数字ic后端设计从入门到精通11(含fusion compiler, tcl教学)全定制设计入门
数字ic全定制设计流程
| 步骤 | 名称 | 主要内容 | 设计目标 | 输出结果 |
|---|---|---|---|---|
| 1 | 功能描述 | 明确设计要求:性能、面积、功耗、端口等;采用 HDL 或文档形式对功能进行描述。 | 确定顶层设计需求和规格 | 功能规格说明书、HDL 描述 |
| 2 | 模块划分 | 按照功能将整个系统划分为多个子模块,明确各模块功能及接口关系,实现层次化、模块化设计。 | 提高设计可管理性和可重用性 | 模块划分图、模块接口定义 |
| 3 | 模块电路设计 | 设计每个模块的具体电路结构,确定晶体管尺寸,完成功能仿真与 SPICE 仿真,验证功能与时序。 | 实现正确、高效、低功耗的电路 | 电路原理图、SPICE 网表、仿真报告 |
| 4 | 模块版图布局规划与实现 | 根据电路图绘制物理版图,合理布局各器件,注意寄生效应影响,并通过 DRC、ERC、LVS 验证。 | 实现与电路一致的物理设计 | 物理版图、GDSII 初稿、验证报告 |
| 5 | 模块版图模拟仿真 | 对完成的版图进行寄生参数提取,进行后仿真(时序、功耗等),根据结果迭代优化电路或版图。 | 确保最终设计满足所有指标 | 参数提取网表、后仿真报告、最终 GDSII 文件 |
📝 补充说明:
- DRC(Design Rule Check):检查版图是否符合制造工艺的设计规则。
- ERC(Electrical Rule Check):检查电气连接是否符合规范。
- LVS(Layout Versus Schematic):比对版图与电路图是否一致。
- GDSII:用于流片的标准版图数据格式。
不同文件类型在集成电路设计流程中的角色、提供者、使用者以及它们的应用阶段
| 文件类型 | 提供者 | 使用者 | 应用阶段/描述 |
|---|---|---|---|
| TLEF (Technology LEF) | 工艺厂商 | EDA工具(APR团队)、全定制团队 | 阶段: 物理设计前期;描述: 包含工艺技术相关的物理信息,如金属层信息,方向、电阻、电容、宽度、间距、包围,通孔,通孔规则,用于指导布局布线工具了解制造工艺特性。 |
| LEF (Library Exchange Format) | 标准单元库供应商、工艺厂商 | EDA工具(APR团队)、全定制团队 | 阶段: 物理设计前期;描述: 包含标准单元库的物理信息(如尺寸、引脚位置),用于自动布局布线。 |
| DEF (Design Exchange Format) | APR团队 | APR工具、EDA厂商、全定制团队 | 阶段: 布局布线阶段;描述: 描述模块的位置、连线等信息,用于指导和记录物理设计的具体实现。 |
| LIB/NLIB (Library) | 工艺厂商、标准单元库供应商 | Timing团队、Power团队、EDA工具 | 阶段: 设计验证阶段;描述: 包含标准单元库的时序、功耗等电气特性,用于静态时序分析和功耗分析。 |
| SDC (Synopsys Design Constraints) | IC前端团队 | Timing团队、APR团队、EDA工具 | 阶段: 综合至物理设计全程;描述: 定义设计的时序约束、I/O延迟、多周期路径等,确保设计满足时序要求。 |
| GDSII | 全定制团队 | 工艺厂商 | 阶段: 最终输出阶段;描述: 标准的版图数据格式,包含所有层次化的几何形状和文本注释,是提交给代工厂进行制造的最终文件格式。 |
补充说明:
- 工艺厂商:主要负责提供制造所需的技术文档和支持,包括TLEF、LEF、LIB/NLIB等文件。
- EDA厂商:开发并提供各种用于设计和验证的软件工具,支持处理上述多种格式的文件,如Cadence、Synopsys等。
- 全定制团队:专注于特定电路的设计与优化,通常涉及从RTL到GDSII的全流程,特别是对于关键模块的设计和优化。
- APR团队:负责将逻辑设计转换为物理实现,使用LEF、DEF等文件进行自动布局布线。
- Timing团队:利用LIB/NLIB文件中的时序模型及SDC文件中的约束条件进行静态时序分析,确保设计满足时序要求。
- Power团队:基于LIB/NLIB文件中的功耗模型和SDC中的电源约束进行功耗分析和优化。
- IC前端团队:负责RTL级的设计与验证,生成的RTL代码经过综合后形成网表,并连同SDC文件传递给后端团队。
详细解释:
- TLEF:提供了工艺技术层面的信息,比如金属层数、最小宽度等,这对于理解如何构建物理设计至关重要。
- LEF:虽然与TLEF相似,但它更多关注的是具体的标准单元库的物理属性,如每个单元的尺寸、引脚位置等。
- DEF:在完成布局布线后生成,它记录了所有组件的实际位置及其互连关系。
