科大讯飞TTS(文字转语音)和STT(语音转文字)
一、语音识别的概念与应用
- 基本概念
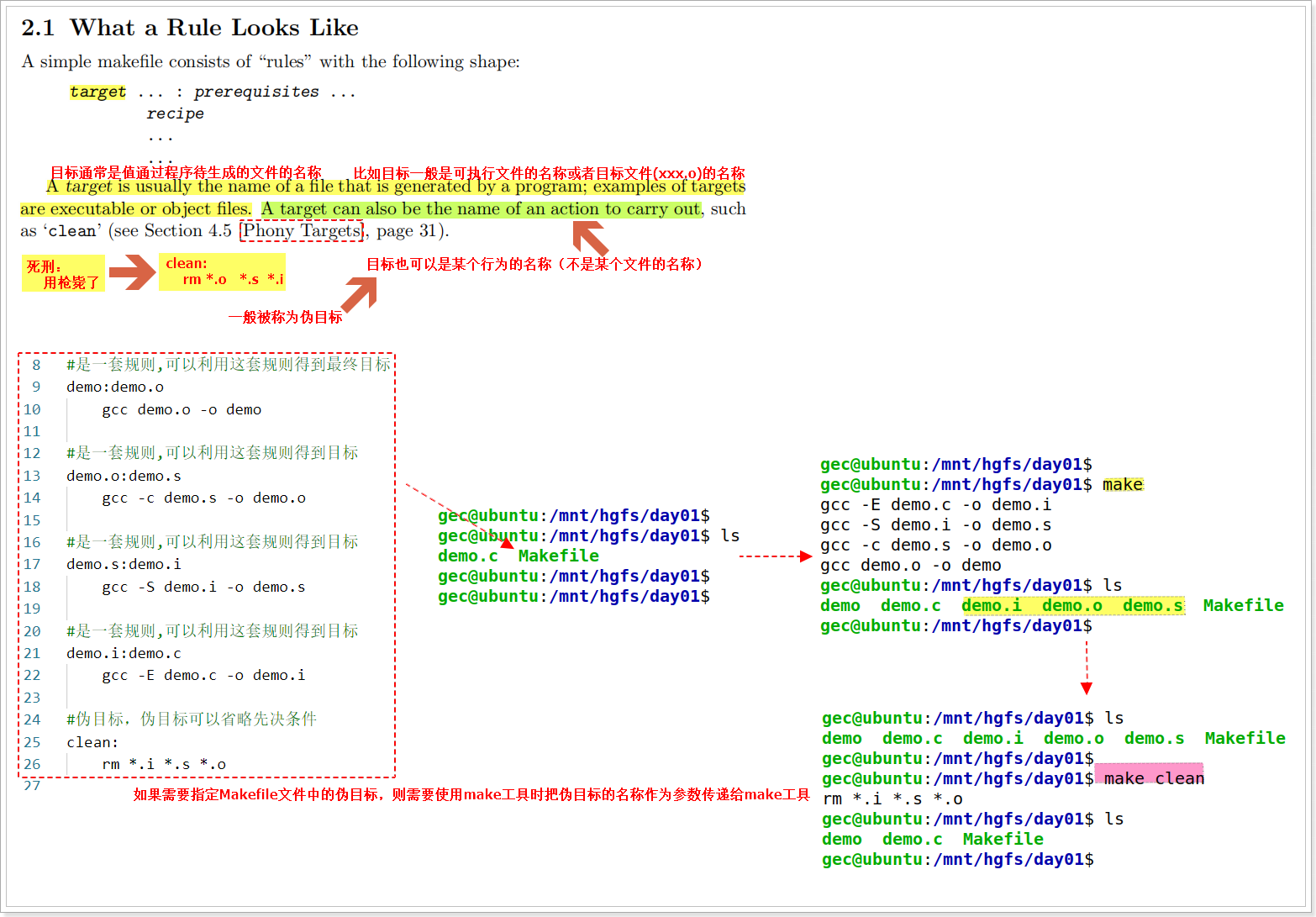
语音识别技术是一种将人类语音转换为计算机可识别的文本或命令的技术。它使用声音信号处理、语音分析、语音识别算法等技术,将人类语音转换为计算机可识别的文本或命令。
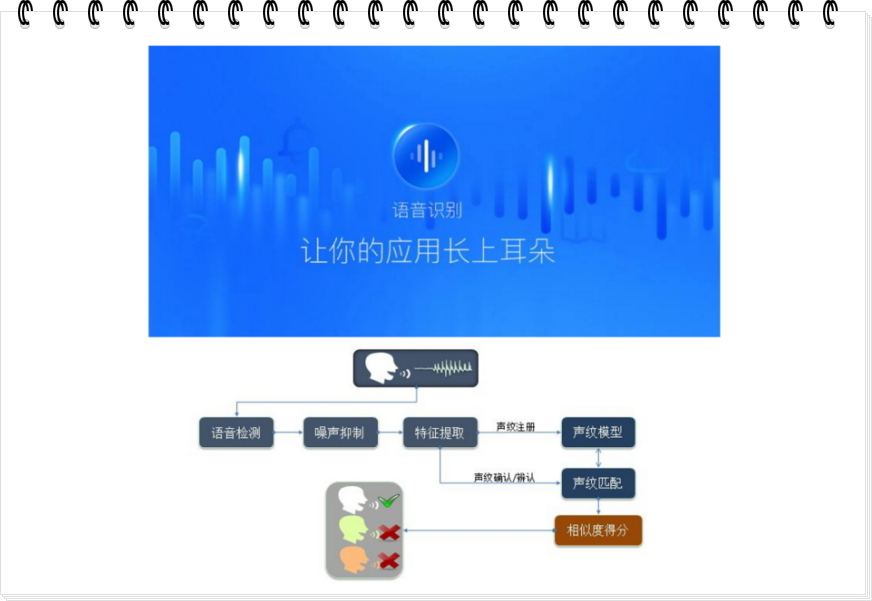
语音识别技术其实包含两个方向,一个是TTS(文字转语音)技术,另一个是STT(语音转文字)技术。目前国内语音识别技术做的非常不错的公司有很多,比如百度AI,或者科大讯飞。
语音转文字和文字转语音是两种基于人工智能技术的语音处理技术,具有以下概念和特点:
语音转文字技术,也称为自动语音识别(Automatic Speech Recognition,ASR),是指将人类语音信号转换为相应的文本形式。这项技术通过分析和解读语音信号的频率、时长和语音单元之间的关系,将语音转化为可读的文字。语音转文字技术的主要特点包括:
1. 实时转换:语音转文字技术可以实时地将说话者的语音转换为文字,实现即时的语音识别,方便用户进行实时交流和数据处理。
2. 多语种支持:语音转文字技术能够支持多种语言和方言的转换,使得跨语言交流和多语种应用成为可能。
3. 应用广泛:语音转文字技术被广泛应用于语音识别系统、智能助理、语音搜索、语音指令等领域,提供了便捷的语音输入方式和更好的用户体验。
文字转语音技术,也称为文本到语音合成(Text-to-Speech,TTS),是指将文本转换为可听的语音信号。该技术利用机器学习和自然语言处理算法,将输入的文本转化为自然流畅的语音输出。文字转语音技术的主要特点包括:
1. 自然流畅:文字转语音技术通过模拟人类语音的音调、语速和语音韵律,生成具有自然流畅性的语音输出,使得听者能够获得良好的听觉体验。
2. 个性化调整:文字转语音技术通常支持对语音的音调、性别、语速等进行个性化的调整,以满足不同用户的需求和偏好。
3. 多平台应用:文字转语音技术可以在各种设备和平台上应用,包括智能手机、电脑、智能音箱等,为用户提供语音交互和辅助功能。
语音转文字和文字转语音技术的结合可以实现语音交互的完整闭环。例如,语音助手可以通过语音转文字将用户的语音指令转换为文本,然后利用文字转语音将回复信息转化为语音输出,实现与用户的自然交流。这两项技术的发展和应用为人机交互提供了更加智能和便捷的方式。
- 应用场景

语音识别技术是一种将语音信号转换为可理解的文本形式的人工智能技术,它在各个领域中具有广泛的应用和巨大的前景。
- 接口下载

科大讯飞(iFlytek)公司是中国领先的人工智能(AI)公司之一,而讯飞开放平台是该公司推出的一个开放的、面向开发者的平台,旨在提供各种语音和人工智能技术的API和SDK,以促进创新和应用的开发。
讯飞开放平台提供了多个功能丰富的API,涵盖了语音识别、语音合成、自然语言处理、人脸识别、图像识别等领域。开发者可以通过讯飞开放平台接入这些API,利用科大讯飞先进的语音和人工智能技术,为自己的应用程序和产品增添智能交互的能力。
- 注册账号
- 登录账号
- 进入后台

- 创建应用
- 参数说明
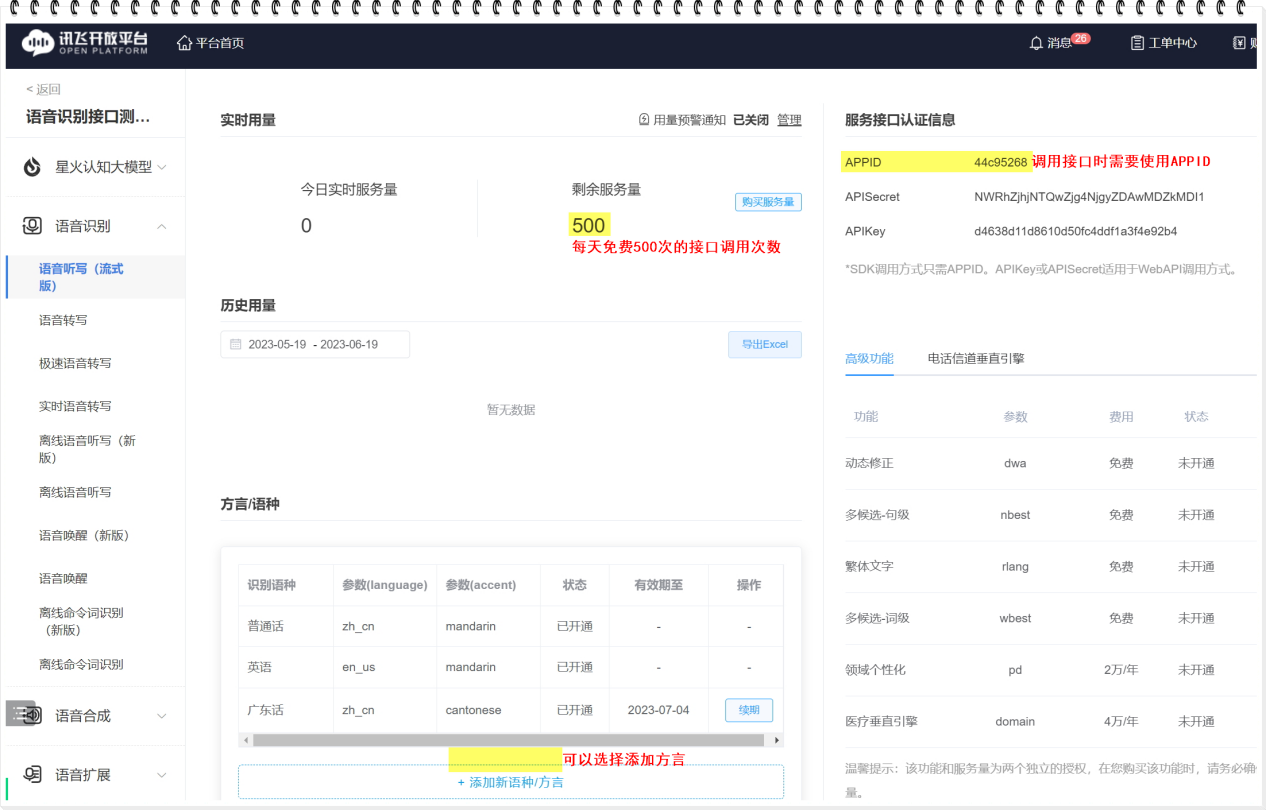
- 接口下载
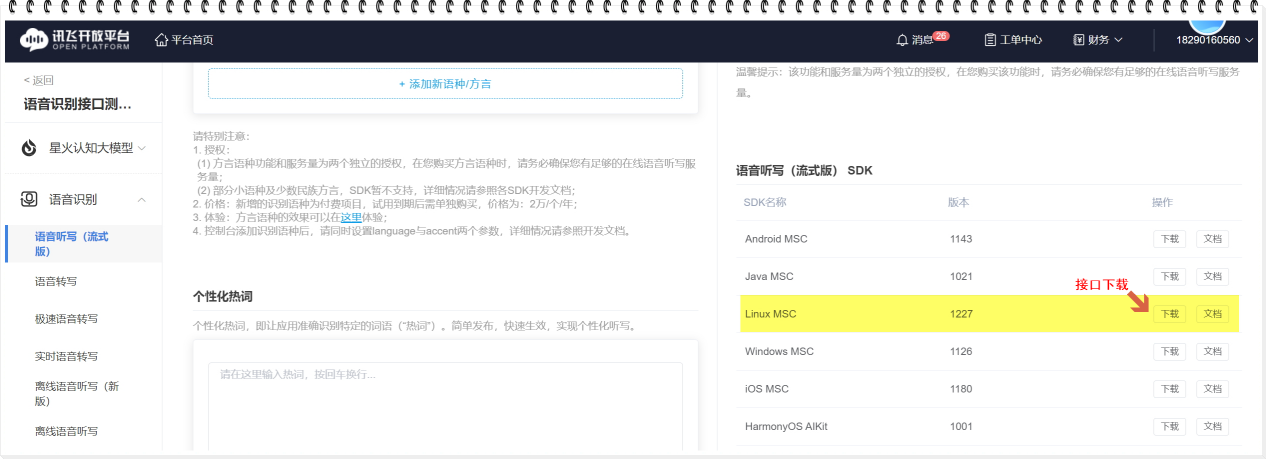

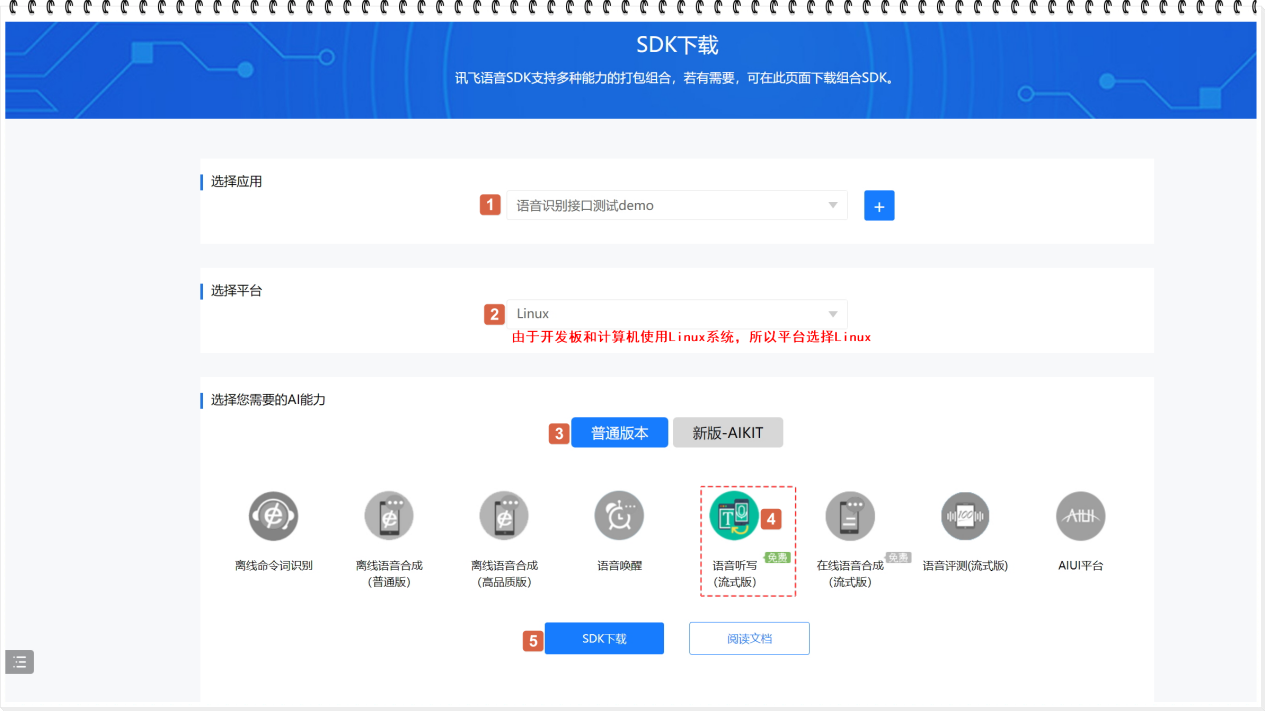
- 使用教程
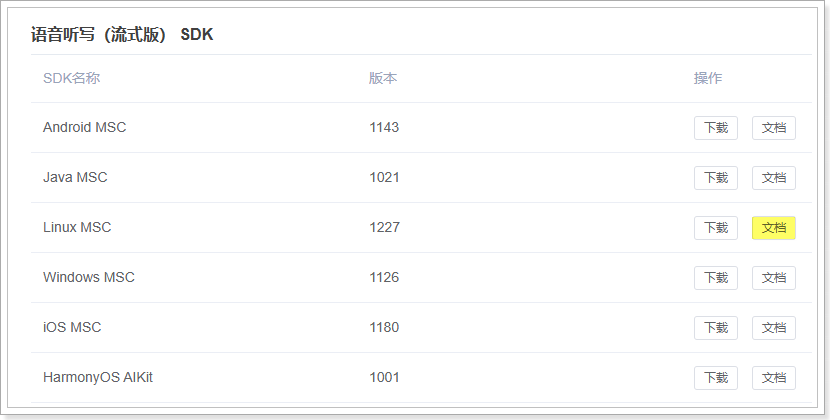

