CCache使用指南
CCache 对于 arm-none-eabi-gcc 这类交叉编译工具链来说,是绝佳的加速工具,因为嵌入式项目的编译往往非常耗时。它能极大地提升你的开发效率。
下面我为你详细解释如何使用。
1. CCache 是什么?
CCache(Compile Cache)是一个编译器缓存。它的原理很简单:
- 第一次编译:CCache 会拦截编译命令,在真正调用编译器(如
arm-none-eabi-gcc)之前,它会根据源代码、编译选项等计算一个哈希值(唯一标识)。然后它把编译结果(.o文件)和这个哈希值一起缓存起来。 - 后续编译:当你再次编译完全相同的代码时,CCache 会通过哈希值发现缓存中存在可用的结果,于是直接使用之前缓存的对象文件,而不是再次调用编译器。这样就跳过了漫长的编译过程,速度极快。
对于嵌入式开发,你修改一两个文件后重新编译整个项目时,效果尤其明显。
2. 安装 CCache
首先,你需要在你的开发机器上(通常是 Linux 或 macOS)安装 CCache。
- Ubuntu/Debian:
sudo apt-get install ccache - Fedora/Red Hat:
sudo dnf install ccache - macOS (使用 Homebrew):
brew install ccache - Windows (MSYS2/Cygwin):
也可以通过相应的包管理器安装,但在 Windows 上更常见的嵌入式开发环境是 WSL 或 Linux虚拟机。
安装完成后,你可以在终端输入 ccache -V 来验证是否安装成功。
3. 为 arm-none-gcc 配置 CCache(三种方法)
核心思想是:让你的构建系统(如 Makefile, CMake)调用 ccache,而不是直接调用 arm-none-eabi-gcc。ccache 会再去调用真正的编译器。
这里推荐三种方法,从最佳到最灵活排列:
方法一:使用符号链接(推荐,最简单通用)
这是最省事的方法,对几乎所有构建系统都有效。
-
创建符号链接:
找一个在你的PATH环境变量中的目录,比如/usr/local/bin或~/bin。# 进入一个存放自定义命令的目录,例如 /usr/local/bin cd /usr/local/bin# 创建指向 ccache 的符号链接,并命名为你的编译器名 sudo ln -s $(which ccache) arm-none-eabi-gcc sudo ln -s $(which ccache) arm-none-eabi-g++ sudo ln -s $(which ccache) arm-none-eabi-cpp # 如果有其他语言编译器,如 arm-none-eabi-gfortran,也可以同样创建 -
调整 PATH 顺序(关键!):
确保/usr/local/bin在你的PATH中的优先级高于原来的工具链路径(如/usr/bin或/opt/gcc-arm/bin)。# 通常在你的 ~/.bashrc 或 ~/.zshrc 文件中修改 export PATH="/usr/local/bin:$PATH" export PATH="/path/to/your/gcc-arm/bin:$PATH" # 原来的工具链路径保持在后然后执行
source ~/.bashrc使配置生效。
原理:当你运行 arm-none-eabi-gcc 时,系统会先在 /usr/local/bin 中找到我们创建的符号链接,这个链接指向 ccache。ccache 被调用后,它会根据可执行文件的名称(arm-none-eabi-gcc)去你的 PATH 的后半部分找到真正的编译器并调用它。
方法二:在 Makefile 中直接修改变量
如果你的项目使用 Makefile,可以直接修改编译器变量。
修改前:
CC = arm-none-eabi-gcc
CXX = arm-none-eabi-g++
修改后:
CC = ccache arm-none-eabi-gcc
CXX = ccache arm-none-eabi-g++
非常简单直接。
方法三:在 CMake 项目中配置
对于 CMake,可以在调用 cmake 生成构建文件时指定编译器路径。
mkdir build && cd build
cmake -DCMAKE_C_COMPILER_LAUNCHER=ccache \-DCMAKE_CXX_COMPILER_LAUNCHER=ccache \..
