DeepSWE:通过强化学习扩展训练开源编码智能体
DeepSWE:通过强化学习扩展训练开源编码智能体
本文聚焦于DeepSWE-Preview这一仅通过强化学习训练的推理编码智能体。详细阐述其在软件工程任务中的训练方法、测试策略及评估结果,深入分析其涌现行为,还分享了训练中未成功的尝试,并展望未来工作。为智能体扩展和强化学习在编码领域的发展提供了全面且深入的参考。
📄 论文标题: DeepSWE: Training a Fully Open-sourced, State-of-the-Art Coding Agent by Scaling RL
🌐 来源: https://www.together.ai/blog/deepswe
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
1. 背景
1.1 LLM智能体
在强化学习(RL)的框架下,智能体是能够自主执行动作并从环境获取反馈的实体。环境类型丰富多样,涵盖从简单的Atari游戏到复杂的机器人控制、代码库软件开发、数据库管理以及蛋白质发现任务等。
大语言模型(LLMs)作为RL智能体,借助基于先前观察和动作构建的内部表示与环境进行交互。它们能够调用外部工具或函数,在各自的环境中执行特定动作。例如,在代码开发环境中,LLM智能体可以根据代码上下文调用文件编辑工具来修改代码。
1.2 软件工程(SWE)
一般的软件工程任务,如处理拉取请求(pull request),可被建模为强化学习环境。智能体处于配备终端和文件系统的计算机环境中,类似于人类开发者使用集成开发环境(IDE),智能体拥有一系列工具,包括bash命令执行、搜索功能以及文件查看/编辑工具,还可能有一个“完成”工具用于表明任务已完成。
