字节开源多模态文档图像解析模型:Dolphin
Dolphin:Document Image Parsing via Heterogeneous Anchor Prompting
一、论文简介
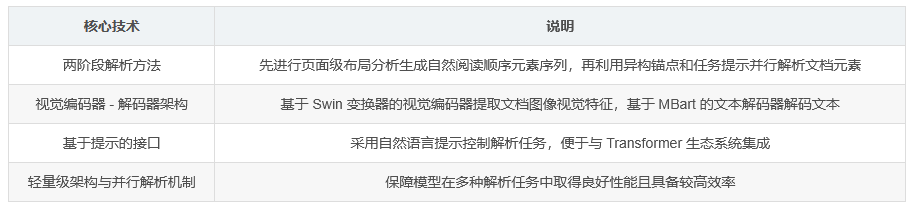
Dolphin 是一种新颖的多模态文档图像解析模型,采用 “先分析后解析” 的范式。它旨在应对文档理解中文字段落、图表、公式、表格等复杂交织元素带来的挑战,通过两阶段方法来处理。
二、模型方法
-
第一阶段 :对页面进行全局布局分析,生成符合自然阅读顺序的元素序列。
-
第二阶段 :利用异构锚点和任务特定提示,并行高效地解析文档元素。
三、模型架构
Dolphin 基于视觉编码器 - 解码器架构,使用变换器构建。
-
视觉编码器 :基于 Swin 变换器,用于从文档图像中提取视觉特征。
-
文本解码器 :基于 MBart,用于从视觉特征中解码文本。
-
基于提示的接口 :使用自然语言提示来控制解析任务,作为 Hugging Face VisionEncoderDecoderModel 实现,便于与 Transformer 生态系统集成。
四、使用方式
即将发布演示,可通过其 GitHub 仓库查看详细使用说明。支持页面级解析和元素级解析,包括对整个文档图像的解析以及对段落、表格、公式等单个元素图像的解析。
五、开源许可
该模型遵循 MIT 许可证发布。
核心技术总结如下: