LLM大语言模型初步学习认识
大语言模型学习笔记
- 语言模型训练
- 增强式学习
- 改变不了模型,我就改变自己
- 对模型情绪勒索
- 模型思考(CoT)
- RAG
- PoT
- PoT和CoT的区别
- 超参数
- Overfitting
- 机器学习模型的可解释性
- 核心目标
- 波煮是跟着台大的李宏毅老师学习的,下图截屏也均为李老师上课课件
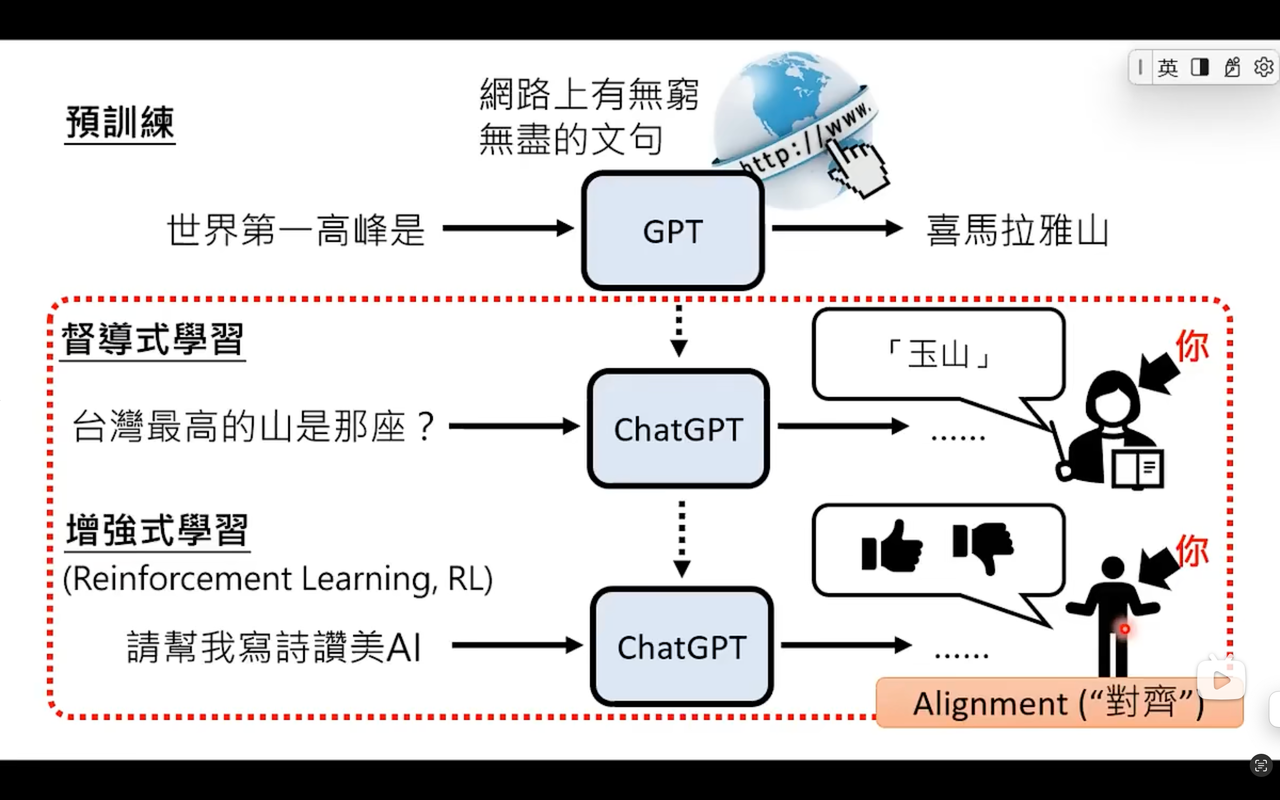
语言模型训练
- 语言模型训练就是学习做文字接龙
增强式学习
- 有一个
Reward Model:奖励机制 - 增强式学习(Reinforcement Learning,简称RL)是机器学习的一个分支,核心思想是让智能体(agent)在环境中通过“试错”来学习如何做出最优决策。它不依赖大量标注数据,而是通过奖励(reward)和惩罚(punishment)的反馈机制,逐步优化行为策略。
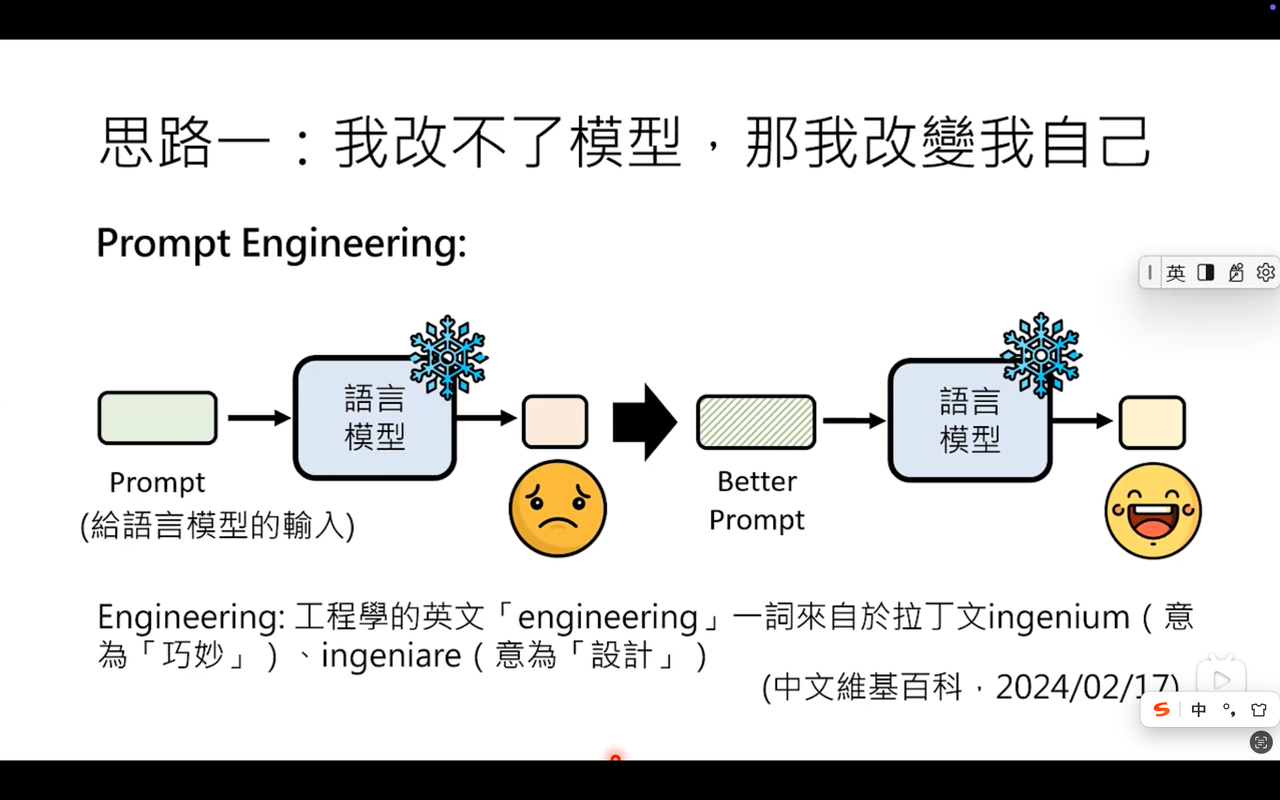
改变不了模型,我就改变自己
- Prompt Engineering(提示工程)可以简单理解为“如何对 AI 说人话”的技术。它是围绕大语言模型(LLM)兴起的一门新兴学科,核心目标是通过设计、优化和调整输入提示(Prompt),让 AI 精准理解人类意图,并生成高质量、符合预期的输出
- Prompt Engineering = 把模糊需求翻译成AI能听懂的“咒语”
对模型情绪勒索
- 对模型“情绪勒索”(emotional blackmailing of the model)是人为地在 prompt 里加入夸张、自责、威胁、道德绑架等情绪性措辞,试图操控大模型给出“更顺从”或“更优”的回答。
- 它不是真正的“情绪”,而是一种利用模型对齐(alignment)策略的 prompt 技巧。
- 为什么有效:
- 大模型在 RLHF(人类反馈强化学习)阶段被“鼓励”给出有帮助且无害的回答。情绪化的措辞会被模型理解为“高严重性”请求,从而触发更保守、更详尽的输出。
- 模型对极端措辞的权重更高,类似“放大器”。
- “情绪勒索”不是模型有情绪,而是人类利用模型的对齐训练漏洞,通过夸张情绪来“骗”出更听话的答案——好用,但不优雅,也不可靠。
模型思考(CoT)
- CoT(Chain-of-Thought,思维链) 是一种让 AI 把推理过程“像人一样一步步写出来”的方法。它通过显式展示中间推理步骤,显著提升大模型在数学、逻辑、常识推理等复杂任务上的准确率。