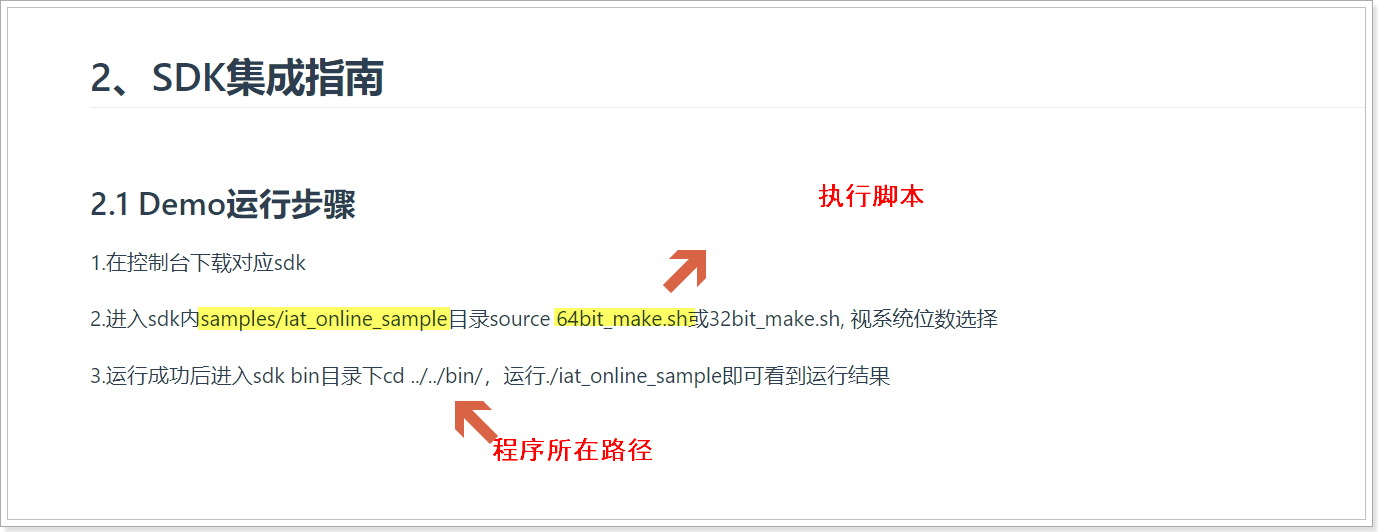
- 接口测试
测试科大讯飞的语音识别接口,需要提前在计算机的ubuntu中安装alsa库,否则会出现无法录音的情况,如果编译过程中出现缺少头文件的提示,则执行以下指令:
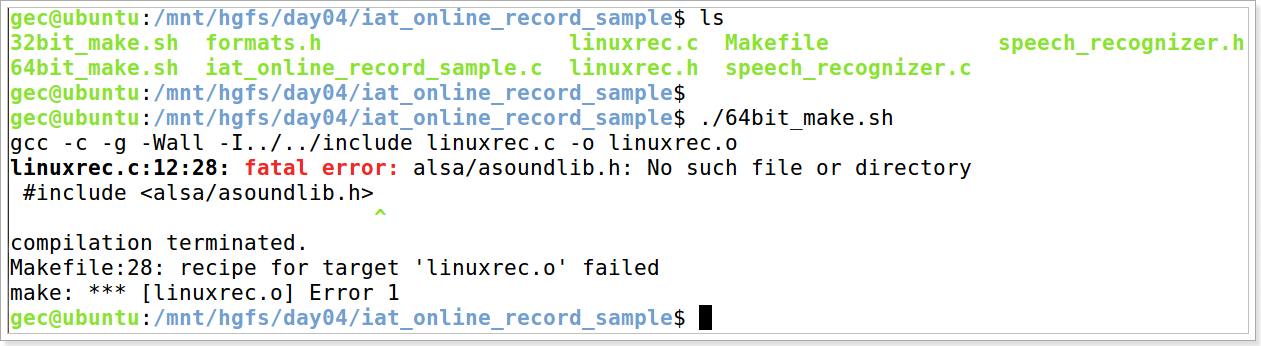
gec@ubuntu:~$ sudo apt-get install alsa-base alsa-utils libasound2-dev
另外,还需要确保Ubuntu系统已经安装过声卡驱动,如果没有则无法识别声音,安装如下:
- 点击VMware菜单栏“虚拟机”选项,然后点击“设置”--> 选择“硬件”,添加声卡:
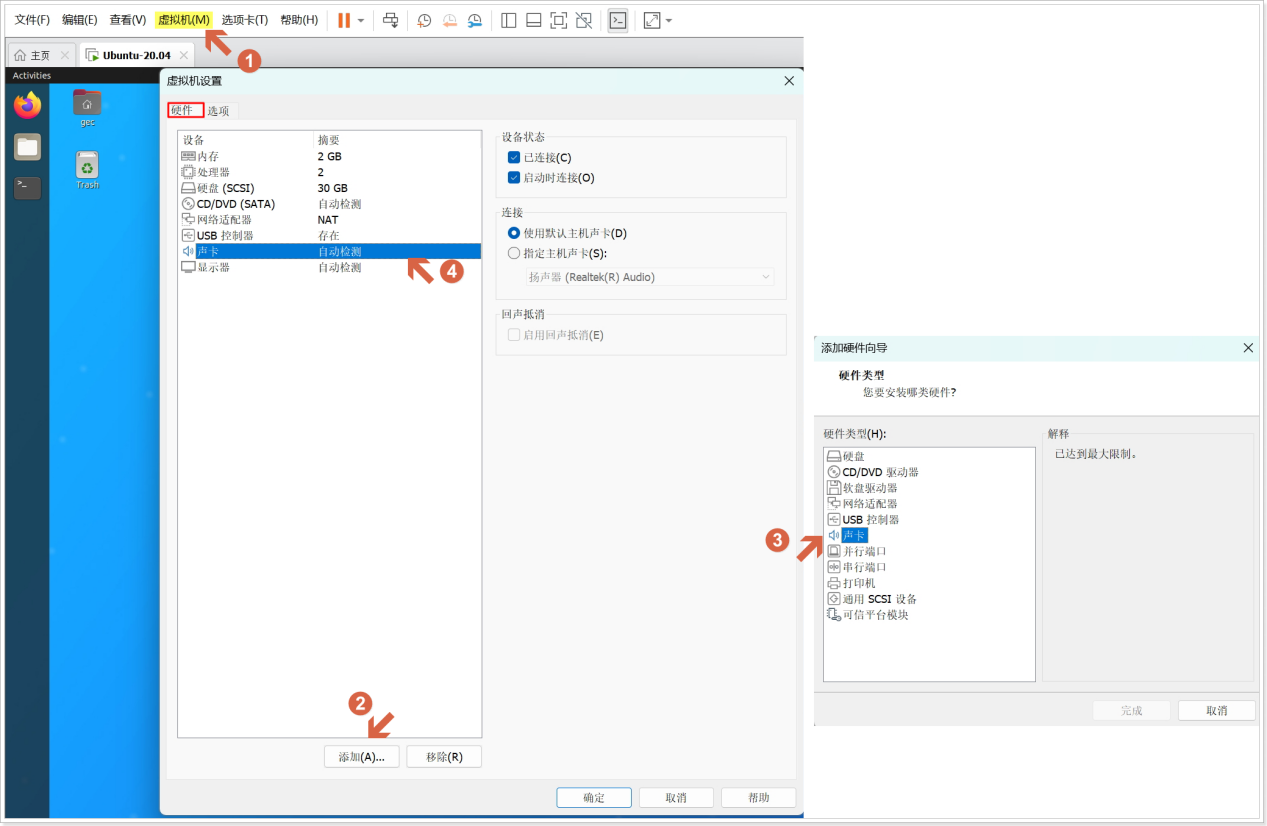
注意:建议大家把自己的虚拟机的声卡先移除,然后再添加新的声卡,避免运行程序时出问题。
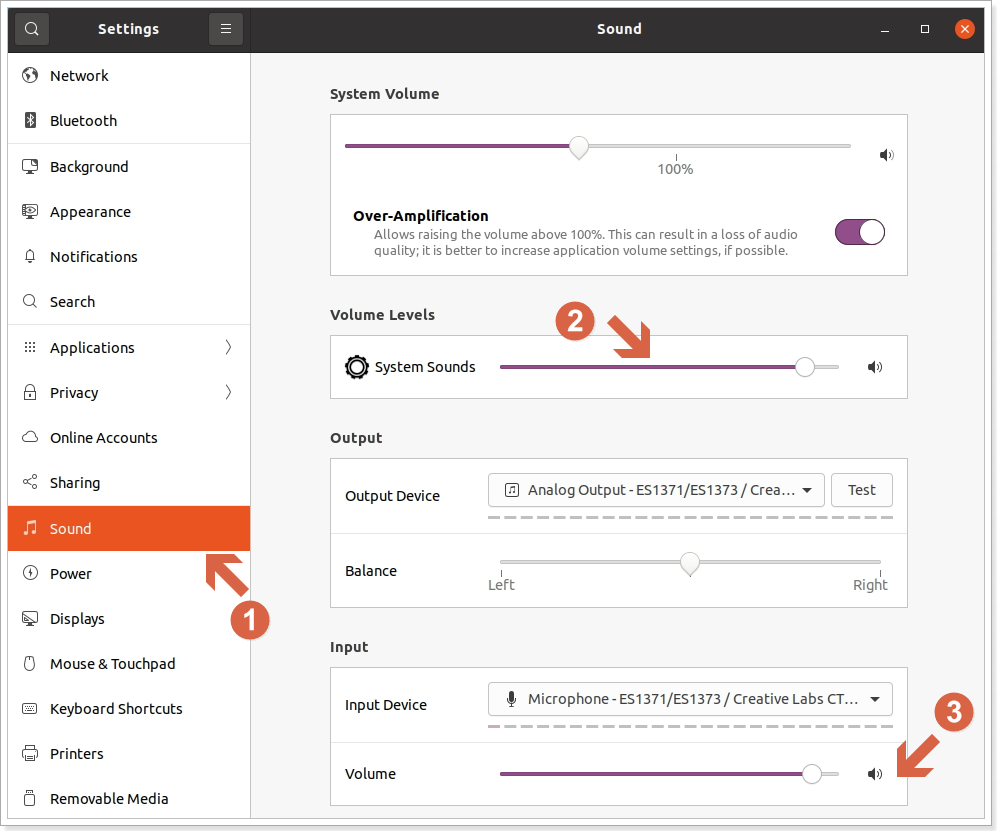
- 声卡添加完成后需要重启Linux系统,然后点击“Setting”--->选择“Sound”,如下图:
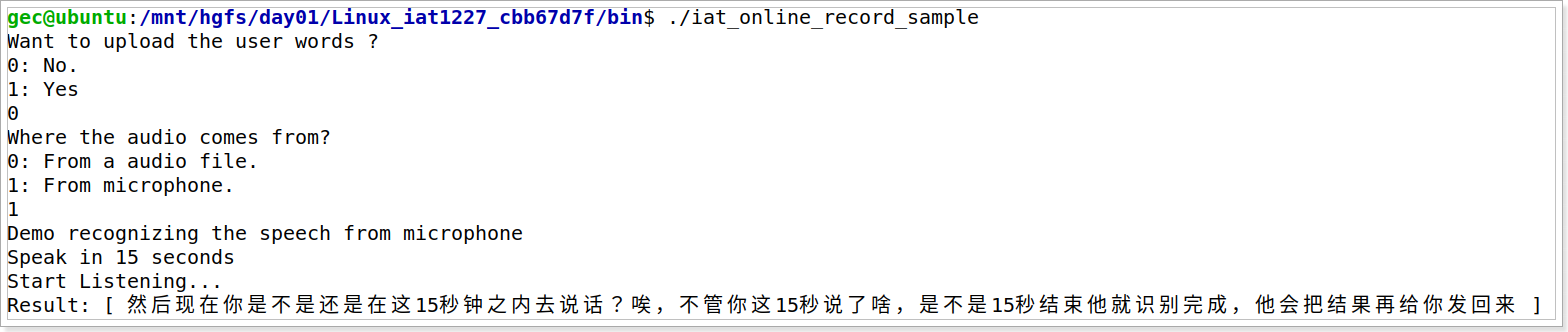
- 结果演示
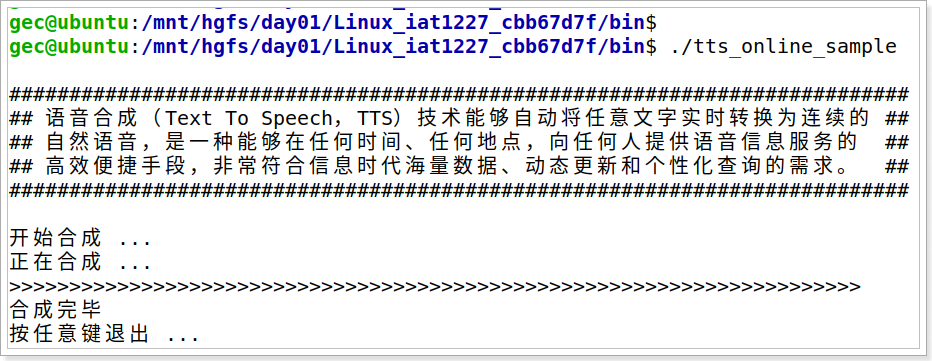
- 注意事项
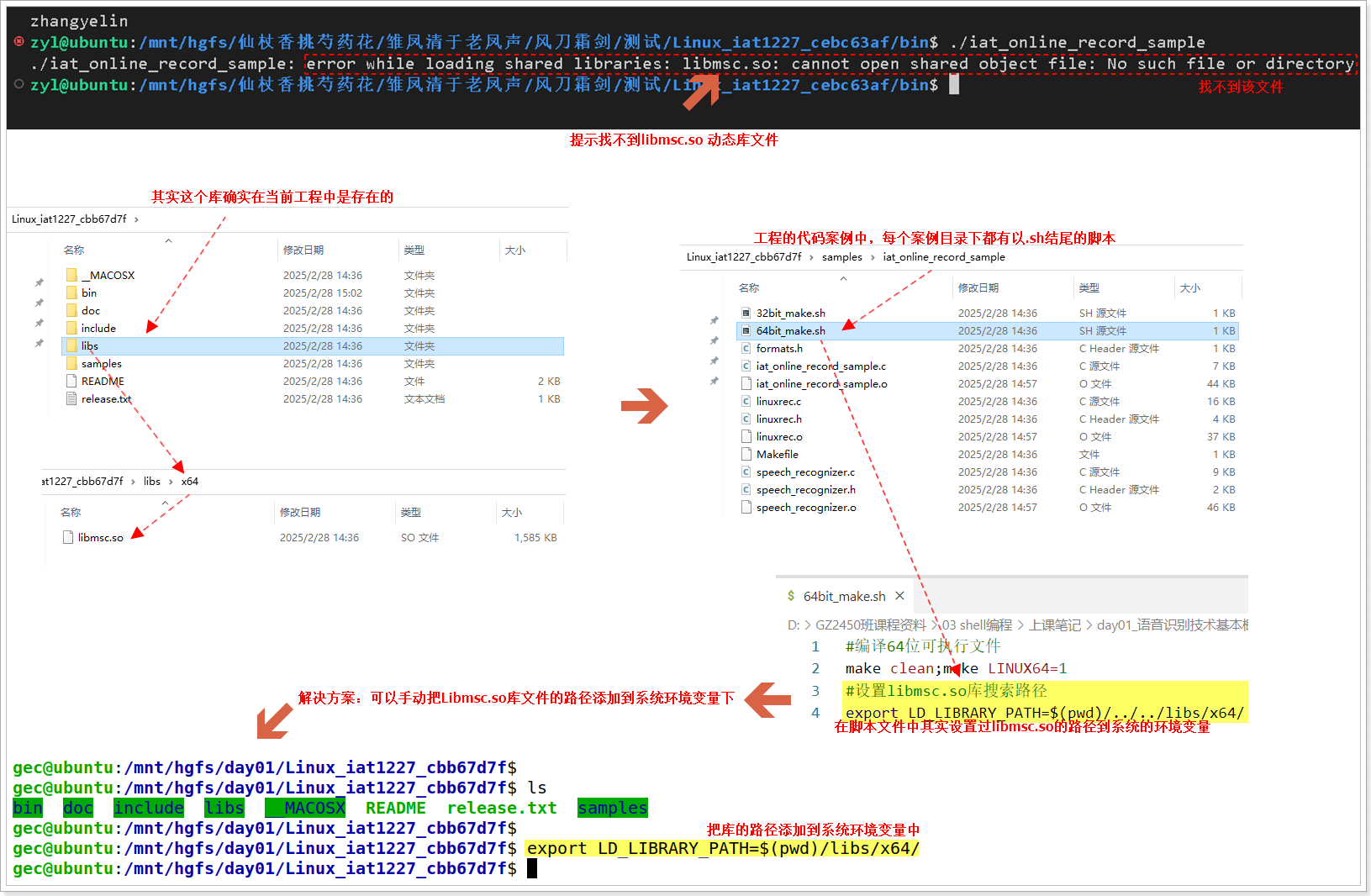
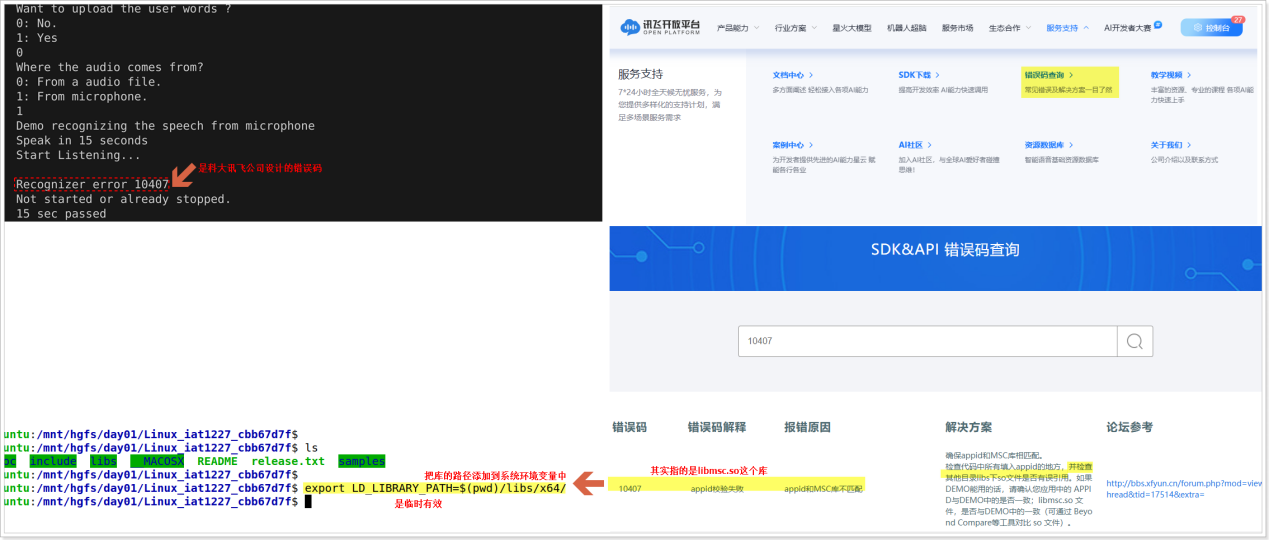
如果程序编译通过,在运行的时候提示找不到libmsc.so库文件,则可以把工程中的库文件的路径添加到系统环境变量即可,如下所示:
另外,如果在运行科大讯飞的SDK的时候出现报错,可以从科大讯飞的官网查找错误码,如下
练习:注册科大讯飞开放平台,创建语音识别应用,下载语音识别流式版SDK,移植到Linux系统,然后按照科大讯飞的SDK的运行方式来对SDK编译运行!!! 测试SDK中的几个案例。
- 源码分析
可以通过运行科大讯飞公司提供的SDK中的代码案例实现STT和TTS,如果想要了解实现机制,以及想要对代码案例进行二次开发,则需要阅读SDK提供的案例源码。
- 作业练习
基础作业:要求在科大讯飞的SDK的代码案例的基础上进行功能优化,要求可以把语音识别技术和AI大模型结合,用户通过麦克风进行提问,然后把识别到的结果进行JSON解析。
拓展作业:在基础作业的基础上,要求把用户提问的问题的结果转换为音频文件(TTS技术)。
提示:应该需要把2个案例进行整合(语音识别 + 语音转写),再配置多线程技术进行实现。
二、项目自动化构建原理与应用
- 基本概念
一般在实际项目开发中,项目都会进行模块化编程,把可以重复使用的函数接口、数据结构等封装为源文件和头文件,当项目的源码数量较大就会导致封装的源文件和头文件的数量较多,此时就大大提高了项目的编译难度。

