cs224w课程学习笔记-第12课
cs224w课程学习笔记-第12课 知识图谱问答
- 前言
- 一、问答类型分类
- 二、路径查询(Path queries)
- 2.1 直观查询方法
- 2.2 TransE 扩展
- 2.3 TransE 能力分析
- 三、连词查询(conjunctive queries)
- 3.1 Query2box 原理
- 1)、投影
- 2)、交集查询(AND 操作)
- 3)、联合查询(OR 操作)
- 4)、and_or操作
- 3.2 Query2box 训练
- 1)、正负样本采样
- 2)、查询过程可视化
- 四、总结
前言
前面一节课讲了知识图谱的嵌入,其常用的加法,乘法模型及其各自的嵌入原理,表征能力与嵌入输出情况.本节课将就最经典的知识图谱的问答任务,阐述如何将问答任务进行任务分析,转化为可以使用知识图谱嵌入模型的嵌入进行任务训练,最终完成该类问答任务.
一、问答类型分类
以下图中的药理知识图谱为例,边有四种,分别是造成causes,相关Assoc,治疗Treat,相互Interact关系,节点有药物,疾病,副作用与蛋白质,右侧是几种类型的问题
- 直接已知一个节点,通过一种关系边,到达目标节点可得到问题的答案(one-hop): Fulvestrant会造成什么副作用(开始节点为Fulvestrant,边为causes,目标节点副作用)
- 路径问答:已知一个节点,通过多种节点关系边,到达目标节点可得到问题的答案: Fulvestrant会造成副作用相关的蛋白质(开始节点为Fulvestrant,边为causes,Assoc,中途节点为副作用,目标节点蛋白质)
- 连词查询:已知多个节点,经过多种节点关系边,得到交互的目标节点,得到问题的答案:造成头疼与治疗乳腺癌的药物是什么(开始节点为(Headache,边为causes),(Breast Cancer ,边Treat)
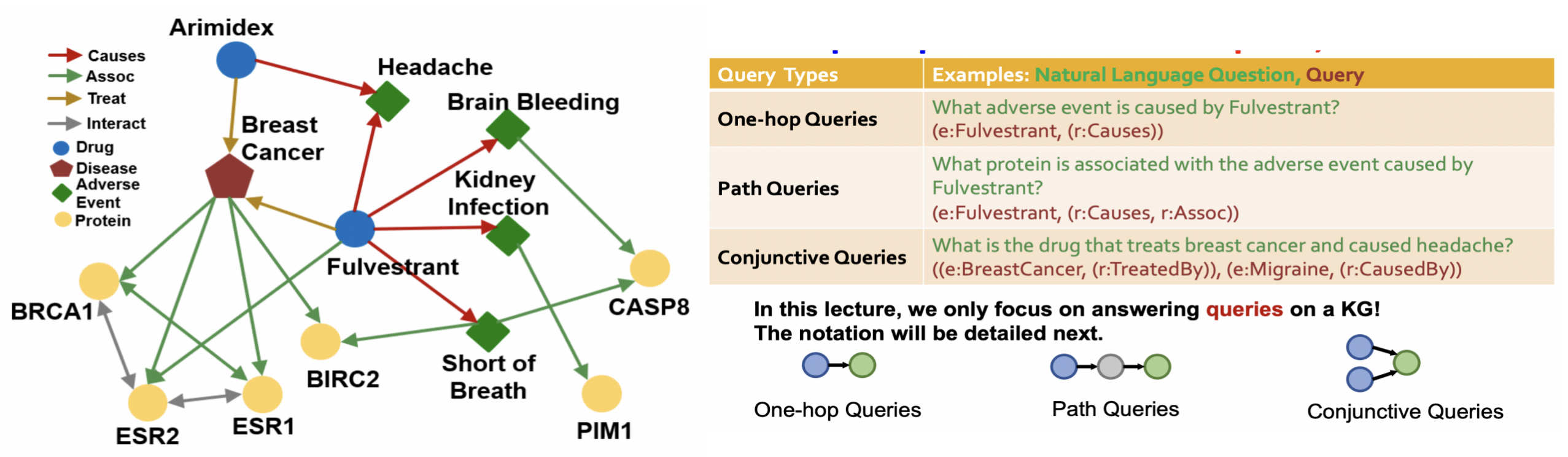
从节点与边的结构图上可以看到其第二种与第三种的差异在于交互上,第一种与第二种的差异在于中间是否需要通过多次路径.因此第一种可以看作是第二种的特例.在接下来我们将区别第二种问答与第三种问答进行其任务求解的说明.
二、路径查询(Path queries)
2.1 直观查询方法
紧接前面的第二个问题,其涉及两种类型边,因此我们有知识图后,从起始节点出发遍历所有第一个类型Causes的边,到达其连接的节点后,再以连接的节点遍历第二类型Assos的边,到达其连接的节点即为答案(图中绿色节点).可以发现的每一类边所到的节点是一个节点集,而不是单个节点,结果也可能是一个节点集.那么在实际场景中,知识图谱往往是不完整的,若此时有一个结果里的节点是缺失的,按当前搜索图的方法就会发现结果集没有拿到全部答案.
