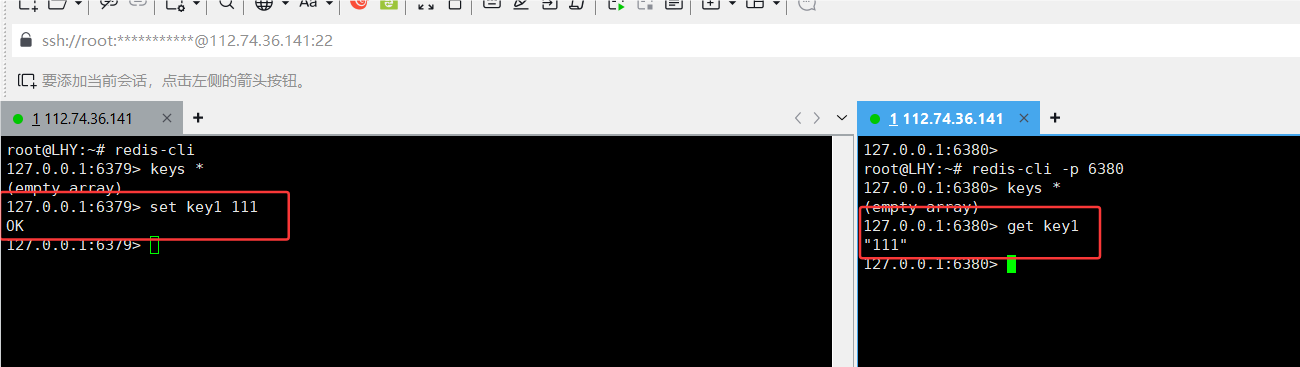
那从节点能否执行写操作呢,不行,
15.主节点查看信息结构信息:
查看主从结构信息:
info replication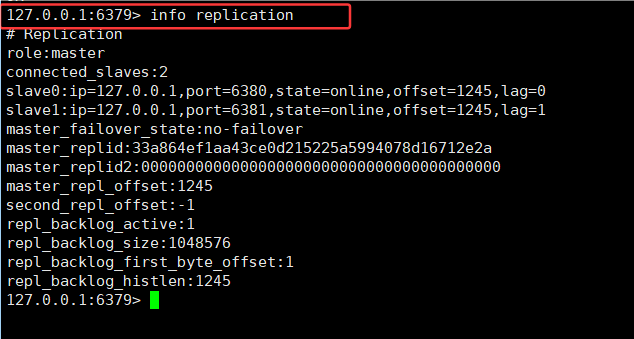
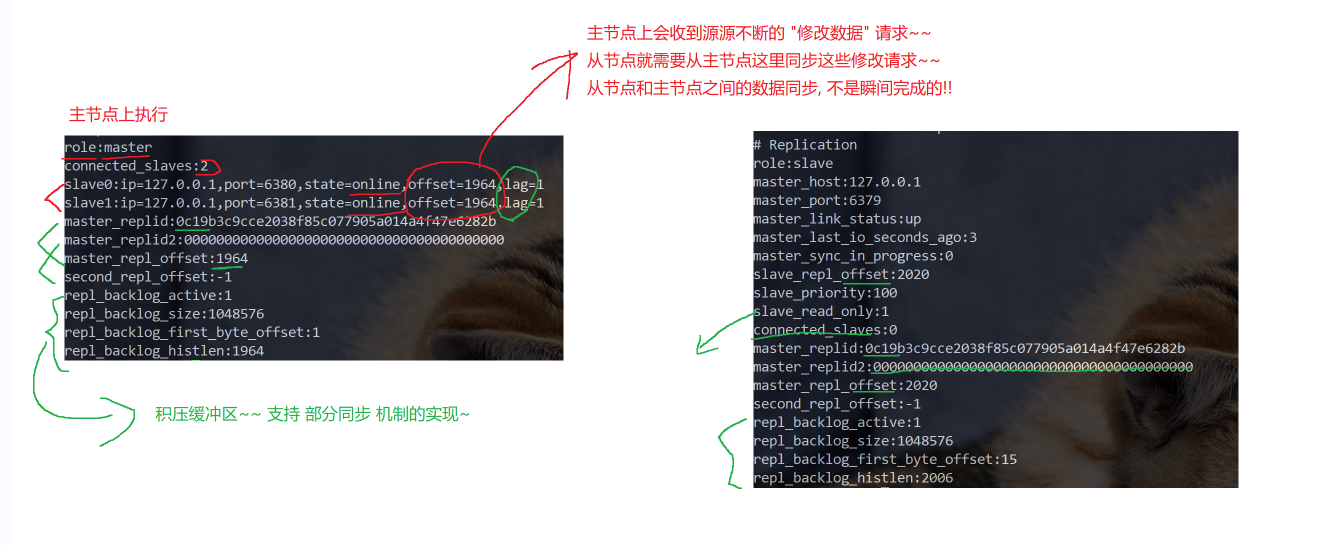
6379 是主节点(role:master)
- 有 2 个从节点:
- slave0 → 127.0.0.1:6380
- slave1 → 127.0.0.1:6381
状态都是 online,offsezh45),说明数据同步正常
lag=0 或 lag=1 表示延迟几乎没有
查看子节点结构信息
info replication- role:slave → 身份是从节点
- master_host:127.0.0.1 / master_port:6379 → 正在跟 6379 同步
- master_link_status:up → 主从连接正常
- master_sync_in_progress:0 → 同步任务已完成
- slave_read_only:1 → 从节点是只读的(Redis 默认如此)
- slave_repl_offset 和 master_repl_offset 一致 → 数据已经完全同步
2.4 断开和修改主从结构
断开命令:
slaveof on one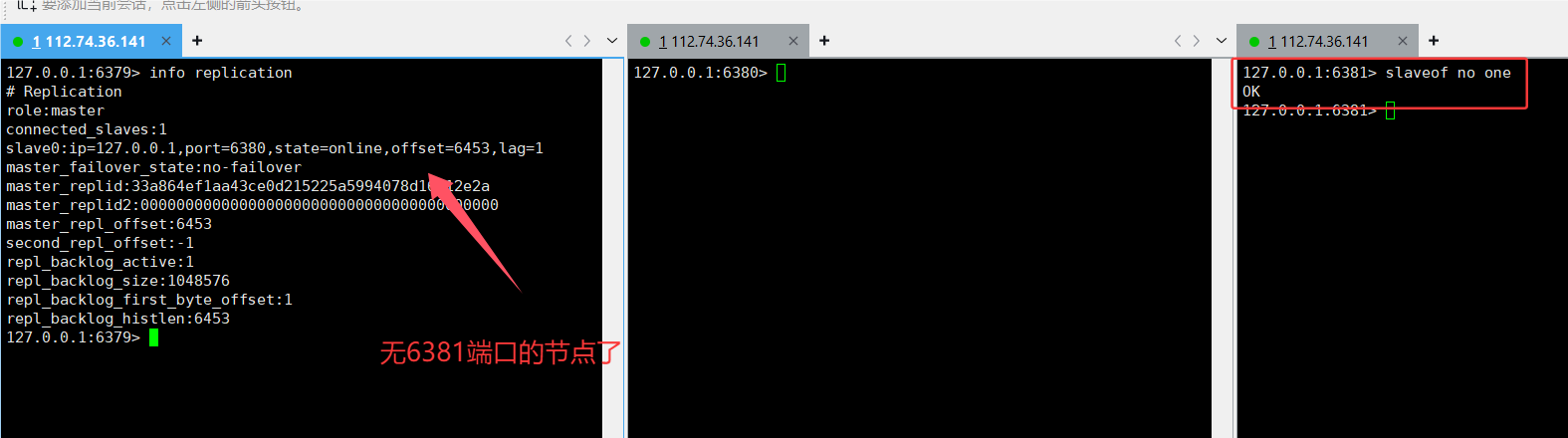
slaveof no one (直接在 redis 客户端中的命令),直接使用这个命令断开现有的主从复制关系。
从节点断开主从关系, 它就不再从属于其他节点了, 里面已经有的数据, 是不会抛弃的!!
但是, 后续主节点如果针对数据做出修改, 从节点就无法再自动同步数据了.
