嵌入式学习-PyTorch(5)-day22
卷积层 classtorch.nn.Conv2d
| 参数 | 含义 | 常见用法 |
|---|---|---|
in_channels | 输入特征图的通道数,比如 RGB 图片是 3 | 输入数据的通道数 |
out_channels | 卷积层输出的通道数(卷积核数量) | 控制输出特征图深度 |
kernel_size | 卷积核大小,可以是整数或元组,如 3 或 (3, 3) | 常用 3、5、7 |
stride | 步长,控制卷积核滑动的步幅 | 默认 1,常见 1 或 2 |
padding | 填充,输入的边缘补零数量 | 常用 0、1、'same'(新版本支持) |
dilation | 扩张卷积的膨胀系数 | 默认 1,>1 时用于空洞卷积 |
groups | 分组卷积的分组数 | 默认 1,Depthwise 卷积可设为 groups=in_channels |
bias | 是否加偏置 | 默认 True,大部分情况保留 |
padding_mode | 填充方式,默认 'zeros'(零填充) | 可选 'reflect', 'replicate', 'circular' |
device | 放在哪个设备上初始化(如 'cuda') | 默认 None |
dtype | 张量类型 | 默认 None |
代码:
import torch
import torch.nn as nnconv = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)
输入 3 通道(比如 RGB 图像),输出 16 个通道,卷积核 3x3,padding=1 保证输出尺寸不变。
小贴士:
不加 padding 的话:输出尺寸会变小
stride=2:特征图尺寸减半
groups>1:用来做分组卷积,
groups=in_channels时就是深度可分离卷积(Depthwise)dilation>1:膨胀卷积用来扩大感受野
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#下载测试集
dataset = torchvision.datasets.CIFAR10("./data_CIF", train=False, transform=torchvision.transforms.ToTensor(),download=True)
#打包为每次64张
dataloader = DataLoader(dataset, batch_size=64)
#创建一个神经网络框架
class Tudui(nn.Module):def __init__(self):super().__init__()#框架中的步骤self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)def forward(self, x):#训练顺序x = self.conv1(x)return xtudui = Tudui()
#tensorboard保存地址
writer = SummaryWriter("./logs")
count = 0
for data in dataloader:#将data中的img取出来img, target = data#训练前的img写到tensorboard上writer.add_images("input", img, count)#img进行训练output = tudui(img)#将输出层数从6变成3,为了不报错而已output = torch.reshape(output, (-1,3,30,30))# 训练的结果写到tensorboard上writer.add_images("output",output,count)count += 1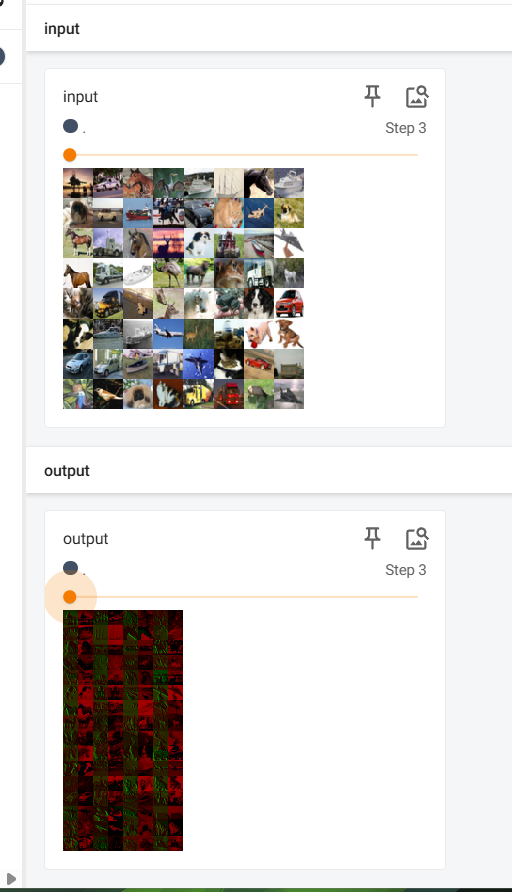
池化层 torch.nn.MaxPool2d
池化层(Pooling Layer)是卷积神经网络(CNN)中的一种下采样(subsampling 或 downsampling)操作,主要作用是降低特征图的尺寸,减少计算量,控制过拟合,同时保留关键特征。
常见池化方式
| 类型 | 特点 | 举例 |
|---|---|---|
| 最大池化 Max Pooling | 取池化窗口内的最大值,保留最显著特征 | 常见于图像分类,如nn.MaxPool2d |
| 平均池化 Average Pooling | 取池化窗口内的平均值,平滑特征 | 常用于特征平滑、稀疏特征 |
| 全局平均池化 Global Average Pooling | 直接对整个特征图求平均,常用于分类器前一层 | nn.AdaptiveAvgPool2d(1) |
为什么要用池化层 💡
降低特征维度:减少后续层的计算量
增加感受野:通过池化,模型感知更大范围的信息
特征平移不变性:小范围位移不会改变池化结果,增强模型的鲁棒性
抑制过拟合:减少模型复杂度,有轻微的正则化效果
池化层工作原理示意
假设输入特征图为 4×4:
1 3 2 4
5 6 1 2
7 2 8 3
4 5 9 0
使用 2×2 的最大池化,步长 2:
第一个窗口 [1,3,5,6] → 最大值 6
第二个窗口 [2,4,1,2] → 最大值 4
第三个窗口 [7,2,4,5] → 最大值 7
第四个窗口 [8,3,9,0] → 最大值 9
输出结果是:
6 4
7 9
👉 尺寸从 4×4 变为 2×2。
一句话总结
池化层=信息压缩器📉,帮你更快更稳地提取重要特征。理解了卷积是特征提取,池化就是特征精炼!
#nn_maxpool.pyimport torch
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#读取数据
dataset = torchvision.datasets.CIFAR10(root='./data_CIF', train=False, download=True,transform=torchvision.transforms.ToTensor())
#将64张照片为一批
dataloader = DataLoader(dataset, batch_size=64)
#创建一个框架
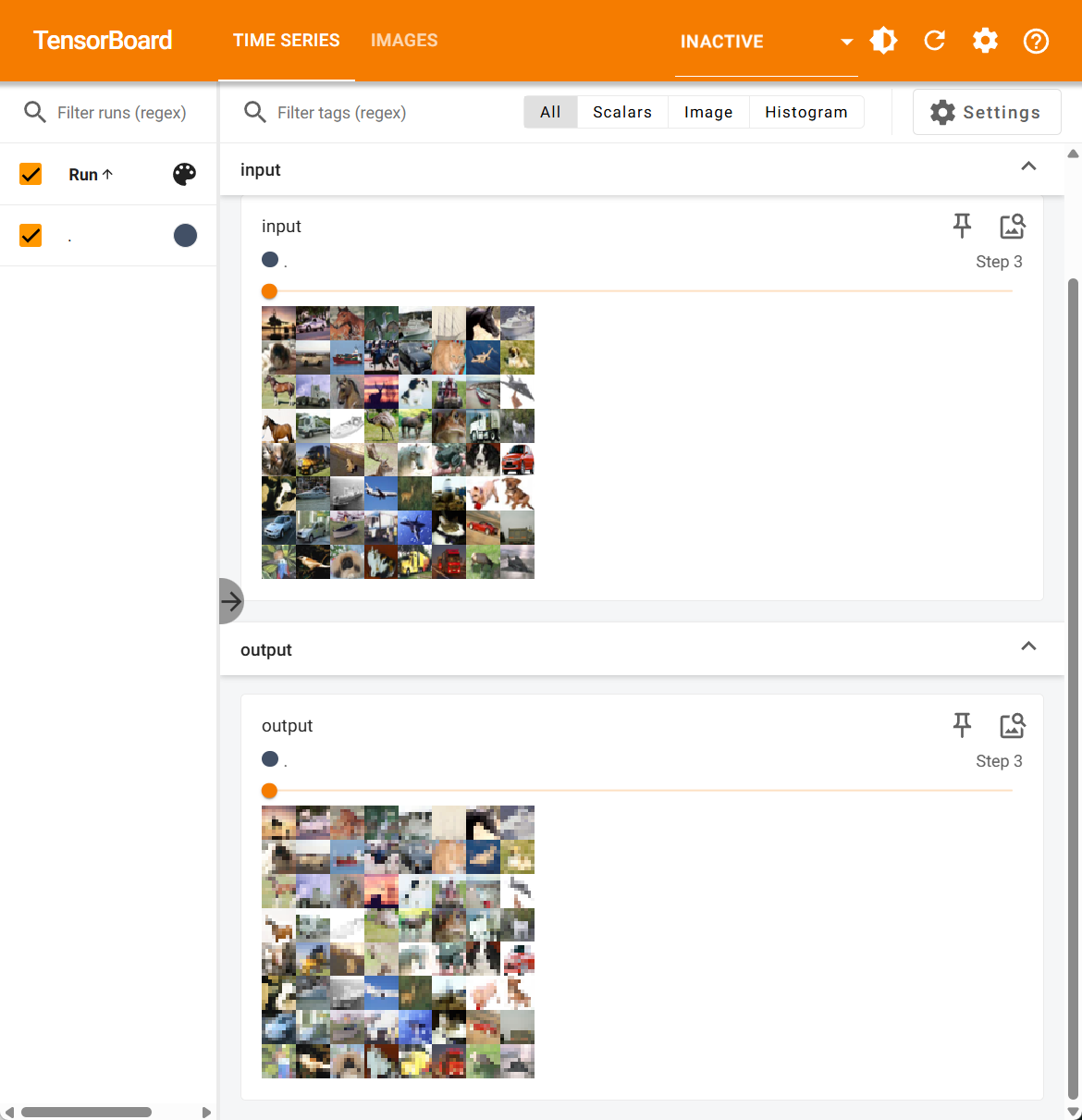
class Tudui(nn.Module):def __init__(self):super().__init__()#定义池化层self.MaxPool = nn.MaxPool2d(kernel_size=3, ceil_mode=False)def forward(self, x):#将x经过池化层后返回给outputoutput = self.MaxPool(x)return outputtudui = Tudui()
#建一个tensorboard文件
writer = SummaryWriter("./logs_maxpool")
count = 0
for data in dataloader:img, target = datawriter.add_images("input", img, count)#将img传给神经网络output = tudui(img)writer.add_images("output", output, count)count += 1writer.close()
结果如下:
非线性激活函数 Non-linear Activations
非线性激活函数(Non-linear Activations),是神经网络的“灵魂”,没有它们,整个网络就只是一堆线性组合,哪怕你叠 100 层卷积,本质还是“线性映射”,根本学不了复杂特征!