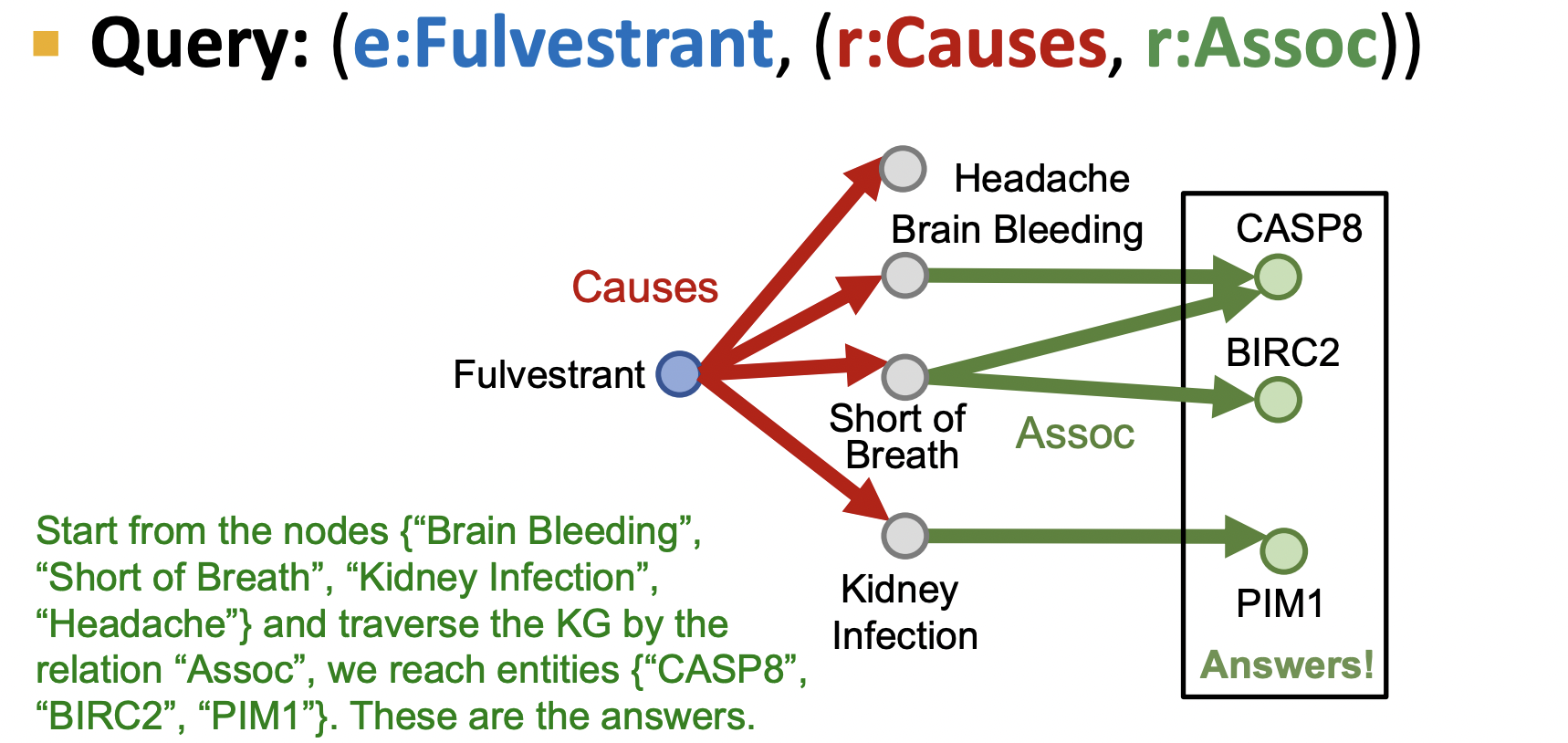
2.2 TransE 扩展
前面我们看到知识图谱往往是缺失的,那么是否可以先补足知识图谱再做查询?
如果先做补足,知识图谱通常非常大,这会导致后续查询时间指数上升.因此我们希望在回答任意问题时,能够隐式推理缺失的答案.
还记得TransE嵌入模型的原理吗?空间向量平移,得分函数为起始节点向量加关系向量减去结束节点向量,其原理是起始节点向量与结束节点存在连接,其起始节点向量加关系向量就越靠近结束节点;对照问答场景,这起始节点向量加关系向量不就是问题的嵌入吗?如果它们之间是存在连接的,那么两者就越接近,那说明这个结束节点就是答案.
因此我们的核心问题就是将TransE 扩展为问题嵌入, 得分函数 f r = − ∣ ∣ h + r − t ∣ ∣ , h + r = > ( v a + r 1 + . . . + r n ) 得分函数f_r=-||h+r-t||,h+r=>(v_a+r_1+...+r_n) 得分函数fr=−∣∣h+r−t∣∣,h+r=>(va+r1+...+rn),其中 v a v_a va是节点嵌入,r是关系嵌入,其计算原理使其独立于中间过程的那些节点集,同时TransE模型本身对传递关系的表征能力也保证了这样操作后不会丢失信息.

使用TransE 的路径查询步骤如下所示:
1、训练TransE 模型,该步骤与前面提到的知识图谱嵌入模型学习一致,输入三元组(h,r,t),学习实体和关系的向量表示,使得对于每个正确三元组,h+r≈t,同时最小化错误三元组的得分。
2. 预测阶段(路径查询):输入是 v a v_a va头部节点,关系路径[r1,r2,r3,…,rn]
- 向量映射:从训练好的嵌入矩阵中获取头实体和关系向量
- 路径向量合成:将路径中的关系向量累加
- 目标位置计算:将头实体向量与路径向量相加,得到预测的目标位置 t ′ t' t′
- 相似度匹配:计算 t ′ t' t′与所有实体向量的距离(如L2距离或余弦相似度),排序后得到最可能的尾实体。
- 输出按相似度排序的尾实体列表(如Top-K个候选实体)
该方法的实现细节中,多跳路径的隐式推理未显式考虑中间实体约束,可能影响复杂推理的准确性。二是关系向量直接相加可能导致误差累积(尤其是长路径).当然这个模型的潜在限制不是本课核心关注点,感兴趣的小伙伴可以自行搜索相关优化模型.