修改主从结构:
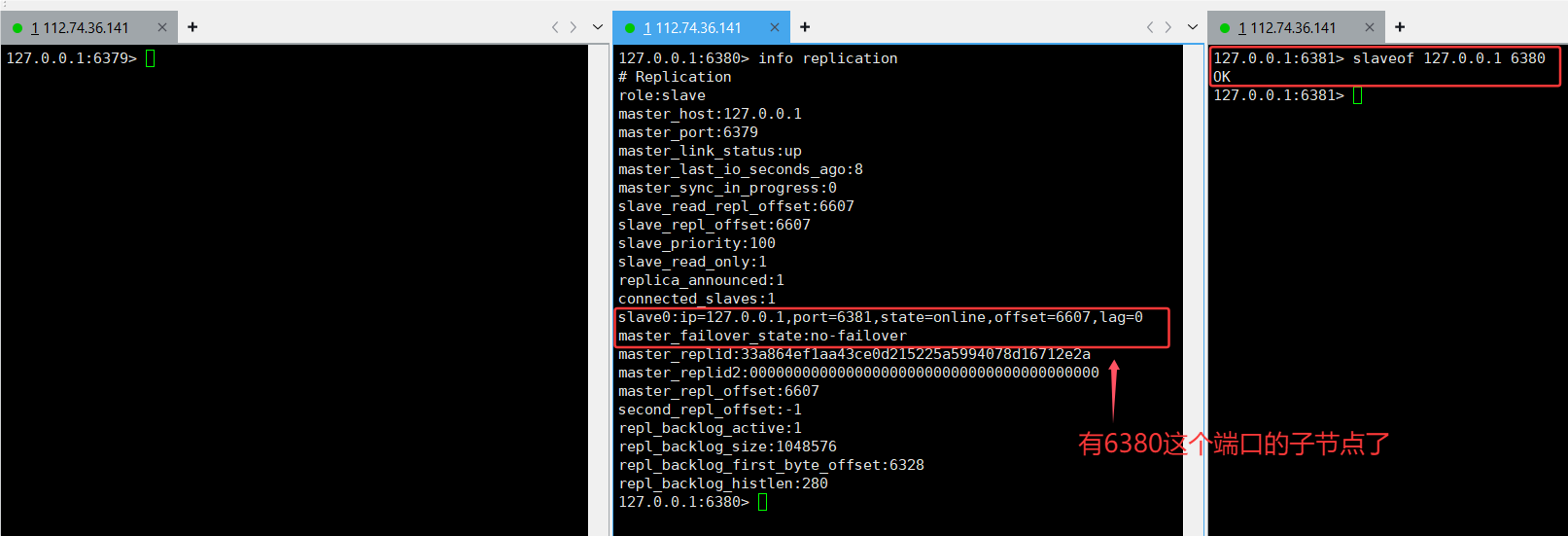
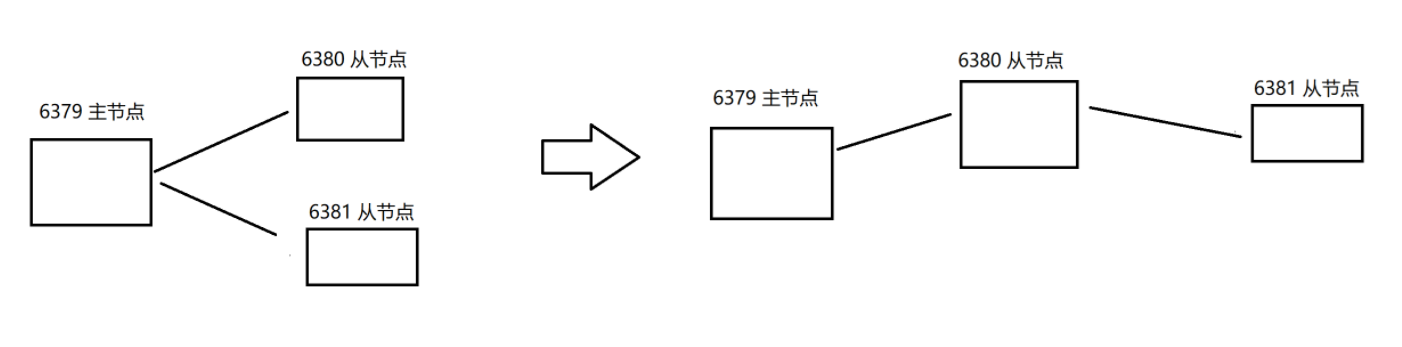
刚才通过 slaveof 是修改了主从结构,
此处的修改是临时性的. 如果重新启动了 redis 服务器, 仍然会按照最初在配置文件中设置的内容来建立主从关系,"主从复制" 是从主节点到从节点,不能 从从节点 到 主节点 。
如果从节点允许修改, 后续对于从节点的修改, 主节点是感知不到的. 数据就不一致了。
通俗解读:
- 修改的临时性:当你用
slaveof命令去调整主从结构(比如让某个节点换个主节点,或者像slaveof no one这样断开关系 ),这种修改 只是临时生效 。要是把 Redis 服务器重启了,它会 回到配置文件里最初设置的主从关系 。举个例子,你配置文件里写好了 6379 是主节点,6380 是从节点,你临时用命令让 6380 断开了和 6379 的关系,可一旦重启 Redis,6380 又会自动作为从节点连接到 6379 那里 。 - 主从复制方向:主从复制的方向是 单向 的,只能是 主节点把数据同步给从节点 ,而 不能反过来 让从节点把数据同步给主节点 。
- 数据不一致风险:要是从节点允许被修改数据(实际正常主从模式里从节点默认是不能修改的,这里是假设情况 ),之后从节点自己被改了数据,主节点 不会知道 从节点的数据有变化,这样主节点和从节点的数据就对不上了,出现 数据不一致 的问题 。
2.5 主从复制的基本流程

2.5.1 同步流程
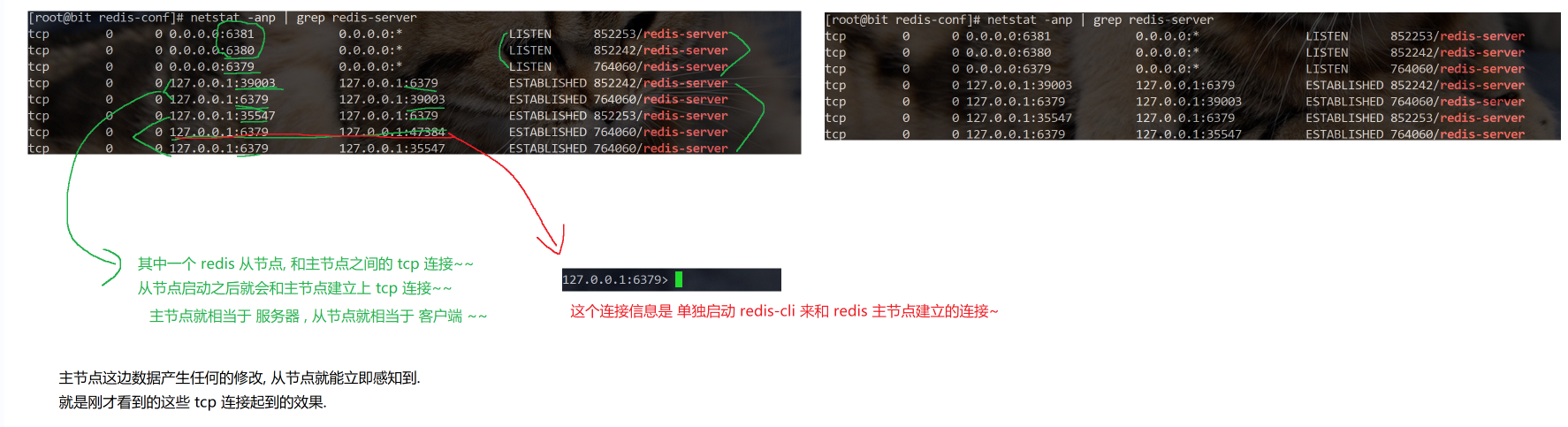
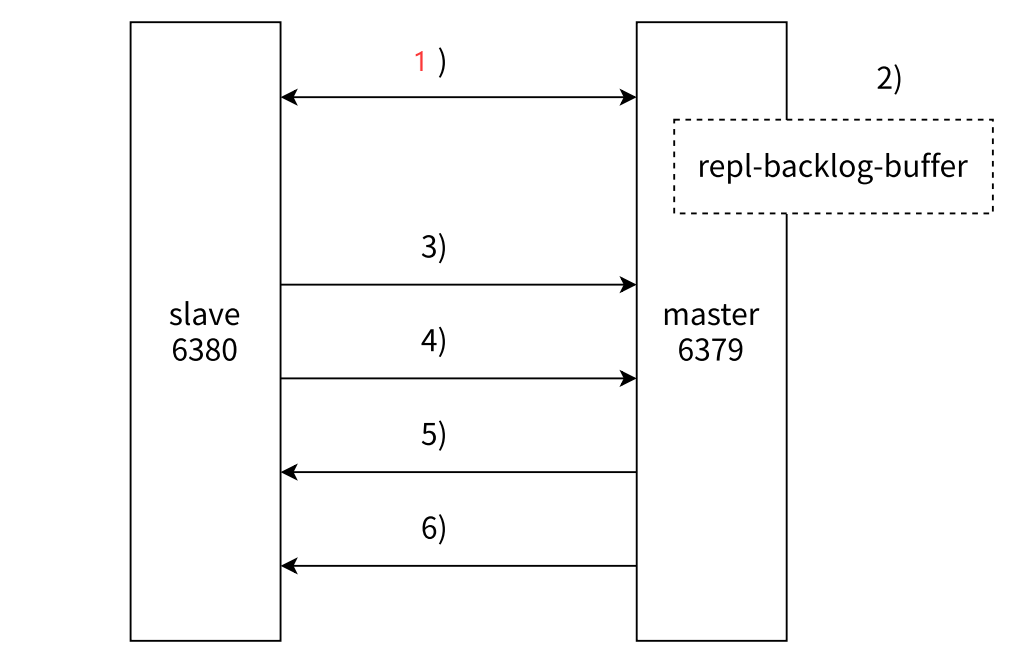
在 Redis 主从架构中,以从节点(slaveof 127.0.0.1 6379,即连接本地 6379 端口的主节点)和主节点(master,端口 6379,从节点自身端口为 6380)为例,其连接与数据同步流程如下:
1. 保存主节点信息
从节点首先会保存主节点的 IP 地址和端口信息,将其存储为变量,这是后续建立连接的基础,属于系统层面的操作。
2. 建立 TCP 连接(三次握手)
从节点基于保存的主节点 IP 和端口信息,与主节点进行 TCP 连接,通过三次握手来验证通信双方是否能够正确读写数据,确保网络通路是畅通的。
3. 发送 ping 命令
从节点向主节点发送 ping 命令,这一步是为了验证主节点是否能够正常工作,属于应用程序层面的检查,类似于检查车辆是否能正常行驶。
4. 权限验证
如果 Redis 主节点开启了密码验证,从节点需要进行相应的权限验证,只有验证通过才能继续后续操作。
5. *同步数据集
在完成上述步骤后,从节点会与主节点进行数据集的同步。
6. *命令持续复制
这是复制数据的最关键操作,从节点会持续复制主节点的命令,以保持与主节点数据的实时一致性。
7. 同步方式
- 全量同步:在初始连接或某些特定情况下,从节点会获取主节点的全部数据进行同步。
- 增量同步:在正常持续运行过程中,从节点主要同步主节点新增或修改的数据,以提高同步效率。
2.5.2 同步命令 psync
Redis 数据同步命令 psync:

2.5.3 replication id
- Redis 提供了 psync 命令来完成数据同步的过程。
- psync 命令具有自动化特性,不需要我们手动去执行。当 Redis 服务器成功建立主从同步关系之后,它会自动执行 psync 命令。
- 在主从同步架构中,从节点负责执行 psync 命令,其作用是从主节点这边拉取数据,就好比助教老师主动来找学生(这里从节点类似学生,主节点类似数据源头,助教老师即数据同步机制,主动帮学生获取知识即数据) ,以实现主从节点间的数据同步。
- psync 命令的格式为 PSYNC replicationid offset ,其中 replicationid 是复制 ID,用于唯一标识一个数据集版本;offset 是偏移量,用于记录复制的进度等信息。通过这两个参数,psync 能够精准地实现数据的增量同步等操作。
replication id 相关内容
- 生成规则:主节点启动、从节点晋升为主节点时生成;同一主节点每次重启,生成的 replication id 不同,类似重启换 “身份证号”。
- 传递逻辑:从节点与主节点建立复制关系后,主动获取主节点的 replication id ,用于确认数据同步来源。
- 实际操作:执行 info replication 命令查看,主节点执行后,结果里 master_replid 字段即主节点的 replication id ,master_replid2 一般场景用不上 。
- 特殊场景(网络波动):主节点 A、从节点 B 同步时网络波动,B 误判 A 宕机并自行晋升为主节点,会生成新 replication id ,同时将 A 旧的 replication id 存于 replid2;后续网络恢复,B 可通过 replid2 尝试重新同步回 A ,但需手动干预 。

