超越现有SOTA!DiT模型助力高分辨率图像生成
在人工智能领域,Diffusion Transformer与图像生成的结合正在引领一场视觉技术的革新。这种创新性融合巧妙地将扩散模型的强大生成能力和Transformer架构的高效特征提取能力结合起来,为高质量图像生成开辟了新的路径。最新研究表明,Diffusion Transformer不仅能够生成细节丰富、逼真的图像,还能在多模态场景中实现更精准的语义理解和内容创作。
通过引入自注意力机制和多尺度特征融合,Diffusion Transformer在图像生成任务中展现出更高的效率和更强的可控性,为未来数字内容创作、虚拟现实和人工智能艺术等领域带来了无限可能。我整理了10篇关于【Diffusion Transformer+图像生成】的相关论文,全部论文PDF版,工中号 沃的顶会 回复“DTrans图像”即可领取。
TIDE:Temporal-Aware Sparse Autoencoders for Interpretable Diffusion Transformers in Image Generation
文章解析
本文提出了一种名为TIDE的新框架,旨在提升基于Transformer的扩散模型(DiTs)的可解释性。
通过引入时序感知的稀疏自编码器(SAEs),TIDE能够捕捉扩散过程中的时间变化激活模式,并提取稀疏且可解释的多层级特征(如3D、语义和类别)。
该方法在重建性能上达到SOTA水平(MSE为1e-3,余弦相似度0.97),并展示了其在图像编辑和风格迁移等下游任务中的应用潜力。
创新点
提出了TIDE框架,首次将时序感知与稀疏自编码器结合用于DiTs的可解释性研究。
设计了渐进式稀疏调度和随机采样增强策略以提升特征学习效果。
揭示了扩散模型在预训练过程中自然习得多层次特征的能力。
提供了针对DiTs的系统性训练与评估协议,验证了TIDE的缩放规律。
实现了对生成过程中各时间步的解耦分析,进一步理解DiT的粗到细生成机制。
研究方法
利用稀疏自编码器(SAEs)从DiT激活层中提取稀疏且可解释的特征。
引入时间感知架构,建模扩散过程中不同时间步的激活模式变化。
采用渐进式稀疏调度策略,在保证重建质量的同时控制稀疏程度。
通过随机采样增强提高模型对高维和长序列数据的鲁棒性。
结合扩散损失进行评估,并与其他SAE方法对比性能表现。
研究结论
TIDE在重建精度和特征可解释性方面显著优于现有方法。
扩散模型在生成预训练中自然地组织了多层级语义概念。
TIDE支持下游任务如图像编辑与风格迁移,增强了生成系统的可控性。
提出的训练策略有效应对了DiTs在时间动态性和高维表示上的挑战。
TIDE为构建更透明、可信的生成模型提供了新的工具和理论基础。

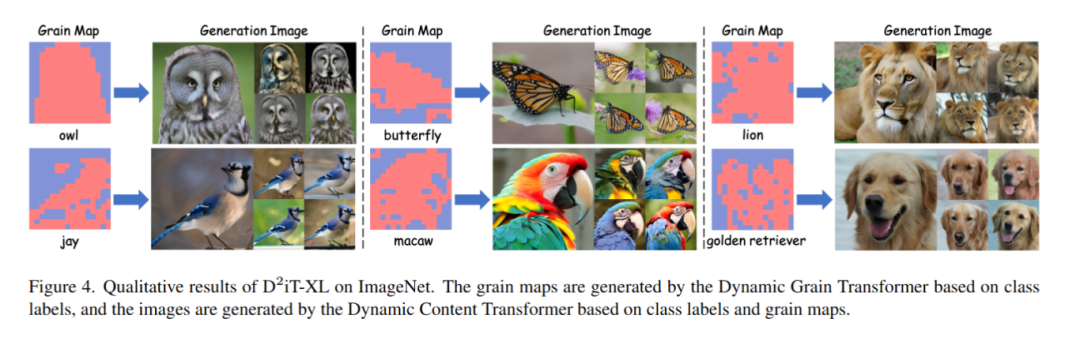
D2iT:Dynamic Diffusion Transformer for Accurate Image Generation
文章解析
本文指出当前基于Diffusion Transformer(DiT)的生成模型在扩散过程中对所有图像区域使用固定的压缩率,忽视了不同区域信息密度的自然差异,从而影响生成图像的质量。
为此,作者提出了一种新的两阶段框架D2iT,通过动态压缩不同图像区域来提升生成效果和效率。第一阶段采用Dynamic VAE(DVAE),根据各区域的信息密度以不同的下采样率编码图像;第二阶段引入Dynamic Diffusion Transformer(D2iT),通过预测多粒度噪声(包括粗粒度和细粒度),实现全局一致性和局部真实感的统一。
创新点
提出了基于信息密度的动态压缩策略,解决了传统DiT中固定压缩带来的局部真实感与全局一致性冲突的问题。
设计了Dynamic Grain Transformer和Dynamic Content Transformer,分别建模空间信息密度和内容信息,支持多粒度噪声预测。
在ImageNet数据集上,仅使用DiT 57.1%的训练资源就实现了23.8%的生成质量提升(FID从2.27降至1.73)。
研究方法
第一阶段采用Dynamic VAE(DVAE)对图像进行分区域编码,依据各区域的空间复杂度决定不同的下采样率。
第二阶段通过Dynamic Grain Transformer学习真实的区域密度分布并生成粒度图。
第二阶段进一步利用Dynamic Content Transformer根据不同粒度应用不同级别的噪声压缩,并采用“粗略预测+细粒度修正”的策略增强全局一致性与局部细节。
整体框架结合了Transformer的全局建模能力与扩散过程的逐级恢复机制,提升图像生成质量与训练效率。
研究结论
固定压缩策略限制了DiT在局部细节还原与全局结构一致性上的表现。
D2iT通过动态压缩和多粒度噪声预测,在保持较低计算负担的同时显著提升了图像生成质量。
实验结果表明,D2iT相比现有方法在生成质量和训练效率方面均具有明显优势。