2.3 TransE 能力分析
我们看到TransE可以解决路径查询问题,那么它可以同时解决连词查询问题吗?
先来看看连词查询,直接遍历知识图谱是如何遍历的,如下图所示,遍历两条路径,其分别以ESR2,Short of Breath 为起始节点,两条路径的结尾交互点为答案.
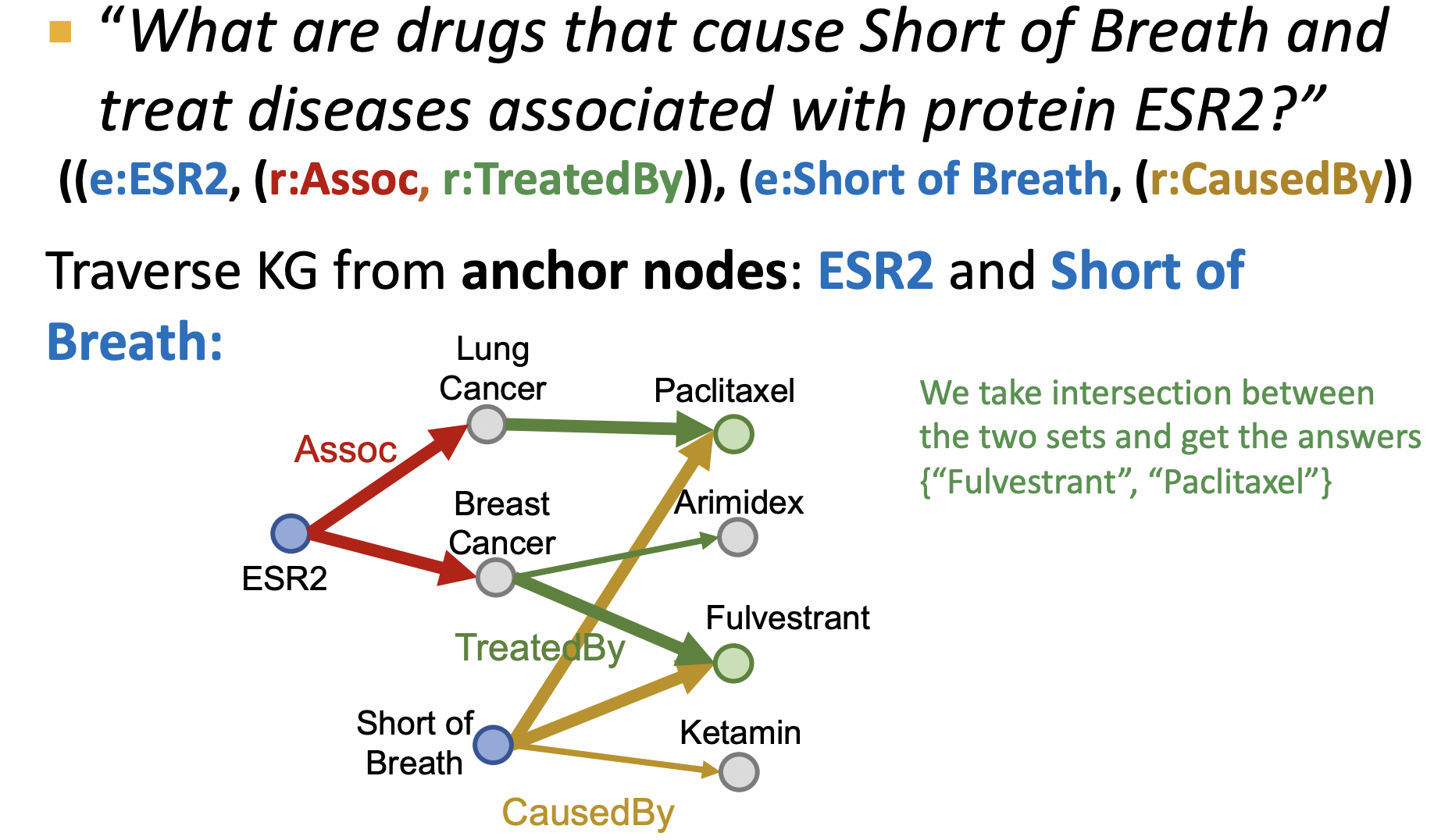
这个遍历在TransE,则为先得到两条路径的嵌入p1,p2, p 1 ≈ t 1 p1\approx t1 p1≈t1, p 2 ≈ t 2 p2\approx t2 p2≈t2,t1=t2时为答案,但因为是线性的,不同关系对应的平移方向可能冲突(例如 r1 和 r2 方向不一致),导致无法找到同时满足条件的解;同时两条路径,会导致累积误差更加严重,从而更难找到合理的答案,因此TransE无法有效的解决连词查询问题.
三、连词查询(conjunctive queries)
该类型查询需要一个更复杂的方法去实现,其(Query2box)箱型查询模型是代表,接下对该模型原理,训练,特点,表征能力,以及连词查询的扩展进行阐述.
3.1 Query2box 原理
回顾TransE模型是向量平移原理,节点,关系都嵌入到一个向量空间,其嵌入范围是点状的,且平移相加,会忽略多次平移中间的节点集的限制.最关键的是无法很好表现与的逻辑操作.这个数学直观会想到集合之间的交集操作,换到集合空间里很容易想象出是多个箱子叠加的部分就是交集.