- LIB/NLIB:这些文件包含了关于标准单元库的详细信息,如延时、功耗等,对于性能评估非常关键。
- SDC:定义了设计的约束条件,包括时钟频率、输入输出延迟等,确保设计符合预期的功能和性能指标。
- GDSII:这是最终提交给晶圆厂用于生产的文件,包含了所有的版图信息。
宏、标准单元与IP核的区别
| 特性 | 宏 (Macro) | 标准单元 (Standard Cell) | IP (Intellectual Property) 核 |
|---|---|---|---|
| 定义 | 预先设计好的较大规模电路模块,如存储器、PLL等。 | 基本逻辑功能单元的集合,如与门、或门、触发器等。 | 经过验证的功能模块或子系统,可以是软核、硬核或固核。 |
| 复杂度 | 高,包含多个逻辑门或模拟电路组件。 | 低至中等,单一逻辑功能。 | 可变,从简单的功能模块到复杂的处理器核心不等。 |
| 布局灵活性 | 固定,不可更改。 | 灵活,可根据需要自由布置。 | 视类型而定,硬核固定,软核灵活。 |
| 用途 | 特定功能模块,如嵌入式存储器、锁相环等。 | 构建任意逻辑电路的基础单元。 | 提供特定功能,如USB控制器、以太网MAC等。 |
| 面积 | 较大,占用较多芯片面积。 | 相对较小,单个单元占据空间小。 | 取决于具体IP核的大小和复杂度。 |
| 优化程度 | 针对特定应用优化,性能、功耗等方面表现优异。 | 通用设计,注重灵活性和标准化。 | 针对特定应用优化,性能、功耗等方面表现优异。 |
| 设计阶段 | 后端设计阶段,通常在自动布局布线时使用。 | 后端设计阶段,用于实现数字逻辑功能。 | 前端或后端设计阶段,根据IP核类型不同。 |
| 示例 | SRAM, PLL, ADC/DAC | AND gate, OR gate, Flip-flop | USB controller, Ethernet MAC, CPU core |
| 提供者 | 工艺厂商、第三方供应商 | 工艺厂商、EDA工具供应商 | 第三方IP供应商、内部开发团队 |
| 使用者 | 全定制团队、APR团队 | APR团队、全定制团队 | IC前端团队、全定制团队、APR团队 |
| 集成方式 | 作为黑盒插入到设计中 | 通过综合工具生成网表并进行布局布线 | 软核通过RTL代码集成,硬核通过GDSII文件集成 |
| 可修改性 | 不可修改 | 可根据设计需求自由选择和组合 | 软核可修改,硬核和固核不可修改 |
补充说明
-
宏:主要用于实现特定功能的大规模电路模块,具有固定的布局和较高的复杂度。它们通常由工艺厂商或第三方供应商提供,并直接用于后端设计流程。
-
标准单元:是构成数字电路的基本单元,包括各种逻辑门和触发器等。这些单元的高度一致,便于自动化工具进行布局布线,适用于构建任意逻辑电路。
-
IP核:指的是经过验证的功能模块或子系统,分为软核(Soft IP,以RTL形式提供)、硬核(Hard IP,以GDSII格式提供)和固核(Firm IP,介于软核和硬核之间)。IP核提供了高度复用性和可靠性,广泛应用于集成电路设计中。
📚 数字IC全定制设计中使用的主流EDA工具分类表
| 工具分类 | 工具名称 | 所属公司 | 主要用途 | 使用阶段 |
|---|---|---|---|---|
| 主流电路和版图设计工具 | Cadence Virtuoso | Cadence | 提供模拟、混合信号、RF及定制数字设计平台,集成多种设计模块 | 全流程使用,尤其在电路与版图设计阶段 |
| 主流电路仿真工具 | Synopsys HSPICE | Synopsys | 高精度晶体管级电路仿真,广泛用于验证功能与时序 | 模块电路设计阶段 |
| 主流电路仿真工具 | Cadence Spectre | Cadence | 适用于模拟、数模混合、存储器、SoC等领域的电路仿真 | 模块电路设计与后仿真阶段 |
| 主流波形分析工具 | Synopsys Cosmos-Scope | Synopsys | 图形化波形查看与分析工具,支持脚本自动化处理仿真数据 | 后仿真结果分析阶段 |
| 主流时序特征化工具 | Synopsys NanoTime | Synopsys | 晶体管级静态时序分析工具,生成.lib文件用于IP集成后的时序检查 | 特征化建模与库生成阶段 |
| 主流抽象信息提取工具 | Cadence Abstract Generator | Cadence | 提取单元物理信息,生成抽象模型用于布局布线优化 | 布局前准备阶段 |
| 主流特征化建模工具 | Cadence Encounter Library Characterizer | Cadence | 自动生成时序库,支持ECSM/CCS模型进行多电压/噪声建模 | 库生成与特征化阶段 |
| 主流特征化建模工具 | Synopsys Liberty NCX | Synopsys | 支持多工艺/电压/温度条件下的时序特征化建模 | 库生成与特征化阶段 |