make
或者,如果你希望永久生效,可以将这两行加入你的 CMakeLists.txt:
set(CMAKE_C_COMPILER_LAUNCHER ccache)
set(CMAKE_CXX_COMPILER_LAUNCHER ccache)
4. 验证 CCache 是否工作
配置好后,进行一次完整编译。然后使用 ccache -s 命令查看缓存统计信息。
$ ccache -s
Summary:Hits: 1234 # 缓存命中!直接使用了缓存,没有调用编译器Misses: 123 # 缓存未命中,需要真正编译Cache directory: /home/yourname/.ccachePrimary config: /home/yourname/.ccache/ccache.confSecondary config: /etc/ccache.conf
如果你看到 Hits 的数字不为 0,说明它正在正常工作!
第二次编译时,你会明显感觉到速度变快,特别是那些没有修改过的文件,几乎是瞬间完成。
5. 常用命令和配置
- 查看状态:
ccache -s - 清空缓存:
ccache -C(清除所有缓存) - 设置缓存大小:默认是 5GB,对于大型项目可能不够。你可以设置更大:
ccache -M 10G # 设置为 10GB - 显示详细配置:
ccache -p
总结
对于 arm-none-eabi-gcc 工具链,强烈推荐使用 CCache。
操作步骤建议:
- 安装
ccache。 - 采用 方法一(符号链接),一劳永逸,对所有项目生效。
- 编译你的项目。
- 运行
ccache -s确认有缓存命中 (Hits)。 - 享受极速编译的快乐!
当你需要清理缓存或调整大小时,记得使用上面提到的命令即可。
好的,这个问题非常核心,我来用一个详细的比喻和步骤分解来解释,保证你能彻底理解。
核心概念:“拦截”和“代理”
你可以把 CCache 想象成一个非常聪明的“点餐员”,而真正的编译器 arm-none-eabi-gcc 是后厨的“大厨”。
-
没有 CCache 时(正常情况):
- 你(构建系统)说:“我要一份水煮肉片(编译
main.c)。” - 构建系统直接跑去后厨,把订单(编译命令)给了大厨(
gcc)。 - 大厨每次都从头开始切肉、备菜、炒制(编译、汇编),很耗时。
- 你(构建系统)说:“我要一份水煮肉片(编译
-
有 CCache 时(我们的目标):
- 你(构建系统)还是说:“我要一份水煮肉片(编译
main.c)。” - 但现在,点餐员(CCache) 拦在了你和后厨之间。它先看了一下订单详情(源代码内容、编译命令参数等)。
- 点餐员有一个巨大的冰箱(缓存目录),里面放着很多做好的菜。它根据订单详情生成一个唯一的“菜名编号”(哈希值),然后去冰箱里找。
- 如果找到了(缓存命中):点餐员立刻把这份已经做好的菜(之前编译好的
.o文件)端给你。完全不需要麻烦后厨,速度极快。 - 如果没找到(缓存未命中):点餐员就把订单原封不动地交给后厨(
gcc)。大厨做好菜后,点餐员会留出一份放在冰箱里,然后再端给你。这样下次再点同样的菜,就能直接从冰箱拿了。
- 如果找到了(缓存命中):点餐员立刻把这份已经做好的菜(之前编译好的
- 你(构建系统)还是说:“我要一份水煮肉片(编译
所以,“让构建系统调用 ccache,而不是直接调用编译器”这句话的意思是:我们“骗”构建系统,让它以为自己是在和编译器对话,但实际上它是在和CCache这个“代理”或“中介”对话。CCache决定是直接给出答案(缓存命中)还是去请教真正的编译器(缓存未命中)。
如何实现这种“欺骗”?—— 三种方法的深入解读
方法一:符号链接(“李代桃僵”)
这是最巧妙的方法,在操作系统层面进行“欺骗”。
-
发生了什么:
- 我们在系统的一个优先路径(如
/usr/local/bin)里,创建了一个名为arm-none-eabi-gcc的“快捷方式”(符号链接),这个快捷方式指向的是ccache程序。 - 我们调整了
PATH变量,让系统在寻找命令时,先去/usr/local/bin找,再去真正的工具链目录(如/opt/gcc-arm/bin)找。
- 我们在系统的一个优先路径(如
-
执行流程:
- 当构建系统(Makefile)想要执行
arm-none-eabi-gcc -c main.c -o main.o时,它会在终端里输入这个命令。 - 系统根据
PATH的顺序,首先在/usr/local/bin里找到了一个叫arm-none-eabi-gcc的文件。 - 系统开始执行这个文件,但这个文件实际上是
ccache。 ccache被启动了,它一看:“哦?我是以arm-none-eabi-gcc这个名字被调用的。” 于是它就知道真正的编译器名字应该是arm-none-eabi-gcc。ccache开始工作(生成哈希值、检查缓存等)。如果需要调用真编译器,它会再去PATH的后面的路径里找到真正的arm-none-eabi-gcc来执行。
- 当构建系统(Makefile)想要执行
简单总结:我们做了一个假的编译器命令,它其实是ccache。系统先找到这个假的,由假的来负责决定是否调用真的。
方法二:修改 Makefile(“明确指定”)
这种方法更直接,在构建脚本的层面进行“欺骗”。
- 修改前:Makefile 直接给系统下命令:
请执行 arm-none-eabi-gcc ... - 修改后:Makefile 给系统下命令:
请执行 ccache arm-none-eabi-gcc ...
执行流程:
- 系统看到命令是
ccache arm-none-eabi-gcc ...。 - 它直接启动
ccache程序,并把arm-none-eabi-gcc ...这些参数全部传递给ccache。 ccache拿到这些参数后,就知道自己要代理的编译器是arm-none-eabi-gcc,然后开始它的标准工作流程。
简单总结:我们不骗系统了,我们明白地告诉系统,这次编译请让ccache来代理执行。
方法三:CMake 配置(“框架级配置”)
这和修改 Makefile 思想类似,只是告诉 CMake 这个高级构建系统:“在生成最终的构建脚本(如 Makefile)时,请在每一个编译器调用前都加上 ccache。”
-DCMAKE_C_COMPILER_LAUNCHER=ccache这个选项的意思就是:“启动C编译器时,请使用ccache这个程序来启动它。”
如何验证“欺骗”成功了?
完成配置后,你可以故意执行一次编译,然后输入命令:
ccache -s
查看输出结果。如果 Hits(命中)和 Misses(未命中)的数字不再是 0,就说明 CCache 已经开始工作并拦截了编译请求。
你还可以在编译时仔细观察输出。如果CCache命中,编译那条命令会执行得飞快,几乎是瞬间完成。
总结
| 方法 | 欺骗层面 | 优点 | 缺点 |
|---|---|---|---|
| 符号链接 | 系统级 | 一劳永逸,对所有项目生效,无需修改代码 | 需要调整PATH顺序,全局性修改 |
| 修改Makefile | 项目级 | 简单明了,只影响当前项目 | 每个项目都需要单独修改 |
| CMake配置 | 构建系统级 | 配置优雅,不污染项目代码 | 只适用于CMake项目 |
希望这个详细的解释能帮助你彻底理解 CCache 的工作机制!它就是这样一个强大的“编译缓存代理”。
非常好的问题!这几个问题正好问到了CCache的核心工作机制。我来逐一详细解释。
1. 缓存文件存到哪里了?
CCache有一个默认的缓存目录,同时它也允许你完全自定义这个路径。
-
默认目录:
- Linux / macOS:
~/.ccache(即你的用户家目录下的隐藏文件夹.ccache) - Windows:
%LOCALAPPDATA%\ccache(如果通过MSYS2安装,也可能在类似C:\Users\<YourUserName>\.ccache的位置)
- Linux / macOS:
-
如何查看当前配置的缓存目录:
只需在终端运行:ccache -s在输出信息的顶部,你就可以看到
Cache directory这一行,后面就是当前使用的完整路径。 -
如何修改缓存目录:
你可以通过环境变量CCACHE_DIR来设置一个新的路径:# 在你的 ~/.bashrc 或 ~/.bash_profile 中设置 export CCACHE_DIR="/path/to/your/custom/cache/directory"之后执行
source ~/.bashrc使其生效。
2. 是不是很占用空间?
是的,它会占用磁盘空间,但它是“智能”且“可控”的,通常不会成为问题。
-
它存了什么:CCache存储的不是原始的源代码文件,而是编译后的结果对象文件(.o文件) 和对应的哈希值映射。每个不同的编译命令和源代码组合都会产生一个独立的缓存条目。
-
空间管理机制:
- 默认大小限制:CCache默认会设置一个缓存大小上限(通常是 5GB)。当缓存总量接近这个限制时,CCache会自动清理掉那些最久未使用的缓存文件,以确保总大小不超过限制。
- 手动调整大小:你可以很方便地修改这个上限。例如,如果你有一个大型项目,可以设置为20GB或更大:
# 将缓存大小设置为 20G ccache -M 20G - 预编译头文件:对于C++等使用预编译头文件(PCH)的项目,缓存可能会变得比较大,因为PCH文件本身很大。但CCache对PCH的处理同样能带来巨大的编译加速。
-
空间 vs. 时间的权衡:用几十GB的磁盘空间(在现在动辄512GB/1TB的硬盘上只占很小比例)来换取数倍甚至数十倍的编译速度提升,这对于开发者来说几乎总是一笔非常划算的买卖。等待编译的时间才是更宝贵的资源。
3. 关于“在调用真正编译器之前接管”的详细过程
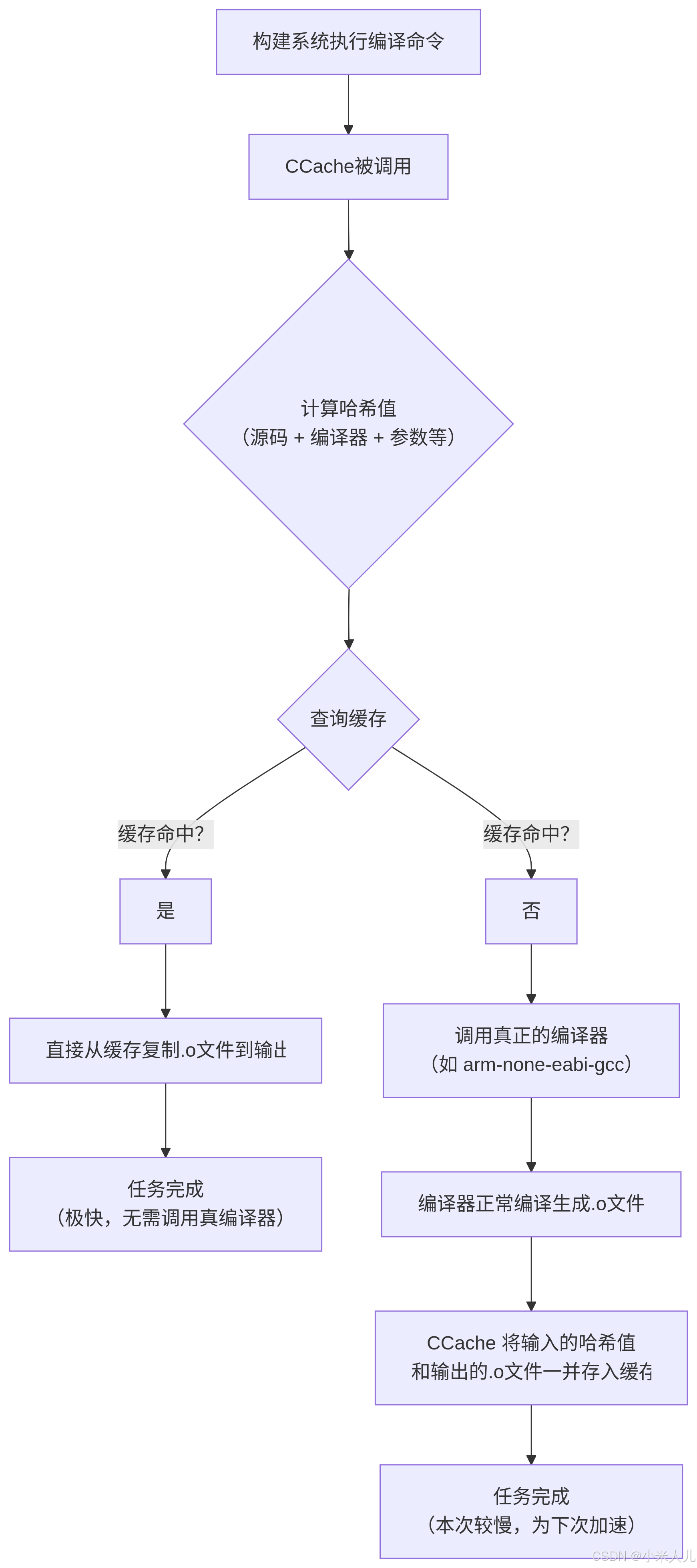
你问到了最精妙的部分。让我用一个流程图和步骤分解来详细说明这个“接管”过程:
flowchart TDA[构建系统执行编译命令] --> B[CCache被调用]B --> C{计算哈希值<br>(源码 + 编译器 + 参数等)}C --> D{查询缓存}D -- 缓存命中? --> E[是]D -- 缓存命中? --> F[否]E --> G[直接从缓存复制.o文件到输出位置]G --> H[任务完成<br>(极快,无需调用真编译器)]F --> I[调用真正的编译器<br>(如 arm-none-eabi-gcc)]I --> J[编译器正常编译生成.o文件]J --> K[CCache 将输入的哈希值<br>和输出的.o文件一并存入缓存]K --> L[任务完成<br>(本次较慢,为下次加速)]
这个过程的关键在于:
- 哈希值是唯一的“身份证”:CCache通过计算一个几乎不可能重复的哈希值来唯一标识一次编译任务。只要源代码、编译器路径、命令行参数(包括
-I、-D等所有选项)中的任何一项发生改变,哈希值都会完全不同,从而不会导致错误的缓存命中。这保证了正确性。 - 只有在必要时才调用:只有在“缓存未命中”这条路径上,真正的编译器才会被启动。一旦命中,整个过程就是在复制文件,速度极快。
- 对构建系统完全透明:无论走哪条路径,最终的结果都是一个正确的
.o文件出现在构建系统期望的位置。构建系统完全不知道背后是CCache处理的结果还是直接编译的结果。
所以,CCache不仅仅是一个简单的“代理”,它是一个带有高速缓存和智能查询机制的编译器前端,完美地优化了“编译”这个耗时操作。
说得非常好,你提供的这段描述是 ccache 工作的核心机制。我来帮你一步步拆解,让你彻底明白。
你的困惑点在于:ccache 伪装成编译器后,它自己怎么知道该去调用真正的 gcc 还是 g++ ?又是如何找到那个真正的编译器的?
