图灵奖获得者经典论文系列(1969):迈向人工智能的步伐(马文·明斯基)
实现“人工智能”的工作是大量计算机研究、设计和应用的中心。这个领域正处于初始的短暂阶段,特点是有许多不同和独立的研究成果。Marvin Minsky被要求将这些工作整合成一个连贯的总结,用适当的解释或理论以非计算机信息补充它,并介绍他对现状技术的评估。这篇论文强调了一类活动,在这些活动中,一个拥有基本程序库的通用计算机被进一步编程来执行操作,从而实现更高层次的信息处理功能,如学习和解决问题。这篇内容丰富的文章将引起的普通读者和计算机专家的兴趣。——《客座编辑》
摘要
启发式编程的问题(让计算机解决真正困难的问题)分为五个主要领域:搜索、模式识别、学习、规划和归纳。
从某种意义上说,计算机只能做它被告知要做的事情。但是,即使我们不知道如何解决某个问题,我们也可能会对机器进行编程,让机器在大量的解决方案尝试中进行搜索。不幸的是,当我们为这样的搜索编写一个简单的程序时,我们通常会发现结果过程非常低效。使用模式识别,可以将机器限制在适合的范围内探索来大大提高效率;通过学习,根据早期经验指导搜索,进一步提高了效率。通过实际分析情况,使用我们所说的计划方法,机器可以通过用更小范围,更合适的探索算法来取代最初给出的搜索来获得根本性的改进。
无论如何,这个讨论是由大量的文献引用和对一些迄今为止最成功的启发式(解决问题)程序的描述来支持的。
引言
如果外星人造访地球,他可能会对计算机在我们的技术中所扮演的角色感到困惑。一方面,他会读到和听到所有关于奇妙的“机械大脑”的故事,它们以惊人的智力表现让创造者感到困惑。他会被警告说,这些机器必须加以约束,以免它们用强大的力量、说服,甚至揭示出令人难以忍受的可怕真相来压倒我们。另一方面,他会发现,机器会因为它们奴性的服从、缺乏想象力、缺乏创新或主动性而受到各方的谴责。简而言之,一切都是因为他们无人性化的迟钝。
如果我们的地球人真的要去发现这些机器,并亲自判断的话,他可能会感到困惑。因为他只会发现少数几台机器(大多数是通用计算机)它们被编程为按照某种规范运行的计算机),它们所做一些事情可能称得上是真正的智力状态。有些人会证明一些性质相当普通的数学定理;一些机器可能会玩某些游戏,偶尔打败它们的设计师。有些人可能会区分手工印刷的字母。这是否足以证明如此多的关注是合理的,更不用说深切的担忧了?我相信是的,我们正处在一个时代的开端,这个时代将受到智能解决问题机器的强烈影响,而且很可能是主导。但我们的目的不是猜测未来可能会带来什么,它只是试图描述和解释现在看来是我们构建“人工智能”的第一步。
随着通用计算机的发展,在过去的几年里,人们越来越重视问题解决过程的发现和机械化。现在已经出现了相当多的论文,描述了与游戏、定理证明、模式识别和其他似乎需要一些智能的领域有关的理论或实际的计算机程序,文献不包括任何关于这一领域突出问题的一般性讨论。
在本文中,将尝试分离,分析和找到其中一些问题之间的关系。分析得到文献中足够多的例子的支持,以服务于综述文章的介绍,但这里仍然有很多相关工作没有描述。这篇文章是高度压缩的,因此无法在有限的篇幅内讨论所有这些问题。
当然,没有普遍接受的“智能”理论,这是我们自己的分析,可能会引起争议。遗憾的是,我们无法在此给出完整的个人致谢,只说我们几乎与每一位被引用的作者都讨论过这些问题就够了。
本文将问题分为五个主要领域:搜索,模式,识别学习,规划和归纳,这些构成了论文的主要部分,让我们非常简短地总结一下整个论点:
从某种意义上说,计算机只能做它被告知要做的事情。但是,即使我们不知道如何解决某个问题,我们也可能会对机器进行编程,让机器在大量的解决方案尝试中进行搜索。不幸的是,当我们为这样的搜索编写一个简单的程序时,我们通常会发现结果过程非常低效。使用模式识别技术,可以通过限制机器仅在适合的尝试类型上使用其方法来大大提高效率。通过学习,通过根据早期经验指导搜索,进一步提高了效率。通过实际分析情况,使用我们所说的计划方法,机器可以通过用更小,更合适的探索来取代最初给出的搜索来获得根本性的改进。最后,在归纳法部分,我们考虑了一些关于如何获得智能机器行为更全局的概念。
一、搜索问题
概要——对于给定的问题,如果我们有办法检查提出的解决方案,那么我们可以通过测试所有可能的答案来解决问题。但是这总是需要很长时间才能产生实际意义,但任何可以减少这种搜索的方法都可能有价值。如果我们能够检测到相对的改进,那么“爬山算法”(l-B部分)可能是可行的,但其使用需要一些搜索空间的结构知识,除非这种结构满足某些条件,否则爬山可能弊大于利。
当我们在下面谈论解决问题时,我们通常会假设所有要解决的问题最初都是明确定义的。我们的意思是,对于每个问题,我们都有一些系统的方式来决定何时可以接受所提出的解决方案。这里讨论的大多数实验工作都涉及在定理证明或具有精确游戏和得分规则的游戏中遇到的明确定义的问题。
从某种意义上说,所有这些问题都是微不足道的。因为如果存在这样的问题的解决方案,那么最终可以通过搜索所有可能性的任何盲目穷举过程找到该解决方案,机械化或编程这样的搜索通常并不困难。
但是,对于任何名副其实的问题,通过所有可能性进行搜索对于实际使用来说效率太低了。另一方面,像国际象棋或数学的不平凡部分这样的系统太复杂了,无法进行完整的分析。没有完整的分析,就必须始终保留一些搜索的核心,即“试错”。因此,我们需要找到一些技术,通过这些技术,不完整分析的结果可以用来使搜索更有效率。这样做的必要性简直是压倒性的。通过跳棋游戏搜索所有路径涉及大约10*40个移动选择,在国际象棋中,大约10*120个。如果我们把银河系中的所有粒子组织成某种以宇宙射线的频率运行的并行计算机,那么后一种计算仍然需要很长时间。我们不能指望仅仅改进“硬件”来解决我们所有的问题。当然,我们必须使用我们事先知道的任何东西来指导试验生成器。我们还必须能够利用在此过程中取得的成果。
A. 相对改进、爬山算法和启发式连接
如果我们没有关于问题的任何信息背景,我们就很难对问题感兴趣。我们通常有一些基础,无论多么薄弱,都可以来检测改进有些试验将被认为比其他试验更成功。例如,假设我们有一个比较者,它会从任意一对试验结果中,选出更好的一个。现在,比较本身不能很好地界定一个问题,因为未定义目标。但是,如果比较者定义的试验之间的关系是“可传递的”(即,如果A优于B,而B优于C意味着A优于C),那么我们至少可以定义“进展”,并要求我们的机器在给定的时间限制下做到最好。
但必须指出,比较者本身无论多么精明,都不能单独比详尽的搜索做出任何改进。可以肯定的是,比较为我们提供了有关部分成功的信息。但是,我们还需要一些方法来利用这些信息将搜索模式引向有希望的方向。选择新的试验点,这些点在某种意义上“相似”或“方向相同”,与那些给出了最好的先前结果。为此,我们需要在搜索空间上添加一些额外的结构。这种结构不需要与普通的方向空间概念或距离概念有太大的相似之处,但它必须以某种方式将启发式相关的点联系在一起。
我们将这种结构称为启发式连接。我们只在非正式场合介绍这个术语——这就是为什么我们的定义本身如此不正式的原因。但我们需要它,为了这个目的,许多出版物误用了精确的数学术语,例如:度量和拓扑。“联系”这个词,在字典中有各种各样的含义,似乎只是用来表示一种关系,而不涉及这种关系的确切性质。一个重要而简单的启发式联系是,当空间有坐标(或参数)时,还定义了一个数值“成功函数”E,这是一个相当平滑的坐标函数。这里我们可以使用局部优化或爬山方法。
B. 爬山算法
假设我们有一个黑箱机器,输入x1,…xn和输出E(x1,…xn)我们希望通过调整输入值来最大化E,但是我们没有给出函数E的任何数学描述,因此,我们不能使用微分或相关的方法。最明显的方法是在一个点附近局部探索,找到最陡上升的方向。一个人向那个方向移动一定的距离,重复这个过程,直到改进停止。如果山丘是平滑的,这可以通过分别估计每个坐标的梯度分量dE/dxi来近似地完成。还有更复杂的方法——可以对每个变量添加噪声,并将输出与每个输入关联起来(见下文),但这只是总体思路。它是一种基本的技术,我们总是在更复杂的系统的后台看到它。启发式地说,它的巨大优点是:抽样工作(用于确定梯度方向)在某种意义上只与参数的数量线性增长。因此,如果我们可以用这种方法解决某一类涉及许多参数的问题,那么增加更多同类型的参数应该不会导致难度的过度增加。我们特别感兴趣的是可以扩展到更多困难问题的解决方法。大多数有趣的系统,通常涉及组合操作,随着我们添加变量,难度会呈指数增长。
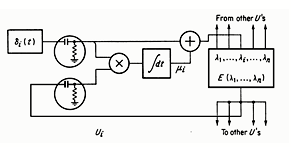
(多个优化器同时搜索某个函数E (x1,…xn)的一个(局部)最大值。每个单元Ui独立地“抖动”它的参数x,可能是随机的,通过在电流平均值mi上添加di(t)的变化。xi和E的变化是相关的,并将其结果用于缓慢改变mi。滤波器用于去除直流分量。这种技术是一种相干检测的形式,通常比单独和依次处理每个参数的方法有优势。参见Wiener , p133ff中关于“信息反馈”的讨论。各种各样的爬坡系统被称为“自适应”或“自优化”进行了研究。 )
C. 爬山算法的麻烦
显然,跟随坡度的登山者如果到达的局部山峰不是真正的或令人满意的最佳位置,就会被困住。然后,它必须被迫尝试更大的步伐或改变。通常认为这种假峰问题是机器学习的主要障碍。这当然会很麻烦。但对于真正困难的问题,在我们看来,通常更根本的问题在于找到任何显著的峰值。不幸的是,已知的困难问题的E函数经常表现出我们称之为“Mesa现象”,在这种现象中,一个参数的小变化通常导致性能不改变或性能的大变化。因此,空间主要由平坦的区域或“台地”组成。试验生成器的任何小步倾向都会导致漫无目的的游荡,而不会补偿信息增益。在这样的空间里进行有利可图的搜索,需要的步数如此之大,以至于爬山基本上是不可能的。解决问题的人必须找到其他方法,通过不同的启发式连接,爬山可能仍然可行。
当然,在人类的智力行为中,我们很少通过稳步迈向成功来解决棘手的问题。我怀疑任何一种简单的机制,例如爬山,将提供建立一个有效和通用的解决问题的机器的手段。智能机器可能需要各种不同的机制。这些将被安排在层次结构中,甚至在更复杂的,可能是递归的结构中。也许在某一层面上相当于直接爬山的行为有时会(在较低的层面上)出现“顿悟”的突然跳跃。
二、模式识别的问题
