Satori:元动作 + 内建搜索机制,让大模型实现超级推理能力
Satori:元动作 + 内建搜索机制,让大模型实现超级推理能力
- 论文大纲
- 一、背景:LLM 推理增强的三类方法
- 1. 基于大规模监督微调(SFT)的推理增强
- 2. 借助外部机制在推理时进行搜索 (RLHF / 多模型 / 工具)
- 3. 现有局限性总结
- 二、Satori 的自我改进思路:强化学习与 Chain-of-Action-Thought
- 5 Why 分析
- 5 So 分析
- 三、与现有方法的全面对比
- 四、总结
- 和 DeepSeek-R1 对比
- 解法拆解
- 1. 按照逻辑关系中文拆解【解法】
- 总体“解法”及主要思路
- 1.1 子解法拆解
- 特征1: LLM不会多步反思 --> 子解法1:COAT 格式(特殊元动作设计)
- 特征2: 不会使用COAT标记 --> 子解法2:小规模FT进行模仿学习
- 特征3: 长序列, 奖励稀疏 & 需局部纠错 --> 子解法3: RAE + RL
- 特征4: RL易陷入局部最优 --> 子解法4: 迭代自我提升 + 蒸馏
- 2. 子解法之间的逻辑链或结构
- 3. 是否存在“隐性方法”?
- 4. 是否有“隐性特征”?
- 5. 方法的潜在局限性
- 如果迁移到医疗领域,那需要什么样的元动作?
- 1. 重新审视症状(\<|reflect_symptoms|>)
- 2. 检查体征/化验单(\<|check_lab|> 或 \<|check_exam|>)
- 3. 咨询指南或文献(\<|consult_guideline|>)
- 4. 求证因果 / 排除性检查(\<|explore_alternative_dx|>)
- 5. 病患访谈 / 追问更多信息(\<|ask_patient|> 或 \<|query_history|>)
- 6. 预判治疗 / 疗效模拟(\<|simulate_treatment|>)
- 7. 最终汇总(\<|finalize_diagnosis|> 或 \<|resolve|>)
- 提问
Paper:https://arxiv.org/pdf/2502.02508
Project:https://satori-reasoning.github.io
论文大纲
├── 1 引言【描述背景和问题】
│ ├── LLMs 具备跨任务推理潜力【研究背景】
│ ├── 现有推理主要依赖推断时多样采样和外部验证器【问题描绘】
│ └── 研究目标:内化搜索能力并提高单模型的推理水平【提出需求】
│
├── 2 相关工作【文献综述】
│ ├── 基于大规模监督微调的推理增强【已有方法】
│ ├── 利用 RLHF/RL 等在推理时对答案进行搜索【已有方法】
│ ├── 通过多模型交互或工具辅助进行答案验证【已有方法】
│ └── 现存问题:仍需高成本外部组件,无法充分自我纠错【局限性】
│
├── 3 初步说明【理论基础】
│ ├── 数学问题场景:给定 x,模型要生成最终答案 y【设定】
│ ├── RL 框架:将推理视作序列决策过程【建模思想】
│ └── 强化学习常用算法(PPO 等)在文本生成中的应用【技术背景】
│
├── 4 方法:Satori【提出解决方案】
│ ├── 4.1 COAT 推理格式【核心概念】
│ │ ├── Continue〈|continue|〉:正常的连续推理【元动作1】
│ │ ├── Reflect〈|reflect|〉:在中途对当前推理进行反思【元动作2】
│ │ └── Explore〈|explore|〉:识别错误后尝试新思路【元动作3】
│ ├── 4.2 两阶段训练流程【整体框架】
│ │ ├── 阶段一:Format Tuning
│ │ │ ├── 采用小规模演示数据,示范 COAT 的使用【内化格式】
│ │ │ └── 模拟专家演示轨迹,进行模仿学习【主要手段】
│ │ └── 阶段二:自我增强 (Self-improvement)【关键创新】
│ │ ├── 利用 RL 与 Restart and Explore 技术【思路】
│ │ ├── 从错误状态重启,探索多条路径【对抗稀疏奖励】
│ │ └── 通过奖励模型与偏好评分细化奖励信号【激励机制】
│ └── 4.3 迭代式自我提升【训练策略】
│ ├── 训练若干轮 PPO 后,用 SFT 进行参数“重置”【逃离局部最优】
│ └── 不断交替 RL 与 SFT 以稳步提升推理能力【循环优化】
│
├── 5 实验与结果【实证验证】
│ ├── 5.1 数学推理基准测试【实验场景】
│ │ ├── GSM8K、MATH、AIME 等数据集【评测目标】
│ │ ├── Satori 在同尺度模型上表现优于已有方法【对比结果】
│ │ └── 多轮训练可进一步提升难题解题率【实验结论】
│ ├── 5.2 域外迁移评测【迁移能力】
│ │ ├── 在逻辑、编程等领域仍能保持较高准确率【结果】
│ │ └── COAT 格式带来的自我探究能力具有通用性【发现】
│ └── 5.3 迭代学习与自我纠正分析【深层分析】
│ ├── 自反思操作可显著提升正确率【定量对比】
│ └── RL 训练阶段使得推理长度自适应增长【自动调配算力】
│
└── 6 结论与展望【总结与思考】├── 单模型内化搜索能力可行并有效【主要贡献】├── COAT 结合 RL 的思路适合多种场景【应用潜能】└── 未来工作:扩展更多元动作与通用领域训练【进一步研究方向】
核心算法:
├── 核心方法【Satori 的关键思路】
│
│ ├── 输入【模型初始条件 + 任务】
│ │ ├── 基础模型【LLM Pre-trained】
│ │ │ └── 未经“COAT推理”特殊训练的通用语言模型【数据来源:大型语料】
│ │ └── 任务与问题【待解决的数学或推理场景】
