面试高频题 力扣 200.岛屿数量 洪水灌溉 深度优先遍历 暴力搜索 C++解题思路 每日一题
目录
- 零、题目描述
- 一、为什么这道题值得你花几分钟看懂?
- 二、题目拆解:提取其中的关键点
- 三、明确思路:暴力枚举与标记重复
- 四、算法实现:深度优先遍历
- 五、C++代码实现:一步步拆解
- 代码拆解
- 时间复杂度
- 六、实现过程中的坑点总结
- 七、举一反三
零、题目描述
题目链接:岛屿数量
题目描述:
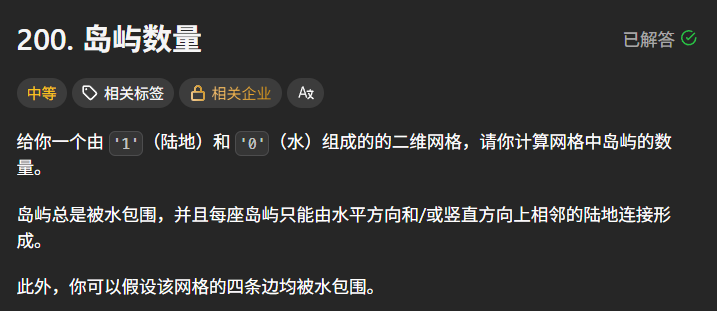
示例 1:
输入:grid = [
[“1”,“1”,“1”,“1”,“0”],
[“1”,“1”,“0”,“1”,“0”],
[“1”,“1”,“0”,“0”,“0”],
[“0”,“0”,“0”,“0”,“0”]
]
输出:1
示例 2:
输入:grid = [
[“1”,“1”,“0”,“0”,“0”],
[“1”,“1”,“0”,“0”,“0”],
[“0”,“0”,“1”,“0”,“0”],
[“0”,“0”,“0”,“1”,“1”]
]
输出:3
提示:
m == grid.length
n == grid[i].length
1 <= m, n <= 300
grid[i][j] 的值为 ‘0’ 或 ‘1’
一、为什么这道题值得你花几分钟看懂?
如果你正在准备算法面试,那「岛屿数量」绝对是绕不开的经典题 —— 它不仅是 LeetCode 第 200 题,更是连通性问题的入门典范,70% 的大厂面试都会考察类似思路。
从算法能力提升来讲,这道题是标准的洪水灌溉(FloodFill)算法的一个应用,并且这道题也是训练搜索与递归思维的绝佳载体。它能让你深刻理解如何在二维结构中进行系统性遍历,掌握 “标记访问” 的核心技巧,而这些能力是解决树、图等复杂数据结构问题的基础。
这道题的核心是「如何识别二维网格中的连通区域」,学会它,你能举一反三解决:
- 岛屿的最大面积(LeetCode 695)
- 被围绕的区域(LeetCode 130)
- 水域大小(LeetCode 1020)
甚至能直接理解生活中诸多「区域划分」场景的核心逻辑 —— 比如地图软件如何自动识别国家边界(本质是相邻地理单元的连通性判断)、疫情防控中如何快速划定高风险区范围(从一个初始病例出发,标记所有密切接触的关联区域)。这些场景的算法逻辑,和我们解这道题时「找连通陆地、标记并计数」的思路,其实是完全相通的。
二、题目拆解:提取其中的关键点
先看原题:
给你一个由 ‘1’(陆地)和 ‘0’(水)组成的二维网格,请你计算网格中岛屿的数量。岛屿总是被水包围,并且每座岛屿只能由水平方向和 / 或竖直方向上相邻的陆地连接形成。网格的四条边均被水包围。
再结合所给的代码框架和提示:
class Solution {
public:int numIslands(vector<vector<char>>& grid) {}
};
核心要素提炼:
- 题中会给我们由vector组成的二维数组
grid,其元素类型是char,这个二维数组的长宽的取值范围是1~300之间,这个数组是用存储岛屿的'0'代表水'1'代表陆地 - 返回的结果是岛屿的数量(相邻的 ‘1’ 组成一个岛屿,斜对角不算)
关键点:
- 遍历网格:用双重循环遍历每个单元格。
- DFS/BFS:发现陆地(
'1')时,用搜索算法标记所有相连陆地。 - 标记已访问:将访问过的陆地改为
'0'避免重复计数。 - 边界处理:搜索时检查坐标合法性防止越界。
- 计数:每启动一次搜索,岛屿数+1。
三、明确思路:暴力枚举与标记重复
1. 最直观的想法:遍历 + 标记
拿到题的第一反应:只要找到一个 ‘1’,就说明发现了一个新岛屿,然后把这个岛屿上所有相连的 ‘1’ 都标记出来(避免重复计数),最后统计这样的 “发现” 次数即可。
举个例子(示例 1):
初始网格:
["1","1","1","1","0"],
["1","1","0","1","0"],
["1","1","0","0","0"],
["0","0","0","0","0"]
第一步:遍历到 (0,0) 是 ‘1’,岛屿数 + 1,然后把所有和它相连的 ‘1’ 都标记为已访问(整个左上角的大岛被标记)。后续遍历:剩下的都是未被标记的 ‘0’ 或已标记的 ‘1’,最终结果为 1。
为什么这个思路可行?
因为岛屿是 “被水包围的连通陆地”,一旦找到一个 ‘1’,它所在的岛屿所有 ‘1’ 都必须被标记(否则会被重复计算)。
2. 我的初步尝试:用布尔数组做标记
最开始我想到的标记方式,是创建一个和网格最大范围同规模的布尔数组(bool mark[300][300])。遍历网格时,每当遇到一个未被标记的 ‘1’,就通过 DFS 或 BFS 遍历整个岛屿,同时在布尔数组中把所有相连的 ‘1’ 对应的位置标记为 true。
这样做的逻辑很清晰:布尔数组专门记录哪些陆地已经被统计过,既不会干扰原始网格的数据,也能准确区分已访问和未访问的陆地。比如在示例 1 中,(0,0) 被发现后,整个左上角岛屿的所有 ‘1’ 在布尔数组中都会被标记为 true,后续遍历到这些位置时,就不会再被算作新岛屿。
3. 更优的标记方式:直接修改原始网格
后来发现,其实可以把标记过程做得更巧妙 —— 直接在原始网格上动手脚。
既然网格里只有 ‘1’(陆地)和 ‘0’(水),那当我们访问过一个 ‘1’ 后,不妨把它改成 ‘0’。这样一来,这个位置就从 “未访问的陆地” 变成了 “水”,后续遍历到这里时,自然会跳过它,也就不会重复计数了。
用同样的示例 1 来看:遍历到 (0,0) 时,先给岛屿数加 1,然后通过 DFS 或 BFS 把所有相连的 ‘1’ 都改成 ‘0’。整个过程就像 “淹没” 了这座岛屿,剩下的网格里再也没有属于这座岛的 ‘1’,后续遍历自然不会重复统计。
4. 两种思路的核心差异
两种方法的本质都是 “标记已访问的陆地”,但区别在于标记的载体:
- 布尔数组标记:需要额外的空间来记录状态,好处是完全不改动原始数据,适合那些不允许修改输入的场景。
- 原地修改网格:利用了题目中 “只有 ‘0’ 和 ‘1’” 的特性,把已访问的 ‘1’ 改成 ‘0’ 来做标记,省去了额外空间,代码也更简洁。
到这里就能看出,原地修改网格的思路更贴合这道题的特点 —— 它没有浪费题目给出的条件,用更巧妙的方式完成了标记工作。
四、算法实现:深度优先遍历
这道题我是用深度优先遍历来写的下面我来讲解我的算思路
核心逻辑:
遇到 ‘1’ 时,通过递归遍历它的上下左右四个方向,将所有相连的 ‘1’ 都改成 ‘0’(相当于“淹没”这个岛屿),以此标记整个岛屿并避免重复计数。
步骤拆解:
- 遍历网格的每个单元格(i,j)。
- 若
grid[i][j] == '1':- 调用 DFS 函数,将当前单元格及所有相连的 ‘1’ 改成 ‘0’(标记为已访问)。
- 岛屿数量 + 1(每完成一次 DFS 遍历,代表发现一个完整岛屿)。
- 遍历结束后,返回岛屿数量。
DFS 函数细节:
- 标记操作:进入 DFS 后,我们要先将当前单元格
grid[x][y]改为'0',明确标记为已访问,一是我们要在下一次进入递归之前完成修改标记的操作,二是防止我们忘记犯低级错误。 - 递归函数的参数和返回值:递归函数
dfs(int x, int y, vector<vector<char>>& grid)的参数中,x和y定位当前遍历的单元格,grid用于判断是否为未访问陆地'1'及通过修改为'0'标记已访问,而这道题我们dfs函数的任务是将找到的联通岛屿进行标记所以并不需要返回值。 - 方向遍历:通过方向数组 dx、dy 定义上下左右四个方向(
dx[4] = {1, -1, 0, 0}对应下、上、右、左;dy[4] = {0, 0, 1, -1}配合 dx 实现坐标偏移),这里我们要注意越界的问题应该如何处理,在写代码的时候我们可以用一个if来解决这个问题,也就是我们的递归条件👇。 - 递归条件:计算新坐标 (nx, ny) 后,需先检查其是否在网格范围内(0 ≤ nx < 行数、0 ≤ ny < 列数),且
grid[nx][ny] == '1'(是未访问的陆地),满足则递归调用 DFS。
五、C++代码实现:一步步拆解
完整代码(附详细注释)
#include <vector>
using namespace std;class Solution {
public:int sum = 0; // 用于统计岛屿数量// 四个方向的偏移量:下、上、右、左int dx[4] = {1, -1, 0, 0};int dy[4] = {0, 0, 1, -1};int rows, cols; // 网格的行数和列数int numIslands(vector<vector<char>>& grid) {if (grid.empty()) return 0; // 边界处理:网格为空则直接返回0rows = grid.size(); // 初始化行数cols = grid[0].size(); // 初始化列数// 遍历网格的每个单元格for (int i = 0; i < rows; i++) {for (int j = 0; j < cols; j++) {if (grid[i][j] == '1') { // 发现未访问的陆地dfs(i, j, grid); // 淹没整个岛屿sum++; // 岛屿数量+1}}}return sum; // 返回岛屿总数}// DFS:淹没与 (x,y) 相连的所有陆地(改成 '0')void dfs(int x, int y, vector<vector<char>>& grid) {// 将当前陆地标记为已访问(改成水域'0')grid[x][y] = '0';// 遍历四个方向for (int i = 0; i < 4; i++) {// 计算新坐标:当前坐标 + 方向偏移量int nx = x + dx[i];int ny = y + dy[i];// 检查新坐标合法性,且该位置是未访问的陆地('1')if (nx >= 0 && ny >= 0 && nx < rows && ny < cols && grid[nx][ny] == '1') {dfs(nx, ny, grid); // 递归淹没相邻陆地}}}
};
代码拆解
1.类中成员变量解析
int sum = 0; // 用于累计岛屿数量,全局可见,方便在dfs后直接累加
// 方向数组:通过偏移量表示下、上、右、左四个方向,避免重复写坐标计算逻辑
int dx[4] = {1, -1, 0, 0};
int dy[4] = {0, 0, 1, -1};
int rows, cols; // 存储网格的行数和列数,避免在dfs中重复计算
作用:将重复使用的变量(如方向、行数、列数)定义为类成员,减少函数参数传递,简化代码逻辑。
2. 主函数 numIslands 核心逻辑
int numIslands(vector<vector<char>>& grid) {if (grid.empty()) return 0; // 边界处理:空网格直接返回0rows = grid.size(); cols = grid[0].size(); // 双层循环遍历每个单元格for (int i = 0; i < rows; i++) {for (int j = 0; j < cols; j++) {if (grid[i][j] == '1') { // 找到未被访问的陆地dfs(i, j, grid); // 调用dfs淹没整个岛屿sum++; // 每淹没一个岛屿,计数+1}}}return sum;
}
核心步骤:
- 先判断网格是否为空,避免后续访问越界;
- 通过双层循环遍历每个单元格,相当于“扫描”整个网格;
- 遇到
'1'时,说明发现新岛屿,调用dfs将整个岛屿“淹没”(标记为'0'),然后计数器sum加1。
示例理解:
以输入网格为例:
[["1","1","0","0","0"],["1","1","0","0","0"],["0","0","1","0","0"],["0","0","0","1","1"]
]
- 遍历到
(0,0)时,发现'1',调用dfs淹没左上角的岛屿,sum变为1; - 遍历到
(2,2)时,发现'1',调用dfs淹没中间的岛屿,sum变为2; - 遍历到
(3,3)时,发现'1',调用dfs淹没右下角的岛屿,sum变为3; - 最终返回
sum=3,符合预期结果。
3. DFS 函数核心逻辑
void dfs(int x, int y, vector<vector<char>>& grid) {grid[x][y] = '0'; // 标记当前位置为已访问(淹没)for (int i = 0; i < 4; i++) { // 遍历四个方向int nx = x + dx[i]; // 计算新行坐标int ny = y + dy[i]; // 计算新列坐标// 检查新坐标是否合法(在网格内),且是未访问的陆地if (nx >= 0 && ny >= 0 && nx < rows && ny < cols && grid[nx][ny] == '1') {dfs(nx, ny, grid); // 递归处理相邻陆地}}
}
核心设计:
- 标记操作:进入
dfs后立即将grid[x][y]改为'0',避免后续遍历重复处理(相当于“淹没”当前陆地); - 方向遍历:通过
dx和dy数组遍历四个方向(下、上、右、左),无需手写四次重复代码; - 边界检查:
nx >= 0 && nx < rows && ny >= 0 && ny < cols确保不会访问网格外的无效坐标; - 递归条件:只有当新坐标是未访问的陆地(
grid[nx][ny] == '1')时,才继续递归。
局部递归思路图(以左上角岛屿为例)
假设当前遍历到(0,0),触发dfs(0,0,grid),递归过程如下:
初始状态(局部网格):
(0,0)='1', (0,1)='1'
(1,0)='1', (1,1)='1'第1步:调用dfs(0,0,grid)
→ 将(0,0)改为'0'
→ 检查四个方向:- 下:(1,0)='1' → 调用dfs(1,0,grid)- 上:(-1,0)越界 → 跳过- 右:(0,1)='1' → 暂存,等待下一层递归- 左:(0,-1)越界 → 跳过第2步:进入dfs(1,0,grid)
→ 将(1,0)改为'0'
→ 检查四个方向:- 下:(2,0)='0' → 跳过- 上:(0,0)='0' → 跳过- 右:(1,1)='1' → 调用dfs(1,1,grid)- 左:(1,-1)越界 → 跳过第3步:进入dfs(1,1,grid)
→ 将(1,1)改为'0'
→ 检查四个方向:- 下:(2,1)='0' → 跳过- 上:(0,1)='1' → 调用dfs(0,1,grid)- 右:(1,2)='0' → 跳过- 左:(1,0)='0' → 跳过第4步:进入dfs(0,1,grid)
→ 将(0,1)改为'0'
→ 检查四个方向:- 下:(1,1)='0' → 跳过- 上:(-1,1)越界 → 跳过- 右:(0,2)='0' → 跳过- 左:(0,0)='0' → 跳过
→ 递归结束,返回上一层最终结果:左上角所有'1'均被改为'0',完成“淹没”
递归特点:像洪水扩散一样,从(0,0)开始,逐步淹没所有相连的陆地,直到整个岛屿被“淹没”为止。
时间复杂度
| 操作类型 | 时间复杂度 | 说明 |
|---|---|---|
| 网格整体遍历 | O(m×n) | 遍历所有单元格 |
| DFS递归处理 | O(m×n) | 每个陆地最多被访问一次 |
| 总计 | O(m×n) | m为行数,n为列数 |
六、实现过程中的坑点总结
其实这些坑点或多或少咱们上面已经说了,这里咱们来总结一下:
1.递归终止条件的顺序
错误写法:
void dfs(...) {if (grid[x][y] == '0') return; // 先检查是否为'0'if (x < 0 || x >= rows || ...) return; // 后检查越界// ...
}
问题:如果坐标越界,直接访问grid[x][y]会导致数组越界异常(如段错误)。
正确做法:先检查坐标合法性,再判断是否为陆地:
if (x < 0 || x >= rows || y < 0 || y >= cols) return; // 先检查越界
if (grid[x][y] == '0') return; // 再检查是否为'0'
2.标记操作的时机
错误写法:
void dfs(...) {// 没有立即标记当前位置for (int i = 0; i < 4; i++) {// 检查相邻位置...dfs(nx, ny, grid);}grid[x][y] = '0'; // 递归结束后才标记
}
问题:未标记的陆地会被重复访问,导致栈溢出(Stack Overflow)或无限循环。
正确做法:进入DFS后立即标记当前位置:
void dfs(...) {grid[x][y] = '0'; // 立即标记// 再遍历相邻位置
}
3.方向数组的初始化
错误写法:
int dx[4] = {1, 0, -1, 0}; // 方向顺序混乱(如:下、右、上、左)
int dy[4] = {0, 1, 0, -1};
问题:方向顺序不统一可能导致代码可读性差,甚至漏掉某些方向。
正确做法:按统一顺序排列方向(如:下、上、右、左):
int dx[4] = {1, -1, 0, 0}; // 下、上、右、左
int dy[4] = {0, 0, 1, -1};
4.未处理空网格的边界情况
错误写法:
int numIslands(...) {// 没有检查网格是否为空rows = grid.size();cols = grid[0].size(); // 如果grid为空,这里会触发越界异常// ...
}
问题:当输入网格为空时,直接访问grid[0]会导致运行时错误。
正确做法:先检查网格是否为空:
if (grid.empty()) return 0; // 先处理空网格
rows = grid.size();
cols = grid[0].size();
5.重复计算网格尺寸
低效写法:
void dfs(...) {// 每次递归都重新计算网格尺寸int m = grid.size();int n = grid[0].size();// ...
}
问题:网格尺寸是固定的,重复计算会增加不必要的开销。
优化做法:将网格尺寸保存为类成员变量:
class Solution {
public:int rows, cols; // 类成员变量int numIslands(...) {rows = grid.size();cols = grid[0].size();// ...}
};
七、举一反三
学会这道题,你能解决所有「连通区域计数」问题,比如:
- LeetCode 695. 岛屿的最大面积:把计数改成计算每个岛屿的 ‘1’ 数量,取最大值。
- LeetCode 130. 被围绕的区域:判断哪些 ‘O’ 被 ‘X’ 包围,思路类似(从边界的 ‘O’ 出发标记,未标记的则被包围)。
- 图像渲染:给一个像素点,把所有相连的同色像素改成目标色,本质是连通区域染色。
最后欢迎大家在评论区分享你的代码或思路,咱们一起交流探讨~ 🌟 要是有大佬有更精妙的思路或想法,恳请在评论区多多指点批评,我一定会虚心学习,并且第一时间回复交流哒!

这是封面原图~ 喜欢的话先点个赞鼓励一下呗~ 再顺手关注一波,后续更新不迷路,保证让你看得过瘾!😉