为了提高项目的开发效率,所以GNU组织就在Linux系统中集成了Make工具,而Makefile文件就属于Make工具的一部分。Makefile是一个强大而灵活的工具,广泛应用于各种编程语言和项目中。通过定义目标、依赖和命令,Makefile可以自动化管理项目的构建过程,处理复杂的依赖关系,简化开发和部署工作。无论是编译大型C/C++项目,还是自动化生成文档和部署应用,Makefile都能提供极大的便利和效率提升。
Makefile可以理解为是一个脚本文件,用于管理项目的自动化构建过程,尤其在编译和链接复杂的源代码项目中非常有用。 Makefile文件的主要目的是简化和自动化项目的构建过程,包括编译源代码、链接生成可执行文件、清理中间文件等任务。
- 发展历史
Make工具最早由斯图尔特·费尔德曼(Stuart Feldman)在1977年开发,作为UNIX系统的一部分推出。费尔德曼的Make工具解决了当时构建大型软件项目的复杂性问题,通过自动化依赖管理和构建过程,显著提高了开发效率。
- 执行方式
一般用于编译项目的Makefile文件编写完成之后,需要执行该文件才可以完成项目的自动化构建,在Linux系统中,可以通过make指令完成Makefile文件的执行,make指令是一个命令工具,是一个解释Makefile文本的命令工具,也可以说它是一个工程管理器软件工具。
如果打算使用该指令则需要在Linux系统中安装该指令:sudo apt install make,如下:
安装完成之后,可以选择阅读man手册来了解make指令的使用规则和注意事项,如下所示:

可以看到,用户在编写makefile文件的时候,该文件的名称应该是makefile或者Makefile,建议大家使用Makefile作为该脚本文件的名称,注意:该文件是没有拓展名的!
注意:make是一个shell命令,用于执行makefile文件中的命令(gcc xxx.c -o xxx),前提是执行make指令的时候,当前路径下需要有makefile文件,如果没有makefile文件,则指令make指令时会报错。

简而言之,Makefile是一个类似配置文件的文本(必须命名为Makefile或者makefile),用于描述如何去编译项目中的源文件以及完成一些其他操作,而make是解释该配置文件的命令工具。

- 基本规则
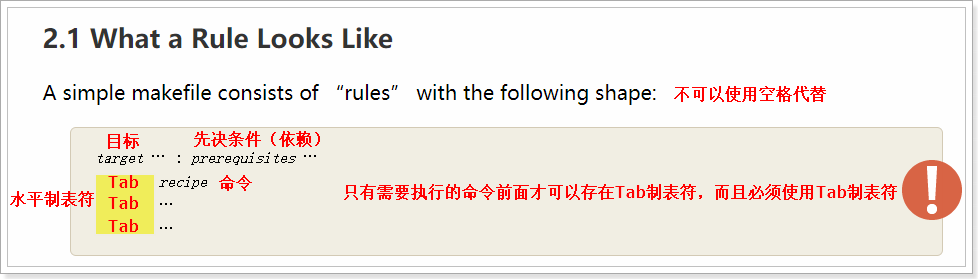
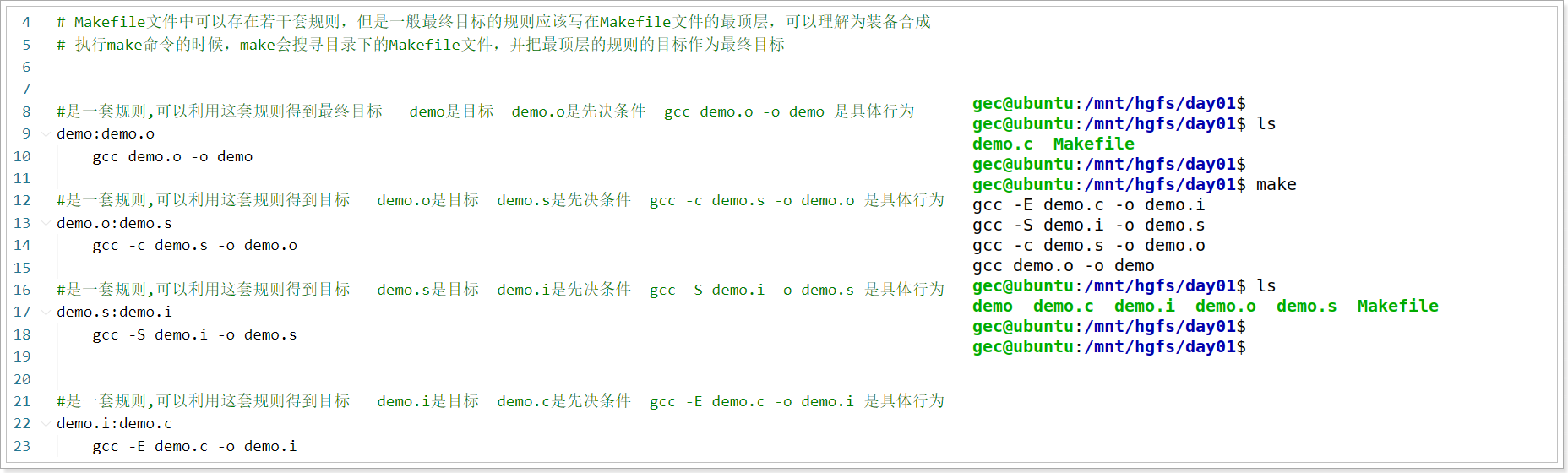
通过GNU组织提供的Make手册可以知道,Makefile文件的基本规则是有四部分组成,分别是目标、先决条件、制表符、命令,具体的规则如下所示:

注意:
- 即是制表符,即Tab键,不能用空格代替;也是因为这个制表符,make才知道后面是一个需要执行的shell命令。
- 目标(需要有)以及其后的依赖列表(可以没有),以及其下的shell命令(可以没有),统称为一套规则。
- 对于是编译代码的Makefile配置文件而言,如果依赖列表中有一个及以上的文件的时间戳比目标文件新,则执行编译源代码命令,否则不执行编译源代码命令。


目标:依赖文件
需要执行的命令
...
...
- 目标和伪目标

- 先决条件(依赖)

- 行为

- 演示案例
假设一个工程有四个源文件,分别为a.c、b.c、x.c和y.c,他们最终将会链接生成可执行文件image,如下图:
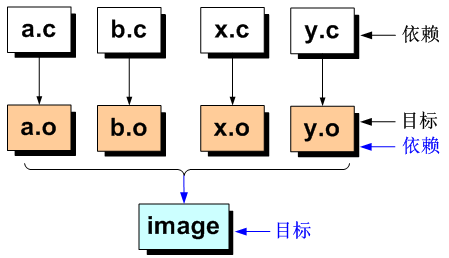
在开发的过程当中,如果修改了x.c源文件,就须重新生成x.o,再重新编译链接生成image文件,但是在由成千上万个源文件组成的庞大工程,比如Linux源码,一旦对若干个源文件进行了修改,则需要花费时间挑选出需重新编译的文件,否则就需要整体工程编译必将会浪费大量的时间;而这个挑选文件的任务可以交给make工程管理器,让make按照Makefile配置文件进行挑选所需文件进行编译处理。
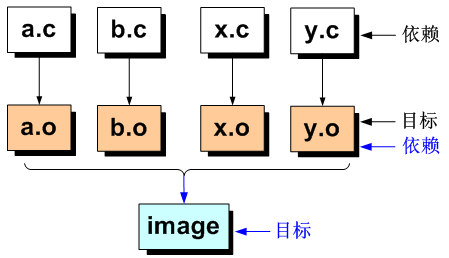
image:a.o b.o x.o y.o
gcc a.o b.o x.o y.o -o image
a.o:a.c
gcc a.c -o a.o -c
b.o:b.c
gcc b.c -o b.o -c
x.o:x.c
gcc x.c -o x.o -c
y.o:y.c
gcc y.c -o y.o -c
这个简单的Makefile文件总共有11行,具有5套规则,其中第1行中的image是第1个目标,冒号后面是这个目标的依赖列表(四个.o可重定位文件)。第2行的行首是一个制表符,后面紧跟着一句shell命令。
下面从第4行到第11行,也都是这样的“目标-依赖”,及其相关的Shell命令。但是这里必须注意一点:虽然这个Makefile总共出现了5个目标,但是第一个规则的目标(即image)被称之为终极目标,终极目标指的是当你执行make的时候,默认生成的那个可执行文件。
注意:如果第一个规则有多个目标,则只有第一个才是终极目标。另外,以圆点.开头的目标不在此讨论范围内,流程如下:
- 找到由终极目标构成的一套规则。(第1行和第2行)。
- 如果终极目标及其依赖列表都存在,则判断他们的时间戳关系,只要目标比任何一个依赖文件旧,就会执行其下面的Shell命令。(目标与执行命令中生成的可执行文件名要一致,否则无法对比依赖列表与目标的时间戳)
- 如果有任何一个依赖文件不存在,或者该依赖文件比该依赖文件的依赖文件要旧,则需要执行以该依赖文件为目标的规则的Shell命令。(比如a.o如果不存在或者比a.c要旧,则会找到a.o所在行的这一套规则,并执行其下一行的Shell命令)
- 如果依赖文件都存在并且都最新,但是目标不存在,则执行其下面的Shell命令。
- 变量说明
编写工程Makefile文件是为了简化编译流程的,但是目前编写的Makefile文件仍然不能满足该要求。
假设:在现有工程基础上再添加一个z.c源文件,要放在一起编译,对于上述的Makefile文件而言,可能需要重新修改一遍,另外,假设工程有1000个文件,貌似就要写1000套规则,这样是不现实的。其实Makefile提供了很多机制,比如变量、函数等来帮助我们更好更方便地组织工作(简化Makefile的编写)。
Makefile中有以下几种变量:
自定义变量
系统预定义变量
自动化变量
在Makefile中变量的特征有以下几点:
- 变量和函数的展开(除规则的命令行以外),是在make读取Makefile文件时进行的,这里的变量包括了使用“=”定义和使用指示符“define”定义的变量。
- 变量可以用来代表一个文件名列表、编译选项列表、程序运行的选项参数列表、搜索源文件的目录列表、编译输出的目录列表和所有我们能够想到的事物。
- 变量名不能包括“:”、“#”、“=”、前置空白和尾空白的任何字符串。需要注意的是,尽管在GNU make中没有对变量的命名有其它的限制,但定义一个包含除字母、数字和下划线以外的变量的做法也是不可取的,因为除字母、数字和下划线以外的其它字符可能会在以后的make版本中被赋予特殊含义,并且这样命名的变量对于一些Shell来说不能作为环境变量使用。
- 变量名是大小写敏感的。变量“foo”、“Foo”和“FOO”指的是三个不同的变量。Makefile传统做法是变量名是全采用大写的方式。推荐的做法是在对于内部定义的一般变量(例如:目标文件列表objects)使用小写方式,而对于一些参数列表(例如:编译选项CFLAGS)采用大写方式,这并不是要求的。但需要强调一点:对于一个工程,所有Makefile中的变量命名应保持一种风格,否则会显得你是一个蹩脚的开发者(就像代码的变量命名风格一样),随时有被鄙视的危险。
- 另外有一些变量名只包含了一个或者很少的几个特殊的字符(符号)。称它们为自动化变量。像“
- 变量的引用跟Shell脚本类似,使用美元符号和圆括号,比如有个变量叫A,那么对他的引用则是$(A),有个自动化变量叫@,则对他的引用是$(@),有个系统变量是CC则对其引用的格式是$(CC)。对于前面两个变量而言,他们都是单字符变量,因此对他们引用的括号可以省略,写成$A和$@。
- 自定义变量
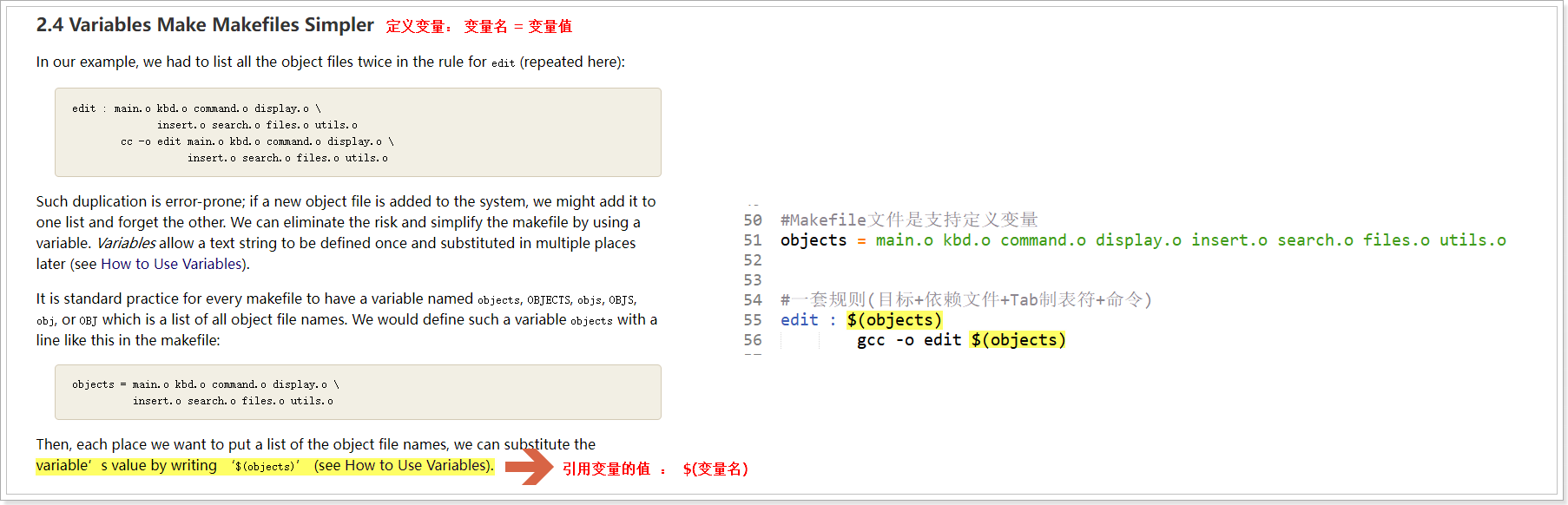

自定义变量,例如:
A = apple
B = I love China
C = $(A) tree
以上三个变量都是自定义变量,其中变量A包含了一个单词,变量B的值包含了三个单词,变量C的值引用了变量A的值,因此他的值是“apple tree”。如果要将这三个变量的值打印出来,可以这么写:既然是类似宏,所以在使用是需要添加特殊符号的: $( )
gec@ubuntu:~$ cat Makefile -n
1 A = apple
2 B = I love China
3 C = $(A) tree
4
5 all:
6 @echo $(A) //echo前面的@代表命令本身不打印出来
7 @echo $(B)
8 @echo $(C)
gec@ubuntu:~$ make
apple
I love China
apple tree
使用自定义变量,可以将前面的工程配置文件Makefile中的所有.o文件用一个变量OBJ来代表:
gec@ubuntu:~$ cat Makefile -n
1 OBJ = a.o b.o x.o y.o
2
3 image:$(OBJ)
4 gcc $(OBJ) -o image
5
6 a.o:a.c
7 gcc a.c -o a.o -c
8 b.o:b.c
9 gcc b.c -o b.o -c
10 x.o:x.c
11 gcc x.c -o x.o -c
12 y.o:y.c
13 gcc y.c -o y.o -c
14 clean:
15 rm $(OBJ)
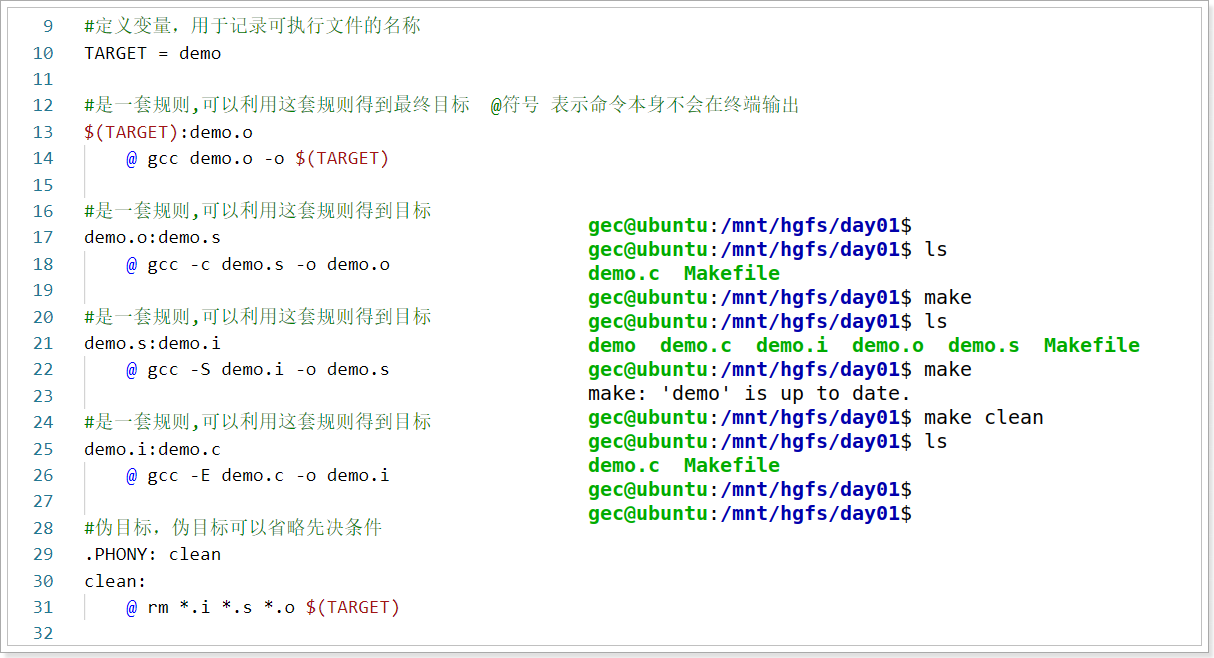
- 系统预定义变量
CFLAGS、CC、MAKE、Shell等等,这些变量已经有了系统预定义好的值,当然我们可以根据需要重新给他们赋值,例如CC的默认值是gcc,当我们需要使用gcc编译器的时候可以直接使用:
gec@ubuntu:~$ cat Makefile -n
1 OBJ = a.o b.o x.o y.o
2
3 image:$(OBJ)
4 $(CC) $(OBJ) -o image
5
6 a.o:a.c
7 $(CC) a.c -o a.o -c
8 b.o:b.c
9 $(CC) b.c -o b.o -c
10 x.o:x.c
11 $(CC) x.c -o x.o -c
12 y.o:y.c
13 $(CC) y.c -o y.o -c
14 clean:
15 rm $(OBJ)
这样做的好处是:在不同平台中,c编译器的名称也许会发生变化,如果我们的Makefile使用了100处c编译器的名字,那么换一个平台我们只需要重新给预定义变量CC赋值一次即可,而不需要修改100处不同的地方。比如我们换到ARM开发平台中,只需要重新给CC赋值为arm-linux-gcc即可。(用自定义变量覆盖系统预定义,实质是变量的值改变了,不再是原本的,而是一个新值)
gec@ubuntu:~$ cat Makefile -n
1 OBJ = a.o b.o x.o y.o
2 CC = arm-Linux-gcc #此处为自定义变量,覆盖系统预定义变量
3
4 image:$(OBJ)
5 $(CC) $(OBJ) -o image
6
7 a.o:a.c
8 $(CC) a.c -o a.o -c
9 b.o:b.c
10 $(CC) b.c -o b.o -c
11 x.o:x.c
12 $(CC) x.c -o x.o -c
13 y.o:y.c
14 $(CC) y.c -o y.o -c
15 clean:
16 rm $(OBJ)
注意:此时的CC就不再是gcc而是交叉工具链arm-Linux-gcc了。Makefile文件中注释使用#号。
常用的系统预定义变量,请看下表:
| 变量名 | 含义 | 备注 |
| AR | 函数库打包程序,可创建静态库.a文档。默认是“ar”。 | 无 |
| AS | 汇编程序。默认是“as”。 | 无 |
| CC | C编译程序。默认是“cc”。 | 无 |
| CXX | C++编译程序。默认是“g++”。 | 无 |
| CPP | C程序的预处理器。默认是“$(CC) –E”。 | 无 |
| RM | 删除命令。默认是“rm –f”。 | 无 |
| ARFLAGS | 执行AR命令的命令行参数。默认值是“rv”。 | 无 |
| ASFLAGS | 汇编器AS的命令行参数(明确指定“.s”或“.S”文件时)。 | 无 |
| CFLAGS | 执行CC编译器的命令行参数(编译.c源文件的选项)。 | 无 |
| CXXFLAGS | 执行g++编译器的命令行参数(编译.cc源文件的选项)。 | 无 |
- 自动化变量
也就是说自动化变量的值是可以改变的,不是固定的。例如@,不能说 @ 的值等于某个固定值,但是它的含义的固定的:@ 代表了其所在规则的目标的完整名称。
有关自动化变量的详细情况,见下表:
| 变量名 | 含义 | 备注 |
| @ | 代表其所在规则的目标的完整名称 | |
| % | 代表其所在规则的静态库文件的一个成员名 | |
| 代表其所在规则的依赖列表的第一个文件的完整名称 | ||
| ? | 代表所有时间戳比目标文件新的依赖文件列表,用空格隔开 | |
| ^ | 代表其所在规则的依赖列表 | 同一文件不可重复 |
| + | 代表其所在规则的依赖列表 | 同一文件可重复,主要用在程序链接时,库的交叉引用场合。 |
| * | 在模式规则和静态模式规则中,代表茎 | 茎是目标模式中“%”所代表的部分(当文件名中存在目录时,茎也包含目录(斜杠之前)部分。 |
上述列出的自动量变量中。其中有四个在规则中代表一个文件名(@、
使用自动化变量,可把之前的Makefile文件修改如下:
gec@ubuntu:~$ cat Makefile -n
1 OBJ = a.o b.o x.o y.o
2
3 image:$(OBJ)
4 $(CC) $^ -o $(@)
5
6 a.o:a.c
7 $(CC) $^ -o $(@)-c
8 b.o:b.c
9 $(CC) $^ -o $(@) -c
10 x.o:x.c
11 $(CC) $^ -o $(@) -c
12 y.o:y.c
13 $(CC) $^ -o $(@) -c
14 clean:
15 rm $(OBJ)
其中在GUN make中,还可以通过以上这七个自动化变量来获取一个完整文件名中的目录部分或者具体文件名,需要在这些变量中加入“D”或者“F”字符。这样就形成了一系列变种的自动化变量:
| 变量名 | 含义 | 备注 |
| @D | 代表目标文件的目录部分(去掉目录部分的最后一个斜杠) | 如果“$@”是“dir/foo.o”,那么“$(@D)”的值为“dir”。如果“$@”不存在斜杠,其值就是“.”(当前目录)。注意它和函数“dir”的区别 |
| @F | 目标文件的完整文件名中除目录以外的部分(实际文件名) | 如果“$@”为“dir/foo.o”,那么“$(@F)”只就是“foo.o”。“$(@F)”等价于函数“$(notdir $@)” |
| *D | 代表目标茎中的目录部分 | |
| *F | 代表目标茎中的文件名部分 | |
| %D | 当以如“archive(member)”形式静态库为目标时,表示库文件成员“member”名中的目录部分 | 仅对“archive(member)”形式的规则目标有效 |
| %F | 当以如“archive(member)”形式静态库为目标时,表示库文件成员“member”名中的文件名部分 | 仅对“archive(member)”形式的规则目标有效 |
| 代表规则中第一个依赖文件的目录部分 | ||
| 代表规则中第一个依赖文件的文件名部分 | ||
| ^D | 代表所有依赖文件的目录部分 | 同一文件不可重复 |
| ^F | 代表所有依赖文件的文件名部分 | 同一文件不可重复 |
| +D | 代表所有依赖文件的目录部分 | 同一文件可重复 |
| +F | 代表所有依赖文件的文件名部分 | 同一文件可重复 |
| ?D | 代表被更新的依赖文件的目录部分。 | |
| ?F | 代表被更新的依赖文件的文件名部分。 |
- 静态规则
所谓的静态规则,其工作原理是:$(OBJ)被称为原始列表,即(a.o b.o x.o y.o),紧跟在其后的%.o被称为匹配模式,含义是在原始列表中按照这种指定的模式挑选出能匹配得上的单词(在本例中要找出原始列表里所有以.o为后缀的文件)作为规则的目标。如下所示:
gec@ubuntu:~$ cat Makefile -n
1 OBJ = a.o b.o c.o
2
3 image:$(OBJ)
4 $(CC) $(OBJ) -o image
5
6 $(OBJ):%.o:%.c
7 $(CC) $(^) -o $(@) l -c
8
9 clean:
10 $(RM) $(OBJ) image
11
12 .PHONY: clean
静态规则工作原理整个过程用下图演示:
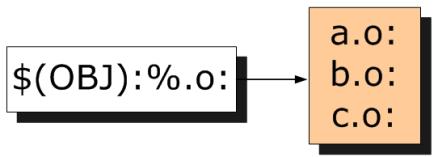
简单地讲,就是用一个规则来生成一系列的目标文件。接着,第二个冒号后面的内容就是目标对应的依赖,%可以理解为通配符,因此本例中%.o:%.c的意思就是:每一个匹配出来的目标所对应的依赖文件是同名的.c文件,这个过程也用图演示如下:
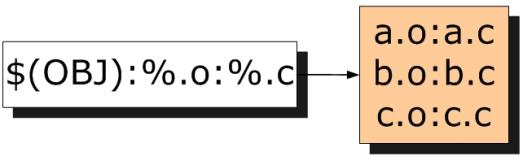
可见,静态规则的目的就是用一句话来自动生成很多目标及其依赖,接下来要针对每一对目标-依赖生成对应的编译语句:

此处可见自动化变量的用武之地了,因为每一对目标-依赖对的名字都不一样,因此在静态规则中不可能直接把名字写死,而要用自动化变量来自动调整为对应的名字。
总结一下,静态规则是:当规则存在多个目标时,不同的目标可以根据目标文件的名字来自动构造出依赖文件(即只需写出目标名,即可寻找相应同名字的依赖文件)。
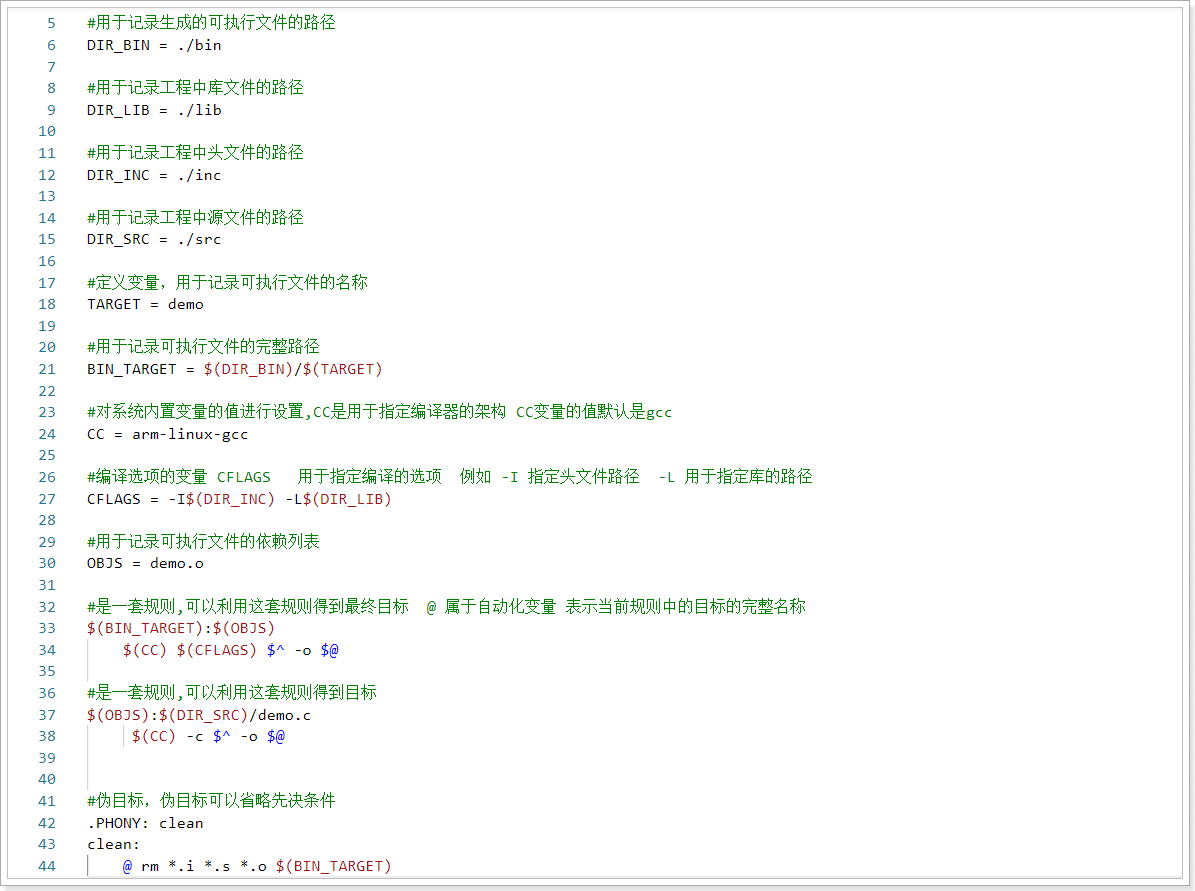
作业:阅读科大讯飞提供的SDK的代码案例中的Makefile文件,把每一句都进行完整的注释,理解每一句的作用。

作业:请对Makefile中的 := ?= +=的区别进行分析,并整理成文本,要求大家背下来!!


作业:了解cmake工具的使用规则,拓展:在linux系统下安装cmake,并尝试使用cmake构建项目中的Makefile。