PG技术分享
文章目录
- 下载安装与基本维护
- 官方下载
- 第三方下载
- 安装方式
- 初始化
- 启停维护
- PG 体系架构
- 逻辑架构
- 物理架构
- PG 内存架构
- PG SQL 原理
- SQL 查询语句的顺序
- 表 join 方式
- PG 中表连接方式
- SQL 解析过程
- SQL 优化
- 服务器参数优化
- 写缓存优化
- PG 常见维护性参数
- 内存相关
- vacuum 相关参数
- bgwriter相关参数
- 连接相关
- io相关参数
- 关闭透明大页
- 打开标准大页(大内存服务器)
- 性能测试工具
- 性能测试
- 配置相关
- 执行计划
- pg_state_statemnts
- pg_profile 快照收集
- CPU 相关
- 实时
- 历史
- 内存相关
- 数据存储与安全
- 数据导入导出
- pg_dump
- pg_dumpall
- pg_bulkload
- copy;\copy
- psql
- pg_restore
- 数据备份恢复
- 全量备份 + 归档
- 增量备份
- pg_repack 清理表膨胀
- wal_miner 数据恢复
- HA 以及负载均衡
- 逻辑复制
- PG 三权分立
- 监控与维护
- 维护优化
- analyze 优化
- **方法 1:调整 autovacuum 相关参数**
- **方法 2:仅对活跃表进行 `ANALYZE`**
- **方法 3:分时段 `ANALYZE`**
- 插件扩展
- 常见插件
- 插件库
- 学习路线图
下载安装与基本维护
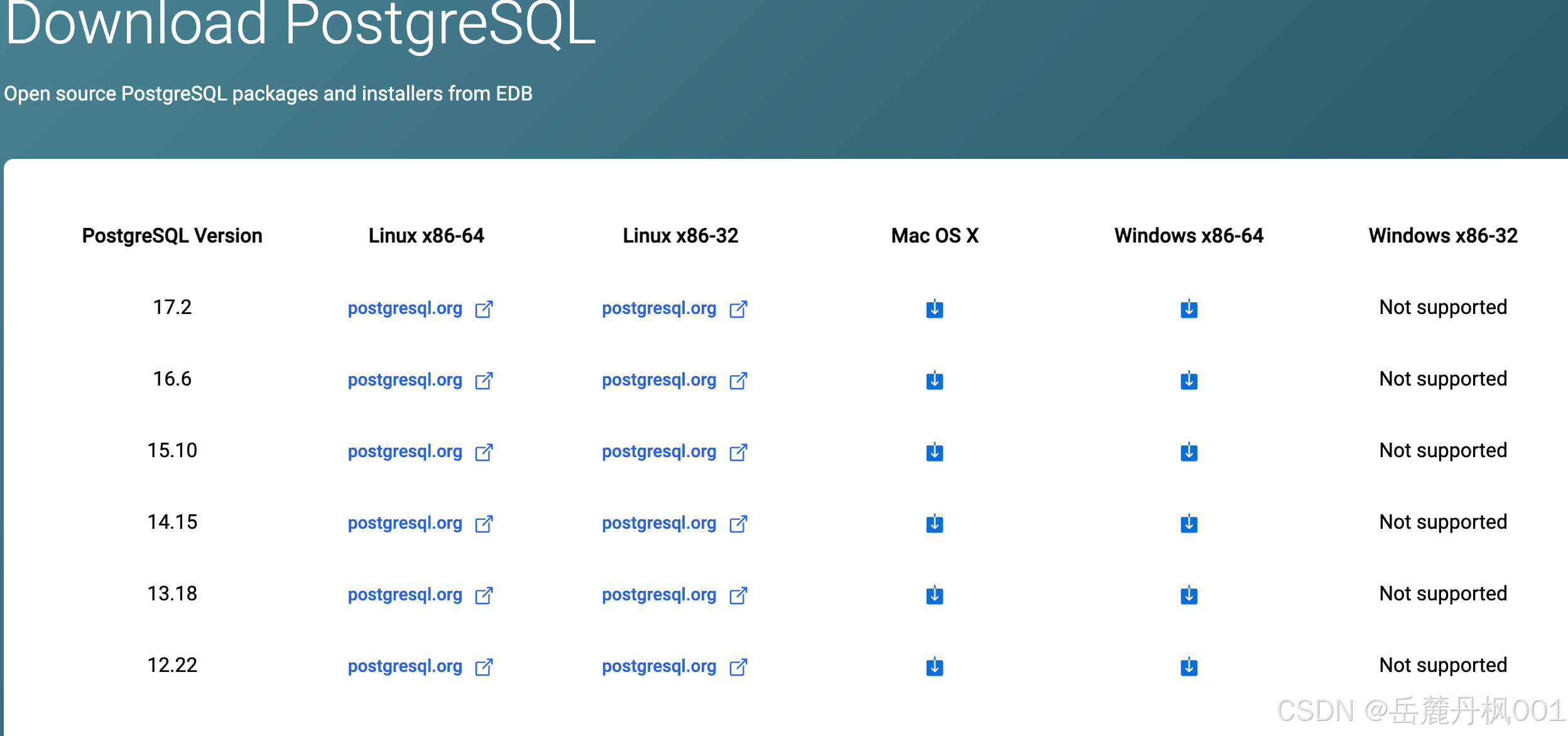
官方下载
https://www.postgresql.org/ftp/source/
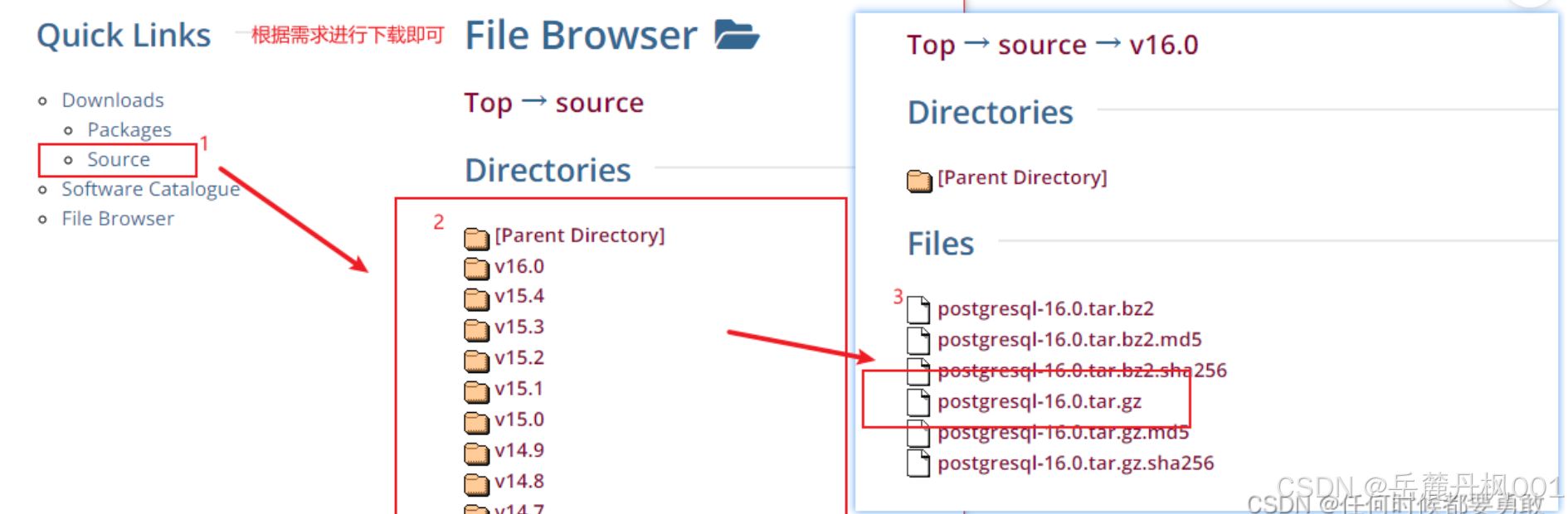
第三方下载
https://www.enterprisedb.com/downloads/postgres-postgresql-downloads
安装方式
- 源码编译安装
- yum 安装
- rpm 包安装
- 二进制包(绿色版)安装
- Windows 环境: 参考 https://www.icode504.com/posts/35.html
- Linux 环境:直接解压之后初始化就行
初始化
initdb -U postgres -E UTF8 --locale=C $PGDATA
启停维护
pg_ctl start -D $PGDATA
psql -c "checkpoint; checkpoint" && pg_ctl stop -m fast -D $PGDATA
psql -c "checkpoint; checkpoint" && pg_ctl restart -m fast -D $PGDATApostmaster -p 5555 -D $PGDATA &
pg_ctl start -D $PGDATA -o "-p 5555"
echo "port=5555" >> $PGDATA/postgresql.auto.conf && pg_ctl start -D $PGDATA
PG 体系架构
逻辑架构
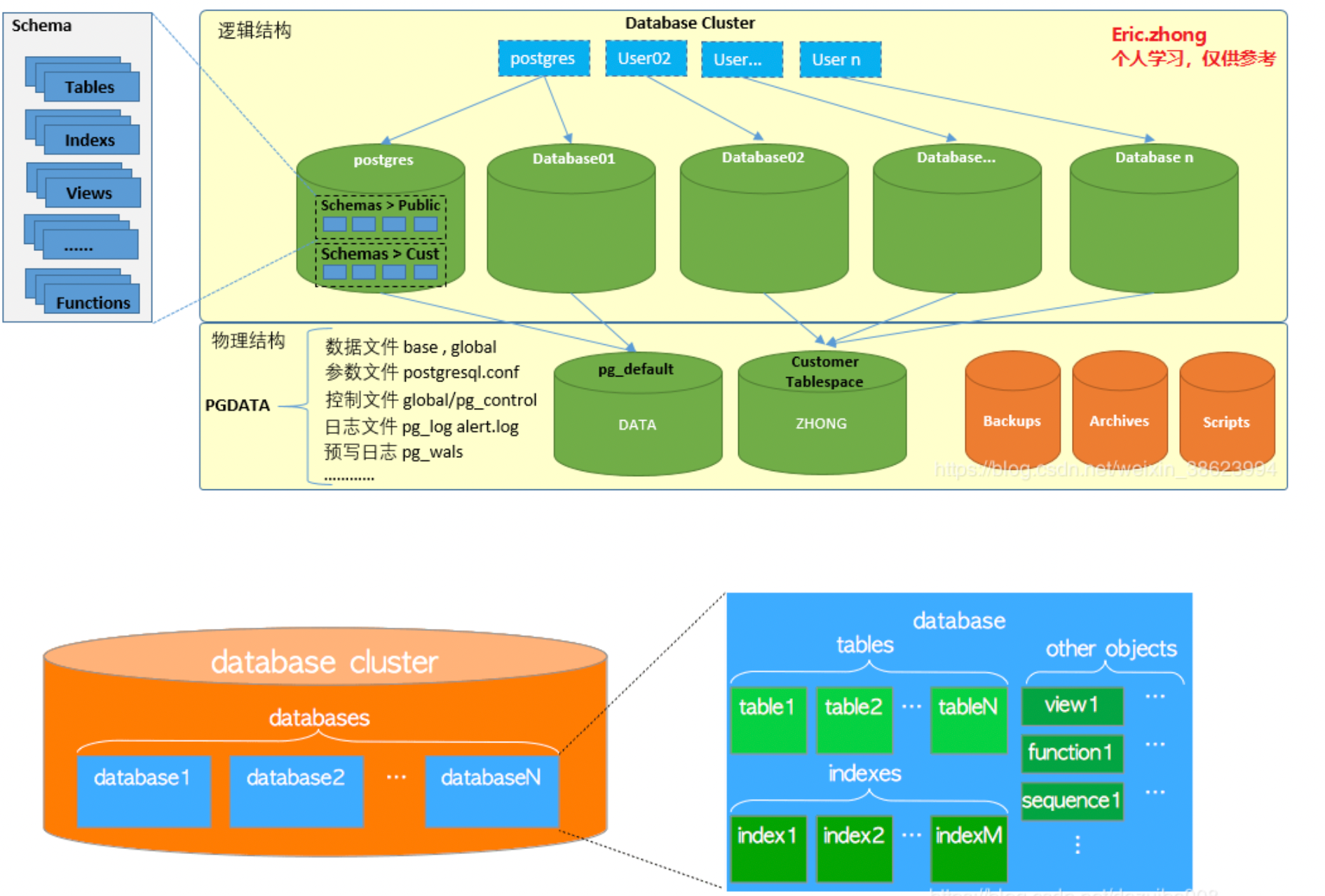
物理架构
参考: https://www.cnblogs.com/zclzc/p/17851678.html
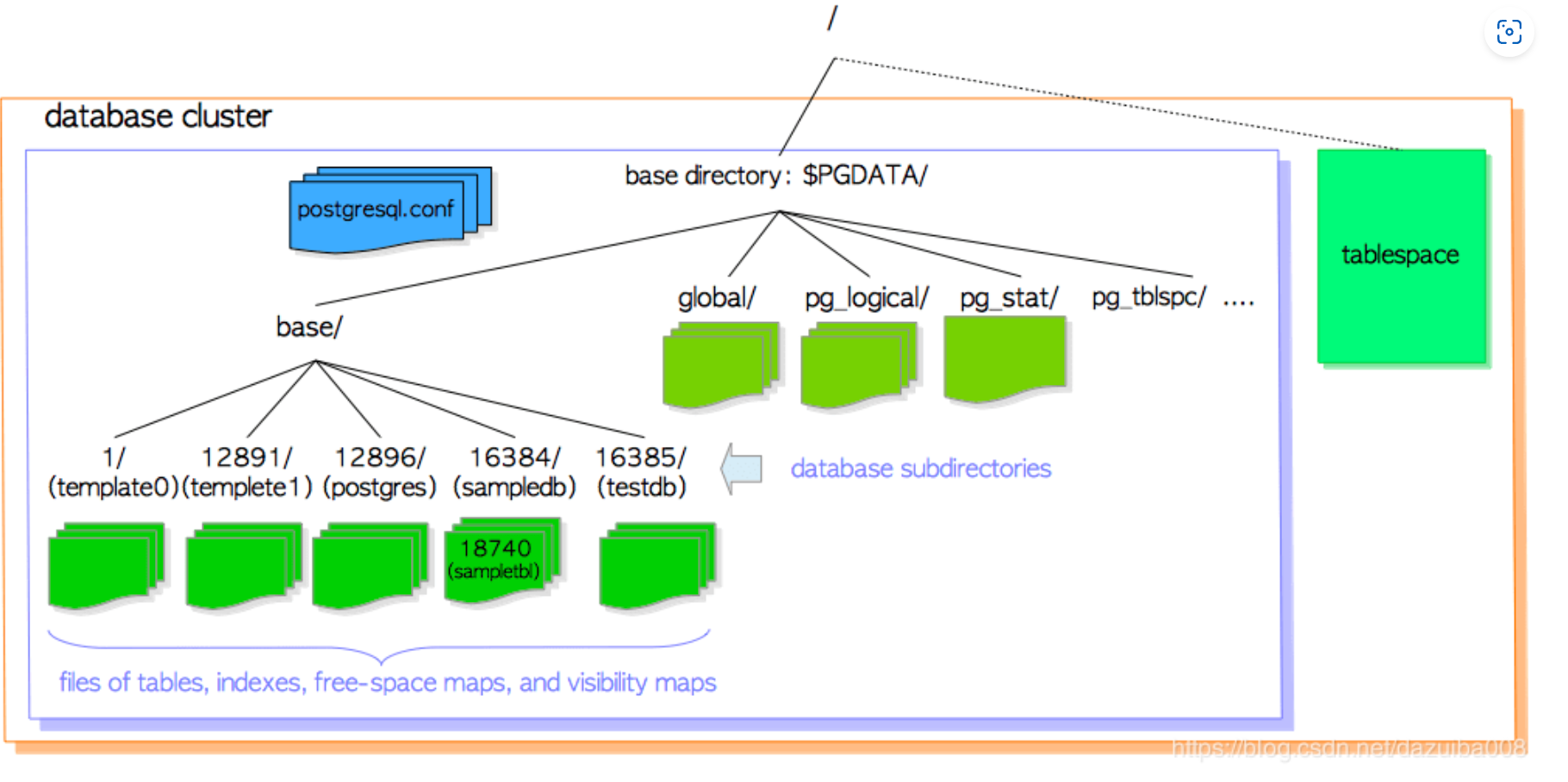
-bash-4.2$ tree -L 1 -d /data/pg12.5/pgdata/
/data/pg12.5/pgdata/ --数据目录
├── base --表和索引文件存放目录
├── global --影响全局的系统表存放目录
├── pg_commit_ts --事务提交时间戳数据存放目录
├── pg_dynshmem --被动态共享所使用的文件存放目录
├── pg_logical --用于逻辑复制的状态数据
├── pg_multixact --多事务状态的数据
├── pg_notify --LISTEN/NOTIFY状态的数据