因此Query2box 原理是将节点嵌入为一个箱子,关系作为偏移方向,可以将原箱子映射得到一个通过该关系把箱子投影,生成了新箱子;其支持的逻辑操作如下:
-
联合查询(OR 操作):通过取两个盒子的并集实现。
两个盒子的并集在空间中被表示为包含范围更大的一个盒子。
并集操作调整 c 和 r 的取值。 -
交集查询(AND 操作):通过取两个盒子的交集实现。
交集操作调整盒子的范围使得最终盒子嵌入更加紧致,表示符合两个查询的共同答案。 -
关系追踪(投影操作):从当前盒子沿着特定关系跳转到下一个范围。 通过关系嵌入来修改盒子的中心和范围。
如下图所示,节点ESR2通过关系Assoc投影到一个红色的新箱子,同样的原理重复该过程直到最后一个关系投影,取两条路径最后的投影箱子进行与逻辑操作得到最后的箱子为当前连词查询的答案.
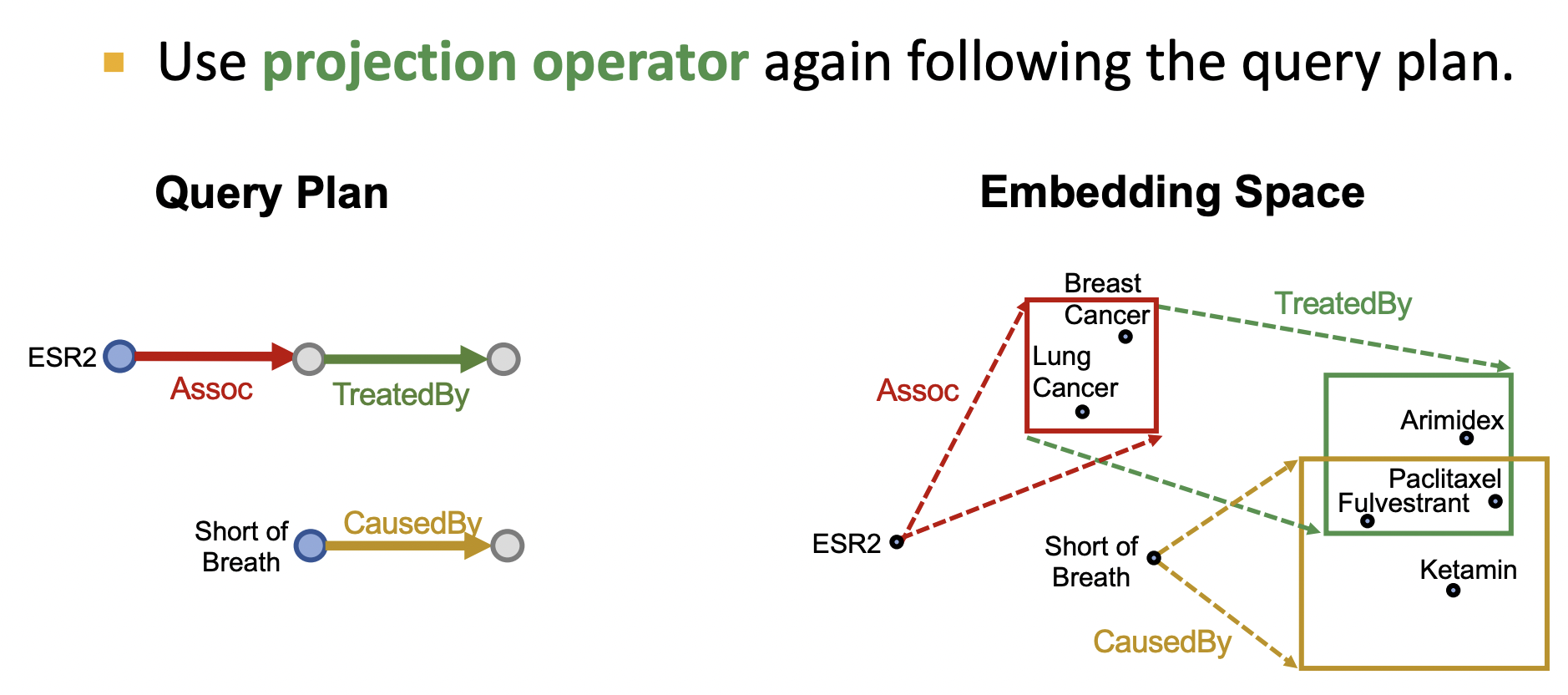
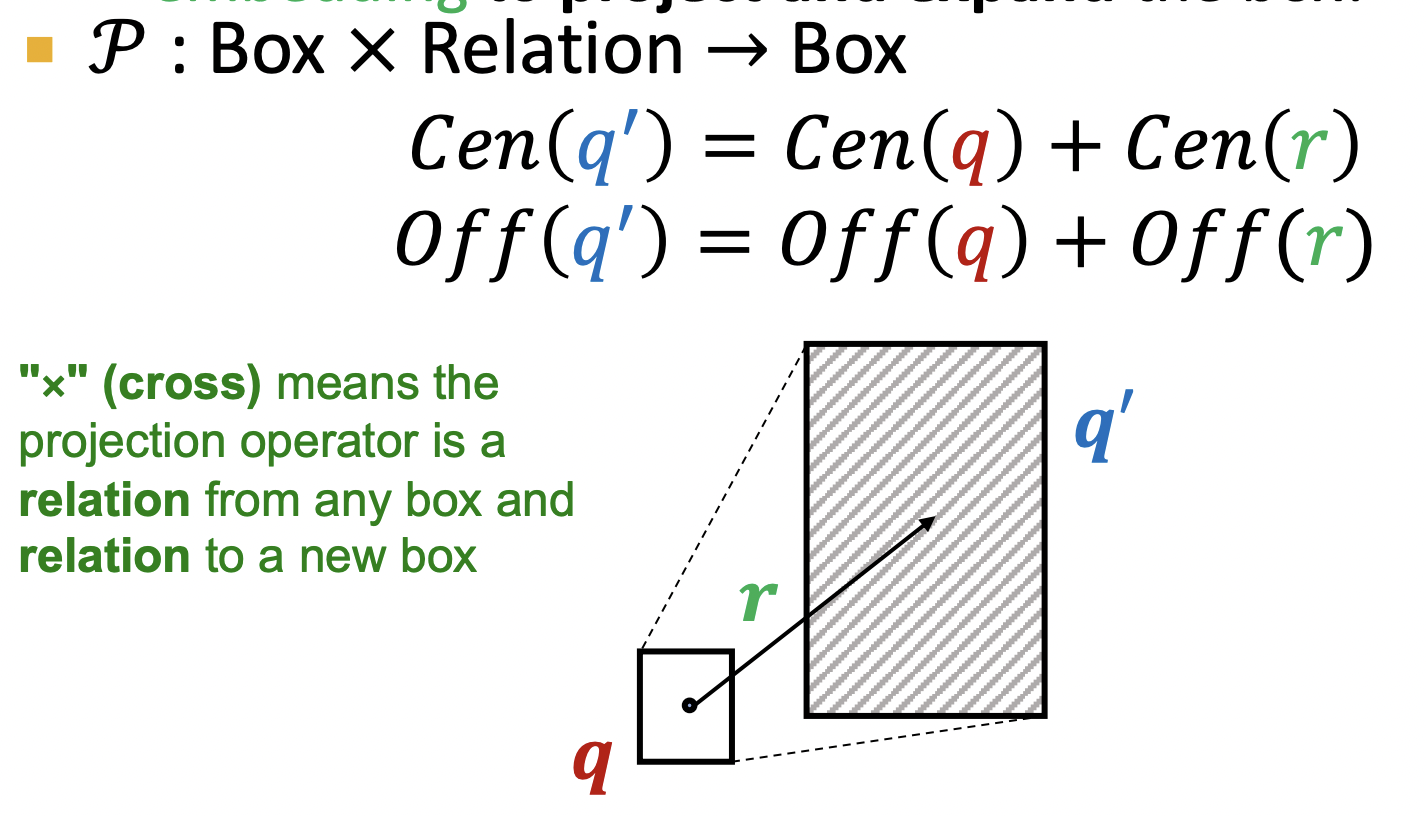
1)、投影
首先一个箱子嵌入定义为中心点的与偏移量,如一个箱子q由中心点cen(q)=(4,3),偏移量off(q)=(1,2);关系r指明投影方向与偏移量,得到一个新箱 q ′ q' q′,其投影操作如下图所示.
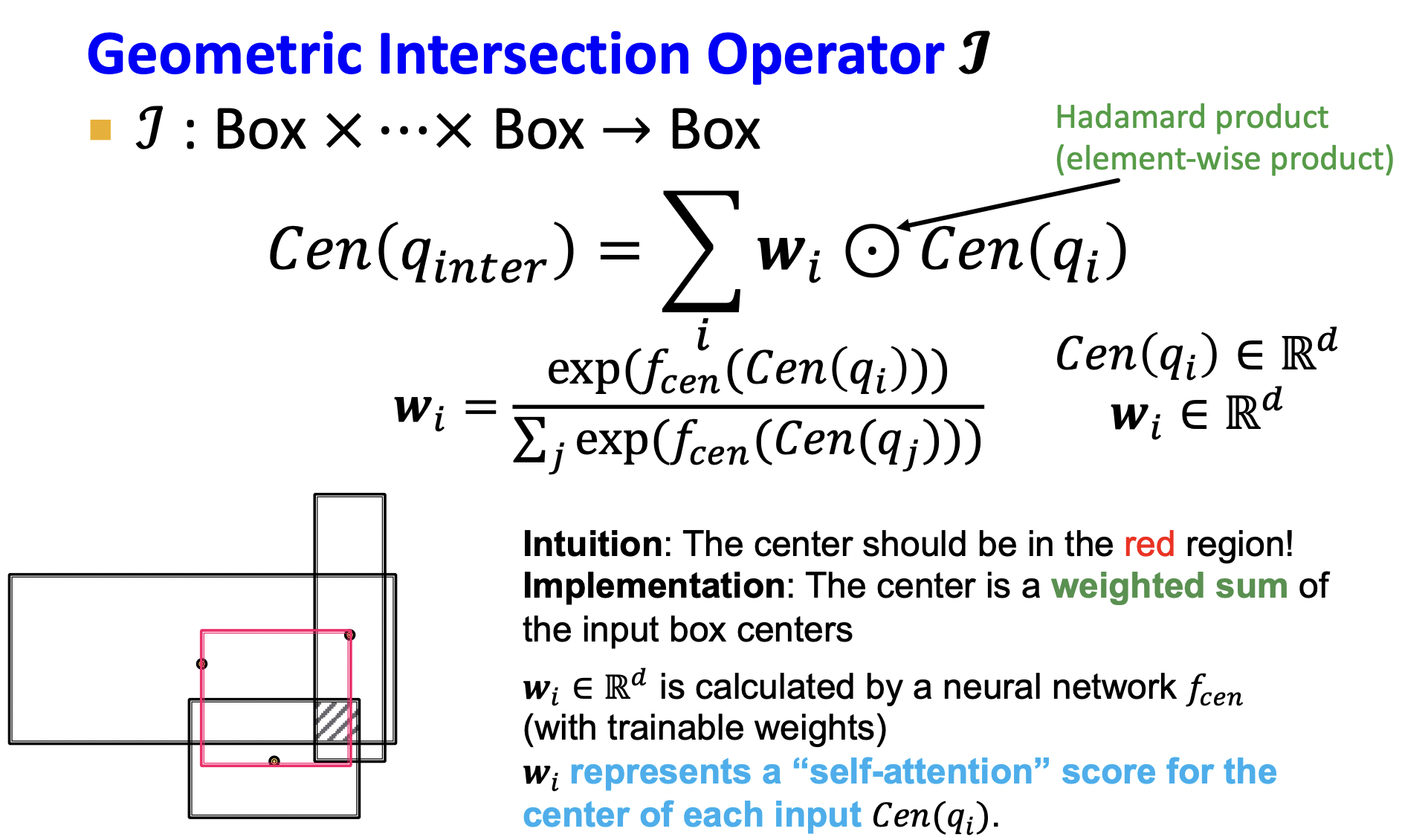
2)、交集查询(AND 操作)
交集是求多个箱子交集的部分,我们知道箱子由中心点,偏移量表示,因此就是求取交集后的新箱子的中心点与偏移量.
