Boundary Attention Constrained Zero-Shot Layout-To-Image Generation
Abstract
最近的文本到图像扩散模型擅长从文本生成高分辨率图像,但难以精确控制空间构成和物体计数。为了应对这些挑战,一些研究开发了布局到图像(L2I)方法,将布局指令合并到文本到图像模型中。然而,现有的L2I方法通常需要微调预训练参数或训练扩散模型的附加控制模块。在这项工作中,我们提出了一种新的零样本学习L2I方法,BACON(边界注意约束生成),它消除了对额外模块或微调的需要。具体来说,我们使用textvisual交叉注意特征映射来量化生成图像的布局与提供的指令之间的不一致性,然后计算损失函数来优化扩散反向过程中的潜在特征。为了增强空间可控制性并减轻复杂布局指令中的语义故障,我们利用自注意力机制特征图中的像素间相关性来对齐交叉注意图,并结合三个受边界注意约束的损失函数来更新潜在特征。在L2I和非L2I预训练扩散模型上的综合实验结果表明,我们的方法在DrawBench和HRS基准上的图像组成方面在定量和定性上都优于现有的零样本学习L2I技术。
Introduction
已经提出了一系列不需要额外监督训练的零样本学习方式生成布局到图像的方法[4 Training-free
layout control with cross-attention guidance.,16 Grounded text-to-image synthesis with attention refocusing.,27 R&b: Region and boundary aware zero-shot grounded text-to-image generation.,28 Text-to-image synthesis with training-free box-constrained diffusion.,31 Loco:
Locally constrained training-free layout-to-image synthesis.]。这些技术利用扩散模型中从UNet[21]中提取的交叉注意图来量化合成图像(基于输入文本提示从初始化的潜在特征zt中采样)与目标布局指令之间的差异;随后对潜在特征zt的迭代更新有助于减少差异。然而,据观察,交叉注意地图通常在概念的中心区域表现出很高的分数,而在其边缘分配可以忽略不计的分数[16,27,31]。因此,生成的概念通常比指定的边界框大或与指定的边界框不对齐,这降低了布局控制的准确性并导致令人不满意的图像生成。此外,当同一概念中的多个对象的边界框间距很小时,现有的方法经常面临重叠的交叉注意地图,导致相对于输入提示的对象计数不准确。
为了提高空间可控制性和解决语义故障,我们提出了一种新的零样本学习L2I方法BACON,即边界注意约束生成(Boundary Attention Constrained generation)。具体来说,我们介绍了两个关键的设计原则:
(1)利用视觉自注意力机制图的像素间相关性来对齐粗粒度交叉注意图;
(2)提出一个边界注意约束来解决前面讨论的尺寸不对齐和计数不准确的挑战。
自注意力机制图捕获视觉特征中像素与像素之间的相关性,可用于过滤有噪声的交叉注意图,并增强低注意分数概念的边缘。同时,边界注意约束确保了每个单一对象的交叉注意保持在框的边界内,同时促进了同一概念内多个对象的交叉注意图的分离。我们的综合实验结果表明,在DrawBench[23]和HRS[1]基准上,所提出的方法在图像组成(空间关系、大小、颜色、物体计数)方面的定量和定性上都优于现有的零样本学习L2I方法
贡献:
• 我们研究了具有复杂布局输入的零样本学习L2I生成中的语义故障,重点关注重叠的交叉注意地图导致不准确的对象计数的问题。
• 我们提出了一种新的方法BACON,通过结合自注意增强来过滤有噪声的交叉注意图,并结合边界注意约束来防止重叠的交叉注意图,从而提高L2I生成性能。
• 我们进行了全面的实验,将我们的方法与现有的L2I方法进行比较。定量和定性实验结果表明,与现有的L2I技术相比,我们的方法达到了最先进的性能。
Related Work
Text-To-Image Diffusion Models
Layout-To-Image Generation
除了文本提示外,layout-to-image (L2I)模型还需要辅助布局指令作为输入,即语义掩码或边界框。有几种方法旨在通过对成对布局和图像数据组成的数据集进行监督微调,将布局指令映射到扩散模型的条件嵌入空间。这些方法要么将边界框集成到文本提示中[3 Geodiffusion: Text-
prompted geometric control for object detection data generation.,29 Reco: Region-controlled text-to-image generation.,32 Layoutdiffusion: Controllable diffusion model for layout-to-image generation.],并对文本编码器进行微调,要么在文本编码器旁边合并额外的模块或适配器,以增强对布局指令的理解[11 Gligen: Open-set grounded text-to-image generation.,30 Reco: Region-controlled text-to-image generation.]。另一种零样本学习方法旨在解决与监督L2I方法相关的计算和数据挑战。受到生成图像的空间布局与[6 Prompt-to-prompt]中观察到的交叉注意图之间的联系的启发,DenseDiff[10]通过操纵文本编码器的交叉注意图来指导对象在目标位置的放置。A&E[2]、BoxDiff[28]等后续研究提出通过最大化扩散模型逆向过程中特定区域的交叉注意分数的极值来优化潜在变量zt。A&R[16]将自注意力机制映射合并到目标函数中,以惩罚出现在指定框之外的对象。
与以往的研究使用最优算法不同,layout-guidance[32]使用目标函数中交叉注意分数的平均值来更新潜在变量zt。由于原始交叉注意图的典型粗粒度和噪声性质,R&B[27]使用Sobel算子[8]来检测这些图中的边缘,并选择包含所有边缘的候选框进行损失计算。为了解决边缘检测带来的额外计算和较慢的推理速度,并发工作LoCo[31]直接利用文本开始标记(SoT)、文本结束标记(EoT)和自注意力机制映射来增强交叉注意映射。然而,上述方法都没有考虑边界注意约束,导致物体计数和精确的空间可控性失败。
Methodology
Zero-shot Layout-To-Image Generation
零样本学习布局到图像生成的目的是使用预训练的扩散模型,根据输入的文本提示和相应的布局指令生成图像,而不需要额外的参数训练或额外的模块。让我们考虑一个文本提示符p = {p1,…, pn}和一组边界框![]() ;这里Bi = {b(i) 1,…, b(i) Ni}表示短语pi对应的边界框,由左上和右下的Ni对点(x1, y1, x2, y2)组成,这些点表示pi描述的Ni对象的位置。生成的图像应与文本提示紧密对齐,同时与边界框b集定义的布局指令保持一致。图1给出了使用边界框作为布局指令生成零样本学习布局到图像的示例。
;这里Bi = {b(i) 1,…, b(i) Ni}表示短语pi对应的边界框,由左上和右下的Ni对点(x1, y1, x2, y2)组成,这些点表示pi描述的Ni对象的位置。生成的图像应与文本提示紧密对齐,同时与边界框b集定义的布局指令保持一致。图1给出了使用边界框作为布局指令生成零样本学习布局到图像的示例。
Cross-Attention and Self-Attention Maps
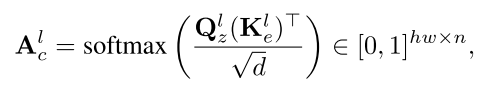
其中n为文本提示符的长度(包括SoT和EoT);de和d分别表示文本和视觉嵌入的尺寸;h和w分别表示视觉特征映射的高度和宽度。
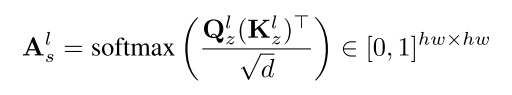
它测量视觉特征的像素到像素的相似性。从L个不同的交叉注意层得到的交叉注意和自注意力机制图汇总为
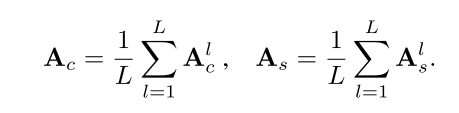
Boundary Attention Constrained Guidance
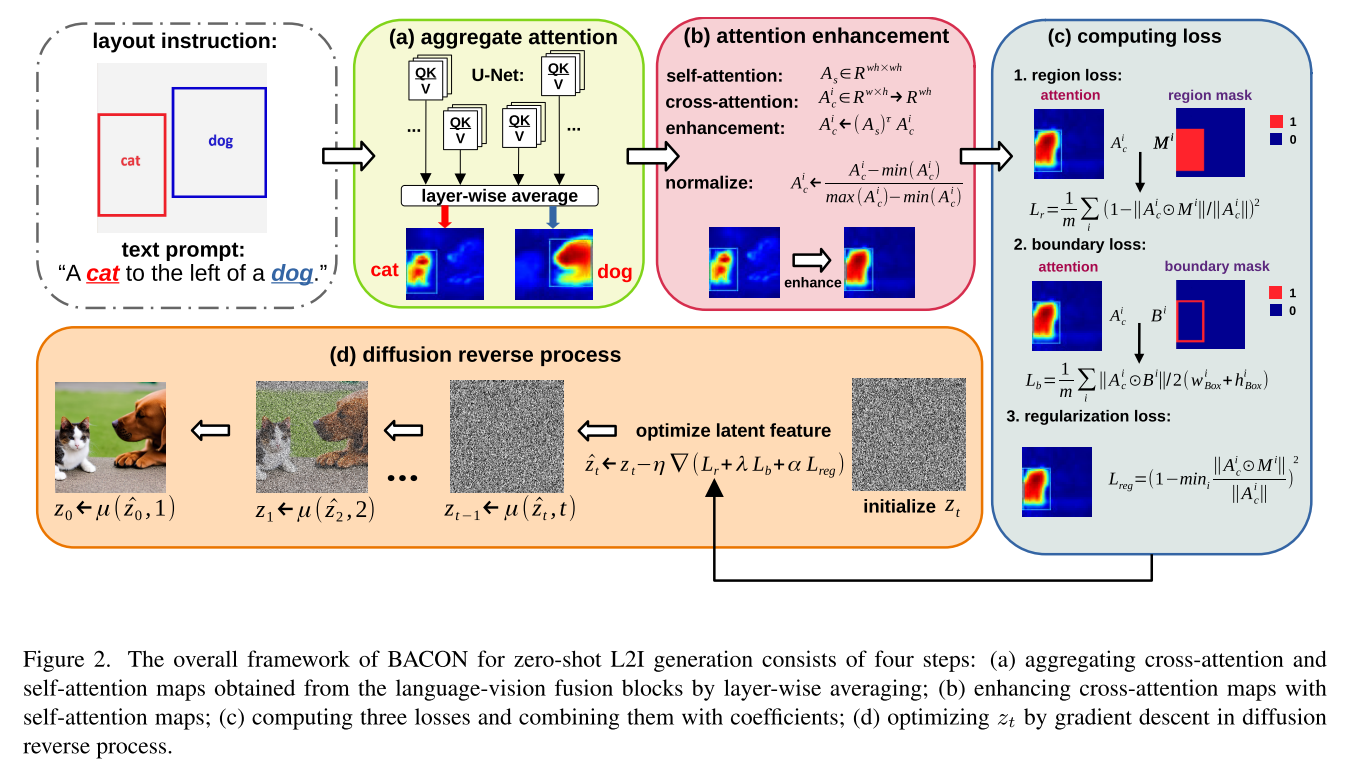
由于扩散反向过程中的潜在特征zt,所设计的损失函数无法解决由于交叉注意图的粗粒度性质而引起的计数和语义失败相关问题。在本节中,我们讨论了注意力增强的效果,并提出了三个损失函数,旨在解决以前方案遇到的问题。
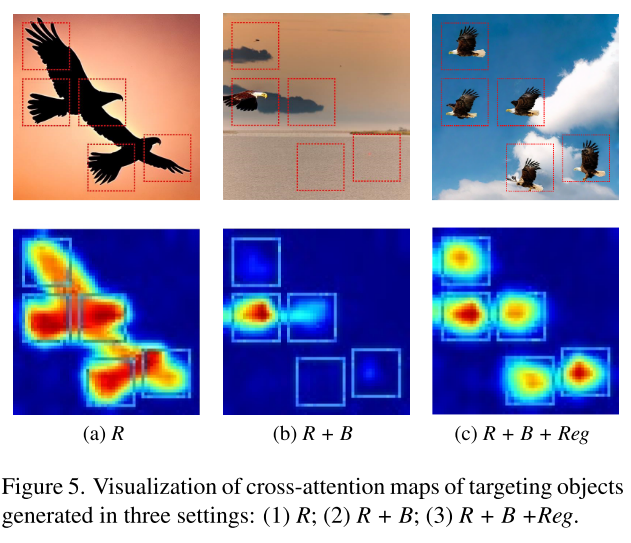
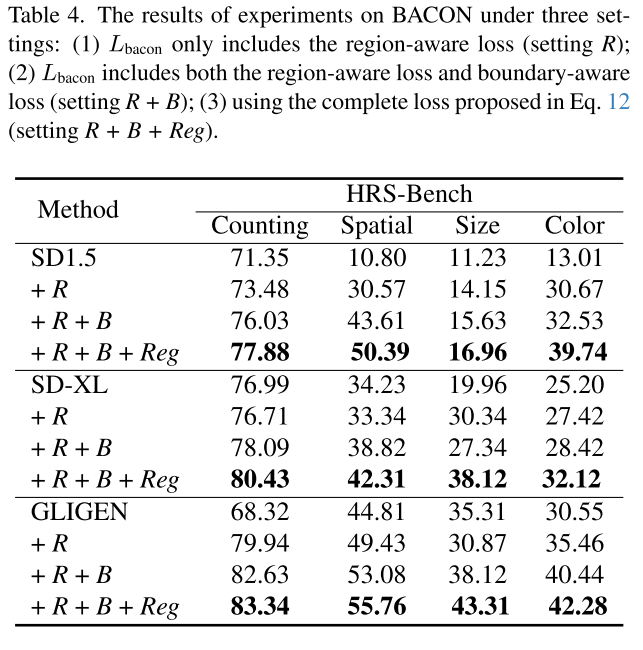
Attention enhancement. 如图2中粉色块所示,“猫”的原始交叉注意图是粗粒度的,注意分散在对象的多个部分。它还显示“狗”在“猫”的交叉注意图中得分显著,可能是由于“猫”和“狗”在预训练模型中高度相关,导致损失计算不一致。先前的研究[14,15]旨在通过使用交叉注意生成接地标签来构建合成数据集,受此启发,我们利用自注意力机制图中包含的全局信息来增强交叉注意图。
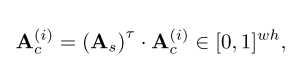
其中I表示短语pi的索引,τ是调节增强幅度的功率系数(默认设置为1)。为了维度一致性,我们根据归一化和重塑A(i) c,并根据重塑A(i) c
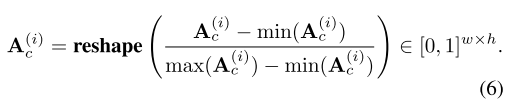
本质上,自注意力机制图As捕获像素之间的成对相关性,允许原始交叉注意图中的突出部分传播到最相关的区域。使用这些增强的交叉注意图,我们计算了三种损失,然后用于改进L2I生成。

Region-attention loss. 与之前的研究相似[4,16,27],区域注意力损失的关键思想是测量交叉注意图A(i) c在边界框Bi∈B之外的比例,并计算这些比例的平均值,进行归一化
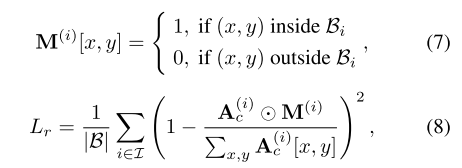
其中A(i) c [x, y]和M(i)[x, y]分别是A(i) c和M(i)中的(x,y)元素。然而,在受相同Bi约束的多个对象交叉注意分数重叠的情况下,仅依靠区域注意损失Lr无法保证高质量的生成,从而导致生成的图像计数错误。

Boundary-attention loss. 其中A(i) c [x, y]和M(i)[x, y]分别是A(i) c和M(i)中的(x,y)元素。然而,在受相同Bi约束的多个对象交叉注意分数重叠的情况下,仅依靠区域注意损失Lr无法保证高质量的生成,从而导致生成的图像计数错误。边界-注意力丧失。如前所述,由于交叉注意分数之间的干扰,由同一短语描述的多个对象的相邻边界框通常会导致L2I代中的错误计数。然而,只要这些交叉注意分数在目标边界框内,区域注意损失可能仍然很小。我们提出了一种边界注意损失,旨在隔离对应于不同物体的相邻交叉注意图,
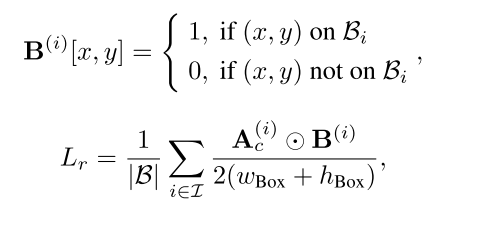
其中![]() , w(i) k和h(i) k分别表示边界框b(i) k的宽度和高度。利用所提出的边界注意力损失,我们能够强制zt生成多个对象之间没有重叠的交叉注意力地图,从而有助于提高计数的准确性。
, w(i) k和h(i) k分别表示边界框b(i) k的宽度和高度。利用所提出的边界注意力损失,我们能够强制zt生成多个对象之间没有重叠的交叉注意力地图,从而有助于提高计数的准确性。

Regularization loss. 虽然区域注意和边界注意损失通常有助于在目标边界框内定位生成的对象,但当不正确数量的对象具有完全包含在边界框内的交叉注意分数(即没有跨越边界)时,这些损失可能最小。为了防止这种情况下的不良生成,我们提出了一种正则化损失,以确保分配的对象没有无效的交叉注意映射,
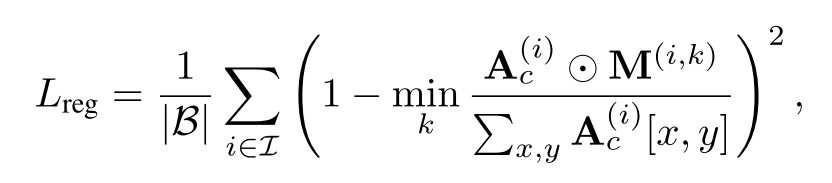
其中M(i,k)是M(i)的一个子集,表示Bi中第k个对象的位置。

Latent Feature Optimization. 在逆向过程的每个采样时间步,Lbacon可以计算为Lr、Lb和Lreg的加权和,
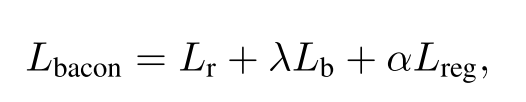
其中λ和α分别控制Lb和Lreg的干预强度。我们计算并使用Lbacon的梯度来更新zt
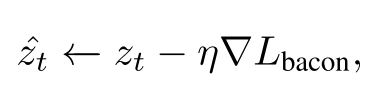
其中参数η控制更新的大小。经过toptim迭代或Lbacon小于预定阈值时提前停止,优化后的潜在特征m_zt被转发到U-Net,用于预测前一个时间步长的潜在特征m_zt−1。
Experiments
Experimental Setup
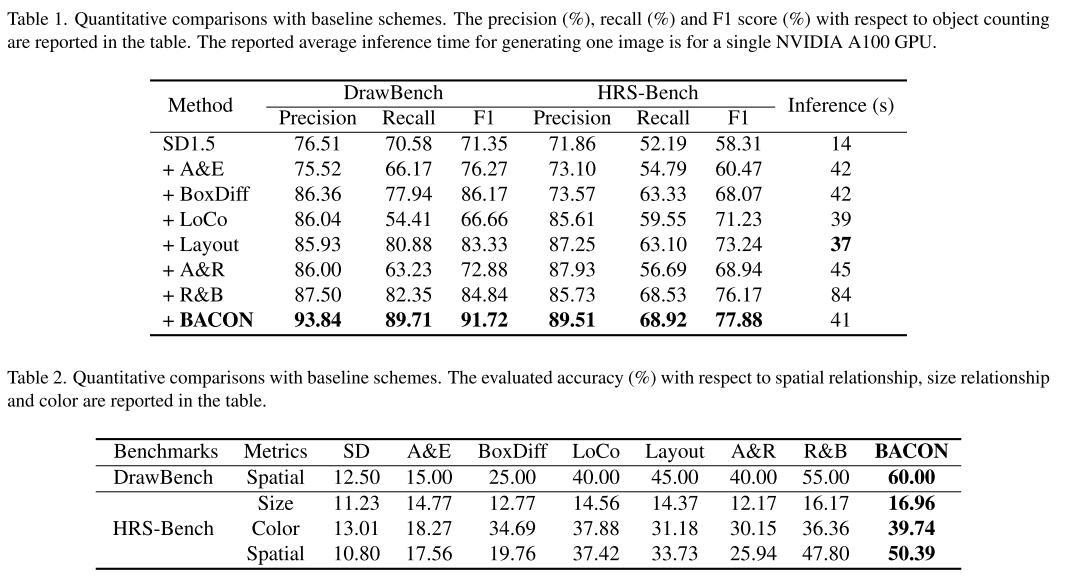
Datasets and base models. 遵循先前研究中的策略[16,27],在两个广泛使用的基准HRS[1]和Drawbench[23]的子集上进行实验。具体来说,我们使用了来自HRS基准的四条轨道——空间关系、大小、颜色和对象计数——它们分别包括1002、501、501和3000个文本提示。这些提示,以及[16]中Chat-4生成的相应布局指令,用于定量和定性地评估我们的方法和基线方法的性能。类似地,来自Drawbench的39个文本提示也用于评估,涉及空间和计数规范。我们以广泛使用的稳定扩散(SD) 1.5[20]作为基本模型进行了实验,并使用SD- xl[17]和微调的L2I模型Gligen[11]进行了烧蚀研究。采样时间步长设置为50,无分类器引导权值设置为7.5。在前10个采样步骤中,只对潜在特征zt进行优化,η设为70。除非另有说明,否则超参数λ和α都被设置为0.5。
Baselines and metrics. 我们将我们提出的方案BACON与六种最先进的方法进行了比较:A&E[2]、BoxDiff[28]、Layout-Guidance[4]、A&R[16]、R&B[27]和LoCo[31]。为了根据这些基线定量评估我们的方法,我们使用了最先进的目标检测器Ground-DINO[13]来检测合成图像中的目标并预测边界框。然后将这些预测框与真实值进行比较。我们计算精度、召回率和F1指标来全面评估BACON在对象计数中的性能。通过比较预测框和真实值框的面积和质心,我们计算了目标大小和空间关系的精度。此外,Ground-DINO预测被检测物体的颜色,我们用它来计算颜色精度。度量计算的细节可以在附录中找到。
Visual Comparisons

Quantitative Results
Plug and Play with BACON
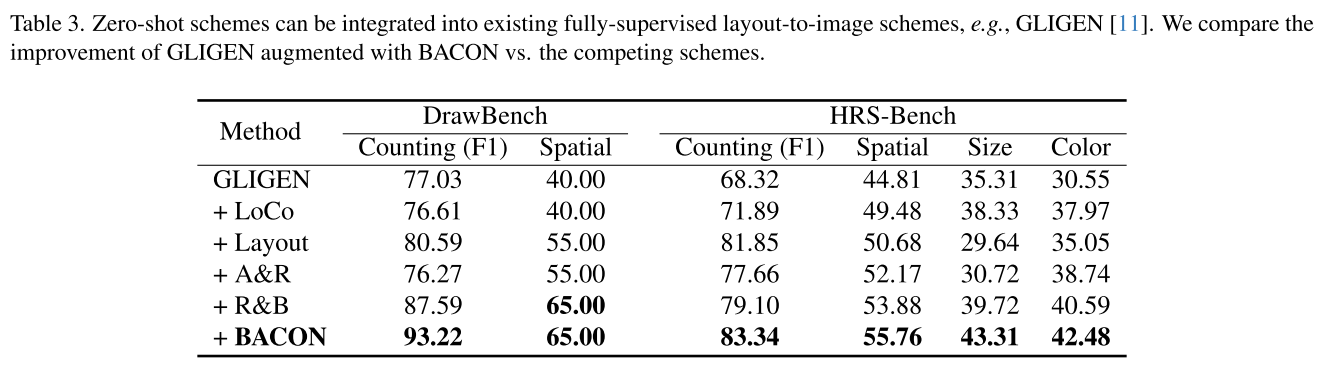
虽然我们主要基于SD 1.5进行实验,但BACON以及这些先前的零样本学习L2I方案不假设特定的模型架构,并且可以使用交叉注意块插入任意预训练的文本到图像模型。我们通过将BACON部署在另一个L2I模型GLIGEN[11]上,进一步评估了BACON的性能,该模型是通过带标签数据集的监督学习训练的。如表3所示,所有零样本学习L2I方案在几乎所有量化可控性的指标上都表现出改进的性能。与sd1.5相比,GLIGEN能够感知输入边界框,并将布局信息纳入对初始噪声z0采样的先验条件中。利用GLIGEN生成的初始潜在特征z0,反向采样器合成的图像布局比使用sd1.5生成的z0更接近给定指令。根据表3,BACON在对象计数、空间关系、颜色。虽然R&B在尺寸指标上优于BACON,但BACON的性能排名第二。在SD 1.5的实验中,普通SD 1.5产生的初始噪声z0对应于不需要的交叉注意图,通过优化可以最小程度地修改这些图,导致bacon在尺寸度量上的改进有限。相比之下,GLIGEN产生改进的初始噪声z0,有助于BACON的增强。
Ablation Study