概要——为了不尝试所有的可能性,机智的机器必须根据机器不同方法的有效性将问题情况分类。这些模式识别方法必须提取问题对象的启发式显著特征,最简单的方法只是将对象与标准或原型进行匹配。更强大的“属性列表”方法使每个对象接受一系列测试,每个测试检测一些启发式重要的属性。在常见的变形形式下,这些性质必须是不变的。这里出现了两个重要的问题:发明新的有用性质和将许多性质结合起来形成一个识别系统。对于复杂的问题,这类方法必须增加用于细分复杂对象和描述其各部分之间复杂关系的工具。
任何强大的启发式程序必然包含各种不同的方法和技术。在解决问题过程的每一步,机器都必须决定处理问题的哪个方面,然后使用哪种方法。我们必须做出选择,因为我们通常无法尝试所有的可能性。
为了处理一个目标或一个问题,也就是选择一个合适的方法,我们必须认清它是一个什么样的东西。因此,在动作中进行选择的需要迫使我们为机器提供分类技术,或进化它们的方法。机器具有现实的分类技术至关重要。但是“现实”只能根据机器要遇到的环境以及可用的方法来定义。不能被利用的区别是不值得承认的。如果没有可以帮助确定何时适用的分类方案,方法通常毫无价值。
A. 分类的目的论要求
有用的分类是与机器的目标和方法相匹配的分类。在分类中组合在一起的对象应该具有一些共同的启发式价值;它们在有用的意义上应该是“相似的”;它们应取决于相关或基本特征。因此,我们不应该对发现自己使用逆向或目的论表达式来定义类感到惊讶。我们确实想要掌握“可以转换为形式 Y 的结果的对象类别”,即满足某个目标的对象类别。人们应该警惕在科学中使用目的论语言的熟悉禁令。虽然确实在某些情况下谈论目标可能会使我们倾向于某些万物有灵论的解释,但这在解决问题领域不一定是坏事。很难看出一个人如何在没有目的的情况下解决问题。目的论定义的真正困难是技术上的,而不是哲学上的,当它们必须被使用而不是仅仅被提及时就会出现。如果一个人需要准确的分类来决定是否尝试该方法,那么一个人显然不能使用实际上需要等待某个远程结果的方法进行分类。因此,在实践中,理想的目的论定义通常必须用实际的近似值来代替,通常会有一些错误的风险;也就是说,必须做出定义 如果一个人需要准确的分类来决定是否尝试该方法,那么一个人显然不能使用实际上需要等待某个远程结果的方法进行分类。因此,在实践中,理想的目的论定义通常必须用实际的近似值来代替,通常会有一些错误的风险;也就是说,必须做出定义,如果一个人需要准确地分类来决定是否尝试该方法,那么显然不能使用一种实际上需要等待某个远程结果的方法来进行分类。因此,在实践中,理想的目的论定义通常必须用实际的近似值来代替,通常会有一些错误的风险;也就是说,必须做出定义启发式有效,或经济上可用。这是非常重要的。(我们可以将“启发式有效性”与普通的“有效性”数学概念形成对比,后者区分了那些完全可以通过机器实现的定义,而不管效率如何。)
B. 模式和描述
通常有必要为符号表达式指定名称,名称的结构将对机器的心理世界产生至关重要的影响,因为它决定了可以方便地思考什么样的事物。有多种分配名称的方法,最简单的方案使用我们将称为常规(或专有)名称的名称;在这里,任意符号被分配给一类。但我们也希望使用复杂的描述或计算的名称;这些是由依赖于种类定义的进程为类构建的。为了有用,这些应该反映它们指定的事物的一些结构,以与问题领域相关的方式抽象出来。描述的概念平滑地融合到更复杂的模型概念中;在我们看来,模型是一种主动描述。它是一种事物,其形式反映了所代表事物的某些结构,但也具有工作机器的某些特征。
在第三节中,我们将考虑“学习”系统。这些系统的行为可以根据过去发生的事情以合理的方式改变。但就其本身而言,简单的学习系统仅在反复出现的情况下才有用。他们无法应对任何重大的新奇事物。只有当学习系统辅以具有某种归纳能力的分类或模式识别方法时,才能获得非凡的性能。因为在不平凡的搜索中遇到的对象种类如此之多,以至于我们不能依赖递归,而仅仅积累过去的经验记录只能发挥有限的价值。模式识别通过提供一种将新旧事物联系起来的启发式连接,可以使学习变得广泛有用。
什么是“模式”?我们经常使用这个术语来表示一组对象,这些对象可以以某种(有用的)方式被同等对待。对于每个问题领域,我们必须问:“对于处理此类问题的机器,哪些模式有用?”
视觉模式识别的问题近年来受到了很多关注,我们的大部分例子都来自这个领域。
C. 原型派生模式
阅读印刷字符的问题是分类最终基于一组固定的“原型”的情况的一个明确实例——例如,制作字体的模具。打印页面上的各个标记可能会显示许多失真的结果。有些扭曲是相当系统的——例如大小、位置和方向的变化。其他失真具有噪声的性质:模糊、颗粒、低对比度等。
如果噪声不是太严重,我们也许可以通过我们所谓的归一化和模板匹配过程来管理识别。我们首先消除与大小和位置相关的差异——也就是说,我们对输入图形进行归一化 。可以这样做,例如,通过构造一个内接在某个固定三角形中的类似图形(见下文),或者可以转换该图形以获得某个固定重心和单位秒中心矩。

(一种简单的规范化技术,如果一个对象在不旋转的情况下均匀地扩展,直到它接触到三角形的所有三条边,则生成的图形将是唯一的,因此模式识别可以在不考虑相对大小和位置的情况下进行。)
旋转等效还有一个额外的问题,即不容易避免所有歧义。人们不想把“6”和“9”等同起来。就此而言,人们不想将(0,o)或(X,x)或xo中的0等同起来,因此可能涉及上下文依赖性。归一化后,可以将未知数字与原型的模板进行比较,并通过某种匹配措施选择最合适的模板。每个“匹配标准”都会对特定形式的噪声和失真敏感,每个归一化过程也是如此。刻字或装箱方法可能对小斑点敏感,而矩法对涂抹特别敏感,至少对于细线图形等。匹配标准的选择必须取决于通常遇到的噪声和转换的种类。尽管如此,对于许多问题,我们可以通过使用简单的相关方法获得可接受的结果。
当等价变换的类别很大时,例如,当存在局部拉伸和变形时,将难以找到统一的归一化方法。相反,人们可能不得不考虑在本地进行调整以最适合模板的过程。(在测量匹配时,可以在局部“抖动”图形;如果发现改进,可以使用稍微不同的变化重复该过程等等。)通常没有实际的可能性将所有允许的变换应用于图形,并识别拓扑如下所示的对的等价性可能超出任何实际类型的迭代局部改进或爬山匹配程序。(不过,这种识别可以通过遵循线条、检测顶点并以顶点连接表的形式建立描述的方法进行机械化。)
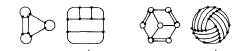
图 A、A' 和 B、B' 是拓扑等价对。长度以任意方式被扭曲,但对应点之间的连接关系被保留。在 Sherman 和 Haller 中,我们发现了可以处理此类等价的计算机程序。
具有规范化和直接比较和匹配标准的模板匹配方案在概念上过于有限,无法在更困难的问题中大量使用。如果变换集很大,归一化或“拟合”可能是不切实际的,尤其是在变换空间上没有足够的启发式连接的情况下。此外,对于每个定义的模式,系统必须提供一个原型。但是,如果一个人想到了一个抽象类,那么可能根本无法用一个或很少的具体例子来表示它的基本特征。如何用一个原型来表示具有偶数个断开部分的图形类?显然,模板系统的描述能力可以忽略不计。属性列表系统使我们摆脱了这些限制。
D. 属性列表和“字符”
我们将属性定义为双值函数,它将数字分为两类:根据函数的值是1还是0,将图形称为具有或不具有该属性。给定许多N个区分属性,我们可以通过它们的集合交集来定义多达2*n个子类,因此,通过将属性与ED和OR相结合,可以定义多达2*2*n个模式。因此,如果我们有三个属性,直线,连接和循环,则有八个子类和256个由它们的交集定义的模式。
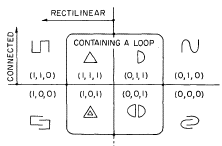
(这八个区域表示三个属性“直线”、“连接”、“包含循环”的值的所有可能配置。每个区域都包含一个代表性图形及其关联的二进制“字符”序列。)
如果给定的属性以固定的顺序放置,那么我们可以用向量或数字字符串来表示这些基本区域中的任何一个。分配给每个图形的向量将称为该图形的字符(相对于所讨论的属性序列)。(我们使用术语特征对于不限制为 2 个值的属性。因此,对于给定的属性序列,正方形具有字符(1,1,1)和一个圆字符(0,1,1)。
对于许多问题,可以使用这些字符作为类别的名称和基本元素来定义一组适当的模式。字符不仅仅是传统名称。相反,它们是描述的非常基本的形式(具有最简单的符号表达式 - 列表的形式),其结构提供了有关指定类的一些信息。这是一个步骤,尽管很小,但超出了模板方法;字符不是模式的简单实例,属性本身可能非常抽象。找到一组良好的属性是许多启发式程序的主要关注点。
E. 不变属性
一个好的属性的主要要求之一是它在通常遇到的等价变换下是不变的。因此,对于视觉模式识别,我们通常希望对象识别独立于大小和位置的均匀变化。在他们的开创性论文1947年,Pitts和McCulloch描述了一种从非不变性质形成不变性质的一般技术,假设变换空间具有一定的(群)结构。
他们的数学论证背后的想法是这样的:假设我们有一个数字的函数P,并假设对于给定的数字F,我们定义[F] = {F1,F2。 成为给定变换集下等价于F的所有图形的集合;进一步,将P [F]定义为集合{P (F1),P (F2), . .} 这些数字上 P 的值。最后,将P* [F]定义为 AVERAGE(P [F])。然后我们有一个新的属性P*,其值独立于从变换定义的等价类中选择 F。我们必须确保,当从类中选择不同的代表时,集合[F]在每种情况下始终是相同的。在连续变换空间的情况下,必须有一个与集合[F]关联的度量或等价物,例如,将操作AVERAGE定义为积分。在中研究的案例中,变换空间是一个具有唯一定义的Haar测度的群:集合[F]可以通过扫描所有变换T对给定图的应用来计算,而不会重复,以便不变属性可以通过它们在该测度上的积分来定义。结果是选择哪个数字不变的,因为积分是在(紧凑)组上。
该方法作为音高不变听觉和大小不变视觉识别的神经生理学模型提出(辅以视觉对中机制)。这个模型也在 Wiener的p160上讨论过。实际应用可能仅限于一维组和模拟扫描设备。
在最近的工作中,通过使用在这些转换下已经不变的属性可以避免此问题。因此,属性可以计算图片中连接组件的数量,该数量的大小和位置不变。或者,属性可以计算图片中垂直线的数量,该垂直线的大小和位置不变(但不是旋转)。
F. 生成属性
Selfridge已经讨论了生成有用属性的问题;我们将总结他的方法:在开始时,机器被赋予了一些基本的转换A1,...一个n,每个数字都以某种重要的方式将每个数字转换为另一个数字。例如,A1可以删除不在实体区域边界上的所有点;A2可能只留下顶点;3可能会填满空心区域等等。
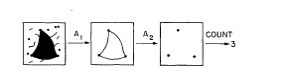