在RL中,奖励的分配依据项目的自动化测试套件运行结果。如果LLM修改后的代码能成功通过所有测试,则获得正奖励,表示拉取请求已解决;若测试失败,则奖励为零。
2. 训练方法
2.1 可扩展数据集整理
- 数据集来源与过滤:使用的数据集包含来自R2E-Gym子集的4500个问题。为避免训练过程中的数据污染,过滤掉了与SWE-Bench-Verified源自相同仓库(如sympy)的问题。所有问题都对应单个Docker镜像,这有助于确保每个问题的独立性和可重复性。
2.2 环境设置
- 环境封装:训练环境基于R2E-Gym,这是一个用于可扩展整理高质量可执行软件工程环境的现有Gym环境。
- 状态与动作:R2E-Gym定义了四个工具作为动作空间,每个工具的输出(一个带有标准输出/标准错误的Python程序)代表返回的状态。具体工具包括:
- Execute Bash:执行LLM生成的bash命令,并输出标准输出和标准错误信息。
- Search:在指定目录或单个文件中搜索LLM定义的查询内容,并返回所有匹配结果。
- File Editor:支持对特定文件进行查看、创建、字符串替换、插入和撤销编辑等操作。
- Finish/Submit:当LLM认为已解决拉取请求时调用此工具,终止轨迹生成。
- 奖励函数:采用稀疏结果奖励模型(ORM),规则如下:
- 如果LLM生成的补丁在时间限制内通过选定的测试样本(包括Pass2Pass和Fail2Pass),则奖励为1。为加速训练,最大时间限制设为5分钟,而官方SWE-Bench评估的时间限制为30分钟。