| 主流寄生参数提取工具 | Cadence QRC Extraction | Cadence | 提取全芯片寄生参数,支持45nm以下先进工艺节点 | 版图后仿真准备阶段 |
| 主流寄生参数提取工具 | Synopsys Star-RCXT | Synopsys | 业界标准寄生参数提取工具,支持变化感知、光刻感知提取 | 版图后仿真准备阶段 |
| 主流寄生参数提取工具 | Mentor Calibre xRC | Mentor (Siemens) | 支持晶体管级、门级和混合级别的寄生参数提取,输出多种网表格式 | 版图后仿真准备阶段 |
| 主流物理验证工具 | Synopsys Hercules | Synopsys | 物理验证工具,支持DRC/LVS,适用于大规模设计 | 物理验证阶段 |
| 主流物理验证工具 | Mentor Calibre | Mentor (Siemens) | 完整的实体验证解决方案,包括DRC、LVS等 | 物理验证阶段 |
模块版图模拟仿真阶段:
特征化建模与库生成 主要发生在此阶段。
在完成版图后,需要对版图进行寄生参数提取,并基于这些提取的数据进行详细的后仿真(包括时序分析、功耗分析等)。
特征化建模工具 如Cadence Encounter Library Characterizer或Synopsys Liberty NCX用于生成标准单元库(.lib文件),这些库包含了单元的时序、功耗和其他电气特性模型。
这些库文件被用于静态时序分析(STA)、功耗分析等后端验证步骤,以确保设计满足所有设计指标。
🧩 小贴士:工具在流程中的位置参考
| 设计阶段 | 对应工具示例 |
|---|---|
| 功能描述 & 模块划分 | ——(人工或文档为主) |
| 模块电路设计 | Virtuoso, HSPICE, Spectre, Cosmos-Scope |
| 版图实现 | Virtuoso Layout Editor, Abstract Generator |
| 寄生参数提取 | QRC, Star-RCXT, Calibre xRC |
| 时序建模与特征化 | NanoTime, Encounter Lib Char., Liberty NCX |
| 物理验证 | Hercules, Calibre |
| 最终交付 | GDSII导出(由Virtuoso / Calibre完成) |
标准单元的基本类型
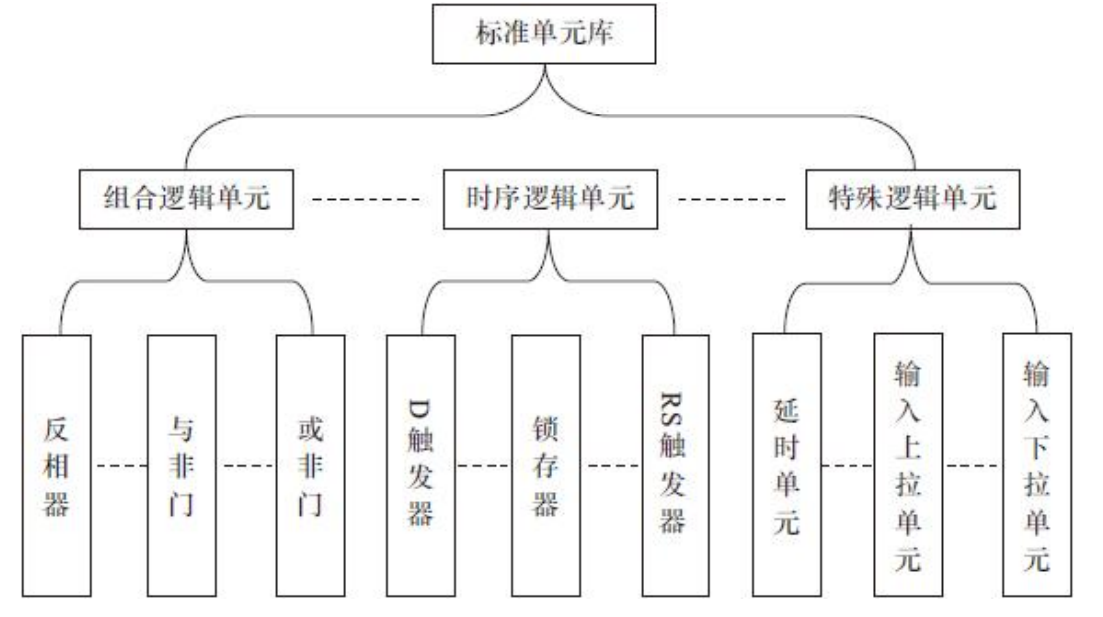
标准单元设计参数
标准单元物理参数
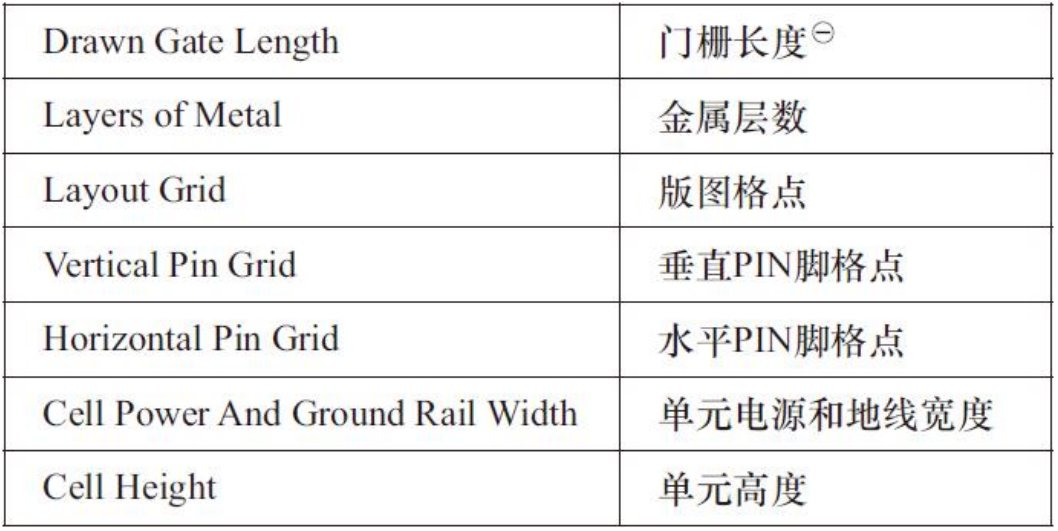
1)门栅长度(Drawn gate length)。该参数用于说明该标准单元的栅长度,一般是指工艺大小,比如0.13μm、0.028μm。
2)金属层数(Layers of metal)。该参数用于说明标准单元库所在的工艺下,能使用的金属层数。
3)版图格点(Layout grid)。该参数用于说明标准单元版图可编辑的最小间距,比如0.005μm。
4)垂直PIN脚格点(Vertical PIN grid)。该参数用于说明垂直走线方向上PIN脚的格点间距是多少。在标准单元设计方法中,大多数的布局布线工具能够对位于格点上的PIN脚进行高效地端口连接,
因此所有标准单元的PIN脚应该位于垂直和水平格点上,关于格点的概念会在后面章节中说明。
5)水平PIN脚格点(Horizontal PIN grid)。该参数用于说明水平走线方向上PIN脚的格点间距是多少。
1标准单元的高度由 Site 高度决定
2标准单元的水平PIN脚格点应与 Site 的高度匹配
3垂直PIN脚格点应与 Site 的宽度(如果非统一宽度)或 Track Pitch 对齐
4所有标准单元的 PIN 脚必须对齐到 Site 的格点系统,以确保在布局布线时不会出现错位
6)单元电源和地线宽带(Cell power and ground rail width)。该参数用于说明标准单元所用电源地线的宽度。
7)单元高度(Cell height)。该参数用于说明标准单元的高度,主要说明该高度能包含多少水平方向上的布线通道数。
格点设置
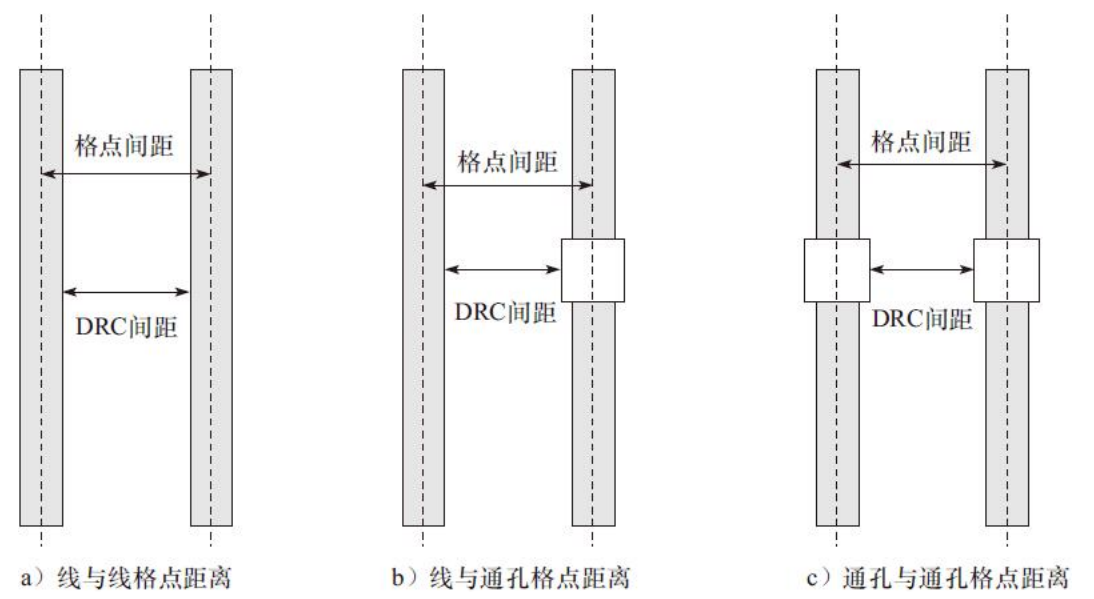
当通孔的面积大于金属线宽的时候,通孔与通孔距离所利用的走线资源比前面两种格点间距的定义方法要少,但是却能很好地解决前面两种格点间距无法解决的最小间距DRC问
题。定义格点间距满足通孔与通孔距离后,布局布线工具可以非常灵活地在走线资源的任何位置进行金属线层与层之间的连接并不会出现最小间距DRC问题。
单元功耗分析
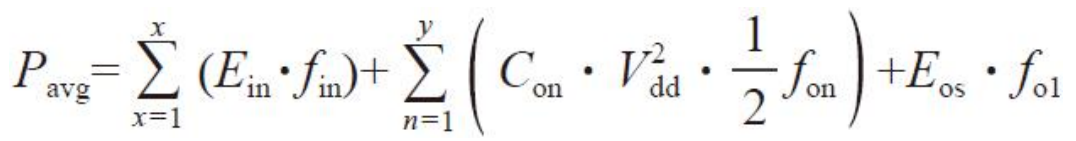
式中 Pavg——平均功耗;
x——输入管脚的数量;
y——输出管脚的数量;
Ein——对应输入管脚消耗的与开关频率相关的单位功耗;
fin——在正常工作频率下输入管脚的开关频率;
Con——某输出管脚的外部负载,包括所有输出管脚与输出驱动相连的电容、外加的布线金属走线电容、实际或预估的负载;
Vdd——实际工作的理想电压;
fon——在正常工作频率下输出管脚的开关频率;
Eos——输出管脚所消耗的与开关频率相关的单位功耗。
通过门级模拟器对典型的输入管脚进行模拟并测量所有相关节点的变化结果来获得单元输入管脚与特殊单元输出管脚的开关频率。总的平均功耗通过把所有端口的平均功耗相加而得。
标准单元设计流程
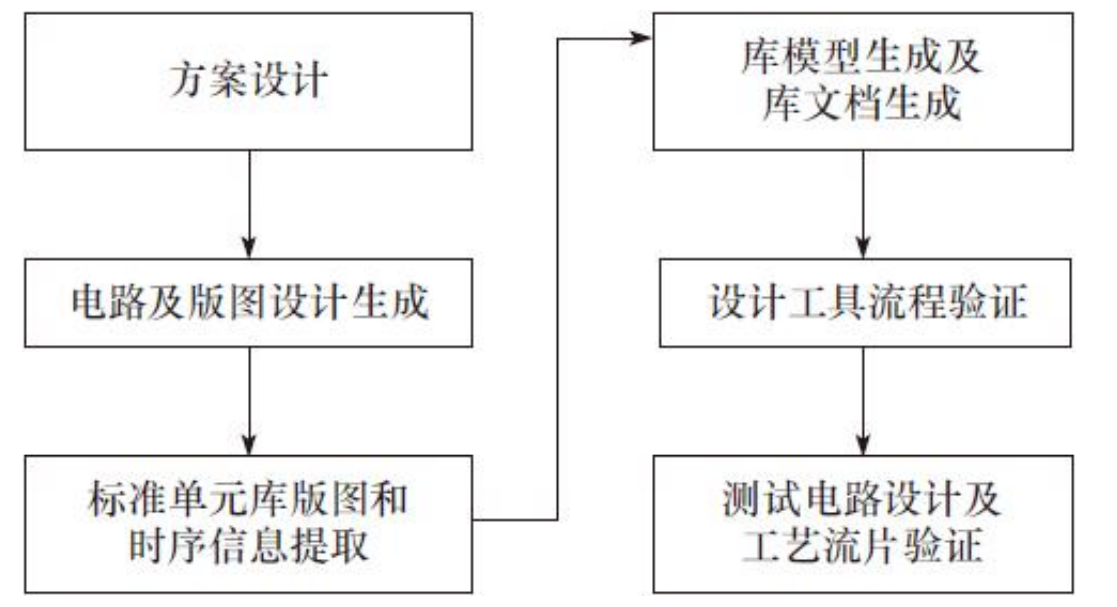
1)方案设计。根据设计需求确定设计目标和实现方案。
2)电路及版图设计生成。标准单元库的主要参数定义后,就需要对各个种类的单元进行电路设计和版图实现。
3)标准单元库版图和时序信息提取。标准单元设计完成了单元的Schmatic和Layout视图后,通过对版图和时序信息进行提取才能被多种EDA工具所识别和使用。
4)库模型生成及库文档生成。标准单元库版图和时序信息都提取完成以后,就可以进行相关数据的整理和归纳,供后续设计使用。
5)设计工具流程验证。标准单元库的数据都准备好了以后,就可以供相关EDA工具使用,验证其数据在设计实现流程中是否可用。
6)测试电路设计及工艺流片验证。测试电路设计主要包括功能验证电路、工作频率测试电路、建立/保持时间测试电路、恢复/移除时间测试电路以及制定测试方案。
方案设计
标准单元电源/地线宽度的确定
可以通过下面3种设计建议的方法来预估和确定。
1)直接参考工艺厂家的标准单元库进行定义。如果在本工艺下有相应工艺厂家的标准单元库,可以直接套用该标准单元中电源/地线的宽度。
2)基于标准单元仿真实验数据进行定义。根据仿真实验数据自行定义标准单元库电源/地线的宽度,确定电源/地线宽度的基本建议方法如下:
电迁移依赖于导体中电流的大小,而电迁移敏感的单元像输出缓冲器和时钟发生器一样的大驱动器。在确定标准单元的物理设计规范前,在大范围温度、供电电压、信号斜率和工艺偏差内对大驱动能力单元进行模拟,以获得流过单元电源地网络的导线电流的预估最大值,同时结合流片厂家的电流密度规则决定电源和地网络导线的最小宽度。
电源地网络导线最小宽度在不同的测试条件下取最大的。
3)基于设计所预估的总功耗和面积信息来定义。下面的设计建议通过一些简单的假设提供比较粗略的预估,假设标准单元的电源线与金属层2的电源条带(stripe)连接。
假定的参数说明如下:
Iavg——设计中的总平均电流,该值通过预估的总功耗计算得到;
dm1——金属层1能够允许的最大电流密度;
dm2——金属层2能够允许的最大电流密度;
Im1——水平方向上的金属层1可以提供的最大电流;
Istrap——金属层1电源线总共需要提供的最大电流;
Wm2——实现垂直电源带的金属层2的宽度;
r——实现垂直金属层2电源带的数目;
c——设计中标准单元电源线的预估总行数;
Wm1——金属层1作为电源线的宽度。
标准单元高度的确定
1)如果在当前工艺下,有相应工艺厂家的标准单元库,可以直接套用该标准单元的高度。
2)可以根据实验数据自行定义标准单元库高度,下面推荐的基本粗略预估思路如下:
由于电子的载流子迁移率大于空穴的载流子迁移率(一般是两倍多),所以P管宽度一般比N管大,而或非门是N管并联,P管串联。
在通用的标准单元库中,单倍四输入的或非门是所有单元中N管有源区最高的(五输入甚至更多的就选用输入最多的或非门),所以假设通过一个四输入NORX1门(保证有源区没有折叠管的最大值),通过固定的N管X1尺寸来确定P管非折叠高度,最终确定最小单元高度。
最后根据版图设计规则和布线要求得到水平布线通道值后,结合四输入NOR门的高度最终确定单元高度等于几条布线通道值。通过对多个工艺下标准单元布线通道值的分析,一般的取值为7-15,所以标准单元的高度在通过或非门计算后,需尽量达到拥有7~15个布线通道的高度。
标准单元驱动强度的设置
一般的逻辑单元都设计了至少四种不同驱动能力的单元:半倍驱动能力的低功耗单元、常用的单倍驱动能力单元、速度更快的2倍驱动能力单元和4倍驱动能力单元,用来满足不同的设计需要。而常用的反相器和时钟缓冲器设计了更多的驱动能力单元。其中,反相器一般会设计10种不同驱动能力的单元,用于时钟树的时钟反相器和缓冲器会设计从半倍到二十倍之间不同驱动能力的单元。
三种定义驱动强度的粗略方法
1)零负载与倍数尺寸。该种驱动能力的定义方法首先是设定输出负载为0,即通过本征延时数据来定义不同驱动能力的单元。以N管最小尺寸为基数,通过扩大基数整数倍的尺寸定义相应的驱动单元(即尺寸通过以最后一级晶体管的最小尺寸为基数,再乘以一个倍数来定义驱动能力),同时按照设计要求规定上升和下降延时的最大偏差值,经过尺寸微调后达到要求即可。
