TGV之LTX:《LTX-Video: Realtime Video Latent Diffusion》翻译与解读
TGV之LTX:《LTX-Video: Realtime Video Latent Diffusion》翻译与解读
导读:这篇论文介绍了LTX-Video,一个基于Transformer的潜在扩散模型,用于文本到视频和图像到视频的生成。论文的核心思想是将视频VAE和去噪Transformer这两个组件进行整合优化,以提高效率和质量。总而言之,LTX-Video 通过其整体的潜在扩散方法和一系列创新性的设计,为实时高质量视频生成提供了一种高效且可扩展的解决方案,为该领域的发展做出了重要贡献。
>> 背景痛点:现有的文本到视频生成模型,例如Sora、MovieGen、CogVideoX等,虽然使用了时空Transformer和3D VAE,但这些模型通常将视频VAE和去噪Transformer视为独立的组件,导致空间和时间压缩的平衡性不好,并且在生成高分辨率视频时效率低下。此外,高压缩率的潜在扩散模型通常难以生成逼真的高频细节,需要额外的上采样模块来处理,增加了计算成本。
>> 具体的解决方案:LTX-Video提出了一种整体的潜在扩散方法,它将视频VAE和去噪Transformer无缝集成,并优化了它们之间的交互。主要包括以下几个方面:
● 高压缩率的视频VAE:通过将patchifying操作从Transformer的输入端移动到VAE的输入端,LTX-Video实现了1:192的高压缩率,时空下采样为32×32×8像素/token。这使得Transformer能够高效地进行全时空自注意力机制,从而生成具有时间一致性的高分辨率视频。
● VAE解码器进行最终去噪:为了解决高压缩率下细节丢失的问题,LTX-Video让VAE解码器执行最后的去噪步骤,直接在像素空间生成清晰的结果,避免了额外的上采样模块。
● 改进的Transformer架构:采用可扩展的Transformer架构,并使用旋转位置嵌入(RoPE)和QK归一化来提高视频生成的时空一致性和鲁棒性。
● 改进的VAE训练:使用重建GAN(rGAN)损失函数,多层噪声注入,统一的对数方差以及视频DWT损失函数来提高VAE的训练效果和重建质量。
● 高效的训练策略:采用多分辨率训练、随机token丢弃以及图像和视频混合训练等策略来提高训练效率和模型泛化能力。
>> 核心思路步骤:LTX-Video的核心思路可以概括为以下步骤:
● 高压缩率编码:使用改进的视频VAE对输入视频进行高压缩率编码,将像素数据转换为低维潜在表示。
● 时空Transformer处理:使用改进的Transformer架构对潜在表示进行处理,利用自注意力机制捕捉时空信息,并根据文本或图像提示进行条件生成。
● VAE解码器最终去噪:使用VAE解码器对潜在表示进行解码,同时进行最后的去噪步骤,直接生成高分辨率的像素空间视频。
>> 优势
● 速度快:LTX-Video实现了比实时更快的视频生成速度,在Nvidia H100 GPU上生成5秒的768×512分辨率24帧视频只需2秒。
● 质量高:在用户调研中,LTX-Video在视觉质量、运动保真度和提示遵守方面显著优于同等规模的其他模型。
● 可访问性:LTX-Video的模型较小,可以在消费级GPU上运行,降低了使用门槛。
● 可扩展性:LTX-Video的架构具有可扩展性,可以生成不同分辨率和持续时间的视频。
>> 结论和观点:LTX-Video通过整合视频VAE和去噪Transformer,并采用一系列改进的架构和训练策略,实现了比实时更快的速度和更高的视频生成质量。它在速度和质量上都优于同等规模的现有模型,并且具有良好的可访问性和可扩展性。 论文也指出了模型的一些局限性,例如对提示词的敏感性、对长视频的支持有限以及在特定领域泛化能力还有待进一步研究。 论文强调了LTX-Video在提高视频生成的可访问性和推动AI社区创新方面的社会影响。
目录
相关文章
TGV之LTX:《LTX-Video: Realtime Video Latent Diffusion》翻译与解读
TGV之LTX:LTX-Video的简介、安装和使用方法、案例应用之详细攻略
《LTX-Video: Realtime Video Latent Diffusion》翻译与解读
Abstract
Figure 1:Text-to-video (first row) and image-to-video samples (last 2 rows, conditioned on the left frame) generated by LTX-Video, highlighting our model’s high level of prompt adherence, visual quality and motion fidelity. Each row shows evenly-spaced frames from a generated 5-second video.图1:LTX-Video生成的文本到视频(第一行)和图像到视频样本(最后2行,以左帧为条件),突出了我们模型的高水平的提示依从性、视觉质量和运动保真度。每行显示从生成的5秒视频中均匀间隔的帧。
Figure 2:LTX-Video holistic denoising strategy – latent-to-latent diffusion denoising steps + final latent-to-pixels denoising step.图2:LTX-Video整体去噪策略-潜到潜扩散去噪步骤+最终潜到像素去噪步骤。
1、Introduction
Conclusion
相关文章
TGV之LTX:《LTX-Video: Realtime Video Latent Diffusion》翻译与解读
TGV之LTX:《LTX-Video: Realtime Video Latent Diffusion》翻译与解读-CSDN博客
TGV之LTX:LTX-Video的简介、安装和使用方法、案例应用之详细攻略
TGV之LTX:LTX-Video的简介、安装和使用方法、案例应用之详细攻略-CSDN博客
《LTX-Video: Realtime Video Latent Diffusion》翻译与解读
| 地址 | 论文地址:[2501.00103] LTX-Video: Realtime Video Latent Diffusion |
| 时间 | 2024年12月30日 |
| 作者 | Lightricks |
Abstract
| We introduce LTX-Video, a transformer-based latent diffusion model that adopts a holistic approach to video generation by seamlessly integrating the responsibilities of the Video-VAE and the denoising transformer. Unlike existing methods, which treat these components as independent, LTX-Video aims to optimize their interaction for improved efficiency and quality. At its core is a carefully designed Video-VAE that achieves a high compression ratio of 1:192, with spatiotemporal downscaling of 32 x 32 x 8 pixels per token, enabled by relocating the patchifying operation from the transformer's input to the VAE's input. Operating in this highly compressed latent space enables the transformer to efficiently perform full spatiotemporal self-attention, which is essential for generating high-resolution videos with temporal consistency. However, the high compression inherently limits the representation of fine details. To address this, our VAE decoder is tasked with both latent-to-pixel conversion and the final denoising step, producing the clean result directly in pixel space. This approach preserves the ability to generate fine details without incurring the runtime cost of a separate upsampling module. Our model supports diverse use cases, including text-to-video and image-to-video generation, with both capabilities trained simultaneously. It achieves faster-than-real-time generation, producing 5 seconds of 24 fps video at 768x512 resolution in just 2 seconds on an Nvidia H100 GPU, outperforming all existing models of similar scale. The source code and pre-trained models are publicly available, setting a new benchmark for accessible and scalable video generation. | 我们推出了 LTX-Video,这是一种基于 Transformer 的潜在扩散模型,它采用整体方法进行视频生成,通过无缝整合 Video-VAE 和去噪 Transformer 的职责。与现有方法不同,这些方法将这些组件视为独立的,LTX-Video 则旨在优化它们之间的交互,以提高效率和质量。其核心是一个精心设计的 Video-VAE,实现了 1:192 的高压缩比,每个标记的时空降采样为 32×32×8 像素,这是通过将分块操作从 Transformer 的输入转移到 VAE 的输入来实现的。在如此高度压缩的潜在空间中运行,使得 Transformer 能够高效地执行完整的时空自注意力,这对于生成具有时间一致性的高分辨率视频至关重要。然而,这种高压缩率固有地限制了对细微细节的表示。为了解决这个问题,我们的 VAE 解码器负责潜在到像素的转换以及最终的去噪步骤,直接在像素空间生成清晰的结果。这种方法在不增加单独上采样模块运行成本的情况下,保留了生成精细细节的能力。我们的模型支持多种用例,包括文本到视频和图像到视频生成,两种能力同时训练。它实现了超实时生成,在 Nvidia H100 GPU 上仅需 2 秒即可生成 5 秒长、24 帧每秒、768x512 分辨率的视频,性能优于所有规模相似的现有模型。源代码和预训练模型已公开,为可访问且可扩展的视频生成设定了新的基准。 |
Figure 1:Text-to-video (first row) and image-to-video samples (last 2 rows, conditioned on the left frame) generated by LTX-Video, highlighting our model’s high level of prompt adherence, visual quality and motion fidelity. Each row shows evenly-spaced frames from a generated 5-second video.图1:LTX-Video生成的文本到视频(第一行)和图像到视频样本(最后2行,以左帧为条件),突出了我们模型的高水平的提示依从性、视觉质量和运动保真度。每行显示从生成的5秒视频中均匀间隔的帧。

Figure 2:LTX-Video holistic denoising strategy – latent-to-latent diffusion denoising steps + final latent-to-pixels denoising step.图2:LTX-Video整体去噪策略-潜到潜扩散去噪步骤+最终潜到像素去噪步骤。
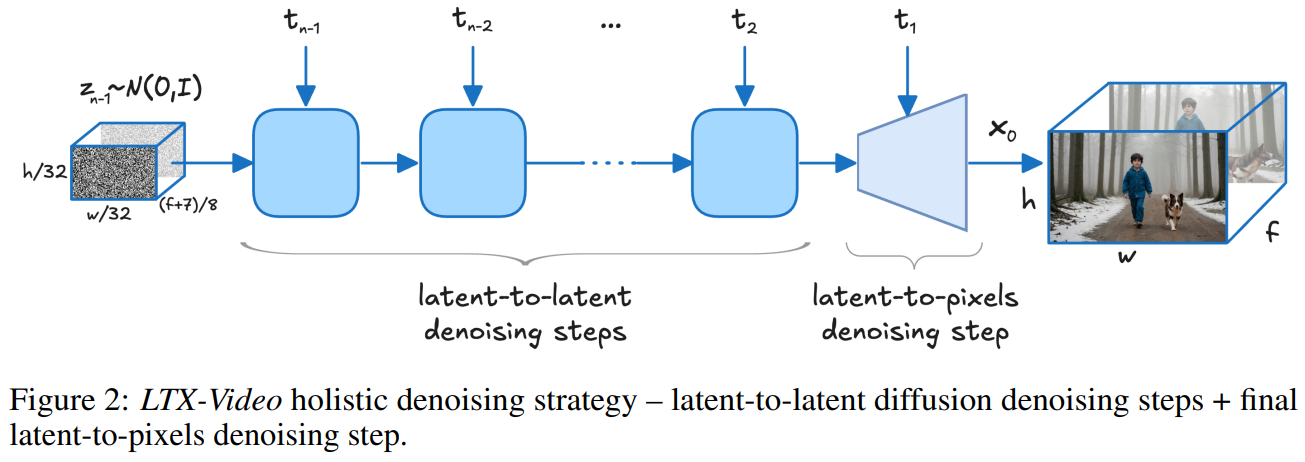
1、Introduction
