[CVPR2025]GLASS:Guided Latent Slot Diffusion for Object-Centric Learning
GLASS: Guided Latent Slot Diffusion for Object-Centric Learning
Krishnakant Singh1 Simone Schaub-Meyer1,2 Stefan Roth 1,2
1 Department of Computer Science, TU Darmstadt 2 hessian.AI
Paper
GitHub
摘要
面向对象的学习旨在将输入图像分解为一组有意义的对象文件(槽)。这些潜在对象表示能够实现各种下游任务。然而,面向对象的学习在现实世界的数据集上表现不佳,这些数据集包含多个复杂纹理和形状的自然日常场景中的对象。为了解决这个问题,我们引入了Guided Latent Slot Diffusion (GLASS),这是一种新的槽注意力模型,它在生成图像的空间中学习,并使用语义和实例引导模块来学习适用于各种下游任务的更好槽嵌入。我们的实验表明,GLASS在诸如(零样本)对象发现和现实世界场景的条件图像生成等任务上明显优于最先进的槽注意力方法。此外,GLASS首次实现了槽注意力对复杂、真实场景的组合生成,项目页面和代码。
引言
人类将场景感知为一组对象[35]。这种将场景分解为对象的能力使人类能够进行更高级的认知任务,如控制、推理以及对未见经验的泛化能力[25]。基于这些理念,面向对象的学习(OCL)旨在将场景分解为组成性和模块化的符号组件。OCL方法将这些组件绑定到潜在(神经)表示中,使得这些模型可以应用于因果推断[61]、推理[3]、控制[5]和分布外泛化[15]等任务。槽注意力模型[45]是一类流行的OCL方法,它们将图像分解为一组潜在表示,其中每个元素称为槽,竞争代表图像的某一部分。槽注意力方法可以归类为一种表征学习,其中的表示(槽)有助于各种下游任务,如属性预测[15]、图像重建[32]、图像编辑[73]和对象发现[62]。然而,许多有前景的槽注意力方法[45, 64, 65]仍然局限于合成和简单数据集[16, 26, 33, 37]。
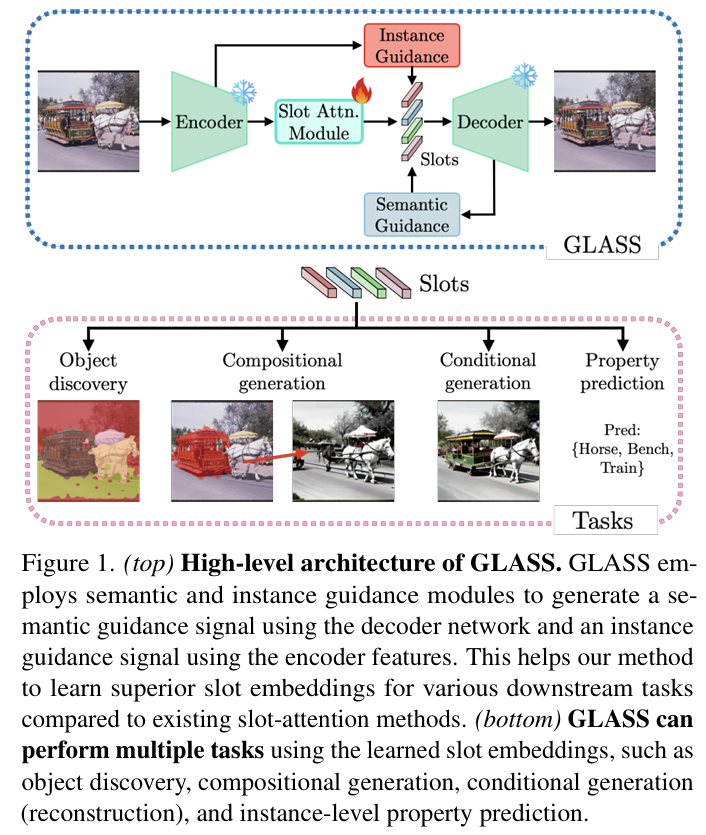
图1. GLASS的高层次架构。GLASS使用语义和实例引导模块,利用解码器网络生成语义引导信号,利用编码器特征生成实例引导信号。这帮助我们的方法学习比现有槽注意力方法更好的槽嵌入。(底部)GLASS可以使用学习到的槽嵌入执行多种任务,如对象发现、组合生成、条件生成(重建)和实例级属性预测。
一些最近的方法[32, 36, 62, 73]使用强大的现代编码器[8, 51]和解码器网络[56]扩展到复杂的现实图像[21, 44]。然而,这些模型仅限于对象发现,缺乏重建或执行现实图像的组合生成的多功能性。此外,所获得的槽表示的质量仍然有限,定性和定量结果都显示槽存在过度分割(将一个对象分割成多个槽)、不足分割(将多个对象分割成一个槽)或不精确的对象边界问题。这种过分割和欠分割问题也被称为部分-整体层次模糊性[29–31]。
