Bert学习笔记
1、Bert的嵌入层(输入表示)
WordPiece(子词分词方法)+ 绝对位置编码 + Segment Embedding
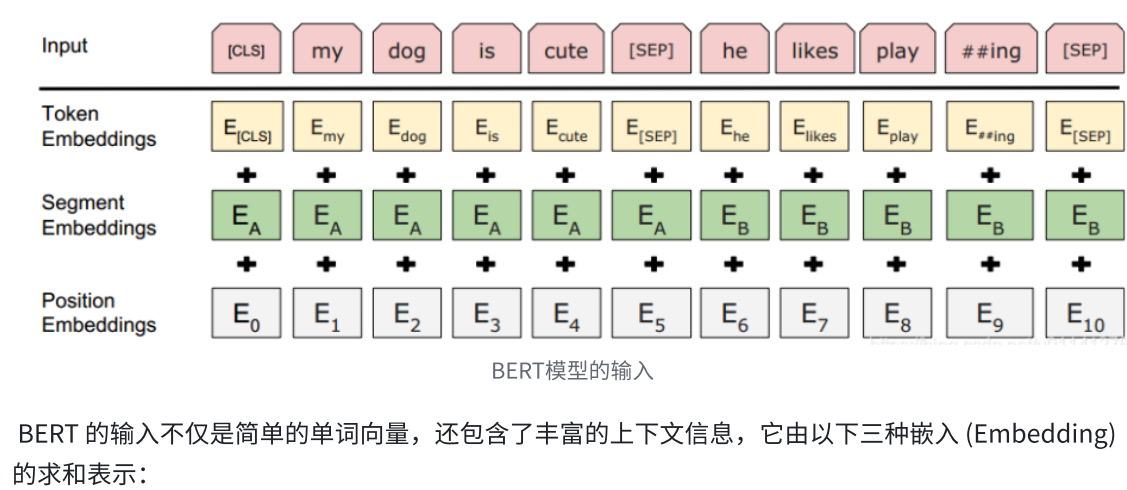
WordPiece Embedding :BERT 使⽤ WordPiece 作为分词⽅法,将单词划分为⼦词单元。这
种处理⽅式既能处理未知词汇,⼜能提⾼模型的灵活性和泛化能⼒。例如,罕⻅或不规则单词会被
分成更常⻅的⼦词单位,进⽽能够在训练中更好地学习到词汇语义。

笔记见:Tokenizer训练方式和常见的分词模型-CSDN博客
位置嵌⼊ (Position Embedding) :由于 BERT 只使⽤ Transformer 的编码器部分,并不依
赖于序列化结构(如 RNN 或 LSTM),因此它⽆法从输⼊序列中⾃然地获取位置信息。为了弥补这⼀点,BERT 通过位置嵌⼊为每个词汇添加了位置特征,使模型能够感知词汇在序列中的相对位
置。BERT 初始化了⼀个位置嵌⼊矩阵,并在训练过程中学习这些位置向量。
段落嵌⼊ (Segment Embedding) :在 BERT 中,输⼊通常是两个句⼦拼接⽽成,特别是在句
⼦预测任务 (Next Sentence Prediction, NSP) 中。因此,BERT 为输⼊中的每个 token 添加⼀个
段落嵌⼊,⽤来区分句⼦ A 和句⼦ B,帮助模型更好地理解句⼦之间的关系。
最终,BERT 的输⼊是这三种嵌⼊的求和:wordpiece embedding + position embedding +
segment embedding,这样能够同时捕捉词汇、位置、以及句⼦间的信息。
2、Bert的编码器层(Transformer的Encoder)
BERT 的主要结构是基于 Transformer 的编码器部分,通过堆叠多层编码器来实现深度语义学
习。Transformer 编码器包含⼏个核⼼部分:multi-head-Attention + Layer Normalization + feedforword + Layer Normalization 叠加产⽣,BERT的每⼀层由⼀个这样的encoder单元构成。
3、预训练任务 (Pre-training Tasks)
BERT 在⼤规模语料上通过⾃监督学习进⾏了预训练,主要包括两个任务:

4、BERT模型特点