2.5.4 offset
offset(偏移量 )相关内容
- 核心作用:主节点、从节点均维护整数偏移量,标记数据同步进度,类似直播 “进度条” 。
- 主节点 offset:主节点接收的写命令(如 set、del )按字节数累加,总和为其 offset,代表数据变更 “总进度” 。
- 从节点 offset:表示从节点同步主节点数据的进度位置,类似直播中自己 “进度条走到哪” 。
- 同步完成标志:从节点 offset 与主节点 offset 相等时,说明从节点数据和主节点完全一致,即 “赶上直播实时进度” 。

2.5.5 全量复制
1.核心基础:offset 控制同步范围
offset = -1
- 原文逻辑:offset 写 -1 时,从节点直接获取全量数据(不管之前同步到哪,重新拉取所有数据)。
offset = 具体正整数
- 原文逻辑:offset 填正整数(如 100),从节点从当前偏移量位置继续同步(只拉取没同步过的新数据)。
2.全量复制 vs 增量复制(核心同步逻辑)
2.1全量复制的触发场景
- 首次同步:从节点第一次连主节点,没任何历史同步记录,必须全量拉取(类似第一次看直播,得从头开始看)。
- 主节点无法部分复制:主节点判断 “不方便给部分数据”(如数据差异太大、网络不稳定),强制全量同步(类似直播平台故障,只能重新发完整回放)。
3.全量复制的执行流程(结合 rdb 、aof )
3.1. 主节点的核心动作:生成 rdb 文件
- rdb 特点:二进制格式,体积小、节省空间(类似把 “文字笔记” 压缩成 “加密压缩包”,传输更快)。
- 生成逻辑:主节点执行
bgsave命令,重新生成 rdb 文件(不能用旧文件,因为数据可能已变化)。
3.2. 全量复制的步骤(以首次同步为例)
- 从节点发
psync -1(因首次同步,无主节点 ID 和偏移量,用 -1 表示全量)。 - 主节点回复
FULLRESYNC,开始全量复制。 - 主节点执行
bgsave生成新 rdb 文件,传给从节点。 - 从节点接收 rdb 文件,加载数据到本地(类似解压 “压缩包”,恢复数据)。
- 主节点把 “生成 rdb 期间的新操作” 记录到缓冲区,等从节点加载完 rdb 后,再把这些新操作同步给从节点(保证数据不丢)。
3.3. aof 日志的特殊处理(从节点开启 aof 时)
- 从节点加载 rdb 数据时,会生成大量 aof 日志(类似边看直播边记超详细笔记,可能有冗余内容)。
