Java处理压缩文件的两种方式!!!!
方式1:前端上传压缩文件zip格式
controller:
@ApiOperation("上传或保存ELC地图文件(ZIP文件)")@PostMapping("/zipUpload")public GeneralResponse zipUpload(@RequestParam("body") String body, @RequestParam("file") MultipartFile zipFile) throws IOException, ServerException, InsufficientDataException, ErrorResponseException, NoSuchAlgorithmException, InvalidKeyException, InvalidResponseException, XmlParserException, InternalException {boolean b = false;JSONObject res = new JSONObject();List<UnzipFileVo> unzipFileVoList = ZipUtil.Ectract(zipFile);// zip压缩包的内容转换成文件流集合List<UnzipFileVo> collect = unzipFileVoList.stream().filter(item -> item.getFile().getOriginalFilename().contains(".") && item.getFile().getSize() > 0).collect(Collectors.toList());//获取zip文件里面的文件,并组装到新的List对象//过滤文件夹for (int i = 0; i < collect.size(); i++) {b = ElcMapFileManager.getInstance().uploadFile(body, collect.get(i).getFile(), res);}if (!b) {return GeneralResponse.failure(ThreadLocalUtil.get().getComment());}return GeneralResponse.success(res);}ZipUtil:
import org.apache.commons.fileupload.FileItem;
import org.apache.commons.fileupload.FileItemFactory;
import org.apache.commons.fileupload.disk.DiskFileItemFactory;
import org.springframework.http.MediaType;
import org.springframework.web.multipart.MultipartFile;
import org.springframework.web.multipart.commons.CommonsMultipartFile;import java.io.*;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
import java.util.zip.ZipEntry;
import java.util.zip.ZipFile;
import java.util.zip.ZipInputStream;public class ZipUtil {public static List<UnzipFileVo> Ectract(MultipartFile multipartFile) throws IOException {List<UnzipFileVo> list= new ArrayList<>();//获取文件输入流InputStream input = multipartFile.getInputStream();//获取ZIP输入流(一定要指定字符集Charset.forName("GBK")否则会报java.lang.IllegalArgumentException: MALFORMED)ZipInputStream zipInputStream = new ZipInputStream(new BufferedInputStream(input), Charset.forName("GBK"));ZipFile zf = toFile(multipartFile);//定义ZipEntry置为null,避免由于重复调用zipInputStream.getNextEntry造成的不必要的问题ZipEntry ze = null;//循环遍历while ((ze =zipInputStream.getNextEntry())!= null) {InputStream is = zf.getInputStream(ze);UnzipFileVo unzipFileVo = new UnzipFileVo();unzipFileVo.setFile(getMultipartFile(is,ze.getName()));list.add(unzipFileVo);}//一定记得关闭流zipInputStream.closeEntry();input.close();return list;}/*** 获取封装得MultipartFile** @param inputStream inputStream* @param fileName fileName* @return MultipartFile*/public static MultipartFile getMultipartFile(InputStream inputStream, String fileName) {FileItem fileItem = createFileItem(inputStream, fileName);//CommonsMultipartFile是feign对multipartFile的封装,但是要FileItem类对象return new CommonsMultipartFile(fileItem);}private static ZipFile toFile(MultipartFile multipartFile) throws IOException {if (multipartFile == null || multipartFile.getSize() <= 0) {return null;}File file = multipartFileToFile(multipartFile);if (file == null || !file.exists()) {return null;}ZipFile zipFile = new ZipFile(file);return zipFile;}private static File multipartFileToFile(MultipartFile multipartFile) {File file = null;InputStream inputStream = null;OutputStream outputStream = null;try {inputStream = multipartFile.getInputStream();file = new File(multipartFile.getOriginalFilename());outputStream = new FileOutputStream(file);write(inputStream, outputStream);} catch (IOException e) {e.printStackTrace();} finally {if (inputStream != null) {try {inputStream.close();} catch (IOException e) {e.printStackTrace();}}if (outputStream != null) {try {outputStream.close();} catch (IOException e) {e.printStackTrace();}}}return file;}public static void write(InputStream inputStream, OutputStream outputStream) {byte[] buffer = new byte[4096];try {int count = inputStream.read(buffer, 0, buffer.length);while (count != -1) {outputStream.write(buffer, 0, count);count = inputStream.read(buffer, 0, buffer.length);}} catch (RuntimeException e) {throw e;} catch (Exception e) {throw new RuntimeException(e.getMessage(), e);}}/*** FileItem类对象创建** @param inputStream inputStream* @param fileName fileName* @return FileItem*/public static FileItem createFileItem(InputStream inputStream, String fileName) {FileItemFactory factory = new DiskFileItemFactory(16, null);String textFieldName = "file";FileItem item = factory.createItem(textFieldName, MediaType.MULTIPART_FORM_DATA_VALUE, true, fileName);int bytesRead = 0;byte[] buffer = new byte[8192];OutputStream os = null;//使用输出流输出输入流的字节try {os = item.getOutputStream();while ((bytesRead = inputStream.read(buffer, 0, 8192)) != -1) {os.write(buffer, 0, bytesRead);}inputStream.close();} catch (IOException e) {throw new IllegalArgumentException("文件上传失败");} finally {if (os != null) {try {os.close();} catch (IOException e) {}}if (inputStream != null) {try {inputStream.close();} catch (IOException e) {}}}return item;}
}UnziipFileVo:
import lombok.Data;
import org.springframework.web.multipart.MultipartFile;@Data
public class UnzipFileVo {private MultipartFile file;
}
方式2:前端上传文件(压缩文件内容)
前端实现:
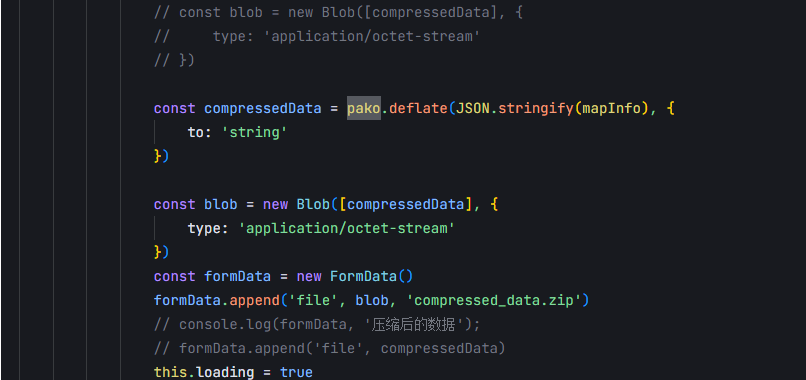
Java实现:
controller:
@ApiOperation("上传或保存ELC地图文件(前端压缩文件内容传递到后端)")@PostMapping("/decompressedUpload")// @PreAuthorize("@userAuthority.check('elcMapFile:decompressedUpload')")public GeneralResponse decompressedUpload(@RequestParam("body") String body, @RequestParam("file") MultipartFile file) {try {JSONObject res = new JSONObject();InputStream rawStream = file.getInputStream();// 将压缩流转换为字节数组byte[] compressedBytes = IOUtils.toByteArray(rawStream);// 解压逻辑(自动检测GZIP/DEFLATE)byte[] decompressedBytes = DecompressUtil.decompressAuto(compressedBytes);// 调用业务逻辑传递解压后数据boolean b = ElcMapFileManager.getInstance().uploadFile(body, file.getOriginalFilename(), decompressedBytes, res);if (!b) {return GeneralResponse.failure(ThreadLocalUtil.get().getComment());}return GeneralResponse.success(res);} catch (Exception e) {try {throw e;} finally {return GeneralResponse.failure(e.getMessage());}}}DecomressUtil:
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.util.zip.DataFormatException;
import java.util.zip.GZIPInputStream;
import java.util.zip.Inflater;public class DecompressUtil {public static byte[] decompressAuto(byte[] compressedBytes) throws IOException, DataFormatException {// 优先尝试GZIP解压(检测头字节1F8B)if (isGzipFormat(compressedBytes)) {return decompressGzip(compressedBytes);} else {// 否则按DEFLATE处理return decompressDeflate(compressedBytes);}}public static boolean isGzipFormat(byte[] data) {return data.length >= 2 && (data[0] == (byte) 0x1F) && (data[1] == (byte) 0x8B);}public static byte[] decompressGzip(byte[] compressedBytes) throws IOException {try {ByteArrayInputStream bis = new ByteArrayInputStream(compressedBytes);GZIPInputStream gzip = new GZIPInputStream(bis);ByteArrayOutputStream bos = new ByteArrayOutputStream();byte[] buffer = new byte[4096];int bytesRead;while ((bytesRead = gzip.read(buffer)) != -1) {bos.write(buffer, 0, bytesRead);}return bos.toByteArray();} catch (Exception e) {throw e;}}public static byte[] decompressDeflate(byte[] compressedBytes) throws DataFormatException {// 移除对zlib头的检查,因为当使用nowrap=true时数据不含头Inflater inflater = new Inflater(false); // 使用nowrap=true处理原始DEFLATE数据inflater.reset();inflater.setInput(compressedBytes);try {ByteArrayOutputStream bos = new ByteArrayOutputStream();byte[] buffer = new byte[10240];while (!inflater.finished()) {int count;try {count = inflater.inflate(buffer);} catch (DataFormatException e) {throw new DataFormatException("解压失败: " + e.getMessage());}if (count == 0) {if (inflater.needsInput()) {throw new DataFormatException("输入数据不完整");}if (inflater.needsDictionary()) {throw new DataFormatException("需要字典但未提供");}}bos.write(buffer, 0, count);}return bos.toByteArray();} finally {inflater.end();}}
}
注意:
在执行这行代码时:count = inflater.inflate(buffer);
我遇到了一个错误:DataFormatException: invalid stored block lengths
我尝试了很多方法都没有效果,这时候你需要看一下这句代码:
Inflater inflater = new Inflater(false); // 使用nowrap=true处理原始DEFLATE数据
我最开始用的是true,会导致一直报错,后来改成false就解决了。
大致问题原因如下:
nowrap参数的核心区别
-
**
nowrap=true**- 适用场景:处理 原始DEFLATE压缩数据(不含zlib头部和尾部)
- 行为特点:
- 跳过对zlib头部(如
0x78 9C)和校验尾部的解析 - 直接解压纯DEFLATE格式的二进制流
- 适用于前端使用
pako.deflate(data, { windowBits: -15 })生成的压缩数据
- 跳过对zlib头部(如
-
**
nowrap=false**- 适用场景:处理 完整zlib格式数据(包含标准zlib头部和校验尾部)
- 行为特点:
- 要求输入数据以zlib头部(如
0x78 9C)开头 - 自动校验Adler-32尾部完整性
- 若数据不含头部或校验失败,会抛出
DataFormatException
- 要求输入数据以zlib头部(如
详细分析
1. 前端压缩行为解析
从提供的代码片段可推断:
const compressedData = pako.deflate(JSON.stringify(mapInfo), { to: 'string' });- 关键点:
pako.deflate默认生成zlib格式数据(包含zlib头0x78 9C和Adler-32校验尾部)- 未显式设置
windowBits: -15,因此不是原始DEFLATE格式
2. 后端解压参数匹配
-
**
nowrap=false的作用**:- 要求输入数据包含完整的zlib头部和校验尾部
- 自动验证数据完整性(Adler-32校验和)
-
**
nowrap=true的陷阱**:- 若强制设为
true,后端会跳过zlib头解析,导致解压时数据偏移,引发DataFormatException(如invalid stored block lengths)
- 若强制设为
后端代码:
// 正确设置nowrap=false以处理zlib格式数据
Inflater inflater = new Inflater(false);