- 首先看中心点,直观上感觉交集的中心点应该在多个中心点围成的范围内,因此可以表示为每个箱子中心点的线性和,其中每个箱子的权重不一样,该权重由模型学习得到.
- 偏移量直观为交集的箱子最小偏移量,为了更精准,乘以一个收缩量,该收缩量由模型学习得到.

3)、联合查询(OR 操作)
在联合查询前,我们先要定义箱子之间的距离计算,其距离可通过欧几里得计算,也可以使用其它方法.

有了箱子的距离后,假设我们的答案是V ,问题有m个,其问题间进行OR操作,则其先对每个一问题求其嵌入,然后进行聚合,其聚合方式如下,其理解为,答案只要是其中一个问题的答案,就应该是联合问题的答案,因此取所以箱子距离之间的最小值.

4)、and_or操作
当一个查询里既有and,也有or时,最佳实现是将查询先拆解为多条and查询,在最后一步再or查询.其原因是不拆解无法在当前维度空间得到嵌入,需要嵌入到更高维度(如下图所示),为在当前维度实现,就要进行先拆解,然后嵌入,最后or.

3.2 Query2box 训练
整体的训练过程与TransE 类似,比较特别的在于这是查询场景的嵌入,因此正负样本采集时会有所差异.接下我们先看训练步骤:
