第2.1节:AI大模型之GPT系列(GPT-3、GPT-4、GPT-5)

🏆作者简介,黑夜开发者,CSDN领军人物,全栈领域优质创作者✌,CSDN博客专家,阿里云社区专家博主,2023年6月CSDN上海赛道top4。
🏆数年电商行业从业经验,历任核心研发工程师,项目技术负责人。
🏆本文已收录于PHP专栏:智能时代:人人都要知道的AI课
🎉欢迎 👍点赞✍评论⭐收藏
各位朋友大家好,欢迎来到我的最新专栏《智能时代:人人都要知道的AI课》,人工智能已经不再是科幻电影中的遥远概念,而是正在深刻改变我们每个人的生活。从ChatGPT的爆火,到自动驾驶的普及,从智能家居的便利,到医疗AI的突破——AI技术正在以惊人的速度重塑我们的世界,今天我们讲【GPT系列(GPT-3、GPT-4、GPT-5)】。
文章目录
- 🚀一、引言
- 🚀二、GPT系列概述
- 🔎2.1 什么是GPT
- 🔎2.2 GPT系列发展历程
- 🔎2.3 GPT系列的技术架构
- 🚀三、GPT-3详解
- 🔎3.1 GPT-3的技术特点
- 🔎3.2 GPT-3的核心能力
- 🔎3.3 GPT-3的应用场景
- 🔎3.4 GPT-3的局限性
- 🚀四、GPT-4详解
- 🔎4.1 GPT-4的技术突破
- 🔎4.2 GPT-4的核心特性
- 🔎4.3 GPT-4的应用创新
- 🔎4.4 GPT-4的改进与挑战
- 🚀五、GPT-5展望
- 🔎5.1 GPT-5的预期特性
- 🔎5.2 GPT-5的技术挑战
- 🔎5.3 GPT-5的发展方向
- 🚀六、GPT系列的技术原理
- 🔎6.1 Transformer架构
- 🔎6.2 预训练与微调
- 🔎6.3 推理机制
- 🚀七、GPT系列的应用实践
- 🔎7.1 API使用示例
- 🔎7.2 实际应用案例
- 🔎7.3 最佳实践
- 🚀八、GPT系列的商业影响
- 🔎8.1 产业变革
- 🔎8.2 商业模式
- 🔎8.3 竞争格局
- 🚀九、未来展望
- 🔎9.1 技术发展趋势
- 🔎9.2 社会影响
- 🔎9.3 发展建议
- 🚀十、总结
🚀一、引言
GPT(Generative Pre-trained Transformer)系列是OpenAI开发的一系列大型语言模型,它们代表了自然语言处理领域的重要里程碑。从GPT-3的惊艳亮相,到GPT-4的多模态能力,再到GPT-5的预期突破,GPT系列正在不断推动AI技术的边界。本文将深入解析GPT系列的发展历程、技术特点和应用场景。

🚀二、GPT系列概述
🔎2.1 什么是GPT
GPT(Generative Pre-trained Transformer)是OpenAI开发的一系列基于Transformer架构的大型语言模型。