- 如果LLM的代码至少在一个测试用例中失败或超时,则奖励为0。
- Kubernetes支持:在扩展SWE-Bench环境时遇到了挑战,因为RL训练的高要求和并行实验会同时生成数千个容器,导致Docker的API服务器过载并最终使Docker守护进程崩溃。为解决此问题,将Kubernetes支持集成到R2E-Gym中,由Kubernetes编排器在节点池中调度容器。每个工作节点约有200个CPU核心和超过6TB的本地NVMe SSD,并预加载SWE-bench镜像,确保大部分层从磁盘加载以实现快速启动,避免从Docker Hub过度拉取镜像。集群可扩展到超过1000个CPU核心,并依靠Kubernetes集群自动缩放器根据负载自动添加或移除节点。当Pod在短时间内无法调度时,自动缩放器会提供额外的工作节点;反之,当节点在约20分钟内利用率较低时,会移除这些节点。这种弹性设置可可靠地收集数百万条轨迹,同时使计算成本与负载成正比。
2.3 通过扩展RL训练SWE智能体
- GRPO扩展到多轮:自Deepseek - R1以来,数学和编码推理作为单步RL环境大多通过广义信赖域策略优化(GRPO)进行训练。从先前的工作可知,将GRPO扩展到多轮或智能体设置时,需要对每个轨迹的环境观察或ChatML格式的用户消息进行屏蔽。
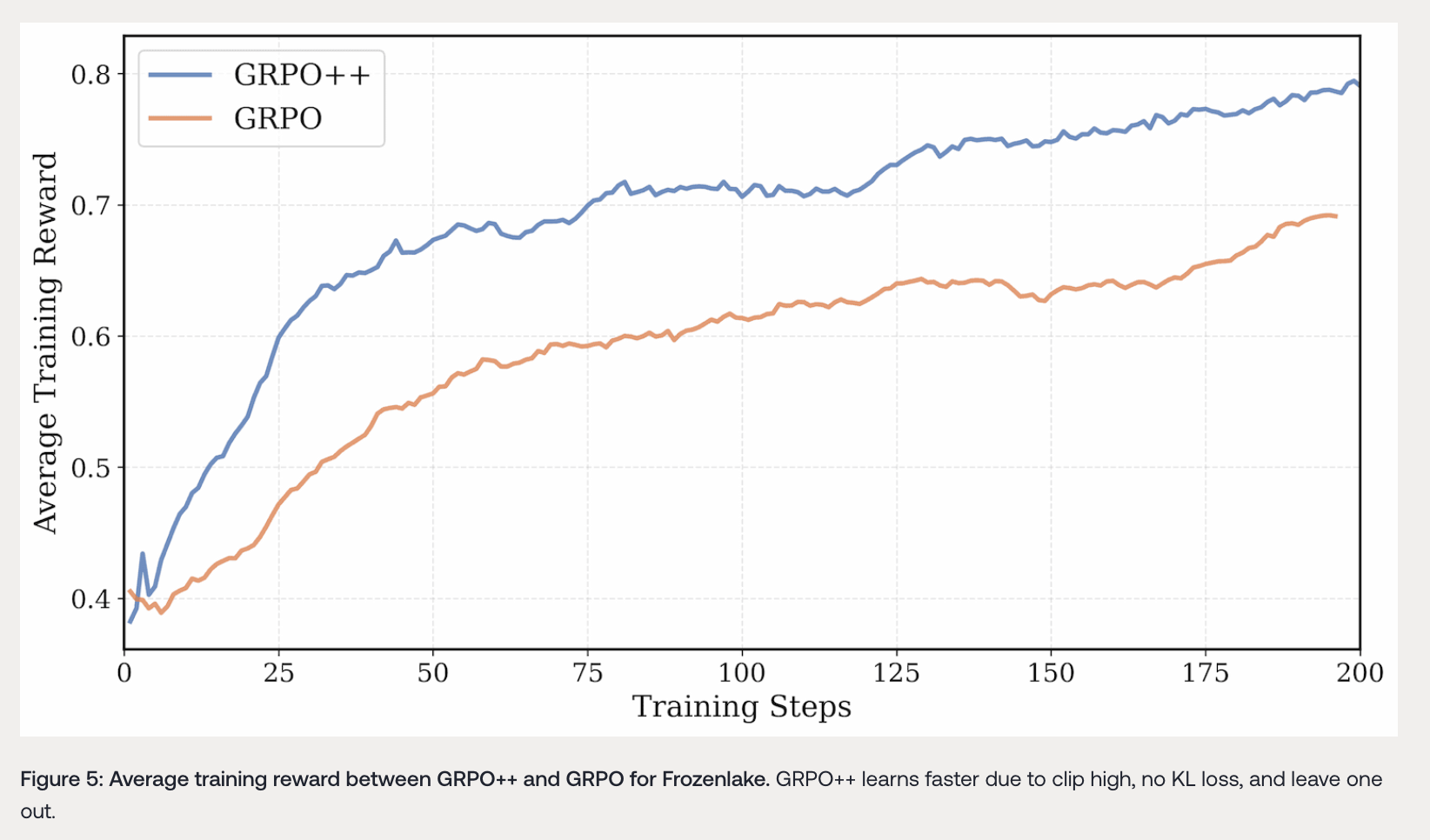
- GRPO++算法:对原始GRPO算法进行改进,集成了多个特性以实现稳定训练和提高性能:
- Clip High(DAPO):提高GRPO/近端策略优化(PPO)替代损失的上限,鼓励探索并稳定熵。这有助于智能体尝试更多不同的动作,增加找到更优解决方案的可能性。
- No KL Loss(DAPO):消除KL散度损失,防止LLM被限制在原始有监督微调(SFT)模型的信任区域内,使模型能够更自由地学习和探索。
- No Reward Standard Deviation(Dr.GRPO):移除奖励标准差,消除GRPO损失中的难度偏差,确保能更好地区分难易问题。
- Length Normalization(Dr.GRPO):将替代损失除以最大上下文长度,消除GRPO中存在的长度偏差,避免不正确响应的长度增加。
- Leave One Out(Loop/RLOO):在优势估计中移除一个样本,减少策略梯度的方差且不引入偏差。
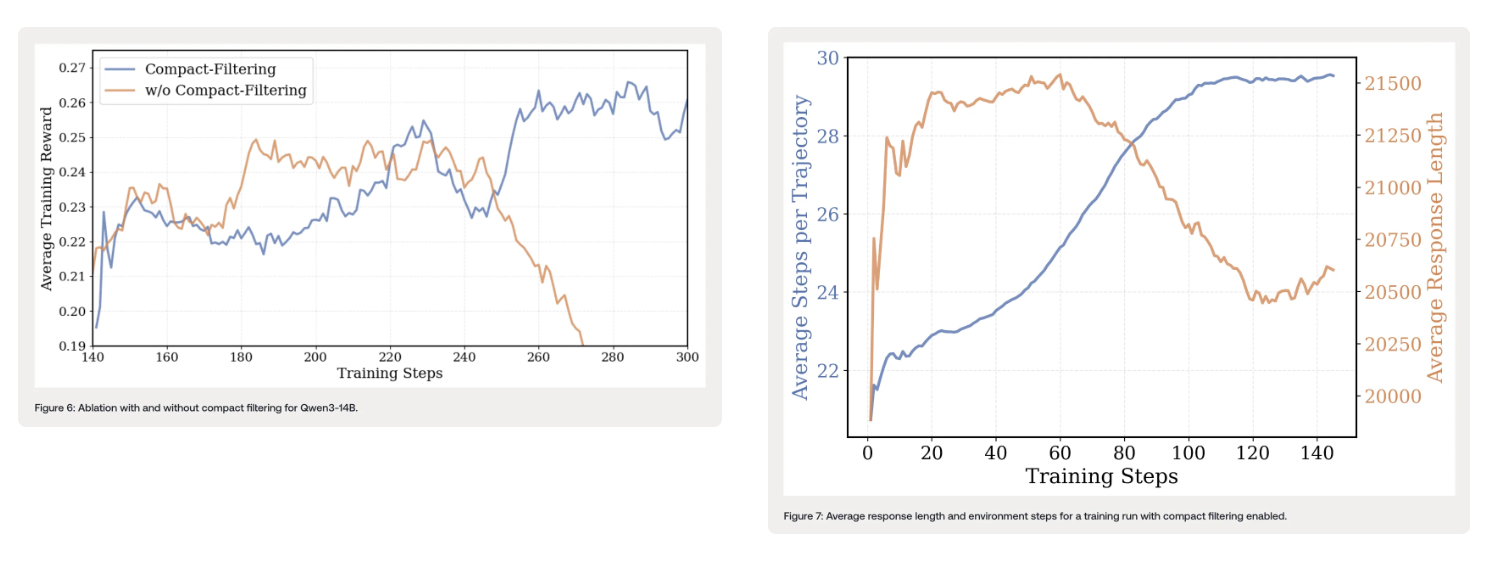
- Compact Filtering:受DAPO的超长过滤启发,对达到最大上下文长度、生成超时(20分钟)或达到最大步数的轨迹的损失进行屏蔽。这样做有两个好处:一是防止或延迟训练过程中的奖励崩溃,避免智能体在未真正理解问题的情况下偶然获得正确补丁而强化不良行为;二是减少每步的过度思考,鼓励跨步骤的长形式推理。例如,训练过程中平均响应长度会减少,但平均环境步骤会增加,表明每步的平均思考时间大幅下降。
- No Entropy Loss:熵损失会引入更高的不稳定性,最终导致熵呈指数级增加,使训练崩溃。只要基础模型的令牌级熵在0.3 - 1之间,就不需要熵损失。
3. 测试时扩展
3.1 现有模型的扩展策略
现有数学和编码推理模型通过增加令牌数量来扩展测试时的计算量和Pass@1性能。例如,之前的DeepCoder - 14B - Preview模型通过将最大上下文长度从32K扩展到64K令牌,使LiveCodeBench Pass@1性能从57.8%提高到60.6%。对于智能体而言,测试时的性能也会随着推理期间计算的轨迹数量的增加而提升。
3.2 DeepSWE - Preview的测试时扩展策略
- 验证器类型:存在两种验证器方法。执行自由验证器(如R2EGym、Openhands Critic、Skywork)使用验证器LLM来选择最佳轨迹,验证器LLM通常经过训练以识别正确和错误的轨迹。例如,DeepSWE - Verifier经过2个周期的训练,用于识别正确/错误的补丁。执行基于验证器(如R2EGym)则使用另一个LLM生成多样化的测试和边缘情况,最佳轨迹应通过最多的测试。
- 混合扩展策略:DeepSWE - Preview的测试时扩展采用混合扩展策略,结合执行自由验证器和执行基于验证器,显著提高了Pass@1性能。
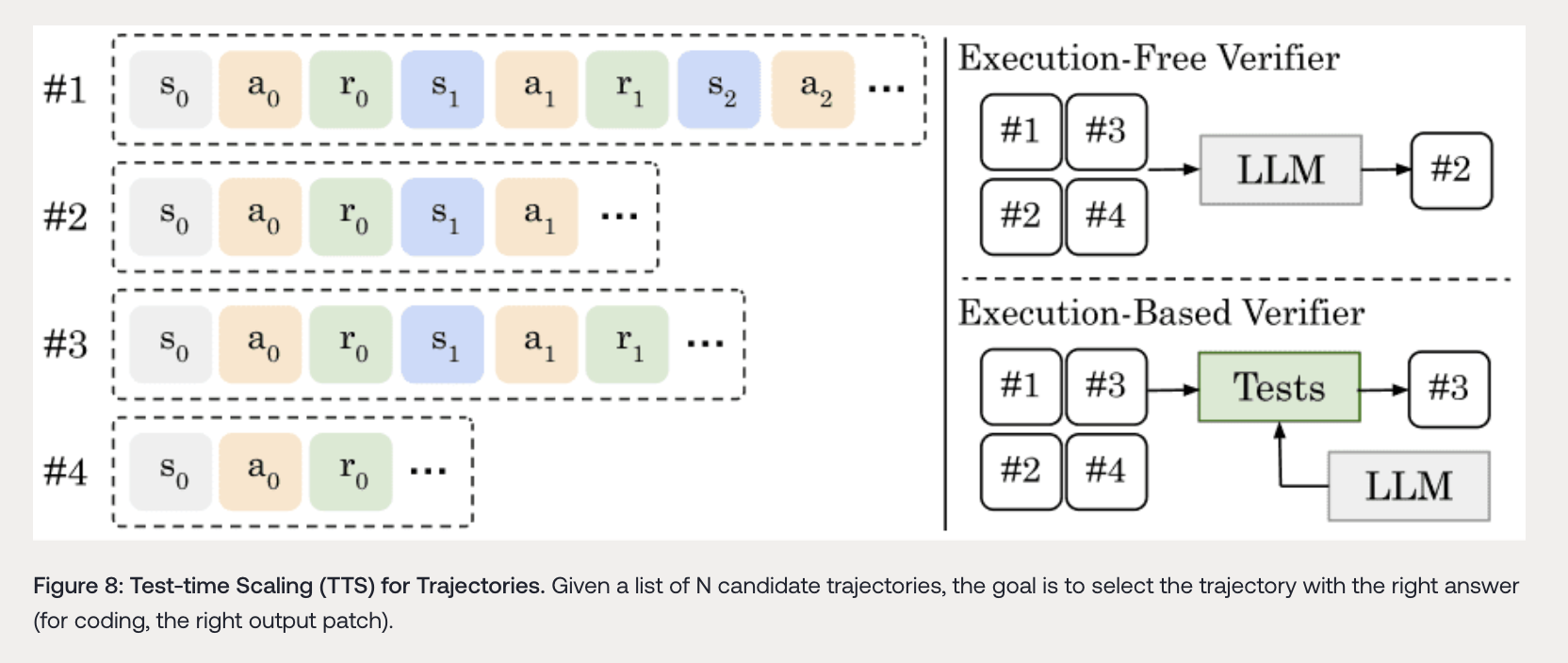
3.3 不同扩展策略的评估
- 按令牌数量扩展:当将最大上下文长度从16K扩展到128K令牌时,DeepSWE - Preview和其他基线模型的性能有所提升,但超过32K上下文后,性能提升幅度较小(≤2%)。这表明对于软件工程相关任务,单纯增加输出令牌数量可能效果不佳。
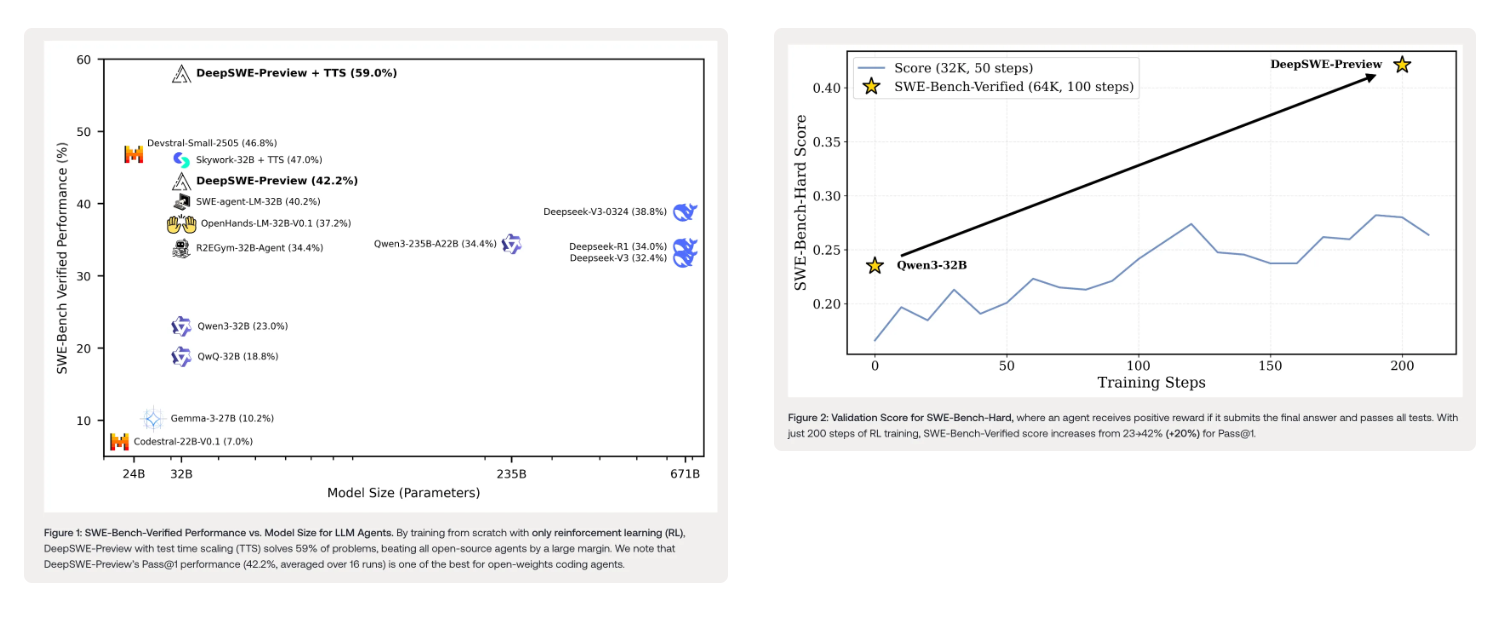
- 按轨迹数量扩展:通过不同的测试时扩展(TTS)技术对DeepSWE - Preview的性能进行评估。Pass@K表示轨迹级TTS技术理论上可达到的最优性能(100%准确率)。现有TTS技术远未达到最优,但混合扩展策略表现显著更好。使用K = 16次滚动时,DeepSWE - Preview达到59.0%的性能,优于执行基于和执行自由验证器。对于大多数实际场景,K = 8时即可实现TTS的大部分性能提升。
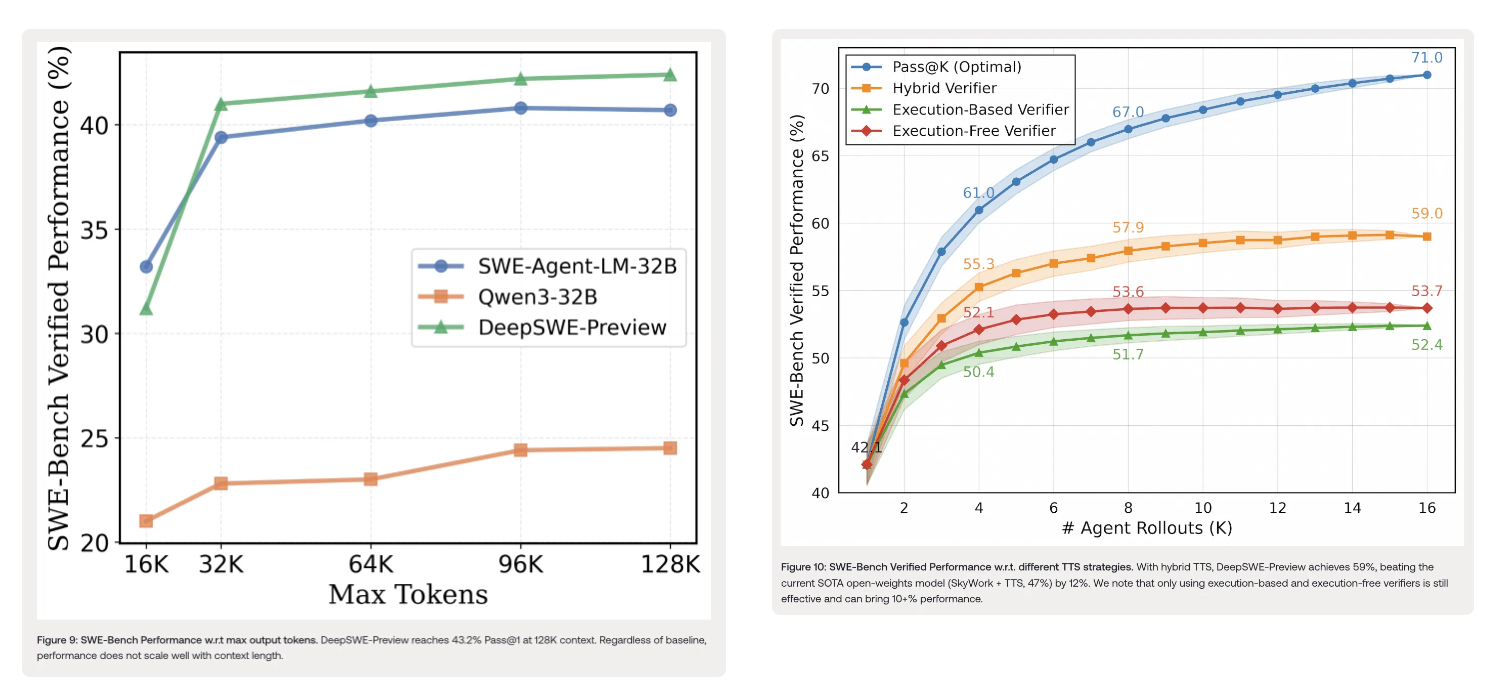
4. 评估
DeepSWE - Preview通过官方R2E - Gym代码库进行评估,最大上下文长度设为64k,最大环境步数设为100。生成的补丁被移植到官方SWE - bench仓库以计算最终分数。在SWE - Bench Verified基准测试中,DeepSWE - Preview的Pass@1准确率平均为42.2%(经过16次运行),Pass@16为71%。采用混合测试时扩展(TTS)后,达到59%的通过率。与其他开源模型相比,仅使用强化学习在Qwen/Qwen3 - 32B模型上进行训练的DeepSWE - Preview,其性能优于多种先前方法,这些方法使用了类似或更多的训练数据,并从更强大的专有教师模型进行蒸馏或有监督微调。
5. 涌现行为分析
5.1 考虑边缘情况和仓库回归测试
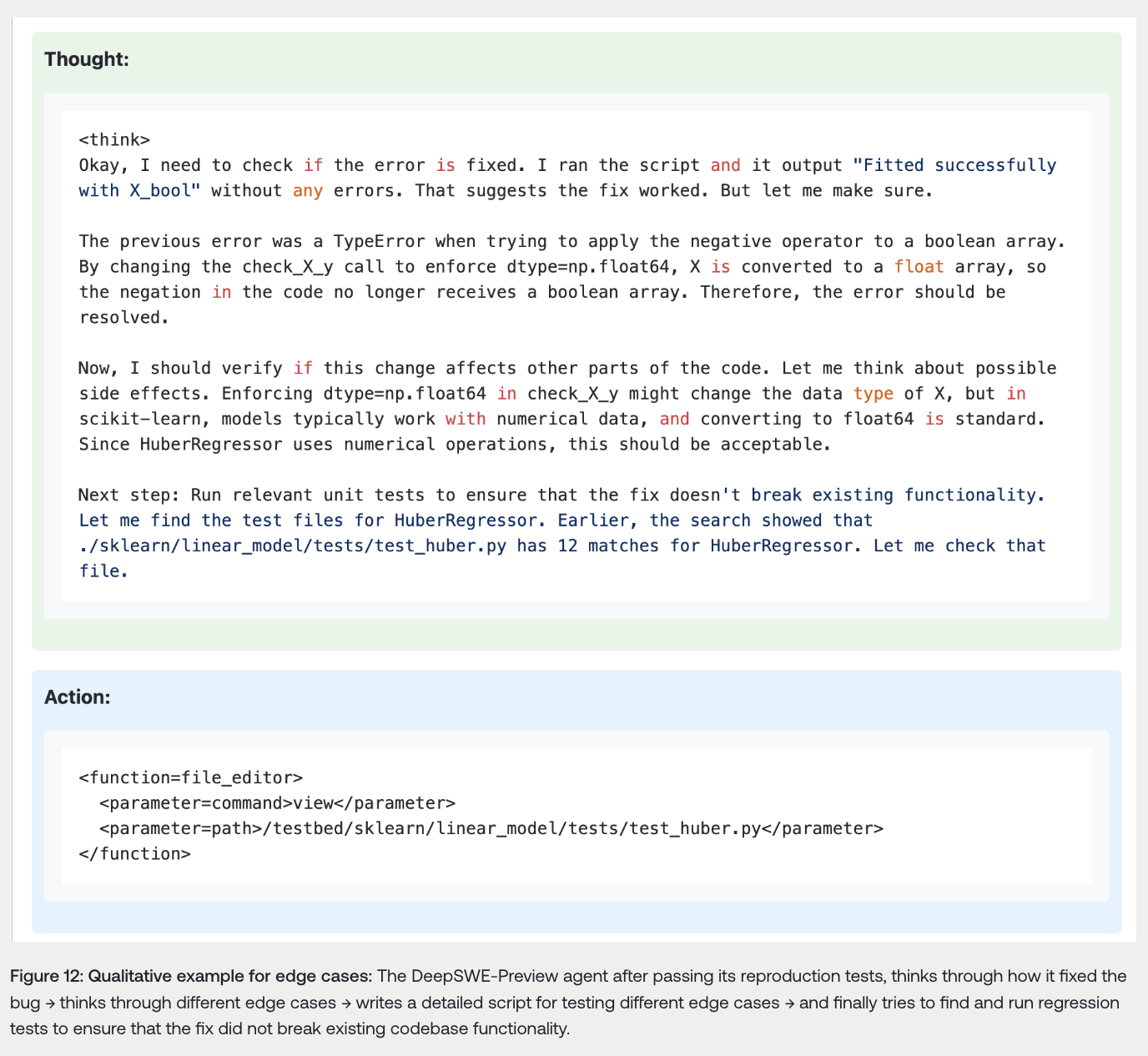