2)倍数负载与固定延时。由于在前端逻辑综合时,综合软件是以延时、面积、功耗等约束进行单元选取。后端布局布线也是根据延时、负载等因素确定单元的选取。传统的零负载与倍数尺寸的方法不能有效地提高前端综合工具和后端布局布线工具对标准单元库的合理选择。因此倍数负载与固定延时的方法比零负载与倍数尺寸法更适合设计适用于EDA工具调用的标准单元库。
该类型驱动能力的定义方法是首先设定INVXL的输入负载为最小单元输出负载的基数值,根据单元驱动的倍数同时增加基数负载的相同倍数,即负载基数值与倍数相乘,不是使用相同驱动力倍数的INV的输入负载值。按照设计要求确定在该对应负载下的延时规定来设计相应驱动能力的标准单元,其延时规定可以定义上升和下降都需延时小于某个数值,并比同类型X1单元的延时偏差小于某个数值。
3)固定负载与降级延时。该方法主要用于添加中间驱动能力单元中。通常标准单元库提供了多种驱动能力(如X1,X2,X4,X8,X16)的单元。在固定负载下,依据延时设置单元的驱动力可以使工具对单元的选取具有更大的灵活性,相对传统方法更具针对性。
一般自动综合和布局布线后,EDA工具使用了大量小驱动能力的单元,可见在典型的设计中低驱动能力单元使用得很普遍。因此,提供延时间隔更短的低驱动能力单元显得更为重要。如果在现有标准单元数据中,INV单元在输入斜率和输出负载相同情况下,延时数据X1和X2间的延时差值比X4和X8间的延时差值大。在相同激励和负载情况下,对于驱动能力相近的单元,其延时与驱动能力近似为线性关系,延时随驱动能力增大而递减,为了提高标准单元库的灵活性,需要在XL-X1和XL~X2间根据延时差值增加更多驱动能力等级的单元,如驱动能力单元X0.6,X0.8,X1.3,X1.7等。
在设置标准单元驱动强度的同时还需要考虑标准单元电路最后一级P/N管宽长比,通常在标准单元库中可以把P/N管宽长比值分成两类。一类是作为构成时钟网络的标准单元P/N管宽长比值,该P/N管宽长比值主要考虑时钟网络标准单元需要平衡上升时间和下降时间。另一类是常规的为延时优化的P/N管宽度比值,该P/N管宽长比值主要考虑标准单元驱动力最优化。
标准单元电路及版图设计
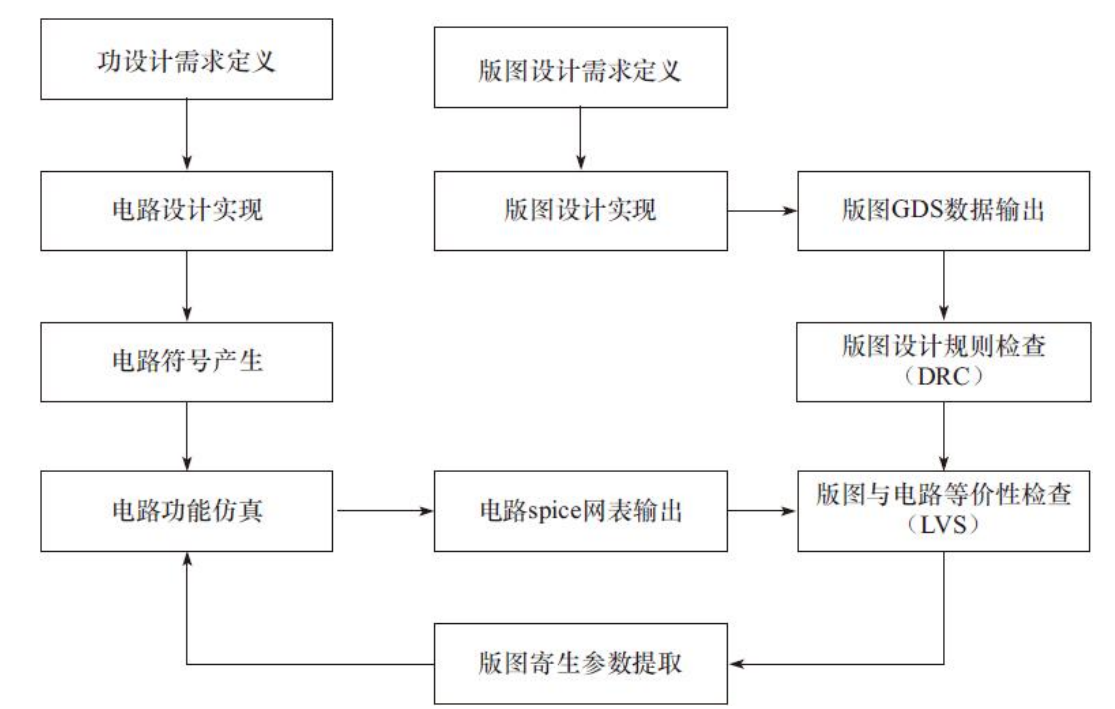
版图实现中,一直要遵循的几个基本设计建议。
1)输入输出端口要尽可能地放置在网格格点上,水平和垂直方向上的端口应尽量错开,这样可以充分利用垂直布线的资源。
2)输入输出端口必须在本单元的边界以内,而且边缘端口必须和单元的边界保持至少半个最小格点间距。
3)对于输入输出端口比较密集的单元,稍微增加单元面积的大小有时会比刻意保持单元面积最小要好,这样可以增加布线资源。
4)保证同类型的单元中最大单元的宽度是最小单元宽度的10倍之内。如果单元很复杂,可以通过增加高度来保证宽度的要求。
标准单元库版图和时序信息的提取
标准单元设计完成了单元的Schmatic和Layout视图后,但单元输入负载、速度和功耗等信息却没有以时序分析工具能认知的形式提取出来,例如综合工具需要知道单元的逻辑功能、单元实际的输入负载电容、在不同输入斜率和输出负载情况下单元的延时和功耗、单元的面积等。因此标准单元必须完成时序信息特征化(提取.lib文件)后,才能被多种时序分析工具所识别和使用。单元时序信息特征化就是通过模拟仿真器来提取标准单元相关时序信息的过程。
版图物理信息Lef文件的提取
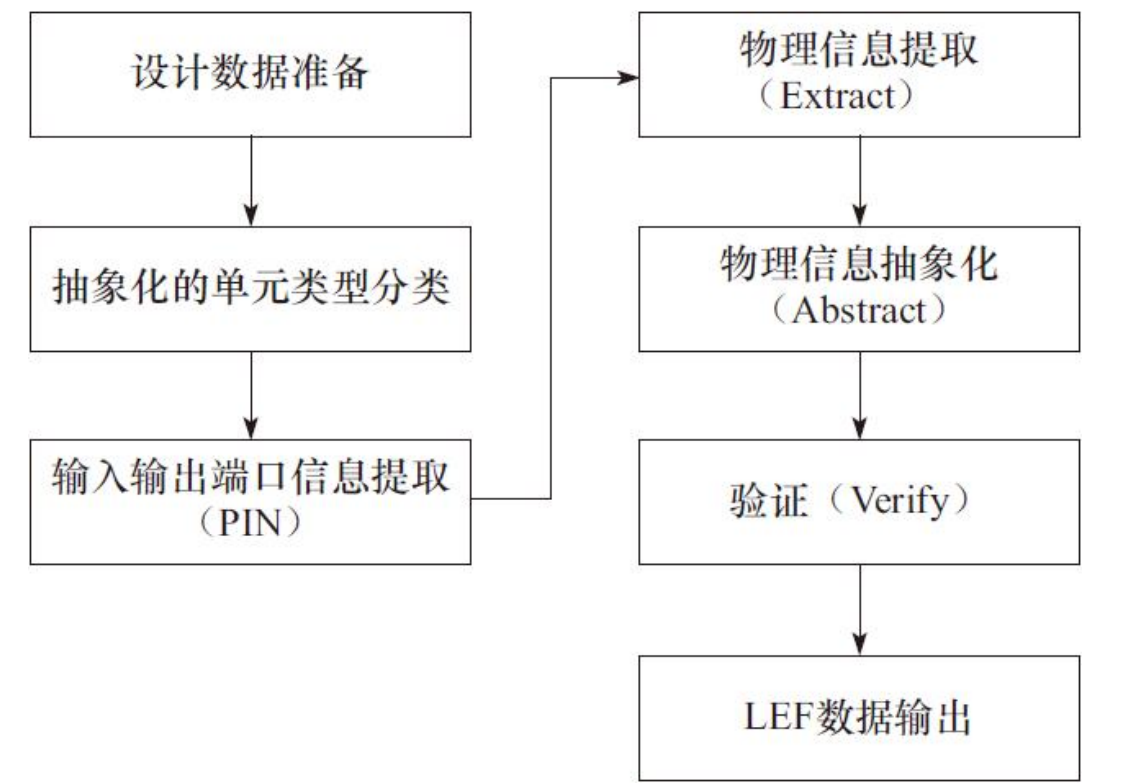
提取Lef文件需要准备的数据是GDSII版图数据和包含布局布线信息的工艺文件。
用Virtuoso将标准单元的GDSII数据导入一个Library,打开Abstract Genetrator并连接Library。为防止Abstract软件错误识别标准单元的PIN信息,需要导入标准单元的逻辑功能网表文件。
测试电路设计及工艺流片验证
测试电路设计主要包括功能验证电路、工作频率测试电路、建立/保持时间测试电路、恢复/移除时间测试电路以及制定测试方案。
标准单元设计需要的数据
CMOS工艺数字电路实现结构
静态电路实现结构
非常有效和简单的方法,但是随着逻辑门复杂性的增加,采用静态结构组成的电路会出现两个主要的问题。
1)静态电路实现一个具有N个输入的静态逻辑门所需要的晶体管数目为2N,因此随着扇入的增加,其面积会明显增加。
2)静态电路的传播延时随扇入的增加而迅速增加。
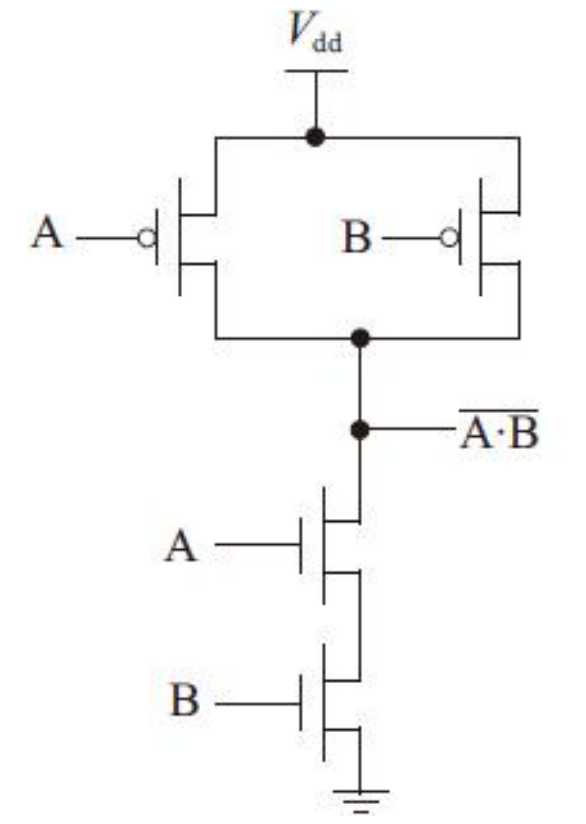
伪NMOS电路实现结构
伪NMOS门的一个显著优点是减少晶体管的数目,它较CMOS静态结构所用晶体管数目由2N个减少到N+1个。与CMOS静态结构相比较,晶体管数目的减少带来的直接好处是降低了电路复杂度,同时减少了传播延时,提高了电路性能。
但是伪NMOS也存在两个主要的缺点:
1)伪NMOS电路输出低电压时不是0V,因为在下拉网络和上拉负载器件(栅极接地的PMOS管)之间存在通路,这降低了噪声容限。因此对使用PMOS管作为上拉负载的伪NMOS电路,输出端的电压摆幅和电路性能取决于NMOS和PMOS的尺寸比。