为了克服上述问题,我们提出了Guided Latent Slot Diffusion (GLASS),这是一种基于弱监督槽注意力的模型,使用预训练扩散解码器重构输入图像和MLP解码器重构编码器特征。GLASS依赖于两个关键观察:(1) 在使用扩散模型生成的图像空间中学习能够很好地泛化到真实图像,因为生成图像的分布紧密模仿真实数据分布[23, 60, 66, 68];(2) 使用生成图像进行学习允许我们使用预训练扩散模型,如Stable Diffusion[56],作为伪地面实况生成引擎。为此,GLASS依赖于语义引导模块,该模块使用扩散解码器生成伪语义掩码。语义引导模块帮助GLASS解决过分割问题并获得精确的边界。
然而,仅使用语义引导会将槽偏向语义类别而不是图像中的实例,导致不足分割。为了解决这个问题,我们在形式上使用了一个MLP解码器的实例模块,类似于[62],通过重构编码器特征来对抗槽漂向语义类别的问题。这使得槽能够学习更好的槽嵌入,这些嵌入更加以实例为中心。
虽然GLASS的一些模块已被单独考虑,但其新颖的语义和实例引导模块结合扩散解码器的组合使其能够忠实地重构/有条件地生成输入图像。更重要的是,GLASS首次实现了使用槽注意力方法对复杂现实场景的组合生成。图1展示了高层架构和模型支持的下游任务。
通过我们的实验,我们证明了GLASS显著超越了现有的最先进的OCL方法[32, 36, 62, 73],在诸如(零样本)对象发现和VOC[21]上的条件图像生成任务中平均IoU提高了+9%,COCO[44]上提高了+5%。我们的方法在(零样本)实例级分割任务上也超过了最先进的OCL方法(在Object365[63]和CLEVRTex[37]上)。GLASS还在OCL方法中建立了新的FID分数标准用于条件图像生成。GLASS还使得使用槽注意力对复杂现实场景进行组合生成成为可能。此外,我们发现我们的方法在语言基础方法[46, 54, 72, 79]的语义级对象发现任务上表现出色。最后,我们展示了GLASS在依赖额外信息(如边界框或知道场景中的对象数量)的其他弱监督最先进的OCL模型[32]上表现优异。
相关工作
面向对象的学习将多对象场景分解为一组可组合且有意义的实体,使用自动编码目标[6, 13, 18, 20, 24, 25, 34, 45, 65]。OCL方法是对象级表示学习方法,可用于各种下游任务(参见表1)。在OCL方法中,槽注意力方法被证明是最有效的;它们采用结构归纳偏差来学习对象嵌入,即所谓的“槽”。
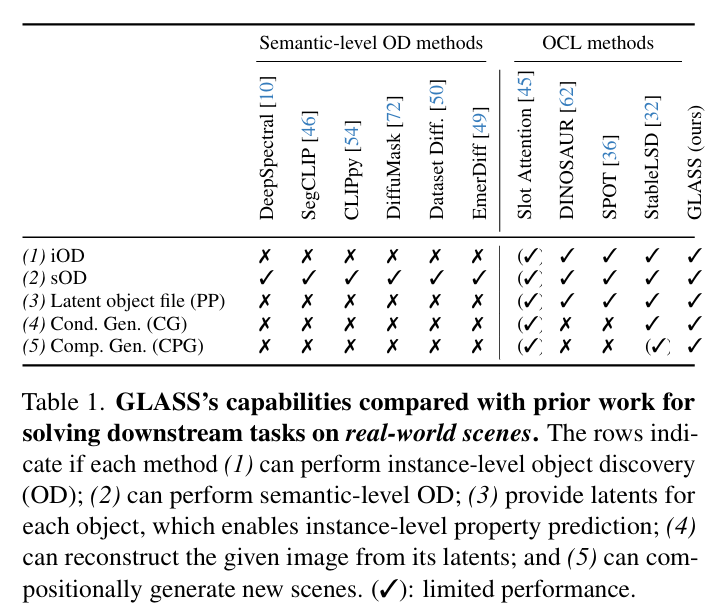
直到最近,槽注意力的一个主要障碍是其在现实世界图像上的较差表现[76]。这通过使用大规模预训练模型作为编码器[62]和解码器[32, 73]得到了部分缓解,这使得槽注意力可以应用于合成图像之外。然而,这些模型仍然受到部分-整体层次模糊性的困扰,影响了学习到的槽嵌入的质量,导致下游任务性能不佳。我们的方法旨在通过提出的语义和实例引导模块来缓解这一问题。
