Kafka 4.0 技术深度解析
Kafka 4.0 技术深度解析
引言:Kafka 4.0 划时代的里程碑
2025年3月18日,Apache Kafka 4.0.0正式发布,标志着这个分布式流处理平台迎来了自诞生以来最重大的架构变革。作为第一个完全摒弃Apache ZooKeeper依赖的版本,Kafka 4.0通过默认启用KRaft模式,彻底重构了元数据管理体系,同时引入了新一代消费者重平衡协议(KIP-848)和共享组队列功能(KIP-932),为高吞吐量、低延迟的实时数据处理树立了新标杆。本文将深入剖析这些核心特性,并通过实战示例展示Kafka 4.0的强大能力。
KRaft模式:告别ZooKeeper的新纪元
架构演进与核心动因
Kafka自诞生以来长期依赖ZooKeeper进行元数据管理和集群协调,但这种架构逐渐暴露出三大痛点:
- 运维复杂性:需独立部署维护ZooKeeper集群,增加系统复杂度
- 性能瓶颈:ZooKeeper在大规模集群(十万级分区)下元数据同步延迟可达秒级
- 扩展性限制:ZooKeeper写性能随节点数增加而下降,制约Kafka集群规模
KRaft(Kafka Raft)模式的引入从根本上解决了这些问题。通过将元数据管理逻辑内置于Kafka Broker,利用Raft共识协议实现控制器选举和元数据同步,Kafka 4.0实现了架构的彻底简化。
KRaft核心架构解析
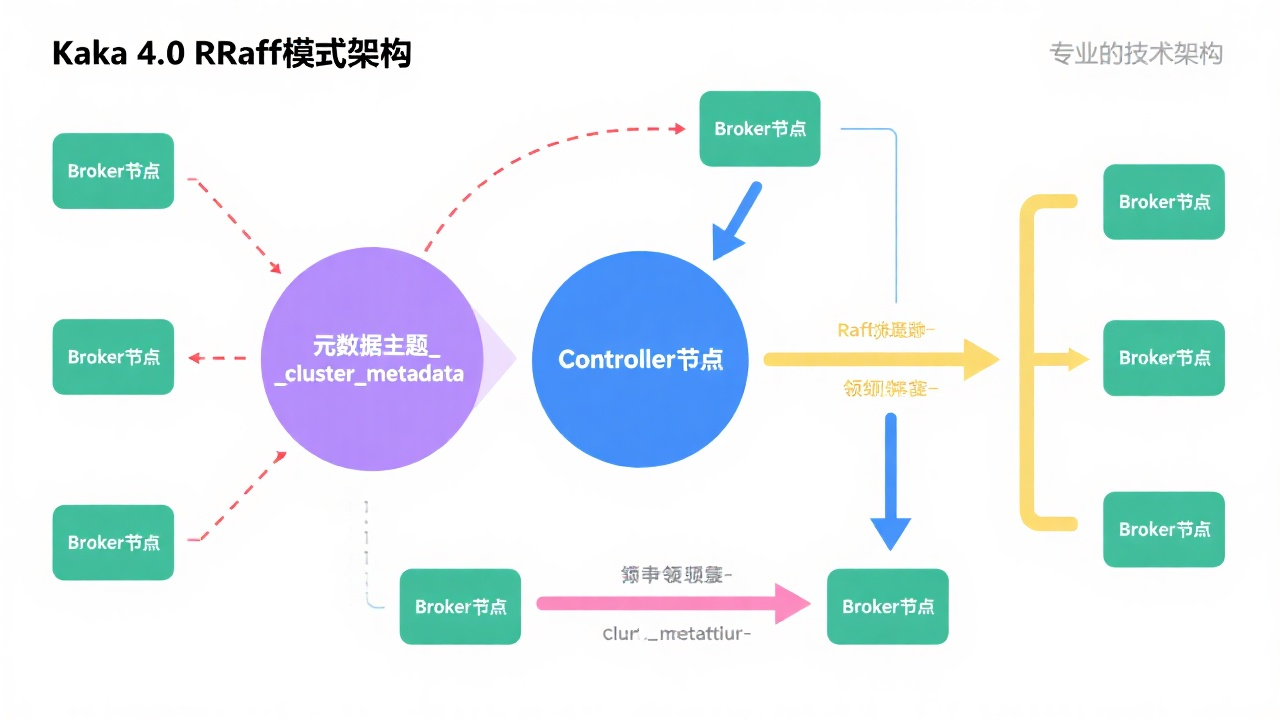
KRaft架构的核心创新点包括:
-
元数据自管理:
- 元数据存储于内部主题
__cluster_metadata,利用Kafka自身的高可用日志存储机制 - Controller节点通过Raft协议实现元数据共识,无需依赖外部协调服务
- 元数据存储于内部主题
-
混合角色节点:
- 支持节点同时扮演Broker和Controller角色,简化部署架构
- 控制器仲裁 voters 配置示例:
controller.quorum.voters=0@172.16.0.106:9093,1@172.16.0.107:9093
-
性能与可扩展性提升:
- 支持数百万级别分区,突破ZooKeeper瓶颈
- Controller故障切换时间从分钟级降至秒级
- 集群恢复速度提升90%以上
KRaft集群部署实战
以下是基于Docker Compose的KRaft集群配置示例:
services:kafka-0:image: bitnami/kafka:4.0.0container_name: kafka-0ports:- "9092:9092"- "9093:9093"environment:- KAFKA_CFG_NODE_ID=0- KAFKA_CFG_PROCESS_ROLES=controller,broker- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@172.16.0.106:9093,1@172.16.0.107:9093,2@172.16.0.108:9093- KAFKA_KRAFT_CLUSTER_ID=abcdefghijklmnopqrstuv- KAFKA_CFG_LISTENERS=PLAINTEXT://0.0.0.0:9092,CONTROLLER://0.0.0.0:9093- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://172.16.0.106:9092- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