│ └── 明确有标准答案的题目 (如 GSM8K, MATH)【评估目标】
│
│ ├── 处理过程【主要技术和方法】
│ │
│ │ ├── 第 1 阶段:Format Tuning (FT)【小规模微调】
│ │ │ ├── 目标:让模型熟悉 COAT 推理格式【适应元动作】
│ │ │ │ └── Chain-of-Action-Thought (COAT)【自反思与自探索的框架】
│ │ │ │ ├── Continue〈|continue|〉【生成并延续当前思路】
│ │ │ │ ├── Reflect〈|reflect|〉【在中途暂停并自检推理】
│ │ │ │ └── Explore〈|explore|〉【识别错误并尝试新思路】
│ │ │ ├── 核心技术:行为克隆 (Imitation Learning)【模仿专家示例】
│ │ │ │ └── 使用小规模轨迹数据 (专家给出的完整 COAT 解题过程) 进行 SFT
│ │ │ └── 输出:Satori-FT【已初步具备 COAT 推理格式的模型】
│ │
│ │ └── 第 2 阶段:自我增强 (Self-improvement)【大规模强化学习】
│ │ ├── 强化学习框架:PPO (Proximal Policy Optimization)【主算法】
│ │ │ └── 将推理过程视为序列决策,终端奖励来自正确性判定
│ │ ├── “Restart and Explore” (RAE) 策略【探索机制】
│ │ │ ├── 允许模型从中间状态重启【降低长序列错误的代价】
│ │ │ └── 鼓励模型在错误路径上进行纠正和多样化尝试【覆盖更多解空间】
│ │ ├── 奖励设计【细化监督】
│ │ │ ├── Rule-based Reward【是否得到最终正确答案】
│ │ │ ├── Outcome Reward Model (ORM)【对正确/错误答案进行细粒度打分】
│ │ │ └── Reflection Bonus【修正先前错误可获得额外奖励】
│ │ └── 输出:Satori【自我提升后的强化学习策略模型】
│ │ └── 已掌握自反思/自探索,减少对外部验证器的依赖
│ │
│ └── 迭代提升【多轮交替 RL 与 SFT】
│ ├── 先进行一轮 PPO 训练【获取新的策略改进】
│ └── 再以最新策略为基础做 SFT“重置”【跳出局部最优】
│
└── 输出【可内化搜索且具备多步自我纠正能力的单模型:Satori】├── 数学推理精度:适应 GSM8K、MATH 等问题集【结果】├── 迁移推理:对逻辑、编程等域外任务亦能提升【泛化能力】└── 实际价值:减少人工干预与外部辅助,提升一体化推理水平【应用前景】
一、背景:LLM 推理增强的三类方法
增强 LLM 推理的工作可以分为三大类:
- 蒸馏:通过教师模型或人工注释手工制作高质量的CoT数据集
- 外部引导搜索:通过提示或验证器引导生成推理步骤
- 自我改进:依靠强化学习(RL)算法进行改进
前面俩种不是我想搞的,只想走 AI 自博弈 路线,做到真正意义上的智能。
从长远看,这些人类构建和标注的知识有上限,会限制 AI 智能发展,人类知识都是干扰。
让 AI 自行搜索和学习的暴力破解方法,最终带来了突破性进展。
比如 AlphaGo 要人类知识喂出来的 AI,和世界冠军 PK,以4比1的总比分获胜。
但采用自博弈的 AlphaGo-Zero 摆脱人类棋谱经验的束缚,直接 100比0 战胜 AlphaGo。
1. 基于大规模监督微调(SFT)的推理增强
-
核心思路:
收集大量高质量的推理示例(如带有 (CoT) 的人工标注数据),对预训练好的语言模型进行进一步的有监督微调,以学习在给定问题场景下如何进行多步推理、得出答案。 -
典型代表:
- 直接在高质量人工标注的 CoT 数据集上进行微调。
- 通过知识蒸馏 (Distillation) 从更强的教师模型上合成数据,再对学生模型进行监督微调。
-
优点:
- 使用明确定义的人工示例和数据标签,训练过程稳定可控。
- 对一些领域数据足够充足时,模型能学到较好的多步推理范式。
-
局限性:
- 需要大量的高质量带推理过程的标注数据,人工成本高昂。
- 如果只依赖静态的监督数据,模型只学习到特定形式的推理示例,泛化能力可能受限。
- 随着问题难度提升,单纯依赖已有示例,仍然容易出现“短路”推理或错误一旦出现就难以及时纠错的情况。
标准的语言模型(例如通过传统的监督微调,SFT)在训练过程中通常是通过大量带有正确答案的训练数据进行优化的,而这些数据并没有明确地教会模型如何在推理过程中“停下来反思”或者“调整自己的思路”。
具体来说,标准语言模型的训练方式(如SFT)会根据输入文本来预测下一个词或生成一个输出,目标是让模型根据输入生成尽可能正确的输出。
但是,这种训练方法并没有教给模型如何在遇到困难或错误时主动“暂停”并反思自己的推理过程,也没有教它如何在中途发现错误时重新审视之前的步骤或者“调整思路”。
在复杂问题中,尤其是需要多步推理或长链推理的任务,模型可能会在某个步骤犯错,但标准的训练方式并没有使模型意识到这个错误并进行修正。
这就导致了一个问题:模型生成的答案如果出错,它就只能继续按照原有的路径生成,无法自我纠正或调整思路。
因此,作者提出的**Chain-of-Action-Thought(COAT)**框架就是为了填补这一缺陷。
COAT引入了元动作(如 <|reflect|>、<|explore|>),让模型在推理的过程中能够有意识地“反思”和“探索替代方案”,从而可以在出错时暂停、纠正并重新调整思路。
这种方式并不仅仅是生成最终答案,而是在推理的过程中允许模型进行中途自我纠错,从而更好地应对复杂的推理任务。
2. 借助外部机制在推理时进行搜索 (RLHF / 多模型 / 工具)
-
核心思路:
- RLHF (Reinforcement Learning from Human Feedback):在推理输出上引入一个独立的“判别器/奖励模型”,根据人类的偏好或客观指标(正确率等)来评分,进而通过强化学习微调策略,使得输出更符合人类期望或在正确率上更高。
- 多模型交互 / 工具辅助:将问题拆分给不同模型或调用工具(如计算器、代码解释器等)进行答案验证与修正。生成器模型会多次询问“验证模型”或利用工具反馈,将错误修正后再输出。
-
典型代表:
- RLHF (如 OpenAI GPT 系列在 ChatGPT 的后期阶段,PPO 算法微调 )。
- “Chain-of-Thought with a verifier” ,主模型负责生成解题过程,另一个“判别/价值”模型逐步对中间解题步骤或最终答案进行验证、评分。
- 工具辅助,让模型在推理中调用计算器、搜索引擎、代码解释器等来检验中间结果。
-
优点:
- 在推理环节动态采样多个候选方案,搜索空间更大,通常能提升准确率。
- 如果外部工具或验证模型强大,可以通过多轮交互显著降低错误率。
-
局限性:
- 需要额外部署“外部判别器模型”或者“多模型”或“外部工具”,增加推理时的计算开销与部署成本,体系复杂。
- 推理过程中依赖外部组件,对隐私、环境隔离或模型独立性等有较高要求时并不适用。
- 虽然能在推理时纠错,但模型本身并未真正“内化”外部纠错策略,不一定具备真正的自主自我反思能力。
3. 现有局限性总结
- 推理过程一旦出错,如果没有外部监督或工具,模型往往会陷入错误的思路中,难以及时纠正。
- 大模型难以自发进行自我策略探索:常规的 SFT 或简单的 RLHF,多数都依赖最终答案的奖励,而中间过程(如自我反思、纠错)经常没有显式激励。
- 结构复杂或成本高:引入多个模型或外部工具在推理阶段搜索,虽然可提升准确率,但部署难度、推理成本明显增加,缺乏“单一模型”端到端自我纠错的方案。
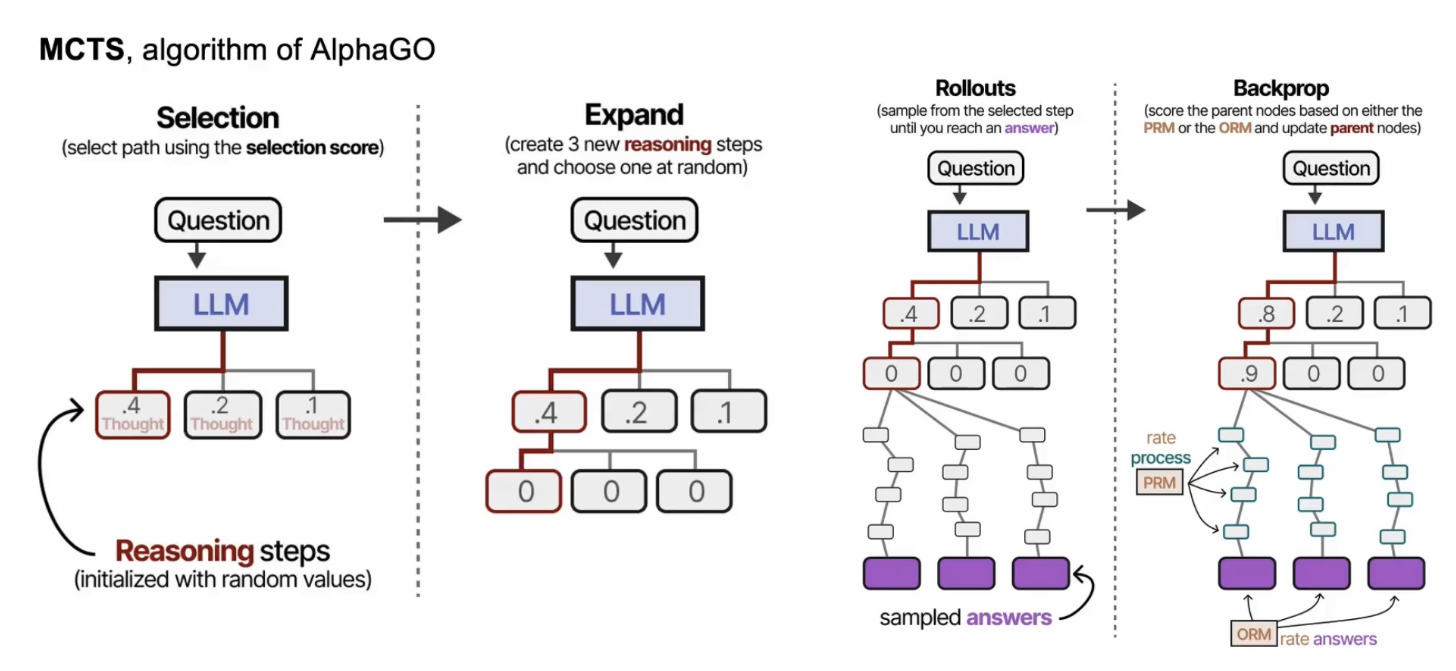
AlphaGo-Zero 一直没从围棋迁移到其他领域。
因为 MCTS 算法倾向于在推理时分多次做采样(例如,一次生成多个完整解答,再选最好;或一步步地让模型中途检查),但依赖“外部”检查或辅助模型。
必须自己额外训练一个奖励模型来评估答案质量。
二、Satori 的自我改进思路:强化学习与 Chain-of-Action-Thought
作者注意到,LLM 之所以需要对思维过程“多做采样”,实际上暗示了一个本质:模型如果能“自己给自己反馈”,自行纠错并探索替代解决方案,可能就不需要引入外部检查模型。
但作者也观察到“仅靠标准的语言模型微调”大概率无法让模型学会“中途改进或切换思路”,因为它并不知道如何在生成文本中插入“请停一下来反思”的信号,也不知道怎么复用之前的部分推理结果。
作者将整个流程分为两个训练阶段:
-
- Format Tuning(FT):用少量(约1万条)的“示范性推理轨迹”数据,让模型先学会如何使用“元动作”(如<|reflect|>、<|explore|>等)进行推理;
-
- Self-improvement via RL:在学会了这套COAT格式后,进行更大规模的强化学习(RL)训练,让模型在自我生成的新数据上不断纠错、并通过“Restart and Explore(RAE)”策略来纠正先前错误,进一步强化对复杂问题的内在推理。
- 关键创新
- 他们引入了“重启和探索”(RAE)机制,以解决“长推理链 + 只在最终答案给奖励导致的稀疏反馈”这个难题,让模型可以从中间步骤重来,而不是仅能从头重来。
- 他们设计了奖励函数,不仅考虑最终答案对/错的规则奖励,还额外加入了反思奖励(reflection bonus)、以及利用比对“正确/错误”推理的偏好奖励(preference bonus),辅助模型在没有大量人工标签的条件下依旧能够从“自生成数据”中得到有效学习信号。
相比同基座的纯指令微调模型,Satori-Qwen-7B 在数学和跨域推理测试中通常提升 2~10 个点。
与此同时,模型只需要一个单体便能实现“自我搜索、自我纠错”,无需外部大模型做审校,也不必依赖昂贵的手动逐步标注。
- COAT 格式:在传统的 Chain-of-Thought 的基础上,引入了特殊「meta-action」动作标记:
<|continue|>:继续当前思路推理;<|reflect|>:暂停并检查先前推理过程,进行自检;<|explore|>:尝试探索其他可能的解法。
通过这些标记,模型可以在单一推理序列中主动执行“再思考”、“纠错”、“换个思路做”等操作,而非依赖外部模型来提醒它这么做。
5 Why 分析
-
Why 1:为什么[加入元动作就能让模型内化搜索能力]?
因为元动作为模型提供了“显式的思考转折点”和“多次决策契机”,使模型能够在一段推理过程中主动暂停、检验或切换路线,而不仅仅是顺序输出。 -
Why 2:这个原因为什么会导致[模型可以进行搜索和纠错]?
因为有了“暂停”“反思”“探索”等指令,模型在推理时能动态评估当前步骤的正确性,及时调整。如果发现错误,可通过元动作切换思路或回溯重新尝试,从而实现“多路径”或“多回合”的内在搜索。 -
Why 3:为什么这些元动作能触发模型的主动决策?
因为模型在训练时学到:当遇到<|reflect|>时,需要检验前面推理;当遇到<|explore|>时,可以放弃当前思路而另起新路。训练中强化了这种“遇到某元动作就做特定策略性操作”的行为,从而赋予模型“在同一个问题上多轮思考”的能力。 -
Why 4:为什么训练中能强化这种行为?
因为在强化学习或有监督微调的过程中,模型若使用恰当的元动作来纠错,就可以得到更好的最终答案以及更高的奖励或更高的评价分数(例如通过奖励模型)。元动作使用得当==>纠正错误==>收获奖励==>进一步强化元动作的使用。 -
Why 5:最根本的原因是什么?