- 需整理 aof 日志(如
bgrewriteaof),减少冗余(类似把 “啰嗦笔记” 精简成 “重点大纲” )。
4.全量复制的优化:无硬盘模式(diskless)
4.1. 优化逻辑
- 主节点生成 rdb 后,不写本地硬盘,直接通过网络发给从节点(省去 “写硬盘 → 读硬盘” 的步骤,更快)。
- 从节点接收 rdb 后,不写本地硬盘,直接加载数据(省去 “存硬盘 → 读硬盘” 的步骤,更快)。
4.2. 优化的局限性
2.5.6 部分复制
1.部分复制的触发场景
从节点之前同步过数据,但因网络抖动、从节点重启等中断,此时只需要拉取新数据(类似直播断流后,从断流位置接着看,不用重看已看内容)。
网络中断,主节点判定故障
当主从节点间网络中断,且超过repl - timeout时间,主节点会判定从节点故障,终止复制连接 。主节点在中断期间的行为
网络中断时,主节点依旧正常响应外部 “修改数据” 等命令 。但本应发给从节点的 “复制命令”,因网络不通无法及时发送,会暂时存到 复制积压缓冲区 里。网络恢复,从节点重连
主从节点网络恢复后,从节点会主动再次连接主节点 。从节点发起部分复制请求
从节点连接主节点时,会把之前保存的replicationId(复制标识,用于主从配对)和 复制偏移量(记录之前同步到哪一步),作为psync(部分复制命令)的参数发给主节点,请求 “接着之前的进度同步,不用全量复制” 。主节点验证并准备数据
主节点收到psync请求后,先做必要验证(比如replicationId是否匹配、偏移量是否有效 )。验证通过后,根据从节点发的offset,去 复制积压缓冲区 找对应的数据,然后响应+CONTINUE给从节点,告诉从节点可以继续同步 。完成数据同步
主节点把从节点需要的 “未同步数据”,通过连接发给从节点,从节点接收并应用这些数据,最终主从节点数据再次保持一致,完成恢复后的同步流程
2.5.7 实时复制
1.实时复制基础流程
从节点完成初始数据同步后,主节点会持续接收新的 “修改数据请求” ,自身数据改变后,要把这些修改同步给从节点,保证数据一致性 。
2.主从节点数据同步方式
- 连接建立:从节点和主节点间建立 TCP 长连接 ,作为数据传输通道。
- 同步流程:主节点收到 “修改数据请求” 后,通过上述长连接,把请求发给从节点;从节点接收请求,依据请求修改自身内存数据 。不过这个同步过程会有时间延迟(正常很短,多级从节点树形结构、层级多的话,延迟会上升 )。
3.连接可用性保障(心跳包机制)
