pcie gen4,gen5,gen6 新增特性说明
Gen 4 新增特性
相比较gen3;
PCIe 4.0速度的升级算是例行公事,除此之外,PCIe 4.0在其他方面带来了哪些惊喜呢?我们按照spec的顺序,挑选重要的,进行一一揭晓!(以下内容均是基于PCIe 3.0作为对比)
1. 10-bit tag field(section 2.2.6.2):
在pcie协议中,事务发起者(requester)发送的TLP需要有身份ID,这个叫做transaction ID,而transaction ID由两部分组成,requster ID和TAG。其中,Requster ID包含了Bus/Device/Function信息。而Tag则表示同一个发起者(requster)同时暂存TLP的数量。(类似于一个axi master的outstanding burst数目)。completions寻找相关的Requster通过Transaction ID。requster ID(我是谁);routing ID(我要去那里)
关于TAG:
1. requster 发送non-posted TLP之后,在没有收到cpl报文之前,对应的Transaction ID不能被释放(在那里释放?)同一个requster发送的non-posted TLP的header中,requster ID肯定是一样的。当一个requster要发起多个non-posted TLPs是,tag字段才有具体的意义。
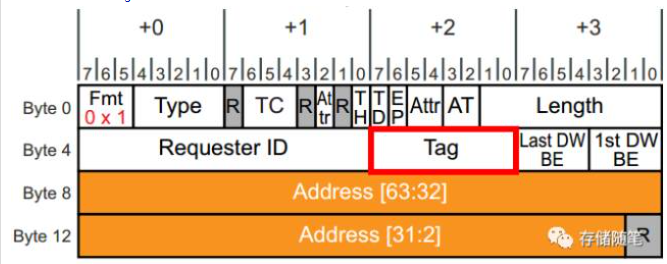
2。tag字段的大小据定了发送端可以暂存同一类型TLP的数量。PCIe 3.0 Spec中显示,默认是bit[4:0],就是默认长度是5,当enable extend Tag bit后,Tag长度为8。也就是说在PCIe 3.0中,每个PCIe设备的发送端最多只能暂存256个TLPs,换句话说,对于同一发起者而言,此时PCIe链路上有其256个TLPs在传输。
3, 其实,PCIe设备的Function设定中也可以扩展Tag字段,这里不展开了。
其实,在大多数情况下,8-bit Tag已经够用了,但是对于一些特殊的高性能系统来说,这还不够。我们来看个算式
![]()
其中,BW=payload bandwith, S=transaction payload size. N= number of oustanding NPRs(non-posted requst), RTT= transaction round-trip time.
从上面的算式中,我们可以看到发起者暂存TLPs数目,也就是Tag字段的大小,与有效带宽成正比。为了配合高速传输的需求,PCIe 4.0将Tag字段从原来的8-bit扩展到10-bit。
Tag字段扩展后,TLP Header的大小以及其他字段的定义保持不变。扩展的两个bits,bit[9]和bit[8]分别位于Byte1 Bit[7]和bit[3](这两个bits在之前是Reserved)。10-bit Tag对应的Header定义如下:
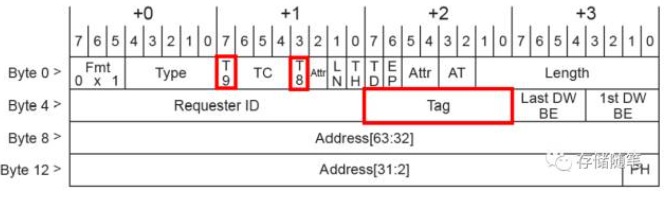
Tag[9:8]的有效取值包括01b, 10b, 11b。00b是无效取值。也就是说,10-bit Tag最大暂存TLP数目由原来的256扩大到了768.