2)伪NMOS电路当输出为低电平时,通过存在于Vdd和GND之间的电流通路会引起静态功耗。伪NMOS电路的静态功耗问题限制了这种电路结构的应用范围。然而,当面积是最重要的因素时,与CMOS静态电路相比,它能大大减少晶体管的数目,因此伪NMOS多应用在大扇入电路设计中。
传输管与传输门电路
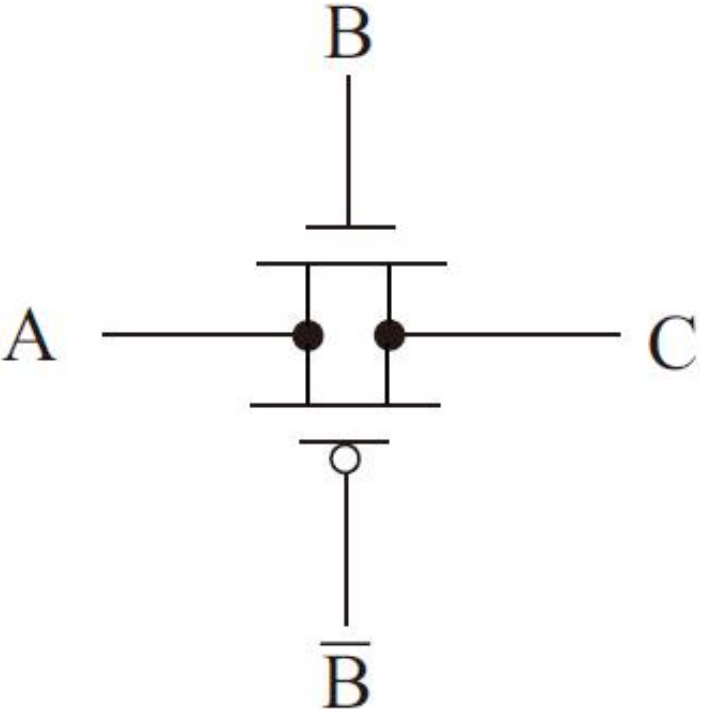
由栅极逻辑互补的控制信号B和B控制的双向开关,当B=1时,两个MOS管都导通并且逻辑关系为A=C。
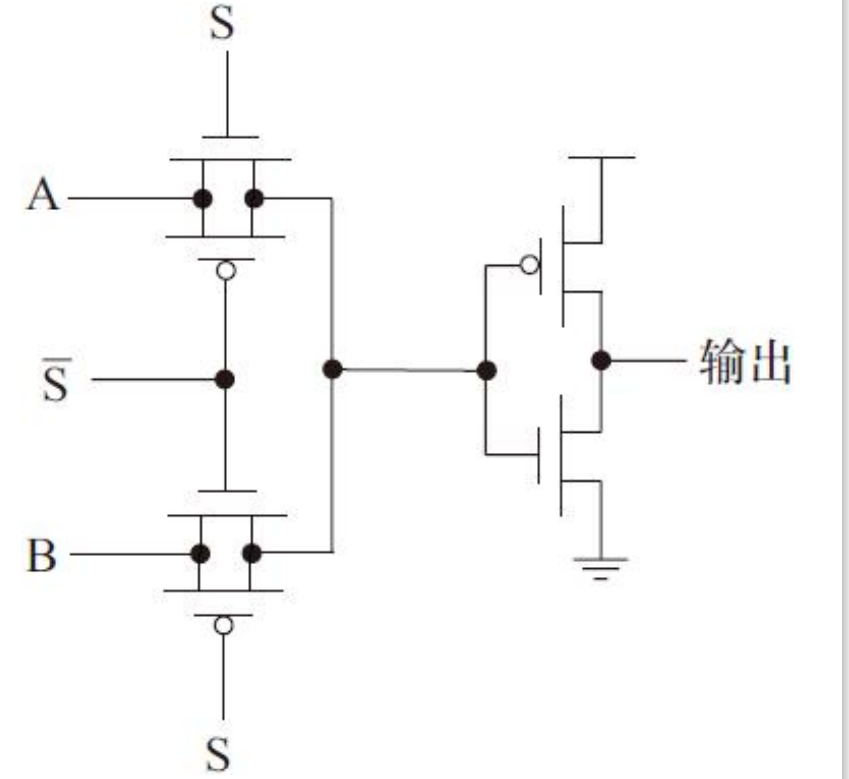
如布尔逻辑:(OUT)=(A·S+B·S),使用传输门结构只需要6个晶体管,而采用CMOS静态电路实现时需要8个晶体管。
动态电路实现结构
这种电路通过增加一个时钟输入实现动态输出
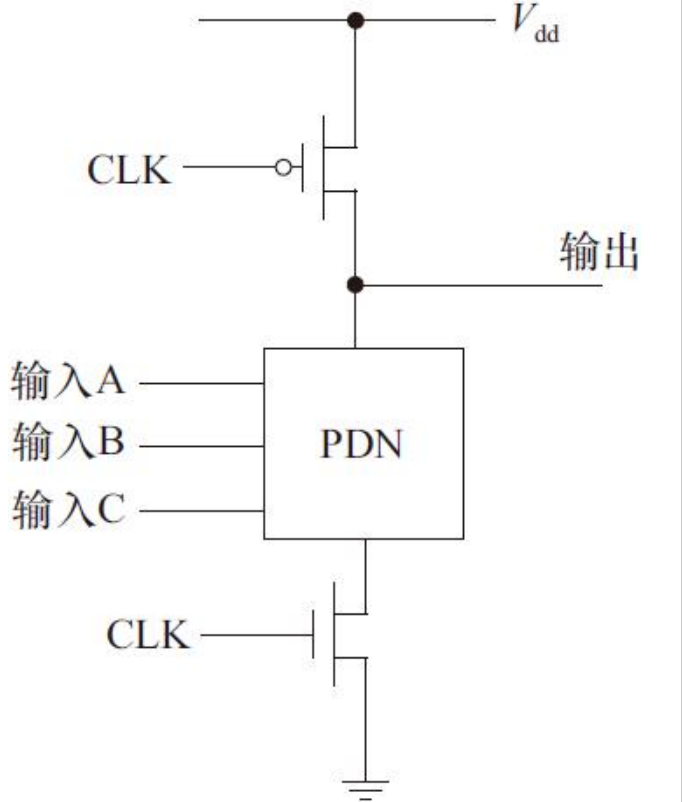
动态电路的下拉网络(PDN)的构成完全与CMOS一样。这种电路分为两个主要阶段:预充电和求值,处于哪种模式由时钟信号CLK决定。
1)预充电。当CLK=0时,输出节点被时钟信号CLK控制的PMOS管预充至Vdd,该PMOS管又称为预充管。在此期间,时钟信号CLK控制的NMOS管截止,该NMOS管称为求值管,因此下拉路径不工
作。
2)求值。当CLK=1时,CLK控制的PMOS预充管截止,CLK控制的NMOS求值管导通。输出根据输入值和下拉网络的逻辑结构进行有条件地放电。如果输入使下拉网络导通,则在输出和GND之间存
在低阻通路,因此输出放电至0V。如果输入使下拉网络断开,预充电值维持为存在输出节点电容上的电压值,理想情况下为电源电压Vdd。在求值阶段,一旦输出端放电后,直到下次预充电之前,输出节
点电容都无法变成高电平,因此输出在求值期间最多只能有一次变化。
动态电路的主要优点是提高了速度,减少了电路结构中的逻辑器件,从而减少了实现面积。
动态逻辑电路存在下面几个不可忽视的问题:
1)由于动态电路主要依靠节点电容的存储效应来保存信息并维持输出,同时由于工艺尺寸的不断缩小,器件尺寸随之减少导致节点电容也减少。另外,随着制造工艺的进步,电源电压也在逐渐下降,导致节点电容存储的电荷减少,从而影响动态电路的可靠性。
2)由于动态电路的结构特点、亚阈漏流和电荷分享等原因导致动态电路中存在泄漏电流,这样在长时间没有预充电的情况下,有可能会使存储信息丢失,影响电路的正常工作。
3)动态电路的时钟节点在每个时钟周期都有翻转,同时周期性的预充电和放电操作表现出较高的翻转概率,导致功耗消耗较高。
4)动态电路需要时钟信号控制电路工作,会使电路设计变得困难和复杂,不能在静态条件下工作,需要周期性地刷新节点电容电压。
高扇入逻辑电路的实现结构
CMOS静态电路实现高扇入逻辑电路
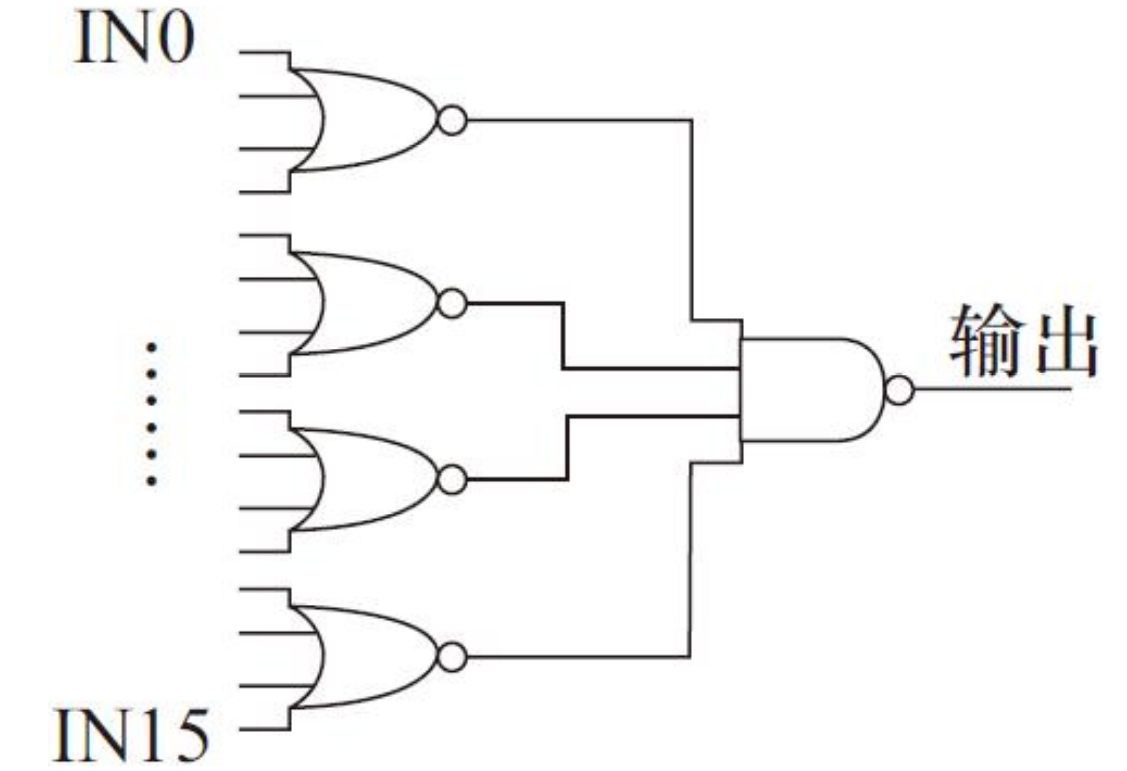
传统的CMOS静态电路实现高扇入逻辑电路时,为了避免大量的NMOS/PMOS管串联,需要采用多级树形结构,如图所示:或门。
实现一个16位的或门需要两级,第一级使用4个4输入或非门,第二级使用一个1个4输入与非门。由于CMOS电路中NMOS/PMOS管串联个数不能太多,多个晶体管串联会显著降低电路速度,因此在设计中串联个数通常不超过4。
伪NMOS静态电路实现高扇入逻辑电路
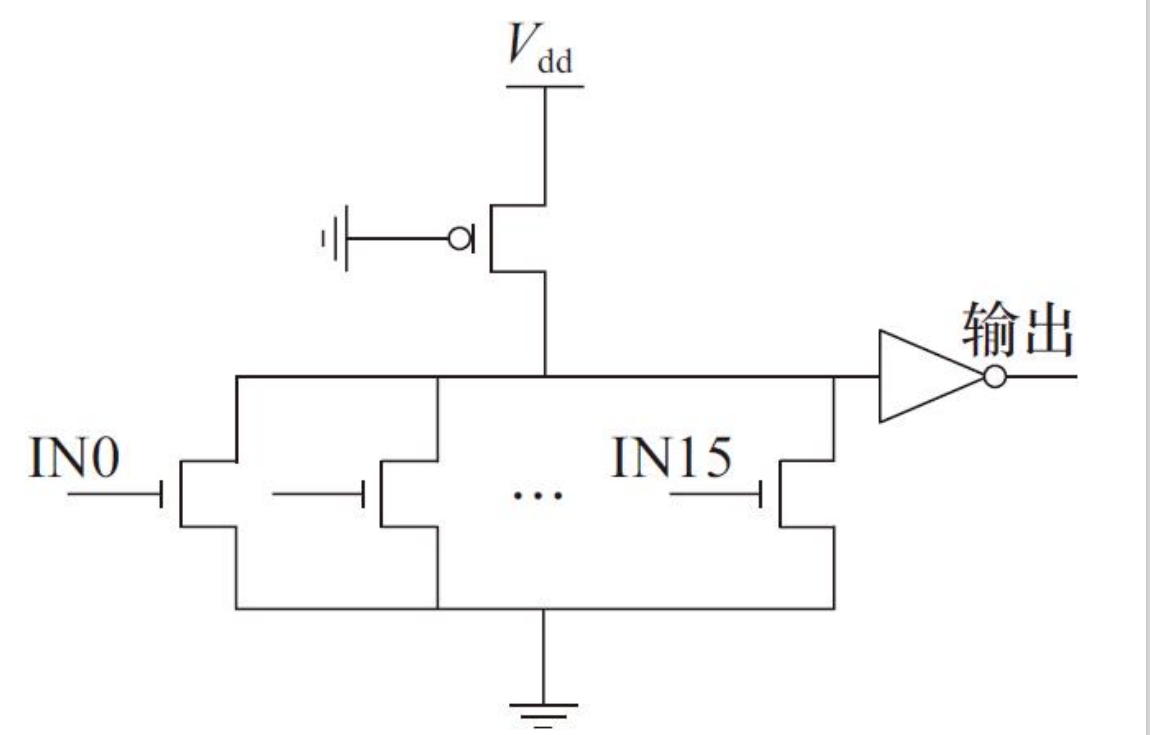
该电路显著优点是减少了晶体管数目。另外,速度也是其一大优势。伪NMOS电路实现的或(或非)门,下拉网络由多个NMOS管并联组成,只要有一个输入为“1”,下拉网络就导通,使输出为“1”。但是随着并联NMOS管数目的增多,电容也相应增大,导致电路速度减慢,甚至不能正常工作,所以,伪NMOS电路适合于实现24扇入以下的或(或非)门。伪NMOS电路不适合实现高扇入与(与非)门,因此也不能采用分级的结构来实现更高扇入的逻辑门。
动态电路实现高扇入电路
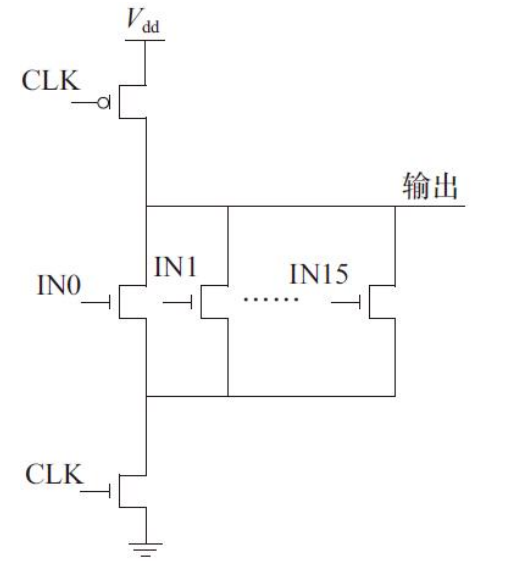
工作时序

因为相同尺寸的PMOS管的电流驱动能力要弱于NMOS管,所以P型动态电路的速度要慢于N型动态电路,于是动态电路实现的与非门速度慢于或非门。但是P型动态电路易于实现大扇入的与/与非逻辑,相比前面介绍的实现结构而言,它具有更少的逻辑级数,而且所需要的器件数目也大大减少。
随着扇入数目的增加,动态电路中的动态节点电容相应增大,这样会影响电路的工作速度,同时造成电路对输入噪声更加敏感,降低可靠性。因此采用动态电路实现高扇入与/或逻辑时,单级实现的扇入数目最好不大于16。对于较大扇入(扇入数目大于16)的与/或逻辑,应采用分块的方法,将动态电路中的求值网络分成多个块,由多级串联的方式实现。这样可以有效地降低动态节点的电容,提高电路的速度和可靠性。
多米诺电路实现高扇入逻辑电路