为确保主从节点间的 TCP 长连接可用,有 “心跳包机制”:
- 主节点行为:默认每隔 10s 给从节点发
ping命令,从节点收到返回pong,用于检测从节点是否在线 。 - 从节点行为:默认每隔 1s 给主节点发特定请求,上报自身复制数据的进度(用
offset标识 ),让主节点掌握同步情况 。 - 补充说明:像 10s、1s 这类时间,以及文中提到的 60s(未明确关联场景,可理解为相关机制里的默认配置 ),都属于可修改的配置,不用死记 。
简单概括就是:主从节点靠 TCP 长连接同步数据修改,用心跳包维持连接可用,同步有延迟且受从节点结构影响,心跳相关时间可灵活调整 。核心是保障主从数据一致,同时通过心跳确保连接 “活着” 能传输数据 。
三.其他补充
3.1Nagle 算法
在游戏开发中,尤其是对即时性要求极高的 FPS、MOBA 等类型游戏,主节点和从节点间通过网络(TCP)传输数据。TCP 内部默认开启支持 Nagle 算法,该算法目的与 TCP 捎带应答类似,即针对小的 TCP 数据报进行合并以减少包的个数,开启它会增加 TCP 传输延迟但节省网络带宽,关闭则减少延迟却增加带宽占用。而“repl-disable-tcp-nodelay”选项可在主从同步过程中关闭 TCP 的 Nagle 算法,让从节点能更快速地与主节点同步。
通俗解读
- 网络传输方式:主节点和从节点之间是通过 TCP 网络 来传输数据,实现主从同步的 。
- Nagle 算法介绍:TCP 协议里默认开启了 Nagle 算法 。它的作用有点像 “攒一波再发” :
- 开启时:会把一些小的 TCP 数据报合并起来发送,这样发送的网络包数量就减少了,能 节省网络带宽 ,但会 增加数据传输的延迟 。比如说,本来要发好几个小数据包,现在合并成一个大的发,带宽省了,可数据从主节点到从节点就得等合并,慢了点 。
- 关闭时:小数据报就会马上发送,不会攒着,这样 传输延迟会减少 ,数据能更快同步,但因为发的包多了,会 增加网络带宽的使用 。
- 对游戏开发的影响:在一些对 即时性要求很高的游戏开发 场景里(像 FPS 射击游戏、MOBA 竞技游戏 ),延迟很关键。要是主从同步延迟高,可能游戏里数据更新就不及时,影响玩家体验 。
- Redis 里的优化选项:Redis 有个配置项
repl-disable-tcp-nodelay,用它可以在主从同步的过程中 关闭 Nagle 算法 。这样做能让从节点 更快速地和主节点同步数据 ,减少延迟,适合对同步速度要求高的场景 。