二、Scaled Flow Control(Section 3.4.2):
在之前的文章"Flow Control概述"中,对Flow Control做了大致的介绍,"PCIe科普贴"中对Flow Control的实现原理也做了比较详细的介绍。在PCIe 3.0中,Flow Control Update Packets中可以看到(下图),Header FC Field=8, Data FC Field=12, 这就意味着PCIe 3.0中Flow Control Credit有最大界限值:Header Credit最大为127,Data Credit最大为2047. (1 Credit=16B);
这个功能在DLLINK_CAP(capability中有详细解释);并且使能了该feature之后;在pcie 建链之后双方会进行DL_Feature dllp报文的发送和接受;用于确定scale的值。
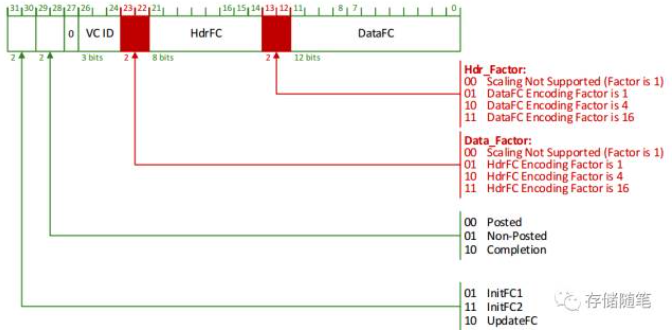
在PCIe 4.0中,对TLP Header和Data如何选择相应的放大系数呢?怎么知道是x1,x4,x16呢?这就依赖于两个参数:Hdr Scale和Data Scale. 这两个参数就在FC DLLPs中,包括FC初始化DLLP: InitFC1 & InitFC2,FC Update DLLP: UpdateFC,如下图. PF0_PORT_LOGIC/VC0_P_RX_Q_CTRL_OFF
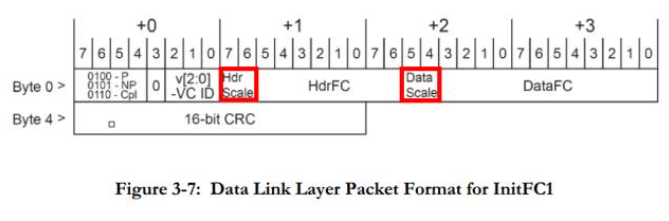
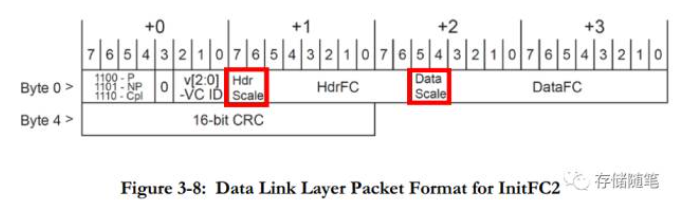
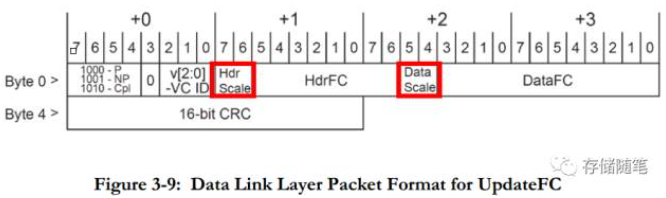
当Scaled Flow Control功能处于Disabled状态时, 之后Hdr Scale和Data Scale的取值只能是00,这时,Flow Control Credits相关设定与PCIe 3.0一致。
当Scaled Flow Control功能被Enable之后,Hdr Scale和Data Scale的取值只能是三种:01,10,11,分别代表着放大系数x1,x4,x16.
引入"Scaled Flow Control"功能之后,PCIe的Data Link也发生了相应的变化。与PCIe 3.0相比, PCIe多了一个"DL_Feature"状态。
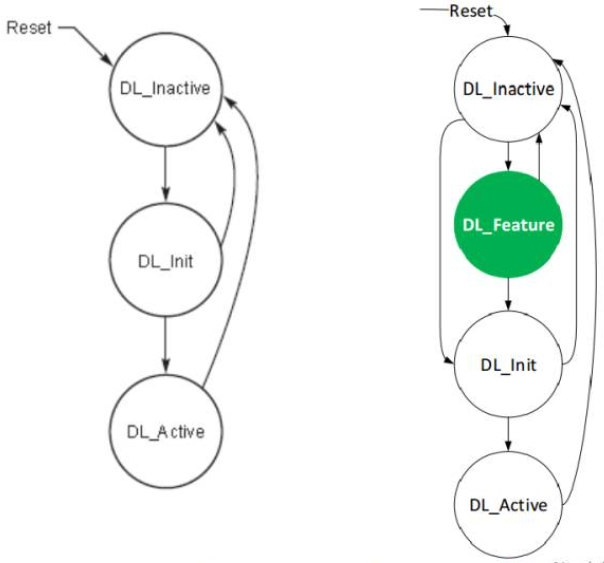
pcie 3.0(左) Vs pcie4.0(右) Data LInk状态机
不过,要进入DL_Feature状态还是有条件的,需要在Data Link Feature Capabilities Register中enable "Data Link Feature Exchange" bit.

在Flow Control中,DL_Feature这个状态主要用于Scaled Flow Control功能的握手交互(专业名称叫做Handshake)。在这个过程中,会用到一个叫做"Data Link Feature DLLP",这个DLLP也是PCIe 4.0新增的, 如下图。dwc_PCIE_USP/PF0_DLINK_CAP
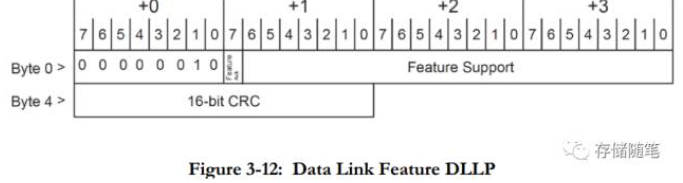
Data Link Feature DLLP中Byte1 bit[7]是Feature Ack bit,就是用来握手的, Byte 3 bit[0]也就是Feature support的bit[0]代表Scaled Flow Control是否support,Feature support的其他bit[22:1]目前是保留的, 以备将来之用。

三、Simplified Protocol Timer(Section 3.6.2.1):
到了PCIe 4.0,PCI-SIG协会自己都不想再为16GT/s单独增加另外一个REPLAY_TIMER Table。于是,提出了更加简便的REPLAY_TIMER Limits.
对于所有的速率的都一样,只有两种选择:
1,当Extend Synch bit=0时,REPLAY_TIMER Limits=24K~31K Symbol time;
2,当Extend Synch bit=1时,REPLAY_TIMER Limits=80K~100K Symbol time;

Extend Synch bit则在Link Control Register中设置:
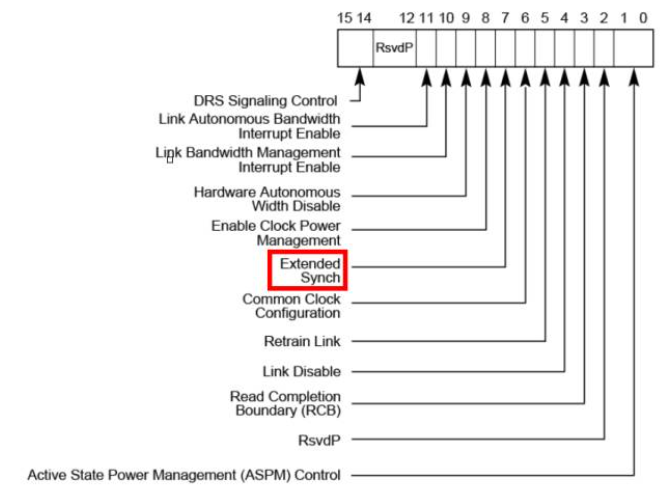
对于这个简化的REPLAY_TIMER,当PCIe链路运行在2.5GT/5GT/8GT时,你也可以选择无视,依然选择原本的定义方式。但是,当PCIe链路运行在16GT/s时,你就别无选择咯,只能按照PCIe 4.0 Spec的要求,乖乖的实验简化RETPLAY_TIMER。
四、Link Equalization(Section 4.2.3):
此节不详细说明。
五、Lane Margining(Section 4.2.13):
在PCIe 4.0协议中,16GT/s拥有一个特有的功能,叫做"Lane Margining",因为是针对接收端的,也可以叫做"Rx Lane Margining". 当PCIe链路运行在2.5GT/s、5GT/s、8GT/s时,无法启动这个功能。当PCIe链路出于L0状态时,Lane Margining功能允许Host监控并修复接收端出现的信号偏差(包括电压和时间),
pcie gen4 &pcie gen5;
最大的区别就是速率上的区别;
2. refclk 抖动容忍程度也不同:
pcie gen4: +/- 300ppm;
pcie gen5: +/- 100ppm;
3. link 均衡的差别;
gen5 支持
euqalizaiton bypass to highest rate; 使能该特性之后如果ep,rc双方都支持那么link时可以直接从gen1--》gen5; 跳过中间 3,4 步骤;
No equalization needed:
如果链路上的所有组件都支持 32.0 GT/s 或更高的数据速率,并且都支持“无需均衡”的机制,那么系统允许跳过整个均衡过程,直接将链路训练到所有设备共同支持的最高速率(如 32.0 GT/s)。这一机制是通过 TS1/TS2(或其修改版本)中的有序集合进行协商的。
该机制的适用前提包括:
- 设备能从以前的链路训练中获取在所有速率下都适用的均衡设置;
- 或者该设备在所有高于 5.0 GT/s 的速率下根本不需要均衡;
- 如果设备设置了“禁止跳过均衡”的控制位,则不得宣称支持该机制。
总的来说该机制在双方都在gen5建联之后,跳转到gen3,或gen4.不需要从新做eq;节省时间。
gen6 & gen5
01)64 GT/s数据速率,通过x16配置可达到256Gbps;
02)PAM4信令利用了行业中已有的PAM4;
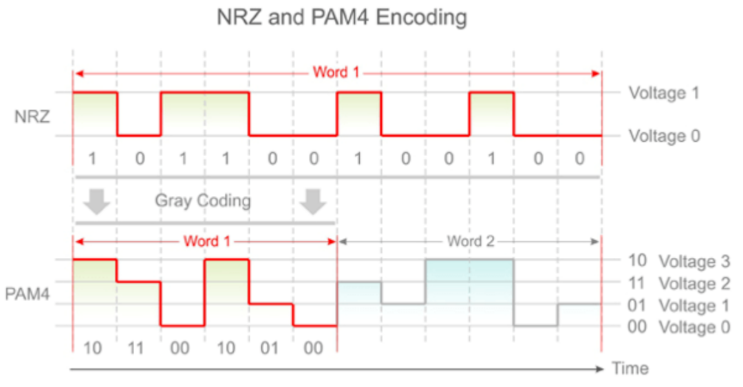
PAM代表脉冲振幅调制,数字4代表电平数量。大多数工程师都熟悉NRZ调制,即非归零调制。NRZ使用两级信号。当Vcc ~ 0V时,逻辑 “0”是通过的。当Vcc ~ 1.8/3.3/5V时,逻辑 “1”通过。每个单位间隔发送一个0或一个1,或一个bit。所以NRZ基本上是一个PAM2。
作为改良产品,PAM4是一个多级的技术,使用四级信令。基本上有着四级信令,分别对应Vcc ~ 0V、Vcc/3、(2*Vcc)/3和Vcc。每个单位间隔发送两个比特而不是一个。 它发送的是0-0、0-1、1-0或1-1。下图详细说明了这些差异:
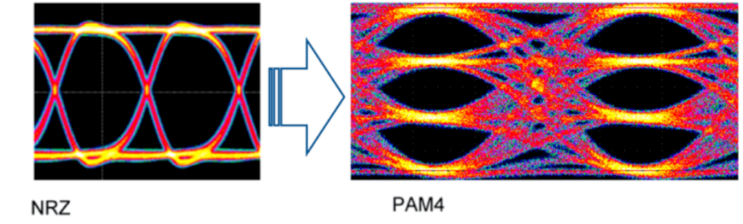
一般来说,NRZ调制支持有一个“眼”的眼图。对于PCIe 5.0规范,“眼”有一个特定的眼高和电压水平,这取决于定义的通道长度。PAM4调制眼图支持三个 "眼"。对于PCIe 6.0规范,每个“眼”也有一个定义的眼高和电压水平,用于特定的信号通道。
为什么PCIe 6.0规范采用了PAM4
以前的PCIe规格是NRZ或PAM2。PAM4规范已被其他网络标准采用,开始是56Gbps,112Gbps,未来是224Gbps。其他标准中存在PAM4的先例。
PAM4信令使数据速率翻倍,同时使用相应NRZ调制原理的相同奈奎斯特频率。例如,PCIe 5.0架构使用16GHz的奈奎斯特频率。使用PAM4调制,PCIe 6.0架构使用相同的16GHz奈奎斯特频率,但数据速率翻倍,达到每条链路64GT/s,并通过x16配置达到256Gbps的双向带宽。
PAM4与NRZ相比,优势是什么?
PAM4减少了通道损耗,因为它以每UI两个bit的一半频率运行。这使得PCIe 6.0规范的信道覆盖范围与PCIe 5.0规范提供的类似。PCIe 6.0规范中的PAM4调制甚至可能允许更少的损耗和扩展的覆盖范围。
从另一个角度来看,对于相同的信号频率,你可以将数据速率提高一倍,或者为下一代应用增加带宽或吞吐量。
【PCIe 6.0】颠覆性技术!你NRZ相守20年又怎样?看我PAM4如何上位PCIe 6.0 !_pcie6.0 pam4-CSDN博客
2. 通道和PAM-4
(a)PCIe 5.0 32GT/s(NRZ信号)显示2个信号电平和单眼,(b) PCIe 6.0 64GT/s(PAM-4信号)显示4个信号电平和3个不同的眼。图1中的两个信号具有相同的16GHz奈奎斯特频率和相同的单位间隔(UI)。这意味着他们基本上可以使用相同的PCIe 5.0通道,而不会让频率相关损耗变得更糟糕,如果使用64GT/s的NRZ信号,奈奎斯特频率为32GHz。这就是56G和112G以太网转换到PAM-4信号的原因,也是PCIe 6.0现在转换到PAM-4的原因,可以降低信号损耗。但是PAM-4的四个电压电平在一个UI中使用2bit编码,而NRZ是1bit编码,从而使数据速率提高了一倍。这听起来很棒,但是这里有一项重要的权衡因素。由于发射端(TX)的总体电压摆幅没有增加,因此PAM-4系统中每只眼的可用电压仅为NRZ的1/3。因此,信号在TX和接收端(RX)之间遇到的任何噪声都会对信号完整性造成更大的损害。
03)轻量级的FEC和CRC减轻了与PAM4信令相关的误码率增加;
pcie6为什么引入FEC:
1. 使用 PAM4 编码带来的信噪比下降
- PCIe 6.0 为了在不成比例增加功耗的前提下提升带宽,引入了 PAM4(4-level Pulse Amplitude Modulation)。
- PAM4 每两个 bit 映射为一个符号,虽然带宽翻倍,但每一位的“眼图”更小,信噪比(SNR)降低,误码率(BER)上升。
- 在这种情况下,传统的误码检测(如 CRC)+重传策略已不足以满足 高吞吐量 + 低延迟 + 低误码 的目标。
2. 传统 CRC 检测+重传机制不够高效
- PCIe 1.0–5.0 中,使用 8b/10b 或 128b/130b 编码,主要依赖 LCRC 检测错误 和 Replay Buffer 做重传。
- 在 PCIe 6.0 这种高速传输中,频繁重传将严重影响有效带宽和延迟。
- 为了避免重传并在传输链路上修复轻微错误,PCIe 6.0 引入 低延迟 FEC(Low Latency FEC)。
FEC是在rx端实现还是在tx端实现?FEC可以修复几bit错误?
1. FEC 是在 RX 端实现还是 TX 端?
答案:
FEC 的编解码分别在 TX 和 RX 两端实现:
tx实现编码;rx实现解码和纠错;
2. FEC 可以修复几 bit 错误?
答案:
这取决于 FEC 使用的算法和参数,但 PCIe 6.0 使用的是 低延迟、有限纠错能力的 FEC,主要是 对每个 FLIT 能够修复小范围(通常是 1~2 个符号)的错误。
04)基于Flit的编码支持PAM4调制并实现>2倍的带宽增益;
gen6,使用flit 包之后tlp格式还会保留吗?
PCIe 6.0 在使用 FLIT 模式时,TLP(Transaction Layer Packet)格式在逻辑层仍然保留,但在物理层不会再原样发送传统的 TLP 格式,而是经过重新封装为 FLIT 单元进行传输。
FLIT 模式中的关键变化:
- FLIT(Flow Control Unit) 是一种定长(固定 256 字节)传输单元,是 PCIe 6.0 新增的机制。
- 原本变长的 TLP 会先被拆分、打包成一个或多个 FLIT Payload;
- 每个 FLIT 中可能包括多个 TLP(如多个小包)、一个大 TLP 的片段、甚至还可包含 DLLP。
因此,在链路上传输的单位已从“包”(TLP)转变为“帧”(FLIT),这有助于:
- 使用 PAM4 编码获得更高带宽;
- 更好地进行 FEC 编码;
- 提高 传输效率与可预测性。
假设你要发送一个 64-byte 的 Mem Write TLP,在 PCIe 5.0:
- 会构造一个完整的 TLP 包;
- 加入 DLLP 信息;
- 经物理层直接以 bit 流形式发送。
而在 PCIe 6.0:
- 同样构造一个 TLP;
- 然后将其塞进一个 FLIT;
- 每个 FLIT 是 256B 固定长度,填不满的部分使用 Padding。
为什么使用flit之后会大幅降低延迟?
FLIT 模式降低延迟的核心原因是:它将原本变长、带开销的数据包(TLP/DLLP)转变为结构化、定长、流水化处理的传输单元,极大地提升了传输效率并减少了协议开销与重传延迟。

05)更新了用于Flit模式的数据包布局,以提供额外功能并简化处理;
移除了automic operation:原子操作