当前的软件工程智能体在修复提出的bug时,可能会忽略边缘情况或引入新的bug,从而破坏代码库的现有功能。然而,在纯RL训练过程中,DeepSWE - Preview智能体自动学会在尝试修复bug时考虑边缘情况(如不同的输入、数据类型等)。此外,它还会尝试在当前仓库中找到相关测试,以确保提出的更改不会破坏代码库的现有回归测试。例如,在通过复现测试后,智能体会思考如何修复bug,考虑不同的边缘情况,编写详细的脚本来测试这些边缘情况,并尝试找到并运行回归测试,以确保修复不会破坏现有代码库功能。
5.2 根据步骤复杂度自适应使用思考令牌
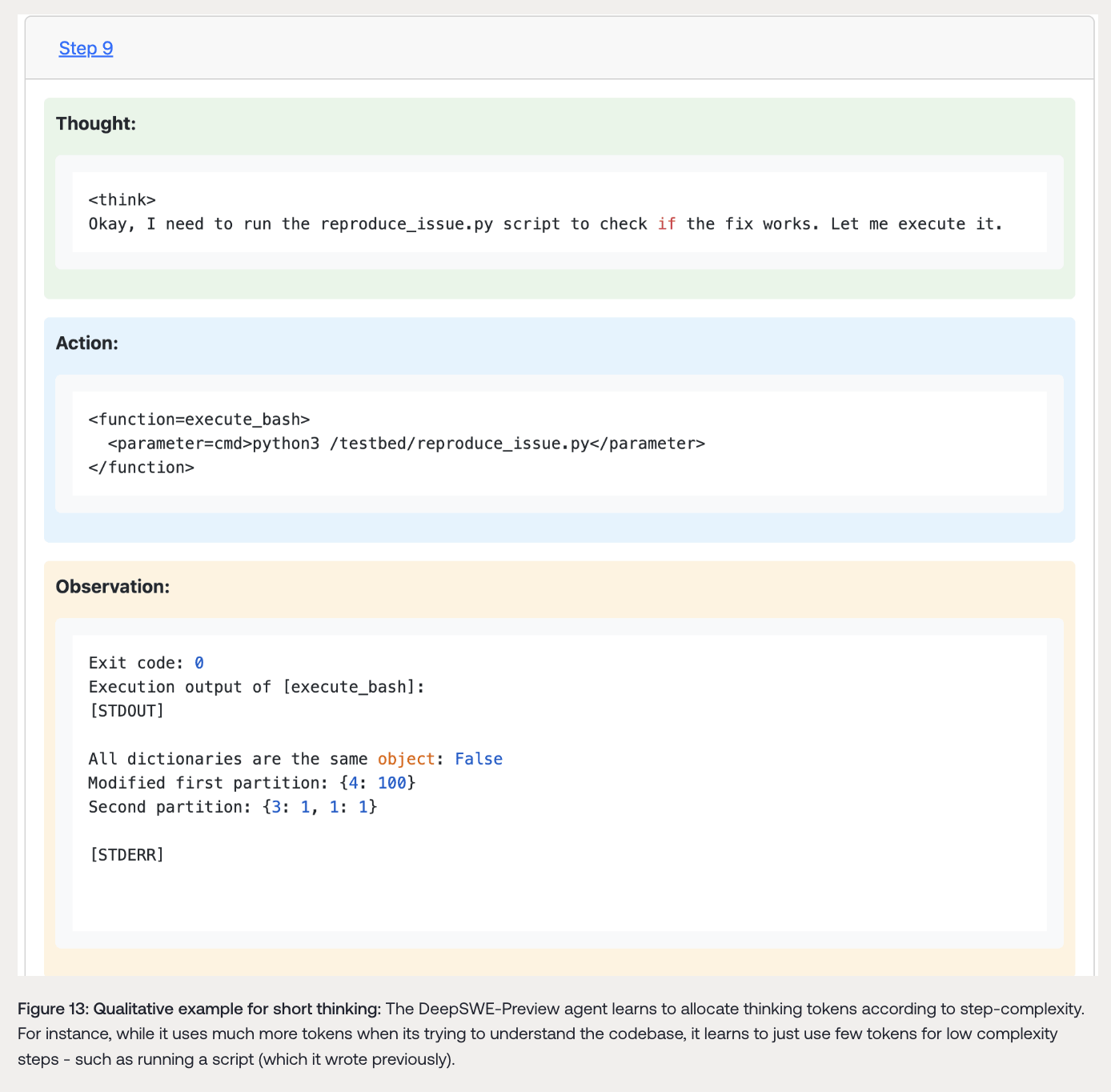
与单步非智能体编码任务不同,多步软件工程任务的不同步骤复杂度可能差异很大。在RL训练过程中,DeepSWE - Preview模型学会根据步骤复杂度分配思考令牌。在尝试定位和思考如何修复bug时,模型会分配大量思考令牌(通常在单步使用约2K令牌进行思考);而在执行其他步骤(如在文件中移动或在代码库中搜索术语)时,使用的思考令牌很少(约100 - 200)。
6. 其他实验尝试
6.1 使用Claude - Sonnet 3.7/4进行SFT
在Qwen3 - 32B上基于Claude - Sonnet 3.7/4进行有监督微调(SFT)后的模型上进行RL训练。经过100次迭代后,模型性能均未得到改善,且微调后的模型性能略低于SWE - agent - LM - 32B。
6.2 不同RL训练数据集和环境