部署步骤:
- 生成集群ID:
echo $(docker run --rm bitnami/kafka:4.0.0 kafka-storage.sh random-uuid) - 格式化存储:
kafka-storage.sh format -t <cluster-id> -c config/kraft/server.properties - 启动集群:
kafka-server-start.sh config/kraft/server.properties
KIP-848:新一代消费者重平衡协议
传统重平衡机制的痛点
Kafka消费者组的重平衡(Rebalance)过程长期存在两大问题:
- 全局同步屏障:任何成员变更触发全组暂停,导致"Stop-the-World"式停顿
- 扩展性瓶颈:万级消费者组重平衡耗时可达数分钟,资源消耗高
增量式重平衡的革新
KIP-848引入的新一代重平衡协议通过三大改进彻底解决了这些问题:
-
协调逻辑转移:
- 由Broker端的GroupCoordinator统一调度
- 消费者仅需上报状态,无需全局同步
-
增量分配策略:
- 仅调整受影响分区,未变更分区可继续消费
- 局部故障仅触发局部重平衡
-
性能对比:
| 指标 | 旧协议(Eager) | 新协议(KIP-848) |
|---|---|---|
| 重平衡延迟(万级组) | 60秒 | <1秒 |
| 资源消耗(CPU) | 高 | 降低70% |
| 扩展上限 | 千级消费者 | 十万级消费者 |
新协议配置与使用
启用新协议仅需在消费者配置中添加:
properties.put("group.protocol", "consumer");
服务器端默认启用新协议,支持新旧协议并存。对于大规模消费者组,建议配合以下参数优化:
properties.put("max.poll.records", 1000);
properties.put("heartbeat.interval.ms", 3000);
properties.put("session.timeout.ms", 30000);
KIP-932:共享组(Share Group)队列功能
传统消费者组的局限性
在Kafka 4.0之前,消费者组存在硬性限制:
- 消费者数量不能超过分区数,多余消费者空闲
- 单分区无法并行处理,吞吐量受限于单消费者性能
- 缺乏传统消息队列的点对点消费语义
共享组的创新实现
KIP-932引入的共享组机制通过以下创新突破了这些限制:
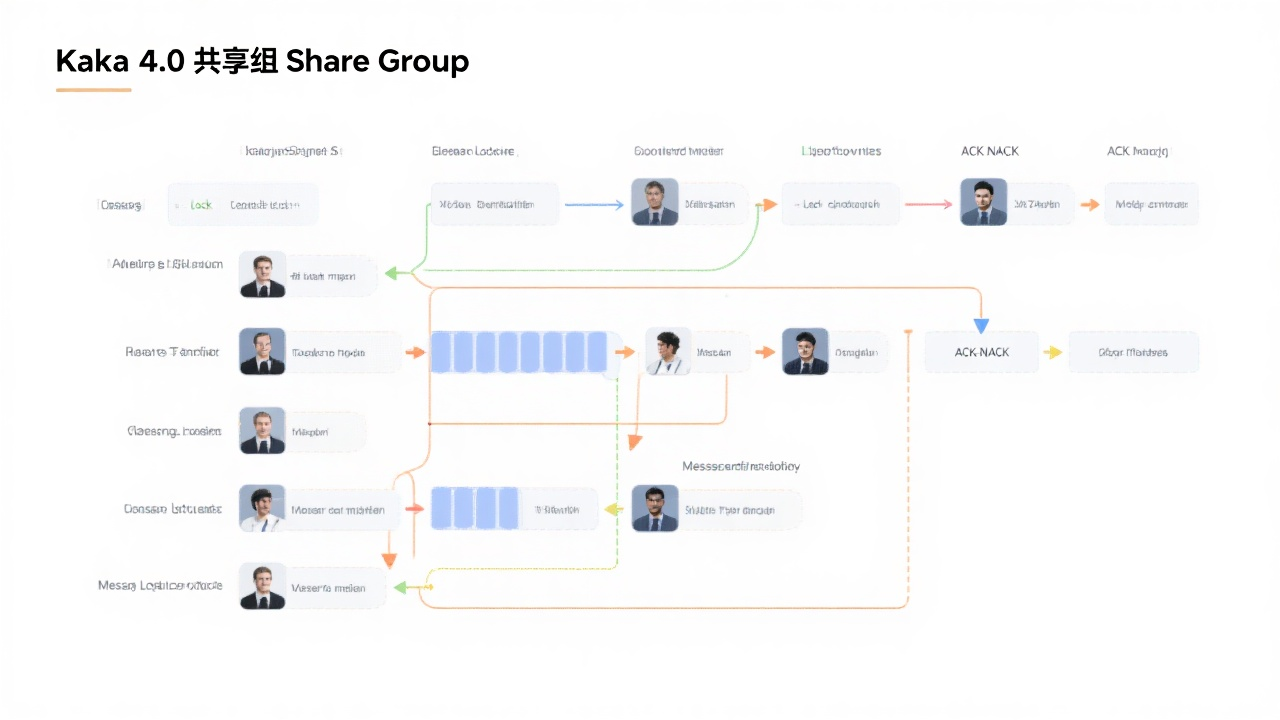
-
核心特性:
- 允许多消费者并发消费同一分区消息
- 记录级锁机制防止重复处理,支持TTL控制
- 逐条ACK/NACK语义,支持Exactly-Once投递
-
与传统消费者组对比:
| 特性 | 传统消费者组 | 共享组 |
|---|---|---|
| 并行消费 | 分区数=消费者数 | 消费者数>分区数 |
| 消息确认 | 偏移量提交 | 逐条ACK/NACK |
| 投递语义 | At-Least-Once | Exactly-Once(可选) |
| 适用场景 | 发布订阅 | 任务队列、负载均衡 |
共享组代码示例
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "order-processing-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 启用共享组模式
props.put("group.protocol", "share");
// 配置记录锁TTL
props.put("share.group.lock.ttl.ms", "5000");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("order-events"));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {try {// 处理订单逻辑processOrder(record.value());// 手动确认消息consumer.acknowledge(record);} catch (Exception e) {// 处理失败,释放锁让其他消费者重试consumer.nacknowledge(record, Duration.ofMillis(1000));}}
}
注意:KIP-932在Kafka 4.0中为早期访问(Early Access)功能,API可能在未来版本变更,建议生产环境谨慎使用。
高级特性与最佳实践
事务消息增强
Kafka 4.0通过KIP-890实现了事务服务端防御机制,显著降低"僵尸事务"概率:
- 服务端主动验证事务状态,防止处理失效事务
- 网络异常自动映射为可重试错误
- 心跳超时检测并清理僵尸事务
配置示例:
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "order-producer-1");
性能优化建议
-
JVM配置:
- Broker端建议使用Java 17,启用ZGC垃圾收集器
- 客户端最低要求Java 11,推荐使用Java 17
-
主题设计:
- 分区数设置:根据吞吐量需求,推荐每分区每秒1000-2000条消息
- 副本因子:生产环境建议3,确保高可用
-
监控指标:
- 新增KIP-1076客户端应用指标,支持监控嵌入式客户端
- 关键指标:
kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec
总结:Kafka 4.0开启流处理新纪元
Kafka 4.0通过KRaft模式的全面推行,不仅简化了部署和运维复杂度,更将可扩展性提升至新高度。新一代重平衡协议和共享组功能的引入,使Kafka既能保持发布订阅模式的优势,又能胜任传统消息队列的点对点场景,进一步巩固了其在流处理领域的领导地位。
随着云原生架构的普及,Kafka 4.0的轻量级设计和弹性扩展能力将更好地适应容器化和Serverless环境。对于构建实时数据管道、事件驱动架构和流处理应用的开发者而言,Kafka 4.0无疑是一个里程碑式的版本,值得深入学习和实践。
未来,我们可以期待Kafka社区在流处理、安全性和多集群协同等方面带来更多创新,持续推动实时数据处理技术的发展。