从根本上讲,传统语言模型只是基于“下一词预测”;而元动作相当于“注入”了一种元层决策结构,让模型能够在同一次解题过程中实现“自洽的多次决策”。这改变了以往“被动生成”的形式,使其能主动搜索、选择与纠正,因而真正内化了搜索能力。
5 So 分析
-
So 1:因此,我们可以怎样解决或改进?
我们可以在语言模型生成的文本中,显式增加若干“元动作”标记,并在训练阶段教模型在合适的情形下触发这些标记,从而增强模型自主搜索与纠错能力。 -
So 2:这个解决方案或改进会带来什么结果?
这样做会使模型不再局限于“一遍到头”式的推理,而是能在中间随时自我检验、重启、或转向别的思路,减少因为小错误就推翻整条推理的浪费,也提升复杂问题的解题成功率。 -
So 3:这个结果会如何影响整个系统或过程?
整个推理过程会变得更灵活与可控。模型在遇到陷阱题或高难度问题时,可以花更多“思考步骤”去拆解,而遇到简单题则可能快速给出答案。这提升了系统在多种难度场景下的鲁棒性。 -
So 4:进一步的影响是什么?
进一步来说,外部对模型的依赖也会减少。例如:不再需要额外的“纠错模型”或“人类监督”,单一模型就能自我审视并调整,部署成本相应下降,系统整体更易扩展到大规模应用场景。 -
So 5:最终,我们希望达到什么目标或状态?
最终希望模型具备高度的“自我管控”能力:既能输出中间推理过程,又能动态修正或探索新思路,从而像人一样进行“深度思考”。这能显著提高模型在推理、规划、复杂决策等任务上的表现。 -
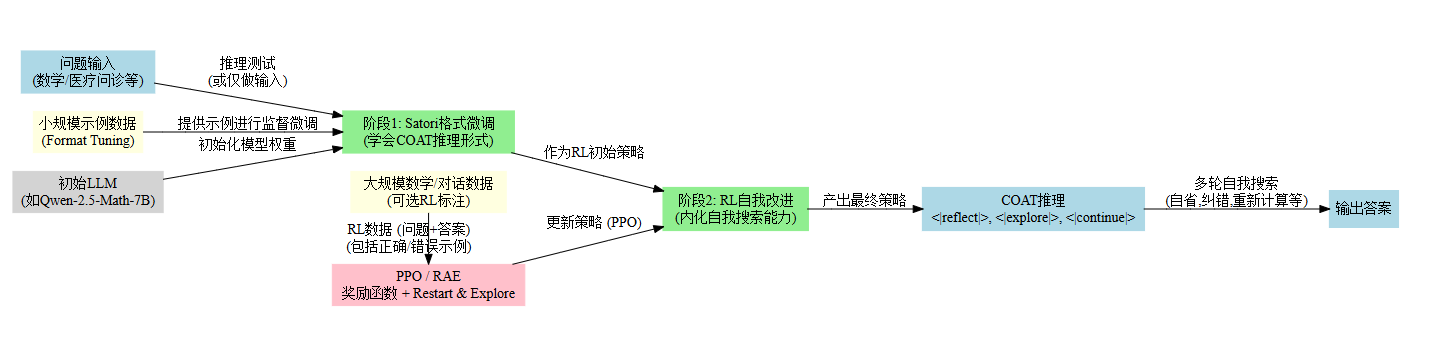
训练流程:
- (1) 小规模演示数据的格式微调(Format Tuning, FT)
先用人工或模型合成出少量(例如 1~10k)的“完整 COAT 轨迹示例”(包括出错、反思、纠正等示例),对基座模型(例如 7B 参数量级)进行监督微调,让模型能够“理解并使用”COAT 中的 meta-action。 - (2) 大规模自我改进的强化学习
使用 PPO 等算法,让模型从大量问题中通过自我生成推理轨迹进行探索。- 通过“Restart and Explore (RAE)”策略,当模型推理出错时,可从中间步骤「重启」并给予适当的奖励或惩罚,引导模型对过去的错误进行自我纠正;
- 额外利用小型奖励模型或规则设计 (如奖励最终正确答案、对纠错成功给予额外分数、对已经正确的思路却反而改错则施加惩罚等),让模型学到更有效的自我反思与纠错习惯。
- 在 RL 训练过程中,模型会逐渐学会根据问题难度分配更多推理 token,碰到疑难时主动进入「
<|reflect|>」纠错,提升问题解决率。
- (1) 小规模演示数据的格式微调(Format Tuning, FT)
这一套训练下来,Satori 不再需要外部模型或工具,在单一模型端就能完成:
- 自主识别推理错误,进入反思模式;
- 重新进行计算或换思路,得到新的答案;
- 在推理的最后时刻进行自查并尝试纠正先前解答。
三、与现有方法的全面对比
| 方法类别 | 核心思路 | 优点 | 局限性 | 代表性工作/模型 |
|---|---|---|---|---|
| A. 大规模监督微调 (SFT) 的推理增强 | 1) 人工或自动标注大量带 CoT 步骤的监督数据进行微调; 2) 或通过强师模型生成推理轨迹,再对学生模型执行蒸馏微调。 | - 有明确的人工监督或教师示例,训练过程可控; - 短期内易操作,效果较为稳定。 | - 对高质量带推理过程标注依赖大; - 通常只学习到固定形式的示例,泛化可能受限; - 仍缺乏自我纠错能力,一旦出错难以自行修正。 | - [Wei et al., 2022]: Chain-of-Thought Prompting - [Huang et al., 2023]; [Min et al., 2024]: Distillation from GPT-4 等 |
| B. 外部机制辅助搜索 (多模型/工具等) | 1) RLHF:有独立的 Reward Model 或审阅者,每次生成之后根据人类偏好或准确率打分,强化学习更新策略; 2) 验证模型 / 工具辅助:在推理过程中多次询问“验证器”或外部工具 (如计算器、搜索引擎) 检查并纠错。 | - 推理时可动态搜索多方案并验证,正确率高; - 工具或强审阅模型越强,纠错越有效。 | - 需要额外部署多个模型或外部 API,推理部署复杂度和计算开销上涨; - 若外部系统不可用或部署受限,则无法实现; - 模型自身并未真正内化纠错策略,更多依赖外部评估。 | - [Ouyang et al., 2022]: PPO for ChatGPT RLHF - [Wang et al., 2023]: Tree-of-Thought + verifier - [Yao et al., 2023]: ReAct/Plan&Solve 等工具调用 |
| C. Satori 的自我改进 (COAT + RL) | 1) 提出 Chain-of-Action-Thought (COAT):在推理序列中显式插入 <|reflect|>、<|explore|> 等元动作,让模型在中途暂停、反思、探索替代方案;2) 采用两阶段训练:(a) 小规模 Format Tuning(FT) 学习 COAT 格式;(b) 大规模强化学习(PPO+RAE) 利用“从中间状态重启、探索”来实现自我改进。 | - 仅需一个模型即可在推理时自我纠错、减少对外部 Verifier 或工具的依赖; - 强调“自我搜索、自我反思”,可反复迭代,提升复杂任务的准确率; - 对人工标注依赖较少,大量数据可通过自我生成与自我反馈而来。 | - 需要先进行少量格式微调来让模型“学会”使用特殊元动作,训练管线相对复杂(FT+RL 两步); - 仍需配合合适的奖励设计与探索策略,否则易陷入局部最优或“不会反思”的局面; - 主要在数学和逻辑推理等领域验证,对更广泛任务尚需更多探索。 | [Shen et al., 2025]: Satori: Reinforcement Learning with Chain-of-Action-Thought 部分开源实现: Satori-Qwen 系列模型 等 |
表格要点:
- 大规模 SFT 方法中,若能获得高质量大规模标注数据,模型推理能力提高明显,但成本极高,且自纠错不足。
- 多模型/外部工具 方法擅长动态搜索,但部署代价大,也并未真正解决模型本身的“自我改进”需求。
- Satori 通过将搜索、纠错机制内化到单一模型,并结合小规模示例 + 大规模强化学习的方式,引导模型学会在推理过程中多次进行“反思—重启—探索”。这样能在不依赖外部大模型或工具的情况下取得优异推理效果,还具备一定的跨任务泛化能力。
四、总结
- Satori 的贡献在于:提出了「Chain-of-Action-Thought」的推理格式,允许模型在一次推理生成序列中灵活调用
<|reflect|>等特殊动作进行自我检查、自我纠错;并利用「格式微调 + 大规模自我强化学习」两阶段框架,成功让模型内化了“多次尝试—纠错—最终收敛到正确答案”的能力。 - 该方法在数学推理上取得了可观的性能提升,且在纯数学训练后,转移到其他逻辑/表格/常识等任务上也有显著效果,表明模型获得了更通用的“自反思—纠错”的推理能力。
- 相比传统依赖外部验证模型或工具的搜索方式,Satori 降低了推理部署成本,亦不会将错误依赖外部构件,从而在很多场景下更具实用价值。
如上所述,通过“COAT + RL”在单一模型中实现多次反思与纠错,是 Satori 的关键创新点。
相较之前的方法,既不需要大规模人工标注的推理过程,也无需外部模型在线提供验证或额外工具干预,从而更低成本、更具可移植性。
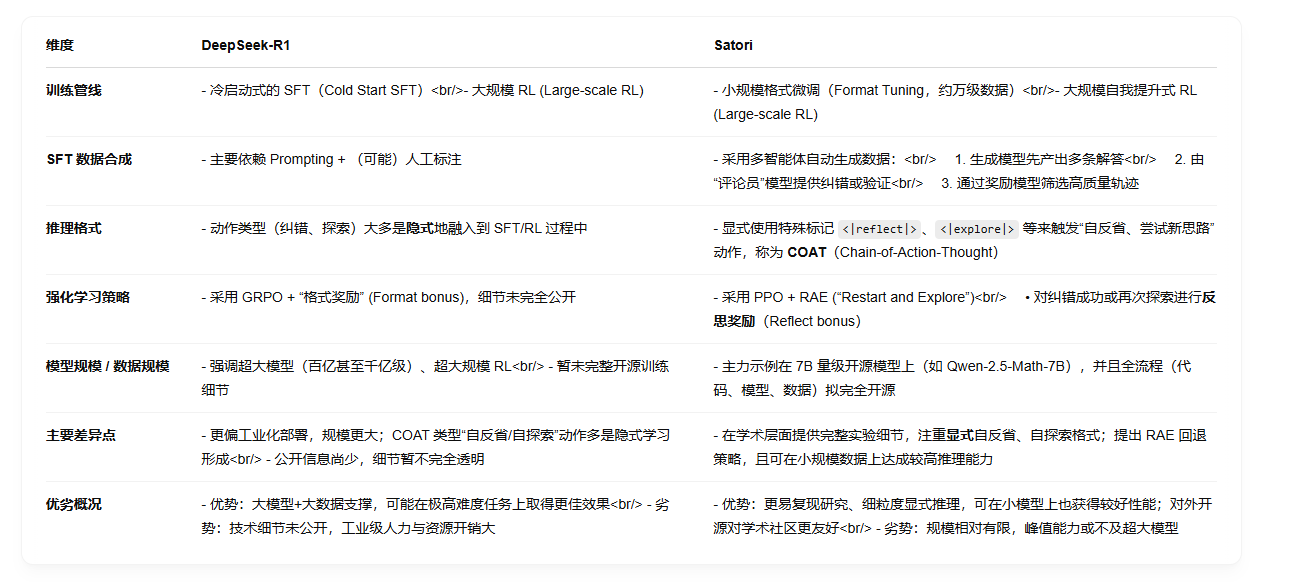
和 DeepSeek-R1 对比
解法拆解
1. 按照逻辑关系中文拆解【解法】
总体“解法”及主要思路
要解决的问题: 如何让大型语言模型(LLM)在推理时能够自主进行多步搜索、自我检查、并探索多种解法,从而在无需额外“外部监督者”的情况下获得更好的推理能力。
主要的技术思路(简要):
- 在语言模型里显式引入 Chain-of-Action-Thought (COAT) 的“元动作”格式,例如
<|reflect|>(反思)、<|explore|>(探索)、<|continue|>(继续),让模型可以在推理过程中“多次反省、纠正、或重新尝试”。 - 设计 两阶段训练范式:
- 第 1 阶段:Format Tuning (FT) 进行小规模模仿学习,让模型初步掌握 COAT 格式以及对这些元动作的理解与执行。
- 第 2 阶段:基于强化学习(RL)的 Self-improvement,通过大规模自我对局(生成并纠错)来提升模型对复杂问题的推理与纠错能力,核心方法是“Restart and Explore (RAE)”。
与同类算法的区别:
- 传统的“Chain-of-Thought (CoT)”只是一种“让模型输出中间思路”的提示工程或微调方式,一般没有明确的“自我反思”或“多次尝试”的动作设计;也缺乏在 RL 框架下将这种自我反思/纠正能力真正“内化”到模型中的机制。
- 以往需要“外部裁判”或“额外模型”去评判推理正确与否,而本方法尝试让一个单一的 LLM 自己进行元动作的控制和探索,从而减少系统部署成本,并在推理复杂度上实现“内在”搜索。
1.1 子解法拆解
特征1: LLM不会多步反思 --> 子解法1:COAT 格式(特殊元动作设计)
-
问题特征: LLM 原本只会顺序输出文字,不具备“显式地决定要不要反思或放弃当前思路并重启”的内部逻辑信号。
-
具体方法: 在生成的文本中引入三类特殊标记(元动作):
<|continue|>:表征“继续当前思路”。<|reflect|>:表征“暂停并自我检查先前步骤”。<|explore|>:表征“放弃当前思路或主动跳到另一种思考路线”。
让模型在输出推理过程时,可以灵活插入这些标记,以决定下一步是反思、继续,还是从头探索。
之所以用“COAT 格式”这一子解法,是因为 LLM 不具备内在‘多次反思’的特征;如果不显式地提供元动作,模型不会知道自己可以随时停下来反省、纠正或另起炉灶。
特征2: 不会使用COAT标记 --> 子解法2:小规模FT进行模仿学习
- 问题特征: 即使有了元动作标记,模型一开始并不知道碰到
<|reflect|>或<|explore|>时应该做什么,也不知道如何利用这些标记组织推理过程。 - 具体方法:
- 利用一个小规模的演示数据集(约 10K),其中包含“专家示范”过的完整 COAT 推理轨迹,让模型对“什么时候使用
<|reflect|>”、“什么时候使用<|explore|>”等有直观的模仿参照。 - 通过有监督微调(Supervised Fine-tuning, SFT)方式进行“行为克隆(Behavior Cloning)”,让模型先“记住”这些示范。
- 利用一个小规模的演示数据集(约 10K),其中包含“专家示范”过的完整 COAT 推理轨迹,让模型对“什么时候使用