├── pg_replslot --复制槽数据存放目录
├── pg_serial --已提交的可序列化信息存放目录
├── pg_snapshots --快照
├── pg_stat --统计信息
├── pg_stat_tmp --统计信息子系统临时文件
├── pg_subtrans --子事务状态数据
├── pg_tblspc --表空间
├── pg_twophase --预备事务状态文件
├── pg_wal --事务日志(预写日志)
└── pg_xact --日志提交状态的数据存放目录
PG 内存架构

PG SQL 原理
SQL 查询语句的顺序

表 join 方式

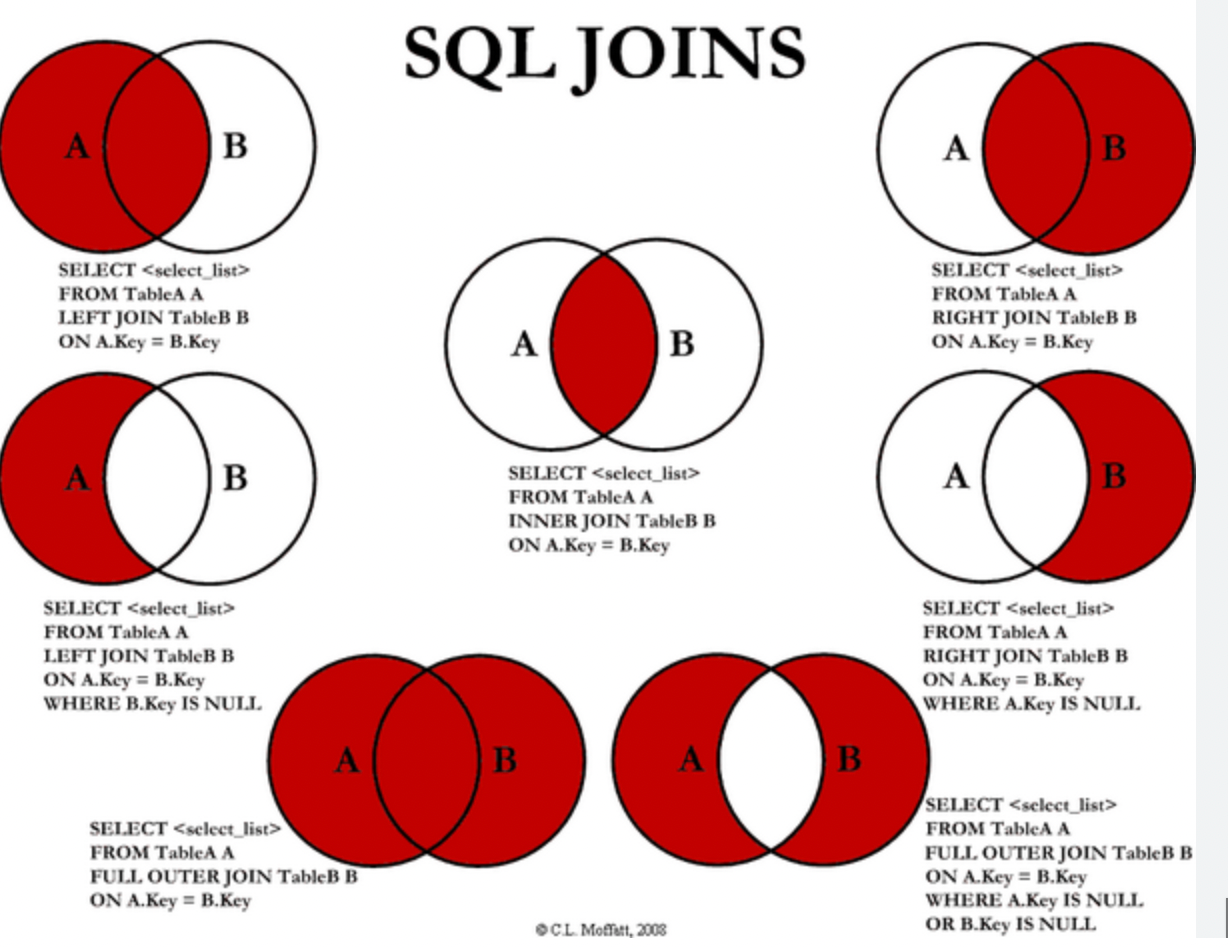
PG 中表连接方式
-
nest loop
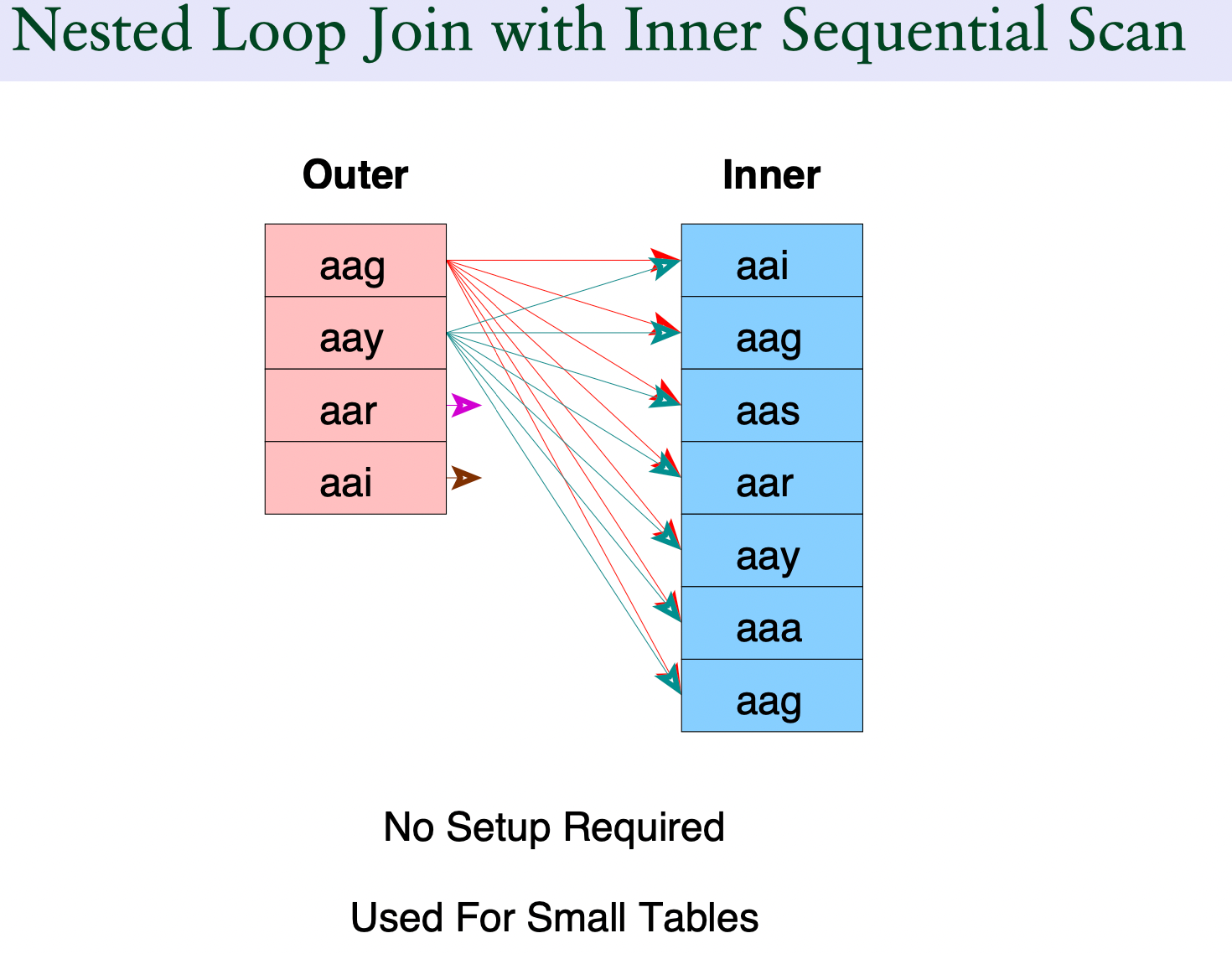
小表作为外表(驱动表) -
hash join
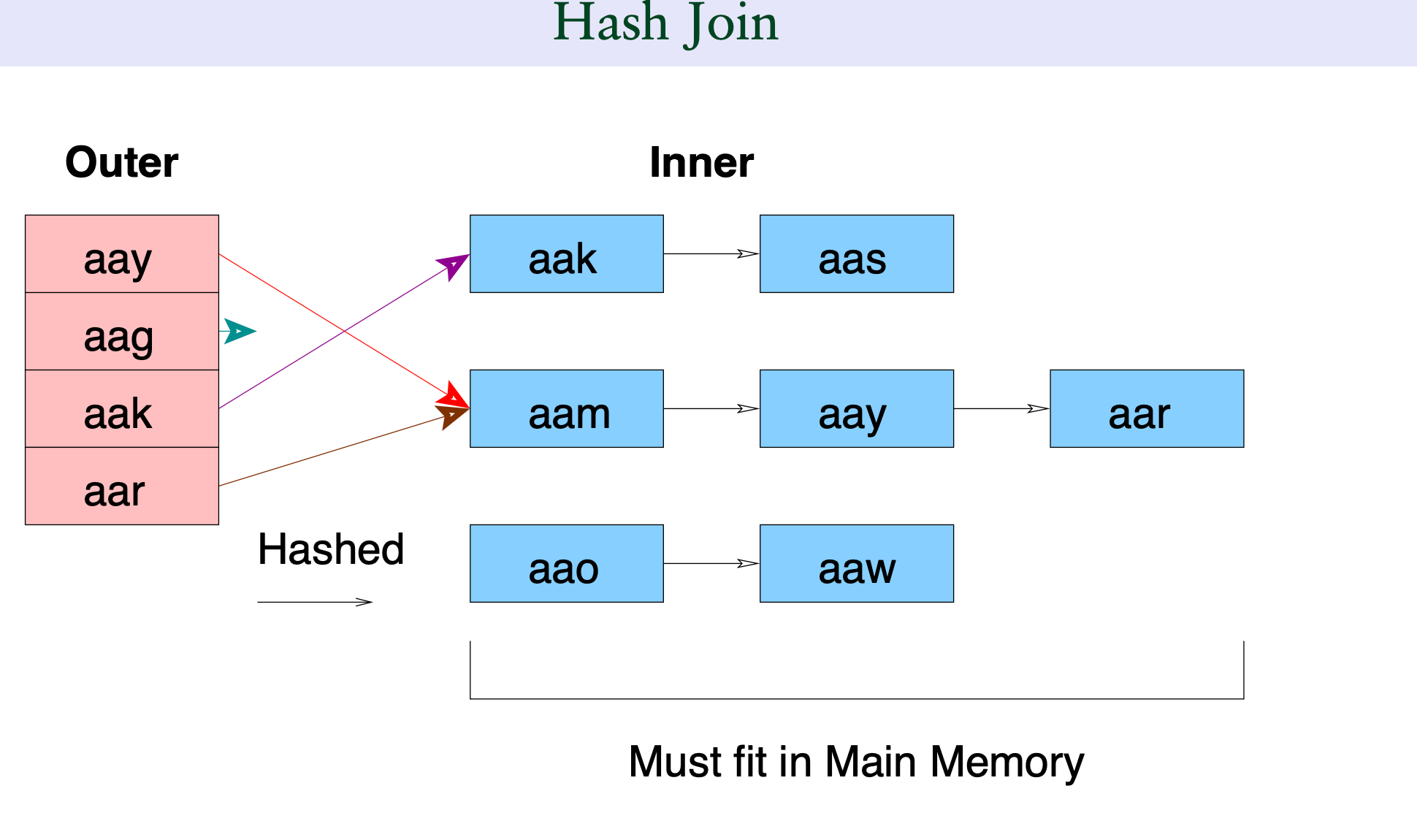 小表做hash
小表做hash -
merge join
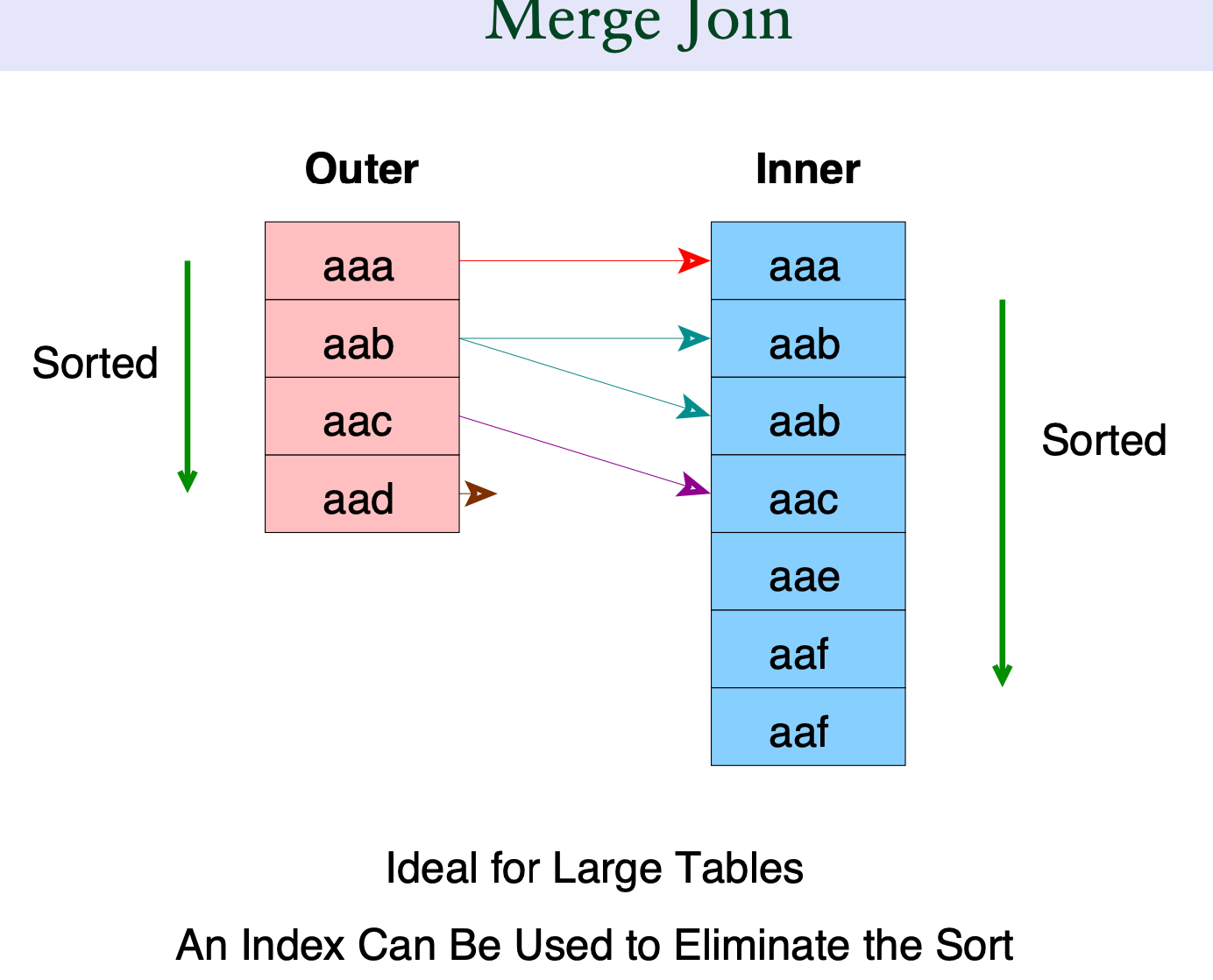
参考: https://cloud.tencent.com/developer/article/2332138
SQL 解析过程
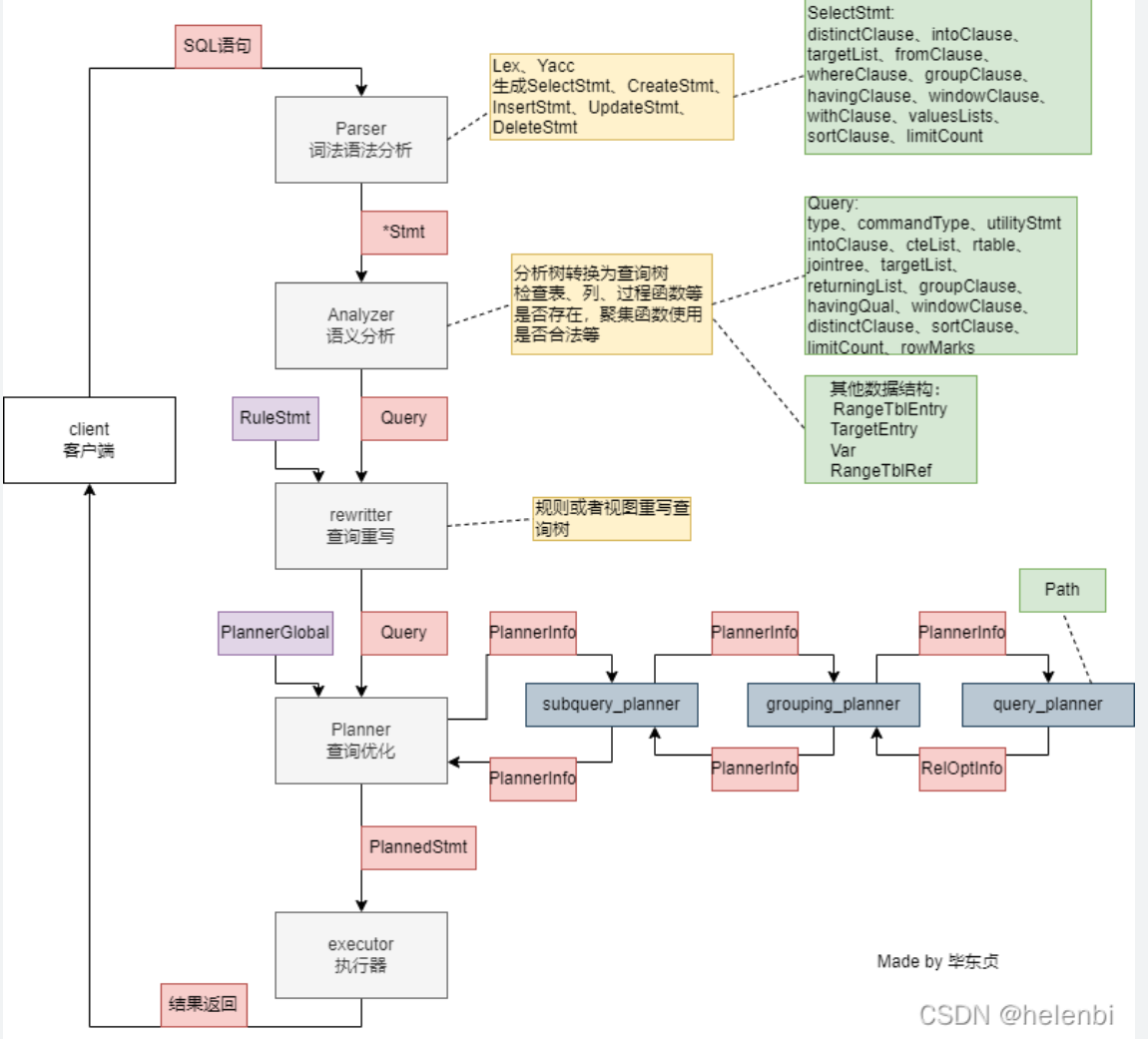
- 执行计划与成本估算
https://cloud.tencent.com/developer/article/2329034 - 多表连接方式及其成本估算
https://architect.pub/book/export/html/554
SQL 优化

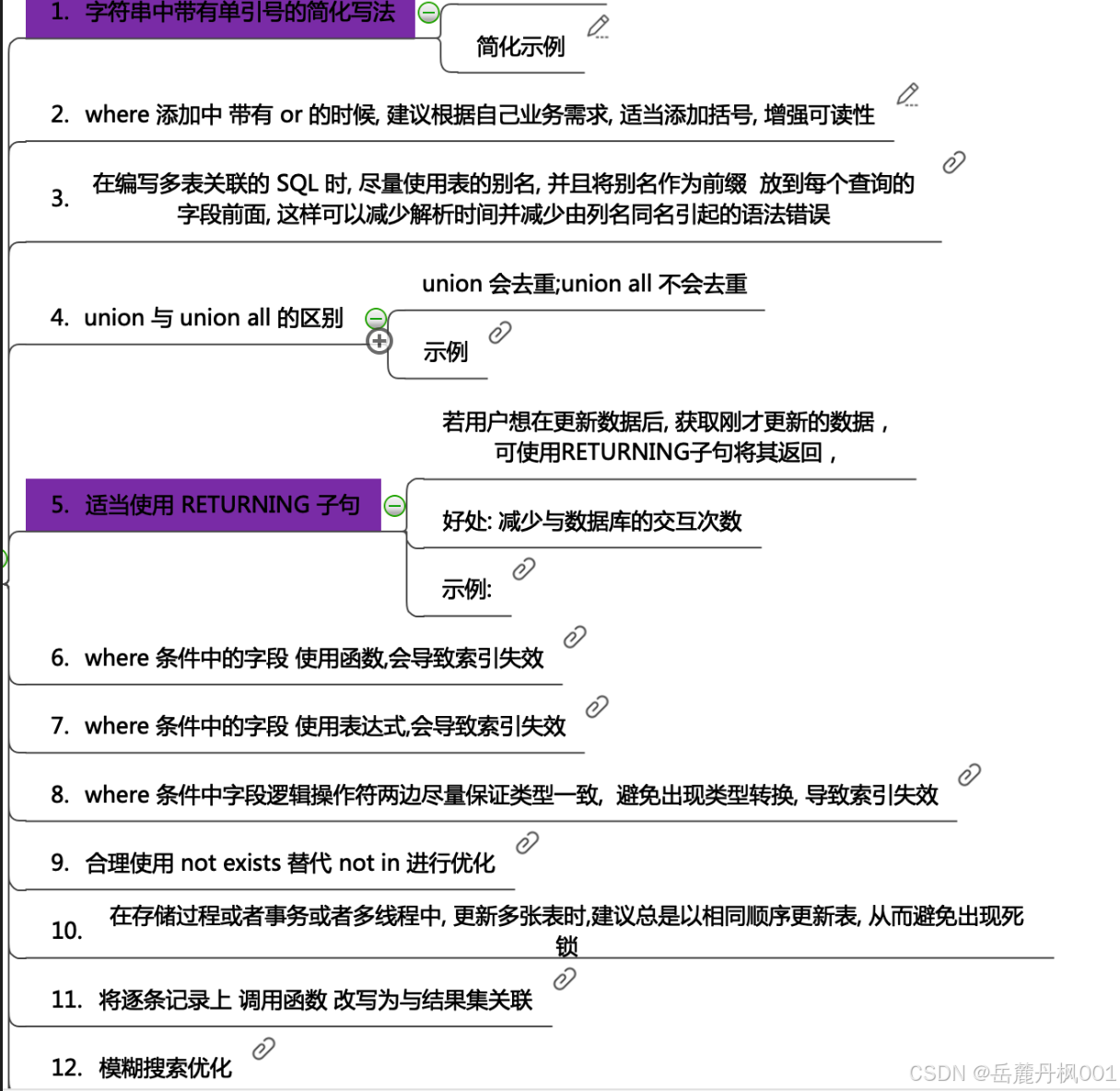
13. 在 plpgsql 函数中, 能用 SQL 实现就不用循环
14. 无日志表;CTE ; 窗口函数, include 索引;函数索引;表达式索引;index only scan;
分表,分区,ddl 注意事项
服务器参数优化
写缓存优化
- vm.dirty_background_ratio=1:是一个百分比,默认值是"10%", 当文件系统的缓存中保存的脏页数超过总内存的这个百分比时,开始后台刷脏数据;
默认值太大,当内存中有大量的脏数据时,会产生很大的性能抖动, 为了保证系统的稳定性,建议把该值设置成一个较小的值; - vm.dirty_ratio=2:与上一参数类似,只是前台刷脏页的百分比,默认值是"20%",也太大, 建议设置成 “2%”
案例参考: https://alidocs.dingtalk.com/i/nodes/mExel2BLV542m6nBT5L9rMkxWgk9rpMq
PG 常见维护性参数
内存相关
shared_buffers: 一般专用数据库服务器, 建议25%; 飞
work_mem: 最后基于会话调整
maintanance_work_mem: 可以适当调大, 需要考虑系统数据库连接数
vacuum 相关参数
适当调大 vacuum_cost_limit (默认是 200, 可以调整为 2000)
适当调小 vacuum_cost_delay (比如 2ms, 新版本默认就是 2ms,老版本值偏大,如果系统 IO 没问题, 可以设置为 0)
bgwriter相关参数
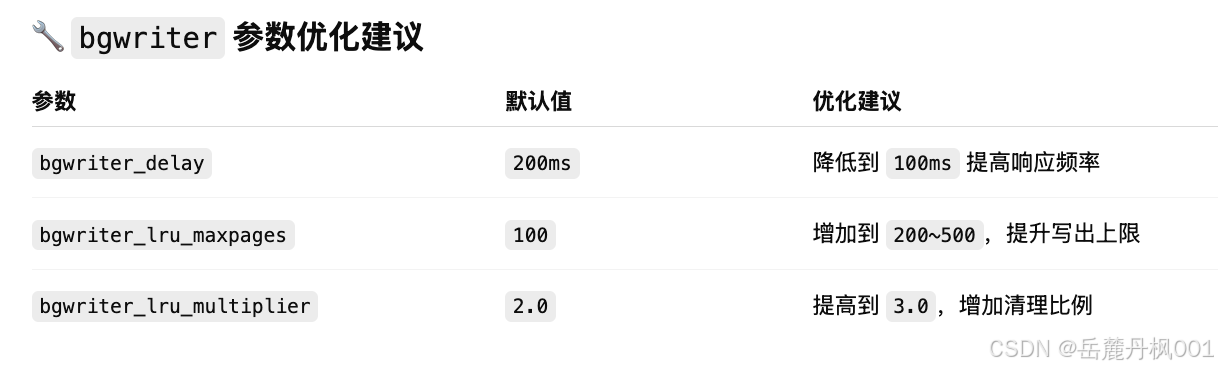
如 buffers_backend 高于 buffers_clean,说明 bgwriter 工作不足
连接相关
- SSL 支持: 源码编译 configure 时要打开相关选项
- socket 资源优化: keepalive_idle; keepalive_interval; keepalive_count; idle_in_transaction_session_timeout; client_check_interval
io相关参数
seq_page_cost and random_page_cost相关参数配置
HDD硬盘:
seq_page_cost=1.0
random_page_cost=4.0SSD硬盘:
seq_page_cost=1.0
random_page_cost=1.0
关闭透明大页
打开标准大页(大内存服务器)
性能测试工具
- sysbench
使用示例参考: https://alidocs.dingtalk.com/i/nodes/YMyQA2dXW7921KRBc2DXn2dNJzlwrZgb?doc_type=wiki_doc
性能测试
配置相关
- 慢 SQL: log_min_duration
- log_statement
- temp_file_limit; temp_file
- pg_database
执行计划
实时的: pg_show_plains(有 bug )
历史的: auto_explain
pg_state_statemnts
pg_profile 快照收集
用法参考:
https://www.modb.pro/db/1809796231233810432
https://blog.csdn.net/alwaysbefine/article/details/130790515
CPU 相关
实时
- top
- pidstat
- pg_top
- strace
- perf top
- perf record
- perf report
- CPU 火焰图
历史
- 整体:sar
- 细节:oswatcher
内存相关
- smem
- pmap -x $pid
- /proc/$pid/smaps
- gdb + dump 内存
- log_parser_stat; log_planner_stat; log_rewriter_stat …
- 内存页回收: sar --> kswapd
- 内存碎片: /proc/buddyinfo; drop cache
数据存储与安全
数据导入导出
pg_dump
* -Fp
* -Fc
* -Fd -j
pg_dumpall
* -g
pg_bulkload
copy;\copy
* to
* from
psql
-E
-c
-qAt
\gexec
...
pg_restore
-L
-l
toc 文件
数据备份恢复
全量备份 + 归档
- pg_basebackup
- archive_mode + archive_command
增量备份
- pg_rman
- pg_probackup
- pg_backrest
pg_repack 清理表膨胀
wal_miner 数据恢复
HA 以及负载均衡
- corosync+pacemaker(读写分离 负载均衡)
- repmgr + pgpool(读写分离 负载均衡)
- repmgr + pgbouncer + HAProxy (连接池; 读写分离, 负载均衡)
- patroni + citus+ HAProxy + pgbouncer
逻辑复制
- wal2json
- pglogical
PG 三权分立
- 目标
在 PostgreSQL 中,三权分立(Separation of Duties, SoD)是一种控制机制,旨在确保系统中有不同的角色分别负责不同的任务和权限,以减少错误、欺诈和滥用的风险。实现三权分立的目标是将数据库中的权限和职责分配给多个角色,避免一个用户或角色拥有过多的权限,造成安全隐患。 - 如何在 PostgreSQL 中实现三权分立
假设我们有以下三类用户和角色:- 管理员(
db_admin):负责管理数据库和用户,但不能直接操作数据。 - 审计员(
auditor):负责数据库的审计和查看日志,但不能修改数据。 - 数据操作员(
data_operator):负责操作数据,如插入、更新、删除,但没有权限创建或删除表等。
- 管理员(
监控与维护

维护优化
analyze 优化
如果担心每天 ANALYZE 影响系统性能,可以考虑更优化的方法:
方法 1:调整 autovacuum 相关参数
PostgreSQL 自带 autovacuum 会在表数据变化超过阈值时自动 ANALYZE,可以调整以下参数以优化行为:
autovacuum_analyze_threshold = 1000 # 最少多少行变化触发 ANALYZE
autovacuum_analyze_scale_factor = 0.05 # 变更超过 5% 触发 ANALYZE
autovacuum_vacuum_cost_limit = 2000 # 资源开销上限
autovacuum_vacuum_cost_delay = 20ms # 每次处理后暂停时间
适用场景:如果数据库负载不高,可以提高
autovacuum_analyze_scale_factor,减少不必要的ANALYZE触发。
方法 2:仅对活跃表进行 ANALYZE
可以使用 pg_stat_user_tables 查询最近更新过的表,针对这些表执行 ANALYZE:
SELECT relname, n_tup_ins, n_tup_upd, n_tup_del
FROM pg_stat_user_tables
WHERE n_tup_ins + n_tup_upd + n_tup_del > 10000; -- 仅分析修改超过 10000 行的表
然后在定时任务中,仅对这些表进行 ANALYZE:
#!/bin/bash
DB_NAME="your_database"
TABLES=$(psql -d $DB_NAME -t -c "SELECT relname FROM pg_stat_user_tables WHERE n_tup_ins + n_tup_upd + n_tup_del > 10000;")
for TABLE in $TABLES; dopsql -d $DB_NAME -c "ANALYZE $TABLE;"
done
适用场景:数据变化集中在少数表,减少不必要的
ANALYZE。
方法 3:分时段 ANALYZE
如果数据库表较多,可以在 业务低峰期(如凌晨)分批执行 ANALYZE:
psql -d your_database -c "ANALYZE table1;"
sleep 10
psql -d your_database -c "ANALYZE table2;"
sleep 10
...
