NLP—词向量转换评论学习项目分析
一·概念说明
同向量转换
单词 转换为向量:series [ ]一行句子 转换矩阵
# 从特征提取库中导入向量转化模块,因为自然语言需转换成数据形式,才能让模型训练 # 1、基于统计的方法:统计每个单词在语句中出现的次数 # 2、基于神经网络模型训练的方法(此处代码未体现,是思路说明 )
二·代码
# 从特征提取库中导入向量转化模块,因为自然语言需转换成数据形式,才能让模型训练
# 1、基于统计的方法:统计每个单词在语句中出现的次数
# 2、基于神经网络模型训练的方法(此处代码未体现,是思路说明 )
from sklearn.feature_extraction.text import CountVectorizer # 导入词向量转换工具,用于统计词频# 需要转化的语句,采用基于统计的方法处理(以下注释是对 ngram 组合方式的说明 )
"""
(1)本例组合方式:两两组合 # 类似贝叶斯模型等场景,模型需数字输入,这里是构造组合示例
['bird', 'cat', 'cat cat', 'cat fish', 'dog', 'dog cat', 'fish', 'fish bird']
(2)如果ngram_range(1, 3),则会出现3个词进行组合
['bird', 'cat', 'cat cat', 'cat fish', 'dog', 'dog cat', 'dog cat cat',
'dog cat fish', 'fish', 'fish bird']
"""# 定义需要处理的文本数据,是后续词频统计的输入内容
texts = ["dog cat fish", "dog cat cat", "fish bird", "bird"]
cont = [] # 初始化空列表(当前代码未用到,预留或后续扩展用 )# 实例化 CountVectorizer 模型
# max_features=6:限制最终提取的特征(词或词组)数量为 6 个,避免特征过多
# ngram_range=(1,3):设置提取 1 个词(unigram)、2 个词(bigram)、3 个词(trigram)的组合
# 作用:统计每篇“文章”(这里每个字符串就是一篇小文本)中每个词/词组出现的频率次数
cv = CountVectorizer(max_features=6, ngram_range=(1, 3))# 用 fit_transform 训练模型并完成转换
# fit:让模型学习 texts 里的词汇、词组规律
# transform:把 texts 转换成词频矩阵,cv_fit 里存的是转换后的结果(每个文本对应的词频稀疏矩阵)
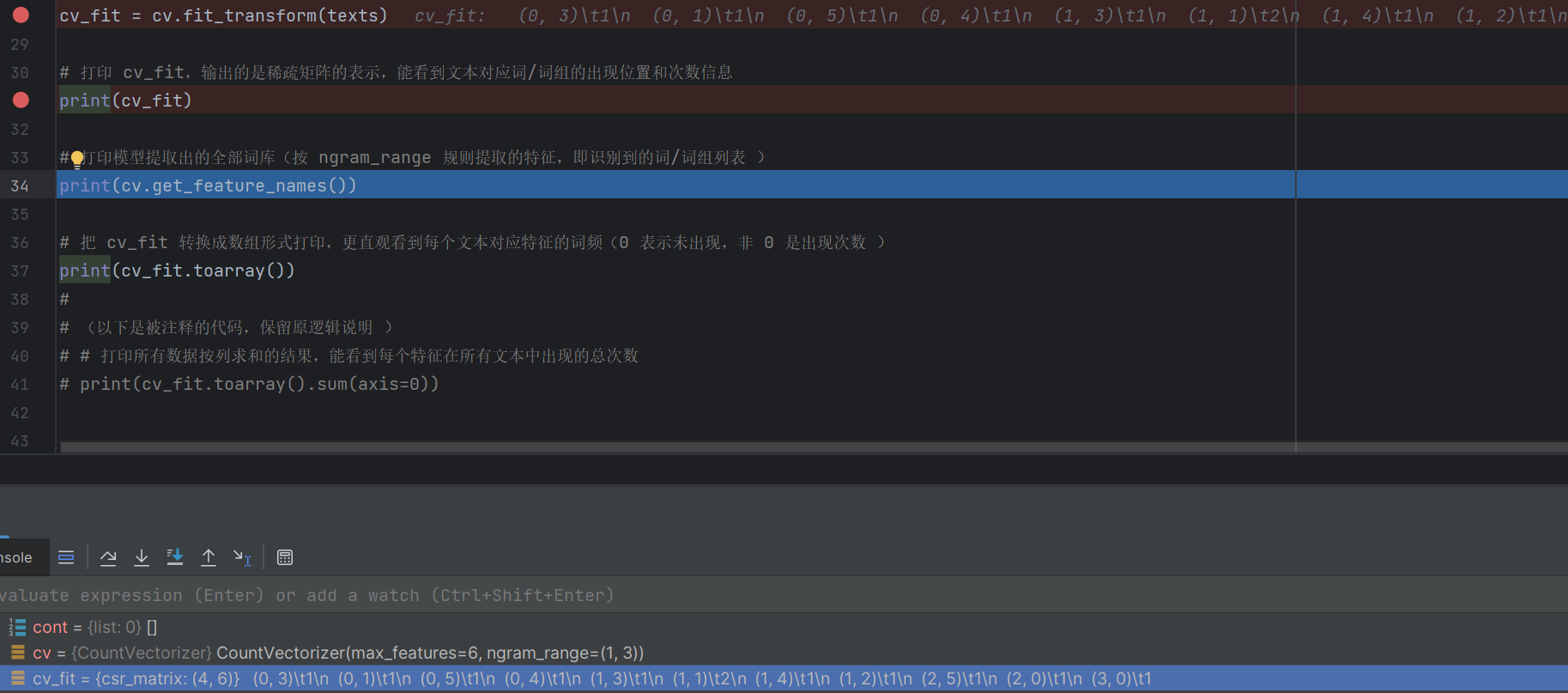
cv_fit = cv.fit_transform(texts)# 打印 cv_fit,输出的是稀疏矩阵的表示,能看到文本对应词/词组的出现位置和次数信息
print(cv_fit)# 打印模型提取出的全部词库(按 ngram_range 规则提取的特征,即识别到的词/词组列表 )
print(cv.get_feature_names_out())# 把 cv_fit 转换成数组形式打印,更直观看到每个文本对应特征的词频(0 表示未出现,非 0 是出现次数 )
print(cv_fit.toarray())# (以下是被注释的代码,保留原逻辑说明 )
## 打印所有数据按列求和的结果,能看到每个特征在所有文本中出现的总次数
# print(cv_fit.toarray().sum(axis=0))核心目的
这段代码主要实现了将文本数据转换为模型可识别的数字形式,用的是基于统计的词频统计方法,让计算机能 "看懂" 文本内容。
1. 库的导入
python
运行
from sklearn.feature_extraction.text import CountVectorizer
- 从 sklearn 的特征提取库中导入了 CountVectorizer 工具
- 这个工具的作用是:把文本里的词语转换成词频数字,因为模型只能处理数字,不能直接理解文字
2. 关于 ngram 组合方式的说明
这部分是对特征提取方式的解释:
- 当 ngram_range=(1,2) 时,会单独提取每个词,也会提取相邻两个词的组合
比如从 "dog cat fish" 中会提取出 "dog"、"cat"、"fish"、"dog cat"、"cat fish" - 当 ngram_range=(1,3) 时,还会额外提取三个词的组合
比如上面的例子还会多出 "dog cat fish"
3. 准备文本数据
python
运行
texts = ["dog cat fish", "dog cat cat", "fish bird", "bird"]
cont = [] # 这个列表暂时没用到,可能是预留着后续扩展用的
把texts当成一个语料库,
- 定义了 4 个简单文本作为处理对象,相当于 4 篇小 "文章"
- 这些文本就是我们要转换成数字的原始数据
4. 实例化词频统计模型
python
运行
cv = CountVectorizer(max_features=6, ngram_range=(1, 3))
这是一个类,下面是说明书
class CountVectorizer(_VectorizerMixin, BaseEstimator):r"""Convert a collection of text documents to a matrix of token counts.This implementation produces a sparse representation of the counts usingscipy.sparse.csr_matrix.If you do not provide an a-priori dictionary and you do not use an analyzerthat does some kind of feature selection then the number of features willbe equal to the vocabulary size found by analyzing the data.Read more in the :ref:`User Guide <text_feature_extraction>`.Parameters----------input : {'filename', 'file', 'content'}, default='content'- If `'filename'`, the sequence passed as an argument to fit isexpected to be a list of filenames that need reading to fetchthe raw content to analyze.- If `'file'`, the sequence items must have a 'read' method (file-likeobject) that is called to fetch the bytes in memory.- If `'content'`, the input is expected to be a sequence of items thatcan be of type string or byte.encoding : str, default='utf-8'If bytes or files are given to analyze, this encoding is used todecode.decode_error : {'strict', 'ignore', 'replace'}, default='strict'Instruction on what to do if a byte sequence is given to analyze thatcontains characters not of the given `encoding`. By default, it is'strict', meaning that a UnicodeDecodeError will be raised. Othervalues are 'ignore' and 'replace'.strip_accents : {'ascii', 'unicode'}, default=NoneRemove accents and perform other character normalizationduring the preprocessing step.'ascii' is a fast method that only works on characters that havean direct ASCII mapping.'unicode' is a slightly slower method that works on any characters.None (default) does nothing.Both 'ascii' and 'unicode' use NFKD normalization from:func:`unicodedata.normalize`.lowercase : bool, default=TrueConvert all characters to lowercase before tokenizing.preprocessor : callable, default=NoneOverride the preprocessing (strip_accents and lowercase) stage whilepreserving the tokenizing and n-grams generation steps.Only applies if ``analyzer`` is not callable.tokenizer : callable, default=NoneOverride the string tokenization step while preserving thepreprocessing and n-grams generation steps.Only applies if ``analyzer == 'word'``.stop_words : {'english'}, list, default=NoneIf 'english', a built-in stop word list for English is used.There are several known issues with 'english' and you shouldconsider an alternative (see :ref:`stop_words`).If a list, that list is assumed to contain stop words, all of whichwill be removed from the resulting tokens.Only applies if ``analyzer == 'word'``.If None, no stop words will be used. max_df can be set to a valuein the range [0.7, 1.0) to automatically detect and filter stopwords based on intra corpus document frequency of terms.token_pattern : str, default=r"(?u)\\b\\w\\w+\\b"Regular expression denoting what constitutes a "token", only usedif ``analyzer == 'word'``. The default regexp select tokens of 2or more alphanumeric characters (punctuation is completely ignoredand always treated as a token separator).If there is a capturing group in token_pattern then thecaptured group content, not the entire match, becomes the token.At most one capturing group is permitted.ngram_range : tuple (min_n, max_n), default=(1, 1)The lower and upper boundary of the range of n-values for differentword n-grams or char n-grams to be extracted. All values of n suchsuch that min_n <= n <= max_n will be used. For example an``ngram_range`` of ``(1, 1)`` means only unigrams, ``(1, 2)`` meansunigrams and bigrams, and ``(2, 2)`` means only bigrams.Only applies if ``analyzer`` is not callable.analyzer : {'word', 'char', 'char_wb'} or callable, default='word'Whether the feature should be made of word n-gram or charactern-grams.Option 'char_wb' creates character n-grams only from text insideword boundaries; n-grams at the edges of words are padded with space.If a callable is passed it is used to extract the sequence of featuresout of the raw, unprocessed input... versionchanged:: 0.21Since v0.21, if ``input`` is ``filename`` or ``file``, the data isfirst read from the file and then passed to the given callableanalyzer.max_df : float in range [0.0, 1.0] or int, default=1.0When building the vocabulary ignore terms that have a documentfrequency strictly higher than the given threshold (corpus-specificstop words).If float, the parameter represents a proportion of documents, integerabsolute counts.This parameter is ignored if vocabulary is not None.min_df : float in range [0.0, 1.0] or int, default=1When building the vocabulary ignore terms that have a documentfrequency strictly lower than the given threshold. This value is alsocalled cut-off in the literature.If float, the parameter represents a proportion of documents, integerabsolute counts.This parameter is ignored if vocabulary is not None.max_features : int, default=NoneIf not None, build a vocabulary that only consider the topmax_features ordered by term frequency across the corpus.This parameter is ignored if vocabulary is not None.vocabulary : Mapping or iterable, default=NoneEither a Mapping (e.g., a dict) where keys are terms and values areindices in the feature matrix, or an iterable over terms. If notgiven, a vocabulary is determined from the input documents. Indicesin the mapping should not be repeated and should not have any gapbetween 0 and the largest index.binary : bool, default=FalseIf True, all non zero counts are set to 1. This is useful for discreteprobabilistic models that model binary events rather than integercounts.dtype : type, default=np.int64Type of the matrix returned by fit_transform() or transform().Attributes----------vocabulary_ : dictA mapping of terms to feature