(任意一系列图片转换,后跟数值函数,可用作图片的属性函数。A1 将移除所有不在实体区域边缘的点。A2 仅留下弧突然改变方向的顶点。函数 C 仅计算图片中剩余的点数。)
每个序列 Ai1,Ai2, . . .的这种操作形成了新的转换,使之有无限的多样性。我们还为机器提供了一个或多个“终端”操作,这些操作将图片转换为数字,以便任何基本转换序列后跟终端操作定义属性。(Dineen 和Kirsch 描述了这些过程是如何在数字计算机中编程的。我们可以从几个简短的序列开始,也许是随机选择的。Selfridge描述了机器如何学习新的有用属性:
“我们现在向机器输入 A 和 0,每次都告诉机器它是哪个字母。除了两个字母下的每个序列之外,机器根据将序列应用于图像的结果建立分布函数。现在,由于序列是完全随机选择,很可能大多数序列具有非常平坦的分布函数;也就是说,它们[提供]没有信息,因此序列[根据定义]不重要。让它丢弃它们e 并选择其他一些。然而,迟早会有一些序列被证明是重要的。也就是说,它们的分布函数会在某个地方达到峰值。机器现在所做的是建立新的序列,比如重要的序列。这是重要的一点。如果它只是随机选择序列,实际上可能需要很长时间才能找到最佳序列。但是有了一些成功的序列,或者部分成功的序列来指导它,我们希望这个过程会快得多。关键问题仍然存在:我们如何构建与其他序列“相似”但又不相同的序列?到目前为止,我们认为我们将仅从重要序列的转换频率构建序列。我们将从重要的频率中建立一个过渡频率矩阵。"
“我们并不声称这种方法一定是选择序列的一种非常好的方法——只是它应该比完全不使用关于哪种序列有效的知识做得更好。在我们看来,这是关键点的学习。”。
如果这不能产生比从完全随机序列选择中获得的更有用的属性,那确实是值得注意的,生成问题在Minsky中进一步讨论。Newell,Shaw和Simon描述了更深思熟虑,更少统计的技术,这些技术可用于发现适合给定问题区域的属性集。人们可能会认为Selfridge提案是一个使用有限状态语言来描述其属性的系统。Solomonoff 和提出了一些技术来发现一组表达式的共同特征,例如,对已经建立的效用的那些属性的描述;然后可以应用这些方法来生成具有相同共同特征的新属性。
G. 组合属性
人们不能指望轻易地找到一小组属性,这些属性将恰好适合问题区域。通常,找到一大组属性要容易得多,每个属性都提供了一些有用的信息。然后,人们面临着找到一种方法将它们结合起来以做出所需区分的问题。最简单的方法是为每个类定义一个原型“特征向量”(属性值的特定序列),然后使用一些匹配过程,例如,计算协议和分歧的数量,将未知数与这些选择的原型进行比较。
下面描述的线性加权方案对此略有概括。这些方法将属性或多或少地视为支持和反对命题的独立证据;更一般的过程(关于这些过程,我们几乎没有实用信息)还必须考虑属性之间的非线性关系,即,必须包含属性值的联合子集的加权项。
I、用于组合独立性质的“贝叶斯网”
我们考虑一个单一的实验,其中一个对象被放置在属性列表计算机的前面。每个属性E;将具有一个值0或1。假设已经定义了一组对象类Fj,并且我们希望使用此实验的结果来决定对象属于这些类中的哪一个。
假设情况是概率性的,并且我们知道概率pij,如果对象在类Fj中,则第 i个属性 Ei 的值将为 1。进一步假设这些属性是独立的;也就是说,即使给定Fj,对Ei值的知识也无法告诉我们同一实验中不同Ek的值。(这是一个很强的条件—见下文。设fj是对象属于类 Fi的绝对概率。最后,对于此实验,将V定义为Ei为1的特定 is 集。那么这个V代表对象的特征!从条件概率的定义来看,我们有:
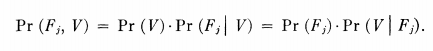
给定字符 V,我们想要猜测哪个Fj发生了(出错的可能性最小 - 即所谓的最大似然估计);也就是说,其中j是 Pr(Fj) 最大的。由于在上面的Pr(V)中不依赖于j,我们只需要计算其中j是Pr(V)Pr(Fj|V) = Pr(Fj)Pr(V|Fj) 最大。因此,通过我们的独立性假设,我们必须最大化:
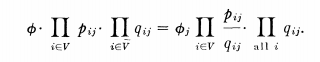
其中第一个乘积超过V,第二个乘积超过其补码。这些“最大可能性”决策可以通过简单的网络设备做出(图6)。
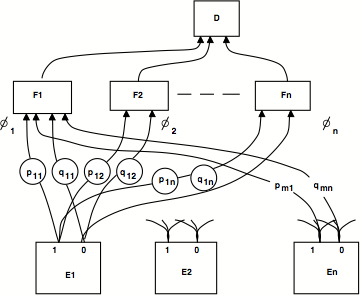
"Net“模型,用于基于属性值线性加权的最大似然决策。输入数据由每个“属性过滤器”Ei检查。每个都有0个和1个输出通道,其中一个通道由每个输入激励。这些输出由相应的 pij 加权,如文本所示。得到的信号以 Fj 单位相乘,每个单位收集特定图形类的证据(我们可以在这里使用 log(pij),并添加。最终决定由最上面的单位D做出,他只选择得分最大的Fj。请注意,(1)的第二个表达式中系数pij/qij的对数可以解释为Ei的“证据权重”,有利于Fj。
注意:以增加网络层为代价,我们还可能考虑如果我们要将一个真正属于F j类的数字分配给Fk,则可能产生的成本gjk。在这种情况下,最小成本决策由k给出,其中:
![]()
这些网络类似于[Selfridge,图3]的“Pandemonium”模型中提出的一般原理图。有人提出,一些智力过程可能由同时运作的称为“守护程序”的子机器的层次结构来执行。每个单元都设置为检测其他单元活动中的某些模式,并且每个单元的输出都会宣布该单元的置信度,即它看到了它正在寻找的内容。我们的Ei单位是Selfridge的“数据守护程序”。我们的单位Fj是他的“认知守护程序”;每个单位都从抽象的数据中收集特定命题的证据。最上面的“决策守护程序”D回应了它下面的人群中的那个,他的尖叫声最响亮。
很容易向这个“贝叶斯网络模型”添加一个机制,这将使它能够学习最佳的连接权重。想象一下,在每个事件发生后,机器被告知发生了哪个F;我们可以通过沿着通往F un it的连接发送回信号来实现这一点。假设连接或对于pij 或 qij包含一个存储数字wij的双端设备(或“突触”)。每当联合事件(Fj,Ei = 1)发生时,我们通过将其替换为(wij +1)q来修改wij,其中q是略小于单位的因子。当联合事件(Fj,Ei = 0)发生时,我们通过用(wij)q替换w ij来递减wij。不难看出,wij的期望值将与pij成正比[事实上,接近 pij [q/(1-q]。因此,机器倾向于根据经验学习最佳权重。(必须采用类似的机制来估计fj's.)归一化权重的方差接近 [(1-q)/(1 +q)] pijqij;因此,q的小值意味着快速学习,但与大方差相关,因此可靠性低。选择接近统一的q意味着缓慢但可靠的学习。q实际上是一种记忆衰减常数,它的选择必须由环境的噪声和稳定性决定,噪声需要很长的平均时间,而变化的环境需要快速适应。当然,这两个要求是不相容的,决定必须基于经济妥协。
G. 使用随机网络进行贝叶斯决策
图6网结构上非常有序。所有这些结构都是必要的吗?当然,如果有很多属性,每个属性都提供很少的边际信息,那么其中一些就不会被遗漏。然后,人们可能会期望通过对所有可能的连接路径w进行采样来获得良好的结果。因此,在这种特殊情况下,人们可能会使用随机连接网络。这里的双层网络类似于Rosenblatt的“感知器”建议。对于后者,还有一个额外的连接水平直接来自随机选择的“视网膜”点。这里的属性,抽象视觉输入数据的设备,是简单的函数,它们添加一些输入,减去其他输入,并检测结果是否超过阈值。我们认为,等式(1)说明了该方案中的价值。很明显,这样的网络可以处理属性函数输出的最大似然分析类型。但是,这些网络,由于其简单随机生成的连接,可能永远无法实现对诸如“具有两个分离部分的一类数字”之类的模式的识别,并且它们甚至无法在没有大小和位置归一化的情况下达到模板识别的效果(除非样本数字以前基本上以所有大小和位置呈现)。因为通过随机方法找到足够多的属性与模式有用地相关的机会非常小,这些模式比原型派生的属性更抽象。这些网络实际上只能分离出(通过加权)各个输入属性中的信息;它们不能提取以非加性形式存在的进一步信息。“感知器”类机器既不能获得优于偶然的特性,也不能组装从随机结构中获得的比添加剂更好的组合。
对于识别归一化的印刷或手印字符,单点属性做得非常好[23];这相当于“平均”许多样本。Bledsoe和Browning声称具有点对特性的良好结果。Roberts描述了这个一般领域的一系列实验。Doyle没有归一化,但具有相当复杂的性质,获得了优异的结果;他的属性已经基本上是大小不变的。对Doyle的工作和其他模式识别实验的一般综述将在Selfridge和Neisser中找到。
对于复杂的区分,例如,在一个和两个连接的对象之间,属性问题非常严重,特别是对于长时间摆动的对象,例如由Kirsch处理[27]。这里需要某种递归处理,即使使用大型网络和长时间训练,简单属性的组合也几乎肯定会失败。
在讨论决策网络模型时,我们不应该不注意它们的重要局限性。pis代表独立事件的假设确实是一个非常强大的条件。如果没有这个假设,我们仍然可以构建最大似然网,但是我们需要一层额外的细胞来表示所有联合事件V;也就是说,我们需要知道所有的Pr(Fj|V)。这给出了一个一般(但微不足道的)解决方案,但n个属性需要2*n个单元,这对于大型系统来说是完全不切实际的。需要的是一个系统,它计算所有联合条件概率的一些抽样,并在需要时使用这些抽样来估计其他抽样。Uttley的工作与这个问题有关,但他提出的实验装置尚未清楚地显示如何避免指数增长。另见Roberts,Papert和 Hawkins。我们在Rosenblatt中找不到类似这种类型的分析。
H. 连接性和注意性——属性列表方法的局限性
[注:我在2000年12月对本节进行了大幅修改,以澄清和简化符号。] 由于它的固定大小,属性列表方案在它可以描述的关系的复杂性方面受到限制。如果一台机器可以识别椅子和桌子,它肯定应该能够告诉我们“有椅子和桌子”。在一定程度上,我们可以发明一些属性,其中嵌入了一些这样的关系,但没有固定形式的公式可以表示任意复杂的关系。因此,我们可能想将下面最左边的图描述为,
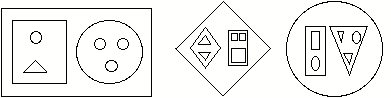
(“矩形 (1) 包含两个水平放置的子图形。左侧的部分是一个矩形 (2),其中包含两个垂直放置的子图形,其上部是圆形 (3),下半部分是三角形 (4)。右边的部分. . .等等)