适用场景:减少集中
ANALYZE造成的系统压力。
插件扩展
常见插件
- plpgsql
- postgres_fdw
- oracle_fdw
- xx_fdw
- pg_duckdb
- pg_vector
- postgis
…
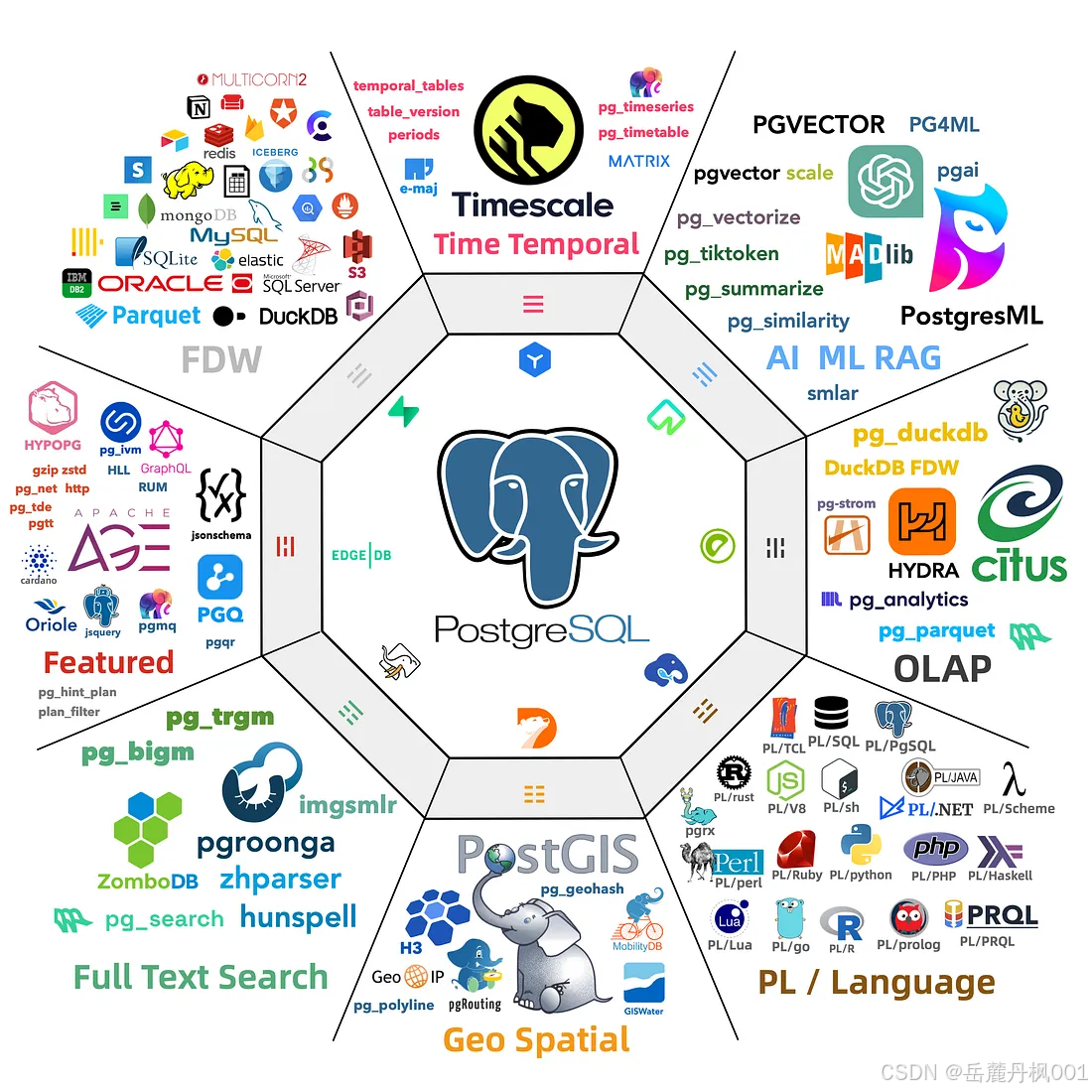



具体参考: https://www.khmer168.com/dbms/postgresql-in-eco-system-real-world/
插件库
https://pgxn.org/
https://roadmap.sh/postgresql-dba?fl=0
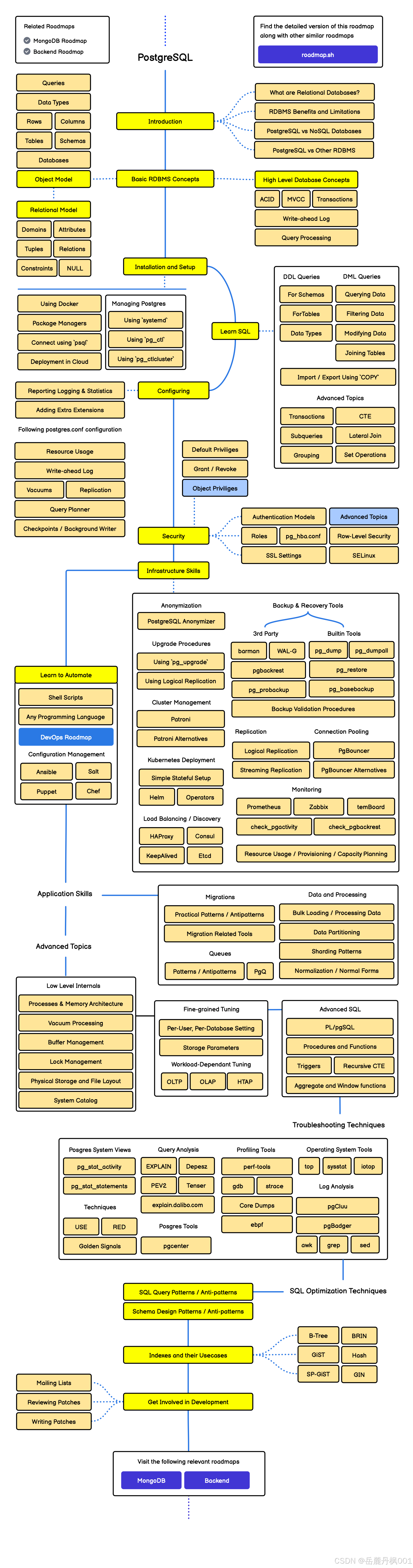
学习路线图
图片来源: https://roadmap.sh/postgresql-dba?fl=0