弱监督的面向对象学习。一些研究尝试通过额外的弱监督信号来解决OCL中的部分-整体层次模糊性问题。基于视频的OCL方法使用运动[41, 67]和深度线索[17],而基于图像的OCL方法则使用位置[40]和形状[16]信息。现有的弱监督基于图像的OCL方法[16, 40]仍局限于合成数据集,而我们专注于复杂的现实世界场景。GLASS还使用辅助信息,这里是以自动生成的标题形式。为了展示我们方法的有效性,我们还将GLASS与一种弱监督变体的StableLSD[32]进行了比较(因为它与GLASS的功能最接近,见表1)。
语义级对象发现。最近,人们对使用大规模基础模型[8, 51, 53, 56]的预训练特征进行语义分割产生了浓厚兴趣。其中一些模型[9, 14, 38, 39, 48, 50, 52, 54, 72, 75]依赖于语言线索,如图像级标签或标题来提取适合语义分割的特征。其他方法如[12, 47, 49, 77]不需要任何附加信息,而是使用聚类或图割法与预训练特征进行语义分割。与OCL方法不同,这些方法专门设计用于执行语义级分割,即它们不能区分同一类的对象。此外,它们不能有条件地或组合地生成图像,也不能执行对象级推理(见表1)。我们将这些方法与GLASS的语义聚焦版本进行比较,以展示其在语义级对象发现上的有效性。
预备知识
槽注意力[45]是一种基于一组 S ∈ R O × d s l o t s S ∈ ℝ^O×d_slots S∈RO×dslots的迭代精炼方案,由O个维度为 d s l o t s d_slots dslots的槽组成,这些槽要么随机初始化,要么通过学习函数初始化。一旦初始化后,槽表示就会根据编码输入图像的特征矩阵 H ∈ R N × d i n p u t H ∈ ℝ^N×d_input H∈RN×dinput(包含N个维度为 d i n p u t d_input dinput的特征向量)和槽的前一状态,使用GRU网络[11]进行迭代更新。槽注意力使用标准点积注意力[69]计算注意力矩阵 A ∈ R N × O A ∈ ℝ^N×O A∈RN×O,并在槽间进行归一化。这种归一化导致槽之间相互竞争,从而导致输入图像的有意义分解。槽使用输入特征H和计算出的注意力矩阵A的加权组合进行更新。形式上,我们有:
S ^ = ( A i , j ∑ l = 1 N A l , j ) i , j v ( H ) \hat{S} = \left( \frac{A_{i,j}}{\sum_{l=1}^{N} A_{l,j}} \right)_{i,j} v(H) S^=(∑l=1NAl,jAi,j)i,jv(H)
其中
A ( S , H ) = softmax ( k ( H ) q ( S ) T D ) A(S, H) = \text{softmax} \left( \frac{k(H) q(S)^T}{\sqrt{D}} \right) A(S,H)=softmax(Dk(H)q(S)T)
其中k、q和v是可学习的线性函数,用于将槽和输入特征映射到相同的D维。更新后的槽集合 S ^ \hat{S} S^被输入到解码器模型中以重建输入。解码器模型可以是简单的MLP[71]、变换器[65]或扩散模型[32, 73]。槽注意力方法使用输入和重建输入信号之间的均方误差损失进行训练。