这样的描述需要将场景分离或“分割”成多个部分的能力。(请注意,在这个例子中,发音本质上是递归的;首先将图形分成两部分;然后使用相同的机制来描述每个部分。)我们可以将这种描述形式化为一种表达语言,其基本语法形式是函数 R(L) 其中 F 命名一个关系,L 是一个有序列表,其中包含相互之间具有该关系的对象或子图形。我们通过允许列表 L 的成员不仅包含“基本”图形的名称而且包含“描述子图形的表达式”来获得所需的灵活性。那么上面最左边的场景可以由表达式描述:
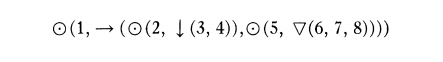
其中 "IN (x, y)" 表示 'y 在 x 内,'-->(xy)" 表示'X 在 Y 的左侧',而 "ABOVE (x, y)" 表示'x 在 y 之上。这种描述可以看作是一种简单的“列表结构”语言的表达。Newell、Shaw 和 Simon 已经开发了强大的计算机技术来操作这些语言中的符号表达,以达到启发式编程的目的。(参见第 1 节末尾的注释IV. 如果列表的某些成员是列表,则它们必须用外括号括起来,这说明了括号的累积。
这种描述语言可以看作是一种简单的“列表结构”语言。Newell、Shaw 和 Simon 开发了强大的计算机技术,用于在这些语言中操作符号表达式,以达到启发式编程的目的。见第四节末尾的注释。通过引入关系“内部”、“左侧”和“上方”的符号,我们构建了一个符号描述。这样的描述可以由机器形成和操作。
通过抽象出图形各部分之间的复杂关系,我们可以重新使用相同的公式来描述以上所有三个图形,对它们都使用相同的“更抽象”的表达方式:
F( A, B, C, D, E, F, G, H ) = IN( A , (-->(IN( B , (ABOVE ( C, D )))), IN( E , (ABOVE (- ->( F, G, H )))))))
其中每个特定的几何图形都被新变量之一替换。因此,左图可以表示为
F(box, box, cir, tri, cir, cir, cir, cir)
其他两个场景可以用相同的 F 表示,但对其变量进行不同的替换。由程序员决定图片的一部分在什么复杂程度下应该被认为是“原始的”。这将取决于描述的用途。我们可以进一步将图形分为顶点、线和弧。显然,对于某些应用,这些关系需要更多的度量信息,例如长度或角度的规范。
这种“关节”描述的重要之处在于,它们可以通过重复应用一组固定的模式识别技术来获得。因此,我们可以从固定复杂度分类机制中获得任意复杂的描述。该机制所需的新元素(除了操纵列表结构的能力之外)是表达能力——“全神贯注”于图片的选定部分,并将所有资源用于该部分。在高效的问题解决程序中,我们通常不会在一次操作中完成这样的描述。相反,描述的深度或细节将受其他过程的控制。只有在必须这样做时,这些才会更深入或更仔细地观察,例如,当当前可用的描述不足以满足当前目标时。作者与 L. Hodes 正在研究使用关节描述的模式识别方案。通过操纵形式描述,我们可以处理重叠和不完整的图形,以及“格式塔”类型的其他几个问题。
似乎随着机器转向更困难的问题领域,被动分类系统将变得不那么充分,我们可能不得不转向更多基于内部生成假设的方案,也许沿着提议的路线“错误控制”MacKay。
空间要求我们终止对模式识别和描述的讨论。在此处未审查的重要著作中,应提及 Bomba 和 Grimsdale等人的著作。其中涉及描述元素,Unger和 Holland 用于并行处理方案,Hebb关注生理描述模型,以及格式塔心理学家的工作,特别是 Kohler ,他肯定会提出一些重要问题,如果没有解决的话。Sherman 、Haller和其他人已经完成了使用线跟踪操作进行拓扑分类的程序。Selfridge 的论文对这一领域的工作产生了重大影响。
另见 Kirsch等人,讨论了一些有趣的计算机图像处理技术,参见 Minot 和 Stevens 对阅读机和相关问题的评论。人们还应该检查一些生物学工作,例如,Tinbergen ,以查看一些乍一看似乎非常复杂的辨别是基于排列在简单决策树中的一些明显简单的属性来解释的。
三、学习系统
概要——为了解决一个新问题,首先应该尝试使用与解决类似问题的方法类似的方法。要实施这种“基本学习启发式”,必须概括过去的经验,而做到这一点的一种方法是使用成功强化的决策模型。这些学习系统被证明是平均设备。使用还学习哪些事件与强化(即奖励)相关的方法,我们可以构建更自主的“二次强化”系统。在将这些方法应用于复杂问题时,人们会遇到一个严重的困难——在涉及的许多决策中分配复杂策略成功的功劳。这个问题可以通过在层次结构中安排局部目标的局部强化来解决。
为了解决一个新问题,人们首先尝试使用类似于过去在类似问题上工作过的方法,使用可能被称为基本学习启发式的方法。我们也希望我们的机器能够从他们过去的经验中受益。由于我们不能期望新情况与旧情况完全相同,因此任何有用的学习都必须涉及泛化技术。与“学习”相关的概念太多,无法准确定义该术语。但我们可以肯定,任何有用的学习系统都必须使用过去的记录作为更一般命题的证据;因此,它必须包含一些关于“归纳推理”的承诺。(参见第 VB 节。)也许对一组实体进行概括的最简单方法是通过构造一个新的实体,它是“理想的”,或者更确切地说,是该集合的典型成员。通常的方法是通过某种平均技术来消除变化。事实上,我们发现大多数简单的学习设备确实包含了一些平均技术——通常是对某种产品进行平均,从而获得某种相关性。我们将在这里讨论这一系列方法,并在第五节中讨论一些更抽象的方案。
A. 强化
强化过程是由于应用“强化操作”Z而导致系统行为的某些方面在未来变得更加(或不那么)突出的过程。这个操作只需要影响那些最近实际发生的行为的各个方面。
类比是动物行为中的“奖励”或“灭绝”(不是惩罚)。这种过程的重要之处在于它是“可操作的”(Skinner 的一个术语),强化操作不会启动行为,而只是从已经发生的事情中选择训练者喜欢的事情。然后,这样的系统必须包含一个设备 M,它产生各种行为(例如,在与某些环境交互时)和一个在应用可用的强化算子时做出关键判断的训练器。
让我们考虑一个非常简单的“操作性强化”模型。
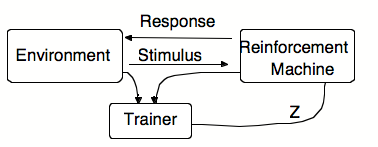
为了响应来自环境的刺激,机器会做出几种可能的反应之一。它会记住在选择此响应时做出了哪些决定。此后不久,训练器向机器发送正向或负向强化(奖励)信号;这会增加或减少未来做出相同决定的趋势。请注意,培训师不需要知道如何解决问题,而只需知道如何检测成功或失败,或相对改进;他的功能是选择性的。训练器可能会被连接以观察实际的刺激 + 反应活动,或者在更有趣的系统中,观察环境状态的某些功能。
假设在每次呈现刺激S时,动物都必须做出选择,例如左转或右转,并且它在第n次试验时右转的概率为pn。假设我们希望它右转。每当它这样做时,我们可能会通过应用运算符 Z+ 来“奖励”它:
Pn+1= Z+(pn) =qpn + (1-q) 0 < q < 1
它使p向统一方向移动一小部分 (1-q)。(正确地,强化函数应该取决于p和之前的反应。如果我们的动物刚刚向左转,奖励应该减少p。文献中的符号在这方面有些混乱。)如果我们不喜欢我们应用负强化做什么
![]()
将 p向 0 移动相同的分数。在 Bush 和 Mosteller [45] 中可以找到一些关于这种“线性”学习算子的理论,可以推广到几种刺激和响应。我们可以证明学习结果是一个按指数衰减时间因子加权的平均值:根据第n个事件是奖励还是消除,令Z n为 ±1,并将p n替换为cn-2p n - 1 ,因此即 -1< c n <1,至于相关系数。然后(c 0 = 0)我们通过归纳得到
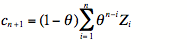
并且因为
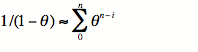
我们可以这样写:
(1)
![]()
如果术语Zi 被认为是 (i) 生物如何响应和 (ii) 给予了哪种强化的乘积,那么cn 是这些生物的联合行为的一种相关函数(具有衰减权重)数量。普通的均匀加权平均值具有相同的一般形式,但具有与时间相关的q:
(2)
![]()
在 (1) 中,我们再次遇到第 II-G-1 节中描述的情况;q的小值提供快速学习,以及快速适应不断变化的环境的可能性。接近统一的q值会降低学习速度,但也会消除由于噪声引起的不确定性。如第 II-G-1 节所述,响应分布近似于替代响应的奖励概率。我认为这种现象的重要性被高估了。这当然不是一个特别合理的策略。一种合理的选择是计算数字p ij 如前所述,但实际上在每次试验中都在玩“最有可能”的选择。除非遇到敌对对手,否则通常没有理由采取“混合”策略。为了获得信息,人们应该多久执行一次与估计的最优策略不同的策略,这是许多领域的一个潜在问题。
Samuel 的系数优化程序在指数平均方法和均匀平均方法之间进行了巧妙的折衷。上面(2)中的 N 值从 16 开始,一直保持到 n=16,然后 N 为 32,直到 n=32,依此类推,直到n=256。此后,N 保持固定在 256。这很好地防止了剧烈波动n 一开始,一段时间内接近均匀加权,最后接近指数加权相关,所有这些都需要很少的计算工作。Samuel 的程序是目前与人类平均能力相匹配的游戏程序的杰出示例,其成功(实时)归功于启发式和编程方面的大量此类优雅。
消失或“遗忘”的问题对于复杂的、分层的学习尤其重要。因为,一旦对过去进行了概括,就有可能在此基础上再接再厉。因此,人们可能会选择某些重要的属性,并开始使用它们来描述经验,也许用它们来存储一个人的记忆。如果以后发现其他一些属性会更好,那么人们必须面临翻译或放弃基于旧系统 011 的记录的问题。这可能是一个非常高的代价。一个人不会轻易放弃看待事物的旧方式,如果更好的方式需要付出很多努力和经验才能发挥作用。因此训练序列可以说,我们的机器将在其度过婴儿期,必须非常精明地选择,以确保早期的抽象将为后来的困难问题提供良好的基础。
顺便说一句,尽管这里为他们的阐述提供了空间,但我不相信这种“增量”或“统计”学习方案应该在我们的模型中发挥核心作用。它们肯定会继续作为我们程序的组件出现,但我认为,主要是默认情况下。一个人越聪明,他就越能从经验中学到相当确定的东西。例如,拒绝或接受假设,或改变目标。(一个明显的例外是在一个真正的统计环境中,平均是不可避免的。但我们认为,解决问题的核心始终是引起搜索的组合部分,我们通常应该能够考虑由“噪音”只是令人烦恼的事情,无论它们多么令人恼火。)在这方面,我们可以参考 Miller、Galanter 和 Pribram 中关于记忆的讨论。这似乎是心理学中第一部展示人工智能领域工作影响的主要著作,其程序总体上相当复杂。
