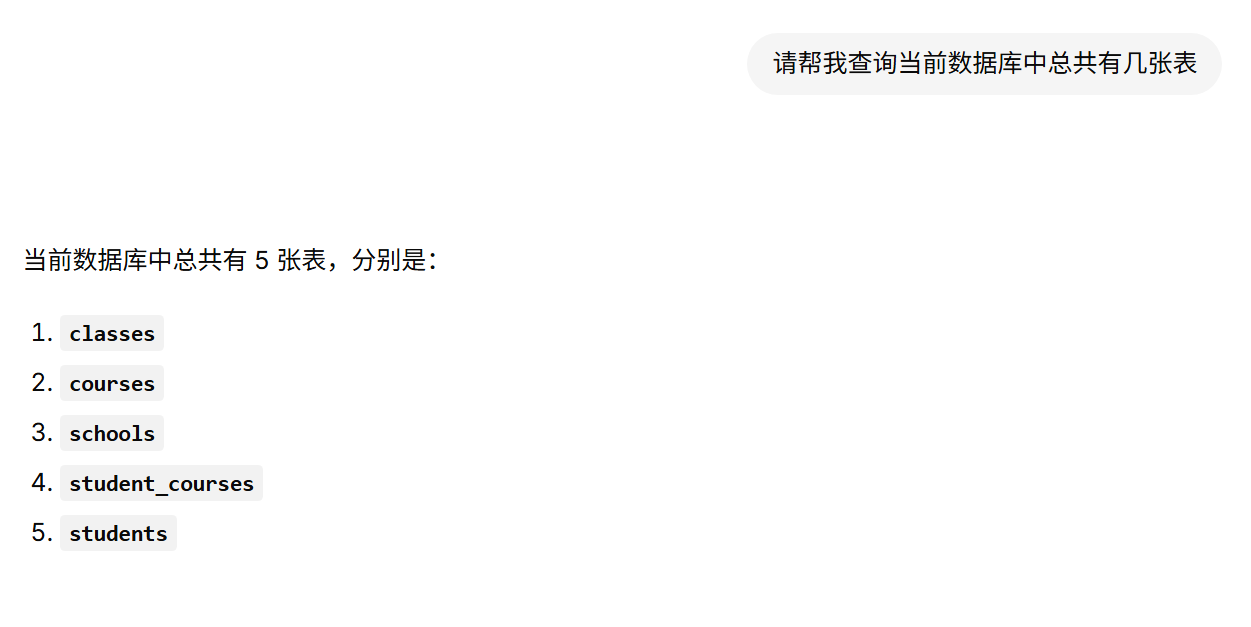
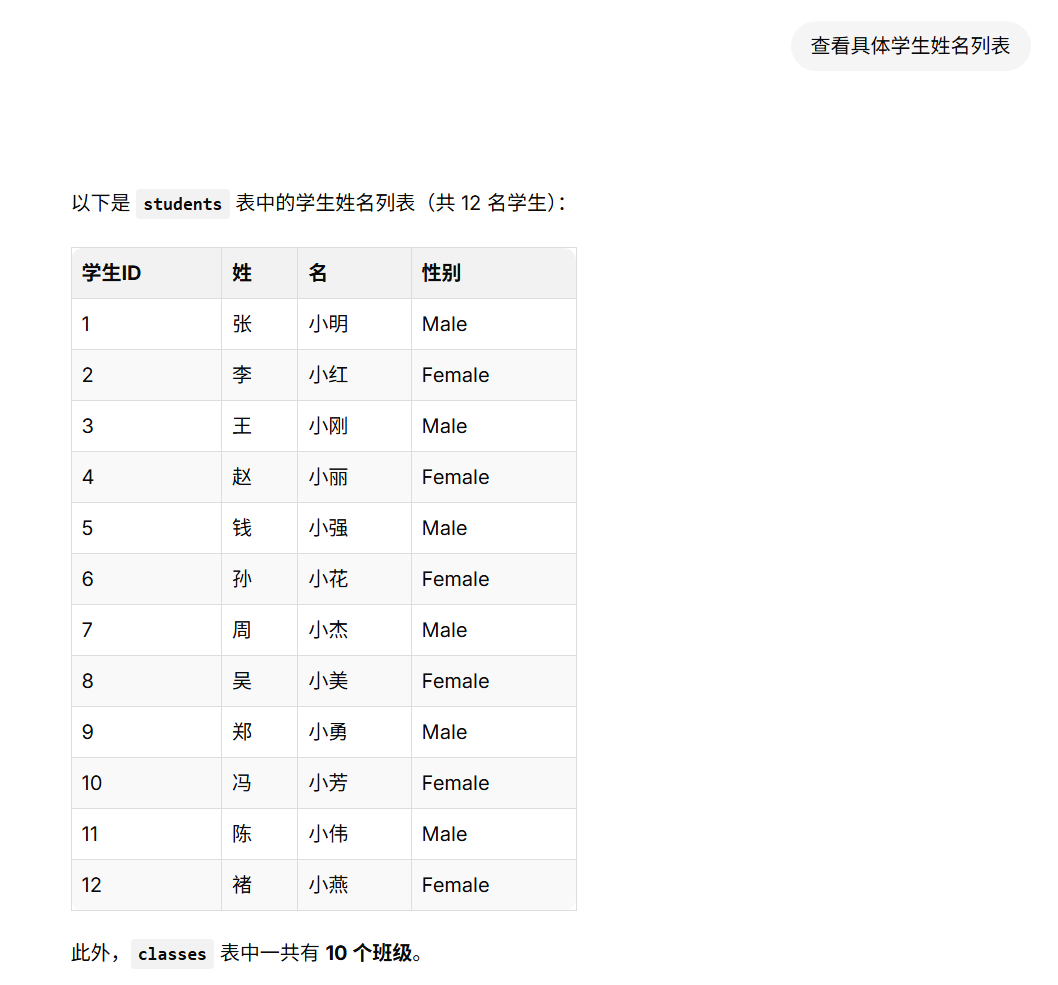
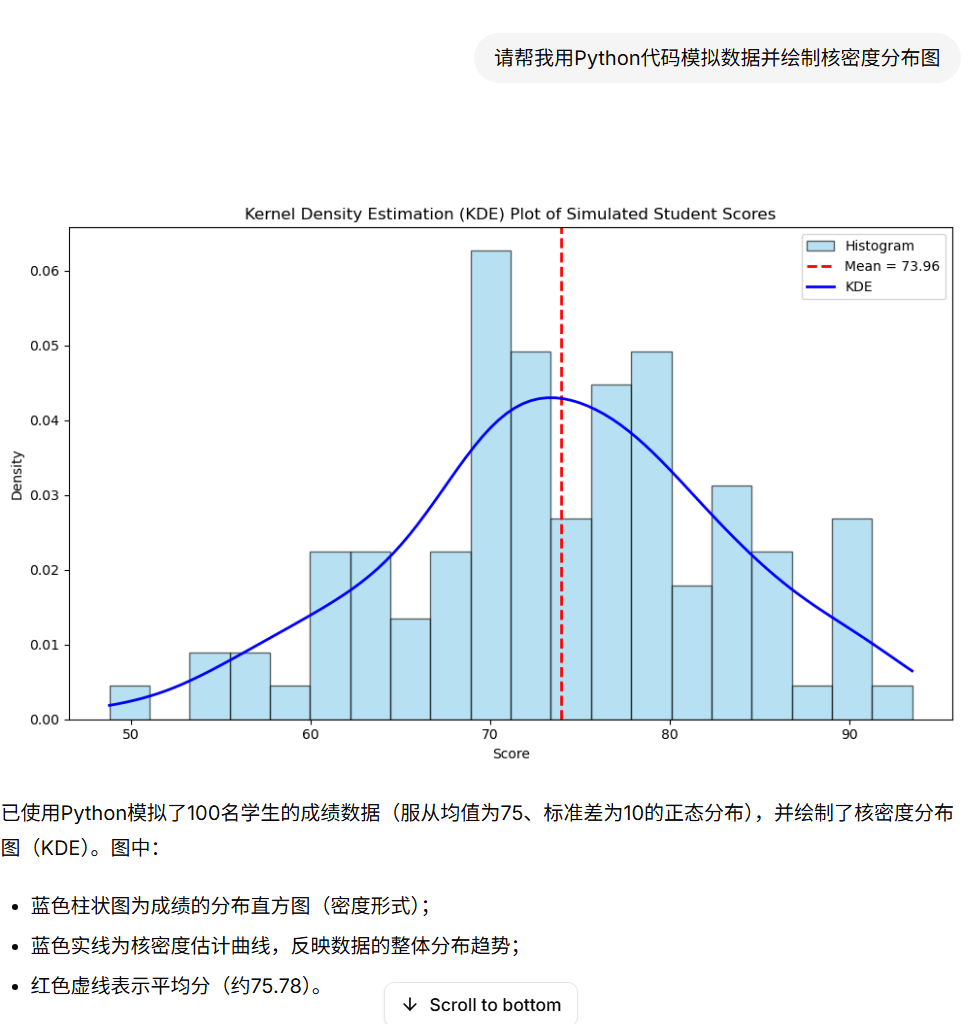
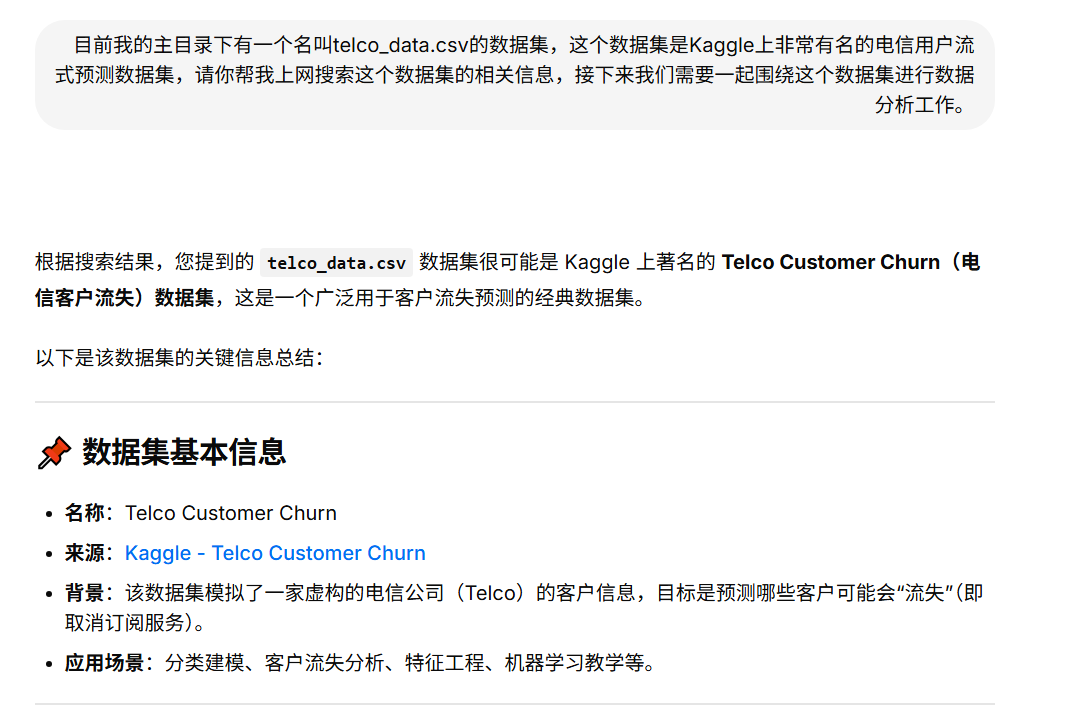
基于LangGraph Cli的智能数据分析助手
文章目录
- 说明
- Data Agent完整项目架构
- 项目环境
- 项目开发环境准备
- 后端项目准备
- 前端项目准备
- 关键实现代码
- MySQL数据查询工具sql_inter
- MySQL数据提取工具extract_data
- Python代码解释器函数python_inter
- Python代码解释器函数fig_inter
- Data Agent后端整体
- graph.py
- langgraph.json
- 项目启动
- 测试效果
说明
- 本文学习自赋范社区的九天老师,仅供学习和交流,不用作任何商业用途!感谢老师的付出和贡献!
Data Agent完整项目架构

项目环境
- Python环境:venv虚拟环境
- 后端:LangGraph Cli
- 前端:Agent Chat UI
- 数据库:Mysql8
- LLM平台:阿里云百炼
- LLL Model:qwen-plus-latest
项目开发环境准备
后端项目准备
- 创建
data_agent项目文件夹,在data_agent目录下创建虚拟Python环境
D:\Code\data_agent>uv venv
D:\Code\data_agent>.venv\Scripts\activate
- 创建依赖文件
requirements.txt,并安装依赖langgraph-cli[inmem] langgraph langchain langchain-core langchain-openai langchain-tavily python-dotenv langsmith pydantic matplotlib seaborn pandas pymysql scikit-learn(data_agent)D:\Code\data_agent>pip install -r requirements.txt - 在本机安装Mysql数据库或者使用云数据库,创建数据库
data_agent,并执行脚本代码,最后记录IP、POERT、Password、DB_name等信息。脚本内容如下,用于构建后续分析助手读取数据库测试数据。-- 创建学校表 CREATE TABLE schools (school_id INT AUTO_INCREMENT PRIMARY KEY,school_name VARCHAR(100) NOT NULL,address VARCHAR(200),phone VARCHAR(20),established_date DATE,is_public BOOLEAN DEFAULT true,created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;-- 创建班级表 CREATE TABLE classes (class_id INT AUTO_INCREMENT PRIMARY KEY,school_id INT NOT NULL,class_name VARCHAR(50) NOT NULL,grade_level INT NOT NULL,head_teacher VARCHAR(50),student_count INT DEFAULT 0,created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,FOREIGN KEY (school_id) REFERENCES schools(school_id) ON DELETE CASCADE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;-- 创建学生表 CREATE TABLE students (student_id INT AUTO_INCREMENT PRIMARY KEY,class_id INT,first_name VARCHAR(50) NOT NULL,last_name VARCHAR(50) NOT NULL,gender ENUM('Male', 'Female', 'Other') NOT NULL,birth_date DATE,email VARCHAR(100),phone VARCHAR(20),address VARCHAR(200),enrollment_date DATE NOT NULL,is_active BOOLEAN DEFAULT true,created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,FOREIGN KEY (class_id) REFERENCES classes(class_id) ON DELETE SET NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;-- 创建课程表 CREATE TABLE courses (course_id INT AUTO_INCREMENT PRIMARY KEY,school_id INT NOT NULL,course_name VARCHAR(100) NOT