让我们通过一个具体的例子,模拟一下当你执行 gcc -c hello.c -o hello.o 时发生的事情。
步骤 1:设置环境(和你描述的完全一样)
- 你把
ccache二进制文件放到了/usr/local/bin/目录下。 - 你在同一个目录下创建了两个符号链接(Symbolic Links):
gcc->ccacheg++->ccache
- 你的
PATH环境变量是/usr/local/bin:/usr/bin:/bin。这意味着系统会优先在/usr/local/bin里寻找命令。
现在,系统的状态是这样的:
/usr/local/bin/
├── ccache # 真正的 ccache 可执行文件
├── gcc -> ccache # 指向 ccache 的链接
└── g++ -> ccache # 指向 ccache 的链接/usr/bin/
├── gcc # 系统真正的 GNU C 编译器
└── g++ # 系统真正的 GNU C++ 编译器
步骤 2:你在终端输入命令 gcc -c hello.c -o hello.o
- Shell 查找命令:Shell 沿着
PATH的顺序寻找名为gcc的程序。它首先在/usr/local/bin里找到了!于是它执行这个文件。 - 执行的是谁?:由于
/usr/local/bin/gcc是一个指向ccache的符号链接,所以实际被加载到内存中执行的是/usr/local/bin/ccache这个程序。 - 关键点:参数传递:Shell 会告诉程序:“你的名字是
gcc”,并且把这些参数-c,hello.c,-o,hello.o传递给你。在程序内部,这些信息通过main函数的参数argv来获取:argv[0]="/usr/local/bin/gcc"(这就是被调用时的名称,即你的“马甲”)argv[1]="-c"argv[2]="hello.c"argv[3]="-o"argv[4]="hello.o"
步骤 3:ccache 开始工作
- 识别“马甲”:
ccache程序启动后,第一件事就是查看argv[0]。它发现自己是被人以gcc的名字调用的。 - 决定要冒充谁:
ccache心想:“哦,用户想调用的是gcc,那我得去找到一个真正的gcc来干活,或者用我之前缓存的内容。” - 寻找真正的编译器(回答你的核心问题):
ccache现在知道它需要找一个名为gcc的真实编译器。- 它也会按照
PATH环境变量的顺序(/usr/local/bin:/usr/bin:/bin)去寻找名为gcc的程序。 - 但是!它有一个非常重要的智能逻辑:它会跳过所有指向它自己的链接!
- 寻找过程:
- 在
/usr/local/bin里找到了gcc,但它发现这个gcc文件指向自己(ccache)。它跳过这个,不选它。 - 继续在
PATH的下一个目录/usr/bin里寻找。找到了!/usr/bin/gcc是一个真正的、独立的编译器文件,不是指向自己的链接。
- 在
- 于是,
ccache就确定了真正的编译器路径是/usr/bin/gcc。
步骤 4:ccache 的核心逻辑
- 计算哈希:
ccache会根据以下信息计算一个唯一的哈希键(Key):- 真正的编译器路径 (
/usr/bin/gcc) - 编译器参数 (
-c hello.c -o hello.o) - 源文件内容 (
hello.c的代码) - 其他可能影响编译结果的选项(如
-I,-D等)
- 真正的编译器路径 (
- 检查缓存:它拿着这个 Key 去自己的缓存目录里查找,看是否已经存在对应的编译结果(比如
hello.o)。 - 两个结果:
- 缓存命中(Hit):如果找到了,
ccache会直接将缓存中的.o文件复制到当前目录,伪装成刚刚编译完成的样子。这个过程极快,几乎是瞬间完成。 - 缓存未命中(Miss):如果没找到,
ccache就会真正地调用/usr/bin/gcc -c hello.c -o hello.o,让真正的编译器完成编译工作。然后,它会将编译结果(输出的.o文件)和刚才计算的 Key 一起保存到缓存中,以备下次使用。
- 缓存命中(Hit):如果找到了,
总结与类比
你可以把 ccache 想象成一个非常聪明的“接待员”或“代理人”。
- 你本来想直接联系
gcc专家(编译器)帮你干活(编译)。 - 但你的电话本(
PATH)第一个号码是代理人的号码(/usr/local/bin/gcc->ccache)。 - 代理人(
ccache)接了你打给gcc的电话(通过argv[0]知道你是来找gcc的)。 - 代理人翻看自己的电话本(
PATH),但他会跳过所有他自己的分机号(跳过指向自己的链接),最终找到了真正的gcc专家的直接号码(/usr/bin/gcc)。 - 代理人检查自己的档案(缓存),看是否处理过完全相同的任务。
- 处理过:他直接把旧结果发给你,省去了打扰专家的麻烦。(高速缓存命中)
- 没处理过:他打电话给真正的
gcc专家,让他处理,然后把结果记入档案再发给你。(缓存未命中)
所以,ccache 通过 argv[0] 知道它应该扮演谁(gcc 还是 g++),然后通过重新搜索 PATH 并跳过自身,来找到它要扮演的那个角色的“真身”。这个设计非常巧妙,使得它能够无缝地插入到任何构建系统中,而不需要修改构建脚本本身。
参考:一文读懂编译加速工具ccache