B. 二次强化和期望模型
简单的强化系统受限于它对训练器的依赖。如果训练器只能检测到问题的解决方案,那么我们可能会遇到“台面”现象,这将限制在困难问题上的性能。(参见第 IC 部分。)避免这种情况的一种方法是让机器学习概括培训师所做的事情。然后,在困难的问题中,它可能能够在此过程中给予自己部分强化,例如,在解决相关子问题时。这台机器有一些这样的能力:
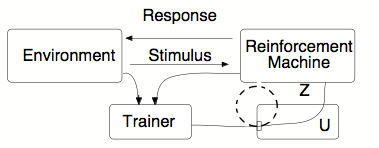
额外的设备 U 使图 8 的机器能够学习来自环境的哪些信号与强化相关联。初级强化信号 S 通过 U 路由。通过巴甫洛夫调节过程(此处未描述),外部信号会产生强化信号,就像过去经常接替它们的那些信号一样。这样的信号可能是抽象的,例如口头鼓励。如果“二次强化”信号被允许获得进一步的外部关联(例如,通过如图所示的通道 Z U ),机器可能能够处理子问题链。但必须采取一些措施来稳定系统对抗由路径 Z U形成的正符号反馈回路. 这个稳定问题带来的巨大困难可能反映在这样一个事实中,即在低等动物中,很难证明这种连锁效应。
新单元 U 是一种设备,它可以了解哪些外部刺激与各种强化信号密切相关,并通过再现相应的强化信号来响应这些刺激。(设备 U不是本身就是一个强化学习设备;它更像是一个“巴甫洛夫式”调节装置,将 Z 信号视为“无条件”刺激,将 S 信号视为移动和回复。我们也可能限制条件刺激的数量。)启发式的想法是,过去与(例如)正强化密切相关的任何来自环境的信号都可能表明好事刚刚发生。如果早期问题的训练是现实的,那么系统最终应该能够将自己从训练器中分离出来,并变得自主。如果我们进一步允许“二级强化物”的“连锁”,例如,原则上,通过承认虚线所示的连接,该方案变得非常强大。承认这种程度的自主权存在明显的缺陷,系统的值可能会转移到非自适应条件。
C.预测和期望
评估单元U应该获得判断情况好坏的能力。这种评估既可以应用于想象的情况,也可以应用于真实的情况。如果我们可以估计提议的动作的后果(没有实际执行),我们可以使用U来评估(估计的)结果情况。这可以帮助减少搜索的工作量,实际上我们将拥有一台具有一定能力的机器向前看或计划。为了做到这一点,我们需要一个额外的设备 P,它在给定情况和动作的描述后,将预测可能结果的描述。(我们将在第 IV-C 节讨论这样做的方案。)设备P可以按照强化学习设备的方式构建。在这样的系统中,所需的增强信号将具有非常有吸引力的特性。因为当实际结果类似于被预测准确的期望得到回报。如果我们可以进一步加强那些具有新颖性的预测,我们可能会期望识别出出于某种好奇心的行为。在强化已确认的新期望(或新解释)的机制中,我们可能会找到模拟智力动机的关键。请参阅 Bernstein 的讨论以及 Newell、Shaw 和 Simon 的极具启发性的论文中更广泛的讨论;不应忽视 Newell 的开创性论文和 Samuel 中对极小化过程的讨论。
塞缪尔的跳棋程序
在塞缪尔的跳棋游戏“泛化学习”程序中,我们发现了一种新颖的启发式技术,可以看作是“期望强化”概念的一个简单例子。让我们非常简要地回顾一下玩这种两人棋盘游戏的情况。正如 Shannon 所指出的那样,此类博弈原则上是有限的,并且可以通过跟踪所有可能的延续来找到最佳策略——如果他去那里,我可以去那里,或者那里等等,然后“备份”或从终端位置“最小化”,赢、输或平局。但在实践中,对由此产生的巨大“移动树”的全面探索是不可能的。毫无疑问,这样的游戏总是需要一些探索。但是树必须修剪。我们可以简单地限制探索的深度:移动和回复的数量。我们还可以限制从每个位置探索的备选方案的数量,这需要一些启发式方法来选择“合理的移动”。现在,如果仍要使用后备技术(使用不完整的移动树),则必须用其他评估非终端位置的“静态”方法来代替绝对的“赢、输或平”标准。[注:在某些问题中,备份过程可以以封闭分析形式处理,因此可以使用贝尔曼的“动态规划”[51]等方法。Freimer给出了一些有限的“前瞻”不起作用的例子。] 如果仍然要使用后备技术(使用不完整的移动树),则必须用其他评估非终端位置的“静态”方法来代替绝对的“赢、输或平”标准。[注:在某些问题中,备份过程可以以封闭分析形式处理,因此可以使用Bellman的“动态规划”[51]等方法。Freimer 给出了一些有限的“前瞻”不起作用的例子。如果仍然要使用后备技术(使用不完整的移动树),则必须用其他评估非终端位置的“静态”方法来代替绝对的“赢、输或平”标准。[注:在某些问题中,备份过程可以以封闭分析形式处理,因此可以使用贝尔曼的“动态规划”等方法。Freimer给出了一些有限的“前瞻”不起作用的例子。
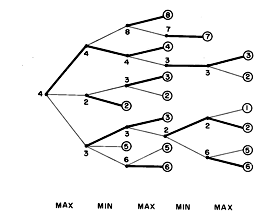
“备份”对博弈树中提议动作的静态评估。从左边的顶点开始,代表棋盘游戏中的当前位置,辐射出三个分支,代表玩家建议的移动。这些中的每一个都可能被各种对手的动作反击,等等。根据一些程序,生成了一个有限树。然后估计每个终端板位置对玩家的价值。(见正文)如果对手有相同的值,他会选择最小化分数,而玩家总是试图最大化。粗线显示了这个最小化过程如何备份,直到确定当前位置的选择。
国际象棋的完整有 10120 个分支——任何人或计算机都无法触及。在评估函数的有效性和树的范围之间存在基本的启发式交换。如果机器可以探索所有连续性,例如 20 个级别,那么非常弱的评估(例如,仅比较玩家的棋子值)将产生毁灭性的游戏。但是只有 6 个关卡,大致在我们目前最大的计算机的范围内,可能不会提供出色的游戏;可能沿着的路线不太详尽的策略会更有利可图。
也许最简单的方案是使用一些选定的位置移动性、前进、中心控制等“属性”函数集的加权和。这是在 Samuel 的程序中完成的,并且在它的大多数前辈中都是如此。与此相关的是用于发现良好系数分配的多重同步优化器方法(使用第 III-A 节中提到的相关技术)。但是强化信号的来源是新颖的。一个人不能为每个学习步骤玩一个或多个完整的游戏。塞缪尔 为每一步测量评估函数直接产生的位置与其预测的结果之间的差异在广泛的继续探索即后备的基础上。此错误的符号“Delta”用于强化;因此系统可能会在每次移动时学到一些东西。
注意:应该注意的是,塞缪尔描述了一个相当成功的跳棋程序,该程序基于记录和检索有关过去遇到的位置的信息,这是一种利用过去经验的不太抽象的方式。Samuel 的工作在使用和不使用各种启发式方法进行的各种实验中都很引人注目。这为真正了解不同启发式方法的比较提供了一个不寻常的机会。更多的工人应该选择(在其他条件相同的情况下)这种变化可行的问题。
D. 学习系统的学分分配问题
在玩国际象棋或跳棋等复杂游戏时,或者在编写计算机程序时,人们有一个明确的成功标准:游戏是赢还是输。但在游戏过程中,每一次最终的成功(或失败)都与大量的内部决策有关。如果运行成功,我们如何在众多决策中为成功分配功劳?正如Newell所指出的:
“在”赢,输或平局“中是否有足够的信息是非常值得怀疑的,当提到整个游戏的玩法时,允许在可用的时间尺度上进行任何学习。为了进行学习,游戏的每次玩法都必须产生更多的信息。这是。。。通过将问题分解为多个组件来实现。成功的单位是目标。如果一个目标得以实现,它的子目标就会得到加强。如果没有,它们就会受到抑制。(实际上,强化的是提供子目标的转换规则。其他类型的结构也是如此:创建的每个策略都提供有关策略搜索规则成功或失败的信息;每个对手的行为都提供了有关可能性推论成功或失败的信息;等等。与学习相关的信息量随着国际象棋机器中机制的数量而直接增加。)
我们完全同意Newell对这个问题的这种处理方式的看法。[另见Samuel的讨论关于为“Delta”的变化分配功劳。]
我的印象是:“自组织”系统和“随机神经网络”领域的许多工作人员并不觉得这个问题的紧迫性。假设一百万个决策涉及一项复杂的任务(例如赢得一个国际象棋游戏)。我们可以为每个决策元素分配完成任务的百万分之一的信用吗?在某些特殊情况下,被加强的连接在一定程度上是独立的,但解决问题的能力相对较弱。
对于更复杂的问题,在层次结构中决策(而不是在同一级别上求和)并且增量足够小以确保可能的收敛,运行时间将变得非常好。对于复杂的问题,我们将不得不以某种丰富的局部意义来定义“成功”。一些困难可以通过使用仔细分级的“训练序列”来避免,如下一节所述。
Friedberg 的程序编写程序:Friedberg 的程序提供了在这个信用分配问题上比较失败的一个重要例子,用于解决程序编写问题。这里的问题是为(模拟的)非常简单的数字计算机编写程序。分配一个简单的问题,例如“计算存储中的两位的与并将结果放在分配的位置。”“生成设备产生一个随机(64 指令)程序。程序运行,它的成功或失败注意。成功信息用于强化个别指令(在固定位置),以便每次成功都倾向于增加成功程序的指令在以后的试验中出现的机会。(我们缺乏关于如何完成的细节的空间。 ) 因此,程序尝试或多或少独立地找到“好”指令,对于程序存储器中的每个位置。这台机器确实学会了解决一些极其简单的问题。但这比纯粹的机会预期要长1000倍。这种失败被讨论并部分归因于我们称之为(IC 部分)的“台面现象”。在一次只更改一条指令时,机器在搜索程序空间时没有采取足够大的步骤。
第二篇论文继续讨论程序生成器及其强化运算符中的一系列修改。有了这些,再加上一些“启动”(用一些有用的指令在正确的轨道上启动机器),系统变得比偶然性差一点。作者得出结论,通过这些改进,“那些具有成功数强化机制的机器的总体性能优于那些没有成功数强化机制的机器,这确实表明这种机制可以为构建学习机器提供基础。”我不同意这个结论。在我看来,每一个“改进”都可以解释为只是为了增加搜索的步长,即机制的随机性;这有助于避免“台面” 现象,从而接近机会行为。但这肯定不能表明“学习机制”正在发挥作用——在争论这一点之前,人们至少希望看到一些比机会更好的结果。问题似乎在于信用分配。工作程序的功劳只能分配给指令的功能组,例如子程序,并且由于这些指令在层次结构中运行,我们不应该期望单独的指令强化能够很好地工作。没有认识到早先提出的怀疑可能是合理的,这似乎令人惊讶。在最后一节中,我们看到了通过将问题分解为多个部分并按顺序解决它们所获得的一些真正成功。这个使用划分子问题的成功演示根本不使用任何强化机制,报道了一些类似性质的实验。
我坚信,任何学习方案或模式识别方案都不能具有非常普遍的效用,除非有递归的规定,或者至少是对先前结果的分层使用。我们不能指望在学习时,系统会在没有为难度越来越大的问题进行合理分级的准备之前处理非常困难的问题。第一个问题必须是可以在合理时间内用初始资源解决的问题。下一个必须能够通过使用第一个开发的方法的合理简单和可访问的组合在合理的时间内解决,依此类推。使用适当的“训练序列”的唯一替代方法是(1) 最初给出的先进资源,或 (2) 可能仅在有机进化史中发现的奇妙探索过程。
[注:然而,应该可以构建学习机制,通过预先安排瓷砖系统设施的相对缓慢的发展或“成熟”,可以从始终复杂的环境中为自己选择相当好的训练序列。'这可以通过预先安排主教练尝试的目标序列在每个阶段合理地匹配模式识别和系统的其他部分机械可用的性能的复杂性来完成。可以通过简单地限制层次活动的深度来完成大部分工作,也许只能在以后允许有限的递归活动。]
即使在那里,如果我们接受 Darlington 的一般观点,他强调遗传系统的启发式方面,我们一定很早就发展了,例如减数分裂和交叉现象,提供隔离的高度专业化机制与子问题的解决方案相关的分组。最近,已经投入了大量精力来构建关于编程“教学机器”的训练序列。自然,心理学文献中充斥着关于复杂行为是如何从简单行为中建立起来的理论。在我们自己的领域,也许 Solomonoff 的工作虽然过于神秘,但显示了对训练序列的这种依赖性的最彻底的考虑。
四、问题解决和规划
概要——通过机器解决非常复杂的问题将需要各种管理设施。在解决问题的过程中,人们会涉及到大量相互关联的子问题。从这些中,在每个阶段,都必须选择极少数进行调查。该决定必须基于 (1) 相对困难的估计和 (2) 不同关注对象的中心性估计。在子问题选择之后(为此提出了几种启发式方法),必须选择适合所选问题的方法。但是对于非常困难的问题,即使是这些逐步减少搜索的启发式方法也会失败,并且机器必须具有分析问题结构的资源,简而言之,用于“计划”。我们讨论了各种规划方案,包括模型的使用——类似的、语义的和抽象的。某些我称之为“字符代数”的抽象模型可以由机器本身在经验或分析的基础上构建。具体而言,讨论从描述一个简单但重要的系统 (LT) 开始,它遇到了其中一些问题。
A. Newell、Shaw 和 Simon“逻辑理论”计划
毫不奇怪,早期解决机械问题的试验场通常是数学或游戏领域,在这些领域中,规则是绝对清晰的。“逻辑'理论”机器,称为“LT”,是通过坦率的启发式方法证明逻辑定理的第一次尝试。尽管按照人类的标准,该程序并没有取得巨大的成功(也没有超越它的设计者),但它在启发式编程和现代自动编程的发展中都是一个里程碑。
这里的问题域是在Russell-Whitehead 系统中为命题微积分发现证明。该系统以一组(五个)公理和(三个)推理规则的形式给出;后者指定了如何应用某些变换来从旧定理和公理产生新定理。
LT 计划的核心是“逆向工作”以找到证据。给定要证明的定理 T,LT 在公理和先前建立的定理中搜索一个,通过三个简单“方法”(体现给定的推理规则)之一的单一应用,可以从中推导出 T。如果找到了,问题就解决了。否则搜索可能会完全失败。但最后,搜索可能会产生一个或多个“问题”,这些“问题”通常是可以直接推导出 T many 的命题。如果其中一个可以反过来被证明为定理,那么主要问题将得到解决。(情况实际上稍微复杂一些。)每个这样的子问题都与“子问题列表”相邻(经过有限的初步尝试),LT 稍后会解决它。LT的全部力量,例如,“反向工作的启发式技术产生了某种目的论过程,LT 是构建目标和子目标层次结构的更复杂系统的先驱。即便如此,程序的基本管理结构也不过是一组通过内存中的列表进行的嵌套搜索。我们将首先概述这个结构,然后提到一些用于提高性能的启发式方法
1. 从问题列表中取出下一个问题。
---------(如果列表为空,则退出失败。)
2. 选择三个基本方法中的下一个。
--------- (如果没有更多方法,请转到 1。)
3. 选择公理列表和先前定理列表中的下一个。
--------- (如果没有,转到 2。)
--------- 将当前方法应用于选定的公理或定理。
--------- 如果问题解决了,有完整的证明退出。
--------- 如果没有结果,转到 3。
--------- 如果出现新的子问题,转到 4。
4) 尝试对子问题的特殊(替代)方法。
--------- 如果问题解决了,有完整的证明退出。
--------- 如果不是,则将子问题附加到问题列表并转到 3。
所研究的启发式方法包括:(1)相似性测试以减少步骤 4 中的工作(包括对定理列表的另一次搜索),(2)从问题列表中选择明显更容易的问题的简单性测试,以及 (3)a强不可证明性检验从问题列表中删除可能是错误的因此无法证明的表达式。在一系列实验中,“学习”被用来找出哪些早期的定理最有用,应该在步骤3中优先考虑。我们无法详细审查这些变化的影响。有趣的是管理某些启发式方法的额外成本与由此产生的搜索减少之间的平衡;在某些情况下,当计算机内存饱和时,这种平衡非常微妙。该系统似乎对训练顺序非常敏感——给出问题的顺序。一些没有显着整体改进的启发式方法确实影响了可解决问题的类别。奇怪的是,任何或所有这些设备都没有大大提高 LT 的总体效率。
Hao Wang 批评了 LT 项目,理由是,正如他和其他人所展示的那样,存在机械化证明方法,对于所考虑的特定问题,使用的机器工作量远低于 LT,并且具有优势他们最终会为任何可证明的命题找到证据。(LT 没有这种详尽的“决策程序”特征,并且可能永远无法找到某些定理的证明。)作者可能不知道存在甚至中等效率的详尽方法,通过与特别低效的详尽程序。尽管如此,我觉得Wang的一些批评是错误的。他似乎没有意识到 LT 的作者对证明这些定理的兴趣不如他们对解决难题的一般问题的兴趣。Russell 和 Whitehead 的组合系统(LT 处理的)远没有 Wang 使用的系统简单和优雅。
Wang的问题虽然在逻辑上是等价的,但形式上要简单得多。他的方法不包括任何使用先前结果的工具(因此它们肯定会在一定程度的问题复杂性下迅速退化),而 LT 基本上是围绕这个问题。最后,由于Wang的方法在所讨论的特定定理上非常有效,他根本不必面对何时决定放弃进攻路线的基本启发式问题。因此,他的程序的强大性能可能将他的注意力从启发式问题上转移了,这些启发式问题在最终遇到真正的数学时必须再次出现。
这并不意味着拒绝Wang的工作和讨论的重要性。他和其他从事“机械数学”研究的人发现,证明程序的效率比人们想象的要高得多。毫无疑问,这样的工作将有助于旅馆构建智能机器,并且如果可用,这些程序肯定会优于“不可靠的启发式方法”。Wang、Davis 和 Putnam 以及其他几个人现在正在将这些新技术推向更具挑战性的谓词演算定理证明领域(不再提供详尽的决策程序),我们没有空间讨论这个领域。
所有这些努力都旨在减少搜索工作量。从这个意义上说,它们都是启发式程序。由于实际上没有人在与“算法”相反的意义上使用“启发式”,因此认真的工作人员可能会避免在这方面毫无意义的争论。真正的问题是找到显着延迟搜索树显然不可避免的指数增长的方法。
B. 子问题选择的启发式
在设计解决问题的系统时,程序员通常会配备一组或多或少不同的“方法”——他的真正任务是为程序找到一种有效的方法来决定何时何地使用不同的方法。不解决问题的方法仍可能将其转化为创建新问题或子问题。因此,在解决一个问题的过程中,我们可能会涉及到大量相互关联的子问题。尚未构想出的“并行”计算机可能一次可在多个计算机上运行。但即使是并行机器也必须有分配资源的程序,因为它不能同时将所有方法应用于所有问题。我们将把这个管理问题分成两部分:选择那些看起来最关键、最有吸引力或最直接的子问题,以及在下一节中选择对选定问题应用哪种方法。
在 LT 的基本程序(第 IV-.X 节)中,子问题选择非常简单。对新问题进行简要检查,并将(如果没有立即解决)放在(线性)问题列表的末尾。主程序沿着这个列表进行(步骤 1),按照问题的产生顺序攻击问题;更强大的系统必须更加明智(无论是在生成问题还是在选择问题时),因为只有这样才能限制过度分支。[请注意,LT 的简单方案具有每个生成的问题最终都会得到关注的特性,即使在第 3 步中创建了几个问题。如果一个人将全部注意力集中在生成的每个问题上,一个人可能永远不会回到替代分支。] 在更复杂的系统中,我们可以期望为每个子问题考虑,至少在这两个方面:1)它的明显“ [人们会想看看所考虑的问题是否与已经考虑的问题相同或非常相似。参见[62]中的讨论。这个问题可以通过简单地更一般地处理 [人们会想看看所考虑的问题是否与已经考虑的问题相同或非常相似。参见[62]中的讨论。这个问题可以通过简单地更一般地处理记住已被攻击的问题的(字符),并根据该记忆检查新的问题。
想象一下,问题及其关系被安排成某种有向图结构 。主要问题是在两个最初区分的节点之间建立“有效”路径。新问题的产生表现为添加新的、尚未生效的路径,或在旧路径中插入新节点。与每个连接关联,描述其当前有效性状态(已解决、合理、可疑等)及其当前估计难度的数量。
全局方法:最通用的问题选择方法是“全局的”——在每一步,它们都会查看整个结构。有一种这样简单的方案可以很好地适用于对我们的问题图的至少一种相当退化的解释。这是基于 CE Shannon 设计的一台机器向我们建议的电气类比,该机器可以玩一种名为“Hex”但在数学家中称为“Nash”的游戏的变体。(在 Shannon 描述了各种有趣的游戏和学习机器。)初始棋盘位置可以表示为特定的电阻网络。
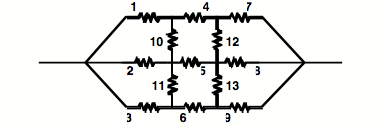
这个游戏是在等电阻的网络上进行的。一个玩家的目标是在两个给定边界之间构建一条短路路径;对手试图打开他们之间的电路。每个动作都包括不可逆转地短路(或打开)剩余的电阻之一。 Shannon的机器在边界之间施加一个电位并选择承载最大电流的电阻器。粗略地说,这个电阻器可能是最关键的,因为改变它会对网络的电阻产生最大的影响,因此,在短路(或打开)电路的目标方向上。虽然这个论点并不完美,也不是真实组合情况的完美模型,但机器确实发挥得非常好。例如,如果机器从打开电阻 1 开始,对手可能会通过短接电阻 4(现在电流最大)来反击。剩余的移动对(如果两个玩家都使用该策略)—将是 (5,8) (9,13) (6,3) (12, 10) 或 (12, 2) — 机器获胜。这种策略在某些情况下可能会做出不合理的举动,但似乎没有人能够在比赛中强制这样做。
[注:写完之后,我确实找到了这样一个策略,击败了这台机器的版本。]
使用这种全局方法进行问题选择需要将相关子问题的可用“难度估计”安排为大致以阻力值的方式组合。此外,我们可以将这台机器视为使用“用于“计划”的模拟模型。(参见第 IV-D 节。)[在 R. Silver 完成的程序中,将匹配网络模拟对手的各种组合方法在麻省理工学院林肯实验室。]
局部和继承方法
每一步都要研究整个问题结构的前景是令人沮丧的,特别是在每次尝试之后结构通常只会略有变化。人们自然会寻找仅仅更新或修改存储记录的一小段的方法。在“先到先得”的问题列表方法和全面的全球调查方法和技术之间存在着各种各样的妥协。也许其中最吸引人的是我们称之为遗传方法的东西——本质上是递归设备。
在继承方法中,分配给子问题的工作量仅由其直接祖先决定;在创建每个问题时,都会为其分配一定的时间或精力总量Q。当一个问题后来被分解为子问题时,这些量由某个局部过程分配给它们,该过程仅取决于它们的相对优点和 Q 的剩余部分。因此,中心性问题被隐式管理。这种方案很容易编程,尤其是新的编程系统,如 IPL 和 LISP,它们本身基于某些遗传或递归操作。当一个人可以与一个简单的全有或全无的Q相处时,就会出现继承方法的特殊情况— 例如,“停止条件”。这产生了 Solomon Golumb称为“回溯”的探索性方法。Jack Wozencraft 的解码过程是继承方法的另一个重要变种。
在 Newell、Shaw 和 Simon 为国际象棋提出的复杂探索过程中,我们有一种具有非数值停止条件的继承方法。在这里,子问题继承了要实现的目标集. 这种目的论控制必须由所有额外的目标选择系统来管理,并且由于备份品种的全局(但相当简单)停止规则[第 III-C 节]而变得更加复杂。(注意:我们在这里将移动树限制问题与问题选择问题识别出来。)虽然还没有广泛的实验结果,但我们认为方案值得任何计划认真工作的人仔细研究区域。它只是展示了我们开发智能机器的复杂性的开始。可以在 Slagle 中找到对这个问题的进一步讨论。
C. “字符法”机器
一旦选择了一个问题,我们必须决定首先尝试哪种方法。这取决于我们对问题进行分类或表征的能力。我们首先计算我们的问题的字符(通过使用一些模式识别技术),然后查阅“字符-方法”表或其他设备,它应该告诉我们哪种方法对那个字符的问题最有效。这些信息可能是根据经验建立的,最初由程序员给出,从“建议”中推导出来,或者作为 GPS 提案中建议的其他问题的解决方案获得。无论如何,从外部来看,这部分机器行为可以被视为一种刺激-反应,或“查表”活动。
如果字符(或描述)的值范围太广,填充字符方法表就会出现严重问题。然后可能不得不减少信息的细节,例如,只使用一些重要的属性。因此 GPS 的 差异[参见第 IV-D 节,2)] 仅描述了定义单个目标所必需的内容,优先方案仅选择其中一个来描述情况。Gelernter 和 Rochester建议使用属性加权方案,这是第 II-G 节中描述的“贝叶斯网络”的一个特例。
D. 规划
通常,人们只能通过将其划分为多个部分来解决复杂的问题,每个部分都可以通过较小的搜索(或进一步划分)来分析。成功的除法将减少搜索时间,而不仅仅是分数,而是分数指数。在从每个节点下降10个分支的图表中,20步搜索可能涉及1020个试验,这是不可能的,而仅插入4个引理或顺序子目标可能会将搜索减少到只有5 * 104个试验,这符合机器探索的理由。因此,在解决复杂问题时,找到这样的“孤岛”是值得的。见[6]第10节。请注意,即使一个人在成功之前遇到106次此类手术失败,在整体试验减少量中仍然会获得10*10倍的系数!因此,实际上,如果问题很困难,那么任何“计划”或“分析”问题的能力都将是有利可图的。可以肯定地说,所有关于如何构建智能机器的简单,统一的概念都会因为某种适度的问题难度而急剧失败。只有积极进行分析以获得一组连续目标的方案才能有望顺利扩展到日益复杂的问题领域。
也许最直接的规划概念是使用问题情况的简化模型。假设对于一个给定的问题,有一些其他“本质上相同的字符”但细节和复杂性较少的问题。然后我们可以先着手解决更简单的问题。还假设这是使用第二组方法完成的,这些方法也更简单,但与原始方法的某些对应关系相同。然后,简单问题的解决方案可以用作较难问题的“计划”。也许每一步都必须详细展开。但是,多个搜索将增加而不是乘以总搜索时间。如果模型在数学上是原始模型的同态,那么情况将是理想的。但即使没有这样的完美,模型解决方案也应该是一个有价值的指南。在数学中,一个人的证明过程通常沿着这些思路运行:例如,首先假设积分和极限总是在规划阶段收敛。一旦大纲完成,这个头脑简单的数学模型,那么人们就会回去试图“严格”证明的步骤,即用真正的推理规则的论证链来取代它们。即使计划失败了,也可以通过替换其几个步骤来修补它。
另一个有助于规划的是语义模型,而不是同态模型。在这里,我们可以在另一个系统中对当前问题进行解释,不一定更简单,但是我们更熟悉它,并且我们知道更强大的方法。因此,关于定理证明的计划,我们将想知道所提出的引理或证明中的岛屿是否实际为真。否则,计划肯定会失败。我们通常可以通过查看解释来轻松判断一个命题是否为真。因此,通过对一些构造图(或解析几何等效物)的实际测量,可以假设平面几何命题的真实性,至少具有很高的可靠性。Gelernter和Rochester的几何机器使用这样的语义模型,结果非常出色,它紧跟提出的路线。
“字符代数”模型:借助模型进行规划在减少搜索方面具有最大的价值。我们可以构建找到自己模型的机器吗?我相信以下内容将提供一种通用的,直接的方法来构建某些有用的抽象模型。关键要求是我们能够编译一个“字符方法矩阵”(除了第 IV-C 节中的简单字符方法表。CM矩阵是一个条目数组,它们以一定的可靠性预测当方法应用于问题时会发生什么。两个矩阵维度都按问题字符编制索引;如果有一种方法通常将字符C的问题转换为字符Cj的问题,那么让矩阵条目Cij成为该方法的名称(或此类方法的列表)。如果没有这样的方法,则相应的条目为 null。
现在假设Cij没有条目,这意味着我们没有直接的方法将Ci类型的问题转换为Cj类型的问题。将矩阵本身相乘。如果新矩阵具有非空 (i, j) 条目,则必须有两个方法的序列来影响所需的转换。如果失败了,我们可能会尝试更高的权力。请注意,[如果我们为(i,i)项设置统一性],我们只需n次乘法即可达到2**2**n矩阵幂。我们不需要定义符号乘法运算;可以使用算术条目,将单位用于原始矩阵中的任何非空条目,将零置于原始矩阵中的任何空条目。这产生了一个简单的连接,或流程图,矩阵,它的n次幂告诉我们一些关于它的长度为2**n的路径集。(一旦发现非空条目,就存在有效的方法来查找相应的方法序列。问题只是找到穿过迷宫的路径,摩尔[71]的方法将非常有效。在一些正式系统中,几乎任何问题都可以转换为在两个终端表达式之间找到一个链的问题。如果将字符视为问题表达式的抽象表示,则此“字符代数”模型可以像可用的模式识别工具一样抽象。
当然,使用字符代数模型进行规划的关键问题是矩阵条目的预测可靠性。不能指望结果的字符由原始字符和所使用的方法严格确定。无论如何,随着矩阵功率的提高,预测的可靠性将迅速恶化。但是,正如我们已经指出的那样,任何计划都比没有好得多,即使预测质量很差,系统也应该比详尽的搜索做得好得多。
这种矩阵公式显然只是角色规划理念的一个特例。更一般地说,一个人将有描述,而不是固定字符,然后必须有更通用的方法,从描述中计算出应用方法时可能发生的事情。
字符和差异:在Newell,Shaw和Simon 的GPS(一般问题解决者)提案中,我们发现一个略有不同的框架:他们使用两个问题(或表达式)之间的差异概念,我们谈论单个问题的特征。如果我们把问题看成是表达式之间的链接或连接,这些视图是等价的。但是,这种差异的概念(作为一对的特征)确实更适合于目的论推理。因为问题所定义的目标是什么,但要减少当前状态和所需状态之间的“差异”?GPS的底层结构正是我们所说的“字符法机器”,其中每种差异在表中都与一种或多种已知“减少”该差异的方法相关联。由于这里的表征总是取决于(1)当前的问题表达和(2)期望的最终结果,因此正如其作者所建议的那样,将GPS视为使用“手段-目的”分析是合理的。
为了说明差异的用法,我们将回顾一个示例。在初等命题演算中,问题是证明从S和(不是P暗示Q)我们可以推导出(Q或P)和S。 该程序通过递归匹配过程查看这两个表达式,该过程从主连接词中分支出来。它遇到的第一个区别是S出现在主连接词“and”的不同侧。因此,它在“更改位置”标题下的“差异方法”表中查找。它发现了一种使用定理(A和B)=(B和A)的方法,这显然有助于消除或“减少”位置的差异。GPS应用这种方法,得到(不是P意味着Q)和S。 然后GPS询问这个新表达式和目标之间的区别是什么。这一次,匹配过程深入到左手成员内部的连接词中,并找到连接词“暗示”和“或”之间的差异。它现在在标题为“Change Connective”的C-M表中查找,并使用不是A暗示B=A或B找到合适的方法。它应用此方法,获得(P或Q)和S。在最后一个循环中,差值评估过程发现在左成员内部需要“改变位置”,并使用(A或B)=(B或A)应用方法。这样就完成了问题的解决方案。
将其描述的“匹配”过程进行比较。“字符”,在描述“GPS”的部分内容时似乎很有用。参考文献包含许多我们无法在这里调查的额外材料。从本质上讲,GPS将自我应用于发现适用于给定问题区域的差异集的问题。这种“自举”的概念——即将一个解决问题的系统应用于改进其自身某些方法的任务——是古老而家庭的,我们也许发现了关于如何实现这种进步的第一个具体建议。
显然,这种“均值-目的”分析在减少一般搜索方面的成功将取决于可以写入差分方法表的特异性程度-基本上与有效字符代数的要求相同。
也可以使用差异进行规划。想象一个“差分代数”,其中预测的形式为D = D1D2。我们必须相应地构造一个差分分解代数,以发现更长的链 D=D1D2 . . Dn 和相应的方法计划。我们应该注意的是,不能指望使用像[15]这样原始差异的计划方法。这些不能形成良好的字符代数,因为(除非它们的表达式具有许多层次的描述性细节)它们的矩阵幂将迅速退化。这种退化最终将限制任何正式规划设备的容量。
人们可能会认为总体规划启发式体现在以下形式的递归过程中。
假设我们有一个问题 P:
为问题 P 制定计划
----选择计划的第一步(下一步)。
-------(如果没有更多步骤,请以“成功”退出。
----尝试建议的方法:
---------成功:返回以尝试计划中的下一步。
---------失败:返回以形成新计划,或者可能更改当前计划以避免此步骤。
----问题判断太难了:将整个过程应用于当前步骤的“子”问题。
观察这样的程序模式本质上是递归的;它将自身用作子例程(在最后一步中显式地),以便必须存储其当前状态,并在将控制权返回给自己时将其还原。[例如,这违反了FORTRAN等编程系统中对“DO循环”的限制。用于编程这些过程的便捷技术由Newell,Shaw和Simon开发程序状态变量存储在“下推列表”中,程序和数据都以“列表结构”的形式存储。Gelernter扩展了FORTRAN来管理其中的一些。McCarthy在LISP]中扩展了这些概念,以允许基于符号表达式的递归函数的语言中程序的显式递归定义。在LISP中,程序状态变量的管理是完全自动化的,另请参阅本期Orchard-Hays的文章。
在第12章和第13章中,Miller, Galanter,和Pribram讨论了人类解决问题和一些启发式计划方案之间可能的类比。似乎可以肯定的是,至少在几年内,人类行为理论与提高机器智力能力的尝试之间将有密切的联系。但是,从长远来看,我们必须准备好发现有益的启发式编程系列,这些编程不会故意模仿人类特征。
空间的限制排除了这里对组织神经网络理论和其他基于大脑类比的模型的详细讨论。其中一些在[C]和[D]中描述或引用。我认为,就启发式编程的主题而言,这种遗漏并不太严重,因为这两个领域的动机和方法似乎如此不同。至少到目前为止,对神经网络模型的研究主要关注的是试图证明某些相当简单的启发式过程,例如强化学习或属性列表模式识别,可以通过简单元素的集合来实现或演变,而无需非常高度组织化的互连。启发式编程工作的特点是寻找新的,更强大的启发式方法来解决非常复杂的问题,并且很少关心什么硬件(神经元或其他)将至少足以实现它。简言之,关于“网”的工作涉及一个人用少量的初始禀赋能走多远。关于“人工智能”的工作涉及利用我们所知道的一切来构建我们所能建立的最强大的系统。我的期望是,在解决问题的能力方面,(据称是类似大脑的)最小结构系统永远不会威胁到与他们更精心设计的同时代人竞争,然而,他们的研究应该在开发组件元件和子系统方面证明是有益的,这些组件元件和子系统将用于构建更系统化的机器。
五、归纳与模型
A. 智能
在所有这些讨论中,我们还没有掌握任何可以独自称为“智能”的东西。我们只讨论了启发式、捷径和分类技术。有什么遗漏吗?我相信迟早我们将能够从启发式设备的复杂组合中组装出具有强大问题解决能力的程序——多个优化器、模式识别技巧、规划代数、递归管理程序等。在其中任何一个中,我们都找不到智能的所在。我们应该问什么是“真正的”智能吗?我自己的观点是,这更像是一个审美问题,或尊严感问题,而不是技术问题!对我来说,“智能”似乎只是指我们碰巧尊重但不理解的复杂表演。通常,数学中的“深度”问题也是如此。一旦一个定理的证明被真正理解,它的内容似乎就变得微不足道了。(不过,对于这个证明是如何被发现的,人们可能仍然感到好奇。)
程序员也知道,程序中从来没有任何“心脏”。每个程序中都有高级例程,但它们所做的只是规定“如果某某,则转移到某某子程序”。当我们查看“实际完成工作”的低级子程序时,我们会发现毫无意义的循环和琐碎的操作序列,只是执行上级的指令。当它被一遍又一遍地深思熟虑地发音时,这样一个系统中的智能似乎就像一个普通单词的含义一样无形。
但是我们不应该让我们无法辨别智能点导致我们得出结论,因此编程的计算机无法思考。因为人类可能如此,就像机器一样,当我们最终了解结构和程序时,神秘感(和自我认可)会减弱。我们发现了关于“创造力”的类似观点。Rosenbloom所表达的思想(或大脑)可以超越机器的观点显然是基于对哥德尔“不可解定理”含义的错误解释。
关于意志问题,我们普遍同意 McCulloch 的观点,即我们的意志自由“大概意味着我们可以区分我们的意图(即我们的计划)和对我们行动的一些干预。” 另见 MacKay及其参考文献;然而,我们不相信他对“模拟”设备的颂扬。关于“心脑”问题,应该考虑 Craik]、Hayek和 Pask的论点。在现代启发式编程的积极领导者中,也许只有 Samuel 对机器思维的想法采取了强有力的立场。他的论点,基于可靠的计算机只做他们被指示做的事情这一事实,有一个基本缺陷。因此,这并不意味着程序员对接下来会发生的事情有完全的了解(因此完全有责任和功劳)。当然,程序员可能会建立一个进化系统,其局限性对他来说是不清楚的,甚至可能是不可理解的。数学家知道一组提议的公理的所有后果再好不过了。肯定是机器必须为了执行。但是,如果系统的操作揭示了程序员无法识别或无法预料的结构,我们就不能将所有功劳归于其程序员。虽然我们还没有看到很多机器智能活动的方式,但塞缪尔在中的论点(循环假设机器没有思想)并不能保证我们不会这样做。图灵对这些问题进行了非常有见地的讨论。
B. 归纳推理
现在让我们为我们的机器摆姿势,各种比任何普通游戏或数学难题都更具挑战性的问题。假设我们想要一台机器,当它被嵌入一个复杂的环境或“宇宙”中一段时间后,它将产生对该世界的描述——以发现它的规律或自然法则。我们可能会要求它预测接下来会发生什么。我们可能会要求它预测某个行动或实验的可能后果。或者我们可以要求它制定管理某类事件的法律。无论如何,我们的任务是为我们的机器配备归纳能力——方法,它可以用来构建关于超出其记录经验的事件的一般陈述。现在,不可能有一个归纳推理系统在所有可能的宇宙中都能很好地工作。但给定一个宇宙,或者宇宙的集合,以及成功的标准,机器的这个(认识论)问题变成了技术问题而不是哲学问题。关于这个主题有相当多的文献,但我们将只讨论目前在我们看来最有前途的一种方法;这就是我们所说的 Solomonoff的“语法归纳”方案,部分基于Chomsky和Miller的工作。
我们将把语言理解为由一组给定的原始符号或表达式通过重复应用给定的一组规则而形成的一组表达式;原始表达式加上规则就是语言的语法。大多数归纳问题都可以归结为发现 gram的问题火星。例如,假设一台机器的先前经验是由大量陈述总结的,其中一些被一些关键设备标记为“好”,一些被标记为“坏”。我们如何有选择地生成更多好的陈述?诀窍是找到一些相对的简单(正式)语言,其中好的语句符合语法,而坏的语句则不是。给定这样的语言,我们可以使用它来生成更多语句,并且可能这些语句会更像好的语句。启发式论证是,如果我们能找到一种相对简单的方法来分离这两个集合,那么发现的规则可能会在直接经验之外有用。如果扩展无法与新数据保持一致,则可以进行一些小的更改在规则中,一般来说,寻找有效语法的问题与寻找有效的机器编码或程序的问题非常相似。在每种情况下,都需要发现数据中的重要规律,并通过精明的缩写来利用这些规律。Solomonoff 的工作 可能的重要性在于,它可能为探索这一发现问题的系统数学方法指明了方向。他考虑了所有程序的类别(对于给定的通用计算机),它们将产生某个给定的输出(有问题的数据体)。如果允许继续,大多数此类程序将添加到该数据体中。通过适当地加权这些程序,也许是按长度,我们可以获得不同可能延续的相应权重,从而为预测提供基础。如果要对这个预测感兴趣,则有必要显示给定计算机的某种独立性;目前尚不清楚这种结果将采取何种形式。
C. 自身模型
如果一个生物可以在没有实际执行该实验的情况下回答有关假设实验的问题,那么答案一定是从该生物内部的某个子机器中获得的。该子机的输出(代表正确答案)以及输入(代表问题)必须是相应外部事件或事件类的编码描述。透过这对编解码通道看,内部子机就像环境一样,具有“模型”的特征。然后可以将归纳推理问题视为构建这样一个模型的问题。
就生物的行为对环境的影响而言,这个世界的内部模型将需要包括生物本身的一些表示。如果有人问这个生物“你为什么决定做某事”(或者如果它自己问这个),任何答案都必须来自内部模型。因此,内省本身的证据很可能最终基于用于构建一个人的自我形象的过程。对这种模型形式的推测导致了一个有趣的预测,即智能机器可能不愿意相信它们只是机器。论据是这样的:我们自己的自我模型具有实质上的“双重”特征;有一部分与物理或机械环境有关(即,无生命物体的行为)——还有一部分与社会和心理问题有关。正是因为我们还没有发展出令人满意的心理活动机械理论,我们才不得不将这些领域分开。即使我们愿意,我们也不能放弃这种划分——直到我们找到一个统一的模型来取代它。
现在,当我们问这样一个生物它是怎样的存在时,它不能简单地回答“直接”。它必须检查其模型。它必须回答说它似乎是一个双重的东西——它似乎有两个部分——一个“头脑”和一个“身体”。因此,即使是机器人,除非配备了令人满意的人工智能理论,否则也不得不在这个问题上保持二元论的观点。
机器本身有一个好的模型的概念存在无限回归的问题:当然,嵌套模型必须丢失细节并最终消失。但是,例如,Hayek的论点——我们不能“完全理解单一秩序”(我们自己的思想)——忽略了递归描述的力量。特别是,它忽略了图灵的演示,即(有足够的外部写作空间)“通用”机器可以回答任何大型机器可以回答的关于自身描述的任何问题。
结论
在试图将“人工智能”工作调查与我们自己的观点总结结合起来时,我们无法提及每个相关的项目和出版物。一些重要的遗漏出现在“大脑模型”领域;Belmont Farley 和 Wesley Clark 的早期工作(也是 Farley 中的论文,经常在不知不觉中被复制,以及 Nathaniel Rochester 和 Peter Milner 的工作) Jerome Lettvin, et al. 的工作的理论有关。我们完全没有触及逻辑和语言的问题,以及必须面对的信息检索问题当动作要基于大内存的内容时;参见,例如,John McCarthy ,我们还没有讨论数学逻辑中与机器可以做什么问题有关的基本结果。有我们甚至几乎没有采样过的全部文献——Nicholas Rashevsky(约 1929 年)和他后来的同事 的大胆开创性;学习理论,例如 Saul Gorn ;博弈论,例如 Martin Shubik;和心理学,例如Jerome Bruner,等。每个人都应该知道 George Polya 关于如何解决问题的工作。我们只能希望传播一些更有野心的项目风格,这些项目直接涉及让机器接管大部分解决问题的任务。
最后一点:我们在这里只讨论了与或多或少独立的问题解决程序有关的工作。但在撰写本文时,我们终于开始看到在构建可用的分时或多程序计算系统方面的积极效果,有了这些系统,将人类与真正的大型机器实时匹配最终将变得经济实惠有益。这意味着我们可以努力对实际上是“思维辅助”的东西进行编程。在未来的几年里,我们预计这些人机系统将在我们向“人工智能”发展的推进中共享,并可能在一段时间内占据主导地位。