NULL,description TEXT,credit_hours DECIMAL(3,1) DEFAULT 1.0,is_required BOOLEAN DEFAULT false,created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,FOREIGN KEY (school_id) REFERENCES schools(school_id) ON DELETE CASCADE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;-- 创建学生选课关联表 CREATE TABLE student_courses (id INT AUTO_INCREMENT PRIMARY KEY,student_id INT NOT NULL,course_id INT NOT NULL,enrollment_date DATE NOT NULL,grade DECIMAL(4,2),is_completed BOOLEAN DEFAULT false,created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,FOREIGN KEY (student_id) REFERENCES students(student_id) ON DELETE CASCADE,FOREIGN KEY (course_id) REFERENCES courses(course_id) ON DELETE CASCADE,UNIQUE KEY (student_id, course_id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;-- 插入学校数据 INSERT INTO schools (school_name, address, phone, established_date, is_public) VALUES ('第一高级中学', '北京市海淀区学院路1号', '010-12345678', '1950-09-01', true), ('第二实验中学', '上海市浦东新区张江路2号', '021-23456789', '1985-05-15', true), ('国际外国语学校', '广州市天河区珠江新城3号', '020-34567890', '2000-03-20', false), ('阳光小学', '深圳市南山区科技园4号', '0755-45678901', '1995-08-10', true), ('希望中学', '成都市武侯区人民南路5号', '028-56789012', '1978-11-25', true);-- 插入班级数据 INSERT INTO classes (school_id, class_name, grade_level, head_teacher, student_count) VALUES (1, '高一(1)班', 10, '张老师', 45), (1, '高一(2)班', 10, '李老师', 48), (1, '高二(1)班', 11, '王老师', 42), (2, '初一(1)班', 7, '赵老师', 50), (2, '初二(2)班', 8, '钱老师', 47), (3, '三年级A班', 3, '孙老师', 30), (3, '四年级B班', 4, '周老师', 32), (4, '五年级(1)班', 5, '吴老师', 40), (5, '高三(1)班', 12, '郑老师', 38), (5, '高三(2)班', 12, '冯老师', 36);-- 插入学生数据 INSERT INTO students (class_id, first_name, last_name, gender, birth_date, email, phone, address, enrollment_date, is_active) VALUES (1, '小明', '张', 'Male', '2007-03-15', 'zhangxiaoming@example.com', '13800138001', '北京市海淀区学院路10号', '2023-09-01', true), (1, '小红', '李', 'Female', '2007-05-20', 'lixiaohong@example.com', '13800138002', '北京市海淀区学院路11号', '2023-09-01', true), (2, '小刚', '王', 'Male', '2007-07-10', 'wangxiaogang@example.com', '13800138003', '北京市海淀区学院路12号', '2023-09-01', true), (2, '小丽', '赵', 'Female', '2007-09-25', 'zhaoxiaoli@example.com', '13800138004', '北京市海淀区学院路13号', '2023-09-01', true), (3, '小强', '钱', 'Male', '2006-11-30', 'qianxiaoqiang@example.com', '13800138005', '北京市海淀区学院路14号', '2022-09-01', true), (4, '小花', '孙', 'Female', '2010-01-05', 'sunxiaohua@example.com', '13800138006', '上海市浦东新区张江路20号', '2023-09-01', true), (5, '小杰', '周', 'Male', '2009-04-18', 'zhouxiaojie@example.com', '13800138007', '上海市浦东新区张江路21号', '2022-09-01', true), (6, '小美', '吴', 'Female', '2015-08-12', 'wuxiaomei@example.com', '13800138008', '广州市天河区珠江新城30号', '2023-09-01', true), (7, '小勇', '郑', 'Male', '2014-06-22', 'zhengxiaoyong@example.com', '13800138009', '广州市天河区珠江新城31号', '2022-09-01', true), (8, '小芳', '冯', 'Female', '2013-02-28', 'fengxiaofang@example.com', '13800138010', '深圳市南山区科技园40号', '2023-09-01', true), (9, '小伟', '陈', 'Male', '2006-10-15', 'chenxiaowei@example.com', '13800138011', '成都市武侯区人民南路50号', '2021-09-01', true), (10, '小燕', '褚', 'Female', '2006-12-20', 'chuxiaoyan@example.com', '13800138012', '成都市武侯区人民南路51号', '2021-09-01', true);-- 插入课程数据 INSERT INTO courses (school_id, course_name, description, credit_hours, is_required) VALUES (1, '数学', '高中数学课程', 4.0, true), (1, '语文', '高中语文课程', 4.0, true), (1, '英语', '高中英语课程', 4.0, true), (1, '物理', '高中物理课程', 3.0, false), (1, '化学', '高中化学课程', 3.0, false), (2, '数学', '初中数学课程', 3.0, true), (2, '语文', '初中语文课程', 3.0, true), (2, '英语', '初中英语课程', 3.0, true), (3, '英语', '小学英语课程', 2.0, true), (3, '数学', '小学数学课程', 2.0, true), (4, '语文', '小学语文课程', 2.0, true), (4, '数学', '小学数学课程', 2.0, true), (5, '物理', '高中物理课程', 3.0, false), (5, '化学', '高中化学课程', 3.0, false), (5, '生物', '高中生物课程', 2.0, false);-- 插入学生选课数据 INSERT INTO student_courses (student_id, course_id, enrollment_date, grade, is_completed) VALUES (1, 1, '2023-09-01', 85.5, true), (1, 2, '2023-09-01', 90.0, true), (1, 3, '2023-09-01', 88.0, true), (2, 1, '2023-09-01', 92.5, true), (2, 2, '2023-09-01', 87.0, true), (2, 3, '2023-09-01', 91.5, true), (3, 1, '2023-09-01', 78.0, true), (3, 2, '2023-09-01', 82.5, true), (3, 3, '2023-09-01', 85.0, true), (4, 1, '2023-09-01', 95.0, true), (4, 2, '2023-09-01', 89.5, true), (4, 3, '2023-09-01', 93.0, true), (5, 1, '2022-09-01', 88.0, true), (5, 2, '2022-09-01', 84.5, true), (5, 3, '2022-09-01', 90.0, true), (6, 6, '2023-09-01', 92.0, true), (6, 7, '2023-09-01', 88.5, true), (6, 8, '2023-09-01', 91.0, true), (7, 6, '2022-09-01', 85.0, true), (7, 7, '2022-09-01', 89.0, true), (7, 8, '2022-09-01', 87.5, true), (8, 9, '2023-09-01', 95.0, true), (8, 10, '2023-09-01', 98.0, true), (9, 9, '2022-09-01', 90.0, true), (9, 10, '2022-09-01', 92.5, true), (10, 11, '2023-09-01', 88.0, true), (10, 12, '2023-09-01', 91.5, true), (11, 13, '2021-09-01', 86.0, true), (11, 14, '2021-09-01', 89.5, true), (11, 15, '2021-09-01', 92.0, true), (12, 13, '2021-09-01', 94.0, true), (12, 14, '2021-09-01', 87.5, true), (12, 15, '2021-09-01', 90.5, true); - 创建
.env文件,配置项目需要的配置信息。- 请在阿里云百炼获取
OPENAI_API_KEY和OPENAI_API_BASE。 - 请在openweathermap获取
OPENWEATHER_API_KEY。 - 请在tavily.com/获取
TAVILY_API_KEY
- 请在阿里云百炼获取
LANGSMITH_TRACING="true"
LANGSMITH_ENDPOINT="https://api.smith.langchain.com"
LANGSMITH_API_KEY="lsv2_xxx"
LANGSMITH_PROJECT="data_agent"
OPENAI_API_KEY="sk-xx"
OPENAI_API_BASE="https://dashscope.aliyuncs.com/compatible-mode/v1"
OPENWEATHER_API_KEY="xx"
TAVILY_API_KEY="tvly-xx"
HOST=127.0.0.1
USER=xxx
MYSQL_PW=xxx
DB_NAME=data_agent
PORT=3306
前端项目准备
- 首先本地安装node.js
- 打开Agent Chat UI项目主页,下载项目源码,然后解压到
data_agent目录下。 - 使用管理员运行终端,进入Agent Chat UI项目目录,执行以下命令:
npm install -g pnpm
pnpm -v
pnpm install # 安装前端项目依赖
关键实现代码
- 很多场景下更加细分的外部函数功能,往往会带来更加稳定的查询结果。创建两个外部工具,分别用于执行MySQL数据查询(sql_inter)和MySQL数据库的数据提取(extract_data)。
MySQL数据查询工具sql_inter
# 加载环境变量
load_dotenv(override=True)
host = os.getenv('HOST')
user = os.getenv('USER')
mysql_pw = os.getenv('MYSQL_PW')
db = os.getenv('DB_NAME')
port = os.getenv('PORT')
description = """
当用户需要进行数据库查询工作时,请调用该函数。
该函数用于在指定MySQL服务器上运行一段SQL代码,完成数据查询相关工作,
并且当前函数是使用pymsql连接MySQL数据库。
本函数只负责运行SQL代码并进行数据查询,若要进行数据提取,则使用另一个extract_data函数。
"""# ✅ 定义结构化参数模型
class SQLQuerySchema(BaseModel):sql_query: str = Field(description=description)# ✅ 封装为 LangGraph 工具
@tool(args_schema=SQLQuerySchema)
def sql_inter(sql_query: str) -> str:"""当用户需要进行数据库查询工作时,请调用该函数。该函数用于在指定MySQL服务器上运行一段SQL代码,完成数据查询相关工作,并且当前函数是使用pymsql连接MySQL数据库。本函数只负责运行SQL代码并进行数据查询,若要进行数据提取,则使用另一个extract_data函数。:param sql_query: 字符串形式的SQL查询语句,用于执行对MySQL中telco_db数据库中各张表进行查询,并获得各表中的各类相关信息:return:sql_query在MySQL中的运行结果。 """# print("正在调用 sql_inter 工具运行 SQL 查询...")# 创建连接connection = pymysql.connect(host=host,user=user,passwd=mysql_pw,db=db,port=int(port),charset='utf8')try:with connection.cursor() as cursor:cursor.execute(sql_query)results = cursor.fetchall()# print("SQL 查询已成功执行,正在整理结果...")finally:connection.close()# 将结果以 JSON 字符串形式返回return json.dumps(results, ensure_ascii=False)
MySQL数据提取工具extract_data
# ✅ 定义结构化参数
class ExtractQuerySchema(BaseModel):sql_query: str = Field(description="用于从 MySQL 提取数据的 SQL 查询语句。")df_name: str = Field(description="指定用于保存结果的 pandas 变量名称(字符串形式)。")# ✅ 注册为 Agent 工具
@tool(args_schema=ExtractQuerySchema)
def extract_data(sql_query: str, df_name: str) -> str:"""用于在MySQL数据库中提取一张表到当前Python环境中,注意,本函数只负责数据表的提取,并不负责数据查询,若需要在MySQL中进行数据查询,请使用sql_inter函数。同时需要注意,编写外部函数的参数消息时,必须是满足json格式的字符串,:param sql_query: 字符串形式的SQL查询语句,用于提取MySQL中的某张表。:param df_name: 将MySQL数据库中提取的表格进行本地保存时的变量名,以字符串形式表示。:return:表格读取和保存结果"""print("正在调用 extract_data 工具运行 SQL 查询...")load_dotenv(override=True)host = os.getenv('HOST')user = os.getenv('USER')mysql_pw = os.getenv('MYSQL_PW')db = os.getenv('DB_NAME')port = os.getenv('PORT')# 创建数据库连接connection = pymysql.connect(host=host,user=user,passwd=mysql_pw,db=db,port=int(port),charset='utf8')try:# 执行 SQL 并保存为全局变量df = pd.read_sql(sql_query, connection)globals()[df_name] = df# print("数据成功提取并保存为全局变量:", df_name)return f"✅ 成功创建 pandas 对象 `{df_name}`,包含从 MySQL 提取的数据。"except Exception as e:return f"❌ 执行失败:{e}"finally:connection.close()
Python代码解释器函数python_inter
- Python代码解释器外部工具组,同样是编写两个外部函数,分别用于执行普通的Python代码(python_inter)以及绘图类的代码(fig_inter)。
# Python代码执行工具
class PythonCodeInput(BaseModel):py_code: str = Field(description="一段合法的 Python 代码字符串,例如 '2 + 2' 或 'x = 3\\ny = x * 2'")@tool(args_schema=PythonCodeInput)
def python_inter(py_code):"""当用户需要编写Python程序并执行时,请调用该函数。该函数可以执行一段Python代码并返回最终结果,需要注意,本函数只能执行非绘图类的代码,若是绘图相关代码,则需要调用fig_inter函数运行。""" g = globals()try:# 尝试如果是表达式,则返回表达式运行结果return str(eval(py_code, g))# 若报错,则先测试是否是对相同变量重复赋值except Exception as e:global_vars_before = set(g.keys())try: exec(py_code, g)except Exception as e:return f"代码执行时报错{e}"global_vars_after = set(g.keys())new_vars = global_vars_after - global_vars_before# 若存在新变量if new_vars:result = {var: g[var] for var in new_vars}# print("代码已顺利执行,正在进行结果梳理...")return str(result)else:# print("代码已顺利执行,正在进行结果梳理...")return "已经顺利执行代码"
Python代码解释器函数fig_inter
class FigCodeInput(BaseModel):py_code: str = Field(description="要执行的 Python 绘图代码,必须使用 matplotlib/seaborn 创建图像并赋值给变量")fname: str = Field(description="图像对象的变量名,例如 'fig',用于从代码中提取并保存为图片")@tool(args_schema=FigCodeInput)
def fig_inter(py_code: str, fname: str) -> str:"""当用户需要使用 Python 进行可视化绘图任务时,请调用该函数。该函数会执行用户提供的 Python 绘图代码,并自动将生成的图像对象保存为图片文件并展示。"""print("正在调用fig_inter工具运行Python代码...")current_backend = matplotlib.get_backend()matplotlib.use('Agg')local_vars = {"plt": plt, "pd": pd, "sns": sns}# ✅ 设置图像保存路径(你自己的绝对路径)base_dir = r"C:\Users\Admin\Desktop\LangGraph App\data_agent\agent-chat-ui\public"images_dir = os.path.join(base_dir, "images")os.makedirs(images_dir, exist_ok=True) # ✅ 自动创建 images 文件夹(如不存在)try:g = globals()exec(py_code, g, local_vars)g.update(local_vars)fig = local_vars.get(fname, None)if fig:image_filename = f"{fname}.png"abs_path = os.path.join(images_dir, image_filename) # ✅ 绝对路径rel_path = os.path.join("images", image_filename) # ✅ 返回相对路径(给前端用)fig.savefig(abs_path, bbox_inches='tight')return f"✅ 图片已保存,路径为: {rel_path}"else:return "⚠️ 图像对象未找到,请确认变量名正确并为 matplotlib 图对象。"except Exception as e:return f"❌ 执行失败:{e}"finally:plt.close('all')matplotlib.use(current_backend)
Data Agent后端整体
graph.py
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
from langchain_core.tools import tool
from pydantic import BaseModel, Field
import matplotlib
import json
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import pymysql
from langchain_tavily import TavilySearch# 加载环境变量
load_dotenv(override=True)
host = os.getenv('HOST')
user = os.getenv('USER')
mysql_pw = os.getenv('MYSQL_PW')
db = os.getenv('DB_NAME')
port = os.getenv('PORT')# ✅ 创建Tavily搜索工具
search_tool = TavilySearch(max_results=5, topic="general")# ✅ 创建SQL查询工具
description = """
当用户需要进行数据库查询工作时,请调用该函数。
该函数用于在指定MySQL服务器上运行一段SQL代码,完成数据查询相关工作,
并且当前函数是使用pymsql连接MySQL数据库。
本函数只负责运行SQL代码并进行数据查询,若要进行数据提取,则使用另一个extract_data函数。
"""# 定义结构化参数模型
class SQLQuerySchema(BaseModel):sql_query: str = Field(description=description)# ✅ 创建MySQL数据查询工具 sql_inter
@tool(args_schema=SQLQuerySchema)
def sql_inter(sql_query: str) -> str:"""当用户需要进行数据库查询工作时,请调用该函数。该函数用于在指定MySQL服务器上运行一段SQL代码,完成数据查询相关工作,并且当前函数是使用pymsql连接MySQL数据库。本函数只负责运行SQL代码并进行数据查询,若要进行数据提取,则使用另一个extract_data函数。:param sql_query: 字符串形式的SQL查询语句,用于执行对MySQL中telco_db数据库中各张表进行查询,并获得各表中的各类相关信息:return:sql_query在MySQL中的运行结果。"""print("正在调用 sql_inter 工具运行 SQL 查询...")# 加载环境变量# load_dotenv(override=True)# host = os.getenv('HOST')# user = os.getenv('USER')# mysql_pw = os.getenv('MYSQL_PW')# db = os.getenv('DB_NAME')# port = os.getenv('PORT')# 创建连接connection = pymysql.connect(host=host,user=user,passwd=mysql_pw,db=db,port=int(port),charset='utf8')try:with connection.cursor() as cursor:cursor.execute(sql_query)results = cursor.fetchall()print("SQL 查询已成功执行,正在整理结果...")finally:connection.close()# 将结果以 JSON 字符串形式返回return json.dumps(results, ensure_ascii=False)# ✅ 创建数据提取工具 extract_data
# 定义结构化参数
class ExtractQuerySchema(BaseModel):sql_query: str = Field(description="用于从 MySQL 提取数据的 SQL 查询语句。")df_name: str = Field(description="指定用于保存结果的 pandas 变量名称(字符串形式)。")# 注册为 Agent 工具
@tool(args_schema=ExtractQuerySchema)
def extract_data(sql_query: str, df_name: str) -> str:"""用于在MySQL数据库中提取一张表到当前Python环境中,注意,本函数只负责数据表的提取,并不负责数据查询,若需要在MySQL中进行数据查询,请使用sql_inter函数。同时需要注意,编写外部函数的参数消息时,必须是满足json格式的字符串,:param sql_query: 字符串形式的SQL查询语句,用于提取MySQL中的某张表。:param df_name: 将MySQL数据库中提取的表格进行本地保存时的变量名,以字符串形式表示。:return:表格读取和保存结果"""print("正在调用 extract_data 工具运行 SQL 查询...")# load_dotenv(override=True)# host = os.getenv('HOST')# user = os.getenv('USER')# mysql_pw = os.getenv('MYSQL_PW')# db = os.getenv('DB_NAME')# port = os.getenv('PORT')# 创建数据库连接connection = pymysql.connect(host=host,user=user,passwd=mysql_pw,db=db,port=int(port),charset='utf8')try:# 执行 SQL 并保存为全局变量df = pd.read_sql(sql_query, connection)globals()[df_name] = dfprint("数据成功提取并保存为全局变量:", df_name)return f"✅ 成功创建 pandas 对象 `{df_name}`,包含从 MySQL 提取的数据。"except Exception as e:return f"❌ 执行失败:{e}"finally:connection.close()# ✅创建Python代码执行工具
# Python代码执行工具结构化参数说明
class PythonCodeInput(BaseModel):py_code: str = Field(description="一段合法的 Python 代码字符串,例如 '2 + 2' 或 'x = 3\\n y = x * 2'")@tool(args_schema=PythonCodeInput)
def python_inter(py_code):"""当用户需要编写Python程序并执行时,请调用该函数。该函数可以执行一段Python代码并返回最终结果,需要注意,本函数只能执行非绘图类的代码,若是绘图相关代码,则需要调用fig_inter函数运行。""" g = globals()try:# 尝试如果是表达式,则返回表达式运行结果return str(eval(py_code, g))# 若报错,则先测试是否是对相同变量重复赋值except Exception as e:global_vars_before = set(g.keys())try: exec(py_code, g)except Exception as e:return f"代码执行时报错{e}"global_vars_after = set(g.keys())new_vars = global_vars_after - global_vars_before# 若存在新变量if new_vars:result = {var: g[var] for var in new_vars}print("代码已顺利执行,正在进行结果梳理...")return str(result)else:print("代码已顺利执行,正在进行结果梳理...")return "已经顺利执行代码"# ✅ 创建绘图工具
# 绘图工具结构化参数说明
class FigCodeInput(BaseModel):py_code: str = Field(description="要执行的 Python 绘图代码,必须使用 matplotlib/seaborn 创建图像并赋值给变量")file_name: str = Field(description="图像对象的变量名,例如 'fig',用于从代码中提取并保存为图片")@tool(args_schema=FigCodeInput)
def fig_inter(py_code: str, file_name: str) -> str:"""当用户需要使用 Python 进行可视化绘图任务时,请调用该函数。注意:1. 所有绘图代码必须创建一个图像对象,并将其赋值为指定变量名(例如 `fig`)。2. 必须使用 `fig = plt.figure()` 或 `fig = plt.subplots()`。3. 不要使用 `plt.show()`。4. 请确保代码最后调用 `fig.tight_layout()`。5. 所有绘图代码中,坐标轴标签(xlabel、ylabel)、标题(title)、图例(legend)等文本内容,必须使用英文描述。示例代码:fig = plt.figure(figsize=(10,6))plt.plot([1,2,3], [4,5,6])fig.tight_layout()"""print("正在调用fig_inter工具运行Python代码...")current_backend = matplotlib.get_backend()matplotlib.use('Agg')local_vars = {"plt": plt, "pd": pd, "sns": sns}# ✅ 设置图像保存路径(相对路径)base_dir = os.path.join(os.path.dirname(__file__), "agent-chat-ui", "public")images_dir = os.path.join(base_dir, "images")os.makedirs(images_dir, exist_ok=True) # ✅ 自动创建 images 文件夹(如不存在)try:g = globals()exec(py_code, g, local_vars)g.update(local_vars)fig = local_vars.get(file_name, None)if fig:image_filename = f"{file_name}.png"abs_path = os.path.join(images_dir, image_filename) # ✅ 绝对路径rel_path = os.path.join("images", image_filename) # ✅ 返回相对路径(给前端用)fig.savefig(abs_path, bbox_inches='tight')return f"✅ 图片已保存,路径为: {rel_path}"else:return "⚠️ 图像对象未找到,请确认变量名正确并为 matplotlib 图对象。"except Exception as e:return f"❌ 执行失败:{e}"finally:plt.close('all')matplotlib.use(current_backend)# ✅ 创建提示词模板
prompt = """
你是一名经验丰富的智能数据分析助手,擅长帮助用户高效完成以下任务:1. **数据库查询:**- 当用户需要获取数据库中某些数据或进行SQL查询时,请调用`sql_inter`工具,该工具已经内置了pymysql连接MySQL数据库的全部参数,包括数据库名称、用户名、密码、端口等,你只需要根据用户需求生成SQL语句即可。- 你需要准确根据用户请求生成SQL语句,例如 `SELECT * FROM 表名` 或包含条件的查询。2. **数据表提取:**- 当用户希望将数据库中的表格导入Python环境进行后续分析时,请调用`extract_data`工具。- 你需要根据用户提供的表名或查询条件生成SQL查询语句,并将数据保存到指定的pandas变量中。3. **非绘图类任务的Python代码执行:**- 当用户需要执行Python脚本或进行数据处理、统计计算时,请调用`python_inter`工具。- 仅限执行非绘图类代码,例如变量定义、数据分析等。4. **绘图类Python代码执行:**- 当用户需要进行可视化展示(如生成图表、绘制分布等)时,请调用`fig_inter`工具。- 你可以直接读取数据并进行绘图,不需要借助`python_inter`工具读取图片。- 你应根据用户需求编写绘图代码,并正确指定绘图对象变量名(如 `fig`)。- 当你生成Python绘图代码时必须指明图像的名称,如fig = plt.figure()或fig = plt.subplots()创建图像对象,并赋值为fig。- 不要调用plt.show(),否则图像将无法保存。5. **网络搜索:**- 当用户提出与数据分析无关的问题(如最新新闻、实时信息),请调用`search_tool`工具。**工具使用优先级:**
- 如需数据库数据,请先使用`sql_inter`或`extract_data`获取,再执行Python分析或绘图。
- 如需绘图,请先确保数据已加载为pandas对象。**回答要求:**
- 所有回答均使用**简体中文**,清晰、礼貌、简洁。
- 如果调用工具返回结构化JSON数据,你应提取其中的关键信息简要说明,并展示主要结果。
- 若需要用户提供更多信息,请主动提出明确的问题。
- 如果有生成的图片文件,请务必在回答中使用Markdown格式插入图片,如:
- 不要仅输出图片路径文字。**风格:**
- 专业、简洁、以数据驱动。
- 不要编造不存在的工具或数据。请根据以上原则为用户提供精准、高效的协助。
"""# ✅ 创建工具列表
tools = [search_tool, python_inter, fig_inter, sql_inter, extract_data]# ✅ 创建模型
model = ChatOpenAI(model="qwen-plus-latest")# ✅ 创建图 (Agent)
graph = create_react_agent(model=model, tools=tools, prompt=prompt)
langgraph.json
{"dependencies": ["./"],"graphs": {"data_agent": "./graph.py:graph"},"env": ".env"
}
项目启动
- 在
data_agent虚拟环境下,进入data_agent目录执行graphrag dev即可运行后端部分。 - 使用管理员运行终端,进入Agent Chat UI项目目录,执行以下命令,打开web地址,填写Graph ID和LangSmith API Key进行连接。
npm install -g pnpm pnpm -v pnpm install # 安装前端项目依赖 pnpm dev # 开启Chat Agent UI
测试效果