| The rise of text-to-video models such as Sora [1], MovieGen [2], CogVideoX [3], Open-Sora Plan [4] and PyramidFlow [5] has demonstrated the effectiveness of spatiotemporal transformers with self-attention and a global receptive field, coupled with 3D VAEs for spatiotemporal compression. While these approaches validate the fundamental architectural choices, they often rely on conventional VAE designs that may not optimally balance spatial and temporal compression. Concurrently with our work, DC-VAE [6] demonstrated that text-to-image transformer-based diffusion models perform more effectively when paired with VAEs that employ higher spatial compression factors and a high dimensional latent spaces with up to 64 channels. However, extending this approach to video presents significant challenges. Inspired by these developments and the success of diffusion models in generating high-resolution images and video, we propose LTX-Video, a transformer-based latent diffusion model that equally prioritizes both spatial and temporal dimensions. Our approach features a carefully designed VAE architecture that achieves higher spatial compression while maintaining video quality through an increased latent depth of 128 channels. This design choice not only enables more efficient processing of video data but also results in a highly performant 3D VAE implementation. | 诸如 Sora [1]、MovieGen [2]、CogVideoX [3]、Open-Sora 计划 [4] 和 PyramidFlow [5] 等文本转视频模型的兴起,证明了具有自注意力机制和全局感受野的时空变换器与用于时空压缩的 3D VAE 相结合的有效性。尽管这些方法验证了基本架构选择的合理性,但它们通常依赖于传统的 VAE 设计,可能无法在空间和时间压缩之间实现最佳平衡。 与我们的工作同时进行,DC-VAE [6] 表明,当与采用更高空间压缩因子和多达 64 个通道的高维潜在空间的 VAE 配对时,基于文本到图像变换器的扩散模型表现得更为出色。然而,将这种方法扩展到视频领域存在重大挑战。 受这些进展以及扩散模型在生成高分辨率图像和视频方面取得的成功启发,我们提出了 LTX-Video,这是一种基于变换器的潜在扩散模型,对空间和时间维度给予同等重视。我们的方法采用精心设计的 VAE 架构,在保持视频质量的同时实现了更高的空间压缩,通过将潜在深度增加到 128 个通道来实现。这种设计选择不仅能够更高效地处理视频数据,还带来了高性能的 3D VAE 实现。 |
| Latent diffusion models trade the ability to apply pixel-level training loss for improved training efficiency, often at the expense of generating plausible high-frequency details. Sora [1] and MovieGen [2] mitigate this limitation by applying a second-stage diffusion model for generating the high-resolution output. Pixel-loss [7] attempt to address this issue by incorporating pixel-level loss on VAE-decoded noisy latents, but retained the entire generation process within the limits of the compressed latent space. In contrast, we propose tasking the VAE decoder with performing the last denoising step in conjunction with converting latents to pixels. This modification is particularly impactful at high latent compression rates, where not all high-frequency details can be reconstructed and must instead be generated. We adopt the scalable and flexible transformer architecture, known for its effectiveness in various applications, enabling our model to generate images and videos across a range of sizes and durations. Building upon Pixart-α [8]’s architecture, which extends the DiT [9] framework to be conditioned on open text inputs rather than constrained to ImageNet class labels, we introduce several key enhancements. Specifically, we replace traditional absolute positional embeddings with Rotary Positional Embeddings (RoPE [10]) enhanced by normalized fractional coordinates, which improve spatial and temporal coherence in video generation. Additionally, we normalize the key and query tensors to stabilize attention computations, enhancing robustness and increasing the entropy of attention weights. Our approach addresses limitations in existing models, offering a more integrated and efficient solution for robust video generation. Our model is the fastest video generation model of its kind, capable of generating videos faster than the time it takes to watch them (2 seconds to generate 121 frames at 768×512 pixels and 20 diffusion steps on an Nvidia H100 GPU), while outperforming all available models of similar scale (2B parameters, before distillation). In addition to text-to-video generation, we extend our model’s functionality to handle image-to-video, a practical application in content creation. Through a simple timestep-based conditioning mechanism, the model can be conditioned on any part of the input video without requiring additional parameters or special tokens. See Fig 1 for text-to-video and image-to-video samples generated by LTX-Video. Additional samples are provided in figures 18 and 19. | 潜在扩散模型通过牺牲应用像素级训练损失的能力来提高训练效率,但往往以生成合理的高频细节为代价。Sora [1] 和 MovieGen [2] 通过应用第二阶段的扩散模型来生成高分辨率输出,从而缓解了这一限制。Pixel-loss [7] 试图通过在 VAE 解码的噪声潜在值上引入像素级损失来解决此问题,但整个生成过程仍局限于压缩的潜在空间内。相比之下,我们提出让 VAE 解码器在将潜在值转换为像素的同时执行最后的去噪步骤。这种修改在高潜在压缩率下尤其有效,因为在这种情况下并非所有高频细节都能被重建,而必须生成。我们采用了可扩展且灵活的 Transformer 架构,该架构以其在各种应用中的有效性而闻名,使我们的模型能够生成不同尺寸和时长的图像和视频。在 Pixart-α [8] 架构的基础上,该架构将 DiT [9] 框架扩展为以开放文本输入为条件,而非局限于 ImageNet 类别标签,我们引入了几个关键改进。具体而言,我们用由归一化分数坐标增强的旋转位置嵌入(RoPE [10])取代了传统的绝对位置嵌入,这提高了视频生成中的空间和时间一致性。此外,我们对键和查询张量进行归一化,以稳定注意力计算,增强鲁棒性并增加注意力权重的熵。我们的方法解决了现有模型的局限性,为稳健的视频生成提供了一个更集成且高效的解决方案。 我们的模型是同类视频生成模型中速度最快的,能够在比观看视频所需时间更短的时间内生成视频(在 Nvidia H100 GPU 上,2 秒生成 121 帧,分辨率为 768×512 像素,扩散步骤为 20 步),并且在参数规模相同(20 亿参数,在蒸馏前)的情况下,性能优于所有现有模型。 除了文本到视频生成外,我们还扩展了模型的功能,使其能够处理图像到视频,这是内容创作中的一个实际应用。通过一个简单的基于时间步的条件机制,模型可以在输入视频的任何部分进行条件设置,而无需额外的参数或特殊标记。 有关 LTX-Video 生成的文本到视频和图像到视频示例,请参见图 1。更多示例请参见图 18 和 19。 |
| Our main contributions are: • A holistic approach to latent diffusion: LTX-Video seamlessly integrates the Video-VAE and the denoising transformer, optimizing their interaction within a compressed latent space and sharing the denoising objective between the transformer and the VAE’s decoder. • High-compression Video-VAE leveraging novel loss functions: By relocating the patchifying operation to the VAE and introducing novel loss functions, we achieve a 1:192 compression ratio with spatiotemporal downsampling of 32×32×8, enabling the generation of high-quality videos at unprecedented speed. • LTX-Video – A fast, accessible, and high-quality video generation model: We train and evaluate our enhanced diffusion-transformer architecture and publicly release LTX-Video, a faster-than-real-time text-to-video and image-to-video model with fewer than 2B parameters. | 我们的主要贡献在于: • 潜在扩散的整体方法:LTX-Video 无缝地将视频变分自编码器(Video-VAE)和去噪转换器集成在一起,在压缩的潜在空间中优化它们之间的交互,并在转换器和 VAE 解码器之间共享去噪目标。• 利用新颖损失函数的高压缩率视频变分自编码器:通过将分块操作移至变分自编码器(VAE)并引入新颖的损失函数,我们在空间和时间下采样为 32×32×8 的情况下实现了 1:192 的压缩率,从而能够以前所未有的速度生成高质量视频。 • LTX-Video - 快速、易用且高质量的视频生成模型:我们训练并评估了增强的扩散-变压器架构,并公开发布了 LTX-Video,这是一个参数少于 20 亿、速度超过实时的文本到视频和图像到视频模型。 |
Conclusion
| In this paper, we introduced LTX-Video, a state-of-the-art transformer-based latent diffusion model designed for text-to-video and image-to-video generation. By addressing key limitations of existing methods, such as constrained temporal modeling and inefficient spatial compression, LTX-Video achieves faster-than-real-time generation while maintaining high motion fidelity, temporal consistency, and strong alignment with input prompts or conditioning frames. At the core of LTX-Video is a holistic approach to latent diffusion, which seamlessly integrates the Video-VAE and the denoising transformer. This integration is achieved by relocating the patchifying operation from the transformer’s input to the VAE encoder, enabling efficient processing within a compressed latent space. Furthermore, the model introduces a novel shared diffusion objective between the VAE decoder and the transformer, effectively fusing the final diffusion step with the latent-to-pixel decoding stage. This innovation ensures fine-detail generation without the need for additional upsampling modules. | 在本文中,我们介绍了 LTX-Video,这是一种基于 Transformer 的先进潜在扩散模型,专为文本到视频和图像到视频生成而设计。通过解决现有方法的关键局限性,例如受限的时间建模和低效的空间压缩,LTX-Video 实现了比实时更快的生成速度,同时保持了高运动保真度、时间一致性以及与输入提示或条件帧的强对齐性。 LTX-Video 的核心是一种整体的潜在扩散方法,它无缝地将 Video-VAE 和去噪 Transformer 集成在一起。这种集成通过将补丁化操作从 Transformer 的输入转移到 VAE 编码器来实现,在压缩的潜在空间中实现了高效处理。此外,该模型在 VAE 解码器和 Transformer 之间引入了一种新颖的共享扩散目标,有效地将最终的扩散步骤与潜在到像素的解码阶段融合在一起。这一创新确保了精细细节的生成,而无需额外的上采样模块。 |
| LTX-Video sets a new benchmark for text-to-video generation, outperforming SOTA open-source models of similar scale in speed and quality. Its ability to efficiently generate high-resolution videos while preserving coherence and adherence to prompts underscores the potential of latent diffusion models for video generation tasks. The accessibility of LTX-Video further amplifies its impact, as its efficient design allows it to run on consumer-grade GPUs, democratizing advanced video generation capabilities. By lowering hardware requirements, LTX-Video opens the door to researchers, developers, and creative professionals who may not have access to high-end compute resources. Future work may explore extending LTX-Video’s architecture to support longer videos, incorporate advanced temporal coherence techniques, and investigate its adaptability to domain-specific tasks such as multi-view video synthesis or fine-grained motion editing. By enabling faster, high-quality outputs with lower compute demands, LTX-Video represents a significant step forward in creative content creation, accessible AI, and scalable video modeling. | LTX-Video 在文本转视频生成领域树立了新的标杆,在速度和质量方面超越了规模相似的开源模型。它能够高效生成高分辨率视频,同时保持连贯性和对提示的遵循,突显了潜在扩散模型在视频生成任务中的潜力。LTX-Video 的易用性进一步扩大了其影响力,因其高效的设计能够在消费级 GPU 上运行,使先进的视频生成能力得以普及。通过降低硬件要求,LTX-Video 为那些可能无法获取高端计算资源的研究人员、开发人员和创意专业人士打开了大门。未来的工作可能会探索扩展 LTX-Video 的架构以支持更长的视频,融入先进的时间连贯性技术,并研究其在特定领域任务(如多视角视频合成或精细动作编辑)中的适应性。通过实现更快、高质量的输出以及更低的计算需求,LTX-Video 在创意内容创作、可访问的人工智能和可扩展的视频建模方面迈出了重要的一步。 |