核心特点:
- 生成式:能够生成连贯的文本内容
- 预训练:在大规模文本数据上进行预训练
- Transformer架构:基于注意力机制的神经网络架构
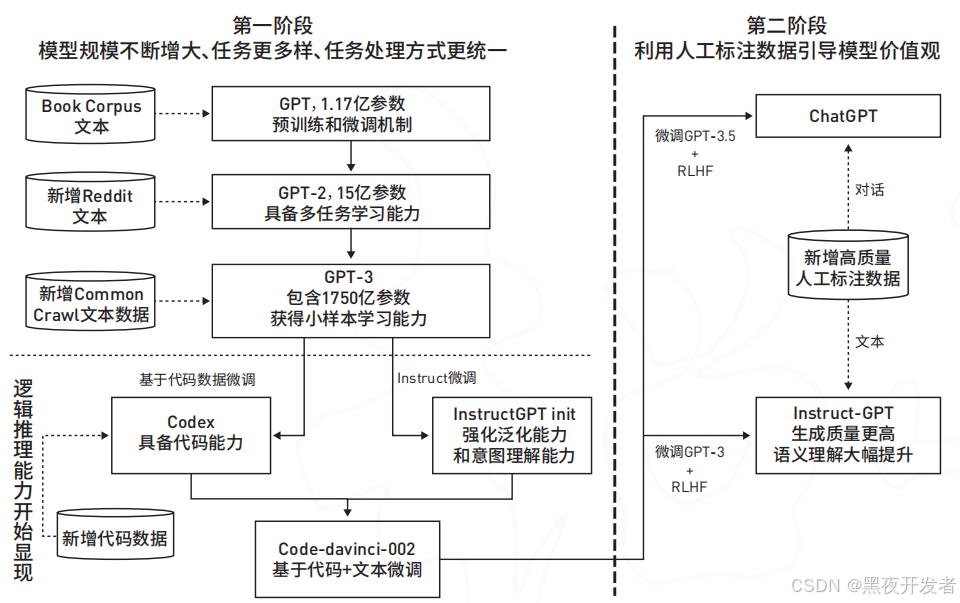
🔎2.2 GPT系列发展历程
GPT-1(2018年):
- 参数量:1.17亿
- 训练数据:BooksCorpus数据集
- 主要贡献:证明了预训练语言模型的有效性
GPT-2(2019年):
- 参数量:15亿
- 训练数据:WebText数据集
- 主要贡献:展示了大规模模型的生成能力
GPT-3(2020年):
- 参数量:1750亿
- 训练数据:Common Crawl、Wikipedia等
- 主要贡献:少样本学习能力,API商业化
GPT-4(2023年):
- 参数量:未公开(估计万亿级别)
- 训练数据:多模态数据
- 主要贡献:多模态能力,更强的推理能力
GPT-5(预期):
- 参数量:更大规模
- 训练数据:更丰富的数据源
- 预期能力:更强的通用智能
🔎2.3 GPT系列的技术架构
基础架构:
输入文本 → Tokenization → Transformer Blocks → 输出概率分布
核心组件:
- Tokenization:将文本转换为数字序列
- Positional Encoding:位置编码
- Multi-head Attention:多头注意力机制
- Feed-forward Networks:前馈神经网络
- Layer Normalization:层归一化
🚀三、GPT-3详解
🔎3.1 GPT-3的技术特点
模型规模:
- 参数量:1750亿
- 层数:96层
- 注意力头数:96个
- 上下文窗口:2048个token
训练数据:
- Common Crawl(60%)
- WebText2(22%)
- Books1(8%)
- Books2(8%)
- Wikipedia(3%)
训练成本:
- 计算资源:数千个GPU
- 训练时间:数月
- 训练成本:数百万美元
🔎3.2 GPT-3的核心能力
少样本学习(Few-shot Learning):
输入:翻译英语到法语:
sea otter => loutre de mer
cheese => fromage
milk => lait
water => eau
beer => bière输出:wine => vin
零样本学习(Zero-shot Learning):
输入:将以下句子翻译成法语:
The cat sat on the mat.输出:Le chat s'est assis sur le tapis.
代码生成能力:
# 输入:写一个Python函数计算斐波那契数列
def fibonacci(n):if n <= 1:return nreturn fibonacci(n-1) + fibonacci(n-2)
🔎3.3 GPT-3的应用场景
文本生成:
- 文章写作
- 故事创作
- 邮件撰写
- 内容营销
代码编程:
- 代码补全
- 函数生成
- 调试帮助
- 文档生成
语言翻译:
- 多语言翻译
- 风格转换
- 语法检查
- 文本润色
问答系统:
- 知识问答
- 数学计算
- 逻辑推理
- 创意解答
🔎3.4 GPT-3的局限性
技术限制:
- 上下文窗口有限(2048 tokens)
- 训练数据截止到2021年
- 可能产生幻觉(hallucination)
- 缺乏实时信息
安全风险:
- 可能生成有害内容
- 存在偏见问题
- 隐私泄露风险
- 滥用可能性
🚀四、GPT-4详解
🔎4.1 GPT-4的技术突破
多模态能力:
- 文本理解:更强的语言理解能力
- 图像理解:能够理解和分析图像
- 代码生成:更准确的代码生成
- 逻辑推理:更强的推理能力
模型规模:
- 参数量:未公开(估计万亿级别)
- 训练数据:多模态数据
- 上下文窗口:32K tokens(GPT-4 Turbo)
- 训练成本:数亿美元
🔎4.2 GPT-4的核心特性
更强的推理能力:
问题:一个房间里有3个人,每个人有2只手,每只手有5个手指。
问:房间里总共有多少个手指?GPT-4回答:
让我们逐步计算:
1. 人数:3人
2. 每人手数:2只手
3. 每只手手指数:5个手指
4. 总手指数 = 3 × 2 × 5 = 30个手指答案:房间里总共有30个手指。
图像理解能力:
- 图像描述
- 图像分析
- 视觉问答
- 图像推理
代码能力提升:
# GPT-4能够生成更复杂的代码
def quicksort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr) // 2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quicksort(left) + middle + quicksort(right)
🔎4.3 GPT-4的应用创新
创意写作:
- 小说创作
- 诗歌写作
- 剧本编写
- 广告文案
学术研究:
- 文献综述
- 实验设计
- 数据分析
- 论文写作
商业应用:
- 市场分析
- 商业计划
- 客户服务
- 产品设计
教育辅助:
- 个性化教学
- 作业辅导
- 知识解释
- 学习规划
🔎4.4 GPT-4的改进与挑战
技术改进:
- 更强的推理能力
- 更好的事实准确性
- 减少幻觉现象
- 更强的安全性
持续挑战:
- 训练数据质量
- 偏见问题
- 安全对齐
- 成本控制
🚀五、GPT-5展望
🔎5.1 GPT-5的预期特性
技术预期:
- 更大规模:参数量进一步增加
- 更强能力:通用智能能力提升
- 多模态增强:更丰富的模态支持
- 实时学习:持续学习能力
应用预期:
- AGI接近:更接近通用人工智能
- 工具使用:更强的工具调用能力
- 自主性:更强的自主决策能力
- 创造力:更强的创造性思维
🔎5.2 GPT-5的技术挑战
技术挑战:
- 计算资源:需要更强大的计算基础设施
- 数据质量:高质量训练数据的获取
- 训练效率:更高效的训练方法
- 安全对齐:确保AI的安全性
伦理挑战:
- 就业影响:对就业市场的影响
- 社会公平:确保技术的公平性
- 隐私保护:保护用户隐私
- 责任归属:AI行为的责任归属
🔎5.3 GPT-5的发展方向
技术方向:
- 架构创新:新的神经网络架构
- 训练方法:更高效的训练策略
- 推理优化:更快的推理速度
- 多模态融合:更好的多模态理解
应用方向:
- 个性化:更强的个性化能力
- 专业化:特定领域的专业化
- 协作性:人机协作能力
- 创造性:创造性任务处理
🚀六、GPT系列的技术原理
🔎6.1 Transformer架构
核心组件:
class TransformerBlock(nn.Module):def __init__(self, d_model, n_heads):super().__init__()self.attention = MultiHeadAttention(d_model, n_heads)self.feed_forward = FeedForward(d_model)self.norm1 = LayerNorm(d_model)self.norm2 = LayerNorm(d_model)def forward(self, x):# 自注意力机制attn_output = self.attention(x)x = self.norm1(x + attn_output)# 前馈网络ff_output = self.feed_forward(x)x = self.norm2(x + ff_output)return x
注意力机制:
def attention(Q, K, V, mask=None):# 计算注意力分数scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)# 应用softmaxattention_weights = F.softmax(scores, dim=-1)# 计算输出output = torch.matmul(attention_weights, V)return output
🔎6.2 预训练与微调
预训练过程:
大规模文本数据 → 自监督学习 → 语言模型
微调过程:
预训练模型 + 任务数据 → 监督学习 → 任务专用模型
指令微调:
预训练模型 + 指令数据 → 指令微调 → 指令遵循模型
🔎6.3 推理机制
自回归生成:
def generate_text(model, prompt, max_length=100):tokens = tokenizer.encode(prompt)for _ in range(max_length):# 获取模型预测outputs = model(torch.tensor([tokens]))next_token_logits = outputs.logits[:, -1, :]# 采样下一个tokennext_token = torch.multinomial(F.softmax(next_token_logits, dim=-1), 1)tokens.append(next_token.item())if next_token.item() == tokenizer.eos_token_id:breakreturn tokenizer.decode(tokens)
温度采样:
def temperature_sampling(logits, temperature=0.7):# 应用温度logits = logits / temperature# 采样probs = F.softmax(logits, dim=-1)next_token = torch.multinomial(probs, 1)return next_token
🚀七、GPT系列的应用实践
🔎7.1 API使用示例
OpenAI API调用:
import openai# 设置API密钥
openai.api_key = "your-api-key"# 文本生成
response = openai.ChatCompletion.create(model="gpt-4",messages=[{"role": "system", "content": "你是一个有用的助手。"},{"role": "user", "content": "请解释什么是机器学习?"}],max_tokens=500,temperature=0.7
)print(response.choices[0].message.content)
流式输出:
def stream_chat(messages):response = openai.ChatCompletion.create(model="gpt-4",messages=messages,stream=True)for chunk in response:if chunk.choices[0].delta.content:print(chunk.choices[0].delta.content, end='')
🔎7.2 实际应用案例
智能客服:
def customer_service_bot(user_message):system_prompt = """你是一个专业的客服代表,请用友好、专业的态度回答用户问题。如果遇到无法解决的问题,请礼貌地转接人工客服。"""response = openai.ChatCompletion.create(model="gpt-4",messages=[{"role": "system", "content": system_prompt},{"role": "user", "content": user_message}])return response.choices[0].message.content
代码助手:
def code_assistant(code, question):prompt = f"""请分析以下代码并回答问题:代码:{code}问题:{question}请提供详细的解释和建议。"""response = openai.ChatCompletion.create(model="gpt-4",messages=[{"role": "user", "content": prompt}])return response.choices[0].message.content
内容创作:
def content_generator(topic, style, length):prompt = f"""请以{style}的风格,写一篇关于{topic}的文章,长度约{length}字。要求:1. 内容准确、有趣2. 结构清晰3. 语言流畅4. 适合目标读者"""response = openai.ChatCompletion.create(model="gpt-4",messages=[{"role": "user", "content": prompt}])return response.choices[0].message.content
🔎7.3 最佳实践
提示工程:
# 好的提示示例
good_prompt = """
请扮演一个经验丰富的Python开发者,帮我优化以下代码:代码:
def fibonacci(n):if n <= 1:return nreturn fibonacci(n-1) + fibonacci(n-2)要求:
1. 提高性能
2. 添加错误处理
3. 添加文档字符串
4. 考虑边界情况
"""# 不好的提示示例
bad_prompt = "优化这个代码"
错误处理:
def safe_api_call(prompt, max_retries=3):for attempt in range(max_retries):try:response = openai.ChatCompletion.create(model="gpt-4",messages=[{"role": "user", "content": prompt}],timeout=30)return response.choices[0].message.contentexcept Exception as e:if attempt == max_retries - 1:raise etime.sleep(2 ** attempt) # 指数退避
🚀八、GPT系列的商业影响
🔎8.1 产业变革
软件开发:
- 代码生成:自动化代码编写
- 调试辅助:智能错误诊断
- 文档生成:自动生成技术文档
- 测试用例:自动生成测试代码
内容创作:
- 文章写作:自动化内容创作
- 营销文案:个性化营销内容
- 翻译服务:高质量多语言翻译
- 创意设计:创意内容生成
客户服务:
- 智能客服:24/7在线服务
- 个性化推荐:智能产品推荐
- 问题解答:快速准确的问题解答
- 情感分析:客户情感识别
🔎8.2 商业模式
API服务:
- 按使用量收费:基于token数量计费
- 订阅模式:固定月费或年费
- 企业定制:定制化解决方案
- 白标服务:品牌化API服务
产品集成:
- SaaS平台:集成GPT能力的SaaS产品
- 移动应用:集成AI能力的移动应用
- 企业软件:企业级AI解决方案
- 硬件设备:集成AI的硬件产品
🔎8.3 竞争格局
主要竞争者:
- Google:PaLM、Gemini系列
- Anthropic:Claude系列
- Meta:LLaMA系列
- 百度:文心一言
- 阿里:通义千问
竞争优势:
- 技术领先:持续的技术创新
- 生态完善:丰富的API和工具
- 用户体验:优秀的用户界面
- 品牌影响力:强大的品牌认知
🚀九、未来展望
🔎9.1 技术发展趋势
模型规模:
- 更大规模:参数量继续增长
- 更高效:训练和推理效率提升
- 更智能:通用智能能力增强
- 更安全:安全性和可靠性提升
应用拓展:
- 多模态融合:更丰富的模态支持
- 实时交互:更自然的对话体验
- 个性化:更强的个性化能力
- 专业化:特定领域的深度应用
🔎9.2 社会影响
积极影响:
- 效率提升:提高工作和学习效率
- 创新加速:加速科技创新
- 知识普及:降低知识获取门槛
- 服务改善:改善用户体验
挑战与风险:
- 就业影响:对传统工作的冲击
- 隐私安全:数据隐私和安全问题
- 偏见问题:算法偏见和公平性
- 依赖风险:过度依赖AI的风险
🔎9.3 发展建议
技术发展:
- 持续创新:保持技术领先优势
- 安全优先:确保AI的安全性
- 开放合作:促进技术开放和合作
- 负责任发展:负责任地发展AI技术
应用推广:
- 普惠性:让更多人受益于AI技术
- 可持续性:确保技术的可持续发展
- 包容性:确保技术的包容性
- 透明性:提高技术的透明度
🚀十、总结
GPT系列代表了自然语言处理领域的重要里程碑,从GPT-3的惊艳亮相到GPT-4的多模态突破,再到GPT-5的预期发展,GPT系列正在不断推动AI技术的边界。
关键要点:
- 技术突破:从单模态到多模态的演进
- 能力提升:从文本生成到通用智能的发展
- 应用广泛:从研究工具到商业产品的转变
- 影响深远:对产业和社会产生深远影响
发展趋势:
- 模型规模不断扩大
- 能力不断增强
- 应用场景日益丰富
- 社会影响持续加深
作为AI学习者,我们应该:
- 持续关注:关注GPT系列的最新发展
- 积极应用:在实际项目中应用GPT技术
- 深入理解:理解GPT的技术原理和应用
- 负责任使用:负责任地使用AI技术
GPT系列的未来充满无限可能,让我们一起探索这个智能时代的美好前景!
思考题:
- 你认为GPT系列最大的技术突破是什么?
- 在你的项目中,你会如何使用GPT技术?
- 如何平衡GPT技术的创新性和安全性?
以上问题欢迎大家评论区留言讨论,我们下期见。