indices.fixed_vocabulary_ : boolTrue if a fixed vocabulary of term to indices mappingis provided by the user.stop_words_ : setTerms that were ignored because they either:- occurred in too many documents (`max_df`)- occurred in too few documents (`min_df`)- were cut off by feature selection (`max_features`).This is only available if no vocabulary was given.See Also--------HashingVectorizer : Convert a collection of text documents to amatrix of token counts.TfidfVectorizer : Convert a collection of raw documents to a matrixof TF-IDF features.Notes-----The ``stop_words_`` attribute can get large and increase the model sizewhen pickling. This attribute is provided only for introspection and canbe safely removed using delattr or set to None before pickling.Examples-------->>> from sklearn.feature_extraction.text import CountVectorizer>>> corpus = [... 'This is the first document.',... 'This document is the second document.',... 'And this is the third one.',... 'Is this the first document?',... ]>>> vectorizer = CountVectorizer()>>> X = vectorizer.fit_transform(corpus)>>> vectorizer.get_feature_names_out()array(['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third','this'], ...)>>> print(X.toarray())[[0 1 1 1 0 0 1 0 1][0 2 0 1 0 1 1 0 1][1 0 0 1 1 0 1 1 1][0 1 1 1 0 0 1 0 1]]>>> vectorizer2 = CountVectorizer(analyzer='word', ngram_range=(2, 2))>>> X2 = vectorizer2.fit_transform(corpus)>>> vectorizer2.get_feature_names_out()array(['and this', 'document is', 'first document', 'is the', 'is this','second document', 'the first', 'the second', 'the third', 'third one','this document', 'this is', 'this the'], ...)>>> print(X2.toarray())[[0 0 1 1 0 0 1 0 0 0 0 1 0][0 1 0 1 0 1 0 1 0 0 1 0 0][1 0 0 1 0 0 0 0 1 1 0 1 0][0 0 1 0 1 0 1 0 0 0 0 0 1]]"""def __init__(self,*,input="content",encoding="utf-8",decode_error="strict",strip_accents=None,lowercase=True,preprocessor=None,tokenizer=None,stop_words=None,token_pattern=r"(?u)\b\w\w+\b",ngram_range=(1, 1),analyzer="word",max_df=1.0,min_df=1,max_features=None,vocabulary=None,binary=False,dtype=np.int64,):self.input = inputself.encoding = encodingself.decode_error = decode_errorself.strip_accents = strip_accentsself.preprocessor = preprocessorself.tokenizer = tokenizerself.analyzer = analyzerself.lowercase = lowercaseself.token_pattern = token_patternself.stop_words = stop_wordsself.max_df = max_dfself.min_df = min_dfself.max_features = max_featuresself.ngram_range = ngram_rangeself.vocabulary = vocabularyself.binary = binaryself.dtype = dtype
- 这行代码创建了一个词频统计器实例,有两个关键参数:
- 这里只需要两个参数
- max_features=6:限制最终只提取 6 个最主要的特征(词或词组),避免特征太多
- ngram_range=(1,3):设置提取 1 个词、2个词、3 个词的组合形式
5. 训练模型并转换文本
python运行
这里就是把单词转化为矩阵,把txt,训练并转化
cv_fit = cv.fit_transform(texts)
- 这是核心操作,包含两个步骤:
- fit:让模型 "学习"texts 里的所有词汇和词组规律
- transform:把原始文本转换成词频矩阵
- 得到的 cv_fit 是转换后的结果,存储着每个文本中各个词 / 词组出现的次数
- 在debug里面可以看到这个一个矩阵
6. 查看转换结果
python
运行
print(cv_fit) # 打印稀疏矩阵
- 输出的是稀疏矩阵形式,记录了哪些文本包含哪些词 / 词组,以及出现的次数
- 稀疏矩阵只记录非零值位置,节省内存
python
运行
print(cv.get_feature_names()) # 打印提取出的词库
# 打印模型提取出的全部词库(按 ngram_range 规则提取的特征,即识别到的词/词组列表 )
- 输出模型识别到的所有特征(词或词组)列表
- 因为设置了 max_features=6,所以会显示排名前 6 的特征
python
运行
print(cv_fit.toarray()) # 打印数组形式的词频矩阵
- 把稀疏矩阵转换成直观的二维数组
- 每行对应一个原始文本,每列对应一个特征
- 数组中的数字表示该文本中对应特征出现的次数(0 表示没出现)
补充说明
注释掉的代码print(cv_fit.toarray().sum(axis=0))的作用是:
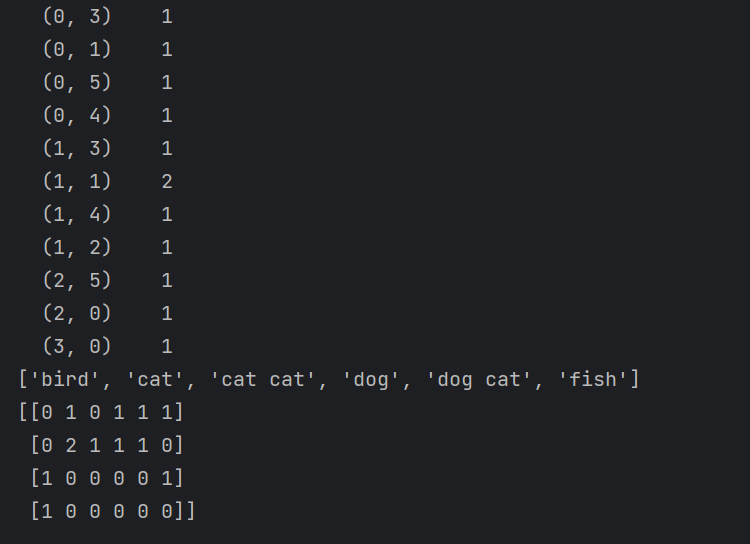
这里最下面的部分就是把前面的narry数组转为numpy矩阵,最后这个矩阵我们就可以传入到模型中训练了,然后这个模型我们选择贝叶斯因为这个模型适合与分类而且适合于NLP自然语言处理,
- 计算每个特征在所有文本中出现的总次数
- 可以帮我们了解哪些词 / 词组在整个语料中出现得最频繁
这是最终结果,可以看出最开始我们的数据是
['bird', 'cat', 'cat cat', 'cat fish', 'dog', 'dog cat', 'dog cat cat',
'dog cat fish', 'fish', 'fish bird']这么多,但是你会发现输出的结果是不同的
第一
- max_features=6:限制最终只提取 6 个最主要的特征(词或词组),避免特征太多
- ngram_range=(1,3):设置提取 1 个词,2个词,3 个词的组合形式
这个参数,max_feature是显示6 个最主要的特征 ngram_range是设置提取 1 个词或者3 个词的组合形式。
这个时候我们把max_feature去掉就会发现
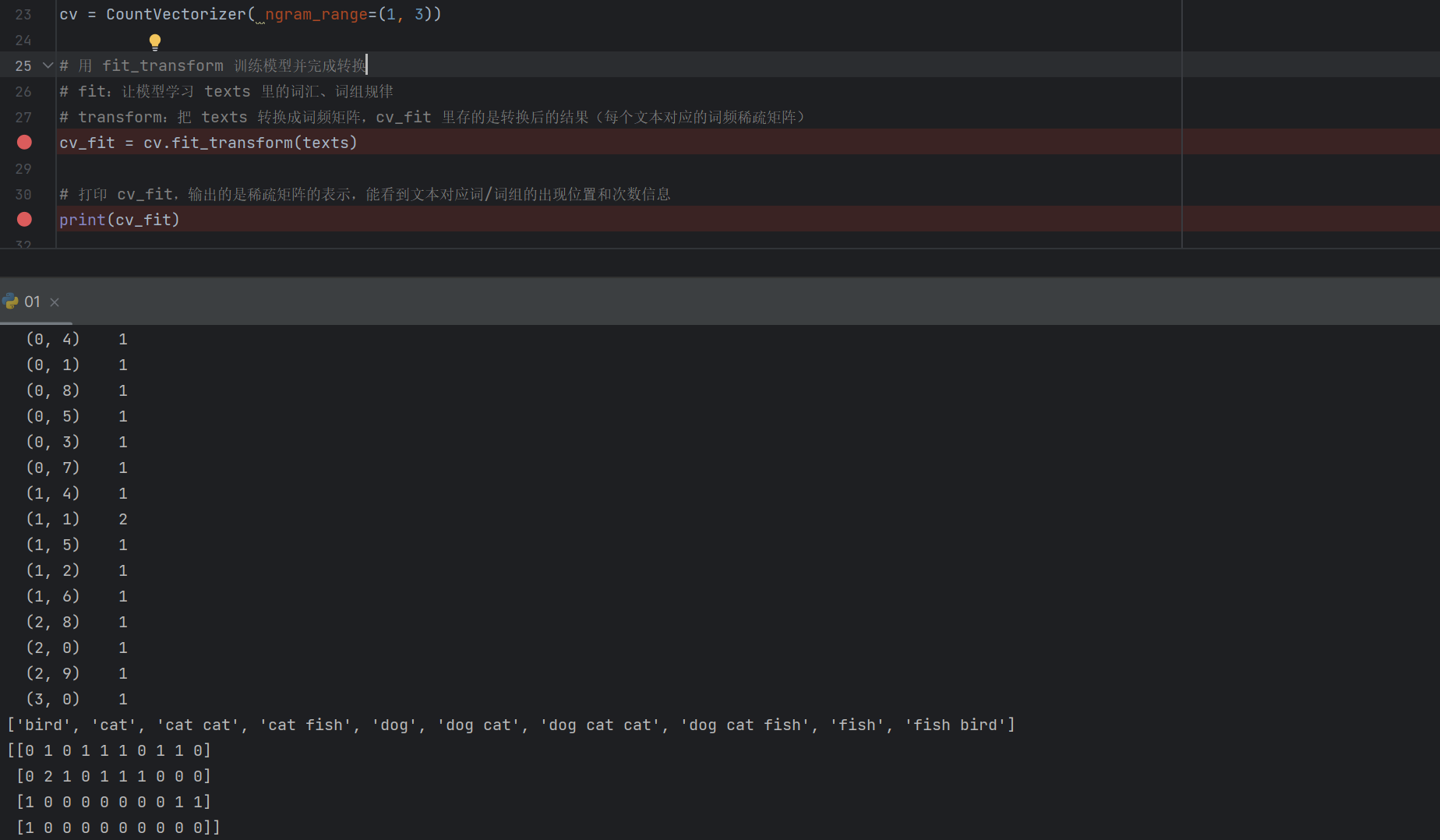
这个是3个词的符合ngram_range参数规则的。
最后这个你会发现有些单词没有了,他符合规则却不在了,就是因为他出现的频率只有一次,所以从概率的角度出发就不要统计,而且模型训练也不具备代表性,效果也不好,而且会导致过拟合