LLMs 系列实操科普(6)
十二、语音输出输出
到目前为止,我们讨论的所有内容都与通过文本与模型交互有关,我们输入文本,它就会返回文本。现在我想讨论的是不同的交互方式。这意味着我们希望以更符合人类自然习惯的方式与这些模型互动。
所以我想和它对话,也希望它能回应我。我想给它传递图像或视频,反之亦然。我希望它能生成图像和视频作为反馈。因此,它需要处理语音、音频以及图像和视频的多模态交互。
我们首先介绍以 chatgpt 为例的语音方面的体验。

首先是这个麦克风图标,它实际是个语音听写功能,即背后调用的是一个语音转文字的模型,将我们的语音转换为文字,然后将文字传输给 chatgpt,chatgpt 的输入和输出本质上还是文字。
![[audio2.png|500]]
旁边的这个是真正的语音模式,即你可以直接类似和朋友语音聊天一样跟模型对话,模型的输入直接就是你的声音,它的输出也是声音,你可以选择不同的人物声音风格,这就像在和一个虚拟的朋友聊天一样,你可以随时打断它的输出,变更到其他话题上。当你语音结束时,在聊天窗口会以文字会话的形式呈现你们的所有通话记录。(下图中前两张图)
(语音功能更多是在手机移动端上使用比较多,此处就随便聊了两句,这里呈现的是聊天结束后自动转录的内容,这里由于是动态语音交互,不方便截图记录,就不演示更多内容了)
现在的模型能够真正将音频作为语言模型内部处理的实际内容,可以像将文本分割成 token 那样,以类似的方式截断音频等不同模态的数据。通常的做法是将音频分解成频谱图,以查看音频中存在的所有不同频率。然后,将它们分成小窗口,基本上将它们量化为 token。这样,就可以拥有一个包含 10 万个可能的小音频块的词汇表。然后用这些音频片段来训练模型,这样它才能真正理解这些小的音频片段,这赋予了模型许多能力。
chatgpt 的语音功能非常谨慎,它不太喜欢做事,会拒绝我们的很多请求,有时候确实会觉得它有点鸡肋和烦人。
claude 和 gemini 目前不支持这种语音交互能力,在移动端上只有麦克风功能,而且 claude 还不知中文语音。
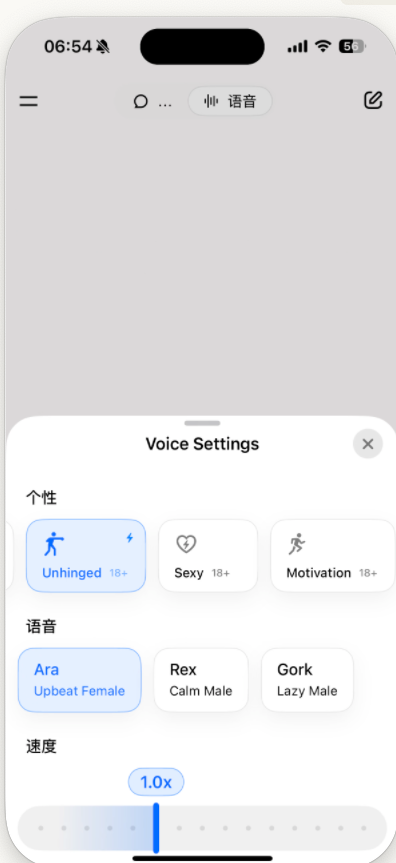
相比之下 grok 可谓“丧心病狂”,它支持非常丰富的个性,甚至有一些 18 禁的个性内容,例如,比较变态的内置个性有:
- Meditation: 冥想
- Unhinged: 失控的
- Sexy: 性感的
- Motivation: 动机
- Conspiracy: 阴谋
你也可以添加自定义个性,当然还有很多比较友善的内置个性,例如儿童模式,可以给小孩讲故事等。
十三、Notebook LM

这是 google 推出的针对 notebook 的 LM 应用产品,登录 notebooklm.google.com 页面使用,这里你可以添加各种类型的文档或者笔记,甚至是 mp3 音频文件,我们可以把前文中我们展示的 meta 论文,再次拿到这里演示,你甚至都不需要本地上传文件,直接提供论文地址即可。

整个页面分为三个板块,左侧是你的资料来源,例如此处我们仅提供了一个论文,在中间位置会给出你资料的摘要概述,并可生成音频概览或思维导图,下方你可以就你的资料跟模型会话,例如可以让它帮你解读论文,答疑,翻译,整理笔记等;左侧中间会有一些预置的功能选项,如学习指南,常见问题解答等。你都可以点击,然后模型自动帮你抽取知识点或答疑等