为什么要用非线性激活?
因为现实世界是非线性的📈!比如:
识别猫和狗,不是简单加加减减就能分开;
预测房价、翻译语言,特征之间关系很复杂。
激活函数引入非线性,帮助网络逼近任意复杂函数,才真正拥有“智能”。
PyTorch 中常见非线性激活函数
| 函数 | 名字 | 特点 |
|---|---|---|
| ReLU | nn.ReLU() | 最常用,正数直接输出,负数输出 0,速度快,收敛快 |
| Sigmoid | nn.Sigmoid() | 输出 (0,1),适合二分类,但有梯度消失问题 |
| Tanh | nn.Tanh() | 输出 (-1,1),比 Sigmoid 对称一点,但梯度也可能消失 |
| LeakyReLU | nn.LeakyReLU() | 负数也给一个小斜率,避免“神经元死亡” |
| PReLU | nn.PReLU() | LeakyReLU 的升级版,负斜率可训练 |
| ELU | nn.ELU() | 负数部分平滑衰减,训练更稳健 |
| Softmax | nn.Softmax() | 输出概率分布,常用于分类的最后一层 |
| LogSoftmax | nn.LogSoftmax() | 取 softmax 的 log 值,常配合 nn.NLLLoss() 使用 |
常见用法 🎯
import torch.nn as nn
# ReLU激活
relu = nn.ReLU()
# 二分类Sigmoid
sigmoid = nn.Sigmoid()
# 多分类Softmax
softmax = nn.Softmax(dim=1) # 注意要指定dim # 用法
output = relu(input)网络结构中的位置
通常用法:
nn.Sequential(nn.Linear(128, 64),nn.ReLU(),nn.Linear(64, 32),nn.ReLU(),nn.Linear(32, 10),nn.Softmax(dim=1) # 只有最后一层用softmax
)👉 特征提取层 + 激活 = 能学到深层次的特征
🌟 一句话总结:
非线性激活函数=大脑的“反射弧”,让神经网络会“拐弯”!
选对激活函数,训练速度飞起,效果也更稳。
import torch
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10(root='./data_CIF', train=False, download=True, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
#创建一个框架
class Tudui(nn.Module):def __init__(self):super().__init__()#定义了relu和sigmod函数self.relu1 = nn.ReLU()self.sigmod1 = nn.Sigmoid()def forward(self, x):#只使用sigmod函数output = self.sigmod1(x)return outputtudui = Tudui()
writer = SummaryWriter("logs_relu")count = 0
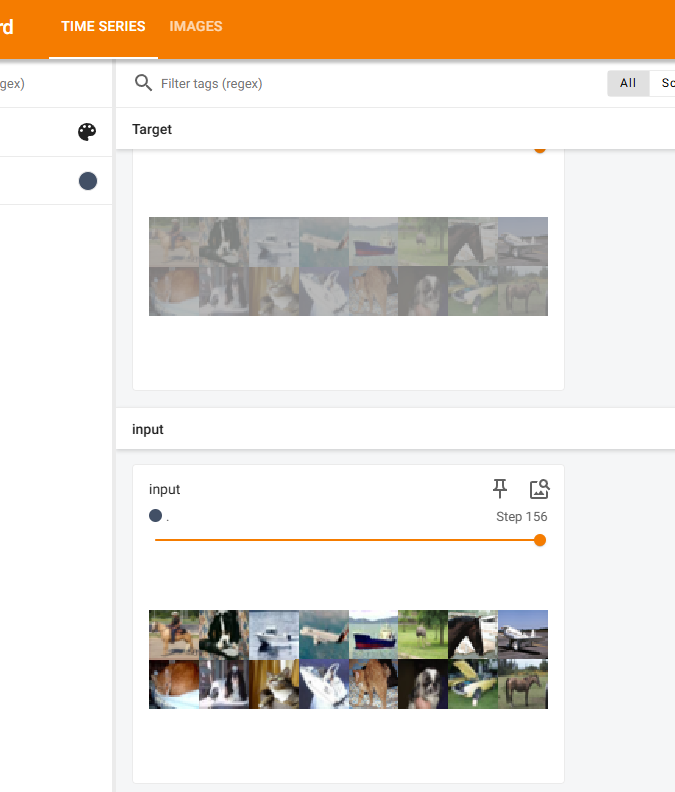
for data in dataloader:img,target = data#将照片送入框架output = tudui(img)writer.add_images("input", img, count)writer.add_images("Target", output, count)count += 1
writer.close()结果: