深度解析六大AI爬虫工具:crawl4ai、FireCrawl、Scrapegraph-ai、Jina、SearXNG、Tavily技术对比与实战指南
一、引言
在AI大模型时代,数据获取与处理是构建智能应用的核心环节。传统爬虫面临技术门槛高、反爬应对复杂、动态内容处理困难等挑战,而AI驱动的爬虫工具通过融合大语言模型(LLM)、图神经网络、自动化解析等技术,正在重塑数据抓取范式。本文将深度测评6款主流AI爬虫工具,从技术原理、核心功能、实战场景到性能对比,为开发者提供一站式选型指南。
二、六大AI爬虫工具深度解析
1. FireCrawl:LLM就绪数据的全能引擎
技术亮点
- 智能内容清洗:基于AI算法自动过滤导航栏、页脚、广告等噪声,输出纯净的Markdown/JSON格式,天然适配LLM输入要求。支持
onlyMainContent参数精准提取正文,includeTags/excludeTags实现标签级内容筛选。 - 全链路爬取能力:
- 单页抓取:通过
/scrape接口快速获取指定URL内容,支持HTML、Markdown、链接列表等多种格式。 - 深度爬取:
/crawl端点递归遍历网站,自动发现子页面,支持设置爬取深度(maxDepth)、页面限制(limit)、路径过滤(includePaths/excludePaths)。 - 动态内容处理:集成Playwright浏览器引擎,支持JavaScript渲染页面,通过
waitFor和timeout参数优化动态内容加载。
- 单页抓取:通过
- 开发者友好生态:
-
多语言SDK:提供Python、Go、Rust等SDK,Python示例代码:
from firecrawl import FirecrawlApp app = FirecrawlApp(api_key="YOUR_API_KEY") # 单页抓取 single_page = app.scrape_url("https://example.com") # 深度爬取 crawl_result = app.crawl_url("https://docs.stripe.com", {"limit": 10, "scrapeOptions": {"onlyMainContent": True}}) -
生态集成:无缝对接LangChain、Dify、LlamaIndex,支持将抓取数据直接导入RAG系统构建知识库。
-
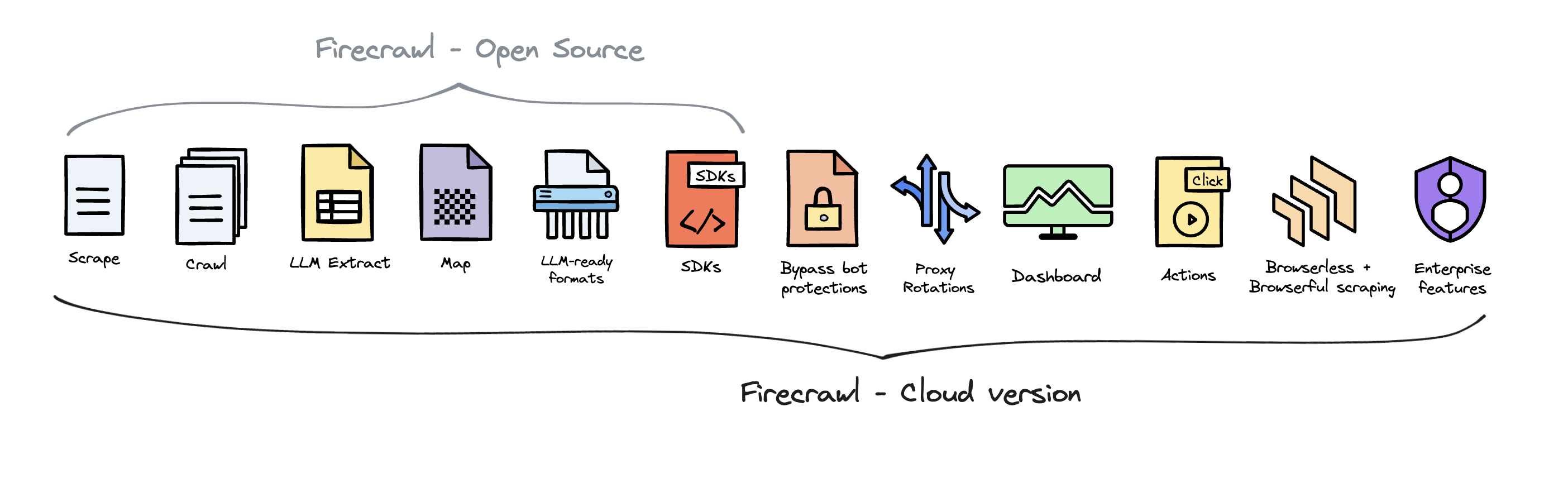
支持版本:提供开源和云产品两种,可免费使用。具体区别如下:
-
适用场景
- 大模型训练数据准备:爬取行业报告、技术文档构建领域语料库。
- 竞品监控:定时抓取竞争对手网站价格、产品更新信息,生成结构化数据报表。
- RAG系统搭建:为检索增强生成模型提供清洗后的Markdown文档,降低数据预处理成本。
优缺点
- 优势:输出格式高度适配LLM,爬取策略灵活,企业级稳定性强。
- 不足:本地部署依赖多语言环境(Node.js/Python/Rust),动态内容爬取耗时较长。
2. crawl4ai:LLM驱动的自适应爬虫
技术亮点
- LLM解析引擎:抛弃传统CSS/XPath规则,通过GPT-4、Llama等大模型理解网页语义结构,自动识别标题、正文、列表等元素。支持自定义LLM prompt,例如:
from crawl4ai import Crawler crawler = Crawler(llm_model="gpt-3.5-turbo", prompt="提取页面中的产品价格和规格参数") data = crawler.scrape("https://xxx.com/product-page") - 动态反爬机制:基于LLM生成随机User-Agent、代理轮换策略,自动处理验证码(需结合外部服务)。
- 增量爬取:通过哈希对比检测页面更新,仅抓取变化内容,降低服务器压力。
适用场景
- 结构多变的垂直网站:论坛、博客聚合页、非标准化电商平台的数据提取。
- 长尾数据采集:针对小众网站缺乏文档的场景,通过LLM动态生成解析逻辑。
- 舆情监控:实时抓取社交媒体、新闻网站的文本内容,提取关键观点和情感倾向。
优缺点
- 优势:对网站改版适应性强,减少人工维护成本;支持无规则解析复杂页面。
- 不足:依赖外部LLM服务,成本较高;解析速度受限于模型响应时间。
3. Scrapegraph-ai:图驱动的智能爬取框架

技术亮点
- 图结构工作流:将爬取任务拆解为“页面抓取”“数据解析”“结果存储”等节点,通过图可视化工具定义流程,支持条件分支、循环遍历等复杂逻辑。
- LLM生成抓取代码:输入自然语言指令(如“抓取某电商网站所有笔记本电脑的名称、价格和用户评价”),自动生成Python抓取脚本,降低编码门槛。
- 本地模型支持:兼容Ollama、Llama.cpp等本地LLM,满足数据隐私要求高的场景。
- 快速开始:演示安装依赖和示例代码。
安装依赖
示例代码pip install scrapegraph-pyfrom scrapegraph_py import Client client = Client(api_key="your-api-key-here") response = client.smartscraper(website_url="https://example.com",user_prompt="Extract the main heading and description" )
适用场景
- 复杂爬取任务:需要多步骤处理(如登录→翻页→数据清洗)的企业级数据采集。
- 定制化管道构建:金融数据监控、学术文献爬取等需要高度自定义的场景。
- 研究与实验:AI驱动爬虫算法的开发与测试平台。
优缺点
- 优势:流程可视化、逻辑可定制,支持自然语言交互;本地部署保障数据安全。
- 不足:学习成本较高,需掌握图结构设计;免费版功能有限。
4. Jina AI Reader API:极简无代码抓取工具

技术亮点
- URL前缀魔法:无需编写代码,在目标URL前添加
r.jina.ai/即可获取清洗后的Markdown内容,例如:输入:r.jina.ai/https://news.ycombinator.com 输出:结构化的新闻标题、正文、发布时间 - 动态渲染支持:后端自动处理JavaScript生成内容,返回去除广告和无关元素的纯净文本。
- 多格式输出:支持Markdown、JSON、纯文本,适配低代码平台(Zapier、Make)和自动化脚本。
适用场景
- 快速内容预览:产品经理快速获取网页核心信息,无需依赖开发团队。
- 无代码工作流:与Notion、Excel集成,实现网页数据的自动化录入。
- 单页数据提取:新闻摘要、竞品页面关键信息抓取等轻量级需求。
优缺点
- 优势:零技术门槛,秒级获取结果;完美适配非技术用户。
- 不足:仅支持单页抓取,不支持深度爬取;免费版有请求频率限制。
5. SearXNG:隐私优先的元搜索爬虫

技术亮点
- 元搜索引擎架构:聚合多个搜索引擎结果(Google、Bing、DuckDuckGo等),支持自定义搜索引擎配置,通过
/search接口返回结构化结果。 - 隐私保护:不跟踪用户行为,支持Tor代理和HTTPS加密,适合敏感数据采集。
- 数据清洗:去除重复结果,标准化日期、链接等字段,提供统一的JSON输出格式。
适用场景
- 多源数据聚合:市场调研中整合不同平台的产品评价、价格信息。
- 隐私敏感场景:学术研究、政府数据采集等对数据来源有严格要求的领域。
- 自定义搜索:通过配置文件添加小众搜索引擎,构建垂直领域搜索系统。
优缺点
- 优势:高隐私性,支持多引擎集成;适合合规要求高的场景。
- 不足:依赖外部搜索引擎API,动态内容处理能力较弱;爬取深度有限。
6. Tavily:实时数据的AI增强爬虫

技术亮点
- AI驱动搜索优化:结合LLM理解用户查询意图,动态调整爬取策略,例如搜索“2025年AI芯片价格趋势”时,自动过滤过时数据,优先抓取最新报告。
- 实时数据处理:支持WebSocket流式返回数据,适合实时监控场景(如股票行情、社交媒体舆情)。
- 反爬对抗:内置IP池、请求间隔随机化、User-Agent池等策略,降低被封禁风险。
- 快速开始:演示安装依赖和示例代码。
安装依赖
pip install tavily-python
from tavily import TavilyClienttavily_client = TavilyClient(api_key="tvly-YOUR_API_KEY")
response = tavily_client.search("Who is Leo Messi?")print(response)
适用场景
- 实时数据监控:金融市场实时报价、电商平台库存动态跟踪。
- 垂直领域搜索:医疗、法律等专业领域的精准数据获取,通过LLM过滤噪声信息。
- 动态内容爬取:单页应用(SPA)、JavaScript渲染页面的高效解析。
优缺点
- 优势:实时性强,AI优化抓取策略;反爬能力突出。
- 不足:商业化程度高,免费版功能受限;技术文档较少。
三、六大工具核心功能对比表
| 维度 | FireCrawl | crawl4ai | Scrapegraph-ai | Jina | SearXNG | Tavily |
|---|---|---|---|---|---|---|
| 核心技术 | LLM内容清洗+递归爬取 | LLM语义解析+动态适配 | 图驱动+LLM代码生成 | URL前缀+后端渲染 | 元搜索+隐私保护 | AI搜索优化+实时处理 |
| 输出格式 | Markdown/JSON/HTML | 结构化数据(LLM推断) | 自定义结构化数据 | Markdown/JSON | JSON/XML | JSON/CSV |
| 易用性 | 简单(API/SDK) | 中等(Python编程) | 较高(图结构+代码) | 极简(无代码) | 中等(配置文件) | 中等(API调用) |
| 动态内容支持 | 强(Playwright渲染) | 中(LLM解析DOM) | 强(可配置渲染引擎) | 强(后端处理) | 弱(依赖引擎API) | 强(实时渲染) |
| 爬取深度 | 支持全网站递归 | 单页/有限深度 | 自定义流程(支持深爬) | 单页 | 浅爬(搜索结果) | 中(动态调整) |
| 反爬能力 | 中等(速率限制+代理) | 强(LLM生成策略) | 强(自定义反爬节点) | 弱(依赖服务端) | 强(隐私保护) | 极强(IP池+策略) |
| 生态集成 | LangChain/Dify/Flowise | 仅Python库 | 自定义管道 | Zapier/Make | 搜索引擎插件 | 商业API对接 |
| 适合场景 | LLM数据准备、RAG知识库 | 结构多变网站、长尾数据 | 复杂流程、定制化爬取 | 快速单页抓取、无代码 | 多源聚合、隐私场景 | 实时监控、精准搜索 |
| 部署方式 | 云端/本地(Docker) | Python包安装 | Python库+自定义环境 | 云端API | 本地/云端(Docker) | 云端API(付费) |
四、实战选型指南
1. 按场景选择
- 大模型训练数据采集:首选FireCrawl,其Markdown输出完美适配LLM输入,支持全网站深度爬取,搭配LangChain可快速构建知识库。
- 复杂网页解析:crawl4ai适合论坛、博客等结构多变的场景,通过LLM动态解析降低维护成本;Scrapegraph-ai则适合需要自定义流程的企业级复杂任务。
- 快速轻量需求:Jina的URL前缀方案是最佳选择,无需代码即可获取干净文本,适合产品经理、运营人员使用。
- 隐私与合规:SearXNG的元搜索架构和隐私保护机制,适合政府、金融等对数据来源敏感的领域。
- 实时动态数据:Tavily的AI优化和实时处理能力,在股票监控、电商价格追踪等场景中表现优异。
2. 按技术栈选择
- Python开发者:crawl4ai、Scrapegraph-ai提供丰富的Python接口,适合深度定制。
- 低代码/无代码用户:Jina、FireCrawl的API设计友好,可快速集成到Zapier、Notion等平台。
- 企业级部署:FireCrawl的Docker部署方案和SearXNG的隐私架构,满足高可用性和合规要求。
五、总结
AI爬虫工具的选择需结合数据需求、技术储备和场景限制:
- 效率优先:FireCrawl和Jina适合快速获取LLM就绪数据;
- 灵活性优先:crawl4ai和Scrapegraph-ai提供强大的自适应和定制能力;
- 隐私与实时性:SearXNG和Tavily分别在合规和动态数据领域领先。
随着大模型应用的深入,爬虫工具正从“数据搬运工”升级为“智能数据净化器”。开发者可根据具体场景组合使用,例如通过FireCrawl爬取基础数据,结合crawl4ai清洗复杂页面,最终通过LangChain构建高效的RAG系统。未来,AI爬虫将进一步融合多模态处理、自动化监控等技术,成为智能应用开发的核心基础设施。