3.2 拓扑结构
在由若干个节点组成的系统中,探讨节点间以何种方式进行组织连接。以 Redis 主从节点为例,存在 Redis-A(主节点,Master)和 Redis-B(从节点,Slave) 。主节点负责处理写数据请求,同时也能处理读数据请求;从节点主要处理读数据请求。
当写数据请求过多时,会给主节点造成一定压力。可以通过关闭主节点的 AOF(Append - Only File,一种数据持久化方式),只在从节点上开启 AOF 来缓解主节点压力。然而,这种设定方式存在严重缺陷:主节点一旦挂掉,不能自动重启。若自动重启,由于没有 AOF 文件,就会丢失数据,并且进一步的主从同步操作会把从节点的数据也删除。改进办法是,当主节点挂了之后,让主节点从从节点这里获取到 AOF 的文件,再启动。
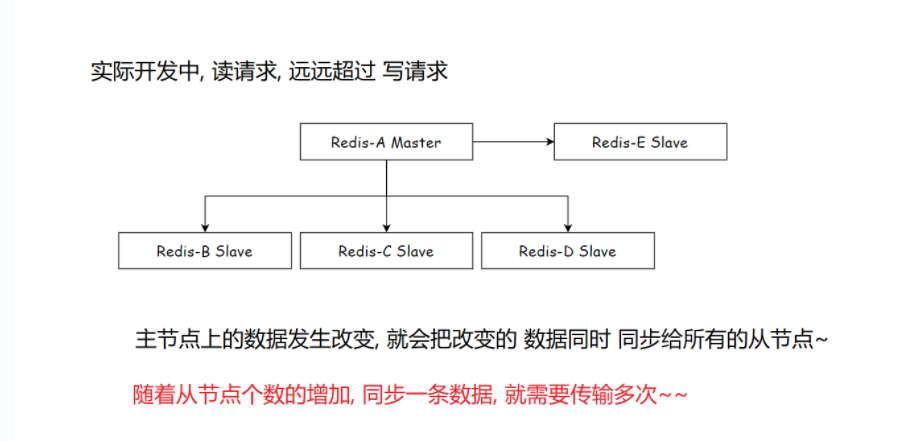
3.3 扁平化结构
在实际开发中,读请求往往远超过写请求。在扁平化结构中,存在 Redis-A(主节点),它连接着多个从节点,如 Redis-E、Redis-B、Redis-C、Redis-D 等从节点。
当主节点上的数据发生改变时,会把改变的数据同时同步给所有的从节点。但随着从节点个数的增加,同步一条数据就需要传输多次。这样一来,主节点就不需要那么高的网卡带宽了,不过一旦数据进行修改,同步的延时会比之前更长。
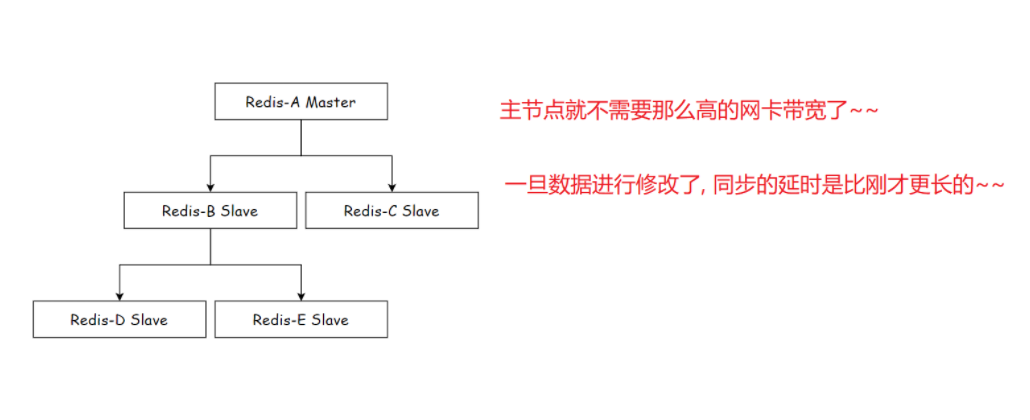
3.4 replid与runid的区别



举个栗子~
- 核心耗时仍在网络传输:不管有没有硬盘操作,大规模数据(全量复制)的网络传输时间省不了(类似发大文件,不管存不存硬盘,传文件本身就慢)。
replid(replication id)
- 作用:主从复制的核心标识,主从关系中相同(主节点生成,从节点同步主节点的 replid ,体现 “数据传承关系” )。
runid
- 作用:标识 Redis 实例的一次 “运行”(每次启动 / 重启,runid 不同,类似 “运行会话 ID” )。
- 关联逻辑:主要支撑 Redis 哨兵(sentinel) 功能(用于哨兵识别实例、判断故障转移 ),和主从复制无直接关联 。
- replid ≈ 主从复制的 “家族族谱 ID”:主节点有一个,从节点同步主节点的,主从 “族谱” 相同,用来确认数据同步关系。
- runid ≈ Redis 实例的 “运行身份证”:每次启动换一个,主要给哨兵用,和主从复制 “不是一家人”。