Soft thinking和MixtureofInputs——大模型隐空间推理——本周论文速读
本周再次碰到卧龙凤雏
有两篇工作都是在【穿decoding的鞋走reasoning的路】,方法也非常相似。这里也放到一起
文章1 是:Text Generation Beyond Discrete Token Sampling,他提出的方法名叫 MOI 后面就称文章1 为MOI
文章2 是: Soft Thinking: Unlocking the Reasoning Potential of
LLMs in Continuous Concept Space 后面称Softthinking
两篇文章用一句话总结
一个分四部分的长句🙄:
- Coconut 是直接用
last hidden state作为输入embedding,但这两个空间天然是不适配的,必须要调整; MOI和Softthinking两个方法则使用的是同一个思路:用模型输出的 next-token distribution(也就是每个词对应的概率)作为权重,给对应词的原始 embedding 做加权平均,作为新的输入 embedding;- 这个新的embedding,
MOI叫他 mixture of inputs,Softthinking叫他concept token; - 这样做不需要额外训练,推理效果略好。
从我的角度看,这两篇文章都是套着latent space推理外衣的decoding方法。因为如果直接不用模型的last hidden,模型前面信息传递的时候积累的隐空间知识也被丢弃了。同时,这两篇文章的生产长度仅比实体COT少20%-30%,在效率上也不能算出众。
关键细节
两篇文章的关键区别在怎么加权
Soft thinking的加权法直白得令人发指
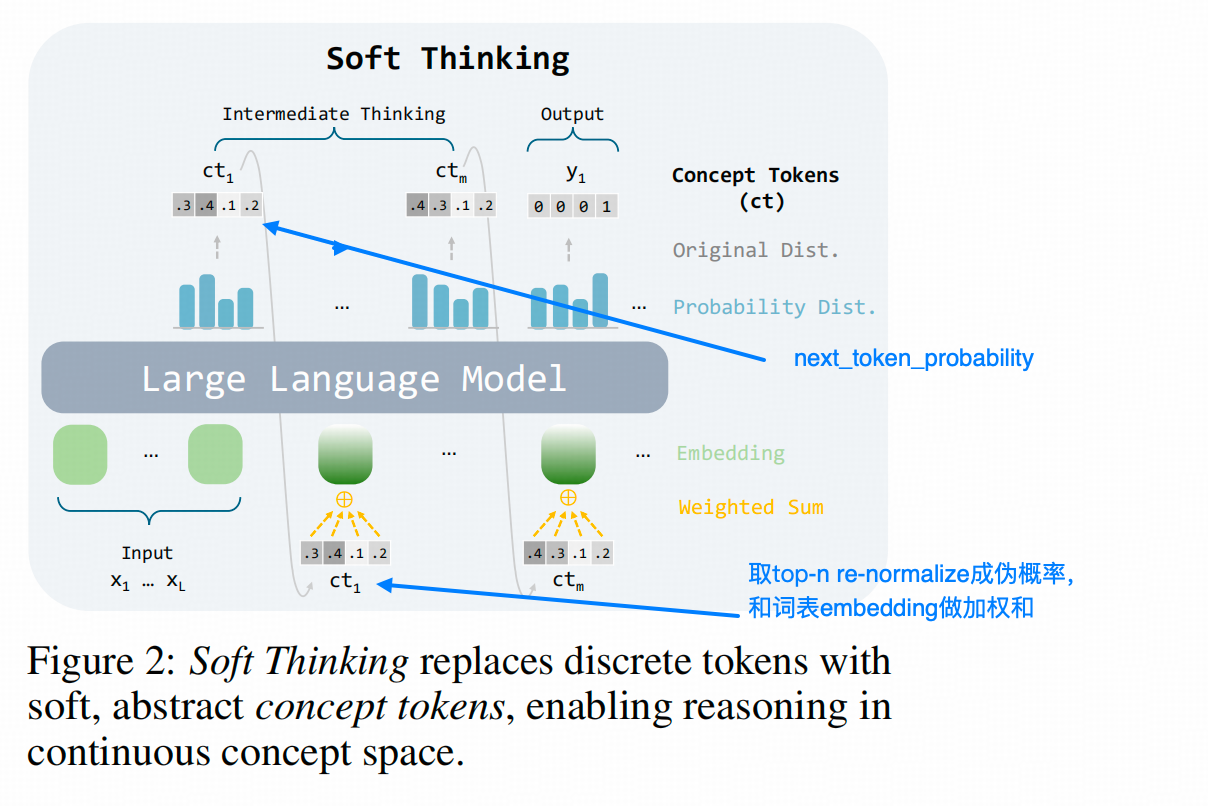
如上图:
step1: Transformer 最后一层的 hidden state–>经过一个 词汇表映射层(线性层 + softmax)得到 p ( x t ∣ x < t ) ∈ R 1 × V p(x_t|x_{<t}) \in \mathbb{R}^{1 \times V} p(xt∣x<t)∈R1×V, V V V是词表大小
Step 2: 选取 p p p向量中前 top-n 的值,并对它们重新归一化到 [0, 1] 之间,作为权重。
Step 3: 在词表的 embedding 中找到对应的 top-n 个词,分别乘以相应权重后求和,得到最终的加权 embedding。
MOI的加权法就比较复杂
而且原文图画的比较差
这个方法需要超参数 β \beta β
Step1: 同softthinking一样,先算next-token distribution p t p_t pt, 并采样出token y t y_t yt;
** 这里 t t t就是第t个token的意思在下面的计算过程中并没有用,但为了和原文的符号保持一致,挂着了。
Step2:MOI的权重——计算要绕几个弯子:
- 计算归一化熵 H = − 1 log V ∑ i p t , i log p t , i H = -\frac{1}{\log V} \sum_i p_{t,i} \log p_{t,i} H=−logV1∑ipt,ilogpt,i,这里是第t个token,词表中第i个词的
- 计算混合权重 w t , i = { H ⋅ p t , i + ( β + 1 − H ) β + 1 , if i = y t H ⋅ p t , i β + 1 , otherwise w_{t,i} = \begin{cases} \frac{H \cdot p_{t,i} + (\beta + 1 - H)}{\beta + 1}, & \text{if } i = y_t \\ \frac{H \cdot p_{t,i}}{\beta + 1}, & \text{otherwise} \end{cases} wt,i={β+1H⋅pt,i+(β+1−H),β+1H⋅pt,i,if i=ytotherwise
- 生成下一步的输入: h t = ∑ i = 1 V w t , i ⋅ E [ i ] h_t = \sum_{i=1}^V w_{t,i} \cdot E[i] ht=∑i=1Vwt,i⋅E[i], E E E是词表embedding
核心区别
Softthinking不需要再sample一个token出来,而MOI需要Softthinking是 “把概率最高的几个token的embedding按概率比例混合”;MOI“则是从采样到的token身上切下一部分概率,分给其他可能的token,按比例混合”
Soft thinking 的特别之处
前面讲RecurrentLLM的时候提到他一个比较有趣的停止循环的方法,就是比较两层hidden之间的KL散度,如果低于5e-4,就停止循环。 Softthinking其实仍然使用的是LLM体外循环,而非体内循环,但是他停止推理的思路是:
next-token distribution p p p的熵 H H H连续低于阈值 τ \tau τ 第n次的时候,停止生成 think
相当于是【再想也想不出别的来】的情况下,就停下。
而MOI 则是采样猜到<\think>的时候停止COT。
效果怎么样?
推理数据集上都有提升
下图是Softthinking的结果
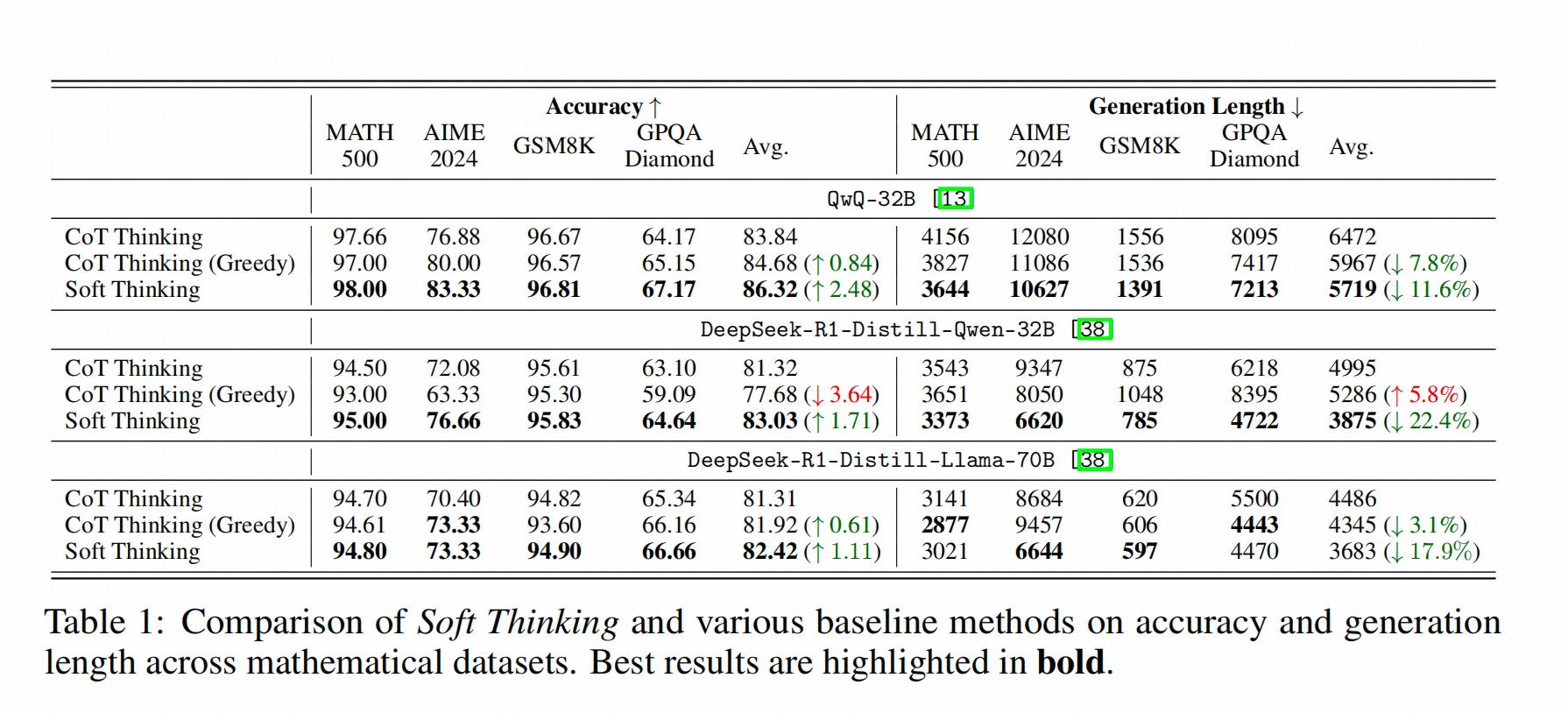
总而言之就是【有提升,但不大】。注意上表的右侧,是生成长度的比较,我认为这两个方法是【披着reasoning的外衣的decoding】的原因就在这儿,这两个方法实际生成的token数较COT而言都没有显著下降。
下图是MOI 的实验结果:同样的,提升有但是不太显著。
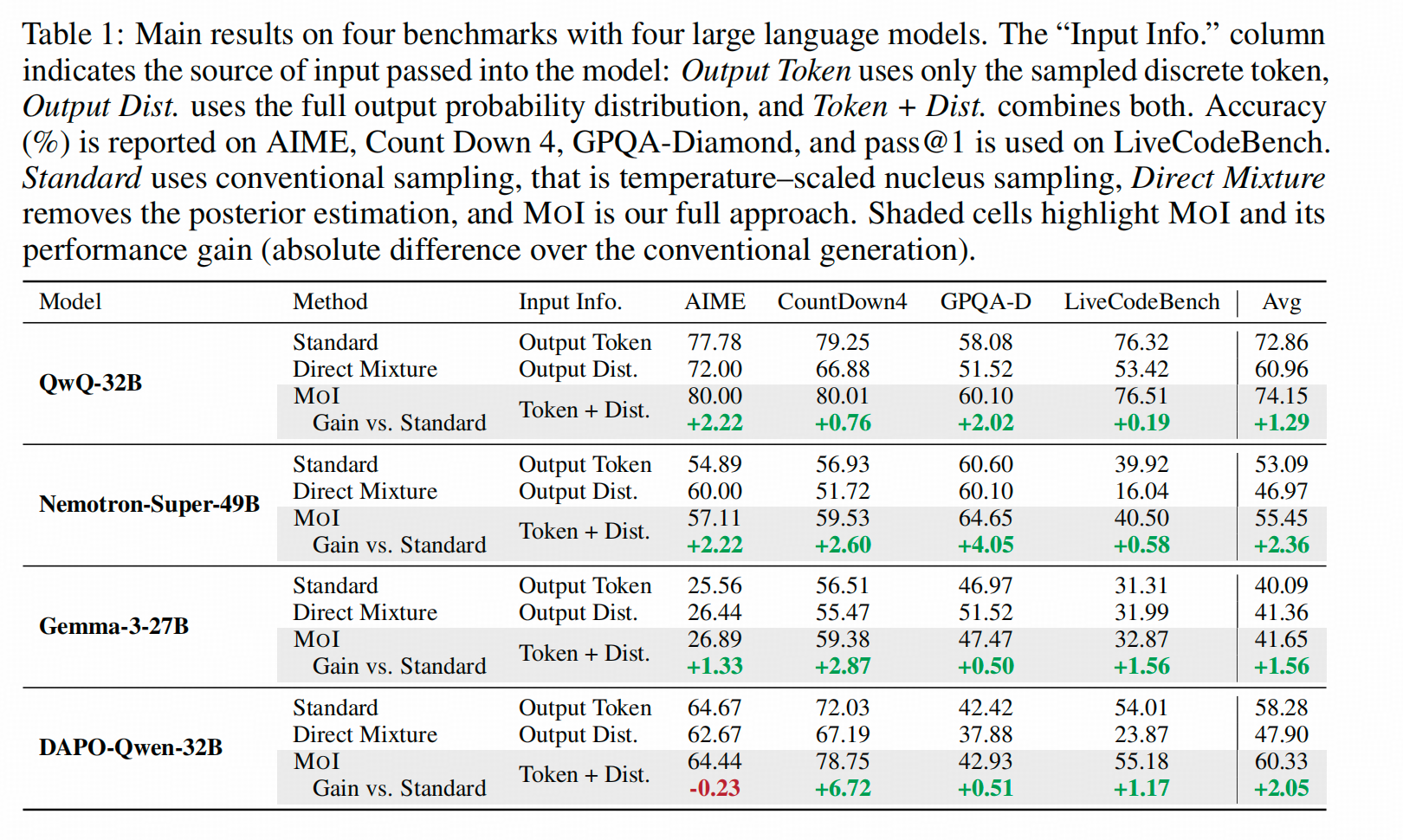
比较有趣的是,这两个方法用的测试集虽然有重合,也都算了QwQ-32B在各个集上的结果,但结果不可比:
- 两个paper用的是不同年份的AIME和LiveCodeBench;
- 两个方法的基线实验的采样方法和结果采纳方法不一样(一次准确率和pass@1)
跟上一对卧龙凤雏能拼出一个完整结果不同,这俩是完美错过。
实验分析中的亮点呢?
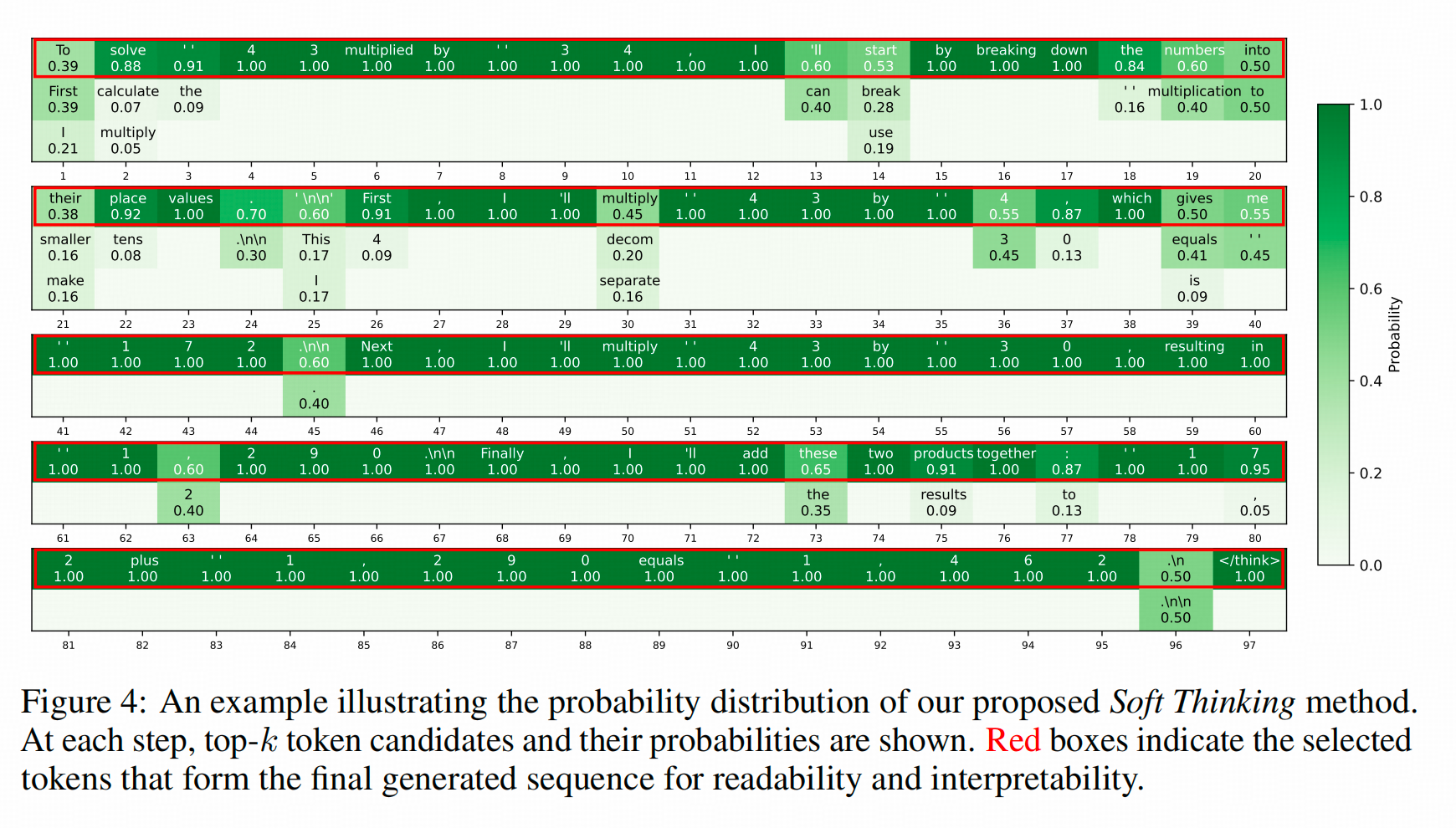
Softthinking为了理解这种合成表征到底保留了什么信息,选取了一个样本进行分析。从上图可以看到几个点:
- 确实在分句层面,模型存在着多路径选择的问题,这样的混合表征法也保留了两个的分叉;
- 大部分token的可选择空间并不多,而且在措辞上的可选对推理来说并不关键,比如最上面一行,是说 ‘To solve something’还是说’First calculate something’在功能上并没什么差异。这也是我认为这篇文章提出的方法提升有限的原因,他既没有涉及到“认知”相关的token,也没有像Coconut那样保留真的分叉路径。更像是穿了时髦衣服的decoding方法,而且也没有真的省下多少token,效率也没提升什么。
评价和感想
- 大家是不是适当的卷一下系统2到系统1的优化啊,自适应推理长度的上周看到几篇,这个thinking token方向上雷同方法又看到两篇。何必呢?我实际生产中仍然头疼的是我模型在需要直接输出结果的场景下,表现提升不上去。既然大家现在都开始卷推理长度了,是不是推理能力上都卷不上去了?卷不上去就回头看看实际生产中需要啥呀!
Softthinking这个工作对Coconut的价值有严重误解,他在比较实验中,直接用last_hidden 作为下一个token的embedding输入,完全没有经过推理压缩训练就和自己的方法比较,这样完全没有意义,因为Coconut的价值就在于1-带着模型内部推理的中间状态继续进行推理;2-大大缩减推理需要的token数。Softthinking在这两方面都没有更有价值的贡献,就不要拿起来一起比了好吧。- 方法设计上
MOI深谙【化简为繁】🙄之道,1是仍然保留了sampling这个做法,2是引入了一个很不好平衡的超参数 β \beta β。在理念上也存在瑕疵,从一个distribution上直接sample出的东西,能直接当做evidence吗?