【菜狗处理脏数据】对很多个不同时间序列数据的文件聚类—20250722
目录
具体做法
可视化方法1:PCA降维
可视化方法2、TSNE降维可视化(非线性降维,更适合聚类)
可视化方法3、轮廓系数评判好坏
每个文件有很多行列的信息,每列是一个驾驶相关的数据,需要对这些文件进行聚类,每个文件代表一个用户的行为。
目标:聚类效果好,将各个用户行为分开。
具体做法
数据预处理
①将每个文件摊平到一行,汇总成为一个很多用户(文件)组成的csv文件。
import os
import pandas as pd# 1. 定义目标文件夹路径
folder_path = "/home/zqy/A_paper/diff_time_norm/cleantime"# 2. 用于存放每个文件(用户)摊平后的数据
flattened_data = []# 3. 遍历文件夹下所有CSV文件
for filename in os.listdir(folder_path):if filename.endswith("truncated.csv"):file_path = os.path.join(folder_path, filename)# 4. 读取CSV文件df = pd.read_csv(file_path)# 5. 将整个DataFrame按行摊平成一维(每行数据拼在一起)# df.values:转为numpy数组,ravel(): 展平flattened_row = df.values.ravel()# 6. 转成List(确保可以加入到汇总列表)flattened_data.append(flattened_row.tolist())# 7. 找到最长的一行长度,补齐其他行
max_length = max(len(row) for row in flattened_data)# 8. 确保所有行都补齐(空位补None或0)
flattened_data_padded = [row + [None] * (max_length - len(row)) for row in flattened_data]# 9. 将所有行转换成DataFrame
summary_df = pd.DataFrame(flattened_data_padded)# 10. 保存到新CSV文件
summary_df.to_csv("/home/zqy/A_paper/diff_time_norm/cleantime/flattened_summary.csv", index=False)print("汇总文件已生成。")
“DataFrame”是Python中pandas库的一个核心数据结构,它类似于Excel中的表格,是一个二维的、大小可变的、异构的数据结构。它由行和列组成,每一列可以存储不同类型的值,比如整数、浮点数、字符串等。在你提到的上下文中,它指的是包含有“数值型”数据的列的表格。
②对汇总后的文件的每一行当中有列表形式的展开处理(因为聚类要求每一列的元素都是数值)
#把多元组的列表转化为多个列import pandas as pd
import astdef expand_list_columns(df):new_cols = []for col in df.columns:if df[col].apply(lambda x: isinstance(x, str) and x.startswith('[') and x.endswith(']')).any():# 将字符串转为列表expanded = df[col].apply(lambda x: ast.literal_eval(x) if isinstance(x, str) else [])max_len = expanded.map(len).max()for i in range(max_len):df[f'{col}_{i}'] = expanded.map(lambda x: x[i] if i < len(x) else None)new_cols.append(col)# 删除原始的列表列df = df.drop(columns=new_cols)return df# 读取CSV
df = pd.read_csv('/home/zqy/A_paper/diff_time_norm/cleantime/flattened_summary.csv')# 转换
df_expanded = expand_list_columns(df)# 保存
df_expanded.to_csv('/home/zqy/A_paper/diff_time_norm/cleantime/expanded_features.csv', index=False)③使用kmeans进行聚类处理。
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt# 1. 读取数据
data_path = "/home/zqy/A_paper/diff_time_norm/cleantime/expanded_features.csv"
df = pd.read_csv(data_path)# 2. 数据预处理(空缺值补0,或用均值/中位数填充)
df_filled = df.fillna(0) # 或 df.fillna(df.mean())# 3. 聚类,这里以KMeans为例,设定聚类数量k
k = 6 # 你可以根据需求调整
kmeans = KMeans(n_clusters=k, random_state=42)
# print(df_filled.dtypes)df_filled = df_filled.fillna(0)clusters = kmeans.fit_predict(df_filled)# 将聚类结果添加回DataFrame
df_filled['cluster'] = clusters# 4. 使用PCA降维到2D便于可视化
pca = PCA(n_components=2)
reduced_data = pca.fit_transform(df_filled.drop('cluster', axis=1))# 5. 可视化
plt.figure(figsize=(8,6))
scatter = plt.scatter(reduced_data[:, 0], reduced_data[:, 1], c=clusters, cmap='viridis', s=50)
plt.title('Clustering Visualization with PCA')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.colorbar(scatter, label='Cluster')
plt.grid(True)
plt.show()
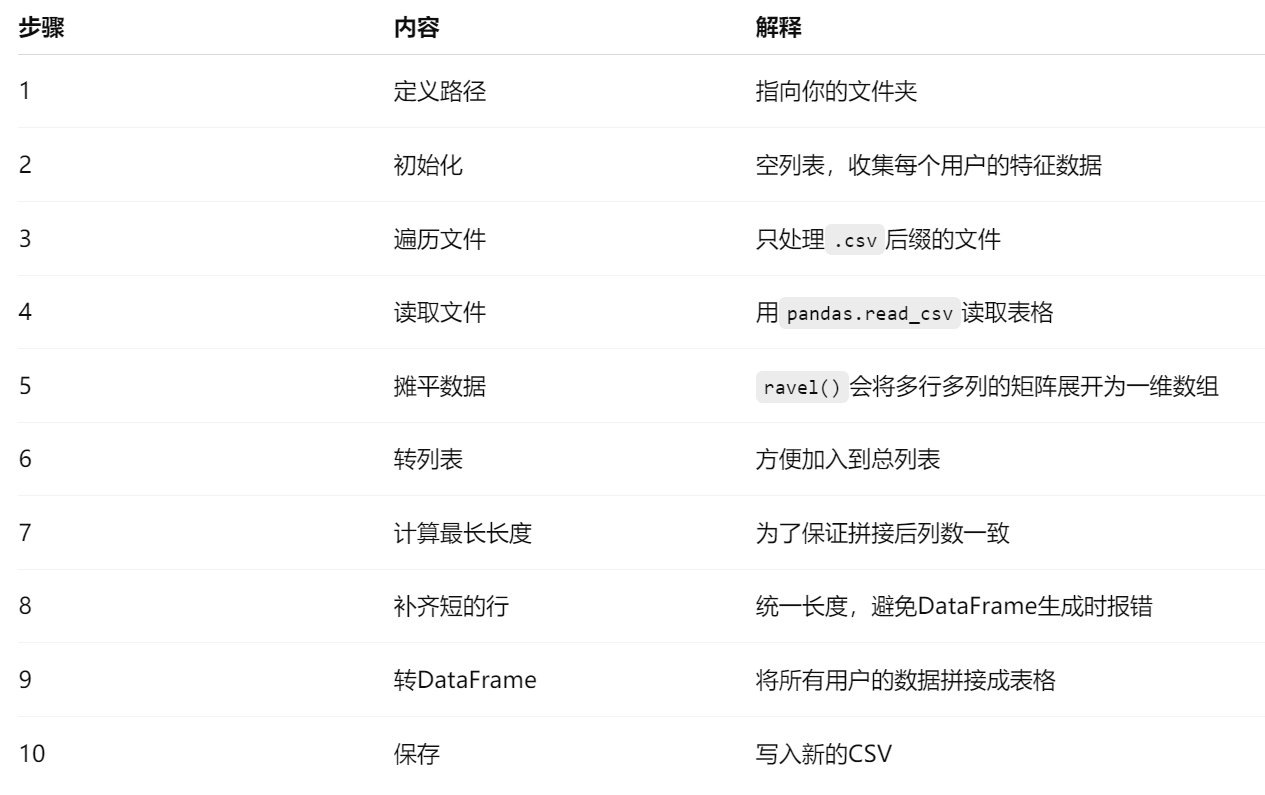
可视化方法1:PCA降维
缺点是只有二维,看不清楚聚类的边界。
pca = PCA(n_components=2)
reduced_data = pca.fit_transform(df_filled.drop('cluster', axis=1))plt.figure(figsize=(8,6))
scatter = plt.scatter(reduced_data[:, 0], reduced_data[:, 1], c=clusters, cmap='viridis', s=50)
plt.title('Clustering Visualization with PCA')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.colorbar(scatter, label='Cluster')
plt.grid(True)
plt.show()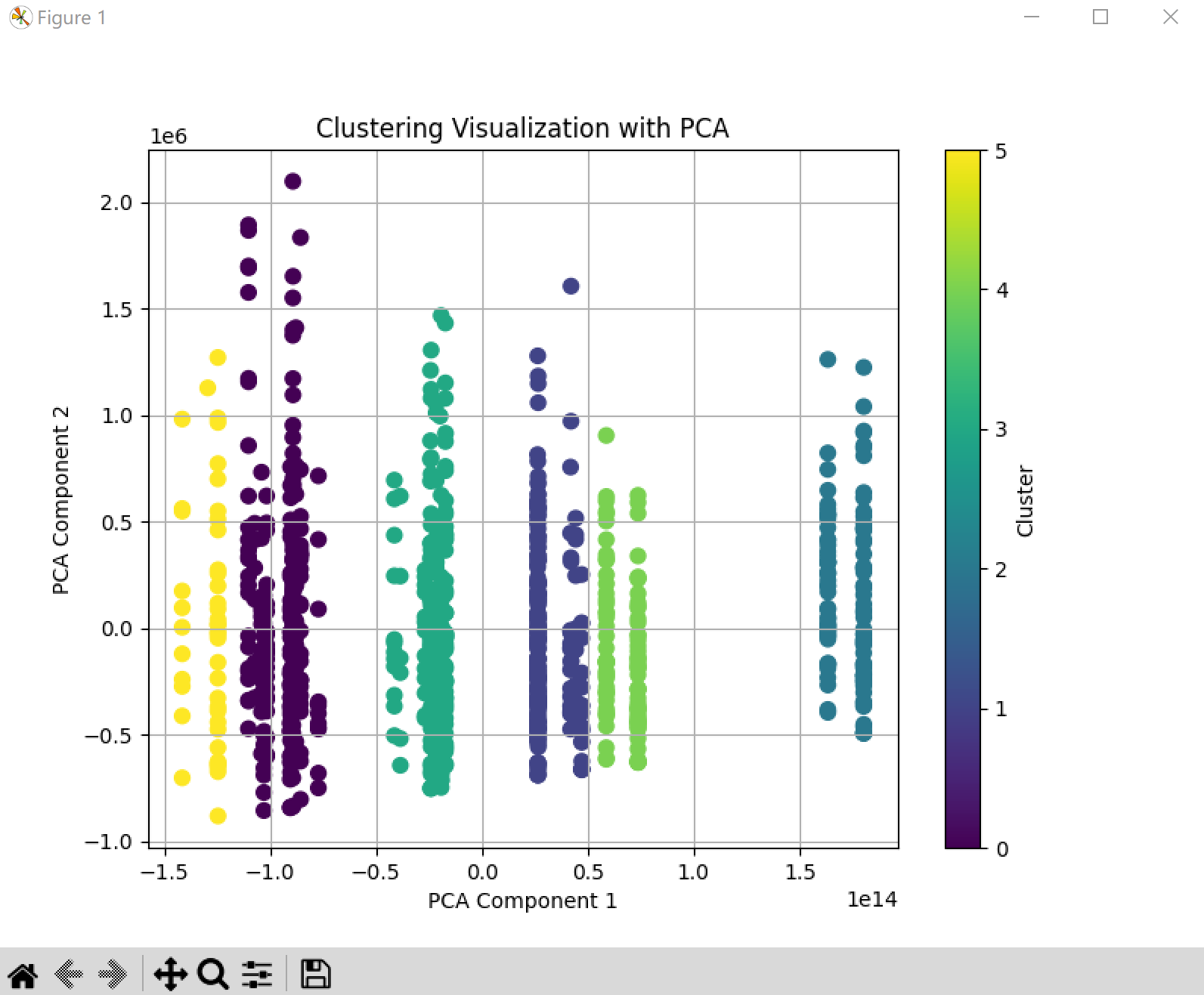
这个图是PCA将维度降低来可视化的方法。
可视化方法2、TSNE降维可视化(非线性降维,更适合聚类)
from sklearn.manifold import TSNEtsne = TSNE(n_components=2, random_state=42, perplexity=30)
tsne_result = tsne.fit_transform(df_filled.drop('cluster', axis=1))plt.figure(figsize=(8,6))
plt.scatter(tsne_result[:,0], tsne_result[:,1], c=clusters, cmap='viridis', s=50)
plt.title('Clustering Visualization with t-SNE')
plt.xlabel('t-SNE Component 1')
plt.ylabel('t-SNE Component 2')
plt.colorbar(label='Cluster')
plt.grid(True)
plt.show()
TSNE 更适合看复杂的、非线性的数据分布。
可视化方法3、轮廓系数评判好坏
from sklearn.metrics import silhouette_scorescore = silhouette_score(df_filled.drop('cluster', axis=1), clusters)
print(f'Silhouette Score: {score}')
结论解释:
-
分数在
-1~1之间 -
接近 1:聚类好,簇内紧凑、簇间分离
-
接近 0:聚类一般
-
接近 -1:聚类效果差
缺点:目前没有考虑不同列数据之间是否有相关性,没有把时间信息充分考虑进来,而是分开每列聚类。并且utime也进行聚类导致效果较好但是不加入效果不够好。
——小狗照亮每一天
20250722