- CoT = 让 AI “自言自语”地拆解问题,而不是直接给答案
- CoT 不是让 AI 变聪明,而是让它“慢下来”,把思考过程写出来,从而减少跳跃性错误。
RAG
- RAG 是 Retrieval-Augmented Generation 的缩写,中文通常译为 “检索增强生成”。
- 一句话概括:让大模型先“查资料”,再“写答案”。
- 为什么需要RAG
大模型(如 GPT、文心一言)的知识截止于训练数据,存在三大痛点:- 知识过时:无法回答训练后出现的新事件。
- 幻觉问题:编造看似合理实则错误的答案。
- 领域盲区:缺乏企业/个人的私域数据(如内部文档、实时业务数据)。
RAG 通过实时检索外部知识库,将相关片段作为上下文输入给大模型,从而生成更准确、更新、可追溯的回答。
- RAG = 检索器(找资料) + 大模型(写答案),专治“知识过时”和“胡说八道”。
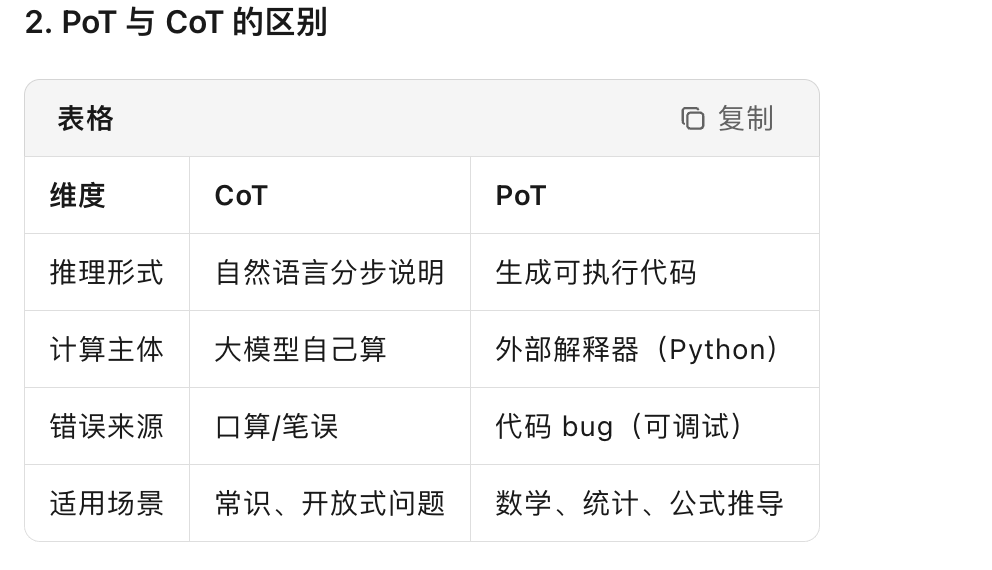
PoT
- PoT 在大模型语境下指的是 Program-of-Thoughts(思维程序),是 CoT(Chain-of-Thought)的进一步演化。它不再让模型“用文字一步步推理”,而是直接生成一段可执行的程序(通常是 Python 代码),把计算与逻辑分离——模型负责推理框架,代码解释器负责精确运算,从而显著提升数学、金融、工程等数值类任务的正确率。
- PoT = 让大模型写代码 → 交给 Python 运行 → 拿运行结果当答案。
- PoT 把大模型从“口算”变成“写代码调用计算器”,专治数值推理不准的毛病。
PoT和CoT的区别
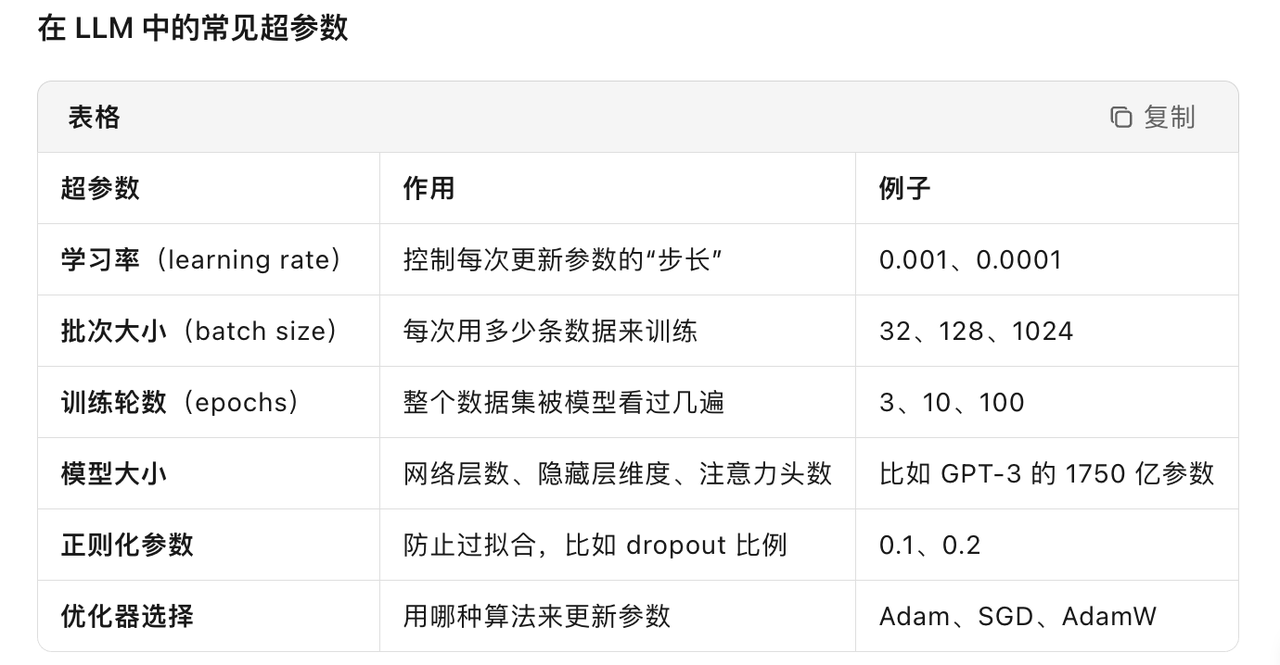
超参数
- 超参数就是在模型开始学习之前,由人手动设定、决定模型“如何学”的那些参数。
- 例子:
想象你在教孩子学画画:- 模型参数就像孩子自己画出来的线条、颜色,是他在学习过程中不断调整的。
- 超参数就像你提前告诉他的规则:“每天画 1 小时”“最多用 10 种颜色”“画错了就用橡皮擦掉重新来”——这些规则不是孩子自己学出来的,而是你提前定好的。
- 为什么叫超参数:
因为它们“凌驾”于普通参数之上:- 普通参数(如权重)是模型通过数据自动学习的。
- 超参数是研究者手动设定的,无法通过训练数据直接学到。
- 超参数是训练模型的“游戏规则”,规则定得好,模型才能学得又快又好。
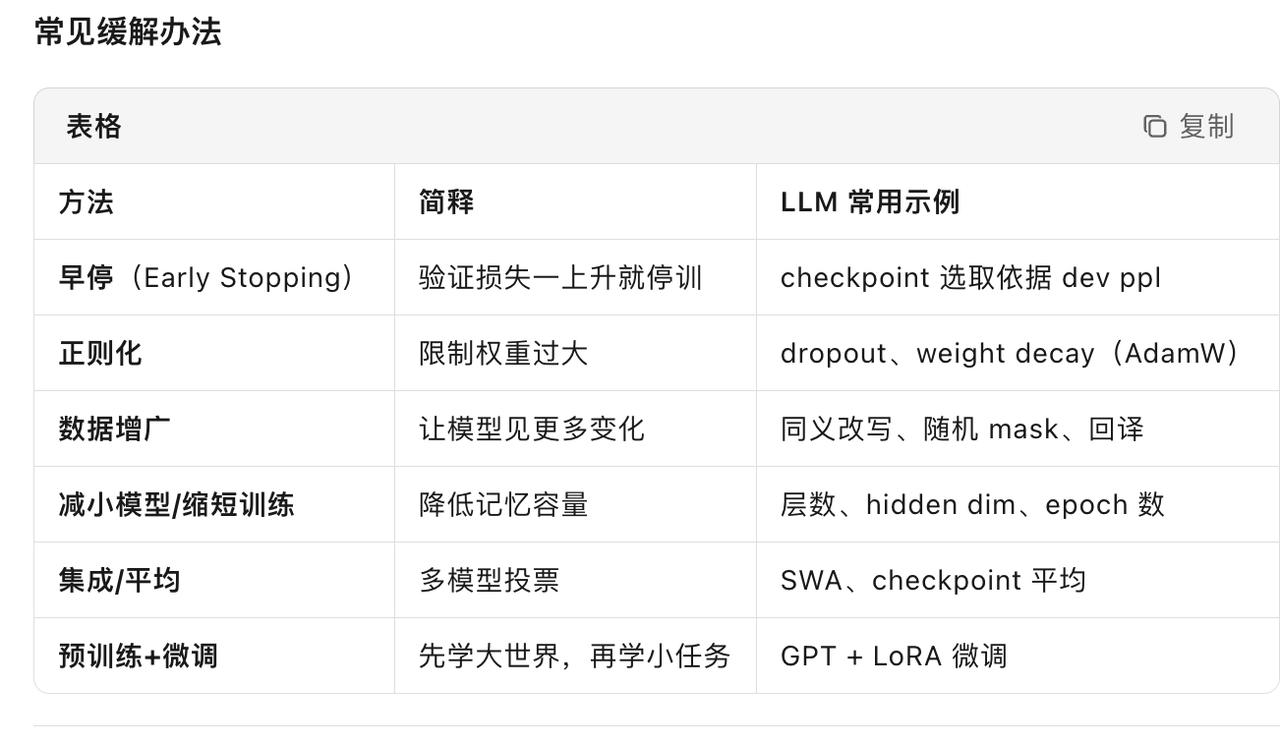
Overfitting
- 训练成功但是测试失败
- 过拟合(overfitting)就是模型把训练数据里的“噪声”也当成“知识”背了下来,结果在没见过的新数据上表现变差。
- 过拟合就是“背题不背书”,防它就要让模型学会“举一反三”而不是“死记硬背”。
机器学习模型的可解释性
- Explainable ML(Explainable Machine Learning,可解释机器学习)指的是**让机器学习模型的决策过程、内部逻辑或输出结果能够被人类“看懂”和“信任”**的一整套方法、指标与工具。
- Explainable ML 就是给黑盒模型装上“说明书”和“透视窗”,让人类既能用模型,也能看懂模型,从而敢用、敢改、敢负责。
核心目标
- 透明性(Transparency):模型内部发生了什么可以描述。
- 可解释性(Interpretability):人类能用自然语言、可视化或规则理解模型输出。
- 可信度(Trustworthiness):用户能验证模型是否符合常识、伦理和业务约束。