【漫话机器学习系列】256.用 k-NN 填补缺失值
用 k-NN 填补缺失值:原理、实现与应用
在实际的数据科学项目中,我们经常会遇到数据缺失(Missing Values)的问题。缺失值如果处理不当,不仅会影响模型训练,还可能导致最终结果偏差。
今天,我们来学习一种简单而有效的方法——使用 k 最近邻(k-Nearest Neighbors,简称 k-NN)来填补缺失值。
下面是本文核心示意图:
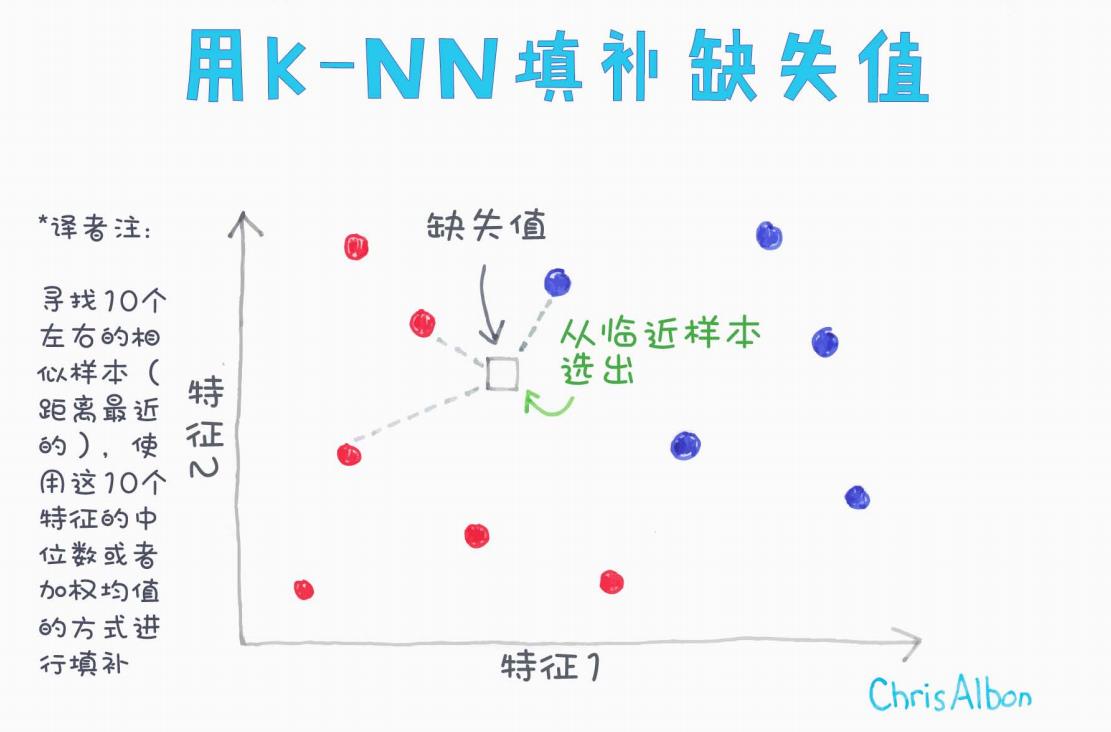
(示意图来源:Chris Albon)
1. 为什么需要处理缺失值?
在机器学习中,大多数算法都要求输入的数据是完整的,即不能存在空缺值 (NaN)。而实际中由于采集错误、设备问题、用户行为等种种原因,数据集通常会出现不同程度的缺失。
常见的缺失值处理方法有:
-
丢弃缺失的样本或特征
-
使用均值、中位数、众数填充
-
使用回归、插值等高级填补技术
-
使用基于 k-NN 的方法进行填补
k-NN 填补是一种基于相似性的填补方法,通常能取得更好的效果,因为它考虑了数据的整体分布和结构。
2. 什么是 k-NN 填补缺失值?
简单来说,k-NN 填补就是:
找到与缺失样本最相似的 k 个样本,利用它们的特征值来填补缺失项。
根据上图,填补步骤可以总结为:
-
确定缺失值位置
比如有一个样本在特征1、特征2上存在数据,但特征3缺失。 -
计算距离
只基于已有特征(非缺失部分)计算该样本与其他样本之间的距离。 -
选取最近邻
找到距离最近的 k 个样本(通常 k 取 5~10)。 -
填补缺失值
取这 k 个样本在缺失特征上的中位数或者加权平均数,作为缺失值的估计。
3. 具体案例:基于 scikit-learn 实现
使用 scikit-learn,我们可以直接使用 KNNImputer 类来完成填补。示例代码如下:
from sklearn.impute import KNNImputer
import numpy as np# 假设我们的数据矩阵中有一些缺失值
X = np.array([[1, 2, np.nan],[3, 4, 3],[5, 6, 2],[np.nan, 8, 1]])# 创建一个k-NN填补器,设置k=2
imputer = KNNImputer(n_neighbors=2)# 执行填补
X_filled = imputer.fit_transform(X)print(X_filled)
输出结果示例:
[[1. 2. 2.5][3. 4. 3. ][5. 6. 2. ][4. 8. 1. ]]
可以看到,缺失值已经被合理地填补。
4. 关键细节和注意事项
-
标准化很重要
在 k-NN 中,距离计算受特征量纲影响很大。因此,通常需要对数据先进行标准化(如使用StandardScaler或MinMaxScaler)。 -
选择合理的 k 值
k 值太小,容易受噪声干扰;k 值太大,又可能引入无关样本。通常可以交叉验证或经验选择 5~10。 -
缺失太多不适用
如果数据中缺失比例太高,k-NN 填补可能不够可靠,此时可以考虑模型预测或直接删除缺失严重的样本/特征。 -
计算复杂度
k-NN 填补在大数据集上会比较慢,因为每次都要计算距离。可以考虑使用近似最近邻算法加速。
5. 应用场景
-
客户信息表缺失部分字段
-
医疗数据(如血液指标)存在缺失
-
设备传感器数据偶尔掉包
-
用户行为数据不完整
在这些场景下,使用 k-NN 填补都能取得比简单均值填补更好的效果。
6. 总结
k-NN 填补缺失值,是一种基于数据本身结构的智能填补方法,简单、直观、效果良好。
虽然计算量较大、对尺度敏感,但在中小规模数据上,特别是特征之间具有明显结构或聚类性的场景下,非常值得使用。
建议在实际使用时搭配标准化处理,并根据数据特点合理选择 k 值!
如果觉得有用,欢迎点赞、收藏、评论交流~