右上角生成了一段 9 分钟的播客音频文件,这太强了,我甚至都听不出来这是模型生成出来的,因为无论从说话<人语气,两个人互动上,甚至是内容上,简直太棒了,两个人就以播客聊天的形式,将这边论文的核心内容都给我讲述了出来,这太强了。
我把这段音频文件分享出来,你可以听一下,感受一下: https://notebooklm.google.com/notebook/e98b64b0-880f-4813-b808-10e2a2fc11f8/audio
这个功能对于辅助阅读论文非常有效,是一款非常好的笔记助手平台。但仍需强调的是,不要上传自己的私密文件,注意隐私安全。
你可以将一些你感兴趣的资料,但又太多来不及一一详读的内容,通通扔给它,让它以音频播客的形式输出,这样你走路、开车或者无聊的时候都可以拿出来听一听。
十四、图像
就像音频一样,事实证明可以用 token 重新表示图像,我们可以将图像表示为 token 流,并且我们可以让语言模型以我们之前对文本和音频建模的相同方式对它们进行建模。
举个例子,最简单的方法就是你可以取一张图像,基本上创建一个像矩形网格的东西,然后把它分割成小块。然后图像就只是一系列的小块,每一个小块你都可以量化。所以基本上可以想出一个词汇表,比如说 10 万个可能的小块,然后你只用词汇表中最接近的小块来表示每一个图片中的小块。正是这种机制让你能够将图像转化为一系列 token 流。然后,你可以把它们放入上下文窗口,并用它们来训练你的模型。令人惊叹的是,语言模型,即 Transformer 神经网络本身,甚至不知道其中一些 token 恰好是文本,一些 token 恰好是音频,还有一些 token 恰好是图像。
它只是对 token 流的统计模式进行建模。然后,只有在编码器和解码器部分,我们才暗自知道图像是以这种方式编码的,而流是以这种方式解码回图像或音频的。就像我们处理音频一样,我们可以将图像分割成 token ,并应用所有相同的建模技术,实际上没有什么变化,只是 token 流和关于 token 的词汇发生了变化。
关于图像的使用,想必大家用的已经非常多,图像具有非常多样化的娱乐功能,但技术在近几个月已经发生了很多变化:
- 首先是看图的能力,早期语言模型并不具备看图能力,它只是一个纯文本的模型,而之所以能看懂图,是借助了一个专门的图像处理的模型,该模型能将图片中的内容以文字描述输出,然后这段文本作为语言模型的输入,使你表面上看起来好像它看得懂图。
- 目前大部分模型应该仍不具备自身可读图的能力
- 然后是生图的能力,目前貌似只有 chatgpt 一家是支持模型自身生图的能力,在以往,chatgpt 生图是将用户的生图需求,转换为其他生图模型可接受的生图 prompt,这其实也是类似工具的使用,通过呼叫专门用于文生图的模型进行图片创作,如 chatgpt 此前使用的是 Dall-E 系列的文生图模型
- 而目前 chatgpt 可自身生成高质量图片,但具体技术细节 openai 并未公开,其创作过程看起来类似扩散模型技术。