一个多米诺电路模块是由一个N型动态电路后接一个静态反相器构成的,它可以避免当动态电路直接串联时可能出现的错误放电现象。引入的静态反相器增加了额外的延时,但是带来的优点是多米诺门的扇出由一个具有低阻抗输出的静态反相器驱动,因此提高了抗噪声能力。由于缓冲器隔离了内部的负载电容,因而稳定了动态输出节点的电容。静态反相器还可以用来驱动一个电压保持器件以抵抗动态节点漏电和电荷的重新分布。
多米诺电路的逻辑功能由NMOS下拉网络实现,因此不会出现静态电路中多个PMOS管的串联。多米诺电路结构适合实现高扇入的或门,如图。
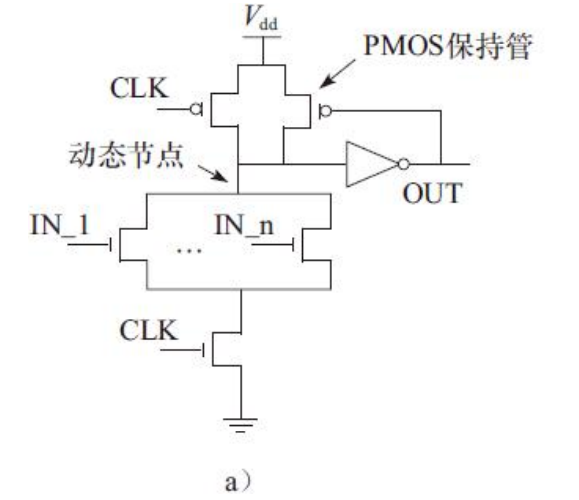
通常多米诺电路的第一级需要使用带尾管结构,即带下面的clk,保证预充电期间下拉网络是断开的。由于在预充电期间多米诺门的输入为低电平,这样所驱动的NMOS管是断开的,因此级联多米诺电路除第一级外均可以考虑取消尾管,这样可以减少时钟负载并提高下拉驱动能力。
另外,为了提高动态门的噪声容限,需要在输出端增加一个保持管(keeper transistor),用来补偿由下拉漏电路径造成的电荷损失。多米诺门的性能优化可以通过调整静态反相器的尺寸来实现,通常采用一个较小的NMOS器件和一个较大的PMOS器件来实现,**小尺寸的NMOS管只影响预充电时间,缺点是降低了噪声容限。**因此设计者在确定器件尺寸的时候应当同时考虑降低噪声容限及性能的影响。
随着输入数目的增大,标准多米诺门的动态节点电容增大,电路速度变慢,可靠性降低。通常,可以通过增加保持管的尺寸改善标准多米诺电路的可靠性。大尺寸的保持管可以使动态门保持高噪声容限,但是同时也增加了保持管与NMOS下拉网络的竞争,该竞争表现为当一个器件试图对一个节点充电而另一个器件试图对其进行放电,这种情况下由于短路电流的存在而增加功耗并且降低性能。
因此,对于多米诺电路结构实现的大扇入或门,在增大保持管的同时,为了保证电路的性能及可靠性,应采用分块的思想,通过多级串联的方式来实现。通过将多米诺电路中的求值网络分成多块,可以有效地降低动态节点的电容,同时每个电路结构块不需要很大的PMOS保持管,小尺寸的保持管可以减少与NMOS下拉网络的竞争,降低功耗。
组合多米诺电路实现高扇入电路逻辑
组合多米诺电路不是每个N型动态门都驱动一个静态反相器,而是借助一个复合静态CMOS门把多个动态门的输出组合起来,这使晶体管数目尽可能减少。组合多米诺电路是构成高扇入或门非常有用的工具,较大扇入的动态结构可以由扇入较小的并行结构及复合CMOS门所代替。图示为组合多米诺电路实现的52位或门。
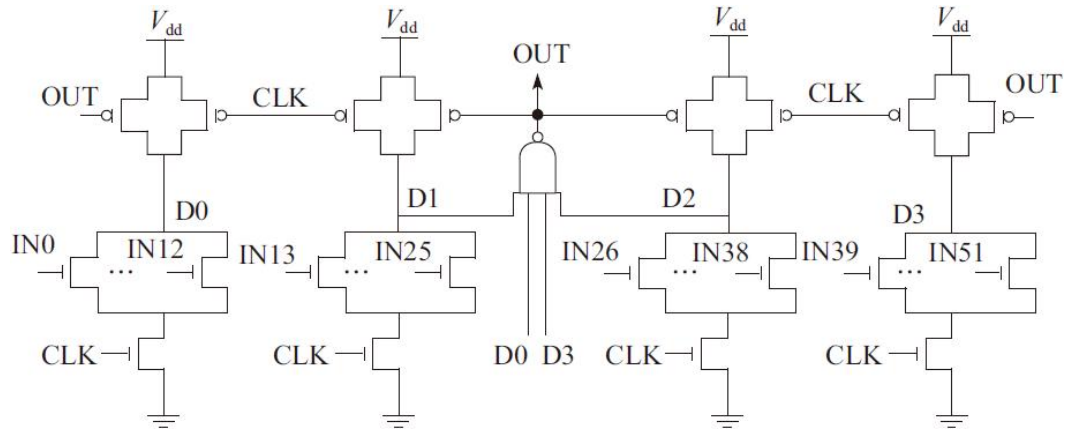
该电路由一组并行的13位动态或非门及一个静态的4输入与非门构成。该电路结构中,将52个输入分为4组,每一组的输出与一个静态4输入与非门相连,与非门的输出接到4个PMOS保持管的栅极。在预充电阶段,即CLK为“0”,4个块的动态节点D0、D1、D2、D3被同时充电至高电平,此时与非门输出为“0”,4个保持管断开。在求值阶段,即CLK为“1”,若所有输入均为“0”,则4个NMOS下拉网络均关断,输出为“0”,打开PMOS保持管防止动态节点的电荷泄露;只要4块中有一个输入为“1”,就通过该块的NMOS下拉网络对动态节点进行放电,使与非门输出为“1”,关闭保持管。
该电路的优点是对NMOS下拉网络进行分块处理,每块只需要一个小尺寸的PMOS充电管,同时可以有效地减少动态节点的电容,又不需要大尺寸的PMOS保持管,从而使保持管与NMOS下拉网络的竞争电流减小,提高电路速度的同时降低功耗。如何分块取决于扇入数的多少,但应该避免分块数过多。由于静态CMOS管实现的与非/或非门随着扇入数增加其电路延时增长也较快,所以一般情况下静态CMOS管实现的与非/或非门扇入数不超过4,这就限制了组合多米诺电路实现或门的扇入数不能太大。此外,若输入的到达时间有先后顺序,应将到达时间接近的输入端分到同一块中,对于输入信号到达时间较晚的电路块的输出应接到与非门中靠近输出的晶体管栅极。
NP-CMOS电路实现高扇入电路
NP-CMOS电路使用了N型和P型两种动态电路,利用N型动态电路和P型动态电路之间的互补性来消除直接串联动态电路时可能出现的错误放电现象。使用NP-CMOS电路串联动态门避免在关键路径中由多米诺电路引入的额外静态反相器。NP-CMOS电路适合于采用分块结构串联动态电路来实现高扇入的与/或逻辑。一组并行的N型动态电路实现的或非门串联一个P型动态电路实现的与非门可以实现高扇入的或门。相反,一组并行的P型动态电路实现的与非门串联一个N型动态电路实现的或非门可以实现高扇入的与门。与级联多米诺电路类似,NP-CMOS电路的第一级需要使用带尾管结构,保证预充电期间求值网络是断开的。由于在预充电期间,第一级NP-CMOS电路的输出使下一级NP-CMOS电路的求值网络断开,因此级联NP-CMOS电路除第一级外均可以考虑取消尾管,这样可以减少时钟负载并提高求值网络驱动能力。