潜扩散模型(LDM)[56]通过首先迭代破坏图像并在每个时间步添加高斯噪声来学习生成图像。这个去噪过程称为“前向过程”。然后,“反向过程”或生成步骤涉及学习一个神经网络 ϵ θ ϵ_θ ϵθ,预测在每个前向扩散步骤中添加的噪声,并在每个时间步从嘈杂图像中去除噪声。为了启用扩散模型的条件生成,通常以文本的形式提供额外的条件信号。参数θ通过最小化预测噪声和地面实况噪声之间的均方误差来学习。训练完成后,可以通过采样随机噪声向量并运行带有给定条件信号的反向过程来生成图像。最常见的选择是具有自我注意和交叉注意层的U-Net[57]。交叉注意层在条件信号和像素特征之间进行交叉注意。
GLASS:引导潜槽扩散
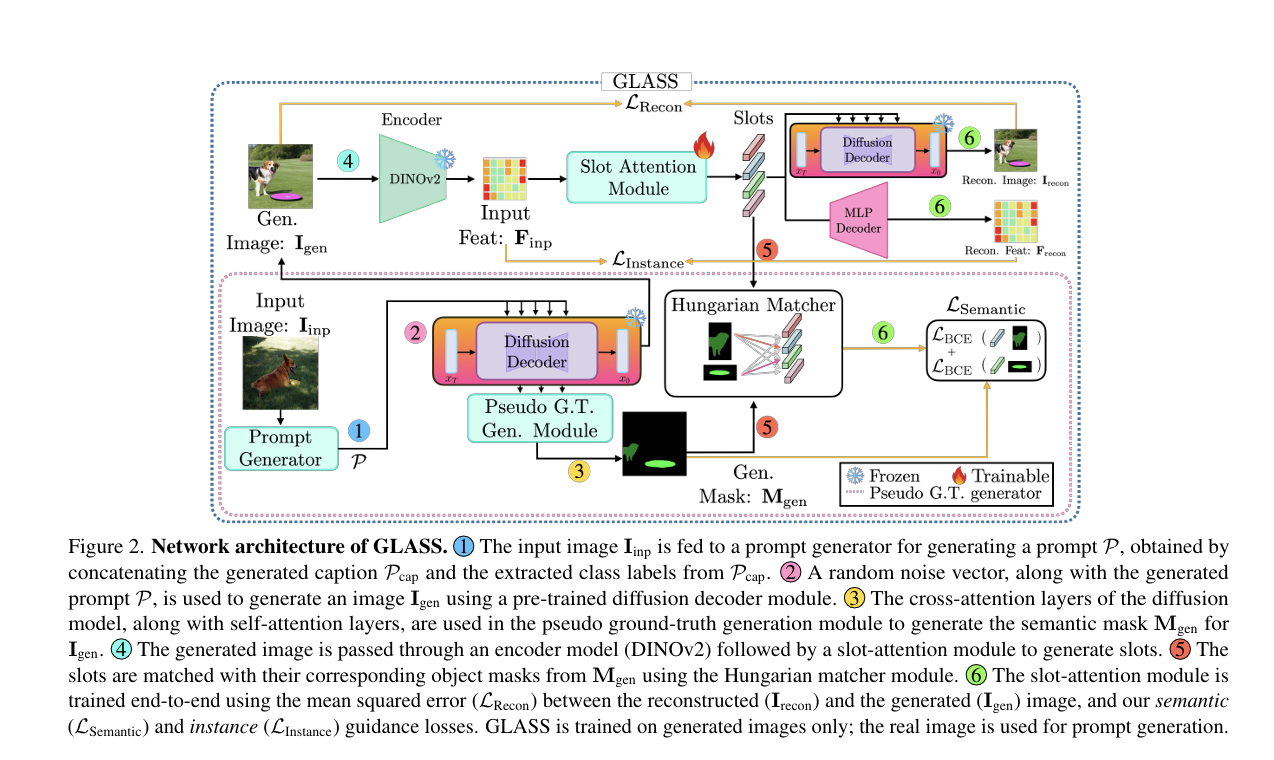
GLASS基于在DINOv2[51](编码器)模型的特征上训练槽注意力模块,并使用预训练的稳定扩散(SD)模型[56](解码器)来重建图像,以及一个小的MLP模型来重建编码器特征。GLASS利用扩散解码器和预训练的字幕生成模型[43]创建引导信号(分割掩码)来引导槽。
我们提出的方法的一个关键设计选择是在预训练扩散模型生成的图像空间中学习槽注意力模块。这使我们能够使用扩散解码器的U-Net[57]中的交叉注意力层来获取给定图像的语义掩码。
现在让我们详细描述每个步骤。
条件图像生成
给定输入图像I_inp,我们首先将其传递给字幕生成器(BLIP-2[43])以生成描述输入图像的字幕P_cap。我们使用词性(POS)标记器[4]从生成的字幕中提取名词,并保留属于COCO数据集[44]类标签集合的名词 C = c 1 , c 2 , . . . , c k C = {c1, c2, ..., ck} C=c1,c2,...,ck。然后通过连接生成的字幕和提取的类标签创建提示P=[P_cap; C]。这个提示P被输入到文本嵌入器中,在这里使用CLIP[53]来获得嵌入 Y ∈ R U × d t o k e n Y ∈ ℝ^U×d_token Y∈RU×dtoken,其中U是维度为 d t o k e n d_token dtoken的令牌数。然后通过从 N ( 0 , I ) N(0, I) N(0,I)中采样随机噪声并在预训练扩散模型上运行“反向过程”来生成图像 I g e n I_gen Igen,并以Y作为条件信号。
伪地面实况生成模块
为了从扩散模型中提取时间t层l的交叉注意力图,我们创建了一个包含单个令牌的新提示,即来自C的一个类令牌。目标标签的交叉注意力图可以通过目标类标签嵌入和嘈杂图像特征的线性投影在共同空间中的标准点积注意力来计算。这针对C中的每个目标类标签完成。最终的交叉注意力图 A C A ∈ [ 0 , 1 ] H × W × k ACA ∈ [0, 1]^H×W×k ACA∈[0,1]H×W×k 是通过对不同时间步长和分辨率下的提取交叉注意力图进行调整大小和平均得到的。这里,H和W是输入嵌入的大小,$k = |C| $是目标类的数量。获得的交叉注意力图通常很嘈杂,需要进一步优化。最近,几项研究解决了优化这类交叉注意力图的问题[39, 50, 72]。我们遵循[50]的方法,使用自我注意力图来优化交叉注意力图。特别是,优化后的掩码M_ref是通过对自我注意力图 A S A ∈ [ 0 , 1 ] H × W × H × W A_{SA} ∈ [0, 1]^H×W×H×W ASA∈[0,1]H×W×H×W进行指数运算并与交叉注意力图ACA相乘得到的,如[50]所述。