效果非常惊人,在这之前想通过 stable diffusion 等方式实现该功能非常非常困难,几乎不可实现。不过模型也不是真的神通广大到无所不能,如果较真的话,首先模特人脸变了,背景墙变了,包包的卡扣变了,裤子变了。
我在日常生活中,会经常采用截图的方式,将我感兴趣的图片交给 LLM 处理,例如截取一段文本,让它识别其中的内容,并同步翻译或解释,这在看书或看论文时有用,或者截一个公式让模型输出 latex 等。
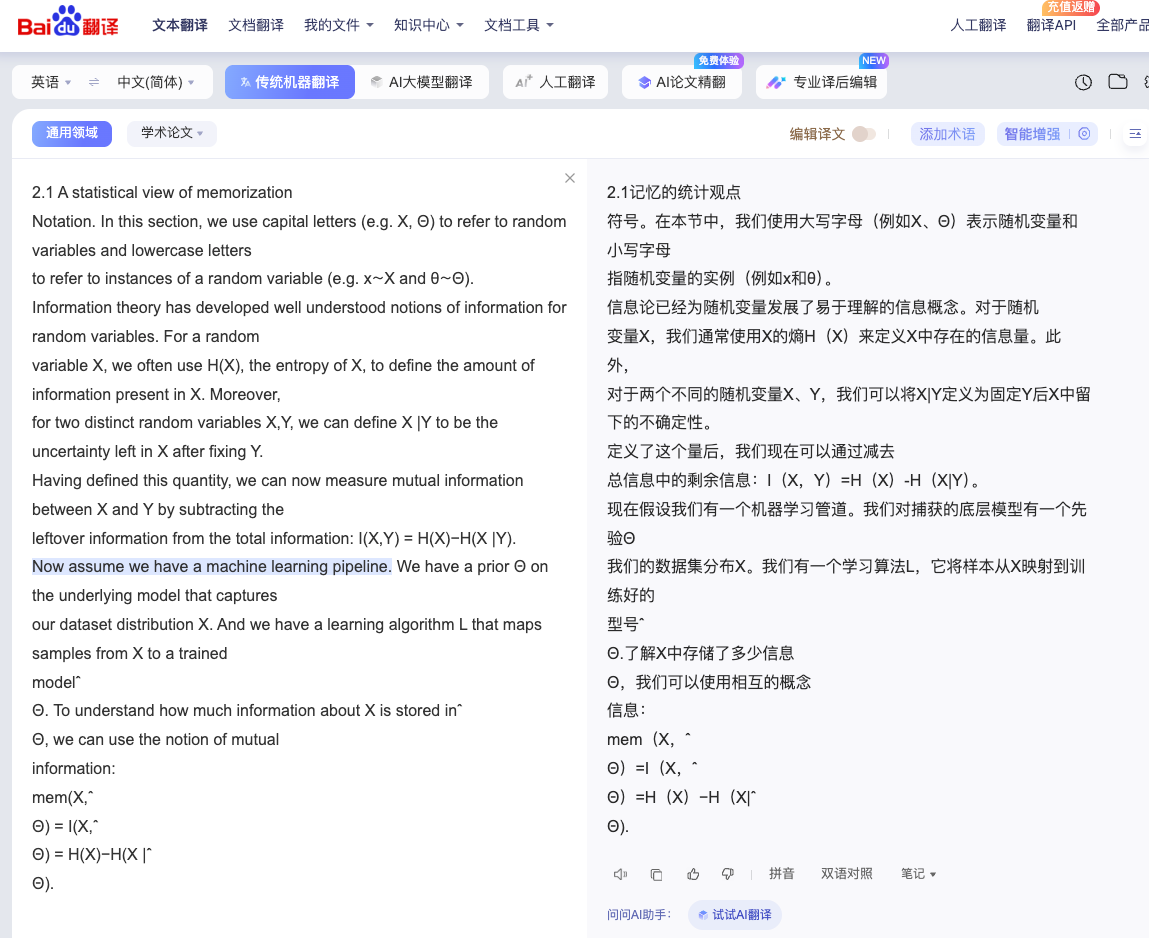
说到这里,还有一个我用的比较多的,例如阅读英文论文时,我想把英文翻译为中文,传统方式是复制论文内容粘贴到百度翻译等传统翻译工具中,但如果论文中夹杂着公式或其他内容后,粘贴到传统翻译工具下的内容就会乱七八糟,翻译结果更是乱,而现在虽然复制出来的文本仍然是乱码的,但模型可以自行修正,真的不错,而如果是截图方式,让模型自行处理这段文本或公式,效果更理想。
例如以这里的论文片段为例:

我们分别展示用传统百度翻译,以及 chatgpt 文字乱码修正,chatgpt 直接识别图片


再比如一个日常场景,当你去医院做了体检或者其他方面的检查,面对一堆你不熟悉的专业术语和指标,你都可以向模型咨询,这里并不涉及 AI 诊断等内容,仅仅是一些指标解读,而这样的知识网络上非常常见,所以模型会做的非常好。
十五、记忆
在前面的内容中,我们每一次对话都是从空白的窗口开始,直到结束,当开始一个新的对话或聊天时,所有内容都会被清空。但 ChatGPT 确实具备在聊天之间保存信息的能力,只是需要被调用才能实现。所以有时候 ChatGPT 会自动触发这个功能,但有时你需要主动提出请求。基本上,你可以这样说:"你能记住这个吗?"或者"记住我的偏好"之类的话。

在前文中,我让它介绍下费曼,然后我说我很喜欢这种风格,需要你记住,然后模型就开始更新保存的记忆

这是它现在帮我保存的记忆库中的内容,我不清楚是不是付费用户也无法编辑这里的记忆,但普通用户只能删除,无法编辑。它已经知道我喜欢物理,尤其是费曼这种风格。

当我开启一个新的窗口时,保存的记忆被带了过来,
记忆库基本上是 ChatGPT 的一个独立部分,有点像关于你的知识数据库。而这个知识库总是被附加在所有对话之前,这样模型就能随时访问它。我其实非常喜欢这个功能,因为时不时地,记忆会更新你与 ChatGPT 的对话内容。如果你只是顺其自然地使用 ChatGPT,随着时间的推移,它确实能在某种程度上逐渐了解你,提供的内容也越来越符合你的需求。这一切都是通过自然的互动和记忆功能逐渐实现的。有时它会主动触发记忆,有时则需要你主动要求它记忆。
十六、总结
一图盖千言
