软考知识点汇总
一、计算机基础知识
CPU
1、运算器:数据处理(算数逻辑单元(ALU)累加寄存器(AC)数据缓冲寄存器(DR)状态条件寄存器(PSW))
2、控制器:程序控制,操作控制,时间控制(指令寄存器(IR)程序计数器(PC)地址寄存器(AR)指令译码器(ID))
- 程序计数器(PC):存储下一条指令的地址
- 指令寄存器(IR):用于存放当前从主存储器读出的正在执行的一条指令
- 地址寄存器(AR):用来保存当前CPU所访问的内存单元的地址
- 指令译码器(ID):从内存中取出的一条指令经过数据总线送往指令寄存器中
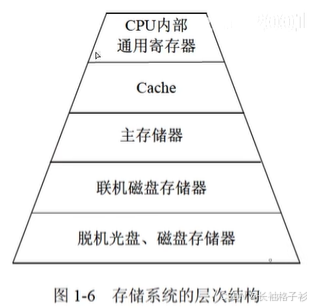
3、存储器
4、输入设备
5、输出设备
计算机的基本单位
位 bit
字节 Byte ========= 1B = 8b
千字节 KB ========= 1KB = 1024B
兆字节 MB ========= 1MB = 1024KB
吉字节 GB ========= 1GB = 1024MB
太字节 TB ========= 1TB = 1024GB
进制及转换
十进制、二进制(B)、八进制(O)、十六进制(H)
二进制转换为十进制、八进制、十六进制

原码、反码、补码、移码的计算
移码的正负0( 1000 0000)和补码的正负0( 0000 0000)表示一致, 补码的补码 = 原码
原码 反码 补码 移码 正数 正常表示的都是原码 与原码一样 与原码一样 补码的符号位变为1 负数 最高位为1的原码 除了符号位,其他位取反 反码+1 补码的符号位变为0 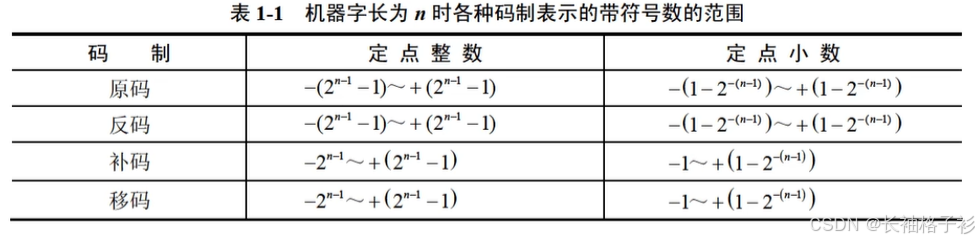
浮点数
一个二进制可以表示为:
最大的正数以及最小负数
计算方式:
对阶:小阶对大阶对齐
浮点数:尾数向右移
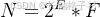

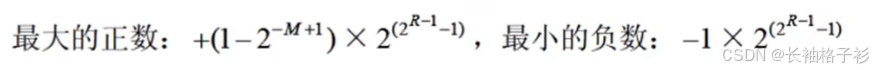
寻址
- 立即寻址:操作数包含在指令当中(速度1)
- 直接寻址:操作数存放在内存单元中,指令中直接给出操作数所在的存储单元的地址(速度3)
- 寄存器寻址:操作数存放在某一个存储器中,指令中给出存放操作数的寄存器名(速度2)
- 寄存器间接寻址:操作数存放在内存单元中,操作数所在的存储单元的地址在某个寄存器中
- 间接寻址:指令中给出操作数地址(速度4)
- 相对寻址:指令地址码给出的是一个偏移量(可正可负),操作数地址等于本条指令的地址加上偏移量
- 变址寻址:操作数地址等于变址寄存器的内容加偏移量
总线
scsi:不是系统总线
串行总线适用于长距离数据传输
并行总线适合近距离高速传输S
专用总线结构在设计上可以与连接设备实现最佳匹配
加密技术与认证技术
报文摘要:确保信息的完整性。判断信息是否被篡改
数字签名:验证信息的来源与完整性。保证了信息的完整性、认证和不可否认性
数字证书:保证信息的真实性。
对称加密与非对称加密
对称密钥(私钥、私有密钥加密)算法:
(共享密钥加密算法)
- DES
- 3DES
- RC-5
- IDEA
- AES
- RC4
非对称加密(公钥、公开密钥加密)算法:
- RSA
- ECC
- DSA
- Hash函数
- MD5摘要算法
- SHA-1安全散列算法
可靠性公式
串联:
R = R1R2···RN
并联:
R = 1 - (1 - R1)(1 - R2)···(1 - RN)
二、程序设计语言
编译程序和解释程序
解释器:翻译源程序时不生成独立的目标程序
解释程序和源程序要参与到程序的运行过程中
编译器:翻译时将程序翻译成独立的目标程序
机器上运行的是源程序等价的目标程序
源程序和编译程序都不参与目标程序的运行过程
编程语言
Lisp:函数式编程语言
Prolog、C:命令式系统内函数式
Java、C++、Python:面向对象
Python:脚本语言
脚本语言:
- 脚本语言采用解释的方式实现
- 简单、易学、易用的特点
编译型语言:
- 编译型语言执行效率更高
标记语言:
- 标记语言常用于描述格式化和链接
函数
函数定义分为两个部分:函数首部和函数体
函数的一般形式为:
返回值类型 函数名(形式参数表)
{
函数体;
}
- 值调用:若是实现函数时将实参的值传递给相应的形参,则称为是传值调用。这种情况下形参不能向实参传递信息,实参可以是变量、常量和表达式
- 引用调用:当形式参数为引用类型时,形参名实际上是实参的别名,函数中对形参的访问和修改实际上就是针对相应的实参所做的访问和改变,引用调用的实参必须有地址,不能是常量、表达式
杂题记忆
程序中常用的三种结构:顺序、选择、循环(重复)
程序中数据都必须具有类型,作用:
- 便于合理分配内存单元
- 便于对参与表达式计算的数据对象进行检查
- 便于规定数据对象的取值范围及能够进行运算
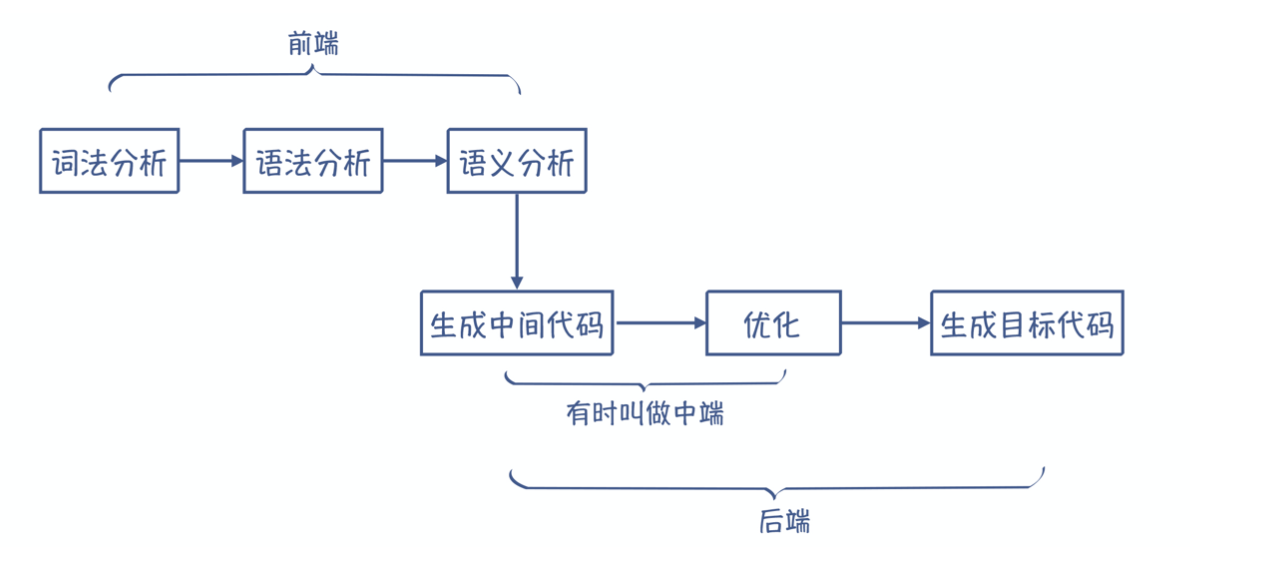
编译、解释翻译阶段
编译方式:词法分析、语法分析、语义分析、中间代码生成、代码优化、目标代码生成
解释方式:词法分析、语法分析、语义分析
编译器和解释器都不可以省略词法分析、语法分析、语义分析,并且顺序是固定的
这三个步骤是必须的
编译器方式,中间代码生成和代码优化不是必要的
符号表
符号表:
不断收集、记录和使用源程序中一些相关符号的类型和特征等信息,并将其存入符号表中。
记录源程序中各个字符的必要信息,以辅助语义的正确性检查和代码生成。
高级语言进行编译的六个过程:
1、词法分析
此阶段的任务是从左到右一个字符一个字符地读入源程序,对构成源程序的字符进行扫描和分解,从而识别出一个个单词(逻辑上紧密相连的一组有集体含义的字符)。
输入:源程序
输出:记号流
词法分析阶段的主要作用是分析构成程序的字符及由字符按照构造规则构成的符号是否符合程序语言的规定
2、语法分析
此阶段的任务是在词法分析的基础上将单词序列分解成各类语法短语(也称语法单位)可表示成语法树。
注:词法分析和语法分析本质上都是对源程序的结构进行分析。
输入:记号流
输出:语法树(分析树)
语法分析阶段的主要作用是对各条语句的结构进行合法性分析
分析程序中的句子结构是否正确
3、语义分析
语义分析是审查源程序有无语义错误,为代码生成阶段收集类型信息。
只能发现静态语义错误,不能发现动态语义错误
输入:分析树
语义分析阶段的主要作用是进行类型分析和检查
4、中间代码生成
“中间代码”是一种结构简单,含义明确的记号系统,这种记号系统可以设计为多种多样的形式,重要的设计原则为两点:
一是容易生成
二是容易将它翻译成目标代码。很多编译程序采用了一种近似“三地址指令”的“四元式”中间代码。这种四元式的形式为:(运算符,运算对象1,运算对象2,结果)
常见的中间代码有:后缀式、三地址码、三元式、四元式和树(图)等形式
中间代码与机器无关,可以将不同的高级语言翻译成同一种中间代码,中间代码可以跨平台
有利于进行与机器无关的优化处理,提高编译程序的可移植性
5、代码优化
将中间代码进行变换或进行改造,目的:使生成的目标代码更为高效,即省时间和空间
6、目标代码生成
任务是把中间代码变换成特定机器上的绝对指令代码或可重定位的指令代码或汇编指令代码。
寄存器的分配工作处于目标代码生成阶段
中间代码生成和代码优化是不一定需要的
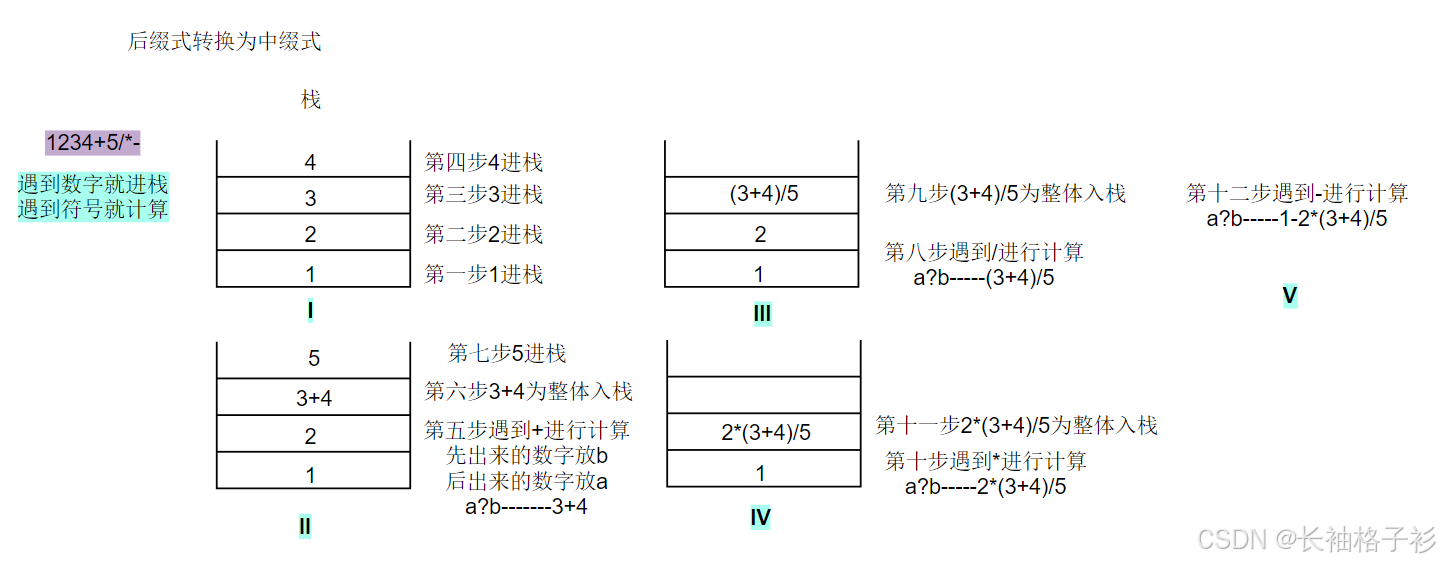
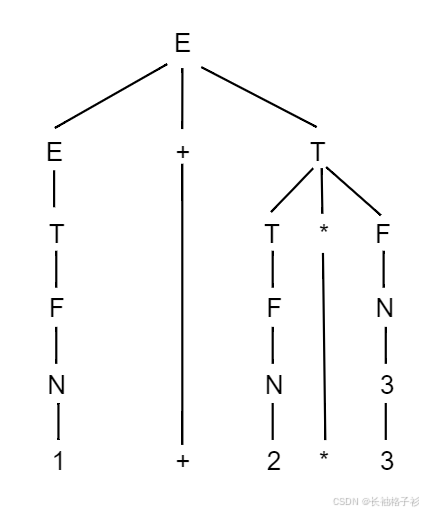
中缀式转换为后缀式
优先级相同:从右往左
中缀式:1+2,1-2,1*2
上面对应下面的后缀式为:12+,12-,12*
- 案例:
- 中缀式:1-2 * (3+4) / 5
- 转换后缀式的步骤为:1234+5/*-
- 首先计算括号里面看作是 a+b 转换为后缀式为 ab+
- 放入到表达式中,此刻为:1-2 * 34+ / 5
- * 和 / 两个优先级相同,从右往左进行转换
- 此刻把 34+ 看做为一个整体
- 34+ / 5转换为后缀式:34+5/
- 放入到表达式中,此刻为:1-2*34+5/
- + 和 *,* 的优先级更高
- 此刻把 34+5/ 看做为一个整体
- 2 * 34+ / 5转换为后缀式为:234+/5 *
- 放入到表达式中,此刻为:1-234+5/*
- 此刻把 234+5/* 看做为一个整体
- 1-234+5/* 转换为后缀式为:1234+5/*-

后缀式转换为中缀式
- 利用栈的先进后出原则进行转换
- 遇到数字就进栈,遇到符号计算(计算之后记得入栈)
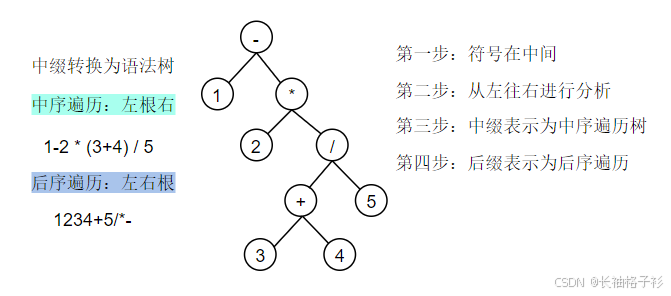
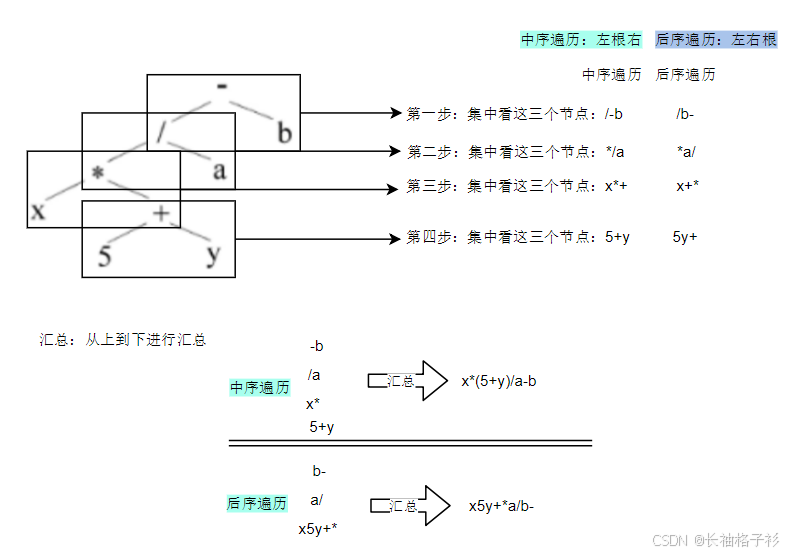
语法树-----中缀和后缀推导
逆波兰式:后缀式
中序遍历:左根右
后序遍历:左右根
优先级:大于、小于、等于 > 逻辑与 > 逻辑或
正规式
正规式是词法分析中的重要工具
- 方法一:利用赋值,给*赋值0或者1去推导答案
- 方法二:利用选项结合方法一推导答案
- 根据题意去推导答案
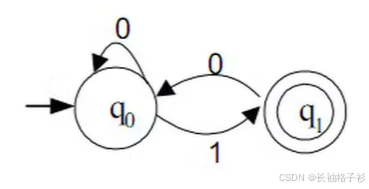
有限自动机
- 有限自动机是词法分析的一个工具,它能正确地识别正规集
- 确定的有限自动机(DFA):对每一个状态来说识别字符后转移的状态是唯一的
- 不确定的有限自动机(NFA):对每一个状态来说识别字符后转移的状态不确定的
- 有一个圈的并且有一个空箭头的为初态:q0
- 有两个圈的为终态:q1
- 注意:初态也可以是终态
- ε表示的是空,也就是不识别
- 识别字符串停留在终态就识别成功,反之就失败
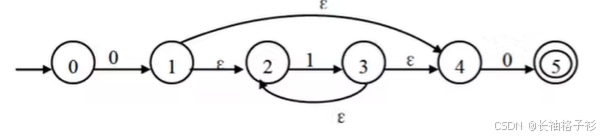
上下文无关文法
- E为开始符号
- 如上图所示,进行相应的替换得到想要的表达式
- 产生式:例如:E - >E+T,可以产生这个式子
- 大多数程序设计语言的语法则用上下文无关文法描述即可

其他知识点
源程序编译得到目标程序之后,不能反编译得到源程序
脚本语言:
- 动态语言
- 解释型语言
- 不产生目标程序
- 成分不可以在编译的时候确定
- php,Python,js
标记语言:
- HTML
- XML
- WML
三、算法和数据结构
大O表示法
时间复杂度:
- 加法规则:多项相加,保留最高阶项,并将系数化为1
- 乘法规则:多项相乘都保留,并将系数化为1
- 加法乘法混合规则:小括号再乘法规则最后加法规则
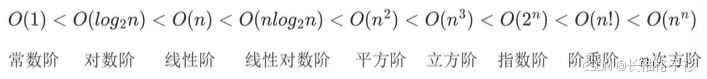
- 常数阶:
/*时间复杂度为:O(1) */ int a = 2022; int b = 528; int t = a; a = b; b = t;
- 对数阶:
/*时间复杂度:O(logn) */ int i = 1; while(i <= n){i = i * 2; }
- 线性阶:
/*时间复杂度:O(n) */ int x = 1; for(int i = 1;i <= n; i++){x++; }
- 线性对数阶:
/*时间复杂度:O(nlogn)嵌套的计算方式:线性阶*对数阶 */for(int i = 1;i <= n; i++){int x = 1;while(x <= n){x = x * 2;} }
- 平方阶:
/*时间复杂度:O(n²)计算方法:线性阶*线性阶 */ int x = 1; for(int i = 1;i <= n; i++){for(int j = 1;j <= n; j++){x++;} }
空间复杂度:
如果算法执行所需要的临时空间不随着某个变量n的大小而变化,即此算法空间复杂度为一个常量,可表示为 O(1)
举例:int i = 1; int j = 2; ++i; j++; int m = i + j;代码中的 i、j、m 所分配的空间都不随着处理数据量变化,因此它的空间复杂度 S(n) = O(1)
空间复杂度O(n)
int[] m = new int[n] for(i=1; i<=n; ++i) {j = i;j++; }如果定义的是二维数组(矩阵),那么空间复杂度为:O(n²)

渐进符号
O记号:渐进上界,大于等于上界
Ω记号:渐进下界,小于等于下界
Θ记号:渐进紧致界,相当于上界和下界逻辑与计算

递归式主方法
题目方法:
- 确定所知道的T(n)属于哪一种条件
- 根据条件计算出O(n)
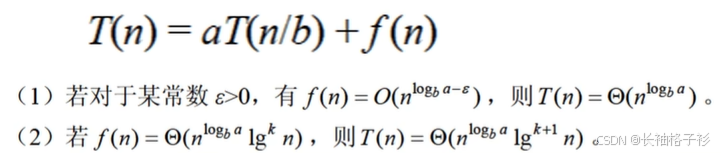
线性结构
线性表:
- 存在唯一的一个称作为“第一个”的元素
- 存在唯一的一个称作为“最后一个”的元素
- 除第一个元素外,序列种的每一个元素均只有一个直接前驱
- 除最后一个元素外,序列中的每一个元素均只有一个直接后继
线性表的顺序存储:
- 优点:随机存取表中的元素
- 缺点:插入和删除都需要移动元素
线性表的插入:
- 需要移动元素的个数:n / 2
- 时间复杂度
- 最好:插入到最后一个位置,不需要移动,时间复杂度为:O(1)
- 最坏:插入到第一个位置,所有元素都需要移动,时间复杂度为:O(n)
- 平均:插入到中间的位置,时间复杂度为:O(n)
线性表的删除:
- 需要移动元素的个数:(n-1)/ 2
- 时间复杂度:O(n)
线性表的元素获取:
- 时间复杂度为:O(1)
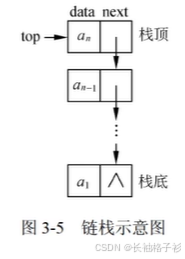
线性表的链式存储
线性表的链式存储:是用通过指针链起来的节点来存储数据,结构如下
数据域:存储数据元素的值
指针域:存储当前元素的直接后继
只有一个指针域,称为线性链表(或单链表)
数据结构的时间复杂度 数据结构 查找 插入 删除 数组(顺序表)
O(N) O(1) O(N) 线性表 O(N) O(N) O(N) 单链表 O(N) O(1) O(N) 循环单链表 O(N) O(N) O(N) 双链表:
- 头结点的前驱指向空
- 前指针指向前驱

栈
先进后出或者后进先出
入栈和出栈都是O(1),遍历是O(n)
栈的基本运算:
- 初始化栈InitStack(S):创建一个空栈S。
- 判断栈空isEmpty(S):当S为空时返回“真”,否则返回“假”。
- 入栈Push(S,x):将元素x加入栈顶,并且更新栈顶指针。
- 出栈Pop(S):将栈顶元素从栈中删除,并且更新栈顶指针。若是需要得到栈顶元素的值,可以将Pop(S)定义为一个返回栈顶元素值的函数。
- 读栈顶元素Top(S):返回栈顶元素的值,但是不修改栈顶指针。
栈的链式存储:
队列
先进先出
队列的基本运算:
- 初始化队列InitQueue(Q):创建一个空队列
- 判断队列为空isEmpty(Q):当队列为空时返回“真”,否则返回“假”
- 入队EnQueue(Q,x):将元素x加入到队列Q的队尾,并更新队尾指针
- 出队DelQueue(Q):将队头元素从队列Q中删除,并且更新队头指针
- 读取队头元素FrontQue(Q):返回队头元素的值,但是不更新队头指针
队列的链式存储与双端队列
队列的链式存储:
- 判断为空:队头=队尾
- 添加数据:对头不变,
双端队列:两端都可以进行入队和出队
串
空串:长度为零的串称为空串,空串不包含任何字符
空格串:由一个或多个空格组成的串
子串:由任意长度的连续字符构成的序列称为子串
串的模式匹配:
- 最好:O(m)
- 最坏:O(n*m) (n-m+1)m
- 平均:O(n+m)
KMP算法
next算法和nextval算法计算
next的进阶版nextval
j值 1 2 3 4 5 6 7 8
模式串 a b a a b c a c
next值 0 1 1 2 2 3 1 2
nextval值 0 1 0 2 1 3 0 2
计算next的值方法
- 第1个是0,第二个是1
- max{n个前缀 = n个后缀} 写n+1
- 前缀 ≠ 后缀 写1(前缀就是包含第一个字母的,从第一个字母开始;后缀就是包含最后一个字母的,从最后一个字母开始,但是写的顺序是原来串的顺序)
- 案例:
- 串:abcd
- 前缀:a,ab,abc
- 后缀:d,cd,bcd
例如:
j值: 1 2 3 4 5 6 7
模式串:a b c a a b b
next值:0 1
第一位和第二位是定下来的
第三位:
前缀:a
后缀:b
前缀 ≠ 后缀 则填 1
第四位:
前缀:a,ab
后缀:c,bc
前缀 ≠ 后缀 则填 1
第五位:
前缀:a,ab,abc
后缀:a,ca,bca
只有一个长度的相等,所以填:长度+1 = 2
第六位:
前缀:a,ab,abc,abca
后缀:a,aa,caa,bcaa
只有一个长度的相等,所以填:长度+1 = 2
第七位:
前缀:a,ab,abc,abca,abcaa
后缀:b,ab,aab,caab,bcaab
只有一个长度的相等,所以填:长度+1 = 3
计算nextval的值方法
- 第1位写0
- 第2位若是与第1位相同则为0,不同为1
- 从第3位开始,根据next指路
- 相同则 = 别人nextval值
- 不同则 = 当前的next值
- 案例:
j值 1 2 3 4 5 6 7 8
模式串 a b a a b c a c
next值 0 1 1 2 2 3 1 2
nextval值 0 1 1 2 1 3 0 2
第一位是定下来的为 0
第二位若是与第一位相同则为0,不同为1,则为 1
第三位位置上的 a 串,下面的next的值指向的位置(例如next为1,则指向1号位置上的串),不同则 = 当前的next值,则为 1
第四位位置上的 a 串,下面的next的值指向的位置(例如next为2,则指向2号位置上的串),不同则 = 当前的next值,则为 2
第五位位置上的 b 串,下面的next的值指向的位置(例如next为2,则指向2号位置上的串),相同则 = 别人nextval值,则为 1
第六位位置上的 c 串,下面的next的值指向的位置(例如next为3,则指向2号位置上的串),不同则 = 当前的next值,则为 3
第七位位置上的 a 串,下面的next的值指向的位置(例如next为1,则指向2号位置上的串),相同则 = 别人nextval值,则为 0
第八位位置上的 c 串,下面的next的值指向的位置(例如next为2,则指向2号位置上的串),不同则 = 当前的next值,则为 2
数组
对称矩阵:
- 二维数组下标从0开始
- 当 i ≥ j 时:A(ij) = i ( i+1 )/2 + j + 1
- 当 i ≤ j 时:把 i 换成 j 即可
- 二维数组下标从1开始
- 当 i ≥ j 时:把 i 换成 i - 1
- 当 i ≤ j 时:把 j 换成 j - 1
三角矩阵:
- 二维数组下标从0开始
- 公式:2i + j + 1
- 二维数组下标从1开始
- 把 i 换成 i - 1,把 j 换成 j - 1
稀疏矩阵:三元组的顺序存储结构称为三元组顺序表
常用的三元组表的链式存储结构是十字链表

树
树:是n(n≥0)个结点的有限集合,当n=0时称为空树
度:子节点的个数
深度:树的高度(层数)
树的度:一棵树最大的度(子节点最多的)
性质:
- 树中的结点总数等于树中所有结点的度数之和加1
- 度为m的树中第 i 层上至多有
个结点(i ≥ 1)
- 高度为h的m次树至多有
个结点
- 具有n个结点、度为m的树的最小高度为
二叉树:
- 根节点左边的是左子树
- 根节点右边的是右子树
- 性质:
- 性质1:二叉树第 i 层(i ≥ 1)上最多有
个结点
- 性质2:高度为h的二叉树,最多有
个结点
- 性质3:对于任何一颗二叉树,度为0的结点数等于度为2的结点数+1
- 性质4:具有n个结点的完全二叉树的高度为
下取整或
上取整
- 满二叉树:每一个结点都是满的
- 完全二叉树:除了最后一层其他层都是满的,必须是从左到右,不能间隔
- 平衡二叉树:对于一个结点来说,左右子树的高度差不超过1
- 二叉排序树(二叉查找树、二叉检索树):(左 < 根 < 右)
- 根节点的关键字
- 大于左子树所有结点的关键字
- 小于右子树所有结点的关键字
- 左右子树也是一颗二叉排序树
- 中序遍历得到的序列是有序序列
- 案例:
- 23 31 17 19 11 27 13 90 61
- 第一个为根节点
- 比根节点大就往左走,比根节点小就往右走
- 构造哈夫曼树(最优二叉树):
- 两个最小结点构成一个树,构成一个新的结点,权值=两个结点之和
- 构造成功之后,把新的结点权值加入新的结点集合里,加入后面
- 从前往后
- 左边比右边小
- 步骤:
- 从前往后找两个权值最小的
- 小左大右
- 加入末尾
- 权值相同,从前往后
- 用的时候再调
- 哈夫曼编码位数计算:最少需要2^(位数) ≥ 编码的个数
- 哈夫曼编码:根据构造的哈夫曼树,左边的路径标0,右边的路径标1,写出来,然后到叶子结点,所需要的01路径
树的性质汇总:
- 满二叉树:每一个结点都是满的
- 完全二叉树:除了最后一层其他层都是满的,必须是从左到右,不能间隔
- 平衡二叉树:对于一个结点来说,左右子树的高度差不超过1
- 二叉排序树(二叉查找树、二叉检索树):(左 < 根 < 右)特殊:单枝树
- 构造哈夫曼树(最优二叉树):两个最小结点构成一个树,构成一个新的结点,权值=两个结点之和
图
图:除了首结点没有前驱,末尾结点没有后继外,一个结点只有唯一一个直接前驱和唯一的一个直接后继,由集合G = (V, E)表示
有向图:箭头有方向用<V1,V2>表示
无向图:箭头没有方向用(V1,V2)表示
完全图:每个顶点与其他所有的顶点都有边,n个顶点的无向完全图有
条边,有向完全图有
条边
出度:箭头指向其他顶点的条数
入度:箭头指向自己的条数
图的度:出度 + 入度(一条边 = 2度------> 总度 = 2*边数)
连通图:(n为顶点数)
- 最少:n - 1条边
- 最多:
强连通图:
- 最少:n条边
- 最多:
邻接矩阵:稠密图(边数多:完全图)
邻接表:稀疏图(边数少)
深度优先遍历:不撞南墙不回头,撞墙之后,回溯到前一个结点(用栈)
- 图用邻接矩阵:时间复杂度
- 图用邻接表:时间复杂度
广度优先遍历:先访问顶点的邻结点,访问完,然后再访问顶点的邻结点的邻结点(用队列)
- 图用邻接矩阵:时间复杂度
- 图用邻接表:时间复杂度
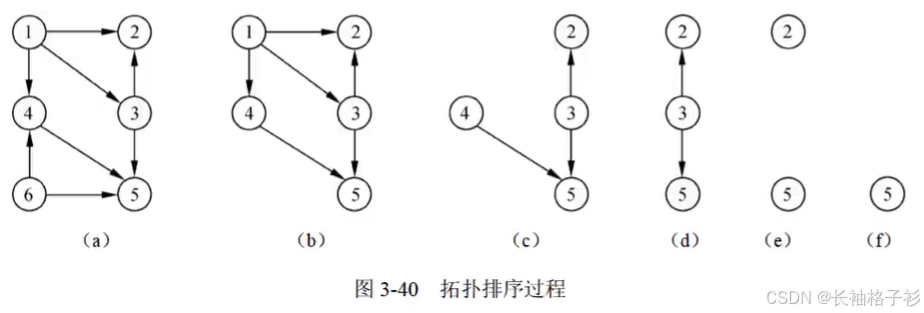
拓扑排序
方法:
- 在AOV图中选择一条入度为0(没有前驱)的顶点并且输出它
- 从网中删除该顶点及该顶点有关的弧
- 重复上述两步,直到网中不存在入度为0的顶点为止
输出拓扑序列:6,1,4,3,2,5
在这个序列前面的数字,可能存在比如说6--->4的弧,但是一定不存在4--->6弧
查找
静态查找表:顺序查找,折半(二分)查找,分块查找
动态查找表:二叉排序树,平衡二叉树,B_树,哈希表
折半查找比较的次数:
哈希函数
把所要存的值放到哈希函数里面,生成一个值,存入线性表中
计算(m是给定的哈希值或者说空间):值%m
解决哈希冲突:
- 方法一:(值+1)%m
第一个方法的案例:
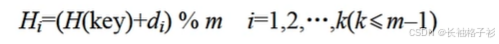


大顶堆和小顶堆
大顶堆:
和
小顶堆:
和
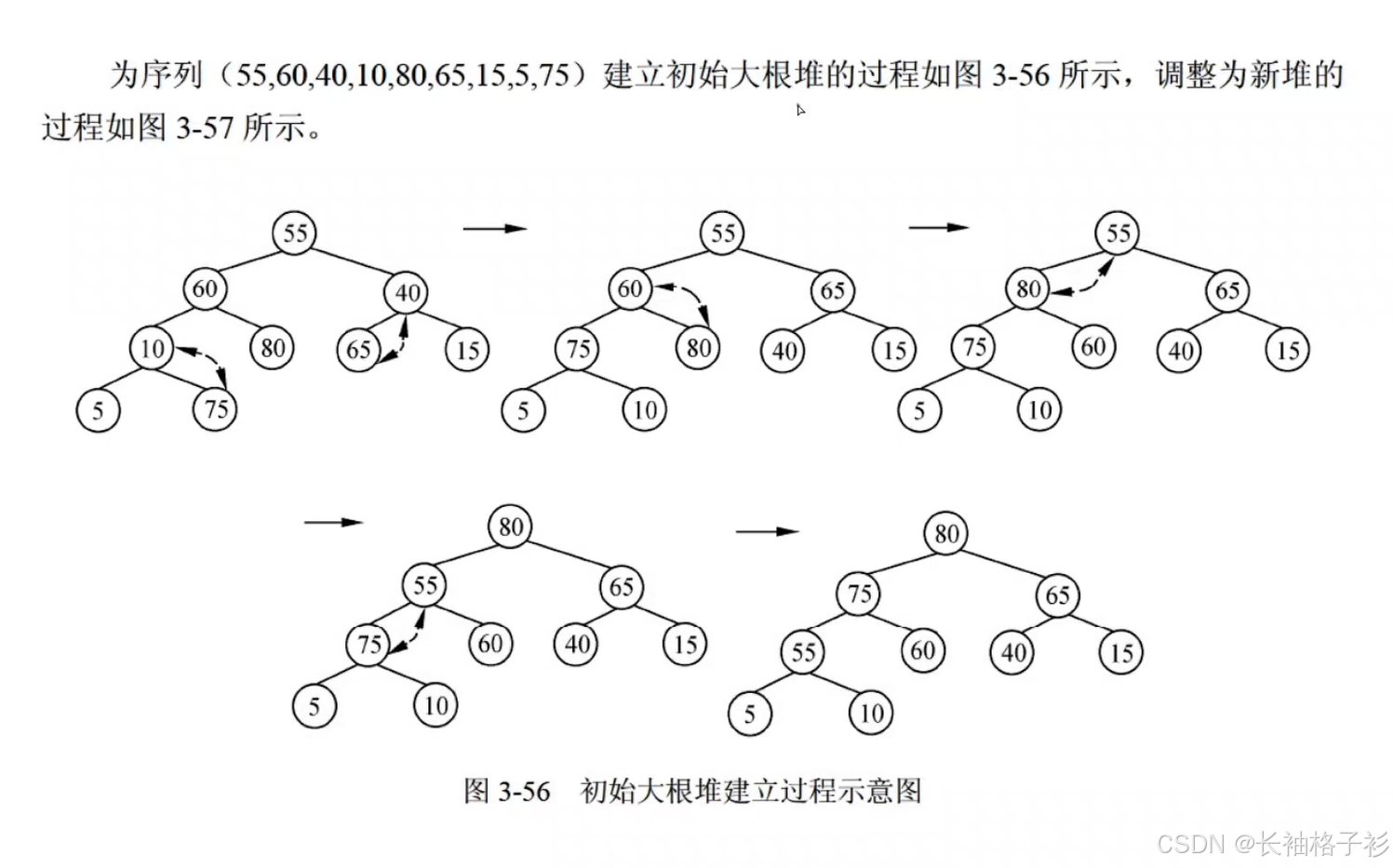
大顶堆和小顶堆的创建:
排序
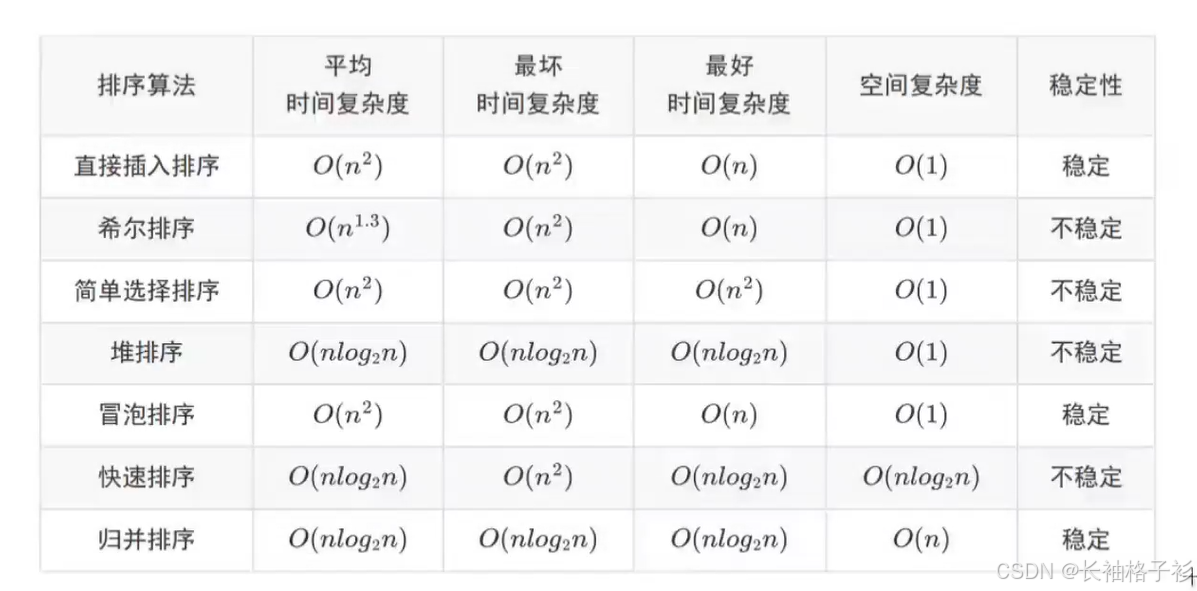
排序的基本空间复杂度以及时间复杂度
- 直接插入排序:一开始是一个a1区间,然后一个值和a1进行比较,插入到这个区间内(稳定的算法)
- 希尔排序: 根据增量序列进行排序,两个进行交换
- 选择排序:找当前序列最小的元素赋值给min,首指针指向的是第一个元素,找到之后,把最小的元素和首指针进行交换,然后首指针指向第二个元素找第二小的元素
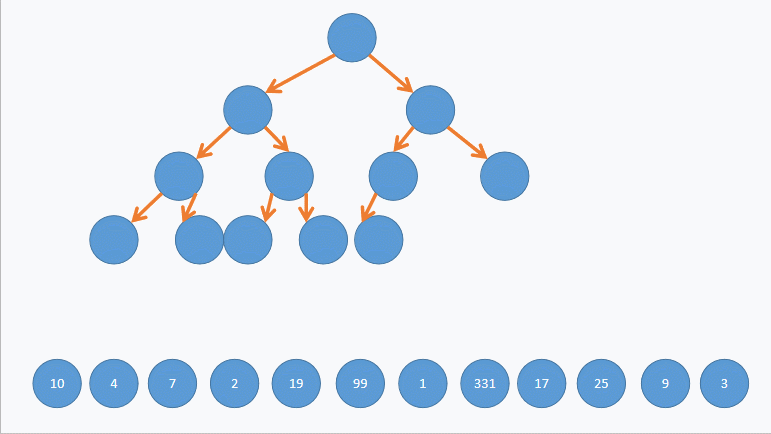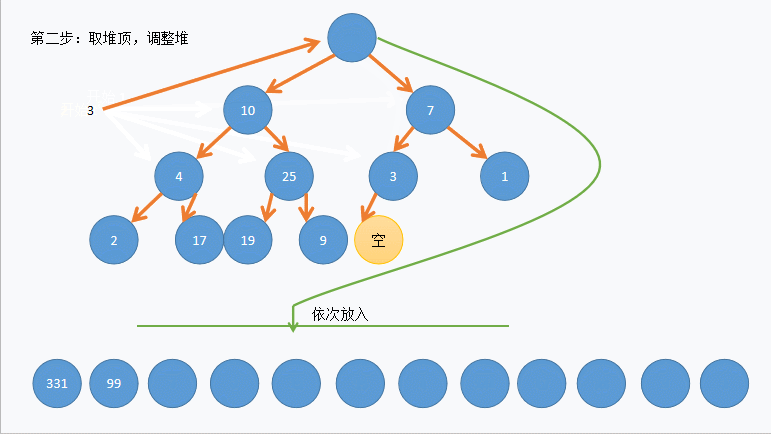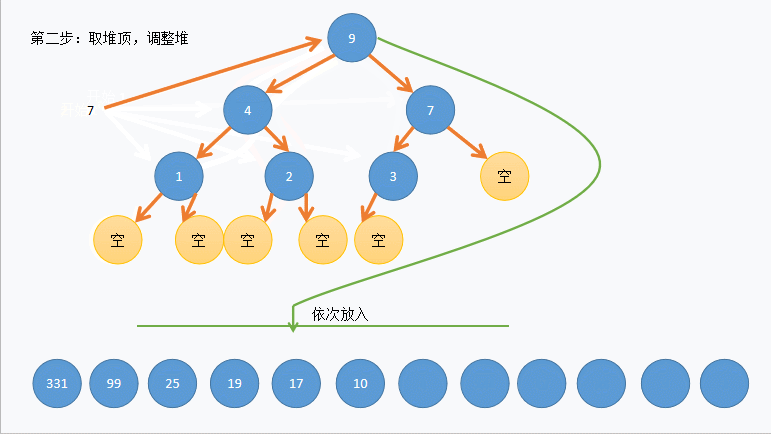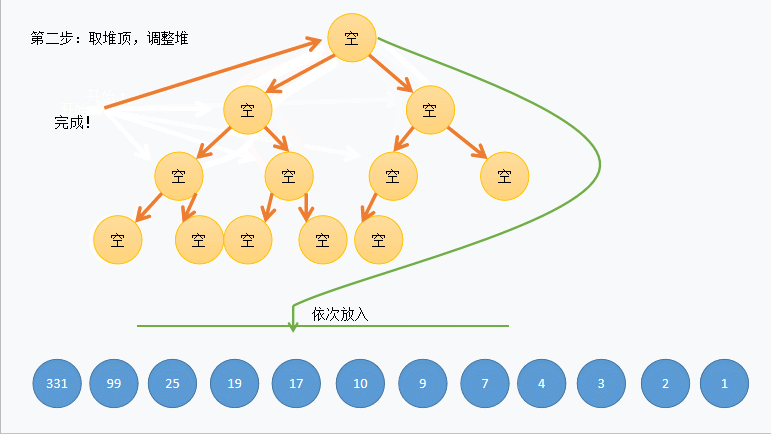
- 堆排序:从左到右进行完全二叉树的构建
- 大根堆:每一个父节点都大于子节点,左小右大
- 小根堆:每一个父节点都小于子结点
- 冒泡排序:相邻的两个元素进行比较,比较到最后,最大(小)的在最后
- 快速排序:第一步首指针指向第一个元素作为中枢,尾指针找比这个中枢小的,找到之后,把这个小的元素赋值给第一个元素,然后首指针向后寻找比中枢大的,赋值给刚刚那个小的,最后两个指针重合之后,把中枢元素赋值给他,分成两个部分,继续上述步骤


四、知识产权
著作权
一、著作权:发表权、署名权、修改权和保护作品完整权
只有发表权的保护时间受限制,其他三个不受限制:发表权 = 终身+50年
专利只有在申请国受到保护
计算机软件著作权:《中华人民共和国著作权法》《计算机软件保护条例》
计算机软件著作权的客体:保护的是计算机程序及有关文档
计算机的程序:源程序 + 目标程序
计算机软件文档:程序设计说明书 + 流程图 + 用户手册,这些表现
计算机软件著作权的保护期(50年):自软件开发完成之日起产生,50年后除了署名权,其他权利全部终止
二、职务作品
职务作品:只享有署名权,著作权属于公司,自行开发完成的作品,属于自己,但是使用了公司设备,就不能属于个人
三、委托开发
委托开发的软件著作权归属:如果没有合同规定那么就归受委托方享有
四、商业秘密《商业秘密权》
商业秘密:采取保密措施的技术信息和经营信息
五、专利申请
专利申请:一份申请一项发明(一个专利只能对应一项创造发明、先到先得)
六、商标权
商标权:十年有效,在满前的6个月内可以续,权利人是软件注册商标
所有人
五、数据库
概念数据模型
实体联系:1:1(一对一),1:n(一对多),m:n(多对多)三种
矩形:实体
椭圆形:属性
菱形:联系
二维表格:关系模型
三级模式结构
- 外模式:视图
- 概念模式:基本表
- 内模式:存储文件
两级映像
- 模式/内模式映像:存在于概念模式和内部级之间,实现了概念模式到内模式的相互转换
- 外模式/模式映像:存在于外模式和概念模式之间,实现了外模式到概念模式的相互转换
- 保证数据的物理独立性:修改概念模式和内模式之间的映像
- 保证数据的逻辑独立性:修改外模式和概念模式之间的映像
关系模型的基本术语
- 关系:一张二维表,就是一个关系
- 元组:一行数据,就是一个元组
- 属性:一列,就是一个属性
- 关系模式:关系的描述
- 关系名(属性名1,属性名2........,属性名n)
- 码:
- 候选码:能够唯一标识一个元组
- 主码:主键
- 全码:所有属性的组合
- 外码:外键
- 超码:包含码的属性集(例如:学号是码,则:(学号,姓名)就是一个超码)
完整性约束
- 关系数据结构:一张二维表
- 关系中的三个完整规则:
- 实体完整性:主码(组合主键)不能为空(部分为空)
- 参照完整性:外键在另外的那张表中必须要有对应的值,或者在本表中为外键的时候可以为空
- 自定义完整性:用户对某一个数据指定的约束条件
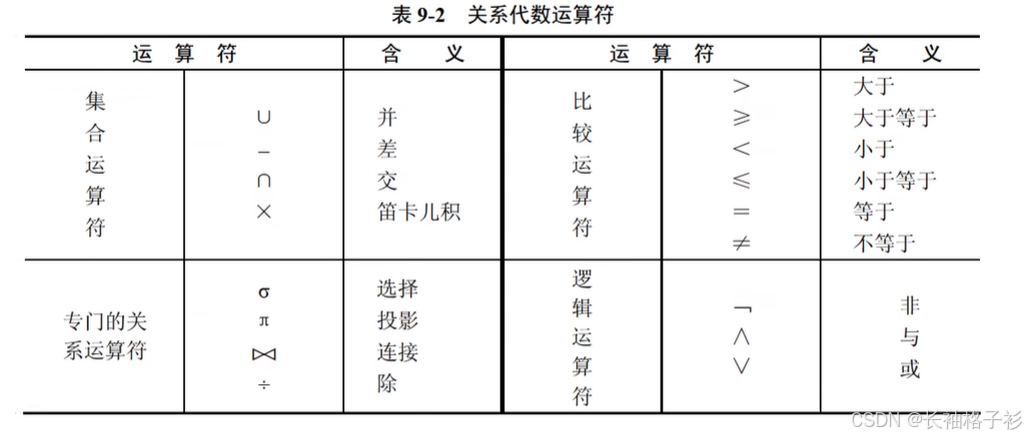
关系代数
- 笛卡尔积:D1 = {0,1},D2 = {a,b}=====>D1 X D2 = {(0,a),(0,b),(0,c),(1,a),(1,b),(1,c)}
- 并:去除相同的元素
- 交:相同的元素
- 差:属于前者不属于后者的元素
- 投影:对列的方向进行运算
- 选择:对行的方向进行运算
- 连接:先做笛卡尔积再计算
- θ连接:
,其中θ为条件
- 等值连接:θ连接的条件是“=”就是等值连接
- 自然连接:没有下面的AθB这个条件就是自然连接
- 计算R×S
- 挑选R.A1 = S.A1(公共属性列都相等)的那些元组
- 去掉重复的列S.A1(后面的表),因为他们相等
- 外连接:在自然连接基础上
- 左外连接:运行到上面第二步的时候,左边有的数据,右边没有,那么右边就填null
- 右外连接:运行到上面第二步的时候,右边有的数据,左边没有,那么左边就填null
- 全外连接:把左右外连接都写出来,然后把有空值的行填写到自然连接中
范式
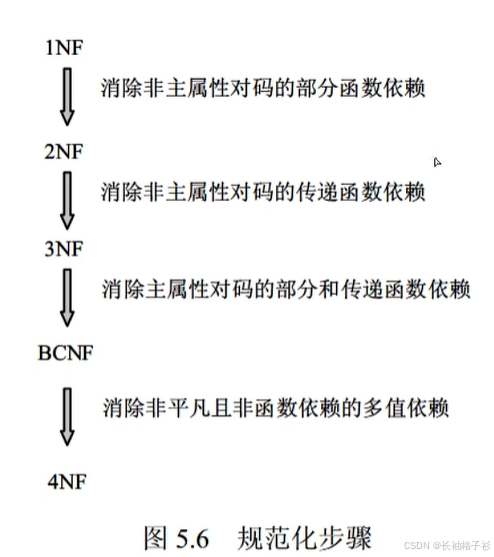
- 第一范式:每一个属性不可分割(原子性)
- 不能排除数据冗余,更新异常等问题,会有修改,插入,删除异常
- 第二范式:解决部分函数依赖
- 可能会有数据冗余、更新异常的问题
- 第三范式:消除传递函数依赖
- 可能存在主属性对码的部分依赖和传递依赖
- BC范式:解决主属性对主码的部分函数依赖
- 第四范式:解决多值依赖
投影、选择转换为SQL语言
投影:
转换为SQL语言为:select A,B,C from R
选择:
转换为SQL语言为:select A,B,C from R where B≥'5'
自然连接转换为SQL语言:
转换为SQL语言为:select R.A,R.B,R.C,S.D from R,S where R.B=S.B and R.C=S.C
关系模式中求候选关键字
例题:设关系模式R(U, F),其中R上的属性集U={A, B, C, D, E},R上的函数依赖集F={A→B,DE→B,CB→E,E→A,B→D}。( )为关系R的候选关键字。分解( )是无损连接,并保持函数依赖的。
问题一:
A: AB B:DE C:CE D:DB
问题二:
A.p={R1(AC),R2(ED),R3(B)}
B.p={R1(AC),R2(E),R3(DB)}
C.p={R1(AC),R2(ED),R3(AB)}
D.p={R1(ABC),R2(ED),R3(ACE)}
- 根据F里面的函数依赖,箭头右边存在的字母先不看,看箭头左边的
- 进行闭包处理,最后的结果会=U就是候选键
- 不看ABDE
- 剩下的就是C
- 进行闭包处理(把能推导出来的字母写到括号里,最后如果和前面的闭包一样,就结束)
- 答案中有CE
- (CE)+-------->(ACE)+-------->(ABCE)+-------->(ABCDE)+-------->(ABCDE)结束
- CE就是候选键,当然也不排除有其他的
E-R图转换为关系模式
名称 描述符号 一般概述 实体 名词 联系 动词
属性
名词
- 1:1的关系:一方的主码 + 联系的属性----->加入到另一方
- 1:n的关系:少的一方的主码 + 联系的属性----->加入到多的一方
- n:m的关系:一方主码 + 另一方主码 + 联系的属性 ------> 组合加入联系中去


事务
- 原子性:事务是原子的,要么都做,要么都不做
- 一致性:从一个状态变到另一个状态
- 隔离性:事务并发执行,这个过程,都不可见
- 持久性:事务提交成功,更新也是永久有效的
数据库的恢复和备份
- 静态存储:在转存期间,不允许存取修改
- 动态存储:在转存期间,可以存取修改
- 海量存储:每次转存全部数据
- 增量存储:每次只转存上一次更新后的数据
- 日志文件:每次操作都写入日志文件
并发控制
- 排他锁(X锁或写锁):如果加上这个锁,那么只允许他修改,其他的事务都不允许加锁
- 共享锁(S锁或读锁):如果加上这个锁,那么只允许他读取,不能修改,其他的事务可以加共享锁
分布式数据库
- 分片透明:用户或应用程序不需要知道表的分块存储
- 复制透明:采用复制技术的分布方法,不用知道复制具体细节
- 位置透明:用户不用知道数据物理位置
- 逻辑透明:用户或应用程序不用知道局部场地使用的数据模型
- 共享性:存储在不同结点的数据共享
- 自治性:结点对数据都能独立管理
- 可用性:一处故障,不至于全部瘫痪
- 分布性:数据分布在不同场地
六、面向对象
对象的组成
一个对象通常可由对象名、属性和方法三部分组成。
封装
封装是一种信息的隐蔽技术,通过将对象的状态信息和行为信息(即方法和数据)捆绑在一起,形成一个独立的实体。这样,对象的使用者只需要知道如何使用对象,而不需要了解对象内部的具体实现细节。
继承
承是面向对象编程中的一个核心概念,它允许在已存在的类(父类或超类)的基础上定义新的类(子类)。子类可以继承父类的属性和方法,并可以添加自己特有的属性和方法
多态
多态是指在同一操作中,当不同的对象接收同一个消息时,会产生不同的行为。多态的实现方式主要有方法重载(Overloading)和方法重写(Overriding)
- 参数多态:采用参数化模板,通过给出不同的类型参数,使得一个结构的种类型(函数模板和类模板)
- 包含多态:最常见的就是子类型化
- 过载多态:同一个名有不同类型
- 强制多态:强制类型转换
消息
传递的变量值
面向对象设计原则
- 单一责任原则:就一个类而言,应该仅有一个引起它的变化
- 开放-封闭原则:扩展-开放的,修改-封闭的
- 里氏替换原则:基类出现的地方,子类一定可以出现
- 依赖倒置原则:依赖于抽象,不依赖于细节(实现)
- 接口分离原则:依赖于抽象,不依赖于具体
- 共同封闭原则:一个变化对包产生影响,则对包以内所有类都产生影响,包以外不影响
- 共同重用原则:重用了包中一个类就重用所有类
面向对象分析
- 认定对象:定义“问题域”,名词
- 组织对象
- 对象间的相互作用
- 基于对象的操作
- 定义对象的内部信息
面向对象分析侧重于理解问题,分析描述软件要做什么
面向对象设计侧重于理解解决方案
先分析后设计
面向对象程序设计
分析-----设计-----程序设计------测试
七、UML
UML
统一对下面几个建模:
- 系统的词汇
- 简单的协作
- 逻辑数据库模式
事物
- 结构事物:静态部分:类、接口、协作、用例、主动类、构件、制品、结点。
- 行为事物:动态部分:消息、状态、动作。
- 分组事物:组织部分:包
- 注释事物:解释部分:UML中的解释部分
关系
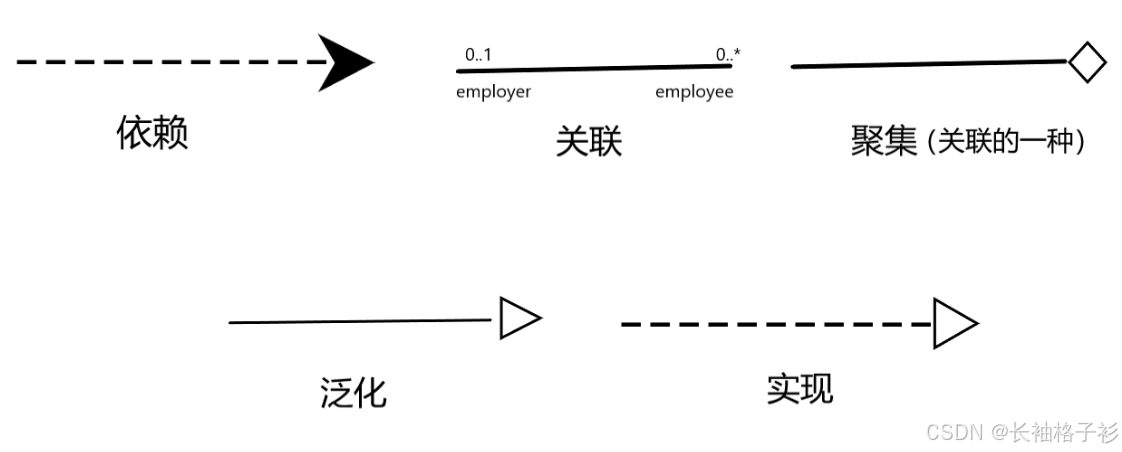
- 依赖:依赖事务 ------> 独立事务
- 关联:0个或1个 <-------> 0个或多个
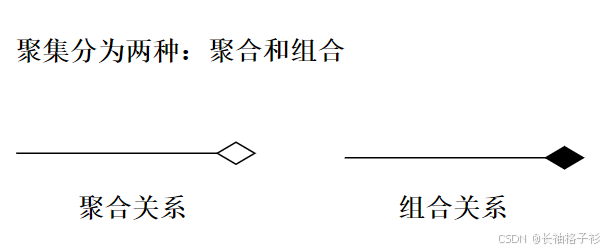
- 聚合:部分和整体的生命周期不一致,整体消失了,部分依然存在,部分可以脱离整体存在
- 组合:部分和整体的生命周期一致,整体消失了,部分也消失,部分不可以脱离整体存在
- 泛化:父类泛化子类
- 实现:实现接口
- 关联和依赖的区别:依赖是偶然临时的,关联是比较强的拥有关系:人---->氧气
- 多重度:一个类的实例能够与另一个类的多少个实例相关联
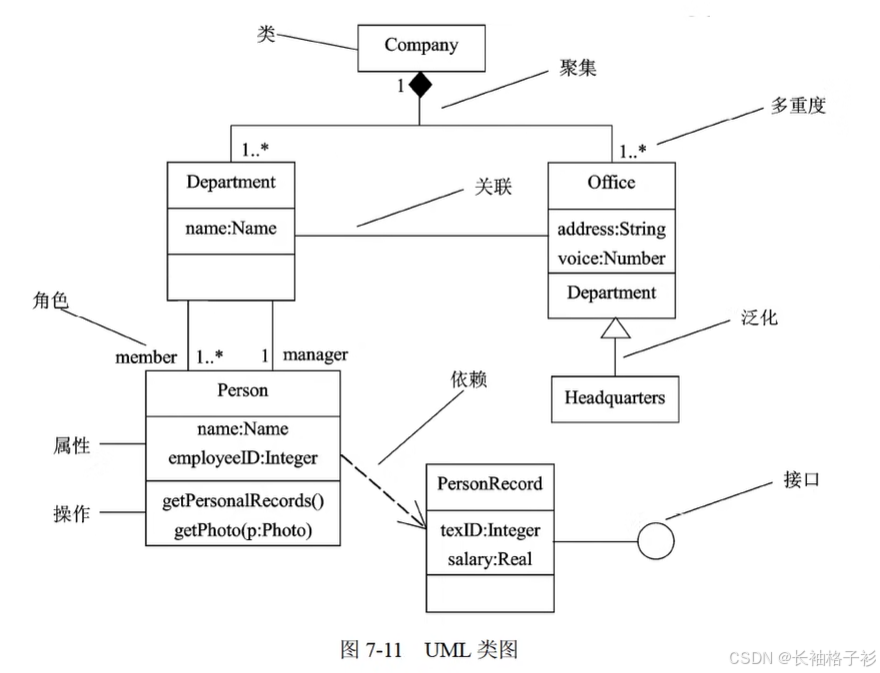
类图
- 类图:展现了,一组对象,接口,协作和它们之间的关系,静态设计建模,支持系统的功能需求
- 案例:
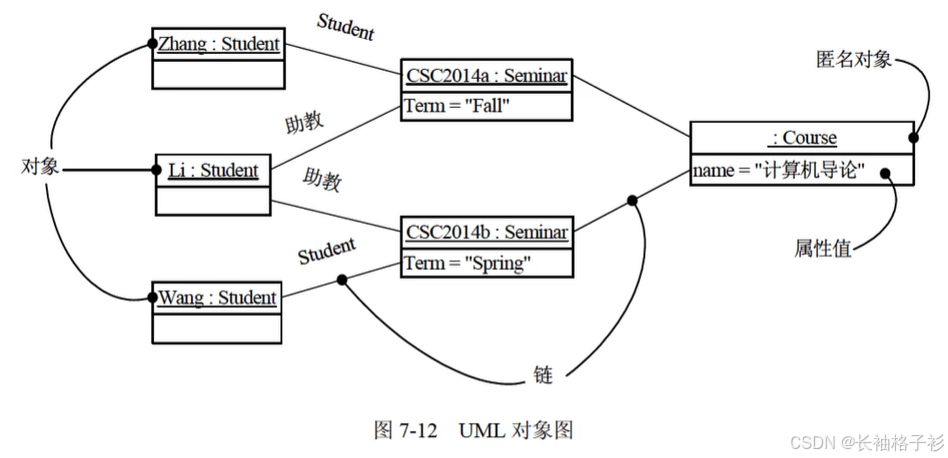
对象图
对象图:展现了某一组对象以及它们之间的关系,给出系统的静态设计视图或静态进程视图
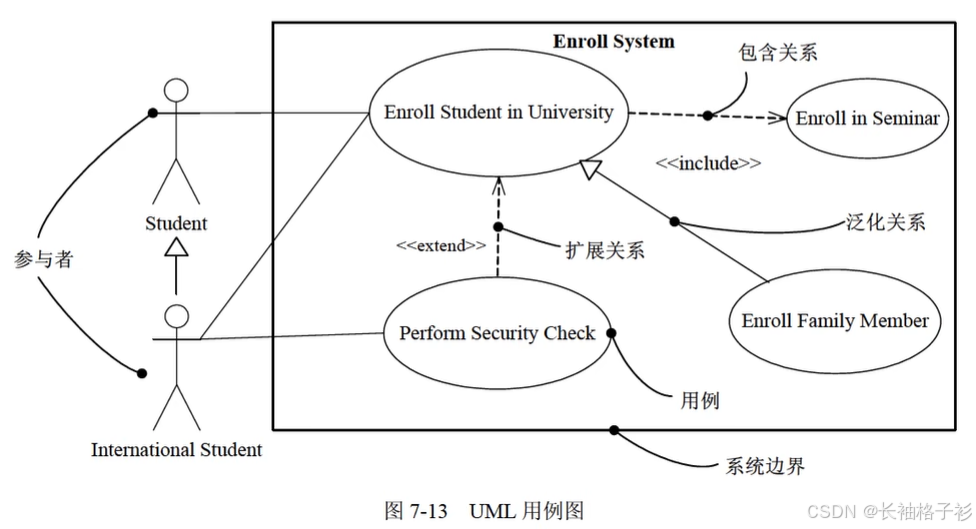
用例图
用例图:展现了用例、参与者以及他们之间的关系
包含关系:一个用例包含另一个用例(删除图书,包含了查询图书)
扩展关系:一个用例执行的时候,可能会发生一些特殊情况或可选情况,这就是用例的扩展用例
泛化关系:参与者与参与者,用例与用例之间的关系(一般和特殊)
- 总结:
- 关联:参与者与用例之间的关系
- 包含:用例和用例之间的关系
- 扩展:用例和用例之间的关系
- 泛化:参与者与参与者,用例与用例之间的关系



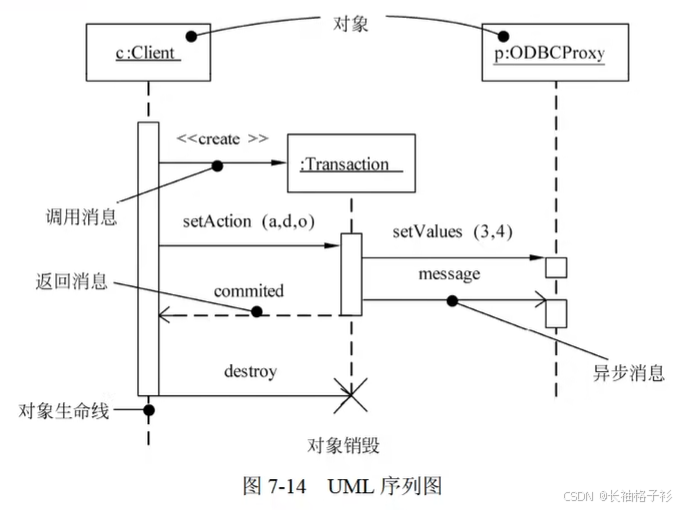
序列图(顺序图、时序图)
- 序列图是场景的图形化表示,描述了时间顺序组织的对象之间的交互活动
- 描述的是一个用例和多个对象的行为
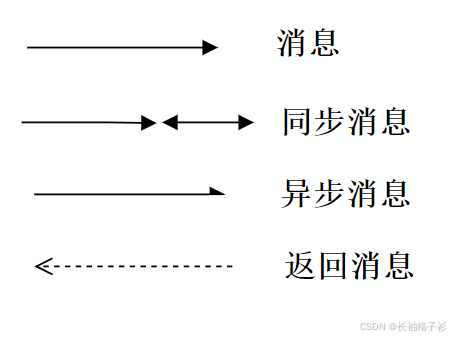
- 消息
- 同步消息:需要等待返回消息:不可以继续发送
- 异步消息:不需要等待返回,可以继续发送
- 返回消息
- 箭头指向哪条线,那么就是哪个对象的方法(方法名(参数))
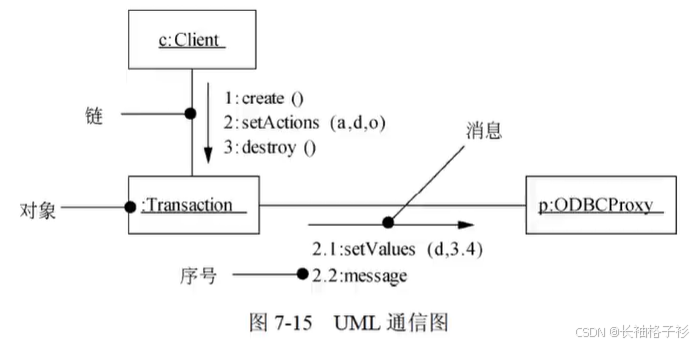
通信图(协作图)
- 通信图:强调收发消息的对象结构组织,展示对象之间的消息流及其顺序
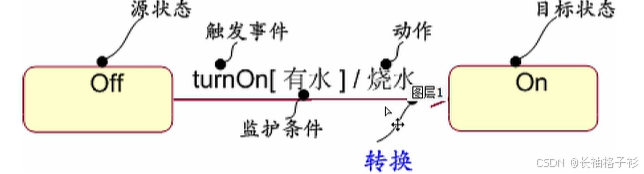
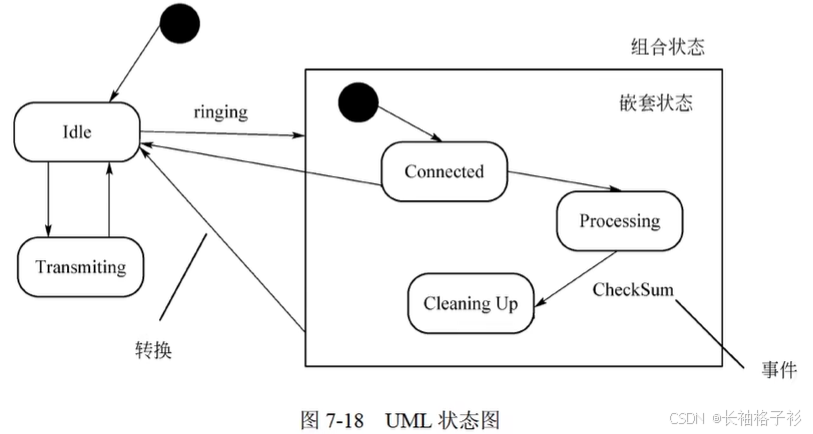
状态图
- 状态图:展现了状态机,它由状态、转换、事件和活动组成(简单状态、组合状态),对一种对象的按事件排序
- 对反应型对象建模
- 状态:
- 初态
- 终态
- 活动:动作组成
- 事件:
- entry:入口动作,进入状态,立即执行
- exit:出口动作,退出状态,立即执行
- do:内部活动,占有有限时间,并可以中断的工作
- 转换:
- 包括两个状态(源状态,目标状态)
- 事件,监护条件,动作
- 事件触发转换(迁移)
- 活动(动作)可以在状态内执行,也可以在状态转换(迁移)时执行
- 案例:


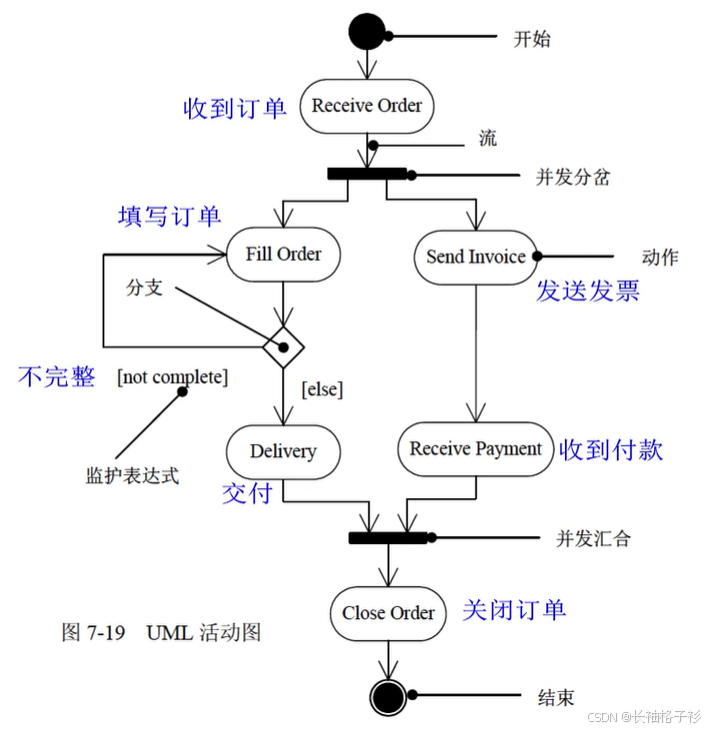
活动图
- 活动图:展现了系统内从一个活动到另一个活动的流程,强调对象间的控制流程
- 对工作流程建模
- 对操作建模
- 对业务流程建模
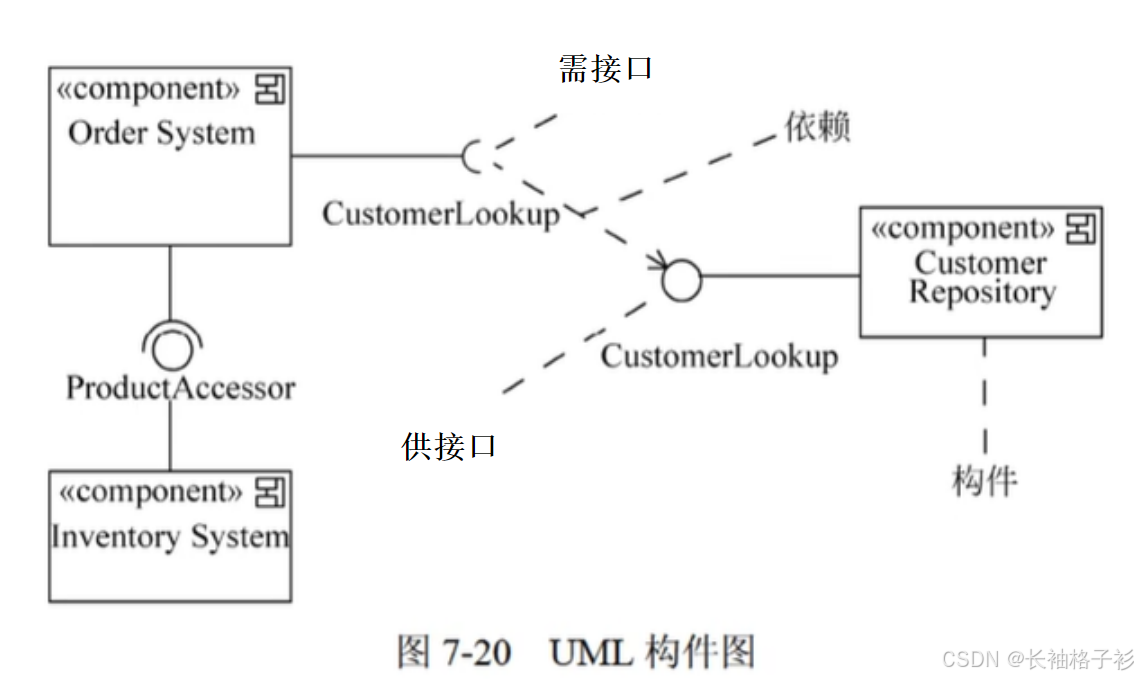
构件图(组件图)
- 构件图:展现了一组构建之间的组织和依赖
- 专注于系统的静态实现视图
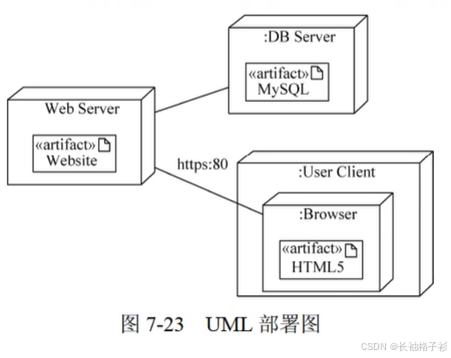
部署图
- 部署图:用来对面向对象系统的物理方面建模
- 部署图通常在实施阶段使用
UML汇总
- 静态建模:类图、对象图、用例图
- 动态建模:序列图(顺序图,时序图)、通信图(协作图)、状态图、活动图
- 物理建模:构件图(组件图)、部署图
- 交互图:序列图(顺序图,时序图)、通信图(协作图)
八、设计模式
设计模式的要素
- 复用成功的设计和体系结构
- 创建型模式:与对象的创建有关
- 结构型模式:处理类和对象的组合
- 行为型模式:对类或对象怎么交互和分配职责进行描述
结构模式的分类
创建型 结构型 行为型 类 Factory Method(工厂方法模式) Adapter(适配器模式) Interpreter(解释模式)
Template Method(模版方法模式)
对象 Abstract Factory(抽象工厂模式)
Builder(生成器模式)
Prototype(原型模式)
Singleton(单例模式)
Adapter(适配器模式)
Bridge(桥接模式)
Composite(组合模式)
Decorator(装饰模式)
Facade(外观模式)
Flyweight(享元模式)
Proxy(代理模式)
Chain of Responsibility(责任链模式)
Command(命令模式)
Iterator(迭代器模式)
Mediator(终结者模式)
Memento(备忘录模式)
Observer(观察者模式)
State(状态模式)
Strategy(策略模式)
Visitor(访问者模式)
创建型设计模式
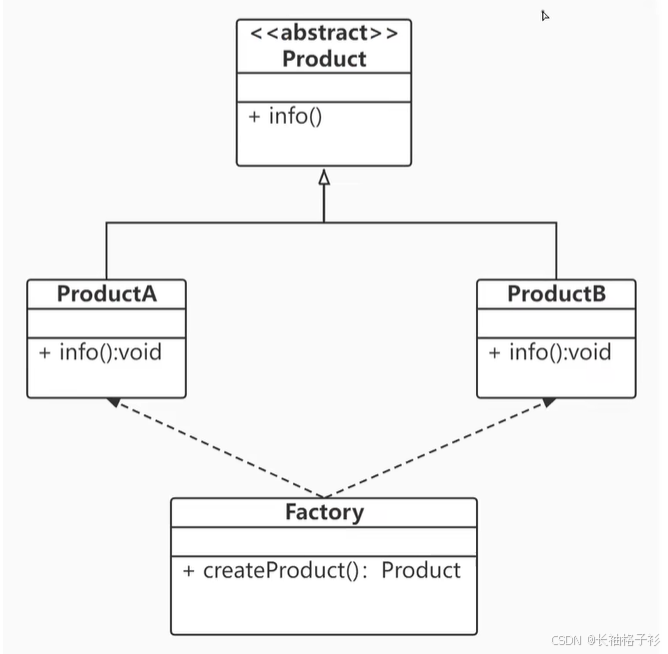
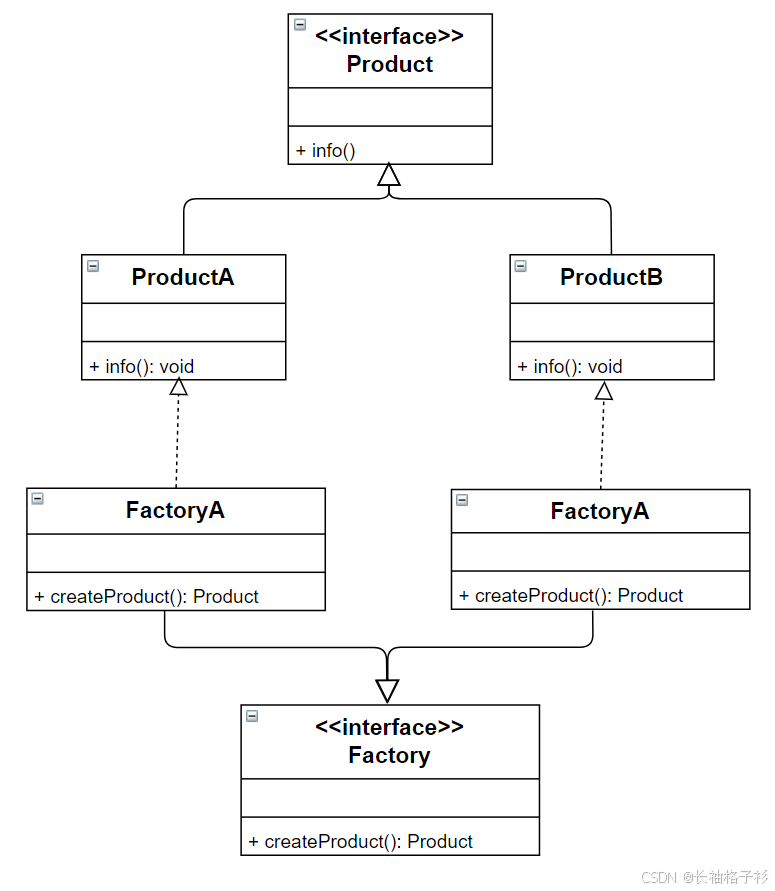
简单工厂模式
- 简单工厂模式不属于23种设计模式之一
- 定义:定义一个工厂类,他可以根据参数的不同返回不同的实例,被创建的实例通常具有相同的父类
- 三类角色:
- 工厂(核心):负责实现创建所有产品的内部逻辑
- 工厂类可以直接被外界调用,创建所需对象(类名.静态方法)
- 抽象产品:工厂类所创建所有对象的父类
- 封装了产品对象的公共方法,所有的具体产品为其子类对象
- 具体产品:简单工厂模式的创建目标
- 所有被创建的对象都是某个具体类的实例,它要实现抽象产品中声明的抽象方法
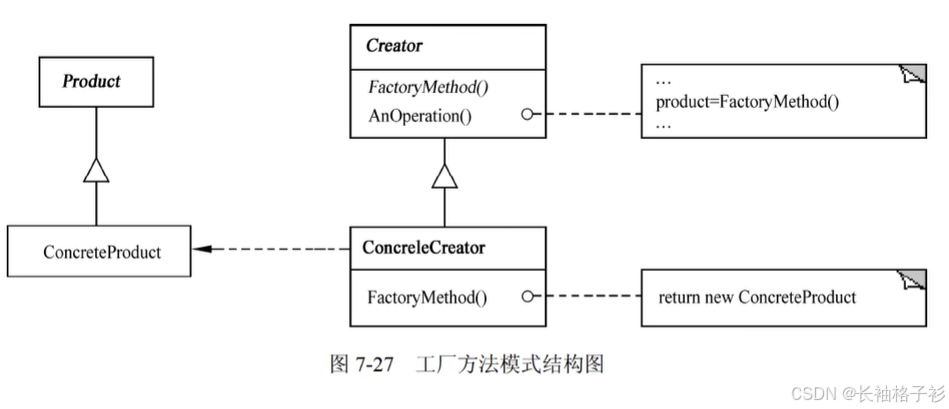
工厂方法模式(Factory Method)
- 意图:定义一个用于创建对象的接口,让子类决定实例化哪一个类(Factory Method使一个类的实例化延迟到了子类)
- 方法和接口的含义
- Product定义工厂方法所创建的对象的接口
- ConcreteProduct实现Product接口
- Creator声明工厂方法,该方法返回一个Product类型的对象,Creator也可以定义一个工厂方法的默认实现,它返回一个默认的ConcreteProduct对象,可以调用工厂方法,以创建一个Product对象
- ConcreteCreator重定义工厂方法以返回一个ConcreteProduct实例
- 适用性
- 当一个类不知道他所必须创建的对象的类的时候
- 当一个类希望由它的子类来指定它所创建的对象的时候(Factory Method使一个类的实例化延迟到了子类)
- 当类将创建对象的职责委托给多个帮助子类中的某一个,并且你希望将哪一个帮助子类是代理者这以信息局部化的时候
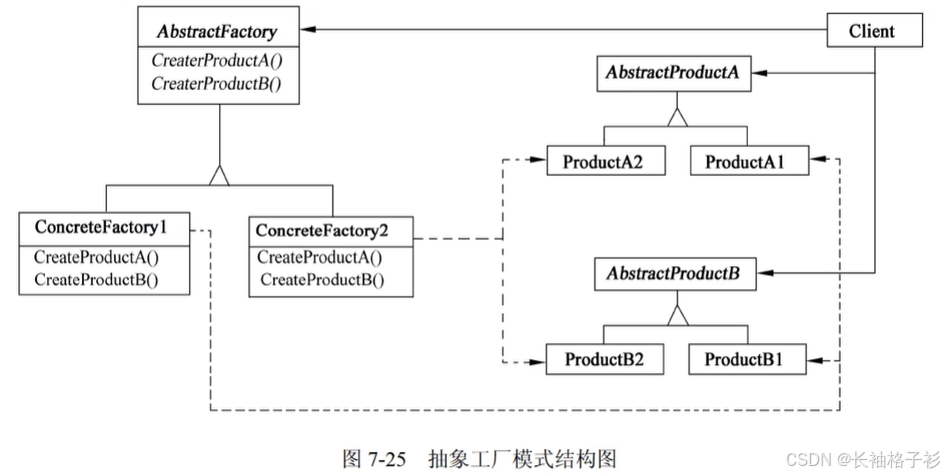
抽象工厂模式(Abstract Factory)
- 抽象工厂模式(相对于工厂模式,多了一个产品,而且无需指定具体的工厂去生产)
- 意图:提供一个创建一系列相关或者相互依赖对象的接口,而无需指定它们具体的类
- 方法和接口含义:
- AbstractFactory声明一个创建抽象产品对象的操作接口
- ConcreteFactory实现创建具体产品对象的操作
- AbstractProduct为一类产品声明一个接口
- ConcreteProduct定义一个将被相应的具体工厂创建的产品对象,实现AbstractProduct接口
- Client仅使用由AbstractFactory和AbstractProduct类声明的接口
- 适用性:
- 一个系统要独立于它的产品创建、组合和表示时
- 一个系统要由多个产品系列中的一个来配置时
- 当要强调一系列相关产品对象的设计以便进行联合使用时
- 当提供一个产品类库,只想显示它们的接口而不是实现时
生成器模式(Builder)
- 意图:将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示
- 结构:
- 方法和接口含义:
- Builder为创建一个Product对象的各个部件指定抽象接口。
- ConcreteBuilder实现Builder的接口以构造和装配该产品的各个部件,定义并明确它所创建的表示,提供一个检索产品的接口。
- Director构造一个使用Builder接口对象。
- Product表示构造的复杂对象。
- ConcreteBuilder创建该产品的内部表示并定义它的装配过程,包含组成组件的类,包括将这些组件装配成最终产品的接口。
- 适用性:
- 当创建复杂对象的算法应该独立于该对象的组成部分以及它们的装配方式时
- 当构造过程必须允许被构造的对象有不同的表示时
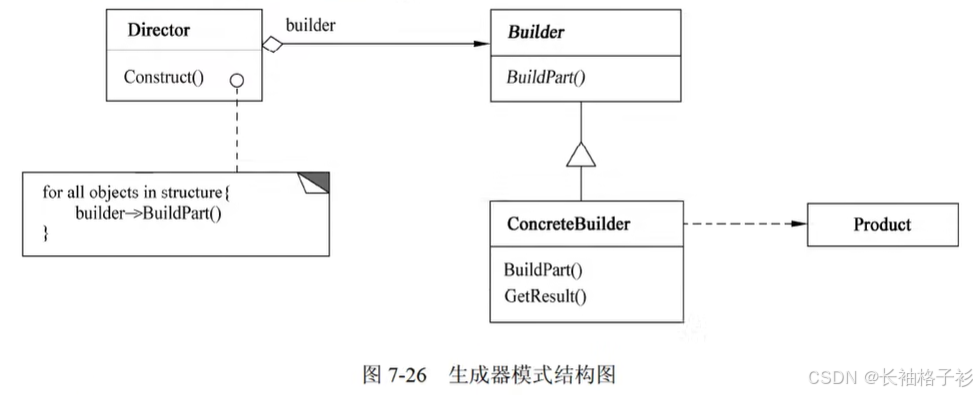
原型模式(Prototype)
- 意图:用原型实例指定创建对象的种类,并通过复制这些原型创建新的对象
- 结构:
- 方法和接口的含义:
- Prototype声明一个复制自身的接口
- ConcretePrototype实现一个复制自身的操作
- Client让一个原型复制自身而创建一个新的对象
- 适用性:
- 当一个写应该独立于它的产品创建、构成和表示时
- 当一个实例化的类是在运行时指定时,例如:通过动态加载
- 为了避免创建一个与产品类层次平行的工厂类层次时
- 当一个类的实例只能有几个不同的状态组合中的一种时,建立相应数目的原型并克隆它们,可能比每次用合适的状态手工实例化该类更方便
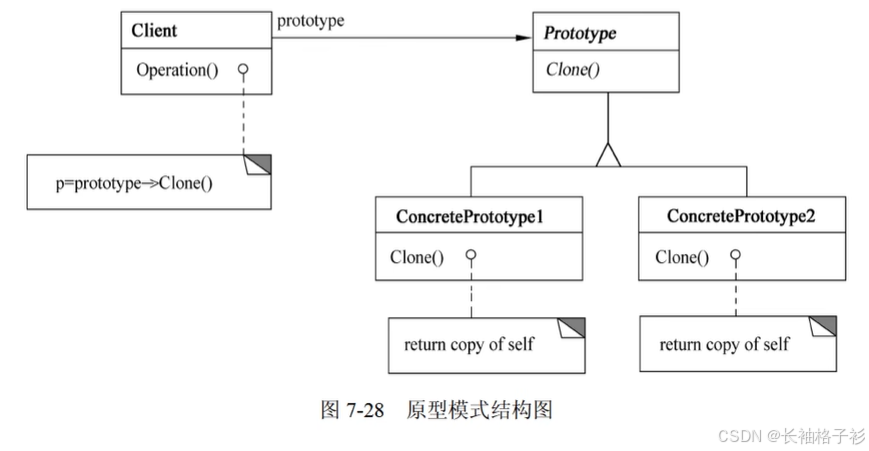
单例模式(Singleton)
- 意图:保证一个类仅有一个实例,并提供一个访问它的全局访问点
- 结构:
- 方法和接口的含义:
- Singleton指定一个Instance操作,允许客户访问它的唯一实例
- Instance是一个类操作,可负责创建它自己唯一实例
- 适用性:
- 当类只能有一个实例而且客户可以从一个众所周知的访问点访问它时
- 当这个唯一实例应该是用过子类化可扩展的,并且客户无须更改代码就能使用一个扩展的实例时
结构型设计模式
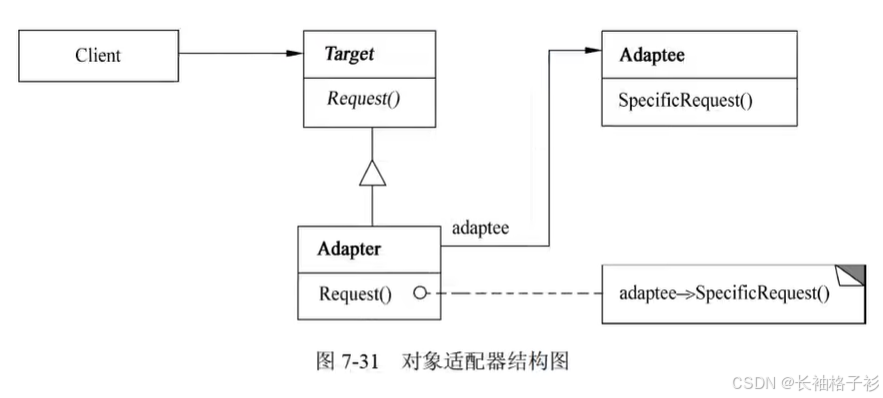
适配器模式(Adapter)
- 意图:将一个类的接口转换成客户希望的另外一个接口,Adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作
- 结构:
- 适用性:
- 想使用一个已经存在的类,而它的接口不符合要求
- 向创建一个可以服用的类,该类可以与其他不相关的类或不可预见的类(即那些接口可能不一定兼容的类)协同工作
- (仅适用于对象Adapter)想使用一个已经存在的子类,但是不可能对每一个都进行子类化以匹配它们接口的接口,对象适配器可以适配它的父类接口
桥接模式(Bridge)
- 意图:将抽象部分与实现部分分离,使它们都可以独立地变化
- 结构:
- 方法与接口的含义:
- Abstraction定义抽象类的接口,维护一个指向Implementor类型对象的指针
- RefinedAbstraction扩充由Abstraction定义的接口
- Implementor定义实现类的接口,该接口不一定要与Abstraction接口完全一致;事实上两个接口可以完全不同,Implementor接口仅提供基本操作,而Abstraction定义了基于这些基本操作的较高层次的操作
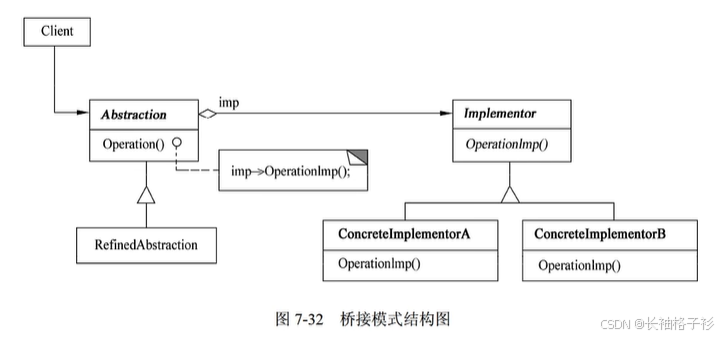
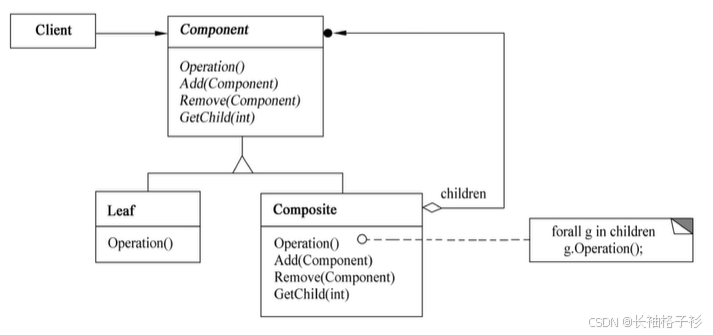
组合模式(Composite)
- 意图:将对象组合成树形结构以表示“部分-整体”的层次结构。Composite使得用户对单个对象和组合对象的使用具有一致性。
- 结构:
- 方法与接口含义:
- Composite为组合中的对象声明接口,声明一个接口用于访问和管路Component的子组件
- Leaf在组合中表示叶节点对象,叶子结点没有子结点,在组合中定义图元对象的行为
- Composite定义有子组件的那些组件的行为。存储子组件。在Composite接口中实现与子组件有关的操作
- Client通过Component接口操纵组合组件的对象。
- 适用性:
- 想表达对象的部分-整体层次结构
- 希望用户忽略组合对象与单个对象的不同,用户将统一使用组合结构中的所有对象
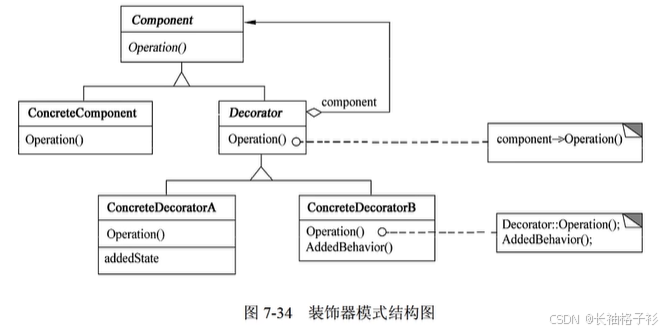
装饰器模式(Decorator)
- 意图:动态地给一个对象添加额外的职责。就增加功能而言,Decorator模式比生成子类更加灵活。
- 结构:
- 方法和接口的含义:
- Component定义一个接口对象,可以给这些对象动态添加职责
- ConcreteComponent定义一个对象,可以给这个对象添加一些职责
- Decorator维持一个指向Component对象的指针,并定义一个与Component接口一致的接口
- 适用性:
- 在不影响其他对象的情况下,以动态、透明的方式给单个对象添加职责
- 处理那些可以撤销的职责
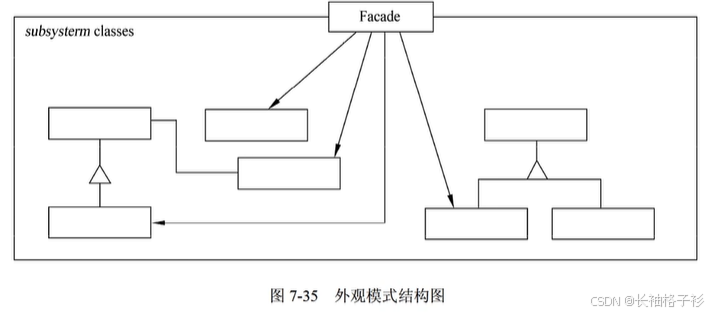
外观模式(Facade)
- 意图:为子系统中的一组接口提供一个一致的界面,Facade模式定义了一个高层接口,这个接口使得这一子系统更加容易使用
- 结构:
- 方法和接口的含义:
- Facade知道哪些子系统类负责处理请求;将客户的请求代理给适当的子系统对象。
- Substance classes 实现子系统的功能;处理有Facade对象指派的任务;没有Facade的任何相关信息,即没有指向Facade的指针。
- 适用性:
- 要为一个复杂的系统提供一个简单的接口时
- 客户程序与抽象类的实现部分之间存在着很大的依赖性
- 当需要构建子系统时,使用Facade模式定义子系统中每层的入口点。
享元模式(Flyweight)
- 意图:运用共享技术有效地支持大量细粒度的对象(理解:相当于去掉重复的类)(五子棋案例:两个棋子就设定两个类,其他的类只是共享它,位置不同而已)
- 结构:
- 适用性:
- 一个应用程序使用了大量的对象
- 完全由于使用大量的对象,造成很大的存储开销
- 对象的大多数状态都可变为外部状态
- 如果删除对象的外部状态,那么可以用相对较少的共享对象取代很多组对象
- 应用程序不依赖于对象标识。由于Flyweight对象可以被共享,所有对于概念上明显有别的对象,标识测试将返回真值
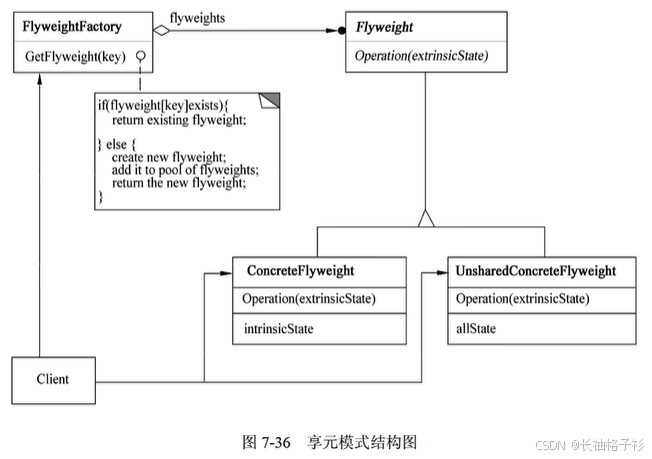
代理模式(Proxy)
- 意图:为其他对象提供一种代理以控制对这个对象的访问
- 结构:
- 适用性:适用于在比较通用和复杂对象指针代替简单的指针的时候
- 远程代理(Remove Proxy)为一个对象在不同地址空间提供局部代表
- 虚代理(Virtual Proxy)根据需要创建开销很大的对象
- 保护代理(Protection Proxy)控制对原始对象的访问,用于对象应该有不同的访问权限的时候
- 智能引用(Smart Reference)取代了简单的指针,它在访问对象时执行一些附加操作
行为型设计模式
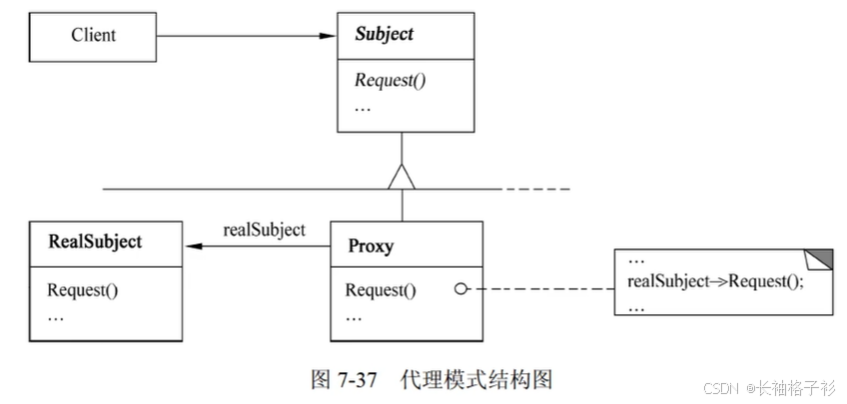
责任链模式
- 意图:使多个对象都有机会处理请求,从而避免请求的发送至和接受者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。(请假案例:<7天找辅导员,<15天找院长,<30天找校长)
- 结构:
- 方法和接口的含义:
- Handle定义一个处理请求的接口;(可选)实现后继链
- ConcreteHandle处理它所负责的请求;可访问它的后继者;如果可处理该请求就处理它,否则将该请求转发给后继者。
- Client向链上的具体处理者(ConcreteHandle)对象提交请求
- 适用性:
- 有多个的对象可以处理一个请求,哪个对象处理该请求运行时刻自动确定
- 想在不明确指定接收者的情况下向多个对象中的一个提交一个请求
- 可处理一个请求的对象集合应被动态指定
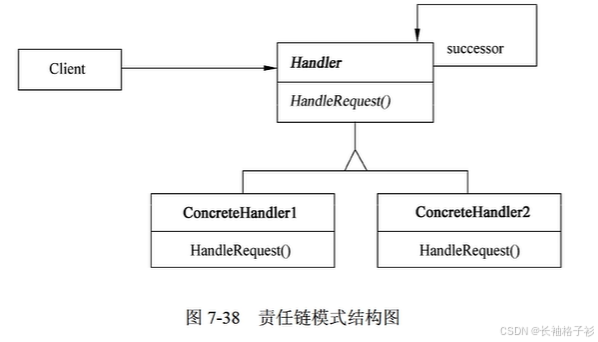
命令模式(Command)
- 意图:将一个请求封装为一个对象,从而使得可以用不同的请求对客户进行参数化;对请求排队或记录请求日志,以及支持可撤销的操作(开关电视机案例:遥控器去命令一个接口去执行开关机命令,接口的实现者电视机去接受那个命令)
- 结构:
- 方法和接口的含义:
- Command声明执行操作的接口
- ConcreteCommand将一个接收者对象绑定于一个动作;调用接收者相应的操作,以实现Execute
- Client创建一个具体命令对象并设定它的接收者
- Invoker要求该命令执行这个请求
- Receiver知道如何实施与执行一个请求相关的操作。任何类都可能作为一个接收者
- 适用性:
- 抽象出待执行的动作以参数化某对象。
- 在不同时刻指定、排列和执行请求。
- 支持取消操作。
- 支持修改日志。
- 用构建在原语操作上的高层操作构造一个系统。
解释器模式(Interpreter)
- 意图:给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子
- 结构:
- 方法和接口的含义:
- AbstractExpression声明一个程序的解释操作,这个额借口为抽象语法树中所有的结点所共享
- TerminalExpression对文法中的每一条规则都需要一个NonterminaExpression类;为每个符号都维护一个AbstractExpression类型的实例变量;为文法中的非终结符实现
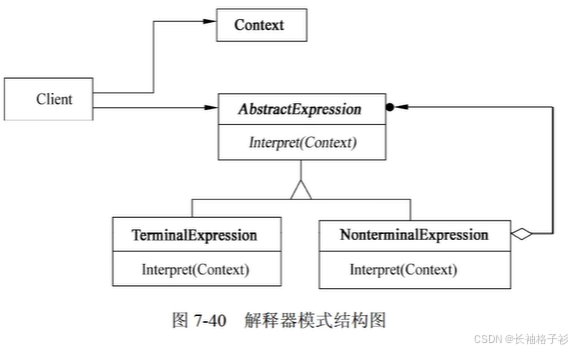
迭代器模式(Iterator)
- 意图:提供一种方法顺序访问一个聚合对象中的各个元素,且不需要暴露该对象的内部表示
- 结构:
- 方法和接口的含义:
- Iterator(迭代器)定义访问和便利元素的接口
- ConcreteIterator(具体迭代器)实现迭代器接口;对该聚合遍历时跟踪当前位置
- Aggregate(聚合)定义创建相应的迭代器对象的接口
- ConcreteAggregate(具体聚合)实现创建相应迭代器的接口,该操作返回ConcreteIterator的一个适当的实例
- 适用性:
- 访问一个聚合对象的内容而无需暴露它的内部表示
- 支持对聚合对象的多种遍历
- 为遍历不同的聚合结构提供一个统一的接口
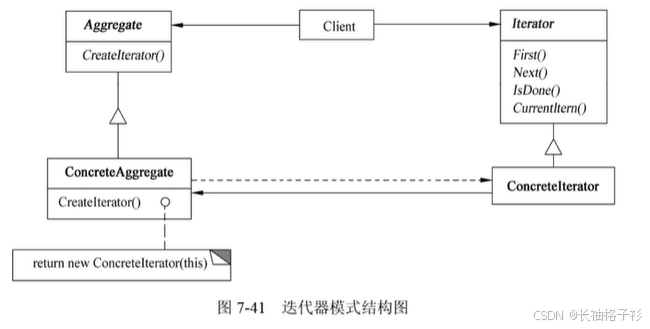
中介者模式(Mediator)
- 意图:用一个对象类封装一系列的对象交互,中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互
- 结构:
- 方法和接口的含义:
- Mediator(中介者)定义一个接口用于各同事(Collegue)对象通信
- ConcreteMediator(具体中介者)通过协调各同事对象实现协作行为;了解并维护它的各个同事。
- Colleague class(同事类)知道它的中介者对象;每一个同事类对象在需要与其他同事通信的时候与它的中介者通信。
- 适用性:
- 一组对象以定义良好但是复杂的方式进行通信,产生的互相依赖关系结构混乱且难以理解
- 一个对选哪个引用其他很多对象并且直接与这些对象进行通信,导致难以复用该对象
- 想定制一个分部在多个类中的行为,而又不想生成太多子类
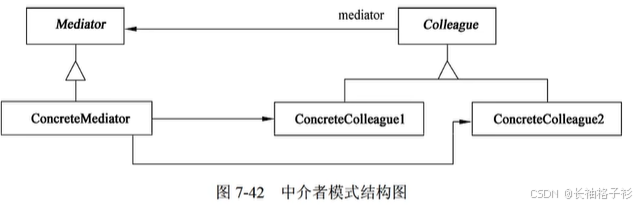
备忘录(Memento)
- 意图:在不破坏封装性的前提下捕获一个对象的内部状态,并在对象之外保存这个状态。这样以后就可以将对象恢复到原先保存的状态。
- 结构:
- 方法和接口的含义:
- Memento(备忘录)存储原发器对象的内部状态,原发器根据需要决定备忘录存储原发器的哪些内部状态;防止原发器以外的其他对象访问备忘录。
- Originator(原发器)创建一个备忘录,用于记录当前时刻的内部状态;使用备忘录恢复内部状态。
- Caretaker(管理者)负责保存好备忘录;不能对备忘录的内容进行操作或检查
- 适用性:
- 必须保存一个对象在某一时刻(部分)状态,这样以后需要时它才能恢复到先前的状态
- 如果一个用接口来让其他对象直接得到这些状态,将会暴露对象的实现细节并破坏对象的封装性
观察者模式(Observer)
- 意图:定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖它的对象都得到通知并自动更新
- 结构:
- 方法和接口的含义:
- Subject(目标)知道它的观察者,可以有任意多个观察者观察同一个目标;提供注册和删除观察者对象的接口
- Observe(观察者)为那些在目标发生改变时需获得通知的独享定义一个更新接口
- ConcreteSubject(具体目标)将有关状态存入各ConcreteObserver对象;当它的状态发生改变时,向它的各个观察者发出通知
- ConcreteObserve(具体观察者)维护一个指向ConcreteSubject对象的引用,存储有关状态,这些状态应与目标的状态保持一致;实现Observe的更新接口,以使自身状态和目标状态保持一致
- 适用性:
- 当一个抽象模型有两个方面,其中一个方面依赖于另一个方面,将这两个在独立的对象中以使它们可以独自地改变和复用
- 当一个对象的改变需要同时改变其他对象,而不知道具体多少对象有待改变时
- 当一个对象必须通知其他对象,而它又不能假定其他对象说是谁,即不希望这些对象时紧耦合的
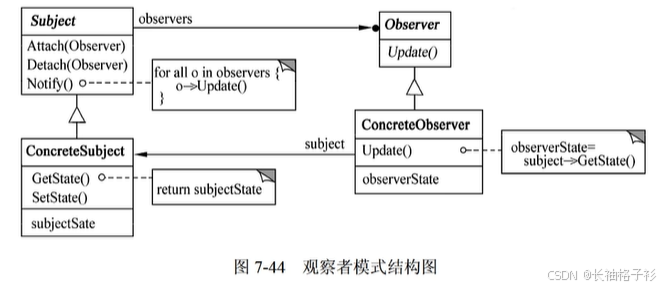
状态模式(State)
- 意图:允许一个对象在其内部状态改变时改变它的状态,对象看起来似乎修改了它的类
- 结构:
- 方法和接口的含义:
- Context(上下文)定义客户感兴趣的接口;维护一个ConcreteState子类的实例,这个实例定义了当前的状态
- State(状态)定义一个接口以封住哪个与Context的一个特定状态的相关行为
- ConcreteState(具体状态子类)每个子类实现与Context的一个状态相关的行为
- 适用性:
- 一个对象的行为决定它的状态,并且它需要在运行时刻根据状态改变它的行为
- 一个操作中含有大量分支的条件语句,且这些分支依赖于该对象的状态
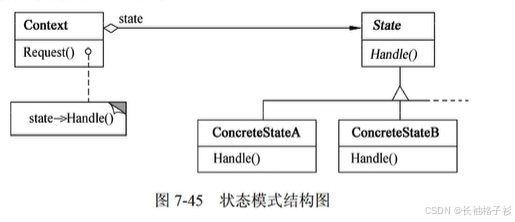
策略模式(Strategy)
- 意图:定义了一系列的算法,把它们一个个封装起来,并且使它们之间可以相互替换,此模式使得算法可以独立于使用它们的客户而变化。
- 结构:
- 方法和接口分含义:
- Strategy(策略)定义所有支持的算法的公共接口。Context使用这个接口来调用某ConcreteStrategy定义算法
- ConcreteStrategy(具体策略)以Strategy接口实现某具体算法
- Context(上下文)用一个ConcreteStrategy对象来配置;维护一个对Strategy对象的引用;可定义一个接口来让Strategy访问它的数据
- 适用性:
- 许多相关的类仅仅是行为有异
- 需要使用一个算法的不同变体
- 算法使用客户应该不知道的数据
- 一个类定义了多种行为,并且这些行为在这个类的操作中可以以多个条件语句的形式出现,将相关的条件分支移入它们各自的Strategy类中,以代替这些条件语句
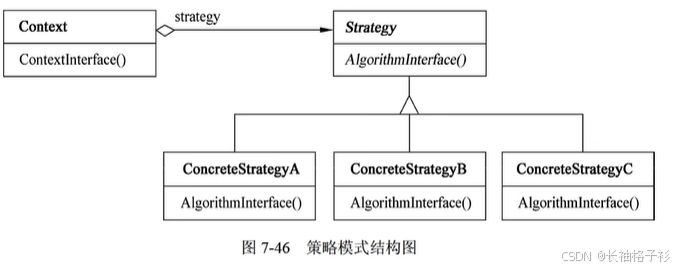
模版方法(Template Method)
- 意图:定义一个操作中的算法骨架,而将一些步骤延迟到子类中。Template Method 使得子类可以不改变一个算法的结构即重定义该算法的某些特定步骤
- 结构:
- 方法和接口的含义:
- AbstractClass(抽象类)定义抽象的原语操作,具体的子类将重定义它们以实现一个算法的各步骤;实现模板方法,顶一个算法的骨架,该模板方法不仅调用原语操作,也调用定义在AbstractClass或其他对象中的操作
- ConcreteClass(具体类)实现原语操作以完成算法中与特定子类相关的步骤
- 适用性:
- 一次性定义算法不变的部分,把可变的部分交给子类来实现
- 各子类公共的行为应被提取出来并集中到一个公共父类中,以避免代码重复
- 控制子类扩展
访问者模式(Visitor)
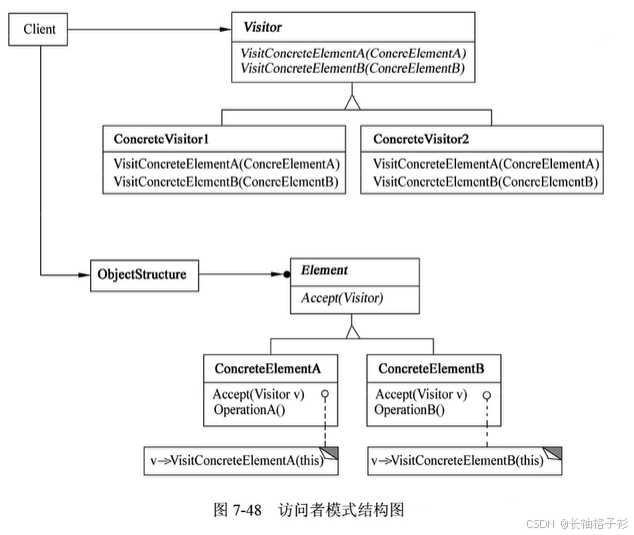
- 意图:表示一个作用于某对象结构中的元素的操作。它允许在不改变各元素的类的前提下定义作用于这些元素的新操作
- 结构:
- 方法和接口的含义:
- Visitor(访问者)为该对象结构中ConcreteElement 的每一个类声明一个Visit操作。该操作的名字和特征标识了发送Visit请求该该访问者的那个类,这使得访问者可以确定正被访问元素的具体类。这样防蚊子就可以通过该元素的特定接口直接访问它。
- ConcreteVisitor(具体访问者)实现每个有Visitor声明的操作,每个操作实现本算法的一部分,而该算法片段乃是对应于结构中对象的类。ConcreteVisitor为该算法提供了上下文并存储它的局部状态。这一状态常常在遍历的过程中积累结果
- Element(元素)定义以一个访问者为参数的Accept操作
- ConcreteElement(具体元素)实现以一个访问者为参数的Accept操作
- ObjectStructure(对象结构)能枚举它的元素,可以提供一个高层的接口允许该访问者访问它的元素;可以是一个组合或者一个集合,如一个列表或一个集合。
- 适用性:
- 一个对象结构包含很多类对象,它们有不同的接口,而用户想对这些对象实施一些依赖于具体类的操作
- 需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而又想要避免一些操作问题
- 定义对象结构的类很少改变,但经常需要在此结构上定义新的操作
23种设计模式的关键字归纳
- 创建型模式
- 工厂方法(Factory Method):创建对象、将对象创建和使用分离。
- 抽象工厂(Abstract Factory):创建一系列相关对象、产品族。
- 生成器(Builder):复杂对象构建、分步构建。
- 原型(Prototype):克隆对象、通过复制现有对象创建新对象。
- 单例(Singleton):唯一实例、全局访问点。
- 结构型模式
- 适配器(Adapter):接口转换、使不兼容接口兼容。
- 桥接(Bridge):将抽象部分与实现部分分离、多维度变化。
- 组合(Composite):整体 - 部分关系、树形结构。
- 装饰器(Decorator):动态添加功能、不改变接口。
- 外观(Facade):简化接口、子系统统一接口。
- 享元(Flyweight):共享对象、节省内存。
- 代理(Proxy):代替、控制访问。
- 行为型模式(橙色:重点考点)
- 责任链(Chain of Responsibility):请求传递、对象链处理。(请假案例:<7天找辅导员,<15天找院长,<30天找校长)
- 命令(Command):请求封装、解耦请求者和接收者。
- 解释器(Interpreter):语法解释、自定义语言、规则解析。
- 迭代器(Iterator):顺序访问、遍历集合元素。
- 中介者(Mediator):协调多个对象间的交互、减少对象间耦合。
- 备忘录(Memento):保存和恢复对象状态。
- 观察者(Observer):发布 - 订阅、对象间一对多依赖。
- 状态(State):对象状态改变、行为改变。
- 策略(Strategy):算法族、可互换的行为。
- 模板方法(Template Method):算法骨架、延迟实现部分步骤。
- 访问者(Visitor):在不改变元素类前提下添加新操作。
十、结构化开发
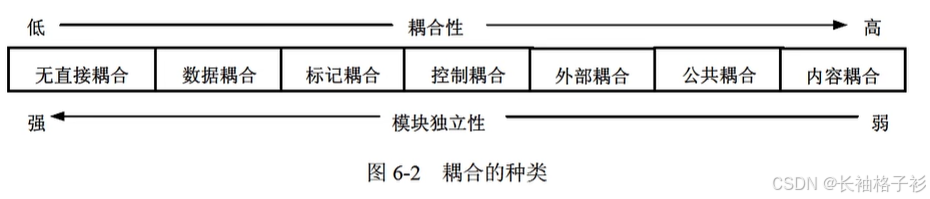
耦合
- 抽象
- 模块化:分而治之
- 信息隐蔽
- 模块独立:每一个模块完成一个子功能,取决于:接口的复杂程度、调用模块的方式以及通过结构的信息类型等
- 无直接耦合:没有直接关系,从属不同模块的控制与调用,不传递任何信息
- 数据耦合:传递数据值
- 标记耦合:传递的是数据结构
- 控制耦合:传递的是控制变量
- 外部耦合:通过软件之外的环境进行联结
- 公共耦合:通过一个公共数据环境相互作用
- 内容耦合:一个模块使用另一个模块的内部数据,非正常入口转入另一个模块内部
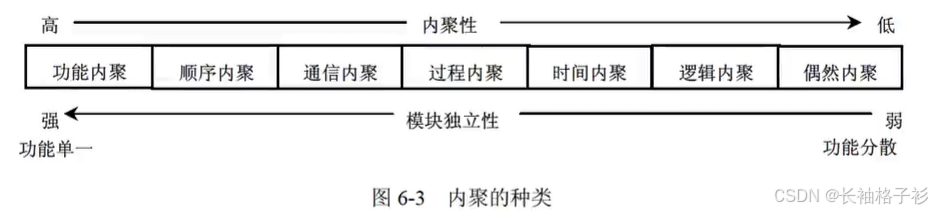
内聚
- 内聚:模块彼此结合程度的度量
- 偶然内聚(巧合内聚):模块内处理元素之间没有任何联系
- 逻辑内聚:执行若干个逻辑上相似的功能
- 时间内聚:同时执行的动作组合在一起
- 过程内聚:一个模块完成多个任务,这个任务必须按照指定的过程执行
- 通信内聚:在同一个数据结构上操作,处理相同的输入数据或者产生相同的输出数据
- 顺序内聚:密切相关,同一功能顺序执行
- 功能内聚:模块共同完成一个功能,缺一不可
高内聚,低耦合
设计原则
- 分解-协调原则
- 自顶向下原则
- 信息隐蔽、抽象原则
- 一致性原则
- 明确性原则:功能明确,接口明确,消除多重功能和无用接口(避免病态连接,消除接口复杂度)
- 高内聚,低耦合
- 模块的扇入系数和扇出系数要合理(3或4,不超过7)
- 模块规模适中
- 模块的作用应该在其控制范围之内
系统文档
系统文档的作用:
- 用户与系统分析人员在系统规划和系统分析阶段进行沟通(可行性研究报告,总体规划报告,系统开发合同,系统方案说明书)
- 系统开发人员与项目管理人员在项目期内沟通(系统开发计划,系统开发月报,系统开发总结)
- 系统测试人员与系统开发人员进行沟通(系统方案说明书,系统开发合同,系统设计说明书,测试计划)
- 系统开发人员与用户在系统运行期间进行沟通(文档运行系统)
- 系统开发人员与系统维护人员进行沟通(系统设计说明书,系统开发总结报告)
- 用户与维修人员在运行维护期间进行沟通(用户记载问题形成:问题报告,维护修改建议)
数据流图第一大题
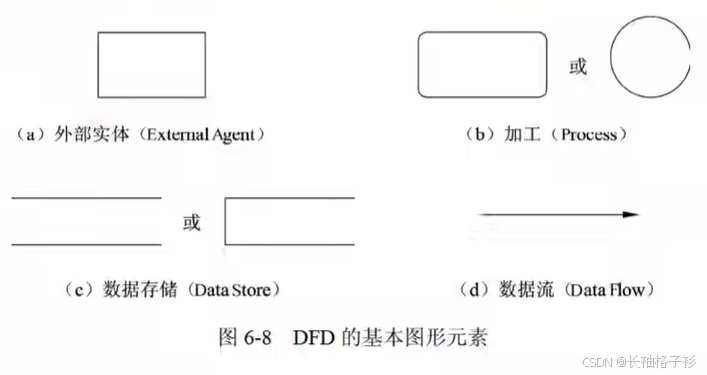
- 数据流图的图形元素:数据流、加工、数据存储、外部实体
- 外部系统:当前系统之外的人,物,外部实体
- 人:学生,老师,员工,主管,医生,客户,供应商.......
- 物:传感器,控制器,单车,车辆,采购部门.......
- 外部系统,支付系统,车辆交易系统,库存管理系统,道闸控制系统.......
- 数据存储:存储数据
- 存储加工的输入和输出数据
- 客户表,订单表,学生表
- 巴士列表文件,维修记录文件,课表文件
- 加工:将输入数处理后得到输出数据
- 一个加工至少有一个输入数据和一个输出数据流
- 加工只有输入没有输出称为:黑洞
- 加工只有输出没有输入称为:白洞
- 加工的数据不足以残生输出数据:灰洞
- 数据流的起点或者终点必须有一个是加工
- 问题一:实体E
- 加工名称对应题目中的序号说明
- 首先根据数据流少的进行分析
- 问题二:存储D
- 存储名,如果题目没有说明,那么就在名词后添加“表”或者“文件”
- 问题三:缺失数据流
- 方法一:父子图数据流平衡
- 方法二:加工既有输出数据流,也有输入数据流(至少有一个输出和一个输入数据流)
- 方法三:根据文字描述,去对比数据流
- 保证起点或者终点,必须有一个是加工
数据字典
数据字典:
- 数据流
- 数据项:组成数据流和数据存储的最小元素
- 数据存储
- 基本加工
加工逻辑描述方法:
- 结构化语言
- 判定表
- 判定树
信息安全
防火墙
- 作用:控制、审计、报警和反应
- 包过滤防火墙:数据包过滤,对用户完全透明,速度较快
- 优点:传入传出网络包实行低水平控制(检查:源地址,目的地址,协议,端口)
- 缺点:不能防范黑客攻击,不支持应用层协议,控制力度比较粗糙
- 应用代理网关防火墙:彻底隔断内网与外网的直接通信,内网对外网的访问变成防火墙对外网的访问,再由防火墙转发给用户,通信都要经过应用代理软件转发
- 优点:可检查应用层,传输层和网络层的协议特征,对数据包的检查能力强
- 缺点:难以配置,处理速度慢
- 状态检测技术防火墙:结合了上面两个防火墙的优点,提升了性能
- 防火墙工作层次越低(高),工作效率越高(低),安全性越低(高)
病毒
- 计算机病毒的特征:
- 传播性
- 隐蔽性
- 感染性
- 潜伏性
- 触发性
- 破坏性
- 病毒:
- Worm:蠕虫病毒:欢乐时光、熊猫烧香、红色代码、爱虫病毒、震网
- Trojan:特洛伊木马:有未知程序试图建立网络连接
- Backdoor:后门病毒
- Macro:宏病毒:感染的是文本文档、电子表格
- X卧底:通过木马形式感染智能手机
- CIH:系统病毒
- 木马软件:冰河
网络安全
- 安全协议:SSL传输层(443端口),TLS:SSL的升级版
- 安全连接:SSH
- 通道:HTTPS
- 电子邮件协议:
- 类型:MIME电子邮件附件扩展协议
- 安全:PGP基于RSA公钥加密协议
网关协议
- 内部网关协议:RIP、OSPF、IS-IS、IGRP、EIGRP
- 外部网关协议:BGP
计算机网络
网络设备
- 物理层:
- 中继器
- 集线器:看成一种多路的中继器
- 数据链路层:
- 网桥
- 交换机:多端口网桥
- 网络层:
- 路由器
- 应用层:
- 网关
- 能隔绝:说明每一个端口都是一个广播域(冲突域)
- 不能隔绝:说明所有端口组成一个广播域(冲突域)
广播域 冲突域 物理层 不能隔绝 不能隔绝 数据链路层
不能隔绝 能隔绝 网络层 能隔绝 能隔绝
协议簇
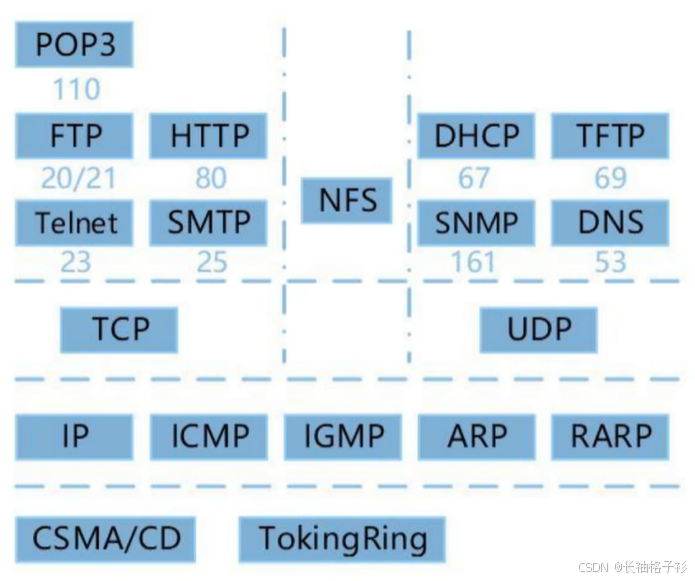
- 图2的记忆方法:
- TCP的上面所有带T字母的都是TCP + POP3(TFTP除外)
- UDP = 所有不带T字母的 + TFTP(POP3除外)
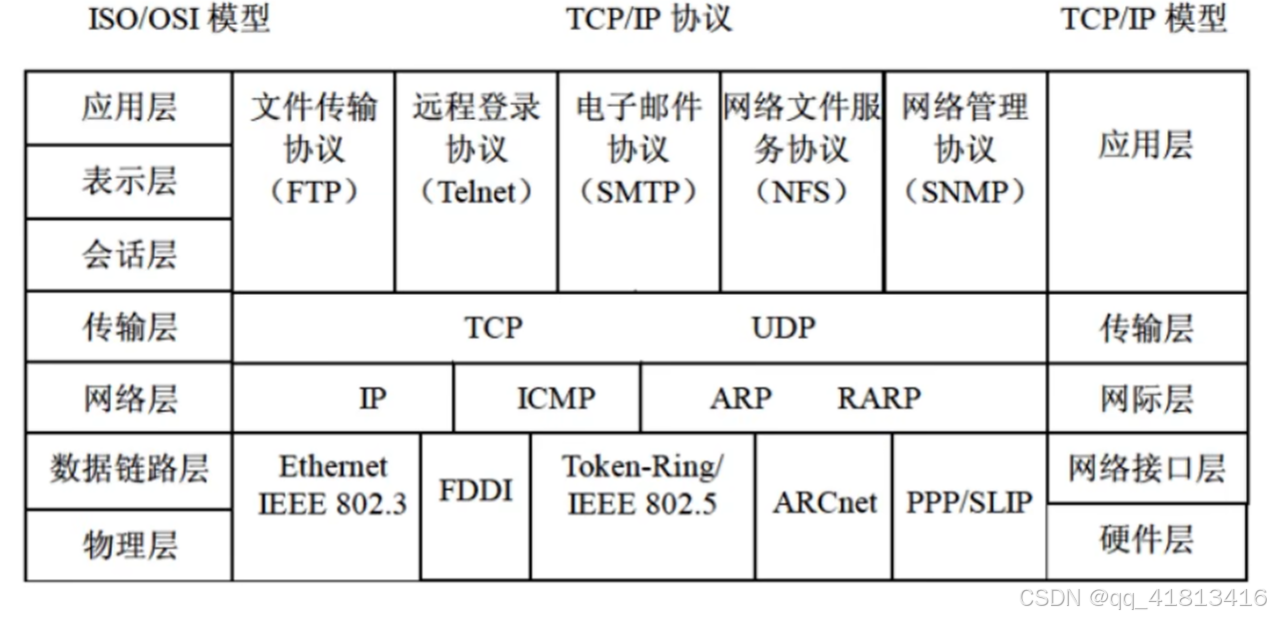
FTP协议
- 默认端口:20、21
- 20表示的是数据端口
- 21表示的是控制端口
应用层协议
利用TCP传输:
- POP3:110 端口
- FTP:20 数据、21 控制
- HTTP:80 端口
- Telnet:23 端口
- SMTP:25 端口
利用UDP传输:
- DHCP:67 端口
- TFTP:69 端口
- SNMP:161 端口
- DNS:53 端口
传输层协议
- TCP(三次握手):可靠的、面向连接的、全双工的数据传输服务
- 可靠传输、连接管理、差错校验和重传、流量控制、拥塞控制、端口寻址
- 流量控制采用:可变大小的滑动窗口协议
- UDP:不可靠、无连接的协议,错误检测功能要弱
- 端口寻址
网络层协议
- IP
- ICMP:利用IP报文发送
- ARP
- RARP
SMTP和POP3
- SMTP:传输电子邮件协议,传输ASCII码文本,传输文字附件(25 端口)
- POP3:接收邮件(110 端口)
- MIME:邮件附件扩展协议
- PEM:私密邮件
- 都采用:C/S模式(客户端 / 服务器模式)
ARP 和 RARP
- IP地址 --------> MAC地址:ARP
- 广播发送请求(ARP Request)IP
- 单播发送响应(ARP Response)MAC
- IP地址 <-------- MAC地址:RARP
DHCP(动态主机配置协议)
- DHCP的功能:集中的管理、分配IP地址,使网络主机动态获得IP地址、Gateway地址、DNS服务区地址,并能提升地址的使用率
- DHCP客户端可以从DHCP服务器获得本机IP地址、DNS服务器地址、DHCP服务器地址和默认网关地址
- Windows无效地址:169.254.X.X,租用失败时分配这个地址
- Linux无效地址:0.0.0.0
URL

浏览器
- DNS域名查询的次序是:本地的hosts文件 ----> 本地DNS缓存 ----> 本地DNS服务器 ----> 根域名服务器
- 主域名服务器的查询次序是:本地缓存 ----> 本地hosts文件 ----> 本地数据库 ----> 转发域名服务器
- 无痕浏览:下载文件会被保存
- HTTP请求的过程
- 浏览器中输入URL,并按下回车键
- 浏览器向DNS服务器发出域名解析请求并获得结果
- 根据目的IP地址和端口号,与服务器建立TCP连接
- 浏览器向服务器发送数据请求
- 服务器将网页数据发送给浏览器
- 通信完成,断开TCP连接
- 浏览器解析收到的数据并且显示
IP地址和子网掩码
- 地址的分类:A B C D E类地址


IPV6
IPV4是32位表示:
个主机
IPV6是128位表示:
个主机
无线网络
- 蓝牙:
- 覆盖范围:最小
- 通信距离:最短
Windows命令
- ipconfig
- ipconfig/release:DHCP客户端手工释放IP地址
- ipconfig/flushdns:清除本地DNS缓存内容
- ipconfig/displaydns:显示本地DNS内容
- ipconfig/registerdns:DNS客户端手工向服务器进行注册
- ipconfig:显示所有网络适配器的IP地址、子网掩码和缺省网关值
- ipconfig/all:显示所有网络适配器的完整TCP/IP配置信息,包括DHCP服务是否已启动
- ipconfig/renew:DHCP客户端手工向服务器刷新请求(重新申请IP地址)
- ipconfig/reset:重新设置
- ipconfig/reload:重新加载
- Ping:测试网络连通性,由近及远
- Ping 127.0.0.1
- Ping 本地IP
- Ping 默认网关
- Ping 远程主机
- Netstat:显示网络相关信息
- MSConfig:用于Windows配置的应用程序
- nslookup:域名查询Internet域名信息,诊断DNS工具
- tracert:确定路由
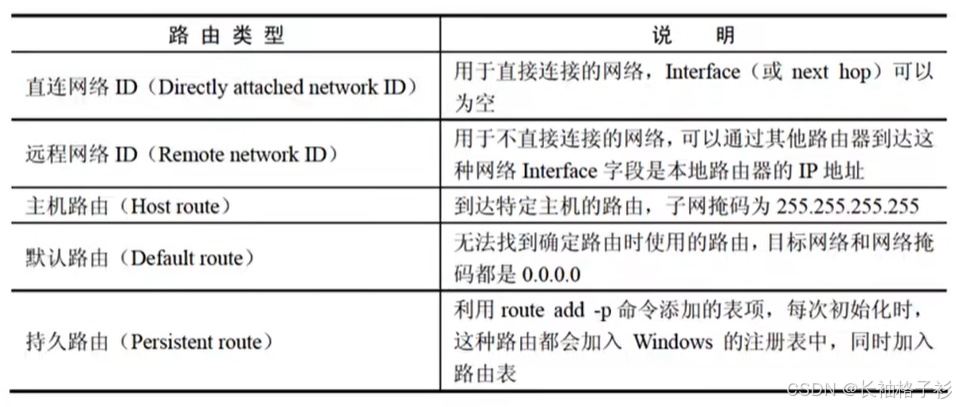
路由
- 查找顺序:
- 主机路由:到达特定主机。子网掩码为:255.255.255.255
- 直连网络:用于直接连接网络,远程网络:不直接连接网络
- 默认路由:无法找到确定路由时使用的路由,目标网络和网络掩码都是0.0.0.0
- 如果收到多条路由,比较路由的管理距离,选择最小的作为本机路由
- 路由策略:
- 静态路由:不更新
- 洪范式:不利用网络信息
- 随机路由:不利用网络信息(洪范式的简化)
- 自适应路由:依据最小代价实时更新路由
HTML
- background:背景图片
- bgcolor:整体文档的颜色
- alink:定义正在被点击的超链接的颜色
- vlink:定义超链接鼠标点击后的颜色
- <HR>:分割线
- <I>:倾斜
- <mailto>:定义邮箱地址的超级链接
- align:对齐方式
Linux
- 根目录:利用 “ \ ” 表示
- 修改文件权限:chmod命令
杂题知识点
- 三网合一:电信网、广播电视网、互联网
- 结构化布线系统:工作区子系统、水平布线子系统、管理子系统、干线子系统、设备间子系统、建筑群子系统
- 工作区子系统:终端设备到信息插座
- 水平布线子系统:楼层间的配线架到工作区之间
- 管理子系统:工作区信息插座到交换机端口之间
- 干线子系统:楼层设备之间的互连系统
- 设备间子系统:中央主配线架与各种设备之间
- 建筑群子系统:各个建筑之间
简称
CISC:复杂指令系统计算机
RISC:精简指令集计算机
VLSL:超大规模集成电路
SIMD:单指令多数据流(S 单 M 多)
VLIW:超长指令字
算数左移、逻辑右移、算数右移、逻辑右移区别
算数左移:高位移出,低位补0(要注意数据位最高位为1时极有可能溢出)
逻辑左移:二进制数整体左移一位(右边补零)
对于二级制的数值来说左移n位等于原来的数值乘以2的n次方
算数右移:符号位要一起移动,并且在左边补上符号位,也就是如果符号位是1就补1,符号位是0就补0
逻辑右移:逻辑右移很简单,只要将二进制数整体右移,左边补0即可
对于二进制的数值来说右移n位等于原来的数值除以2的n次方
用户权限
用户默认权限由高到低的顺序是:
- administration
- power user
- users
- everyone
防火墙
- 保护内部网络安全
- 对数据流进行分析和检查
- 对数据包的过滤
- 保护用户访问网络记录和服务器代理功能
- 防火墙工作层次越高,工作效率越低,安全性越高
DMZ:是为了解决防火墙安装后不能访问内部网络服务器的问题,而设置的一个缓冲区,放置公开设施:企业Web服务器,FTP服务器和论坛等
网络攻击
主动攻击:
- 重放
- IP地址欺骗
- 拒绝服务攻击
- 目的是使计算机网络无法提供正常服务
- 不断发请求
- DDoS是一种拒绝
- 修改数据库命令
- 系统干涉
被动攻击:
- 流量分析
- 会话拦截
安全需求
物理安全
- 机房安全
网络安全
- 入侵检测
系统安全
- 漏洞补丁管理
应用安全
- 数据库安全
病毒
- Worm:蠕虫病毒
- Trojan:特洛伊木马
- Backdoor:后门病毒
- Macro:宏病毒
蠕虫病毒:利用网络进行复制和传播,传播途径:网络、移动存储设备和电子邮件
- 红色代码
- 爱虫病毒
- 熊猫烧香
- Nimda病毒
- 爱丽兹病毒
- 欢乐时光
木马病毒:用于远程监控
- 冰河
- X卧底
- 特洛伊病毒
DOS攻击:
- SYN Flooding攻击
系统病毒:
- CIH
其他病毒:
- 宏病毒:感染对象是使用某些程序创建的文本文档、数据库、电子表格等文件