小白成长之路-文件和目录内容检索处理(一)
文章目录
- 基础命令
- 一、grep筛选
- -i:忽略大小写
- **-v****反转匹配,只显示不匹配的行
- 根据关键字查找目录下文件内容并返回文件名称
- 根据通配符查找
- 过滤掉注释内容和空行内容
- 二、 find查找
- 根据关键字查找
- 根据文件类型查找
- 根据文件大小查找
- 多选项查找
- 指定路径深度进行查找
- 使用-exec处理find查找到的结果
- find结合xargs命令进行结果的再处理
- 三、sort排序
- 四、uniq去重
- 总结
基础命令
一、grep筛选
在文本中查找指定的字符串所在的行
语法:
grep [选项] file
选项:
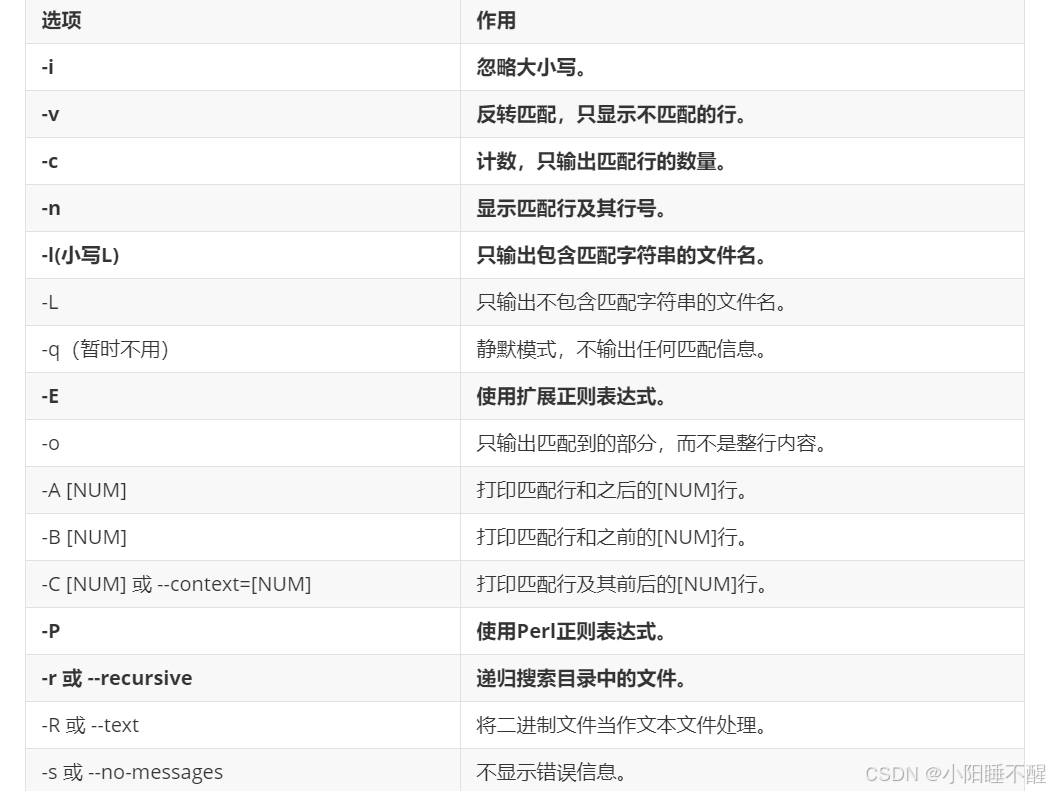
-i:忽略大小写
grep -i “a” ex.txt
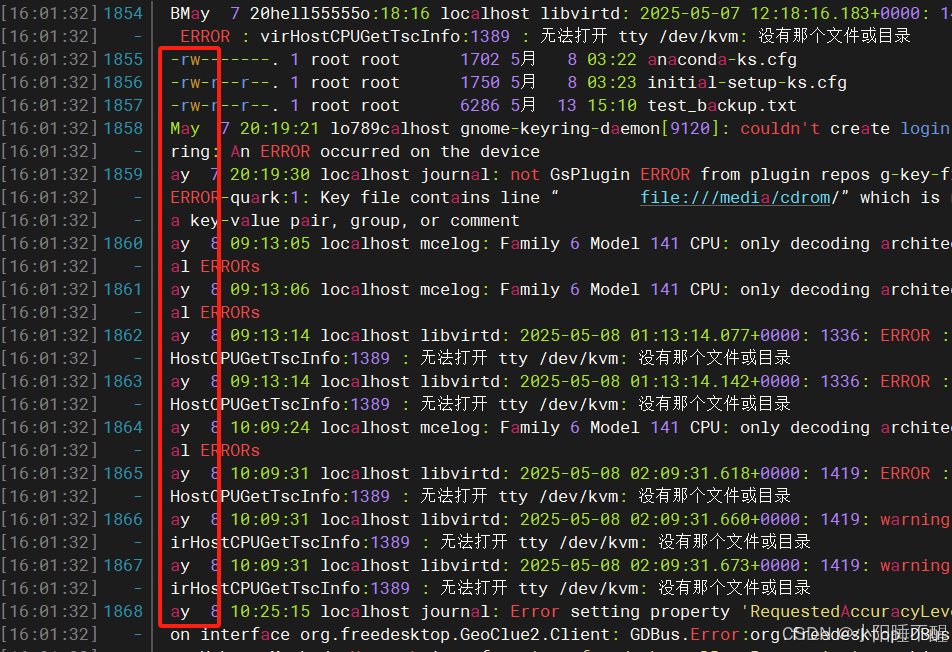
**-v****反转匹配,只显示不匹配的行
grep -v “a” ex.txt----筛选出包含a 的行
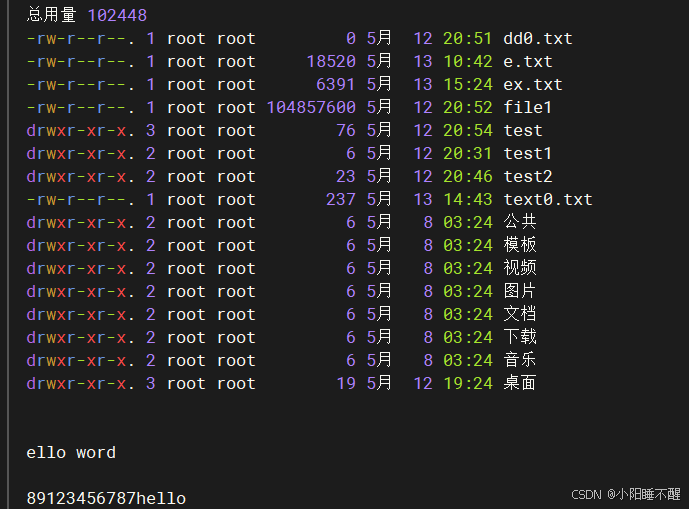
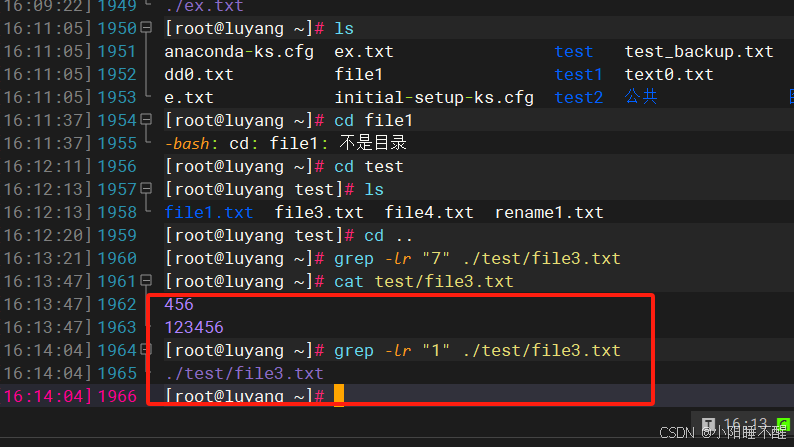
根据关键字查找目录下文件内容并返回文件名称
grep -lr “a” ./
./test.txt
#查看/var/log/目录下包含"error"的日志文件并返回文件名
根据通配符查找
^: 以什么什么开头
$:以什么什么结尾
.:表示单个字符
找May
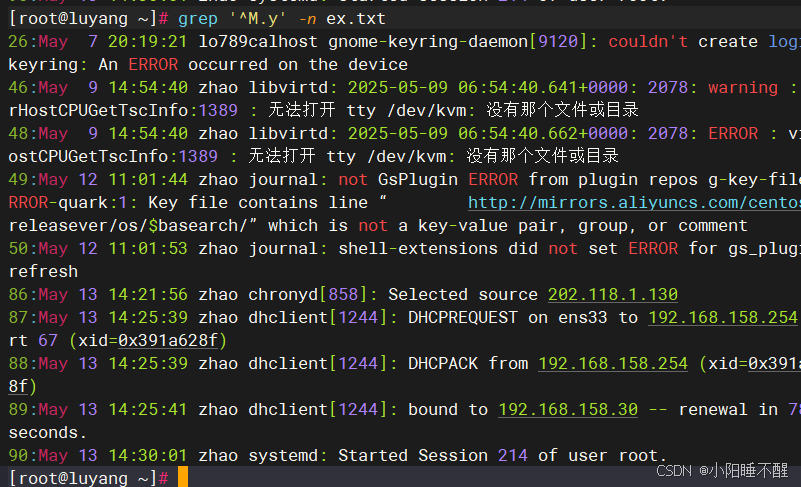
过滤掉注释内容和空行内容
grep “^$” -v test.txt | grep -v “^#” -n
二、 find查找
find - 递归地在层次目录中处理文件
根据关键字查找
查找txt文件
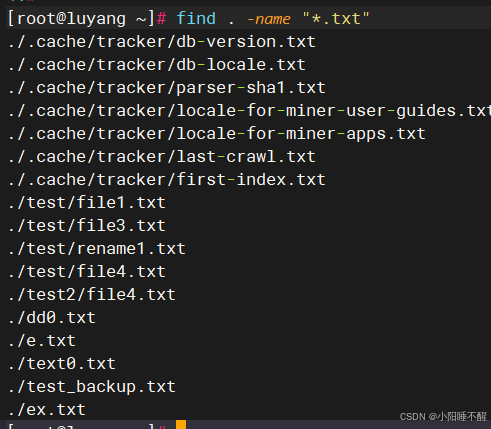
根据文件类型查找
文件类型:
- 普通文件: f
- 目录:d
- 连接文件: l
- 字符设备文件: c
- 块设备文件: b

根据文件大小查找

多选项查找

指定路径深度进行查找

使用-exec处理find查找到的结果

find结合xargs命令进行结果的再处理

三、sort排序
以行对文件进行排序
说明:
当使用sort -n对包含英文字母的文本进行排序时,它会尝试将英文字母按照其在字符编码中的顺序进行数值化解释并排序
四、uniq去重
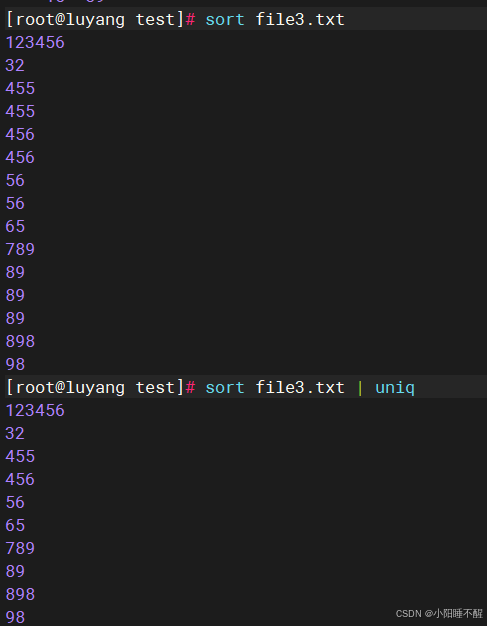
uniq 是 Unix 和类 Unix 系统中的命令,用于从排序的文本数据中去除重复行,仅保留唯一的行。它通常与 sort 命令结合使用,因为 uniq 只能删除相邻的重复行
语法:
uniq [options] [input_file [output_file]]


1.排序后有重复的455和456 通过uniq删除
总结
有些简单的命令就没有案例截图了,望体谅哦