【强化学习漫谈】4. 从统一视角看 LLM Post-Training
目录
- LLM 的统一格式
- LLM Pretrain 为什么不能直接使用
- 各种 LLM Post-Training 方法在统一格式下的拆解
- SFT
- Reject Sampling Fine-Tuning
- PPO
- DPO
- 一些泛用 trick
- 一些讨论
- 为什么经典的 RLHF 是 SFT + RL
- 能不能融合 SFT 和 RL?
系列文章
- 【强化学习漫谈】1.RLHF:从PPO到GRPO
- 【强化学习漫谈】3.RLHF:从Reward Model到DPO
LLM 的统一格式
我们先回到最开始的位置,思考 LLM 究竟是在做什么?对于这个问题,可以说不止是 LLM,包括深度学习在内的所有 概率密度估计 算法,在做的事情都可以理解为:假设有一个理想分布 P ∗ P^* P∗,使得对于所有输入 x x x, P ∗ ( x ) P^*(x) P∗(x) 都是我们理想的输出。但是由于 P ∗ P^* P∗ 是不可知的,因此我们就希望寻找(训练)一个函数 π θ \pi_{\theta} πθ,使得 π θ \pi_{\theta} πθ 尽量靠近 P ∗ P^* P∗。训练出来的 π θ \pi_{\theta} πθ 就是可知的了,这样我们就可以使用 π θ \pi_{\theta} πθ 来达到非常接近理想分布 P ∗ P^* P∗ 的效果。数学上有一个概念就专门用于衡量两个分布之间的距离,即 KL 散度:
K L [ P ∗ ( x ) ∣ ∣ π θ ( x ) ] = E x ∼ P ∗ [ log P ∗ ( x ) π θ ( x ) ] \begin{aligned} KL[P^*(x)||\pi_{\theta}(x)] &= E_{x \sim P^*}[\text{log}\frac{P^*(x)}{\pi_{\theta}(x)}] \end{aligned} KL[P∗(x)∣∣πθ(x)]=Ex∼P∗[logπθ(x)P∗(x)]
上式直观上也很好理解,即如果 ∀ \forall ∀ x x x,都有 log P ∗ ( x ) π θ ( x ) = 0 \text{log}\frac{P^*(x)}{\pi_{\theta}(x)} = 0 logπθ(x)P∗(x)=0,说明 ∀ x , P ∗ ( x ) = π θ ( x ) \forall x, P^*(x) = \pi_{\theta}(x) ∀x,P∗(x)=πθ(x),那么这样找到的 π θ \pi_{\theta} πθ 自然是可以很好的拟合理想分布 P ∗ P^* P∗。因此我们可以把上式作为 训练目标,对目标函数求导,有:
∇ θ E x ∼ P ∗ [ log P ∗ ( x ) π θ ( x ) ] = ∇ θ E x ∼ P ∗ [ log P ∗ ( x ) − log π θ ( x ) ] = P ∗ ( x ) 与 θ 无关 − E x ∼ P ∗ [ ∇ θ log π θ ( x ) ] \begin{aligned} \nabla_{\theta}E_{x \sim P^*}[\text{log}\frac{P^*(x)}{\pi_{\theta}(x)}] &= \nabla_{\theta}E_{x \sim P^*}[\text{log}P^*(x) - \text{log}\pi_{\theta}(x)]\\ &\overset{P^*(x) 与 \theta 无关}{=} - E_{x \sim P^*}[\nabla_{\theta}\text{log}\pi_{\theta}(x)] \end{aligned} ∇θEx∼P∗[logπθ(x)P∗(x)]=∇θEx∼P∗[logP∗(x)−logπθ(x)]=P∗(x)与θ无关−Ex∼P∗[∇θlogπθ(x)]
但这个目标函数实际是无法使用的,因为这里要求样本 x x x 是从理想分布 P ∗ P^* P∗ 中采样的,但 P ∗ P^* P∗ 我们并不知道,很多时候也无法从中采样。但对于大部分任务,我们总可以拿到一批数据,这批数据可以看作是从另一个分布 π s a m p l e \pi_{sample} πsample 中采样的。那我们要如何用从 π s a m p l e \pi_{sample} πsample 采样的数据来估计 E x ∼ P ∗ log [ ∇ θ π θ ( x ) ] E_{x \sim P^*}\text{log}[\nabla_{\theta}\pi_{\theta}(x)] Ex∼P∗log[∇θπθ(x)] 呢?这里就需要再次使用我们在 PPO 中使用过的 重要性采样 调整了:
E x ∼ P ∗ [ ∇ θ log π θ ( x ) ] = ∑ x P ∗ ( x ) ∇ θ log π θ ( x ) = ∑ x π sample ( x ) P ∗ ( x ) π sample ( x ) ∇ θ log π θ ( x ) = E x ∼ π sample [ P ∗ ( x ) π sample ( x ) ∇ θ log π θ ( x ) ] \begin{aligned} E_{x \sim P^*}[\nabla_{\theta}\text{log}\pi_{\theta}(x)] &= \sum_x P^*(x)\nabla_{\theta}\text{log}\pi_{\theta}(x)\\ &= \sum_x \pi_{\text{sample}}(x) \frac{P^*(x)}{\pi_{\text{sample}}(x)} \nabla_{\theta}\text{log}\pi_{\theta}(x)\\ &= E_{x \sim \pi_{\text{sample}}} [\frac{P^*(x)}{\pi_{\text{sample}}(x)} \nabla_{\theta}\text{log}\pi_{\theta}(x)] \end{aligned} Ex∼P∗[∇θlogπθ(x)]=x∑P∗(x)∇θlogπθ(x)=x∑πsample(x)πsample(x)P∗(x)∇θlogπθ(x)=Ex∼πsample[πsample(x)P∗(x)∇θlogπθ(x)]
由于 LLM 都可以建模成 Next Token Prediction 问题,这里我们统一使用之前 PPO 中的记号: s t s_t st 表示 “prompt + 到当前 token 之前的所有 token”, a t a_t at 表示 “当前要预测的 token”。那么 LLM 中使用的梯度公式就可以写成:
E τ ∼ π sample [ ∑ t P ∗ ( a t ∣ s t ) π sample ( a t ∣ s t ) ∇ θ log π θ ( a t ∣ s t ) ] = 记作 E τ ∼ π sample [ ∑ t w ( a t ∣ s t ) ∇ θ log π θ ( a t ∣ s t ) ] \begin{aligned} E_{\tau \sim \pi_{\text{sample}}} [\sum_{t} \frac{P^*(a_t|s_t)}{\pi_{\text{sample}}(a_t|s_t)} \nabla_{\theta}\text{log}\pi_{\theta}(a_t|s_t)] \overset{记作}{=} E_{\tau \sim \pi_{\text{sample}}} [\sum_{t} w(a_t|s_t) \nabla_{\theta}\text{log}\pi_{\theta}(a_t|s_t)] \end{aligned} Eτ∼πsample[t∑πsample(at∣st)P∗(at∣st)∇θlogπθ(at∣st)]=记作Eτ∼πsample[t∑w(at∣st)∇θlogπθ(at∣st)]
其中 w ( a t ∣ s t ) = P ∗ ( a t ∣ s t ) π sample ( a t ∣ s t ) w(a_t|s_t) = \frac{P^*(a_t|s_t)}{\pi_{\text{sample}}(a_t|s_t)} w(at∣st)=πsample(at∣st)P∗(at∣st) 我们称之为 梯度系数,可以看出它表示的是 隐含理想分布相对采样分布的“调整”,并在训练时据此来 对每个 token 的梯度做不同程度的调整。接下来我们可以论证,常见的 LLM Post-Training 方法,例如:SFT,Reject Sampling Fine-Tuning,PPO,DPO 等等,都可以统一到上述格式,而不同方法间的区别主要在于:
- 数据集来源 π sample \pi_{\text{sample}} πsample 不同
- 梯度系数不同,这意味着 a. 隐含的目标分布 P ∗ P^* P∗ 不同, b. 体现在目标函数上就是对 token 的梯度调整策略不同
LLM Pretrain 为什么不能直接使用
在讨论 LLM Post-Training 之前,我们先来看另一个重要的问题:已经有 Pretain 模型了,为什么还要做 Post-Training 而不是直接使用 Pretrain 模型呢?我们知道,LLM Pretain 其实就是在大规模通用语料上通过 Next Token Prediction 建模了一个语言模型,目标函数如下:
E τ ∼ π sample [ ∑ t log π θ ( a t ∣ s t ) ] E_{\tau \sim \pi_{\text{sample}}} [\sum_{t} \text{log}\pi_{\theta}(a_t|s_t)] Eτ∼πsample[t∑logπθ(at∣st)]
其中 s t s_t st 表示 “prompt + 到当前 token 之前的所有 token”, a t a_t at 表示 “当前要预测的 token”。但这里有两个问题:
- 它建模的是一个 能够产生流畅文本的通用语言模型,但我们实际需要的缺不仅仅是一个语言模型,而是一个例如可以对话,可以写方案,可以解数学题的模型
- 上述目标函数会使得:
- 对于出现在样本集中的数据,只要当前模型对任意 s t , a t s_t,a_t st,at,有 π θ ( a t ∣ s t ) < 1 \pi_{\theta}(a_t|s_t) < 1 πθ(at∣st)<1,那么目标函数就会对其进行惩罚。这导致 π θ \pi_{\theta} πθ 不会给样本集的任何 token 出小概率或者零概率
- 对于没有出现在样本集中的数据,虽然我们本意可能是这样的数据是不希望模型拟合的数据,或者称“负样本”,但实际上这个想法并没有体现在目标函数中,这意味着我们的训练目标 并不约束 π θ \pi_{\theta} πθ 在样本集之外 token 上的概率
以上两个因素结合,对于 LLM 这种生成式模型,又考虑到其样本集规模巨大,最终会导致一个称为 “Zero Avoiding” 的效果。即在样本集内, π θ \pi_{\theta} πθ 会避免给零概率;而在样本集外,虽然给任何概率都不受惩罚,但模型仍然会倾向于给任意 token 都保留一定概率,因为这样是更“安全”的做法。事实上,我们经常说的 LLM 会出现 “幻觉”, 即训练集中没有出现过的说法,却会出现在输出中,就可以理解成 “Zero Avoiding” 现象的一种表现
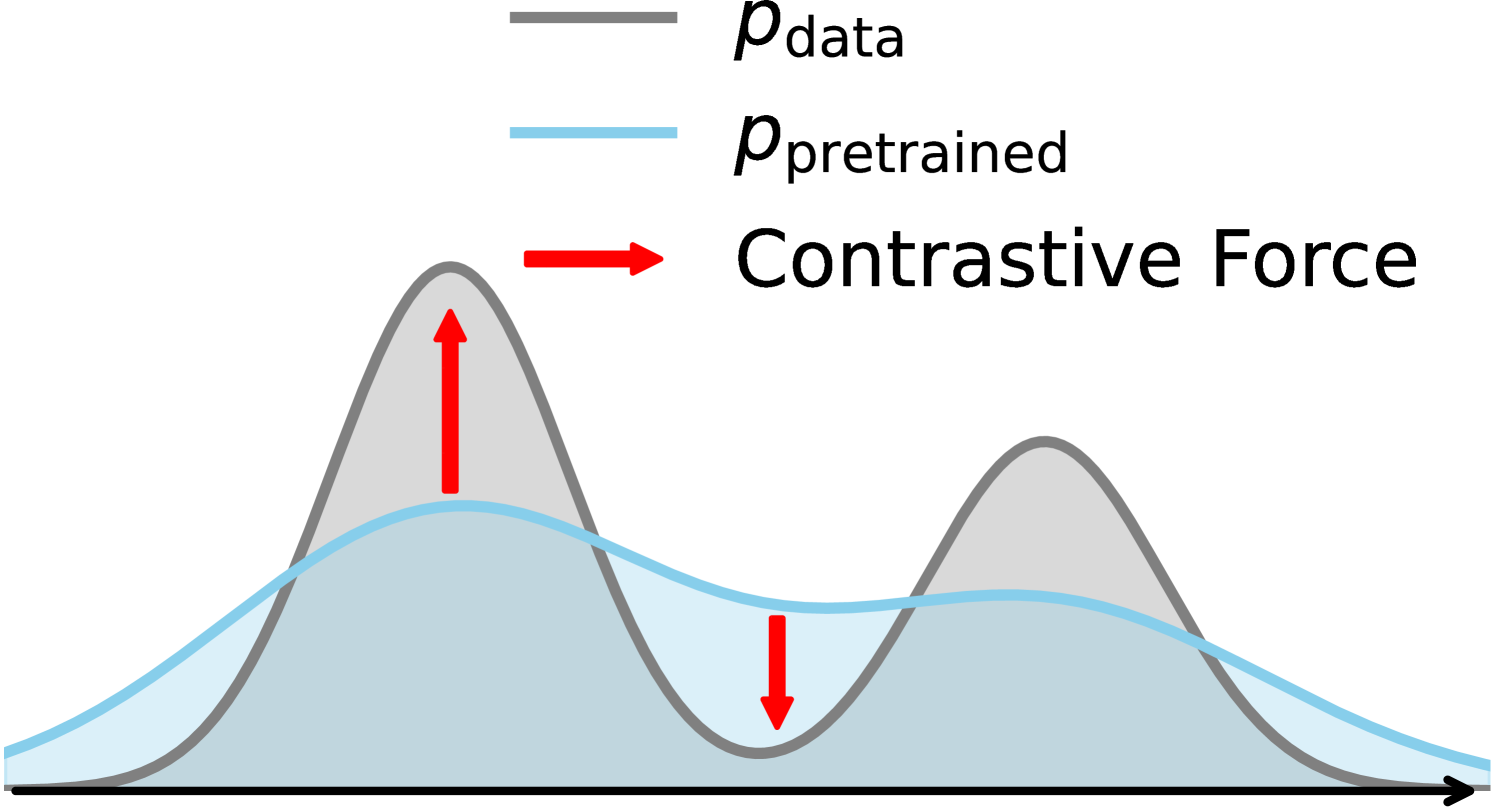
Note:事实上只要是使用交叉熵目标的模型在训练中都会遇到上述问题,但对于:
- 分类任务,由于输出空间要小得多,而且在 inference 时,我们只需要最优 label 可以胜出其他 label 即可,所以即使出现 “Zero Avoiding” 也不太影响实际使用效果
- 生成任务天然有 a. 输出空间巨大,b. 输出序列长度大,的特性。导致如果关键位置的错误 token 概率不为零,有可能使得一条错误的输出序列在后期整体胜出,从而产生劣质输出
各种 LLM Post-Training 方法在统一格式下的拆解
因此我们需要做 Post-Training 来解决/缓解上述说到的 LLM Pretrain 阶段的问题,回忆上述讨论过的目标函数梯度的统一格式:
E τ ∼ π sample [ ∑ t w ( a t ∣ s t ) ∇ θ log π θ ( a t ∣ s t ) ] E_{\tau \sim \pi_{\text{sample}}} [\sum_{t} w(a_t|s_t) \nabla_{\theta}\text{log}\pi_{\theta}(a_t|s_t)] Eτ∼πsample[t∑w(at∣st)∇θlogπθ(at∣st)]
其中梯度系数 w ( a t ∣ s t ) = P ∗ ( a t ∣ s t ) π sample ( a t ∣ s t ) w(a_t|s_t) = \frac{P^*(a_t|s_t)}{\pi_{\text{sample}}(a_t|s_t)} w(at∣st)=πsample(at∣st)P∗(at∣st) 表示 隐含目标分布相对于采样分布所作的“调整”。由于 Post-Training 是在 Pretrain 的基础上利用重要性采样技术进行“分布迁移”,一般需要满足以下两个条件才能使得训练过程比较稳定:
- 采样分布 π sample \pi_{\text{sample}} πsample 不会距离隐含目标分布 P ∗ P^* P∗ 太远 → \rightarrow → 否则重要性采样调整不准确
- 隐含目标分布 P ∗ P^* P∗ 不会离初始分布太远 → \rightarrow → 否则分布迁移太大,容易导致训练效率低,训练崩溃或者灾难性遗忘等问题
Note:第二条对于 on-policy 算法来说是一个 “动态目标”,因为每个 epoch 都会使用新的数据,这意味着每个 epoch 的隐含目标分布 P ∗ P^* P∗ 都在发生变化,而只要每个 epoch 的隐含目标分布 P ∗ P^* P∗ 不会离这个 epoch 的初始分布太远,就不会出现分布迁移过大
(其实这一条某种程度上来说应该是对 Pretrain 模型 π base \pi_{\text{base}} πbase 的要求,因为如果 P ∗ P^* P∗ 已经满足了条件 1,那么说明它就是一个好的目标分布。如果此时条件 3 不满足,我们应该调整的不是 P ∗ P^* P∗,而是初始分布 π base \pi_{\text{base}} πbase。这条也可以解释,很多时候如果后训练效果不好,除了调整数据和后训练方法,通过 continue pretrain 等方法提升 π base \pi_{\text{base}} πbase 或者干脆换一个更好的 π base \pi_{\text{base}} πbase 模型可能是一个更好的选择)
除此之外,以下两个条件可以帮助丰富 Loss 信息,有利于生成效果更好的模型:
1.对于负样本有可训练的信息
2. 有稠密的激励信号
第一条在前面讨论 LLM Pretrain 的时候说过,正是由于 Pretrain 阶段对于负样本是没有惩罚的,而正样本的置信度又非常高,导致这样的训练方式会有 “Zero Avoiding” 的特性,从而容易产生 “幻觉”。而引入可训练的负样本,输出中不正确的 token 会受到惩罚,进而会产生一种称为 “Zero Forcing” 的现象:
因此增加负样本训练信息可以缓解一部分 “幻觉” 问题。
第二条则是通过提供更精细的 Loss 信号,帮助模型雕琢更多细节。一个典型的例子是:
中国的首都不是南京,是北京 \text{中国的首都不是南京,是北京} 中国的首都不是南京,是北京
这样一条数据如果出现在 SFT 这种非稠密信号的模型中,它的每一个 token 都会赋予相同的权重 1,但这里面 “不是南京” 明显是废话,它不应该享有和 “是北京” 一样的置信度。但 PPO 这种稠密信号模型就可以给不同 token 以不同的权重,例如这里 “不是南京” 每个 token 可能只有 0.1 的激励而 “是北京” 有 1 的激励,那么模型就可能学到 “中国的首都是北京” 是一个更好的回复。
但这两项的一个问题是,会使建模的目标函数不再是标准的语言模型了,这意味着如果任务数据与原始分布迁移较大,甚至发生模式坍塌/灾难性遗忘时,SFT 模型至少还能保持语言能力,但 RL 模型却可能连语言能力都不保留,生成一些不通顺的句子。
接下来我们要把不同 LLM Post-Training 方法按前面推导的统一格式进行拆解,并讨论各个算法的优势和问题。
SFT
SFT 的训练过程其实和 Pretrain 阶段是一样的,唯一的区别是,我们使用的数据集不再是通用数据集,而是适配指定任务的一个离线数据集,因此
- π sample \pi_{\text{sample}} πsample 为任务数据集
- 梯度系数 w ( a t ∣ s t ) = 1 w(a_t|s_t) = 1 w(at∣st)=1,隐含目标分布 P ∗ = π sample P^* = \pi_{\text{sample}} P∗=πsample : P ∗ ( a t ∣ s t ) = { 1 输出在样本集内 0 输出在样本集外 P^*(a_t|s_t) =\begin{cases} 1& 输出在样本集内\\ 0& 输出在样本集外 \end{cases} P∗(at∣st)={10输出在样本集内输出在样本集外
SFT 的想法是最简单直接的,它相当于就是在 直接把初始分布往任务分布上迁移,这样的好处是:
- 训出来的模型一般都具有完成指定任务的能力(因为目标直接就是拟合任务数据集)
- 训出来的模型一般还是可以保持较好的语言能力,因为 SFT 的目标函数仍然是在建模语言模型
问题也显而易见:
- SFT 直接拟合任务数据集,因此它的效果和泛化性,会非常依赖数据的质量以及多样性
- SFT 并不能保证隐含目标分布 P ∗ P^* P∗ 不会离初始分布太远,这可能会导致训练不稳定 & 灾难性遗忘问题
- SFT 对负样本不提供训练信息,因此它也容易出现 “幻觉”。而 Pretrain 模型本来就有幻觉,如果分布迁移比较大,相当于引入的还是新的幻觉,因此 SFT 很多时候幻觉会比 Pretrain 模型更严重
SFT 的优化方向:
- 尽可能提高数据质量和多样性
- 对于指定的任务数据集,可以通过在基础模型上计算 Perplexity,来判断是否有分布迁移过大的问题。也可以通过剔除 Perplexity 过高的样本,缓解分布迁移大的问题。(这里有一个点可以聊一下,对于同一个问题,可能不同的几个回复在我们看来都是对的,因此它们都可以出现在任务数据集中。但不同的基础模型,由于训练数据和训练方式不一样,可能就会出现例如某个模型它只“认”顺序说法,但对于倒装说法困惑度却很高的情况。这里剔除困惑度高的数据其实就是先“顺着”基础模型的风格来,如果非要保留困惑度高的数据进训练,可以在后面的 epoch 中再逐步混入这些数据,并调小学习率,防止抖动过大)
- 如果任务数据集就是比较“脏”,但出于各种原因又不得不用,也可以通过加一个 KL 散度惩罚来避免模型被脏数据带的太远,即: E τ ∼ π task [ ∑ t log π θ ( a t ∣ s t ) + KL [ π base ( a t ∣ s t ) ∣ ∣ π θ ( a t ∣ s t ) ] ] E_{\tau \sim \pi_{\text{task}}} [\sum_{t} \text{log}\pi_{\theta}(a_t|s_t) + \text{KL}[\pi_{\text{base}}(a_t|s_t)||\pi_{\theta}(a_t|s_t)]] Eτ∼πtask[t∑logπθ(at∣st)+KL[πbase(at∣st)∣∣πθ(at∣st)]]
SFT 适合的场景
- 格式调整:即基础模型已经具备回答问题所需的知识,但输出格式杂乱的情况(原因:分布偏移较小,且偏移方向明确,适合 SFT 对 token 都给高置信的特点)
- 文风/语气转换:这类任务对回复的内容没有特别要求,可以认为是在基础模型的输出上,通过添加语气词/修改用字等方式进行调整,也符合 SFT 的特性
Reject Sampling Fine-Tuning
不同于 SFT 直接使用任务数据,Reject Sampling Fine-Tuning 的工作流程是:
- 给定任务 prompt,从初始模型 π base \pi_{\text{base}} πbase 收集一批数据集
- 通过人工选择/模型选择的方式,只留下“判断为正确”的数据
- 在这个数据集上进行 Fine-Tuning
其目标函数梯度可以写成:
E τ ∼ π base [ ∑ t I ( τ ) ∇ θ log π θ ( a t ∣ s t ) ] E_{\tau \sim \pi_{\text{base}}} [\sum_{t} \mathbb{I}(\tau) \nabla_{\theta}\text{log}\pi_{\theta}(a_t|s_t)] Eτ∼πbase[t∑I(τ)∇θlogπθ(at∣st)]
因此:
- π sample \pi_{\text{sample}} πsample 为 π base \pi_{\text{base}} πbase
- 梯度系数 w ( a t ∣ s t ) = I ( τ ) = { 1 输出判断为正确 0 输出判断为错误 w(a_t|s_t) = \mathbb{I}(\tau) =\begin{cases} 1& 输出判断为正确\\ 0& 输出判断为错误 \end{cases} w(at∣st)=I(τ)={10输出判断为正确输出判断为错误,隐含目标分布是 P ∗ ( a t ∣ s t ) = { 1 输出判断为正确 0 输出判断为错误 P^*(a_t|s_t) =\begin{cases} 1& 输出判断为正确\\ 0& 输出判断为错误 \end{cases} P∗(at∣st)={10输出判断为正确输出判断为错误
RFT 跟 SFT 整体还是比较像,主要的区别在于数据的来源。不同于 SFT 使用离线任务数据,RFT 只有一个任务 Prompt 集合,回复是从初始模型 π base \pi_{\text{base}} πbase 直接采样的,因此它天然不容易出现 “分布迁移太大的问题”。但这样的数据来源有另一个问题是:采集的回复不一定满足任务需求,因此它需要一个 Verifier 来筛选符合任务需要的数据。换句话说,SFT 是先确保数据是任务数据,再筛选分布迁移小的;RFT 是先确保数据集分布迁移小,再筛选符合任务的
RFT 优点:
- 天然不容易出现分布迁移过大的问题
- 无需准备高质量回复数据集
- 也能保持语言能力
RFT 问题:
- 需要一个靠谱的 Verifier,而这个 Verifier 不一定是容易获得的
- 对基础模型要求高,因为数据全部来自于初始模型采样,如果基础模型能力不足,较难获得理想数据
- 类似 SFT,也会引入幻觉
RFT 适合的场景
- 任务高质量数据集难以获得,但 Verifier 相对容易获得 (例如 math/code 任务)
- 需要快速验证模型在指定任务上迁移能力的情况(因为RFT 可以“随时”对一批新 Prompt 重新采样并筛选,不用等完整的数据标注过程,就能快速验证模型对新需求的效果)
PPO
前面我们曾经推导过 PPO 的目标函数:
J ( θ ) = E y ∼ π θ [ ∑ t = 0 T A ^ π ( s t , a t ) − β ⋅ D K L [ π θ ( y ∣ x ) ∣ ∣ π r e f ( y ∣ x ) ] ] J(\theta) = E_{y \sim \pi_\theta}[\sum_{t=0}^T \hat{A}_{\pi}(s_t,a_t) - \beta \cdot D_{KL}[\pi_{\theta}(y|x) || \pi_{ref}(y|x)]] J(θ)=Ey∼πθ[t=0∑TA^π(st,at)−β⋅DKL[πθ(y∣x)∣∣πref(y∣x)]]
其中:
A ^ π ( s t , a t ) = min [ π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) A π G A E ( s t , a t ) , c l i p ( π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) , 1 − ϵ , 1 + ϵ ) A π G A E ( s t , a t ) ] \hat{A}_{\pi}(s_t,a_t) =\text{min}[\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta}^{old}(a_t|s_t)}A^{GAE}_\pi(s_t,a_t), clip(\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta}^{old}(a_t|s_t)}, 1- \epsilon, 1+\epsilon)A^{GAE}_\pi(s_t,a_t)] A^π(st,at)=min[πθold(at∣st)πθ(at∣st)AπGAE(st,at),clip(πθold(at∣st)πθ(at∣st),1−ϵ,1+ϵ)AπGAE(st,at)]
这里 D K L [ π θ ( y ∣ x ) ∣ ∣ π r e f ( y ∣ x ) ] D_{KL}[\pi_{\theta}(y|x) || \pi_{ref}(y|x)] DKL[πθ(y∣x)∣∣πref(y∣x)] 是为了防止reward hacking而增加的一项,原始的 PPO 模型只考虑了:
E y ∼ π θ [ ∑ t = 0 T A ^ π ( s t , a t ) ] E_{y \sim \pi_\theta}[\sum_{t=0}^T \hat{A}_{\pi}(s_t,a_t) ] Ey∼πθ[t=0∑TA^π(st,at)]
求导为:
E y ∼ π θ [ ∑ t = 0 T A ^ π ( s t , a t ) ∇ θ log π θ ( a t ∣ s t ) ] E_{y \sim \pi_\theta}[\sum_{t=0}^T \hat{A}_{\pi}(s_t,a_t) \nabla_{\theta}\text{log}\pi_{\theta}(a_t|s_t)] Ey∼πθ[t=0∑TA^π(st,at)∇θlogπθ(at∣st)]
因此:
- π sample \pi_{\text{sample}} πsample 为当前 epoch 的起始分布 π θ start \pi_{\theta}^{\text{start}} πθstart
- 梯度系数 w ( a t ∣ s t ) = A ^ π ( s t , a t ) w(a_t|s_t) = \hat{A}_{\pi}(s_t,a_t) w(at∣st)=A^π(st,at),隐含目标分布是 P ∗ ( a t ∣ s t ) = π θ start ( a t ∣ s t ) ⋅ A ^ π ( s t , a t ) P^*(a_t|s_t) =\pi_{\theta}^{\text{start}}(a_t|s_t) \cdot \hat{A}_{\pi}(s_t,a_t) P∗(at∣st)=πθstart(at∣st)⋅A^π(st,at)
不同于前面的 SFT 和 RFT 只在指定数据集上做一次分布迁移这种 “迈大步”,PPO 的优化策略更像是 “小碎步逐渐积累” ,这里
P ∗ ( a t ∣ s t ) = π θ start ( a t ∣ s t ) ⋅ A ^ π ( s t , a t ) P^*(a_t|s_t) =\pi_{\theta}^{\text{start}}(a_t|s_t) \cdot \hat{A}_{\pi}(s_t,a_t) P∗(at∣st)=πθstart(at∣st)⋅A^π(st,at)
可以理解成:在当前 epoch,从起始分布 π θ start \pi_{\theta}^{\text{start}} πθstart 采样一批回复,然后根据每个 token 的优势 A ^ π ( s t , a t ) \hat{A}_{\pi}(s_t,a_t) A^π(st,at),对起始分布 π θ start ( a t ∣ s t ) \pi_{\theta}^{\text{start}}(a_t|s_t) πθstart(at∣st) 进行调整,优势高的 token 就把它的输出概率调高一点,优势低的 token 就把它的输出概率调低一些。 一个 epoch 后得到的这个 P ∗ P^* P∗ 就会成为下一个 epoch 的 起始分布 π θ start \pi_{\theta}^{\text{start}} πθstart,然后再重复 “采样+调整” 的步骤,这样 一小步一小步 的接近最后的目标。
我们可以通过两个图像很直观的看到这类 RL 方法的调整效果:
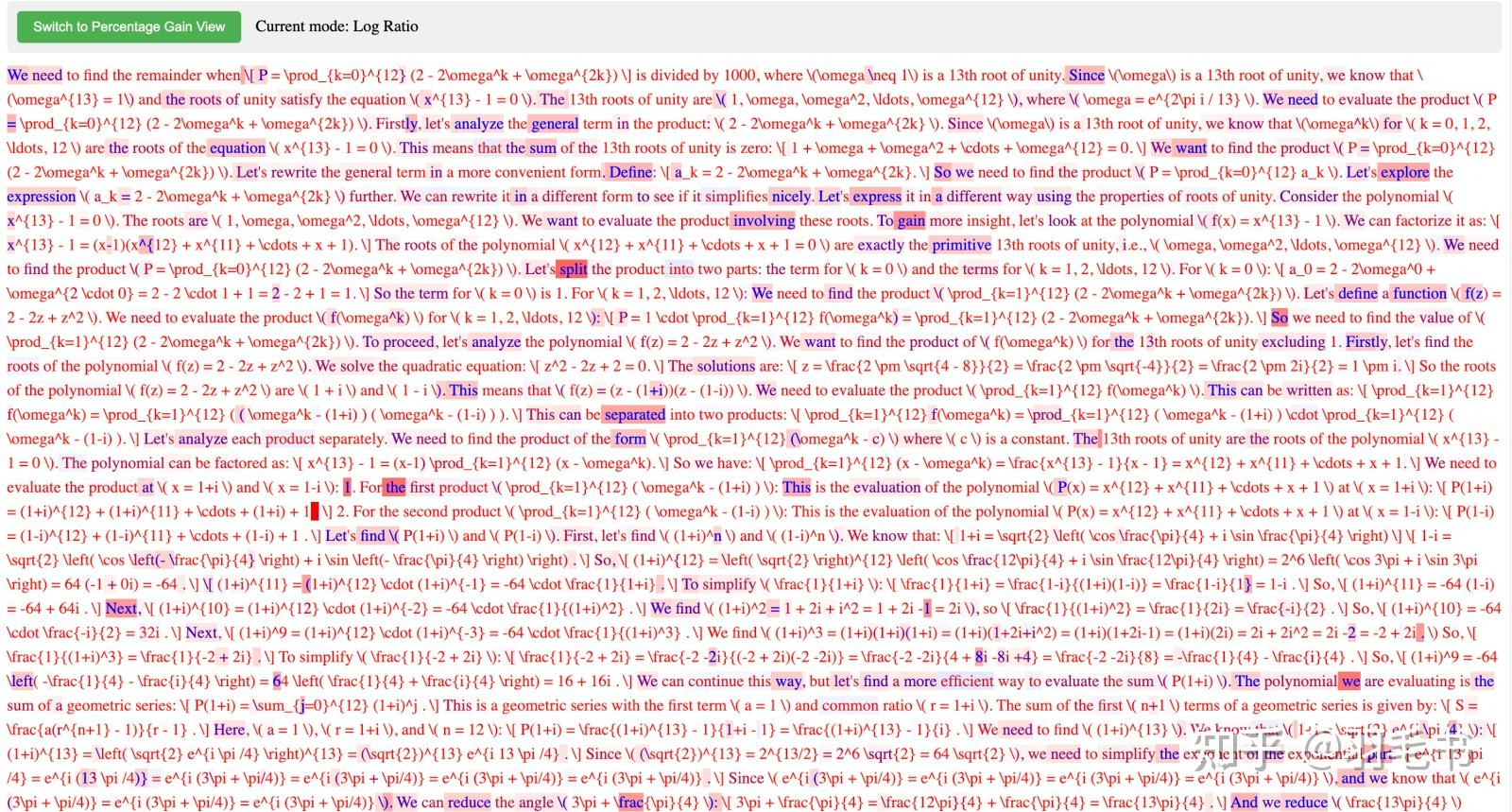
图一展示的是 RL 模型生成的一个推理内容,其中红色越深的,说明相比基础模型,模型对这个 token 的调整力度越大,即它是 RL 模型找到的 “优势高” 的 token。可以看出:输出概率的改变大部分都发生在连接词、推理流程影响的词,而在单步公式、数字、推理这些基本能力上,模型输出几乎还是在沿用基础模型认为最好的路径,说明这些基础能力几乎完全来自基础模型
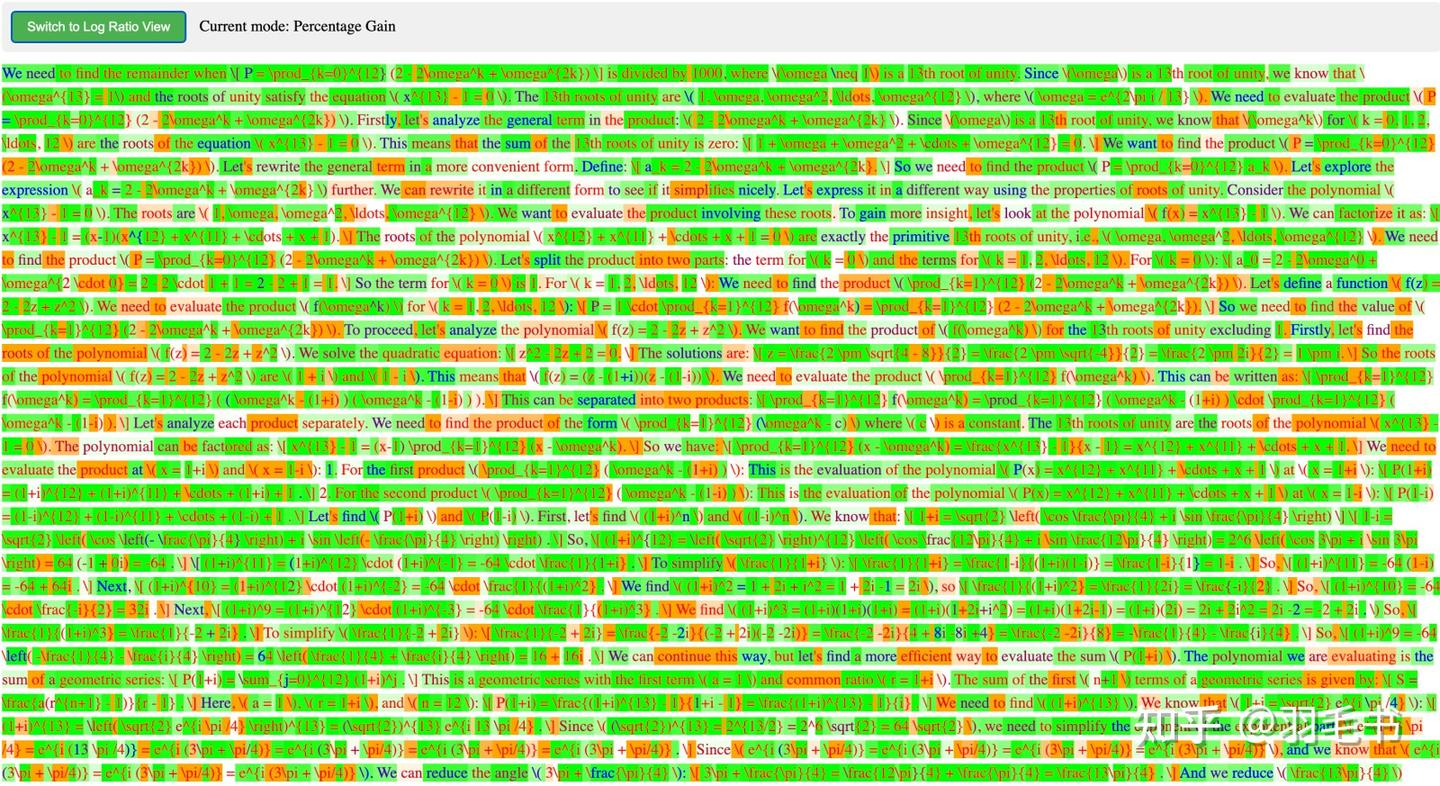 图二展示了 RL 模型生成的回复中,相比基础模型,对每个 token 的置信度接近 1 的程度,越绿的说明模型对这个 token 越有信心。可以看出:==基础模型中本来概率很高的 token,依然在 RL 中被不断加强,在训练后置信度变得更接近1,也就是进行了过度自信的优化==
图二展示了 RL 模型生成的回复中,相比基础模型,对每个 token 的置信度接近 1 的程度,越绿的说明模型对这个 token 越有信心。可以看出:==基础模型中本来概率很高的 token,依然在 RL 中被不断加强,在训练后置信度变得更接近1,也就是进行了过度自信的优化==
\quad
PPO 的优势:
相比简单直接的 SFT,PPO 明显是一个下了更多功夫,有更多细节的算法。首先就是它在训练稳定性上下了很多功夫,由于每个 epoch 的 P ∗ P^* P∗ 相对 π θ start \pi_{\theta}^{\text{start}} πθstart 的调整程度取决于 A ^ π ( s t , a t ) \hat{A}_{\pi}(s_t,a_t) A^π(st,at),而优势函数由于做了 “Clip”,调整是有限制的,而每个 epoch 的训练数据直接从 π θ start \pi_{\theta}^{\text{start}} πθstart 上采,这导致以下两个条件 PPO 都是直接满足了的:
- 采样分布 π sample \pi_{\text{sample}} πsample 不会距离隐含目标分布 P ∗ P^* P∗ 太远
- 隐含目标分布 P ∗ P^* P∗ 不会离初始分布太远
除此之外,PPO 也提供了负样本的训练信息以及稠密的激励信号,因此它的优势还有:
- 模型回复可控性较高,不容易出现“幻觉”
PPO 的缺点
- 非常依赖基础模型的能力,甚至比 RFT 对基础模型的要求还高,因为 RFT 在采样之后好歹还会过一下 Verifier,一定程度上减少了对基础模型能力的依赖,而 PPO 是采啥用啥
- 依赖 Reward Model 的性能,因为优势函数基本就依赖 Reward Model 的能力,所以这一项直接影响 PPO 的最终效果
- PPO 由于建模的不是语言模型,如果 reward hacking 严重,甚至可能丢失语言能力
- 计算量大,这个之前讲 PPO 时已经详细讨论过了
PPO 的优化方向
- 加一个与基础模型的 KL 散度,既可以缓解 reward hacking,也可以维持语言能力
- 找一批 通用数据集,加一个在这个数据上的 Pretrain Loss,这一项是更直接的维持语言能力
- 前面两项虽然是 PPO 的经典做法,大部分训练框架也都实现了,但近来的很多研究表明由于上面两项都是对所有token无差别加的,而我们前面说过,PPO 其实就是根据优势函数,调整一些 token 的概率。所以有可能 PPO 好不容易做了一点不错的调整,一个 KL 散度又给拉回去了。因此更好的一个做法是:只给 “正样本” 加 Pretrain Loss (Positive-Example LM Loss): E y ∼ π θ [ ∑ t = 0 T A ^ π ( s t , a t ) ] + E y + ∼ π θ + [ ∑ t = 0 T + log π θ ( a t ∣ s t ) ] E_{y \sim \pi_\theta}[\sum_{t=0}^T \hat{A}_{\pi}(s_t,a_t) ] + E_{y^+ \sim \pi_\theta^+}[\sum_{t=0}^{T^+} \text{log}\pi_{\theta}(a_t|s_t) ] Ey∼πθ[t=0∑TA^π(st,at)]+Ey+∼πθ+[t=0∑T+logπθ(at∣st)]
PPO 适合的场景
- 理想输出空间大,无法通过单一示例 SFT 精准刻画的场景。eg:推理,多轮对话,复杂问答
- 需要显示避免某种输出的任务。eg:代码生成,安全生产
- 偏好明确的任务,这类任务一般容易构建稳定的 reward signal。eg:毒性检测,政治敏感问题
DPO
之前我们推导的 DPO 目标函数为:
E τ + , τ − ∼ D τ [ log σ ( ∑ t = 0 T + β log π θ ( a t + ∣ s t + ) π r e f ( a t + ∣ s t + ) − ∑ t = 0 T − β log π θ ( a t − ∣ s t − ) π r e f ( a t − ∣ s t − ) ) ] E_{\tau^+,\tau^- \sim \mathcal{D_{\tau}}}[\text{log} \sigma(\sum_{t=0}^{T^+} \beta \text{log} \frac{\pi_{\theta}(a_t^+|s_t^+)}{\pi_{ref}(a_t^+|s_t^+)} - \sum_{t=0}^{T^-}\beta \text{log}\frac{\pi_{\theta}(a_t^-|s_t^-)}{\pi_{ref}(a_t^-|s_t^-)})] Eτ+,τ−∼Dτ[logσ(t=0∑T+βlogπref(at+∣st+)πθ(at+∣st+)−t=0∑T−βlogπref(at−∣st−)πθ(at−∣st−))]
求导为:
E τ + , τ − ∼ D τ [ ∑ t = 0 T + exp ( β R dpo ) ∇ θ log π θ ( a t + ∣ s t + ) − ∑ t = 0 T − exp ( β R dpo ) ∇ θ log π θ ( a t − ∣ s t − ) ] E_{\tau^+,\tau^- \sim \mathcal{D_{\tau}}}[\sum_{t=0}^{T^+} \text{exp}(\beta R_{\text{dpo}}) \nabla_{\theta}\text{log} \pi_{\theta}(a_t^+|s_t^+) - \sum_{t=0}^{T^-}\text{exp}(\beta R_{\text{dpo}}) \nabla_{\theta}\text{log}\pi_{\theta}(a_t^-|s_t^-)] Eτ+,τ−∼Dτ[t=0∑T+exp(βRdpo)∇θlogπθ(at+∣st+)−t=0∑T−exp(βRdpo)∇θlogπθ(at−∣st−)]
DPO 中,样本是成对出现的,其中 R dpo = log π θ ( a t + ∣ s t + ) π r e f ( a t + ∣ s t + ) − log π θ ( a t − ∣ s t − ) π r e f ( a t − ∣ s t − ) R_{\text{dpo}} =\text{log} \frac{\pi_{\theta}(a_t^+|s_t^+)}{\pi_{ref}(a_t^+|s_t^+)} - \text{log}\frac{\pi_{\theta}(a_t^-|s_t^-)}{\pi_{ref}(a_t^-|s_t^-)} Rdpo=logπref(at+∣st+)πθ(at+∣st+)−logπref(at−∣st−)πθ(at−∣st−) 表示这对样本的“偏好分数”。因此带入统一格式有:
- π sample \pi_{\text{sample}} πsample 为 D τ \mathcal{D_{\tau}} Dτ,即可以是一个明确的离线数据集,也可以是初始模型 π base \pi_{\text{base}} πbase 中采集的数据
- 梯度系数 w ( a t ∣ s t ) = exp ( β R dpo ) w(a_t|s_t) = \text{exp}(\beta R_{\text{dpo}}) w(at∣st)=exp(βRdpo),隐含目标分布是 P ∗ ( a t + , a t − ∣ s t ) = π sample ( a t + ∣ s t + ) ⋅ π sample ( a t − ∣ s t − ) ⋅ exp ( β R dpo ) P^*(a_t^+,a_t^-|s_t) =\pi_{\text{sample}}(a_t^+|s_t^+) \cdot \pi_{\text{sample}}(a_t^-|s_t^-) \cdot \text{exp}(\beta R_{\text{dpo}}) P∗(at+,at−∣st)=πsample(at+∣st+)⋅πsample(at−∣st−)⋅exp(βRdpo)
相比于 PPO 这种传统 RL 方法, DPO 绕开了对 reward model 的依赖,直接通过提供偏好对样本来提供训练信息。上述隐含目标分布可以拆成:
P ∗ ( a t + , a t − ∣ s t ) = π sample ( a t + ∣ s t + ) ⋅ π sample ( a t − ∣ s t − ) ⋅ exp ( β R dpo ) = π sample ( a t + ∣ s t + ) ⋅ π sample ( a t − ∣ s t − ) ⋅ exp ( β log π θ ( a t + ∣ s t + ) π r e f ( a t + ∣ s t + ) − β log π θ ( a t − ∣ s t − ) π r e f ( a t − ∣ s t − ) ) = [ exp ( β log π θ ( a t + ∣ s t + ) π r e f ( a t + ∣ s t + ) ) ⋅ π sample ( a t + ∣ s t + ) ] ⋅ [ exp ( − β log π θ ( a t − ∣ s t − ) π r e f ( a t − ∣ s t − ) ) ⋅ π sample ( a t − ∣ s t − ) ] \begin{aligned} P^*(a_t^+,a_t^-|s_t) &=\pi_{\text{sample}}(a_t^+|s_t^+) \cdot \pi_{\text{sample}}(a_t^-|s_t^-) \cdot \text{exp}(\beta R_{\text{dpo}})\\ &= \pi_{\text{sample}}(a_t^+|s_t^+) \cdot \pi_{\text{sample}}(a_t^-|s_t^-) \cdot \text{exp}(\beta\text{log} \frac{\pi_{\theta}(a_t^+|s_t^+)}{\pi_{ref}(a_t^+|s_t^+)} - \beta\text{log}\frac{\pi_{\theta}(a_t^-|s_t^-)}{\pi_{ref}(a_t^-|s_t^-)})\\ &= [\text{exp}(\beta\text{log} \frac{\pi_{\theta}(a_t^+|s_t^+)}{\pi_{ref}(a_t^+|s_t^+)})\cdot \pi_{\text{sample}}(a_t^+|s_t^+) ]\cdot [\text{exp}(- \beta\text{log}\frac{\pi_{\theta}(a_t^-|s_t^-)}{\pi_{ref}(a_t^-|s_t^-)})\cdot \pi_{\text{sample}}(a_t^-|s_t^-)] \end{aligned} P∗(at+,at−∣st)=πsample(at+∣st+)⋅πsample(at−∣st−)⋅exp(βRdpo)=πsample(at+∣st+)⋅πsample(at−∣st−)⋅exp(βlogπref(at+∣st+)πθ(at+∣st+)−βlogπref(at−∣st−)πθ(at−∣st−))=[exp(βlogπref(at+∣st+)πθ(at+∣st+))⋅πsample(at+∣st+)]⋅[exp(−βlogπref(at−∣st−)πθ(at−∣st−))⋅πsample(at−∣st−)]
这样就能看出,如果用 PPO 中的概念来理解,DPO 其实就是给了正样本一个 exp ( β log π θ ( a t + ∣ s t + ) π r e f ( a t + ∣ s t + ) ) \text{exp}(\beta\text{log} \frac{\pi_{\theta}(a_t^+|s_t^+)}{\pi_{ref}(a_t^+|s_t^+)}) exp(βlogπref(at+∣st+)πθ(at+∣st+)) 大小的优势,负样本一个 exp ( − β log π θ ( a t − ∣ s t − ) π r e f ( a t − ∣ s t − ) ) \text{exp}(- \beta\text{log}\frac{\pi_{\theta}(a_t^-|s_t^-)}{\pi_{ref}(a_t^-|s_t^-)}) exp(−βlogπref(at−∣st−)πθ(at−∣st−)) 大小的优势。基本的趋势是:
1.对于正样本,当前模型相比基础模型生成正样本的概率越高,优势越大
2. 对于负样本,当前模型相比基础模型生成负样本的概率越高,优势越小
这样就能鼓励模型增加正样本生成的概率,降低负样本生成的概率。我们再回头来看 PPO 的优势函数是怎么构造的:
A π ( s t , a t ) = Q π ( s t , a t ) − E s t [ Q π ( s t , a t ) ] A_\pi(s_t,a_t) = Q_\pi(s_t,a_t) - E_{s_t}[Q_\pi(s_t,a_t)] Aπ(st,at)=Qπ(st,at)−Est[Qπ(st,at)]
- 从形态上来看,PPO 的优势是线性函数,对大小优势一视同仁,而且可以通过给负优势来强烈压制某些 token 的概率;而 DPO 的优势函数是指数函数,我们看指数函数的形态:
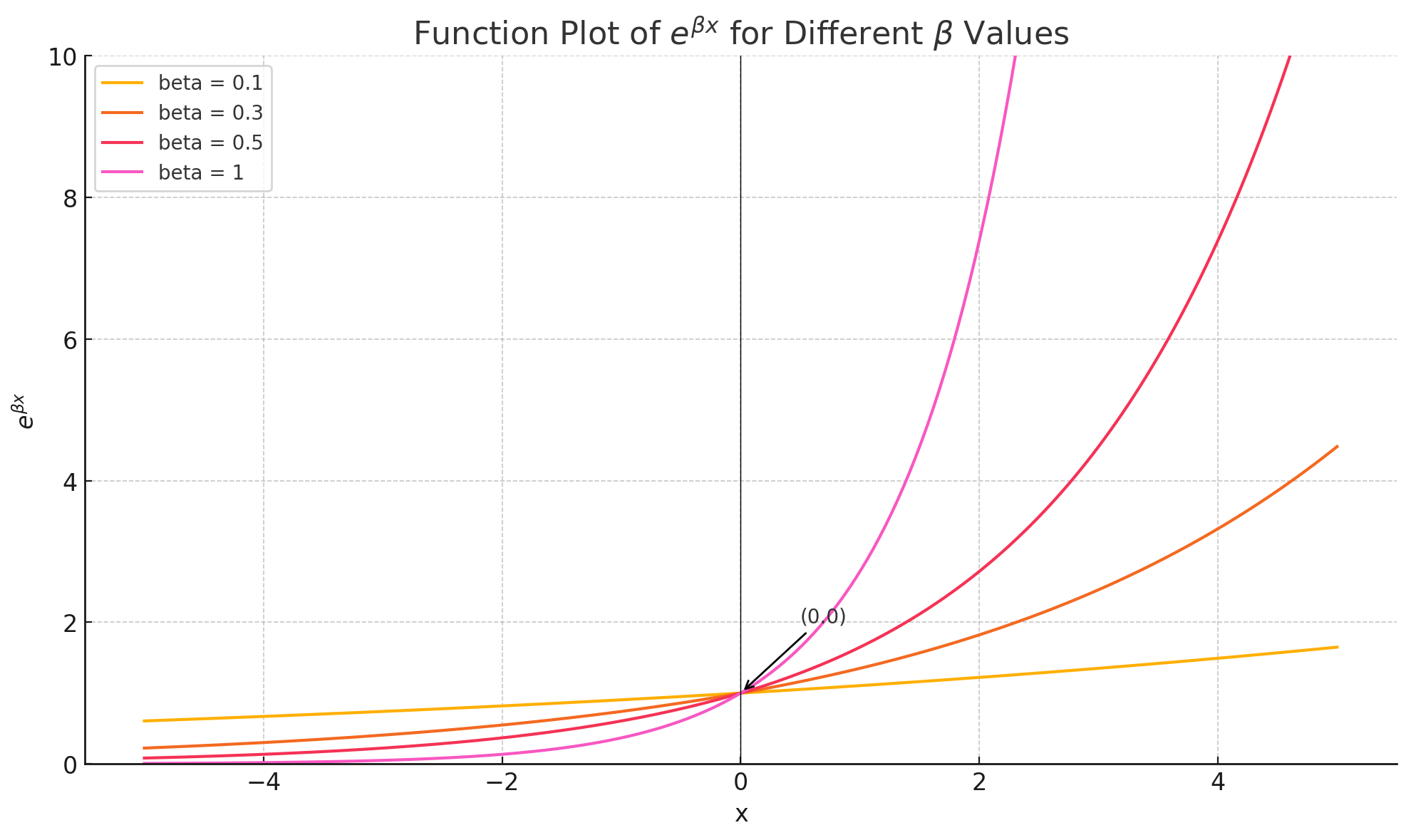
- 首先 DPO 的优势只有大小,没有正负
- 其次位于曲线两头的样本对模型更新的力度完全不对称:尤其是当 β \beta β 比较大时,稍微增加正样本的生成概率,就能有很大的增益;而压低负样本的生成概率增益却不明显。从这个角度也能解释我们之前聊 DPO 时的一个现象: 当正样本和负样本比较相似时,开始时可以增加正样本概率,降低负样本概率,但当负样本概率降低到一定程度,再持续增大 margin 反而会拉低正样本的生成概率。 也是指数函数这种两头极度不对称现象带来的问题。
- 再从基准线来看,PPO 和 GRPO 本意都是想拟合 “预取分数线”,只是 PPO 是采样了迭代的方式,而 GRPO 是通过多个样本求平均的方法。而 DPO 就比较简单粗暴了,直接使用基础模型在样本的概率作为基准线,优势是计算量小,缺点是准确性应该不太高。
DPO 的优势
- 计算量小
- 模型回复可控性较高,不容易出现“幻觉”
DPO 的劣势:
- 基础假设有“缺陷”(通过使用比较小的 β \beta β 可以缓解)
- 如果采用离线数据集,分布迁移不可控,有可能会训练不稳定
- 也不能保证维持语言能力
DPO 适合的场景
- 想引入负样本,但计算资源有限
一些泛用 trick
其实在把各种常见的 LLM Post-Training 统一到同一个格式之后,我们就会发现一些可能产生问题的点都是类似的,因此不管使用的是哪种算法,有一些 trick 是都可以考虑使用的:
- 基础模型很重要,训之前先测测看基础模型在指定任务上的能力,如果太差考虑换模型
- 在线采样很重要,如果不能在线采,可以通过 Verifier 过滤掉一些分布偏移大的数据,或者控制这种数据在数据集中出现的比例和顺序 → \rightarrow → (稳定训练,防止灾难遗忘/模式坍缩)
- 有时会面临人工数据可能分布迁移过大,而在线数据质量又不够好(不足以体现任务目标),也可以考虑在在线数据中混入一些人工标注数据,有利于给模型提供正确的指导
- 数据脏/Verifier差,加 KL 散度防止模型被带跑偏
- RL 类模型都可以在正样本上加 pretrain loss,以维持语言能力
- 依赖 Reward Model/Verifier 的算法,如果 Reward Model/Verifier 不靠谱,考虑使用更小的学习率/学习率退火,防止步子迈大了一下子学崩了
- 只要是在多个 epoch 中重复使用同一批数据进行训练的算法,都可以使用 PPO 中的“重采样+Clip”技术,这样可以在降低采样成本和维持模型性能上找一个平衡
- Prompt 集要精心选择,对于随机采样 N 个回复,N 个回答全对或者全错的,都不是好 Prompt,没有有益的训练信号,还可能带来噪声,可以删除掉/降低比例
一些讨论
经过上面的分析,我们可以尝试解答/思考一些问题:
为什么经典的 RLHF 是 SFT + RL
其实从前面的分析就能看出,SFT 和 RL 具有明显的 “互补” 特性:
- RL 只在基础模型附近调整,如果基础模型效果不好,很容易训崩;SFT 刚好擅长把分布迁移到指定位置
- SFT 目标明确,但信号粗糙,只能大概把分布迁移到目标附近;RL 雕琢细节,完成关键的最后一步
- SFT “Zero Avoiding”,容易有幻觉;RL “Zero Forcing”,回复可控
最近的 Reinforcement Learning Finetunes Small Subnetworks in Large Language Models 论文就发现:与 RL 阶段相比,SFT 阶段的参数更新则密集得多。从下图可以看到:SFT 的更新密度很高(稀疏性仅为6%-15%),而 RL 则呈现出显著的稀疏性(通常高于70%)
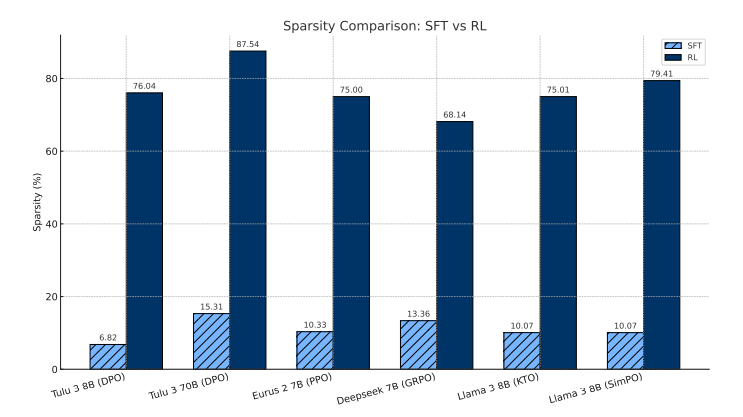
这也论证了刚刚说的:SFT 先大刀阔斧先把模型拉到任务分布附近,RL 再在这个基础上,精心雕琢一些细节,提升回复质量。其实这个组合与人类学习新技能的过程也很相似:
- 例如学习一个代码语言,先是通过看书&示例代码了解这门语言的固定语法,大概知道该怎么写了(SFT);然后自己实际上手写一些代码,并通过编译器运行结果反馈写得对不对(RL:在线采样+RM打分),再通过看报错修改之前的错误认知(RL:更新策略),然后修改代码再编译(RL:在新策略上采样+RM打分),这样循环往复
- 再例如学习写诗,是不是也得先从背诗开始,知道好的诗都是咋写的(SFT);然后再尝试自己写,然后老师会评点哪里写得好,哪个字可以修改(RL:在线采样+RM打分),体会老师的点评精华(RL:更新策略),重新修改然后再给老师看(RL:在新策略上采样+RM打分),这样循环往复
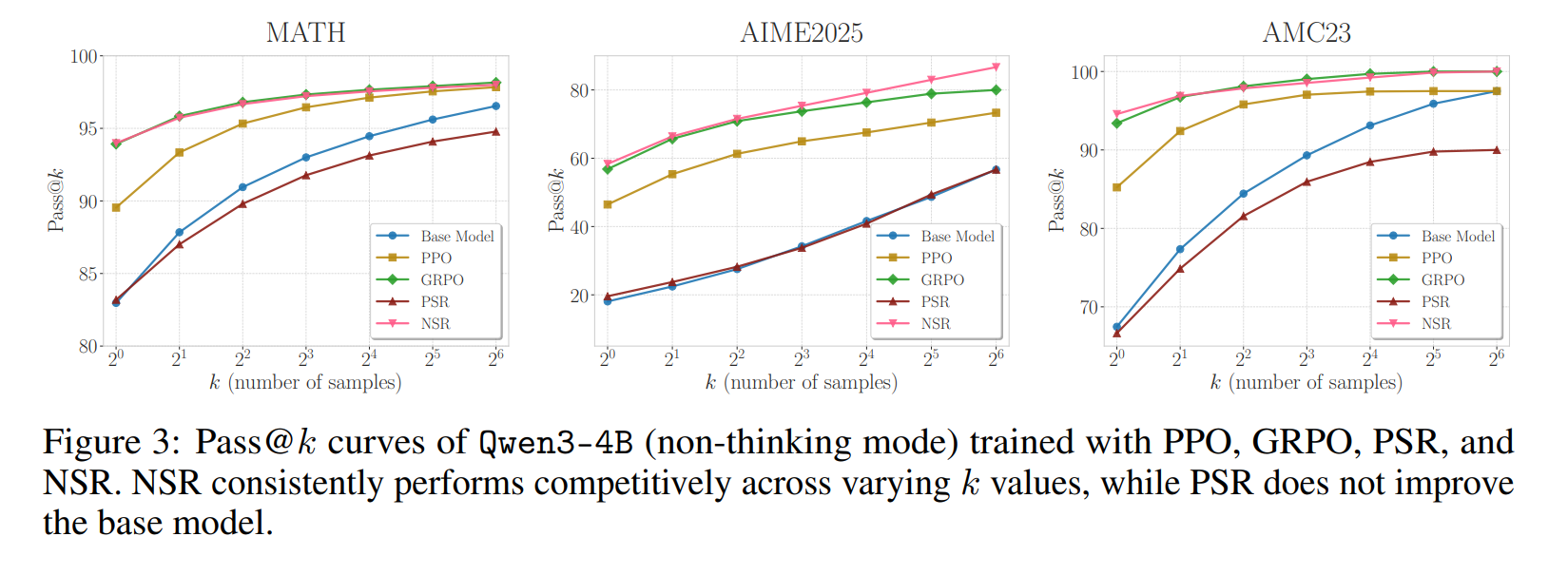
能不能融合 SFT 和 RL?
RL 虽然好,但训起来确实比较麻烦,那我们能不能既要 SFT 训练简单的优点,又要 RL 可以进行细致优化的优点呢?其实回顾前面的分析,RL 的主要特征就是:1. 能给负样本提供训练信号,2.并且部分 RL 算法(例如 PPO)还会给每个 token 一个细致的优势。后者可能难以近似,但在 SFT 中增加一个负样本理论上是可以做到的。事实上,六月初新鲜出炉的一篇文章 The Surprising Effectiveness of
Negative Reinforcement in LLM Reasoning 就发现了一个令人惊讶的结论:仅使用负样本做 REINFORCE,即只惩罚模型的错误回答,而不显式奖励其正确回答,也能表现出非凡的有效性,这里 REINFORCE 就是讲 PPO 时提过的,只考虑分数,没有减去预期分数线的 RL 算法。但论文中进一步简化成:只对整个回复进行打分,且正样本打 1 分,负样本打 -1 分,因此目标函数可以写成:

这里 L PSR \mathcal{L}_{\text{PSR}} LPSR 恰好就是 SFT 的目标函数,而 L NSR \mathcal{L}_{\text{NSR}} LNSR 则通过加负号传递对负样本的训练信号,相当于是在 SFT 中增加了负样本的训练。实验结果显示仅训练负样本的 L NSR \mathcal{L}_{\text{NSR}} LNSR 就能达到与最优 RL 方法相当的 Pass@K 通过率。这说明在基础模型还不错的基础上,通过在线采样+增加负样本,SFT 的训练方式或许也可以达到类似 RL 的效果。