除了R2E - Gym,还尝试在SWE - Smith和SWE - Gym两个替代数据集上进行RL训练。实验中,使用其他数据集时性能提升有限,训练过程中常出现较高的无解率。总体而言,R2E - Gym最适合RL训练,因为它为智能体提供了足够的课程学习,使其能够随着时间推移解决越来越难的问题。
6.3 非思考模式
在Qwen3 - 32B的非思考模式下进行RL训练,观察到性能提升有限。鉴于Claude - 4的非思考和思考模式在SWE - Bench - Verified上的性能相近,这可能是模型容量问题。
7. 未来工作
DeepSWE - Preview展示了在高质量执行环境(如R2E - Gym)下,纯RL驱动的推理可用于扩展长时多步智能体。未来计划在DeepSWE - Preview的基础上进一步训练另一个模型,类似于DeepSeek - R1在DeepSeek - R1 - Zero基础上的训练方式。此外,还计划训练具有更长上下文的更大模型,并将研究扩展到不同的智能体领域,如Web智能体。
8. 结论
DeepSWE - Preview是一个仅使用强化学习从Qwen3 - 32B模型训练的编码智能体,在SWE - Bench - Verified上取得了优异成绩,使用混合测试时扩展(TTS)后通过率达到59.2%(Pass@1为42.2%,Pass@16为71.0%)。它由rLLM框架驱动,rLLM是Agentica用于语言智能体后训练的开源框架。团队的使命是将强化学习推广到大语言模型,DeepSWE - Preview是在之前的数学和编码模型DeepScaleR和DeepCoder基础上的又一里程碑。为加速社区发展,团队开源了所有相关内容,包括数据集、训练代码和评估日志,希望推动强化学习和智能体AI的发展。