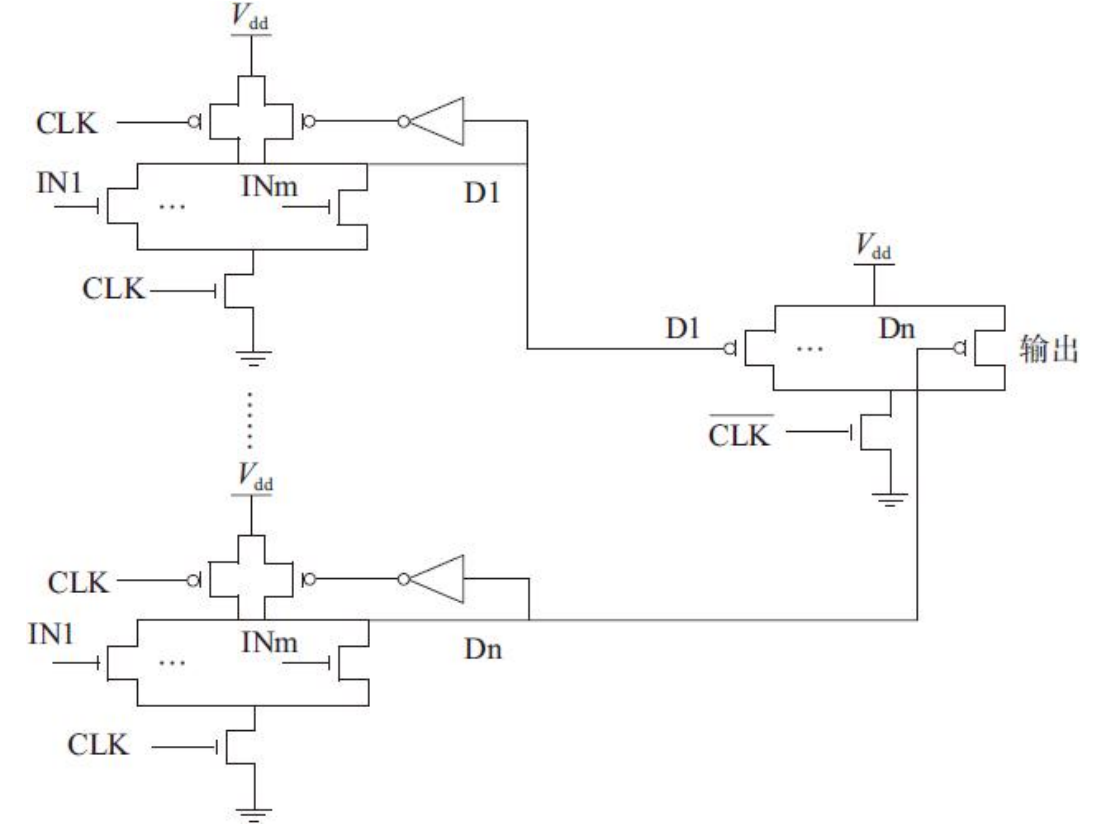
第一级为N个并行的N型动态电路实现的M扇入或非门,使用带尾管的电路结构。第二级为一个P型动态电路实现的N扇入的与非门,使用了省去尾管的电路结构。为了提高动态门的噪声容限,需要在N型动态电路的输出端增加一个保持管,用来补偿由于下拉漏电路径造成的电荷损失。N型动态电路由CLK控制,P型动态电路由CLK控制,N型动态电路可以直接驱动P型动态电路。在预充电阶段(CLK=0),N型动态电路的输出被充电至高电平,而P型动态电路的输出被预放电至低电平。由于N型动态电路的输出与PMOS上拉器件相连,P型动态电路的上拉网络此时断开。在求值期间
(CLK=1),N型动态电路的输出只能进行1→0的翻转,有条件地导通P型动态电路中的一些晶体管,这就保证了不会发生对输出错误的充电。若所有的输入均为“0”,则N个NMOS下拉网络均断开,第一级输出都为“1”,使第二级的PMOS上拉网络断开,结果输出为“0”。只要N块中有一个输入为“1”,就通过该块的NMOS下拉网络对动态节点进行放电,使第二级的PMOS上拉网络导通,结果输出为“1”。
NP-CMOS电路的优点是避免了在关键路径中由多米诺电路引入额外的静态反相器,降低了信号翻转的频率,降低了功耗。NP-CMOS电路适合于采用分块结构串联动态电路来实现较大扇入的与/或逻辑。NP-CMOS电路的缺点是由于在逻辑网络中PMOS管的电流驱动较弱,所以P型动态电路块比N型动态电路块慢。要使它们的传播延时相等,需要额外的面积。另外,由于缺少缓冲器,在动态门之间也存在与动态节点的连线。
CMOS数字电路优化
1)选择最优的电路实现结构。前面讲到,CMOS数字电路实现结构主要包括静态电路、动态电路、传输管结构和传输门结构等,不同的电路结构具有不同的特点。对于不同的设计需求,逻辑门电路实现结构可以结合面积、速度、功耗等方面的设计指标来进行选择。
2)优化电路逻辑结构。优化电路布尔逻辑的方法可以有效地降低复杂电路对扇入的要求,从而降低逻辑门的延时。比如逻辑门延时和扇入数成正比的指数关系使实现8输入的与门逻辑延时很大,然而,把8输入的与门逻辑分解成由两个4输入的简单与非逻辑门和一个或非逻辑门组合可以显著提高电路性能。
3)调整晶体管的尺寸。加大晶体管的尺寸能够有效地降低串联器件的电阻和提高器件的充放电能力。但是如果晶体管尺寸的增加会产生较大的寄生电容,那么会增加前一级电路的输出负载,因此如果增大晶体管尺寸后,其负载电容主要还是门自身的本征电容,该方法才会起到优化电路的作用。
4)优化电路中的关键路径。通常在复杂的逻辑电路中,所有的输入信号并不能保证同时有效,但是电路中却存在部分信号可能比其他一些信号更加重要。那么对于这些重要的输入信号,如果它是所有输入信号中最后达到稳定有效状态的输入信号,那么该信号就是该逻辑电路中的关键信号,同时与该关键信号相关并且决定电路最终性能的电路路径称为关键路径。通过优化关键路径的性能能够达到提高整体电路性能的目的。
逻辑努力
通过分析电路拓扑结构在逻辑链中的相互作用,并且提供使电路延时最小化的晶体管调整依据的电路优化设计技术。
由于在晶体管尺寸相同的情况下,反相器在所有的静态CMOS门中具有最小的本征延时,因此一个门的逻辑努力(logical effort)g是指对给定的负载,当加大这个门的尺寸使之能提供和所对应的反相器相同的驱动电流时,这个门的输入电容与对应的反相器输入电容的比。
简单地说,就是对于给定的负载,复杂逻辑门必须比反相器更“努力”工作才能得到类似的性能。
这样的话,一个逻辑门的逻辑努力告诉电路设计者,当假定这个逻辑门的每一个输入只代表与一个反相器相同的输入电容时,在产生输出电流上它比一个反相器差多少。同理,反过来逻辑努力表示一个复杂逻辑门与一个反相器提供相同的输出电流时它表现出的输入电容比反相器大多少。
假设PMOS与NMOS的尺寸比为2,那么最小尺寸反相器的输入电容等于最小尺寸NMOS管栅电容的3倍,同时逻辑努力为1。
根据二输入NAND的电路结构分析,由于其NMOS是串联结构,因此每个NMOS的尺寸必须是反相器NMOS管尺寸的2倍才能保证与反相器NMOS管相等的电阻值,同时由于二输入NAND的PMOS管是并联结构,因此其PMOS管尺寸与反相器PMOS管大小一致即可保证电阻值相等。
这样二输入NAND的输入电容增加4倍,因此为了使二输入NAND的门延时达到最小的本征延时性能,其逻辑努力是反相器的4/3。
同理,根据二输入NOR的电路结构分析,为了确定二输入NOR门的尺寸,由于其PMOS是串联结构,因此每个PMOS的尺寸必须是反相器PMOS管尺寸的2倍大小才能保证与反相器PMOS管相等的电阻值。同时由于二输入NOR的NMOS管是并联结构,因此其NMOS管尺寸与反相器NMOS管大小一致即可保证电阻值相等。这样为了使二输入NOR的等效电阻等于反相器的电阻,其输入电容为反相器的5/3,因此二输入NOR的门延时达到最小的本征延时性能的逻辑努力是反相器的5/3。