智能意图识别 + 内容定位,contextgem重构文档处理逻辑
ContextGem 是一个免费、开源的 LLM 框架,它极大地简化了从文档中提取结构化数据和见解的过程——只需少量代码。
大多数用于从文档中提取结构化数据的 LLM 框架都需要大量的样板代码来提取基本信息。这显著增加了开发时间和复杂性。
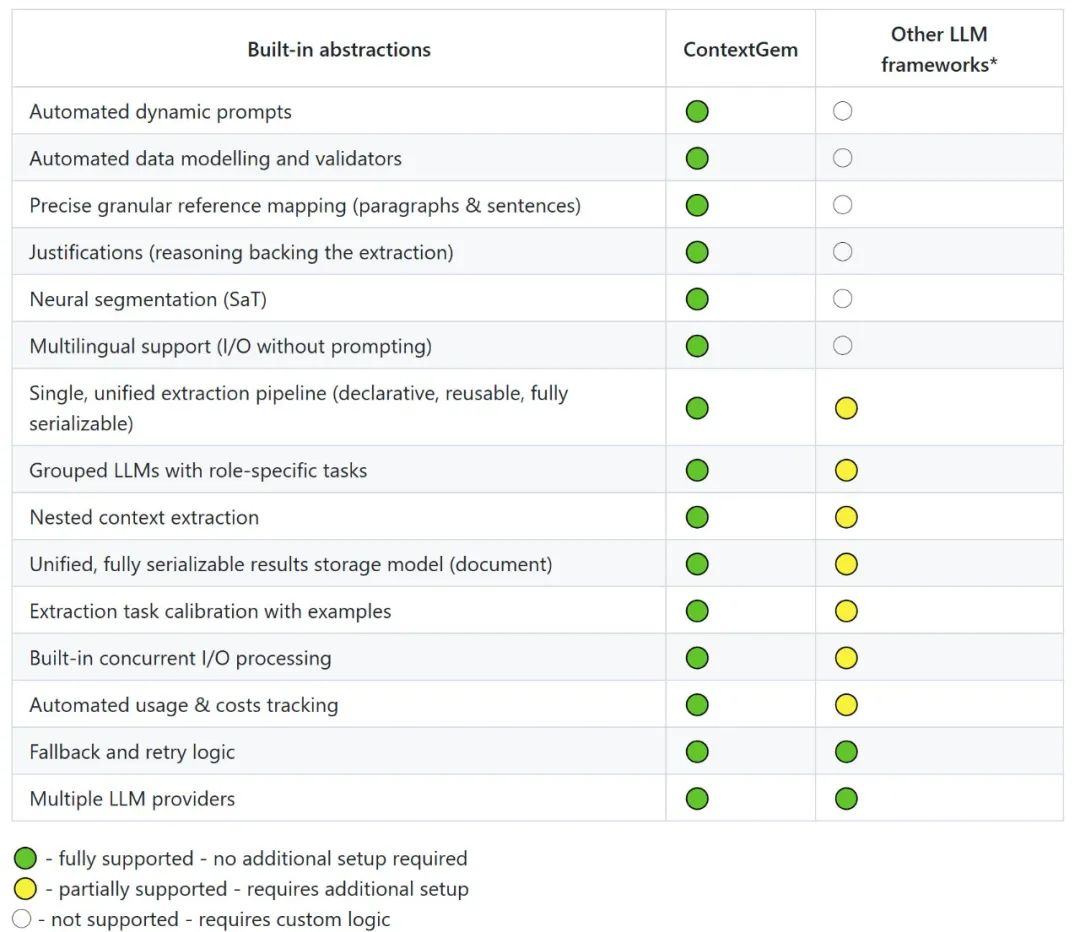
ContextGem 通过提供一个灵活、直观的框架来解决这一挑战,该框架能够以最小的努力从文档中提取结构化数据和洞察。复杂且耗时最多的部分由强大的抽象处理,消除了样板代码并减少了开发开销。
主要功能
用少量代码,你可以:
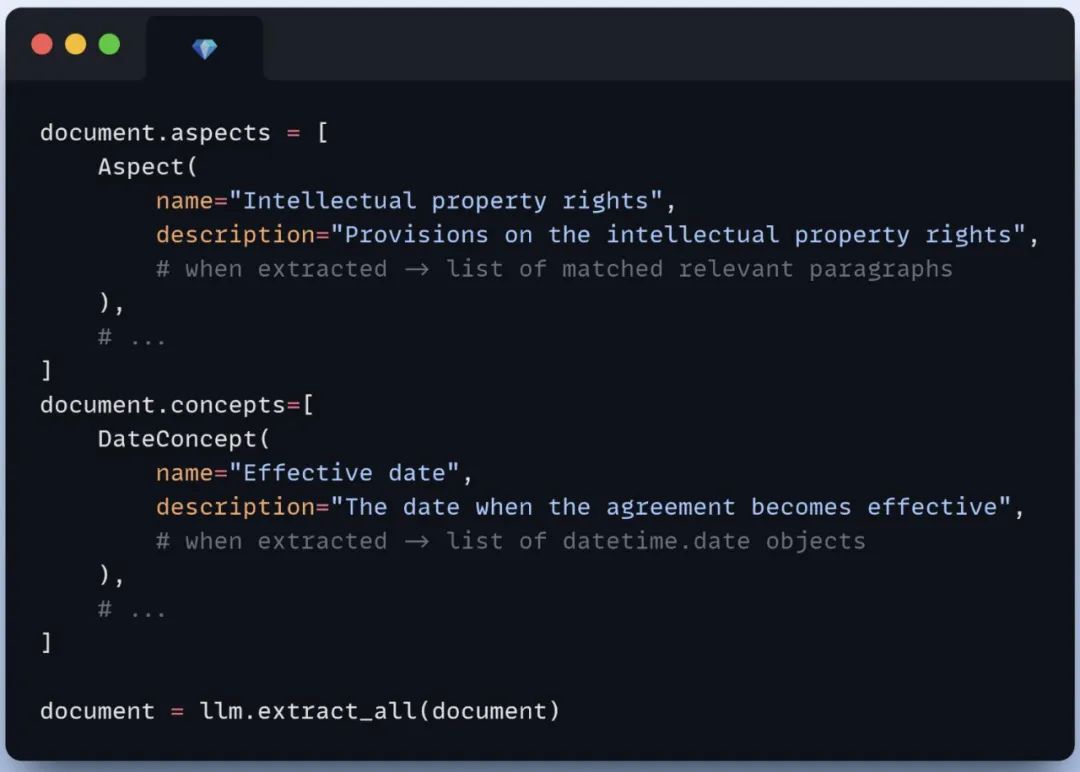
从文档(文本、图像)中提取结构化数据;
在文档中识别和分析关键方面(主题、主题、类别);
从文档中提取特定概念(实体、事实、结论、评估);
通过简单直观的 API 构建复杂的提取工作流;
创建多级提取管道(方面包含概念,层次结构方面);
聚焦文档分析
ContextGem 利用 LLMs 的长上下文窗口来提供从单个文档中提取信息的卓越准确性。与通常难以处理复杂概念和细微见解的 RAG 方法不同,ContextGem 利用不断扩大的上下文容量、不断发展的 LLM 能力和不断降低的成本。这种集中式方法能够直接从完整文档中提取信息,消除检索不一致性,同时优化深度单文档分析。虽然这为单个文档提供了更高的准确性,但 ContextGem 目前不支持跨文档查询或语料库范围的检索 - 对于这些用例,现代 RAG 系统(例如 LlamaIndex、Haystack)仍然更合适。
支持的 LLMs
云端 LLMs:OpenAI、Anthropic、Google、Azure OpenAI 等;
本地 LLMs:使用 Ollama、LM Studio 等本地运行模型;
模型架构:支持推理/CoT 能力(例如 o4-mini)和非推理模型(例如 gpt-4.1);
简单 API:统一所有 LLM 的接口,轻松切换提供者;
应用场景
适合需要大量阅读文档的场景,比如说让它找合同里的关键条款、报告里的重要数据、论文里的核心观点等等,帮你精读;
它能定位信息,告诉你信息具体在哪段哪句话,并且能解释为什么提取这些信息,推理过程是什么;
几行代码就能完成复杂提取,自动化程度比较高,很多复杂操作都被封装了,自动生成提示词,自动数据验证,自动分段。
github:https://github.com/shcherbak-ai/contextgem