之所以用“Format Tuning (FT)”这一子解法,是因为 模型初始时对 COAT 的标记含义一无所知;必须先有一些人工或其它模型产出的示范数据来“手把手教”它。
特征3: 长序列, 奖励稀疏 & 需局部纠错 --> 子解法3: RAE + RL
- 问题特征1(长序列/稀疏奖励): 在数学或复杂推理任务中,正确答案通常只出现在“最后一步”,导致奖励稀疏;如果让模型每次从零开始生成完整解答,很难有效学习到中间纠错的价值。
- 问题特征2(错误纠正需求): 很多解答只是中途犯了小错误,如果能在中间状态“重启”并改正,效率会更高;否则从头再来可能导致重复浪费计算。
- 具体方法:
- 在 RL 训练中,保留模型自己生成的部分正确/错误的解答轨迹,将其“中间状态”存进正/负两个“重启 buffer”。
- 训练时,可直接从某个中间状态启动推理,并插入
<|reflect|>提示模型反思,鼓励它只对局部做改正或进一步深挖。 - 通过在奖励函数中增加“反思奖励”或“探索奖励”,让模型在成功从错误中纠偏时得到额外收益,在无意义地改动正确答案时受到惩罚。
之所以用“RAE + RL”这一子解法,是因为 推理路径长、正确奖励稀疏、但小错误往往可回溯更正;“重启并探索”的机制帮助模型在中间状态就能纠偏,且减少训练浪费。
特征4: RL易陷入局部最优 --> 子解法4: 迭代自我提升 + 蒸馏
- 问题特征: 大规模强化学习过程,模型可能会陷入局部最优;RL 训练后期也会遇到梯度难以更新的瓶颈。
- 具体方法:
- 在一轮 RL 训练收敛后,提取该“优化后”的策略,然后再用监督微调的方式,将其策略(好样本)“蒸馏回”到同一个模型的初始参数(类似重置并汲取优势)。
- 利用蒸馏后的模型,再进行下一轮 RL 训练,如此往复,从而持续突破局部最优。
之所以用“迭代自我提升 + 知识蒸馏”这一子解法,是因为 RL 容易局部收敛;通过定期地把当前好策略蒸馏回初始模型,一方面巩固了已学会的好轨迹,另一方面也相当于“重置”某些参数,使得后续 RL 还能继续改进。
举一个例子:
- 在解一个数学题:
“2+3+8=?”时,模型若初步算错“5+8=14”,它可以在输出中插入<|reflect|>,意识到此前加法不对,然后重新尝试<|explore|>另一条思路,最后输出13并结束。
2. 子解法之间的逻辑链或结构
- 先通过“子解法1 + 子解法2”,让模型掌握 COAT 格式及正确用法;
- 再结合“子解法3”进行大规模的 RL 自我纠错;
- 在 RL 里,如果训练陷入瓶颈,则启用“子解法4”做迭代自我提升。
这些子解法实际上是**“串行累加”**的关系:COAT (1) → 小规模FT (2) → 大规模RL (3) → 迭代蒸馏 (4)。
3. 是否存在“隐性方法”?
逐行对比与传统做法(如纯 SFT 或纯 CoT)区别,可以看到:
- COAT 中的“反思/探索元动作” 本身就是一个新颖的“隐性方法”。在很多经典做法里并没有明确的“重启”信号,这更像是作者为了让 LLM “内化”搜索而额外增加的机制。
- “在中间状态直接重启训练”(RAE)这一步骤,也可以视为一种并不常见的“隐性技巧”:并不是书本上经典的“从头开始生成再对比好坏”的 RL,而是借助“中间断点”去做局部纠错,让 RL 训练更有效。
这两个方法都属于典型的“书本上没有的关键步骤”,只能在阅读论文细节才发现。
因此可以定义两个关键“隐性方法”:
- 隐性方法A:COAT 的元动作机制(引入
<|reflect|>等标记,以实现模型的分段反省与探索) - 隐性方法B:在强化学习中使用 RAE“重启-探索”策略(不从零开始,而是利用正确或错误的中间状态进行局部反思与纠正)
4. 是否有“隐性特征”?
在解法步骤中,也出现了与传统“问题特征”不同的隐性特征。例如:
- “从正确中间状态再度修改反而出错” 这一特征:论文中给出了一个“惩罚”机制(如果本来已经对的解答却偏要在中间状态插入
<|reflect|>并改错,就会被负奖励),这是典型的“隐性特征”——它并不出现在题目本身,而是模型推理中间步骤所暴露的一类“潜在错误”。 - “从错误中间状态成功纠正” 这一特征:论文中会给它额外正奖励,也是根据中间轨迹能否修正失误的一种“隐性特征”。
在普通的监督学习或传统 CoT 下,并不会刻意区分“中途改错”还是“保持正确”。
Satori 在中间步骤引入了这些额外奖励或惩罚,说明它定义并捕捉了这两个隐性特征。
5. 方法的潜在局限性
- 元动作设计需要手工定义:
<|reflect|>、<|explore|>、<|continue|>这些符号及其语义,目前是由作者人工设定;若要扩展到更灵活、更通用的“meta-actions”,需要更加复杂的设计与微调。 - 训练成本和算力消耗大: RAE + RL 本身需要在大规模数据上长时间训练,而且要不断生成、评估和重启,可能对硬件资源要求较高。
- 对提示及奖励函数较敏感: 如果“反思”或“探索”被奖励不当,模型可能会产生过度反思(回答极度冗长)或反思不足(仍旧草草下结论)的问题。
- 主要验证集中在数学或推理题: 论文显示虽然在一定程度上有跨领域泛化能力,但若是开放式生成、创意写作等类型的任务,是否同样能受益还需要进一步验证。
- 局部错误严重时仍需大量尝试: 如果模型从来没见过某类新知识或逻辑错误点,可能要多次
<|reflect|>和<|explore|>才能找到正确答案,效率并不总是最优。
如果迁移到医疗领域,那需要什么样的元动作?