最终的语义掩码 M g e n M_{gen} Mgen是通过对C中的所有目标类标签的 M r e f M_{ref} Mref进行像素级arg max操作找到负责某个像素的类得到的。最后,使用范围阈值分类每个像素为前景或背景。详见补充材料。请注意,尽管我们的伪地面实况生成方法类似于[50],但GLASS将其与匈牙利匹配模块和引导槽结合在一起,超出了先前的工作。
槽匹配
一旦生成图像 I g e n I_{gen} Igen及其对应的伪地面实况语义掩码 M g e n M_{gen} Mgen,我们可以使用这些语义掩码来指导槽。首先,我们将生成的图像I_gen通过编码器和槽注意力模块以获得槽分解。我们使用公式(1)中的注意力矩阵 A ( S , H ) A(S, H) A(S,H)提取每个槽的预测掩码,并将它们调整为生成的语义掩码 M g e n M_{gen} Mgen的分辨率。然后将每个预测掩码分配给生成的语义掩码的组件。这类似于求解二分匹配问题,我们使用匈牙利匹配[42]。
形式上,给定O个槽及其预测掩码和包含F个段的语义掩码,二进制匹配矩阵 P ∈ 0 , 1 O × F P ∈ {0, 1}^O×F P∈0,1O×F 可以使用匈牙利算法计算,该算法最小化将槽i分配给生成掩码 M g e n M_{gen} Mgen 中段j的成本 c i , j c_{i,j} ci,j:
arg min P ∑ i = 1 O ∑ j = 1 F − c i , j p i , j \arg \min_P \sum_{i=1}^{O} \sum_{j=1}^{F} -c_{i,j} p_{i,j} argPmini=1∑Oj=1∑F−ci,jpi,j
其中 p i , j ∈ 0 , 1 p_{i,j} ∈ {0, 1} pi,j∈0,1 表示槽i是否与 M g e n M_{gen} Mgen 的段j匹配。优化受限于每个槽只能分配给一个段。成本 c i , j c_{i, j} ci,j 由槽i的预测掩码与生成的语义掩码 M g e n M_{gen} Mgen的段j之间的平均交并比(IoU)给出。
损失函数
一旦分配完成,我们的引导槽注意力模型使用生成图像Igen和重建图像Irecon之间的均方误差损失(LMSE)以及我们的(语义)引导损失,即Mgen和槽预测掩码A(S, H)之间的二元交叉熵损失(LBCE)进行端到端训练。二元交叉熵损失仅在根据匹配矩阵P ≡ P ( M g e n , A ( S , H ) ) P(Mgen, A(S, H)) P(Mgen,A(S,H))匹配的槽上计算。然而,仅使用图像重建和语义引导损失会导致槽表示漂向语义类而不是对象。受[62]启发,其利用特征重建损失来学习更好的槽表示,我们利用特征重建来解决语义漂移问题。这个实例引导损失由输入(Finp)和重建(Frecon)特征之间的均方误差给出(见图2)。我们的完整损失如下所示:
L = L M S E ( I g e n , I r e c o n ) + λ s L B C E ( P ( M g e n , A ( S , H ) ) ) + λ i L M S E ( F i n p , F r e c o n ) L = LMSE(Igen, Irecon) + λs LBCE(P(Mgen, A(S, H))) + λi LMSE(Finp, Frecon) L=LMSE(Igen,Irecon)+λsLBCE(P(Mgen,A(S,H)))+λiLMSE(Finp,Frecon)
语义引导损失有助于学习符合对象边界的槽表示,避免对象被分成多个槽(即避免过分割),但这会导致槽关注语义而不是实例。特征重建损失有助于解决语义漂移问题,因为预训练ViT模型的特征已经表现出实例感知特性[19],但不使用语义引导会导致过分割和欠分割问题。因此,当实例和语义引导结合时,槽会绑定到实例而不是语义,从而缓解部分-整体模糊性,参见图4。
我们将GLASS的训练过程分为两个阶段:在第一阶段,仅训练槽注意力模块和MLP解码器。这有助于学习绑定到实例的槽嵌入。在第二阶段,我们联合训练槽注意力模块与扩散和MLP解码器。在此阶段,我们对槽注意力和MLP解码器模块使用非常小的学习率(基本冻结)并对扩散解码器使用较高的学习率。第二阶段帮助扩散解码器与槽嵌入对齐并产生高质量的图像。除非另有说明,我们在所有实验中使用 λ s = 0.7 λ_s= 0.7 λs=0.7 和 λ i = 0.9 λ_i= 0.9 λi=0.9。图2显示了我们的完整架构并说明了每个步骤。更多细节请参见补充材料。
实验
我们的主要目标是学习更好的对象表示,即槽嵌入。为了评估所学表示的有效性,我们在各种任务上进行评估,如对象发现、实例级属性预测、重建和组合生成。GLASS使用来自BLIP-2[43]的生成字幕,该模型训练于大量从网络挖掘的图像-字幕对(一小部分来自COCO数据集);因此,我们的模型可以被视为弱监督的。因此,我们还与其他弱监督OCL方法进行比较。我们进一步提出了一种变体,称为GLASS†,它使用与输入图像关联的真实类标签而不是生成的字幕来进行生成和语义引导。
实例感知对象发现
测试槽如何绑定到对象的标准方法是在对象发现任务上进行评估,即生成覆盖图像中出现的独立对象的一组掩码。我们将GLASS与现有的最先进的面向对象的方法进行比较,使用OCL文献中流行的多对象发现指标[32, 62, 73]。这包括(i) 预测掩码和地面实况实例掩码之间的平均交并比(mIoUi),(ii) 实例级掩码的最佳重叠平均值(mBOi),以及(iii) 类别级掩码的最佳重叠平均值(mBOc)。详细信息和附加结果请参见补充材料。
表2显示,GLASS在mIoUi、mBOi和mBOc指标上明显优于所有之前的OCL方法。表3显示了SO-PO-GO指标。我们的方法在绑定到单个对象的槽百分比上更高,同时减少了PO和GO指标中的过分割和欠分割问题。
零样本学习。接下来我们展示了减少部分-整体模糊性也有助于对象发现(OD)的零样本方式。由于槽现在偏向对象,它们可以更好地分割场景,即使没有经过这些场景的训练。我们使用在COCO数据集上训练的GLASS报告了CLEVRTex[37]和Obj365[63]数据集上的零样本OD结果,见表4。我们通过使用地面实况边界框提示SAMv2[55]获得了Obj365数据集的掩码。我们观察到我们的方法再次优于最先进的OCL方法。