- 1、从知识图谱中采样得到问题集q,答案集 v v v与非答案集 v ′ v' v′
- 2、计算q的嵌入
- 3、计算打分函数 f q ( v ) f_q(v) fq(v)
- 4、优化loss,正确的越大越好,错误的越小越好
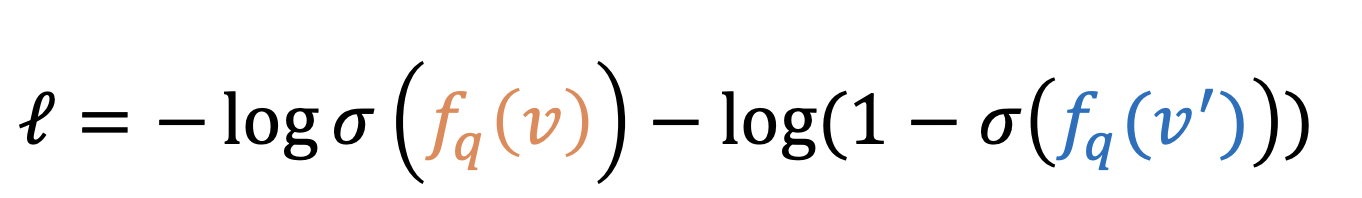
1)、正负样本采样
从开章我们就知道问题分为三种类型,因此采样时候,各类型均要包含在内,
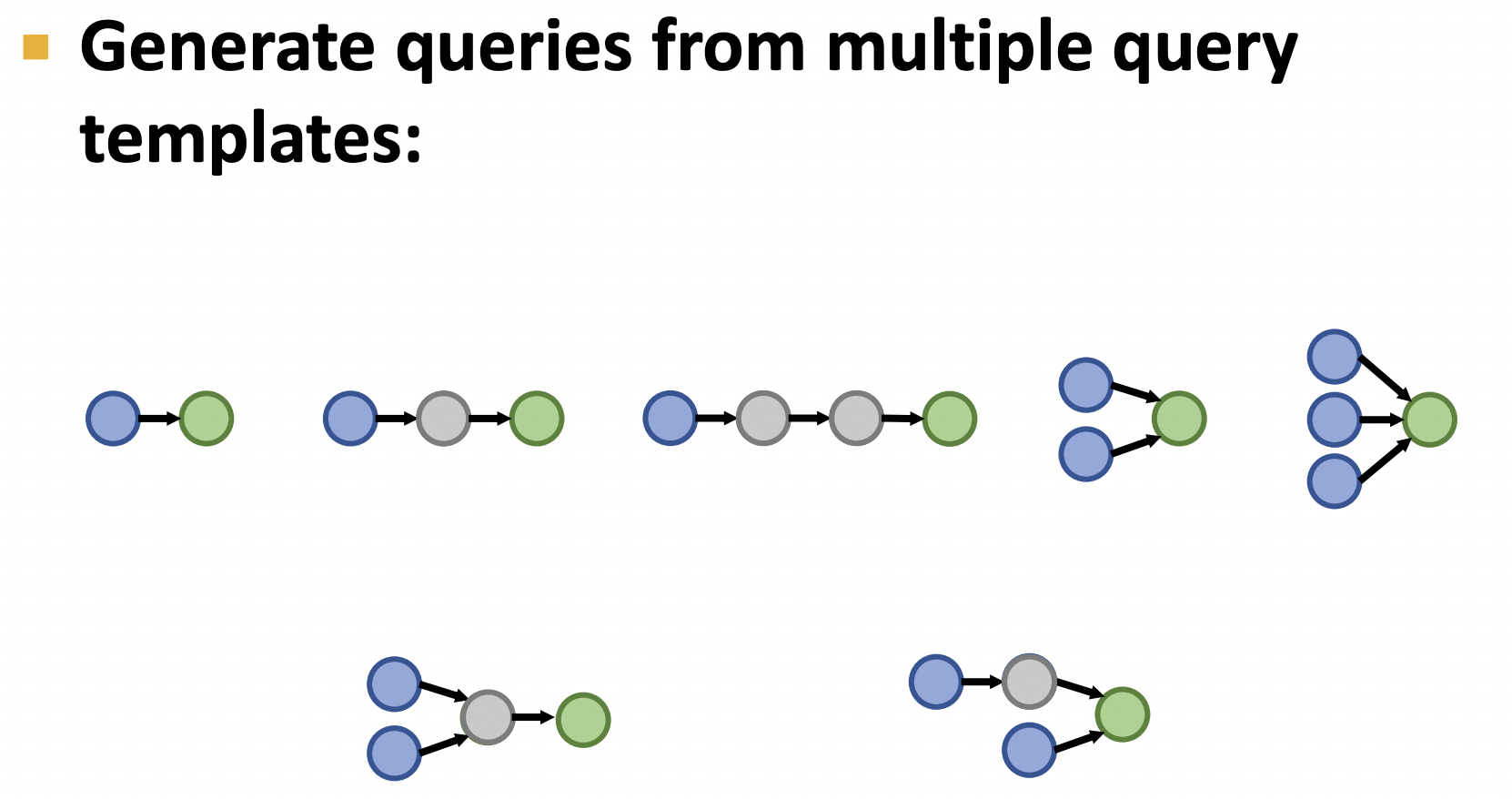
以其中一个问题类型为例,其绿色节点为答案.
- 我们从答案节点开始(随机选择一个),沿着图中的边遍历,直到所有起始节点均获得;
- 有了起始节点后再沿着图遍历得到满足条件的所有答案;
- 得到了问题集,答案集与非答案集.
接下来以下图问题类型为例,我们随机采样到Fulverstrant 为答案节点,随机选取与其相连的边如TreatedBy获得与该边相连的节点Breast Cancer,同样选取与其相连的边如Assoc得到起始点ESR2;重复随机选取边的过程,将得到问题节点集与关系集,再通过问题节点集与关系集(构成多个Query template 样本)得到Fulverstrant再内的其它答案节点,得到答案集,不在问题集与答案集里的节点则为非答案节点,采样得到非答案集,
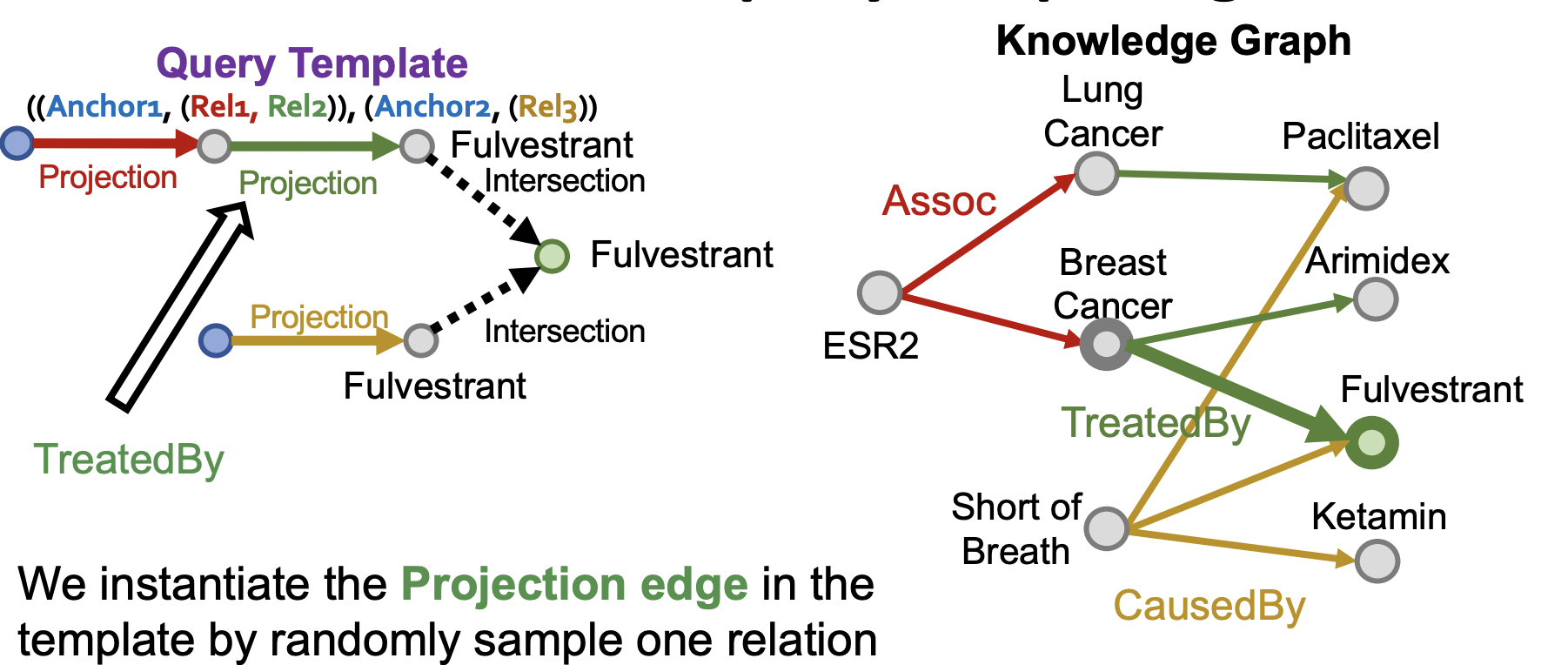
2)、查询过程可视化
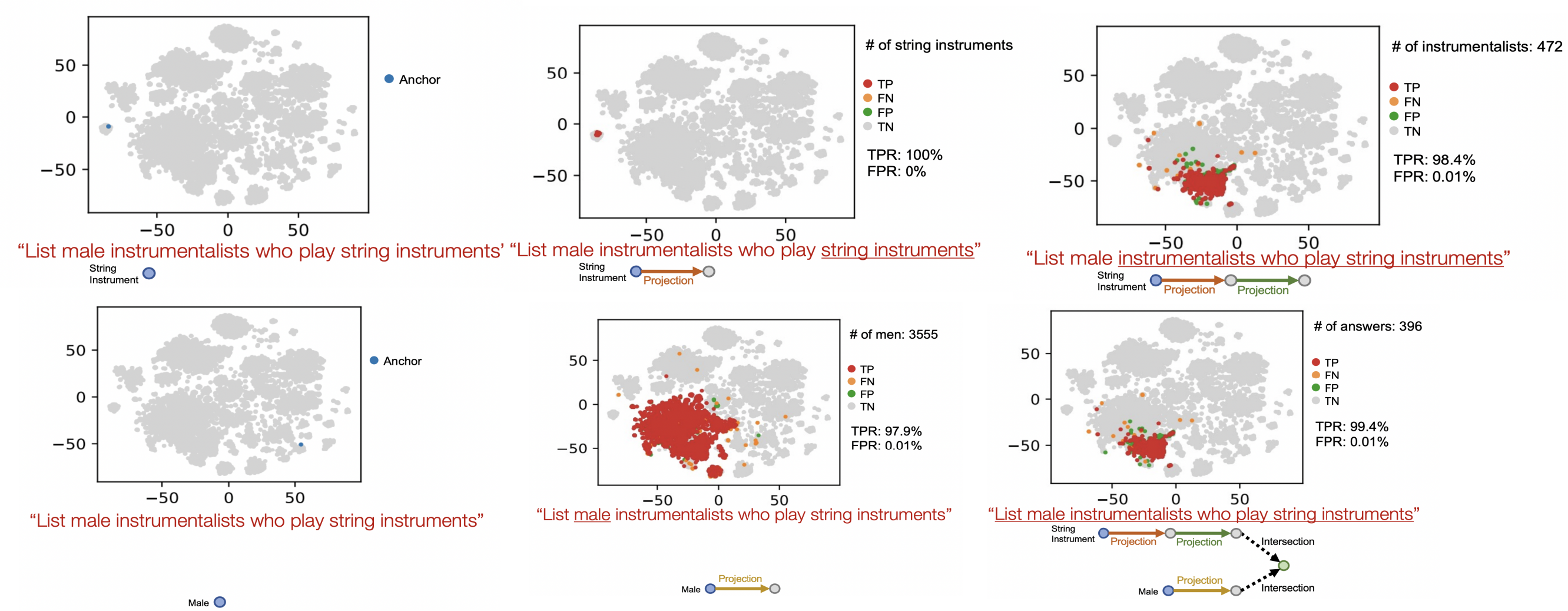
以问题:“List male instrumentalists who play string instruments”为例,将其嵌入到2维空间,这样可以观测其嵌入过程的变化,其问题分解路径如下
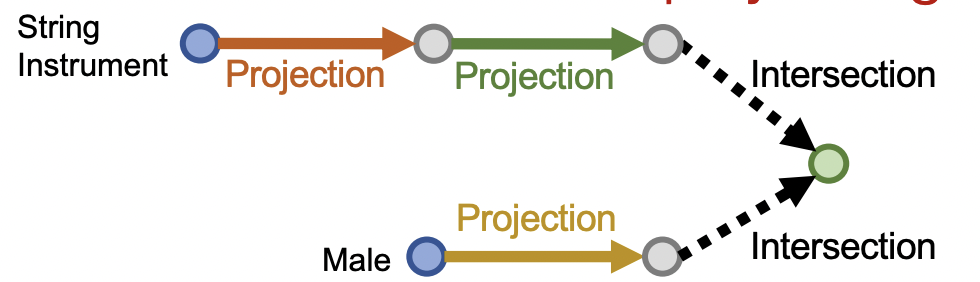
其查询过程如下图所示
四、总结
本课主要讲知识图谱下的查询应用如何实现,首先对查询进行分析,通过其不同类型,与知识图谱嵌入模型特点联系起来,其中路径类查询使用前面的TransE 即可解决,因为其传递的表达能力;而有交集,OR类的查询,则需要更复杂的嵌入模型,文中介绍了queryBox的嵌入算法,该嵌入算法为箱子的思想,类比集合操作,从而实现该类查询的学习;深入介绍了queryBox的嵌入算法的原理,训练过程,最后对查询可视化进行了一个例子的说明,加深对嵌入模型在查询应用上的理解.