在医疗场景下,如果我们希望迁移论文中“自我反思、自我探索”的思路,就需要考虑医疗任务的特定需求,包括如何采集、整合、验证各种症状与检查数据,并最终得到诊断或治疗策略。
与数学推理或代码调试相比,医疗诊断往往包含更多面向“数据来源”、“辅助检查”、“医学知识库”的操作。
下面给出一些 可能适用的元动作(仅作示例,实际落地会根据任务细节作增删):
1. 重新审视症状(<|reflect_symptoms|>)
- 作用场景:
当模型在推理某种疾病或病情时,发现已有症状信息可能不一致,或尚有未排查的相关症状。 - 示例触发:
「患者有夜间咳嗽,但是还没有确认咳嗽性质或是否伴随胸闷,可能需要补问或核实相关症状」。 - 模型行为:
通过触发<|reflect_symptoms|>,模型会检查先前列出的症状清单,发现遗漏或疑点并进行补充解释或请求更多信息。
2. 检查体征/化验单(<|check_lab|> 或 <|check_exam|>)
- 作用场景:
临床诊断往往需要多种检查结果(血常规、CT、X光、B超等)。如果诊断不明确,模型可以触发“查看”或“补充申请”相关检查,以降低推理不确定性。 - 示例触发:
「患者怀疑肺炎?查看是否有胸片或 CT 结果」;
「考虑心肌损伤?需要心肌酶谱检查……」。 - 模型行为:
通过<|check_lab|>发起“读取/查询当前病患的检测数据”,或者建议去做额外检测并根据检查结果更新诊断思路。
3. 咨询指南或文献(<|consult_guideline|>)
- 作用场景:
许多疾病诊疗有既定临床路径,或已有学会指南作指导。模型在不确定时,可以调用这条元动作来“内置检索”相应文献/指南思路。 - 示例触发:
「在推理自体免疫病时,需要看 Rheumatology 指南」;
「儿童退烧用药是否符合最新儿童用药指引」。 - 模型行为:
通过<|consult_guideline|>让模型进行“查询或回顾”现行指南的要点,然后将之纳入本轮推理中。
4. 求证因果 / 排除性检查(<|explore_alternative_dx|>)
- 作用场景:
当一个诊断思路走不通,需要切换到其他备选方案时,类似数学推理中的<|explore|>,但在医学里更倾向于“排除诊断”或“差异诊断”切换。 - 示例触发:
「若不是细菌性肺炎,是否可能病毒感染?或存在其他合并症?」 - 模型行为:
触发<|explore_alternative_dx|>后,模型会回退到某个关键症状/证据点,重新对差异诊断(Differential Diagnosis)列表进行梳理,对可疑疾病逐一排除或并列考虑。
5. 病患访谈 / 追问更多信息(<|ask_patient|> 或 <|query_history|>)
- 作用场景:
当现有信息不充分,需要与患者进行更深入的问诊、补充既往史、家族史等。 - 示例触发:
「是否有高血压家族史、糖尿病史?最近是否有出国经历?」 - 模型行为:
通过<|ask_patient|>,模型会列出尚未确认却影响诊断的关键信息,提示用户或下游系统采集更多数据。相当于“再询问一轮”才能继续推理。
6. 预判治疗 / 疗效模拟(<|simulate_treatment|>)
- 作用场景:
在医学决策里,有时会先假设一种治疗方案,推测其潜在效果与风险,若效果不佳或矛盾,再回退进行调整。 - 示例触发:
「若使用某种抗生素,是否有效?患者是否可能产生严重不良反应?」 - 模型行为:
触发<|simulate_treatment|>时,模型会根据病人特征和既往统计数据,评估此治疗方案的安全性与有效性;若评估发现与病例不符,则回退并切换其他方案。
7. 最终汇总(<|finalize_diagnosis|> 或 <|resolve|>)
- 作用场景:
在医学推理接近尾声时,需要将所有信息综合考虑,给出最终诊断和建议。 - 示例触发:
「已排除了其他差异诊断,也确认相关检查结果,综合判断为 XX 疾病」 - 模型行为:
触发<|finalize_diagnosis|>,模型将当前的推理、症状、检查数据、差异诊断结论等统一汇总为一份结构化医疗建议或诊断报告。
它们让模型能够:
- 分步思考:像查病历、查化验单、查指南一样,一步步聚合信息;
- 自我校验:发现症状或结论冲突时可中途反思、回退;
- 探索分支:有多种可能疾病时,可自动发起“差异诊断”、视需要收集更多数据;
- 最终下结论:在信息足够、推理完备时给出诊断或治疗建议。
这些动作实际上就像是“对话式医疗系统”的一个扩展,把医生在临床上“回头翻看病历、补充检查、考虑替代诊断”等逻辑一步步显性化,使得单一模型具备了近似“内在树状搜索”的能力,而不必完全依赖外部辅助器或手工脚本。
随着医疗 AI 的发展,还可以继续拓展更多元动作,以满足越来越复杂的临床决策需求。
提问
Q1. 为什么作者在论文中要强调“在一个单一 LLM 内部实现搜索”比使用“外部 LLM 验证器”更有潜力?
A1. 论文指出,使用单一模型具备可扩展性和部署便利性。
两玩家框架(一个生成器+一个验证器)在推理时需要两次推理调用,且需要独立部署,成本较高。
反观将搜索能力“内化”到一个模型里,能减少系统复杂度并在推理时更灵活地进行自我纠错。
Q2. COAT(Chain-of-Action-Thought) 与传统 CoT(Chain-of-Thought) 的根本区别是什么?
A2. 传统的 CoT 只是在推理中展示中间思路;COAT 则在文本中显式插入“元动作”标记,如 <|reflect|>、<|explore|> 等,让模型可以做出自我反思、检验或切换新路线的决策。
这些“元动作”使得模型在推理过程中可以多次纠错、重启或另行探索,而不仅仅是顺序输出推理步骤。
Q3. 为什么作者在小规模的“Format Tuning (FT)”阶段只使用了 10K 条示范数据就能让模型学会 COAT 格式?
A3. 根据论文,10K 水平的数据虽然相对较小,但足以让模型“熟悉”元动作的用法——比如 <|reflect|> 出现时要进行自我检验。
作者发现:只要最初有一个模仿学习的冷启动,“后续的大规模自我强化学习”就能带来更大增益,所以前期并不需要海量示范。
Q4. Satori 在数学推理方面使用了哪些公开数据集来评测?为什么选择这些数据集?