与弱监督OCL的比较。由于GLASS依赖于BLIP-2[43]进行字幕生成,因此可以认为它是弱监督的。我们展示了这种(非常)弱监督形式的表现远好于更昂贵的弱监督信号,例如边界框或知道场景中的对象数量。特别是,我们将我们的方法与两种弱监督变体的StableLSD进行比较:(i) StableLSD-BBox,它使用与每个对象相关的边界框信息来初始化槽。这种形式的引导以前在[41]中使用过。(ii) StableLSD-Dynamic,它不是为每个场景固定数量的槽,而是动态地为每个场景分配等于存在的对象数量的槽。[80]表明这对于解决部分-整体模糊性问题是有用的,从而导致更好的对象发现。我们选择StableLSD进行比较,因为它在支持的下游任务方面最接近我们的模型(见表1)。如表5所示,StableLSD的弱监督变体优于StableLSD。重要的是,GLASS甚至超过了这两种弱监督方法,尽管它使用的监督信号更弱。
语义和实例引导的重要性
接下来,我们评估语义和实例引导损失的贡献。表6a显示了使用不同的三个损失函数组合(LRecon、LSemantic和LInstance)的mIoUi指标。我们观察到,将语义和实例损失一起使用会产生比单独使用它们更好的结果。更重要的是,图4中的定性结果显示,仅使用重建损失会导致噪声分割(过分割和欠分割)。添加语义损失可以产生更精确的边界,使分割不再那么嘈杂。然而,仅使用语义损失会导致语义漂移并将槽绑定到语义类别(欠分割);添加实例引导可以避免语义漂移问题,并使槽绑定到对象而不是语义类别。因此,利用语义和实例引导可以缓解过分割和欠分割问题,为下游任务提供更好的槽嵌入。
不同编码器网络的性能
接下来,我们分析GLASS对编码器架构的依赖性。我们比较了三种不同的编码器模型,即掩码自动编码器(MAE)[27]、DINOv2[51]和DINOv1[8]。如表6b所示,我们的方法对编码器模型的选择具有鲁棒性。此外,它在所有编码器模型架构上都优于在下游能力方面最接近我们的模型(StableLSD)。
伪地面实况生成模块的重要性
我们方法的一个关键优势是利用解码器模型进行槽解码和语义引导生成,从而无需额外的引导生成依赖。接下来我们展示,与从模型如SAMv2[55]获取引导信号相比,我们获取引导信号的方法更为优越。为了评估语义引导信号的影响,我们在此实验中关闭了实例引导(λi= 0)并将λs设置为1。如表6c所示,我们的伪地面实况信号比使用SAMv2的掩码效果更好。这是因为,在没有提示的情况下,SAMv2产生的掩码要么过分割,要么欠分割,相比之下不如我们方法的掩码。为了有效使用SAMv2,我们需要一个额外的提示,例如边界框,但这种形式的监督比生成的字幕或图像级标签更昂贵。
生成能力
条件生成/重建
在GLASS中使用基于扩散的解码器使我们的模型能够从槽中条件性地重新生成输入图像,并且更重要的是,能够组合性地生成新场景。我们将GLASS与StableLSD进行基准测试,因为这是迄今为止唯一能够重建复杂现实世界图像的OCL模型。我们报告PSNR、SSIM[70]、LPIPS[78]和FID[28]指标。无论是定量(见表7)还是定性(见图5),我们的方法都优于StableLSD。FID是使用512张生成和真实的COCO图像计算的。定性结果显示,GLASS能够更忠实地重建输入图像,并且具有更高的保真度。