A4. 论文中提到的主要数学数据集包括 GSM8K、MATH500、AMC2023、AIME2024、OlympiadBench 等。
这些数据集覆盖了从基础算术到竞赛级难度的问题,以测试模型在不同层次上的数学推理能力,同时观察是否能从简单题延伸到更复杂的竞赛难题。
Q5. 论文提到的“test-time scaling”概念指的是什么?Satori 又是如何体现这一特性?
A5. “Test-time scaling”是指模型在推理阶段分配更多计算/生成步骤,能让其推理更充分、得到更高准确率。
Satori 因为学会了在过程中反思与纠错,遇到难题时往往输出更长的推理序列,以继续搜索正确解;
这被作者称为一种“可伸缩”的自适应推理方式。
Q6. 在 RL 训练里,作者怎么解决“长序列、奖励稀疏”导致难以学习的问题?
A6. 作者使用了 “Restart and Explore (RAE)” 机制:模型若在推理中途出现错误,也可以从中间状态重启,而不是完全从头再来。
这样减少了无效重算,更有机会得到正向反馈。
此外还设计了“Reflection Bonus”等额外奖励,强化“从错误中纠正”的行为。
Q7. 在 RL 阶段,为什么要“惩罚”从正确答案重启后却把答案改错的情况?
A7. 论文称之为“reflection penalty”的一部分。
这样做是为了防止模型对“已正确”的中间状态做不必要的修改。
如果它在一个已经正确的状态下仍要 <|reflect|> 并错误更改,会得到惩罚,避免浪费算力和时间。
Q8. 作者提出的 “Outcome Reward Model (ORM)” 在奖励函数中起什么作用?
A8. ORM 用偏好学习(Bradley-Terry 框架)来为完整解答打分。
除了最后“正确或错误”的离散标签外,ORM 还能提供更细粒度的奖励(评分),帮助模型在没有完全正确答案的情况下也能区分“哪条推理更好”,缓解纯二元奖励的稀疏性。
Q9. 论文里为什么提到在 RL 开始时,模型的平均生成长度可能先缩短,然后随着训练继续又变长?
A9. 在初期,模型尚未学会自反思技巧,有时会倾向“尽快给出答案”。
随着强化学习的推进,模型发现“多步反思”能带来更高收益,渐渐就学会了在更难题目上延长推理序列,从而改进准确度,故生成长度又变长。
Q10. 为什么论文作者要在 RL 收敛后,再用 supervised fine-tuning (SFT) 进行知识蒸馏?这种迭代循环的好处是什么?
A10. 作者提到:直接让 RL 反复迭代,容易陷入局部最优,导致模型更新停滞。
通过“将当前优秀策略蒸馏回模型初始参数”,可以在参数空间里“重置”一部分,接着再做 RL。
这样能让模型吸收已学到的好策略,同时保持一定探索能力。
Q11. 为什么只用小规模的人工示范就能训练出对数学问题普遍泛化的能力?是否意味着对其他领域也同样适用?
A11. 论文强调,小规模示范只是为了教模型如何使用 COAT 结构,真正的能力来自后续大规模自我强化学习。
对于其他领域要不要同样适用,还需额外验证,但作者的实验表明,Satori 在某些常识或推理数据集上也有“零样本”迁移能力。
Q12. COAT 的 <|reflect|> 和 <|explore|> 两种元动作有何使用差异?它们都能“切换解题思路”,为什么要分开?
A12. <|reflect|> 通常指自我校验、排查当前思路的错误,有时会修正一些小失误;
<|explore|> 更侧重直接从头来或彻底更换思路,适合重大错误或全新尝试。
它们在训练中分别带有不同的提示语义和意图。
Q13. 在作者的实验中,Satori 是如何在数学以外的一些逻辑、表格、常识推理任务上进行评测的?
A13. 论文列出了诸如 FOLIO(一类逻辑推理任务),BGQA(棋盘规则推理),CRUXEval(代码推理),StrategyQA(常识推理),TableBench(表格推理)等外部数据集,并对比了 Satori 与同尺寸或更大尺寸模型的表现。
结果显示 Satori 在部分任务上超越了原基座模型。
Q14. 作者为什么要强调“COAT 格式”相比传统的“CoT 格式”在最终结果上更有提升?难道 CoT 不也能显示中间推理吗?
A14. 论文指出:传统 CoT 只是静态输出思路,而 COAT 多了“元动作标记”,让模型在推理时可主动触发纠错/反思。
在复杂问题上,纯 CoT 常常一次成文,错了也不回头;
COAT 则可以动态检查上一段计算并修正,实测准确率更高。
Q15. 训练 Satori 时,为什么还需要一个额外的“多代理数据生成框架”(Generator, Critic, Reward Model)来合成小规模演示数据?
A15. 这是为了获得带有元动作的“专家演示”。
模型自己在初始阶段无法写出合格的 COAT 轨迹,所以作者用已有强模型(如 Qwen-2.5-Math-Instruct)来做 Generator,另用一个更大模型(如 Llama-3.1-70B-Instruct)当 Critic,筛选/修正后再选好轨迹,用 Reward Model 排序优劣,最后得到 10K 条优质示例。
Q16. 为什么称“RAE”策略借鉴了“Go-Explore”思路?两者在概念上有什么共同点?
A16. “Go-Explore” 强调从已知的状态中间断点继续探索,避免反复从头来。
RAE 在语言模型推理中做了类似思路:记录中间状态、允许重启并探测新路径。
共同点都是“通过回到已有中间阶段,减少重复探索起点”。
Q17. 论文提到一个关键信号:Satori 学会了“在更难的题目上输出更长的推理序列”。它背后的机制是什么?
A17. 强化学习中,回答正确的最终奖励更高,于是模型自动发现“难题若不多花点推理步数就很难解对”,所以倾向在高难度场景多次 <|reflect|> 或 <|continue|>。
这种动态分配推理步骤的行为即“test-time scaling”。
Q18. 论文中说“自我纠正不总是积极的”;在统计上,Satori 会不会把本来对的答案改错?
A18. 会有一定概率。论文提到“负惩罚”是为了降低这种情况,但并不能完全杜绝。
实践中,确实观察到少量“从正确改到错误”的负面样本,只不过总体收益大于损失。
Q19. 如果别人想把 Satori 迁移到其他大模型上,作者是否给出了对应思路或提示?
A19. 作者在文中最后一部分讨论了“Distillation + Format Tuning”的组合方案:先用强模型生成大批带有 COAT 轨迹的数据,再拿这些数据去蒸馏到更弱的基模型。
这是论文给出的可行迁移思路之一,并且比单纯“格式微调”更有效。
Q20. Satori 方法仍存在哪些局限性?论文中作者自己强调了哪些未来改进方向?
A20. 主要局限包括:
- 需要手动定义元动作且奖励设计精细;
- RL 训练本身耗时高,对硬件要求大;
- 主要实验集中在数学和部分推理任务,对更开放式写作、对话等领域的迁移还需进一步研究。
作者提出可拓展“更多元动作或策略”,以及改进奖励机制,让模型在更广泛的场景下也能高效自我纠错。