组合生成
据我们所知,GLASS是第一个能够以高保真度组合生成复杂现实世界场景的槽注意力方法。在图6中,我们展示了可以通过移除一个槽从输入场景中移除对象,或者通过添加来自另一个场景的槽将对象添加到场景中的示例。与StableLSD的组合生成会导致低保真度图像,详见补充材料。
属性预测
实例级属性预测评估槽表示的质量。在此任务中,我们预测对象属性,例如从学习到的槽嵌入中获取的类标签和对象位置(对象边界框的中心)。我们比较了GLASS和StableLSD学习到的特征的信息量。我们报告标签预测的top-1准确率和对象中心预测的均方误差。如表8所示,GLASS在两项任务上始终优于StableLSD,表明我们学到的槽包含比StableLSD的槽嵌入更多的关于对象的信息。
语义级对象发现
由于我们的方法使用了大规模预训练的基础模型[8, 51, 56],我们也将其与之前利用这些基础模型特征进行语义级分割的方法[e.g., 12, 46, 72, 79]进行了比较。虽然我们的方法设计用于实例级分割,但它可以修改为启用语义级分割。我们考虑了一个变体GLASS-Sem(语义聚焦的GLASS),其中我们故意对图像进行欠分割(一个槽负责属于同一类的多个对象)。为此,我们在训练期间将实例引导损失项设置为低值(λi=0.1)。我们报告了在预测掩码和地面实况语义掩码之间计算的mIoUc指标。
表9显示,我们的方法不仅优于所有面向对象的学习方法,还优于依赖大规模模型特征进行语义级对象发现的方法。我们将GLASS的改进归因于不同基础模型之间的特征的仔细交互:我们的方法聚合了基础模型(DINOv2[51])的特征,但这种特征聚合是由我们的语义引导模块指导的,这帮助它实现了精确的边界。这一解释得到了以下观察的支持:即使像GLASS一样使用稳定扩散特征来创建伪掩码,GLASS也优于诸如Dataset Diffusion[50]等模型。
限制
尽管我们的工作在几个任务上比最先进的基线OCL方法取得了更好的结果,但仍有几个局限性:(i) 首先,像大多数基于槽注意力的方法一样,我们的方法对槽的数量敏感(参见补充材料中的表12)。(ii) 虽然我们的方法更加以实例为中心,但它有时会将槽绑定到语义上,而不是实例上(参见补充材料中的图10)。(iii) 图像生成结果仍然低于最先进的生成模型,需要进一步改进。
结论
我们提出了GLASS,这是一种新颖的面向对象的学习方法,它在预训练扩散模型生成的图像空间中学习。我们的方法利用语义和实例引导来学习更好的以实例为中心的表示。我们在各种任务上明显优于之前的最先进的OCL方法:实例级(零样本)对象发现和条件图像生成。我们的工作还超越了使用大规模预训练模型进行语义级对象发现的最先进的模型,并且比同样多功能的OCL方法学习到了更好的槽表示用于实例级属性预测。值得注意的是,我们的方法是第一个能够组合生成复杂现实世界场景的OCL方法。
致谢
本项目得到了欧洲研究委员会(ERC)根据欧盟地平线2020计划(资助协议编号No. 866008)的资助。该项目还部分得到了黑森州通过“人工智能第三波(3AI)”项目的资助。
参考文献
略